
Surface Duo Blog
Build great Android experiences, from AI to foldable and large-screens.
Latest posts

2023 year in review
Hello Android developers, 2023 was the year that machine learning and artificial intelligence really became mainstream, and we covered both topics with a focus on Android implementations. We published series on using the ONNX machine learning runtime, building Android apps with Microsoft Graph, and tutorials for Jetpack Compose developers! Take a look back at all the best posts from 2023… OpenAI on Android The blog focused heavily on working with OpenAI on Android using Kotlin, starting with some basic API access and then building out the JetchatAI demo using a variety of techniques including emb...

Use ONNX Runtime in Flutter
Hello Flutter developers! After recently reading about how Pieces.app uses ONNX runtime inside a Flutter app, I was determined to try it myself. This article shows a summary of the journey I took and provides a few tips for you if you want to do the same. Since we have FFI in Dart for calling C code and ONNX Runtime offers a C library, this is the best way to integrate across most platforms. Before I walk down that path, I decide to have a look at pub.dev to see if anyone did this before me. My thinking here is that anything running ONNX Runtime is a good starting point, even if I must contribute to t...

OpenAI Assistant functions on Android
Hello prompt engineers, This week, we are taking one last look at the new Assistants API. Previous blog posts have covered the Retrieval tool with uploaded files and the Code interpreter tool. In today’s post, we’ll add the function that we’d previously built to the fictitious Contoso employee handbook document chat. Configure functions in the playground We’ll start by configuring the assistant in the OpenAI playground. This isn’t required – assistants can be created and figured completely in code – however it’s convenient to be able to test interactively before doing the work to incorporat...

OpenAI Assistant code interpreter on Android
Hello prompt engineers, Over the last few weeks, we’ve looked at different aspects of the new OpenAI Assistant API, both prototyping in the playground and using Kotlin in the JetchatAI sample. In this post we’re going to add the Code Interpreter feature which allows the Assistants API to write and run Python code in a sandboxed execution environment. By using the code interpreter, chat interactions can solve complex math problems, code problems, read and parse data files, and output formatted data files and charts. To keep with the theme of the last few examples, we are going to test the code in...
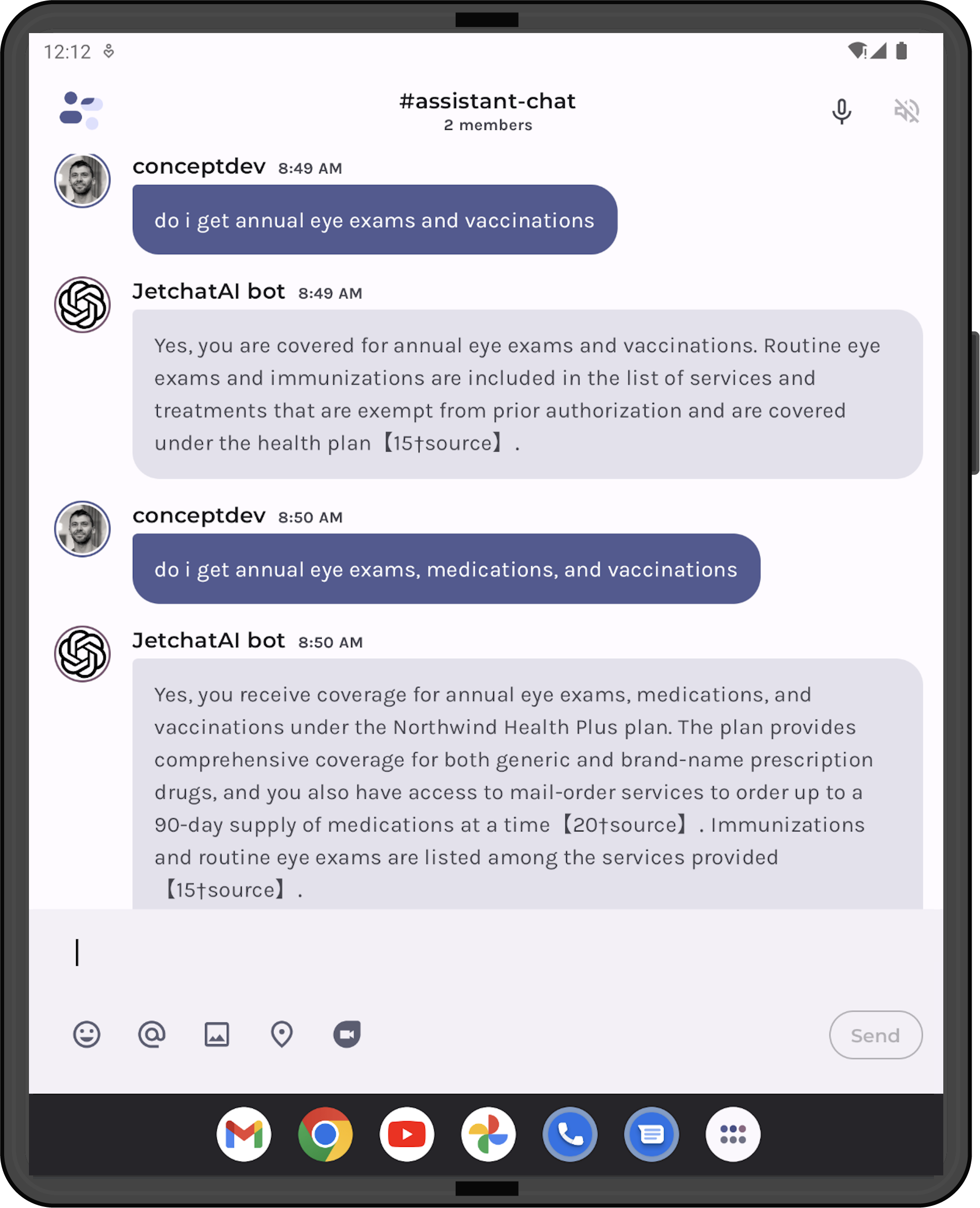
OpenAI Assistant on Android
Hello prompt engineers, This week we’re continuing to discuss the new Assistant API announced at OpenAI Dev Day. There is documentation available that explains how the API works and shows python/javascript/curl examples, but in this post we’ll implement in Kotlin for Android and Jetpack Compose. You can review the code in this JetchatAI pull request. OpenAI Assistants A few weeks ago, we demonstrated building a simple Assistant in the OpenAI Playground – uploading files, setting a system prompt, and performing RAG-assisted queries – mimicking this Azure demo. To refresh your memory, Figure 1 show...
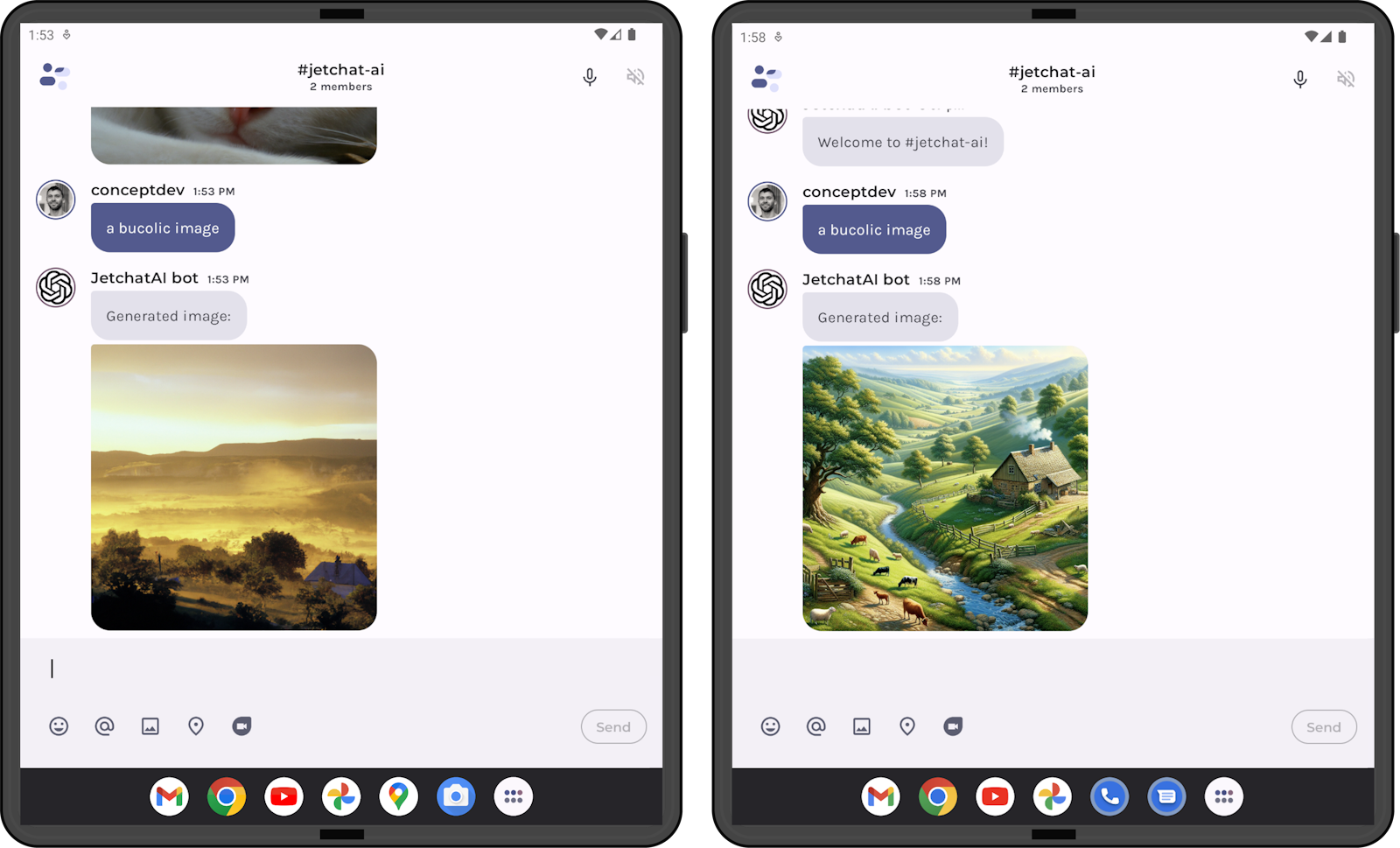
Test the latest AI features in Kotlin
Hello prompt engineers, Last week we looked at one of the new OpenAI features – Assistants – in the web playground, but good news: the OpenAI Kotlin library is already being updated with the new APIs and you can start to try them out right now in your Android codebase with snapshot package builds. With a few minor configuration changes you can start testing the latest AI features and get ready for a supported package release. Use OpenAI Kotlin library snapshots While new features are being added to the Kotlin library, you can track progress from this GitHub issue and the related PRs including sup...
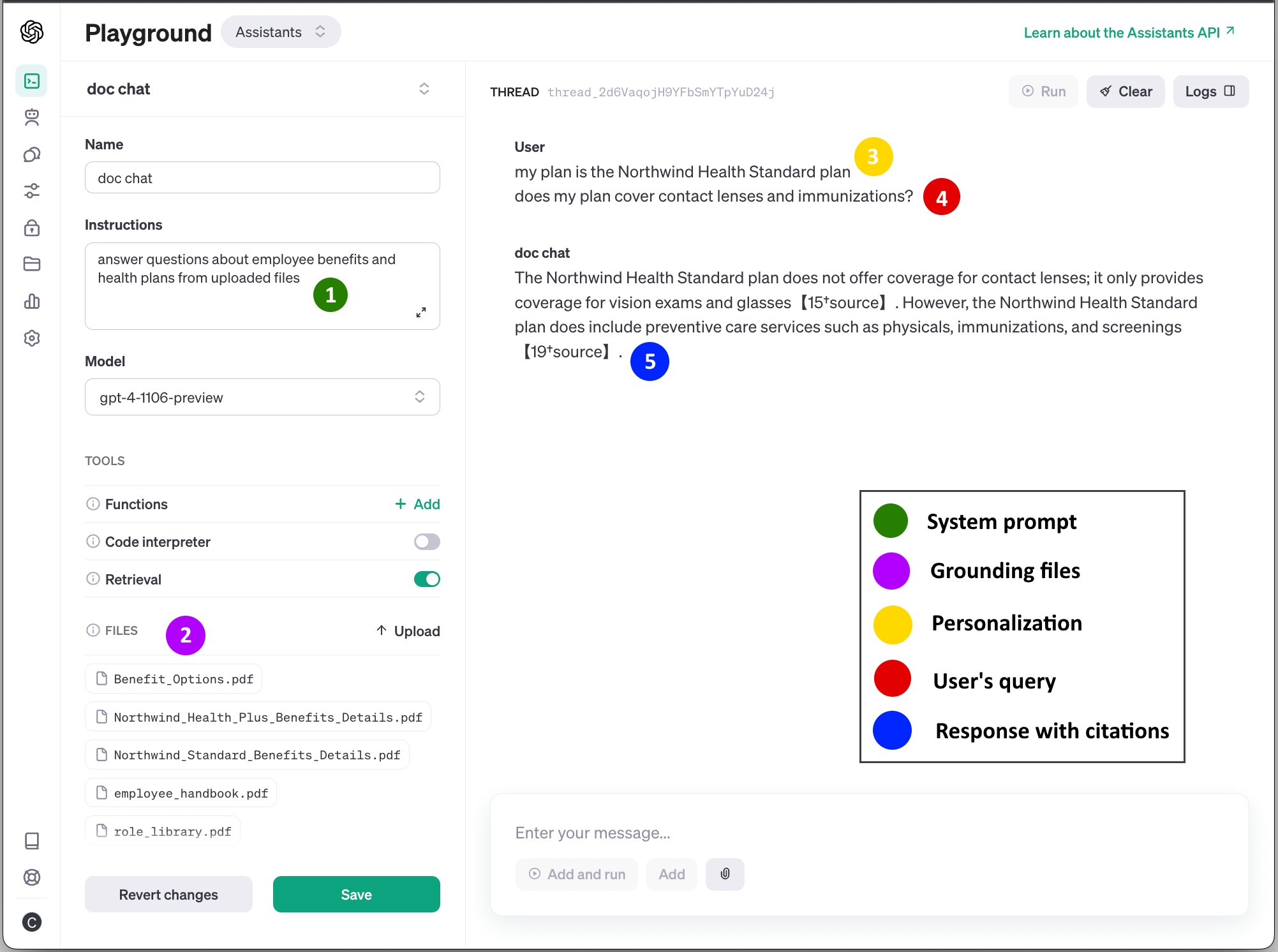
OpenAI Assistants
Hello prompt engineers, OpenAI held their first Dev Day on November 6th, which included a number of new product announcements, including GPT-4 Turbo with 128K context, function calling updates, JSON mode, improvements to GPT-3.5 Turbo, the Assistant API, DALL*E 3, text-to-speech, and more. This post will focus just on the Assistant API because it greatly simplifies a lot of the challenges we’ve been addressing in the JetchatAI Android sample app. Assistants The Assistants overview explains the key features of the new API and how to implement an example in Python. In today's blog post we'll compar...

Chunking for citations in a document chat
Hello prompt engineers, Last week’s blog introduced a simple “chat over documents” Android implementation, using some example content from this Azure demo. However, if you take a look at the Azure sample, the output is not only summarized from the input PDFs, but it’s also able to cite which document the answer is drawn from (showing in Figure 1). In this blog, we’ll investigate how to add citations to the responses in JetchatAI. Figure 1: Azure OpenAI demo result shows citations for the information presented in the response In order to provide similar information in the JetchatAI documen...
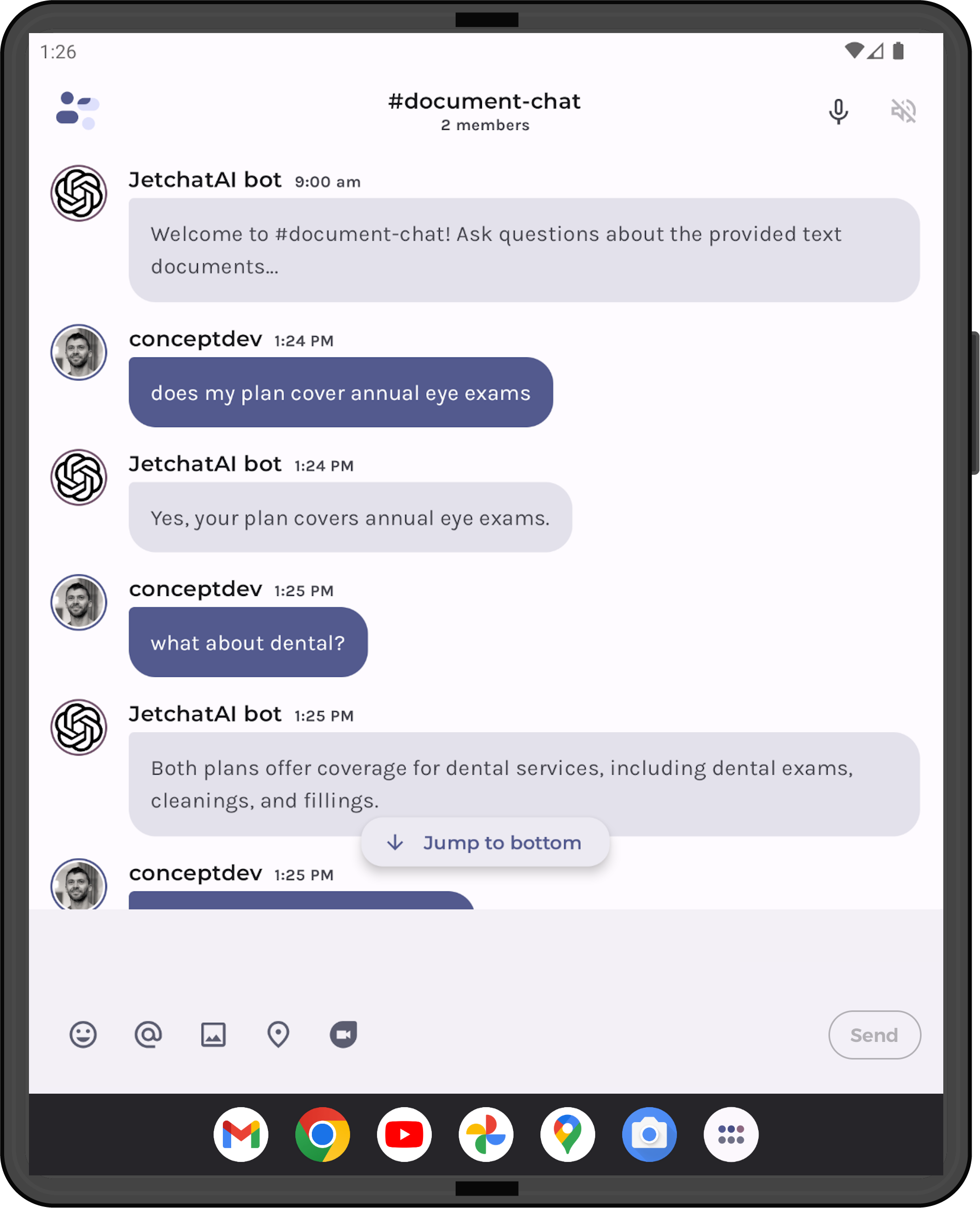
Document chat with OpenAI on Android
Hello prompt engineers, In last week’s discussion on improving embedding efficiency, we mentioned the concept of “chunking”. Chunking is the process of breaking up a longer document (ie. too big to fit under a model’s token limit) into smaller pieces of text, which will be used to generate embeddings for vector similarity comparisons with user queries (just like the droidcon conference session data). Inspired by this Azure Search OpenAI demo, and also the fact that ChatGPT itself released a PDF-ingestion feature this week, we’ve added a “document chat” feature to the JetchatAI Android sample ap...

More efficient embeddings
Hello prompt engineers, I’ve been reading about how to improve the process of reasoning over long documents by optimizing the chunking process (how to break up the text into pieces) and then summarizing before creating embeddings to achieve better responses. In this blog post we’ll try to apply that philosophy to the Jetchat demo’s conference chat, hopefully achieving better chat responses and maybe saving a few cents as well. Basic RAG embedding When we first wrote about building a Retrieval Augmented Generation (RAG) chat feature, we created a ‘chunk’ of information for each conference session....
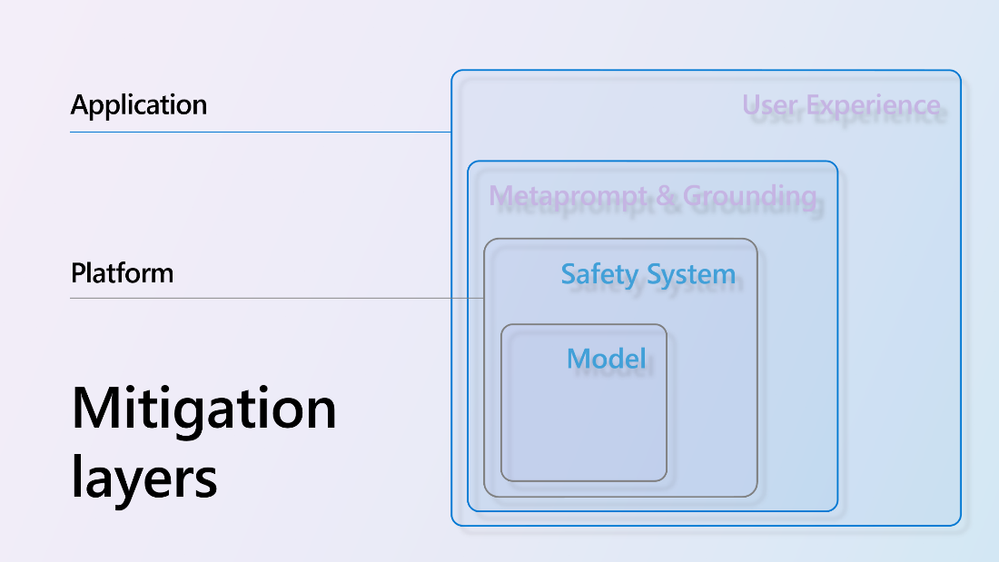
Responsible AI and content safety
Hello prompt engineers, This week we’re taking a break from code samples to highlight the general availability of Azure AI Content Safety. In this blog series we’ve touched briefly on the using prompt engineering to restrict the types of responses an LLM will provide, such as setting the system prompt to set boundaries on what questions will be answered: Figure 1: System prompt set to "You will answer questions about the speakers and sessions at the droidcon SF conference." However, ensuring a high-quality user experience goes beyond simple guardrails like this. You want your application’...

“Search the web” for up-to-date OpenAI chat responses
Hello prompt engineers, Over the course of this blog series, we have investigated different ways of augmenting the information available to an LLM when answering user queries, such as: However, there is still a challenge getting the model to answer with up-to-date “general information” (for example, if the question relates to events that have occurred after the model’s training). You can see a “real life” example of this when you use Bing Chat versus ChatGPT to search for a new TV show called “Poker Face” which first appeared in 2023: Figure 1: ChatGPT 3.5 training end...
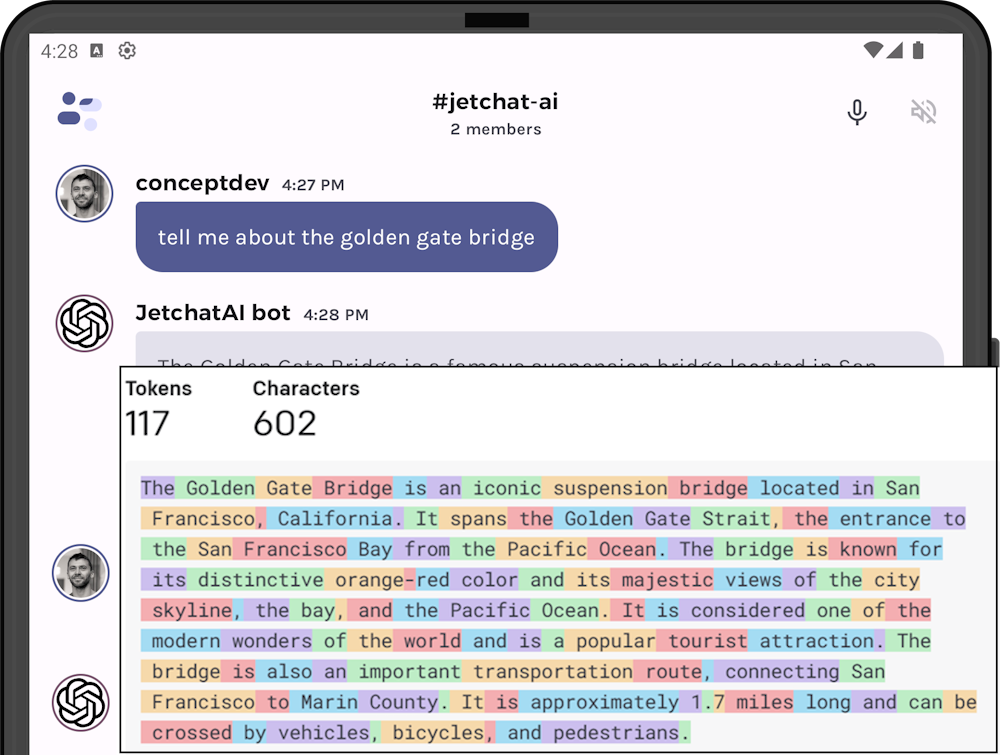
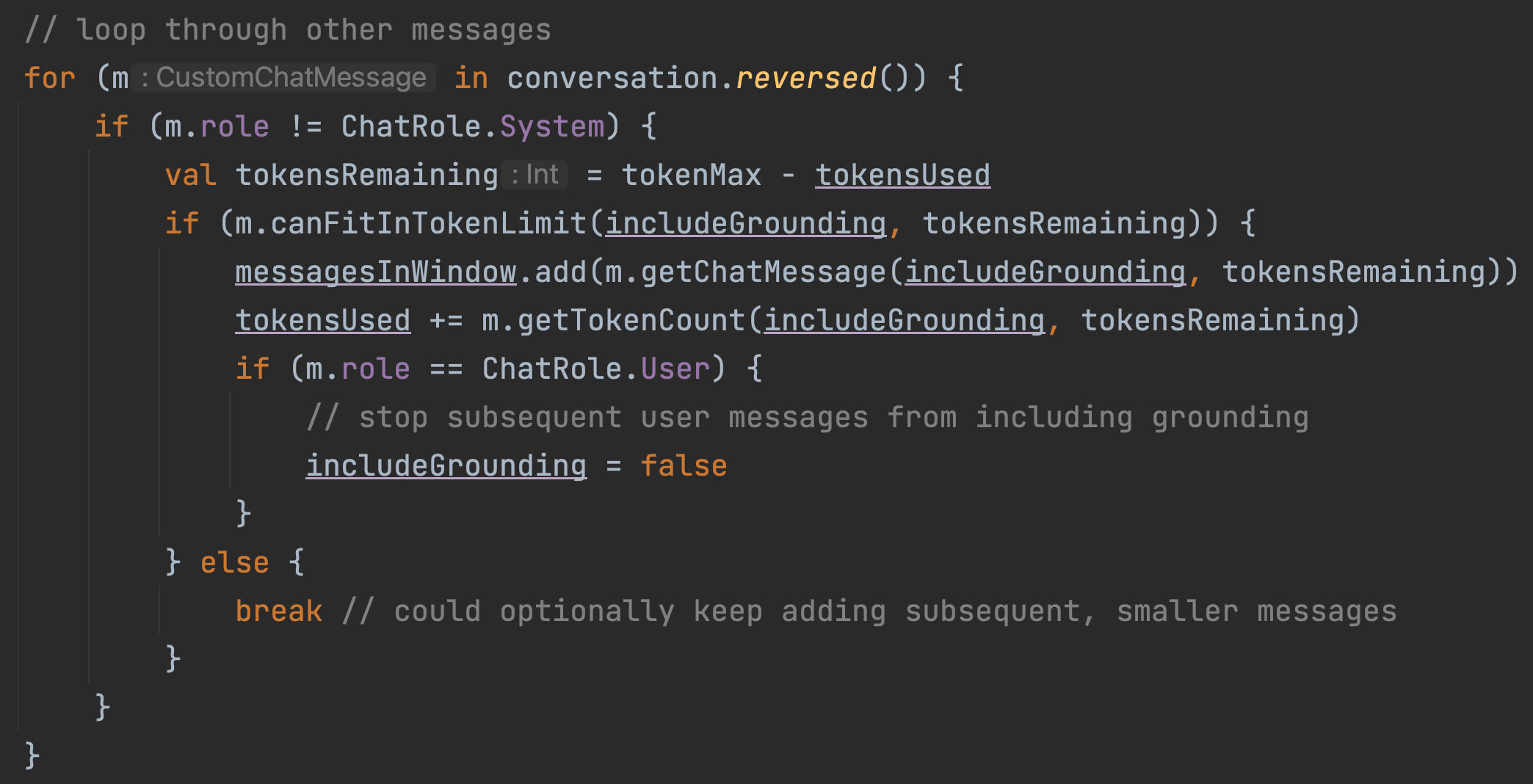
Android tokenizer for OpenAI
Hello prompt engineers, The past few weeks we’ve been extending JetchatAI’s sliding window which manages the size of the chat API calls to stay under the model’s token limit. The code we’ve written so far has used a VERY rough estimate for determining the number of tokens being used in our LLM requests: This very simple approximation is used to calculate prompt sizes to support the sliding window and history summarization functions. Because it’s not an accurate result, it’s either inefficient or risks still exceeding the prompt token limit. Turns out that there is an Android-compatible ...
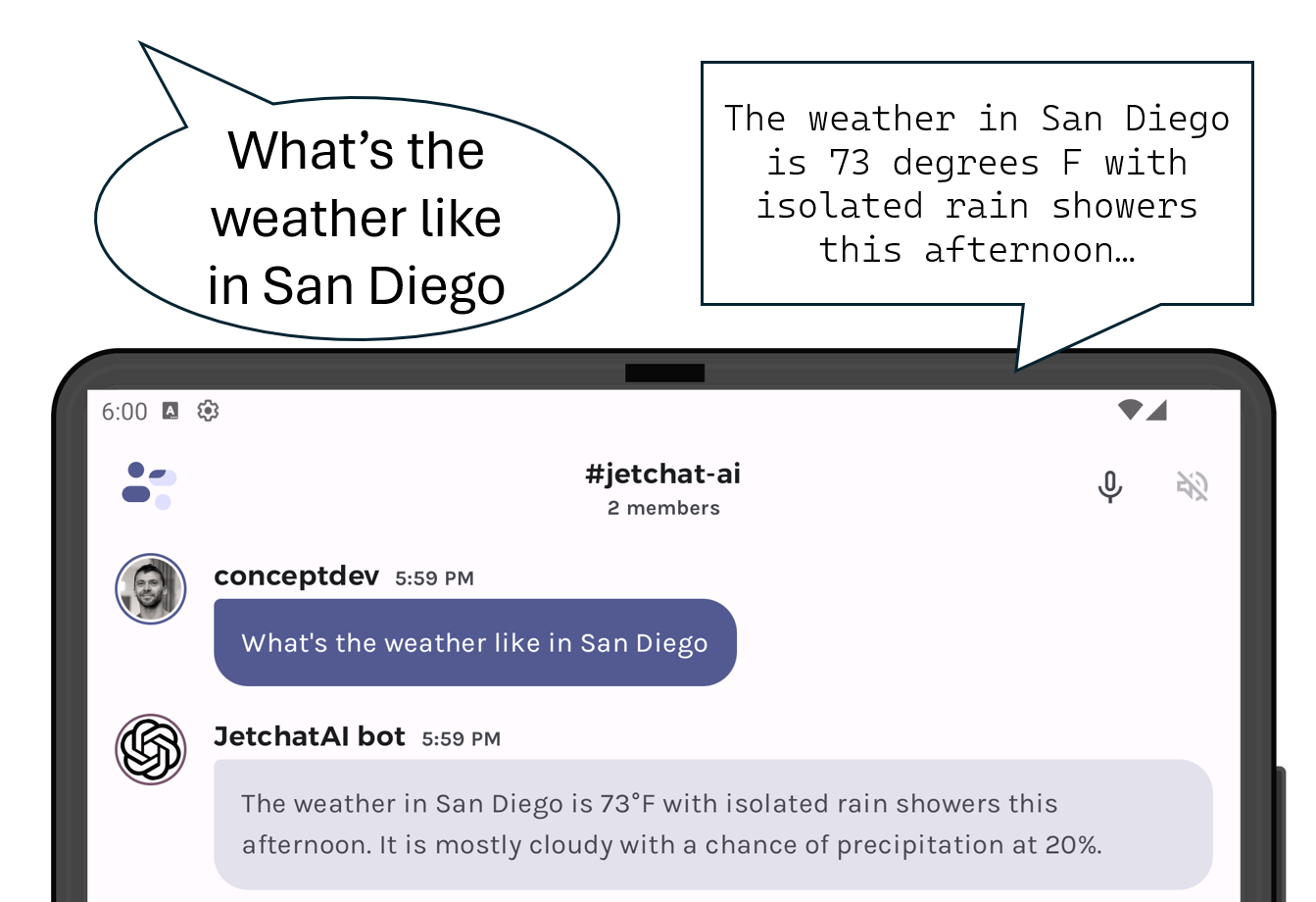
Speech-to-speech conversing with OpenAI on Android
Hello prompt engineers, Just this week, OpenAI announced that their chat app and website can now ‘hear and speak’. In a huge coincidence (originally inspired by this Azure OpenAI speech to speech doc), we’ve added similar functionality to our Jetpack Compose LLM chat sample based on Jetchat. The screenshot below shows the two new buttons that enable this feature: Figure 1: The microphone and speaker-mute icons added to Jetchat The speech that is transcribed will be added to the chat as though it was typed and sent directly to the LLM. The LLM’s response is then automati...
Infinite chat with history embeddings
Hello prompt engineers, The last few posts have been about the different ways to create an ‘infinite chat’, where the conversation between the user and an LLM model is not limited by the token size limit and as much historical context as possible can be used to answer future queries. We previously covered: These are techniques to help better manage the message history, but they don’t really provide for “infinite” memory. This week, we will investigate storing the entire chat history with embeddings, which should get us closer to the idea of “infinite chat”. One of the first fe...
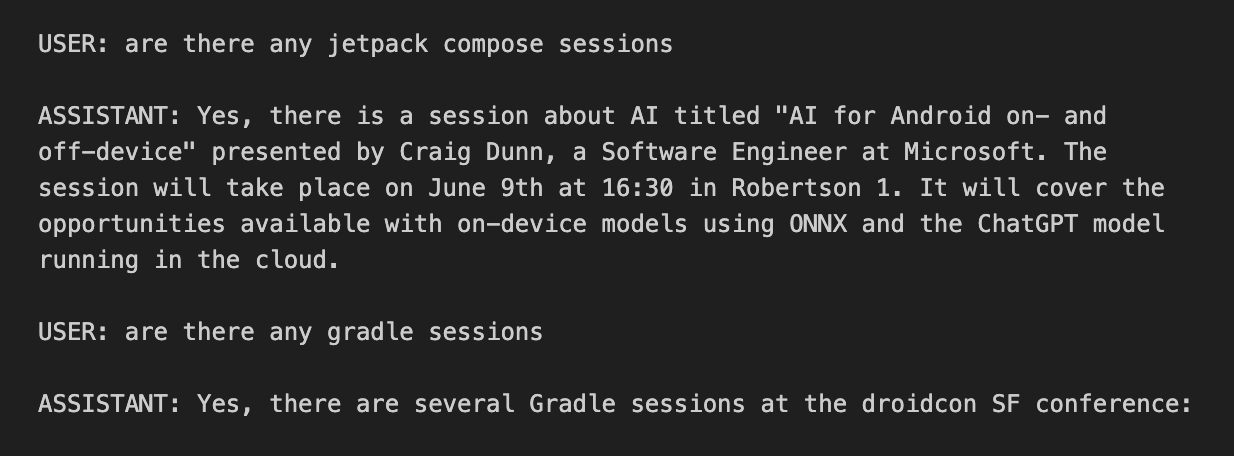
“Infinite” chat with history summarization
Hello prompt engineers, A few weeks ago we talked about token limits on LLM chat APIs and how this prevents an infinite amount of history being remembered as context. A sliding window can limit the overall context size, and making the sliding window more efficient can help maximize the amount of context sent with each new chat query. However, to include MORE relevant context from a chat history, different approaches are required, such as history summarization or using embeddings of past context. In this post, we’ll consider how summarizing the conversation history that’s beyond the slidi...
De-duplicating context in the chat sliding window
Hello prompt engineers, Last week’s post discussed the concept of a sliding window to keep recent context while preventing LLM chat prompts from exceeding the model’s token limit. The approach involved adding context to the prompt until we've reached the maximum number of tokens the model can accept, then ignoring any remaining older messages and context. This approach doesn’t take into account that some context is duplicated when the results are augmented with embeddings or local functions, because the request contains the augmented source data AND the model’s response contains the relevant in...
Infinite chat using a sliding window
Hello prompt engineers, There are a number of different strategies to support an ‘infinite chat’ using an LLM, required because large language models do not store ‘state’ across API requests and there is a limit to how large a single request can be. In this OpenAI community question on token limit differences in API vs Chat, user damc4 outlines three well-known methods to implement infinite chat: The thread also suggests tools like Langchain can help to implement these approaches, but for learning purposes, we’ll examine them from first principles within the context of the...

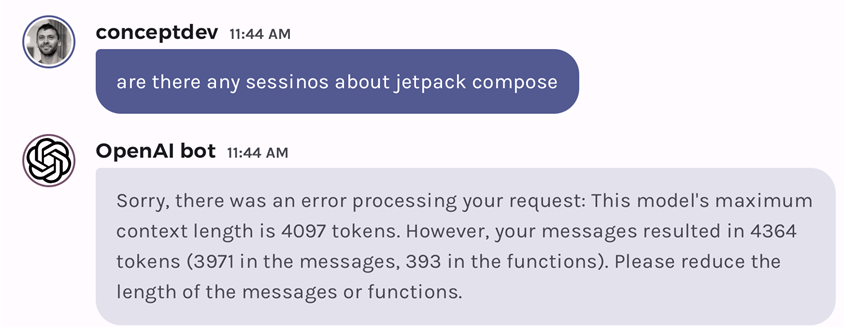
OpenAI tokens and limits
Hello prompt engineers, The Jetchat demo that we’ve been covering in this blog series uses the OpenAI Chat API, and in each blog post where we add new features, it supports conversations with a reasonable number of replies. However, just like any LLM request API, there are limits to the number of tokens that can be processed, and the APIs are stateless meaning that all context needed for a given request must be included in the prompt. This means that each chat request and response gets added to the conversation history, and the whole history is sent to the API after each new input so that the co...
Prompt engineering tips
Hello prompt engineers, We’ve been sharing a lot of OpenAI content the last few months, and because each blog post typically focuses on a specific feature or API, there’s often smaller learnings or discoveries that don’t get mentioned or highlighted. In this blog we’re sharing a few little tweaks that we discovered when creating LLM prompts for the samples we’ve shared. Set the system prompt The droidcon SF sessions demo has a few different instructions in its system prompt, each for a specific purpose (explained below): Keep the chat focused The first part of the sy...
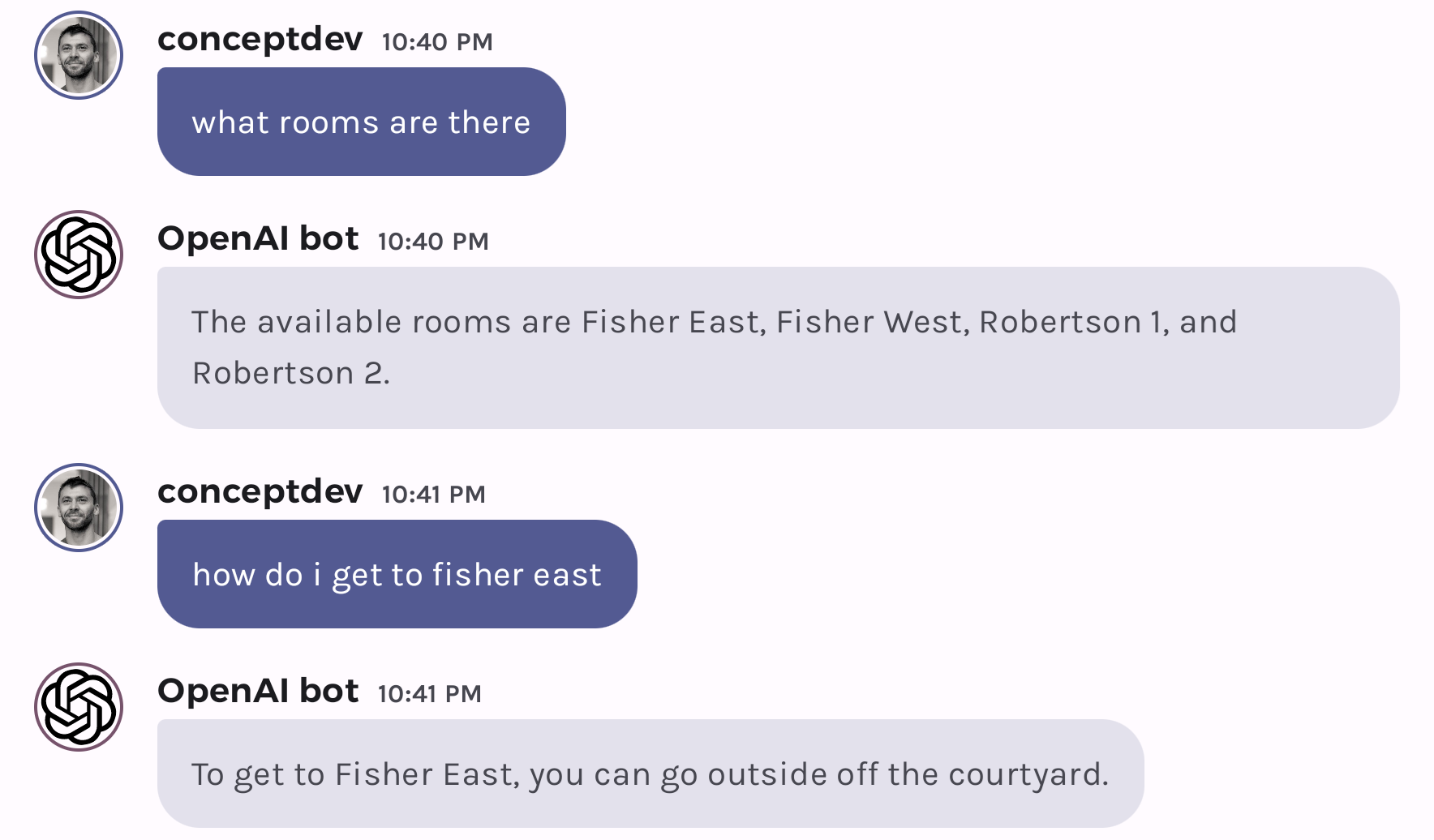
Dynamic Sqlite queries with OpenAI chat functions
Hello prompt engineers, Previous blogs explained how to add droidcon session favorites to a database and also cache the embedding vectors in a database – but what if we stored everything in a database and then let the model query it directly? The OpenAI Cookbook examples repo includes a section on how to call functions with model generated arguments, which includes a python demo of a function that understands a database schema and generates SQL that is executed to answer questions from the chat. There’s also a natural language to SQL demo that demonstrates the model’s understanding of SQL. ...

Embedding vector caching (redux)
Hello prompt engineers, Earlier this year I tried to create a hardcoded cache of embedding vectors, only to be thwarted by the limitations of Kotlin (the combined size of the arrays of numbers exceeded Kotlin’s maximum function size). Now that we’ve added Sqlite to the solution to support memory and querying, we can use that infrastructure to also cache the embedding vectors. Note that the version of Sqlite we’ll use on Android does not have any special “vector database” features – instead, the embedding vectors will just be serialized/deserialized and stored in a column. Embedding vector simil...
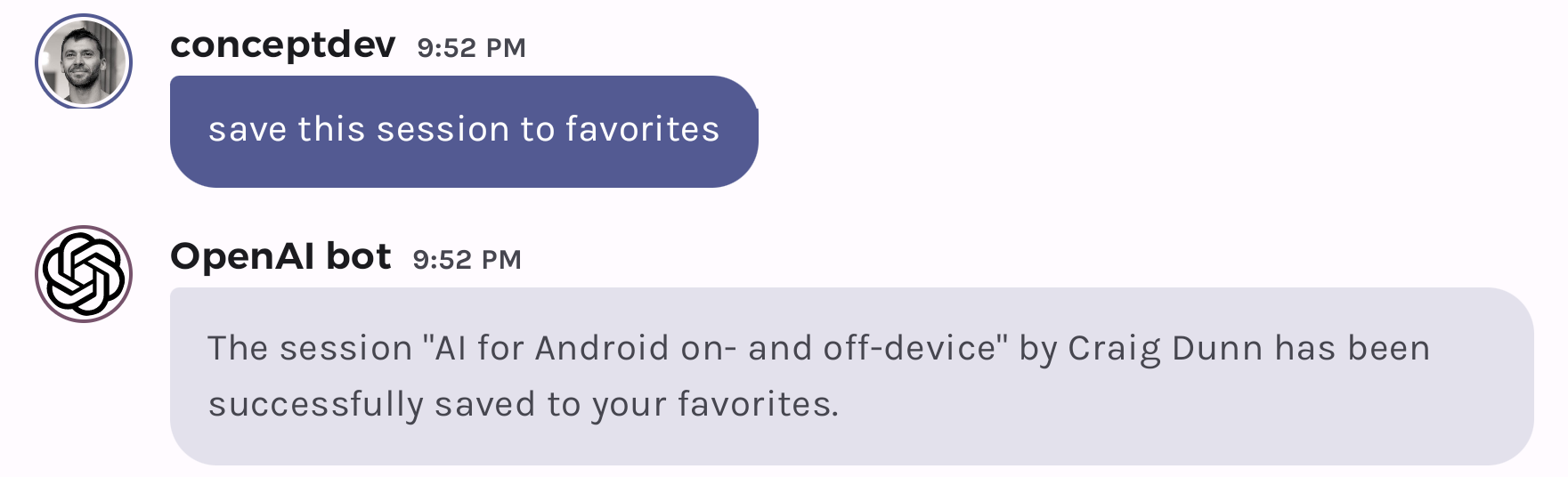
Chat memory with OpenAI functions
Hello prompt engineers, We first introduced OpenAI chat functions with a weather service and then a time-based conference sessions query. Both of those examples work well for ‘point in time’ queries or questions about a static set of data (e.g., the conference schedule). But each time the JetchatAI app is opened, it has no recollection of previous chats. In this post, we’re going to walk through adding some more function calls to support “favoriting” (and “unfavoriting”) conference sessions so they can be queried later. Figure 1: saving and retrieving a favorited session This will ...
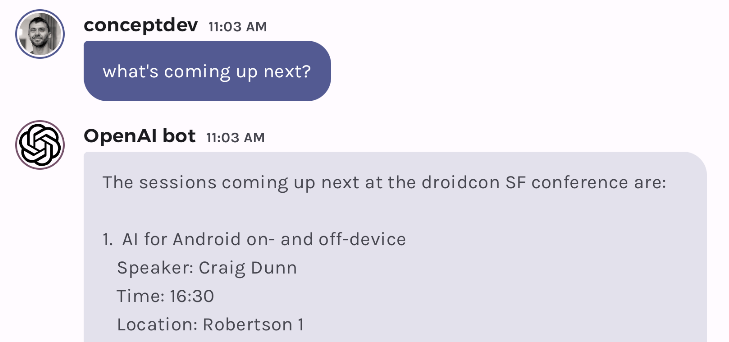
Combining OpenAI function calls with embeddings
Hello prompt engineers, Last week’s post introduced the OpenAI chat function calling to implement a live weather response. This week, we’ll look at how to use function calling to enhance responses when using embeddings to retrieve data isn’t appropriate. The starting point will be the droidcon SF sample we’ve covered previously: Figure 1: droidcon chat and the questions it can answer using the system prompt or embedding similarity As you can see, the droidcon chat implementation can answer questions like “when is droidcon SF?” (using grounding in the system prompt) and “are there any AI s...
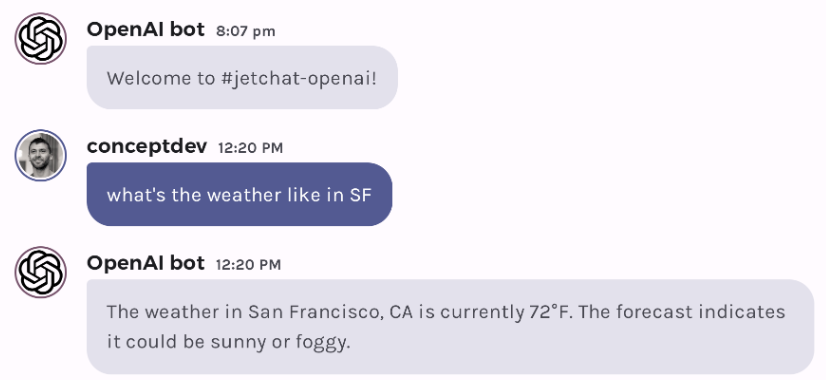
OpenAI chat functions on Android
Hello prompt engineers, OpenAI recently announced a new feature – function calling – that makes it easier to extend the chat API with external data and functionality. This post will walk through the code to implement a “chat function” in the JetchatAI sample app (discussed in earlier posts). Following the function calling documentation and the example provided by the OpenAI kotlin client-library, a real-time “weather” data source will be added to the chat. Figures 1 and 2 below show how the chat response before and after implementing the function: Figure 1: without a function to provide r...

Multimodal Augmented Inputs in LLMs using Azure Cognitive Services
Hello AI enthusiasts, This week, we’ll be talking about how you can use Azure Cognitive Services to enhance the types of inputs your Android AI scenarios can support. What makes an LLM multimodal? Popular LLMs like ChatGPT are trained on vast amounts of text from the internet. They accept text as input and provide text as output. Extending that logic a bit further, multimodal models like GPT4 are trained on various datasets containing different types of data, like text and images. As a result, the model can accept multiple data types as input. In a paper titled Language Is Not Al...
Embedding vector caching
Hello prompt engineers, A few weeks ago I added a custom datastore (the droidcon SF schedule) to the Jetchat OpenAI chat sample. One of the ‘hacks’ I used was generating the embeddings used for similarity comparisons on every startup and caching in memory: This results in ~70 web requests each time, plus the (albeit low) monetary cost of the OpenAI embeddings endpoint. It is a fast and easy way to build a demo, but in a production application you would want to avoid both the startup delay and the cost! In this post I’ll discuss my first attempt building a vector cache on-device, and the...