
Hello prompt engineers,
Last week’s post discussed the concept of a sliding window to keep recent context while preventing LLM chat prompts from exceeding the model’s token limit. The approach involved adding context to the prompt until we’ve reached the maximum number of tokens the model can accept, then ignoring any remaining older messages and context.
This approach doesn’t take into account that some context is duplicated when the results are augmented with embeddings or local functions, because the request contains the augmented source data AND the model’s response contains the relevant information that was extracted. It’s questionable whether we need the grounding data in the chat history (to be re-sent as context for future answers).
This post considers how the sliding window could be more efficient if we excluded embeddings source from the chat context so that more chat messages can be included in the context window.
What’s in a RAG?
RAG stands for Retrieval Augmented Generation, which we first explored in the post JetchatAI gets smarter with embeddings. This works by having a dataset that is pre-processed into chunks of information and then generating an embedding vector for each piece of information. When the user writes a message that will be sent to the LLM model, an embedding is calculated for that too, and compared to the database of content embeddings. Content that is determined to be a close match to the query is included in the chat completion request to the model, so that the model can summarize and answer accurately based on the matching information.
As an example, if the user types a query “is there a talk on gradle” in the droidcon chat example, that phrase’s embedding is ‘close’ to six droidcon sessions. The session summary for all six sessions is therefore included in the prompt. That data is shown in Figure 1 below – 8,096 characters and 1,795 tokens:
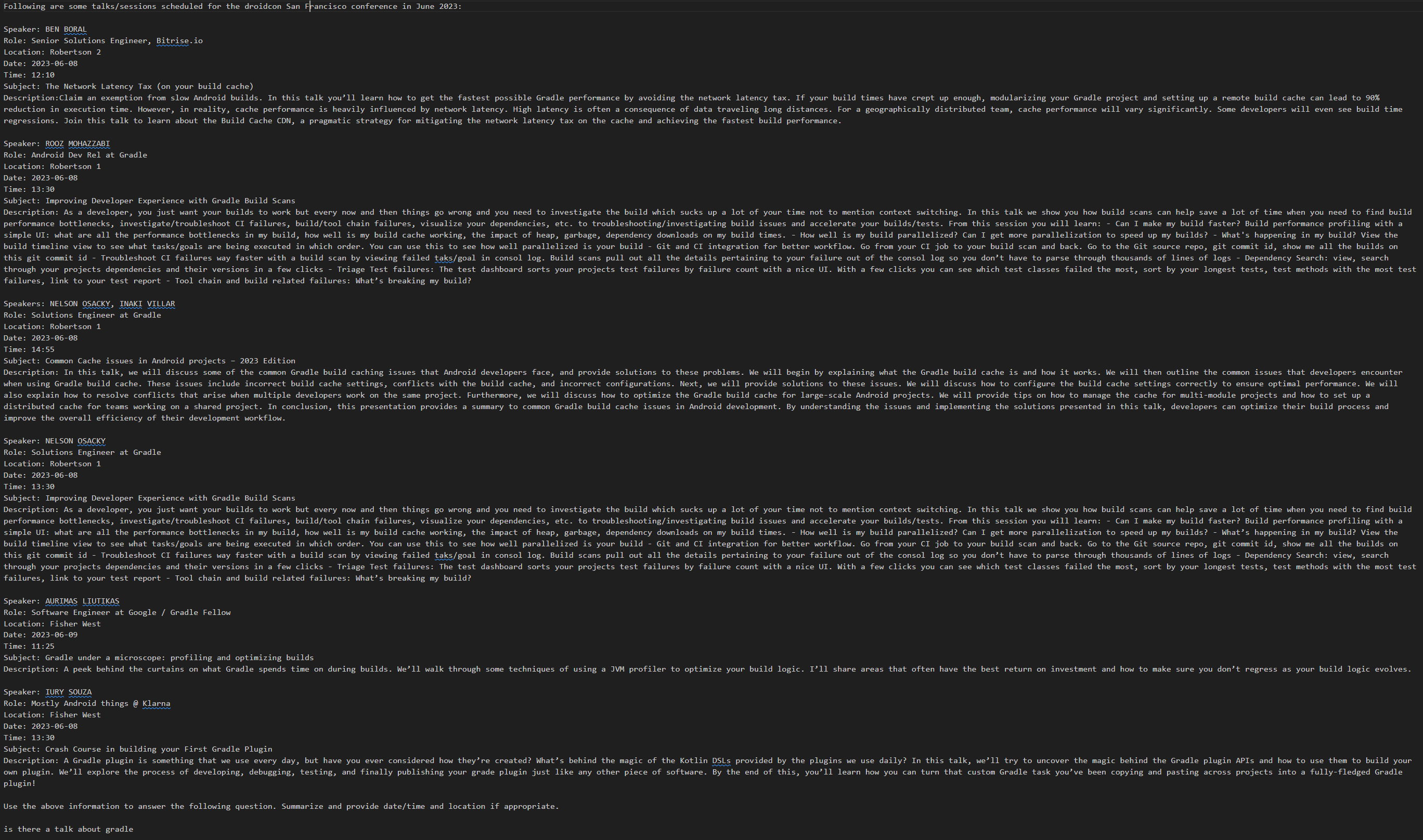
Figure 1: augmented source data for a query – six sessions summaries that will be used to answer a user query. This isn’t meant to be readable, just to provide a visualization of how much data is sent to support a simple six word query.
Since that source is unreadable Figure 1 screenshot, here’s an example snippet (five of the six session summaries omitted for clarity) in Figure 2:
Following are some talks/sessions scheduled for the droidcon San Francisco conference in June 2023: Speaker: BEN BORAL Role: Senior Solutions Engineer, Bitrise.io Location: Robertson 2 Date: 2023-06-08 Time: 12:10 Subject: The Network Latency Tax (on your build cache) Description: Claim an exemption from slow Android builds. In this talk you’ll learn how to get the fastest possible Gradle performance by avoiding the network latency tax. If your build times have crept up enough, modularizing your Gradle project and setting up a remote build cache can lead to 90% reduction in execution time. However, in reality, cache performance is heavily influenced by network latency. High latency is often a consequence of data traveling long distances. For a geographically distributed team, cache performance will vary significantly. Some developers will even see build time regressions. Join this talk to learn about the Build Cache CDN, a pragmatic strategy for mitigating the network latency tax on the cache and achieving the fastest build performance. . . . OTHER FIVE SESSION SUMMARIES OMITTED FOR CLARITY . . . Use the above information to answer the following question. Summarize and provide date/time and location if appropriate. is there a talk about gradle?
Figure 2: the user query “is there a talk about gradle” is submitted along with embedding data and additional prompt hints. The format is shown here (with some data omitted for clarity)
All 8,096 characters are sent to the chat API, and then the model’s response is shown to the user. You can read more about how embeddings work in the post JetchatAI gets smarter with embeddings. Figure 3 shows what they see in the app – their original query and the model’s summarized result:
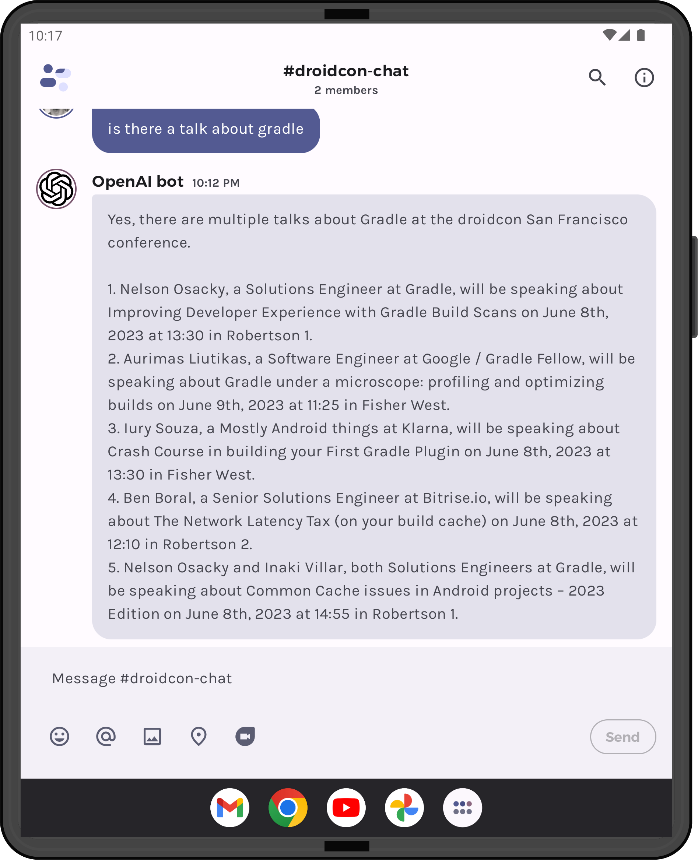
Figure 3: a RAG query and response
Given that what the user sees makes the most sense to keep as context for future queries, we could update the algorithm to discard the embeddings that were originally sent in all past completion requests. This makes even more sense if you consider that the query in Figure 4 returns the same six embeddings (8,096 characters, 1,795 tokens), but only needs a fraction of that to show the correct answer:
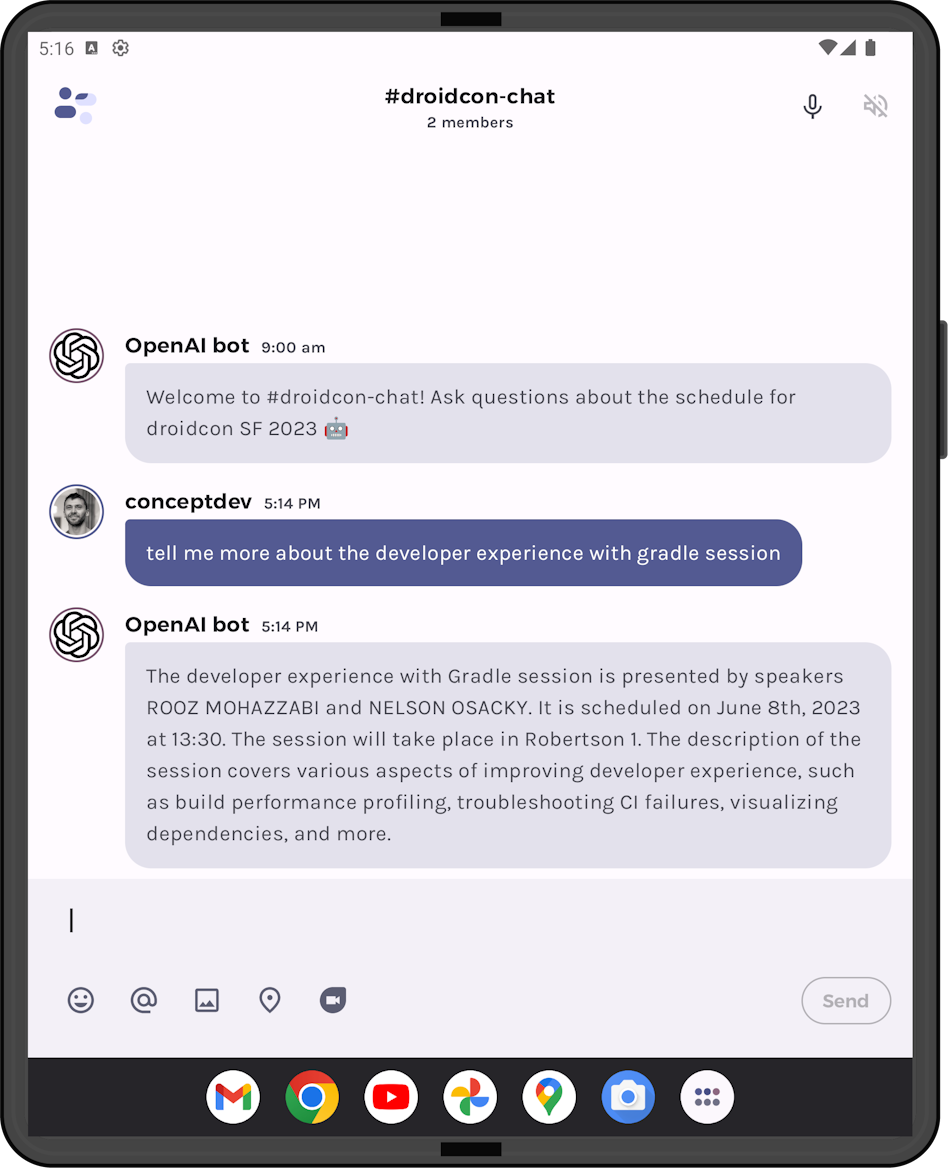
Figure 4: this query results in the same set of embeddings as Figure 3
This is a good example of why it makes sense to trim the embeddings grounding data for this query the next time we submit the chat history to the completion API – six embeddings matched the query, but the model determined that only one of them answered the question. What’s displayed back to the user should be sufficient context to keep in the chat history.
The code changes below will remove embedding context from the chat history, so that the sliding window can accommodate more history (measured by number of messages) by giving up unnecessary or duplicate context that only makes sense in for the “current” query being sent to the model. This should improve the ability of the chat to remember more context overall before discarding messages outside the sliding window.
De-dup’ing context in conversation history
You can see the changes to support this more efficient use of context history in this pull request on GitHub:
-
The main
conversationvariable was updated to be of typeCustomChatMessageso that we can manage the grounding content in a more granular fashion. -
In the
CustomChatMessageclass:-
userContentandgroundingvariables are set independently, so that we can optionally exclude the grounding. In previous versions of the code, these were concatenated together. -
getTokenCount– new function that calculates the size of the message in tokens. -
canFitInTokenLimit– new function that compares the message’s size to the token limit. -
Existing
CustomChatMessage.getChatMessagefunction has been updated to include or exclude the grounding context as required.
-
Compared to the code shared last week, the sliding window logic (SlidingWindow.kt) has changed slightly to use the includeGrounding boolean value. As shown in Figure 5, the CustomChatMessage functions all have this added to their parameters so that the ChatMessage objects that are used in the completion request can be crafted to include or exclude the grounding as part of the prompt. The includeGrounding starts true to ensure the most recent message includes the grounding context; and is then set to false to ensure subsequent messages in the history do NOT include large amounts of grounding data.
for (message in conversation.reversed()) {
if (m.role != ChatRole.System) {
val tokensRemaining = tokenMax - tokensUsed
if (m.canFitInTokenLimit(includeGrounding, tokensRemaining)) {
messagesInWindow.add(m.getChatMessage(includeGrounding, tokensRemaining))
tokensUsed += m.getTokenCount(includeGrounding, tokensRemaining)
if (m.role == ChatRole.User) {
includeGrounding = false // stop subsequent user messages from including grounding
}
} else {
break // could optionally keep adding subsequent, smaller messages to context up until token limit
}
}
}
Figure 5: Updated sliding window code only includes the embeddings grounding data for the ‘current user query’
You will notice in Figure 5 that there is another new variable –
tokensRemaining. This was added to further customize thegetChatMessagefunction, which fixes a bug discussed in the next section.
To see the updated algorithm in action, figure 6 shows the logcat from the old code on the left and the new code on the right. You can see that the assistant messages use roughly the same number of tokens, but the user messages (which is where we send the embedding context) are much smaller.
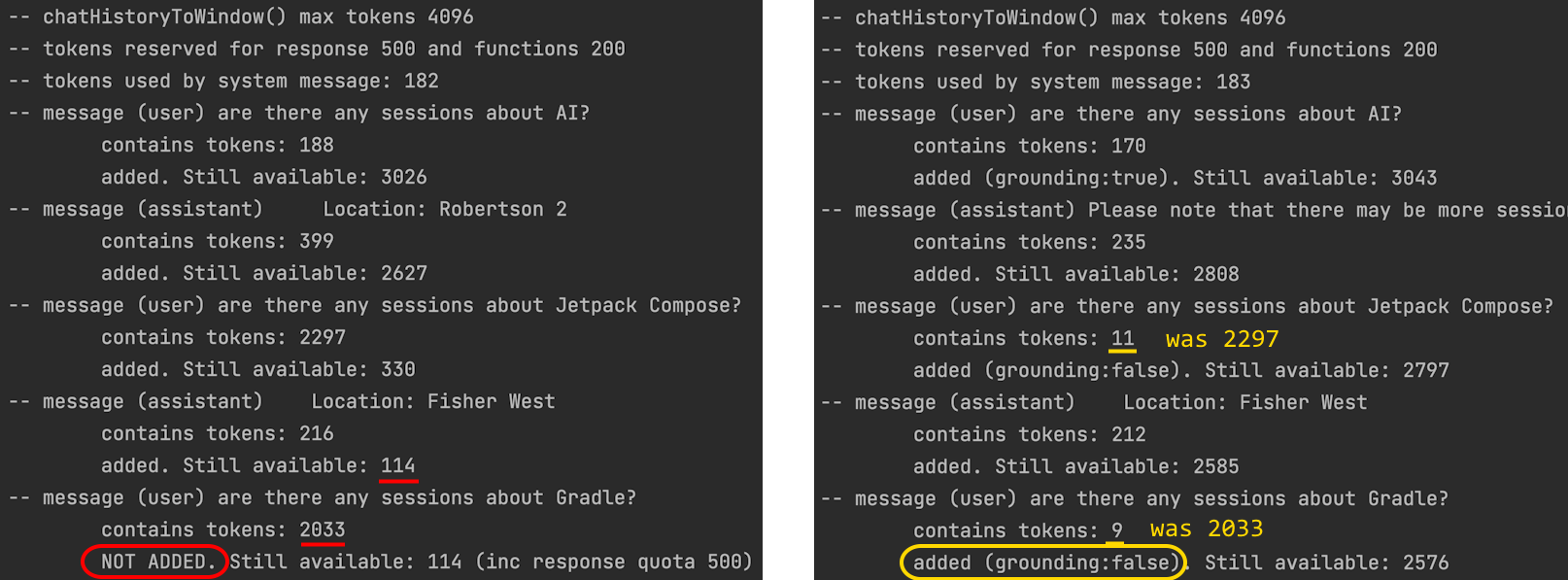
Figure 6: comparing the ‘chat history stack’ in logcat output before (left) and after (right) this code change
Because we’re not re-sending the grounding for each query, the completion request only includes relevant information, and after three messages there is still plenty of room left under the token limit (2576 tokens) for more message history!
And a bug fix…
Testing specifically with a model that has a small token limit highlighted a bug that can occur when the user query matches so many embeddings that it cannot fit under the model’s token limit. For example, the query “what sessions are about Android?” will return embedding matches for most (maybe all) of the sessions, which would be more data than can fit in the model’s token limit.
If we send all the embeddings, the model will respond with an error that the token limit is exceeded. If we do not send any of the embeddings, the model will not be able to answer. The proposed simple fix is to just truncate the embeddings to send as much information as possible within the token limit (this could be done more intelligently, depending on your use case).
The following changes in the pull request were implemented to fix this bug:
-
Tokenizerhelper class has a new methodtrimToTokenLimitwhich truncates excessively long embeddings grounding content when required. -
CustomChatMessagefunctions all have atokensAllowedparameter which is used to customize theChatMessagethat is added to the completion:-
getTokenCount– if the full message with groundings is larger than the token limit, will return a value that fits under the limit (assuming this can be achieved just by trimming the grounding content). -
canFitInTokenLimit– takes into account that the grounding data may be truncated if required to fit within a given limit. -
CustomChatMessage.getChatMessage– has new code that will trim the grounding (embeddings data) to fit within the token limit. This should be a rare occurrence, when the embeddings matches are particularly broad or the matches contain a lot of content.
-
There are two important things to note about this fix:
-
The
Tokenizeras-written only does a rough approximation of truncating the grounding content to a specific token limit. - Because the model is not receiving all the matching embeddings, its response to the user will be limited only to the information that was included. The model itself has no knowledge of the truncated content.
Depending on your application, you could take different approaches like stripping back the individual embeddings when token size is limited (include less detail, such as omit the session descriptions), or show an error in the UI that asks the user to refine their question without even sending to the model.
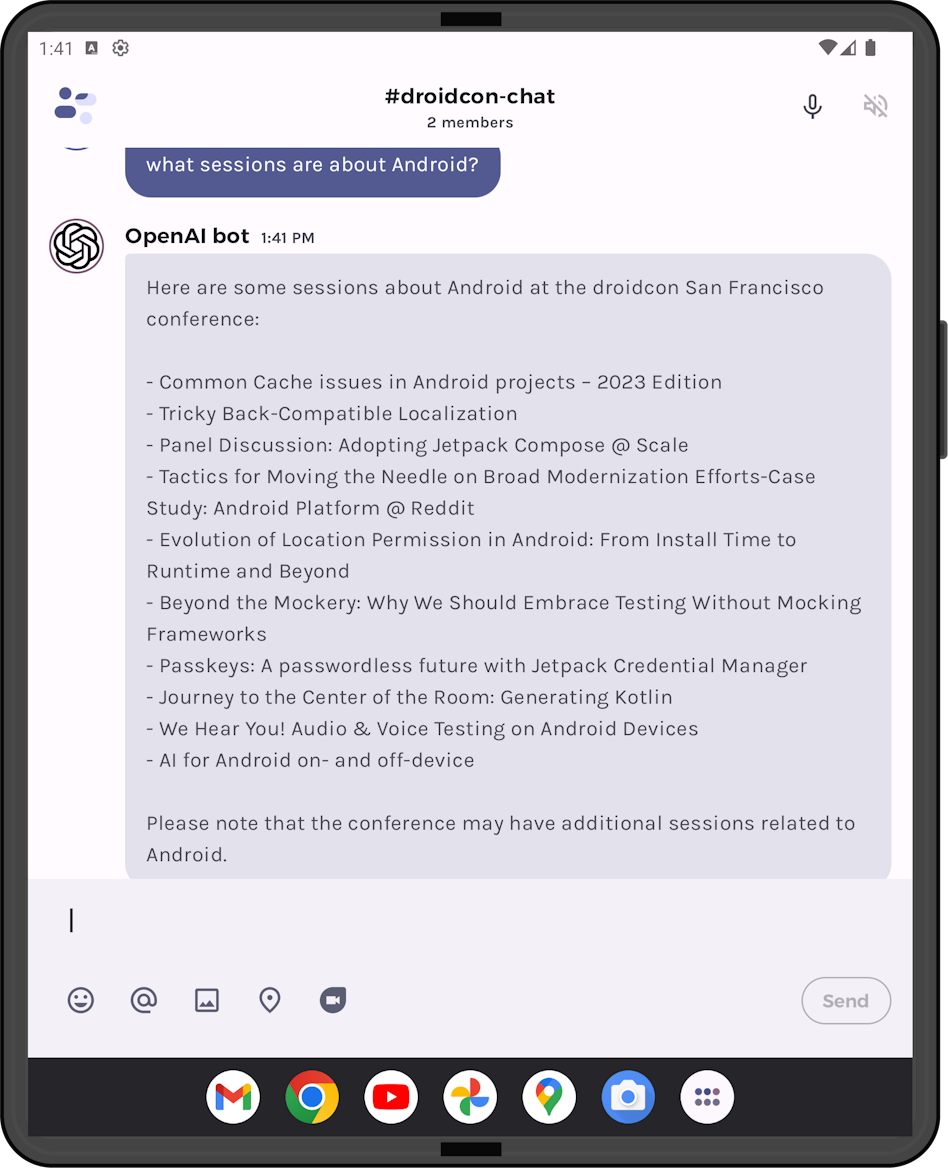
Figure 7: answer to a question where the grounding had to be truncated to fit in the token limit
Resources and feedback
Upcoming posts will continue the discussion about different ways to implement a long-term chat beyond a simple sliding window, like summarization and embeddings. You can download and try out the sample from the droidcon-sf-23 repo by adding your own OpenAI API key.
The OpenAI developer community forum has lots of discussion about API usage and other developer questions.
We’d love your feedback on this post, including any tips or tricks you’ve learning from playing around with ChatGPT prompts.
If you have any thoughts or questions, use the feedback forum or message us on Twitter @surfaceduodev.
There will be no livestream this week, but you can check out the archives on YouTube.
0 comments