

Hello prompt engineers,
The Jetchat demo that we’ve been covering in this blog series uses the OpenAI Chat API, and in each blog post where we add new features, it supports conversations with a reasonable number of replies. However, just like any LLM request API, there are limits to the number of tokens that can be processed, and the APIs are stateless meaning that all context needed for a given request must be included in the prompt.
This means that each chat request and response gets added to the conversation history, and the whole history is sent to the API after each new input so that the context can be used to give the best answer. Eventually the number of tokens in the combined chat history will exceed your model’s limit (eg. ChatGPT 3.5 originally had a 4,096 token limit)… note that the limit for a given API request is the combination of the prompt AND the completion, so if the prompt (including chat history) is 3,000 tokens, the completion cannot be more than around 1000 tokens.
Even if your model has a higher limit, eventually an ongoing conversation is going to run out of tokens.
In the next few weeks we’ll discuss strategies for continuing a chat “conversation” beyond the token limit, starting with a discussion of tokens in this post.
What are tokens?
To understand what “tokens” are, read what are tokens and how to count them in the OpenAI documentation. You can think about tokens as roughly analogous to a single word in English, although that’s more true for simple/common words, and other words might consist of multiple tokens. Tokens may also be punctuation and could include spaces. Tokens can also be non-English characters.
OpenAI model token limits are shown on the model overview. The default for gpt-3.5 was originally 4,096 tokens however newer models are available with up to 32,768 tokens. You’ll also see that pricing is based on token usage, so more tokens costs more money!
Visualizing tokens
The OpenAI tokenizer can help you to visualize how your prompt is broken down into tokens – for the most accurate count you should represent the prompt syntax (including your system prompt) exactly as the API expects (including any JSON formatting).
As an example, here is a chat interaction with the Jetchat demo app where the model’s response is grounded in the system prompt:
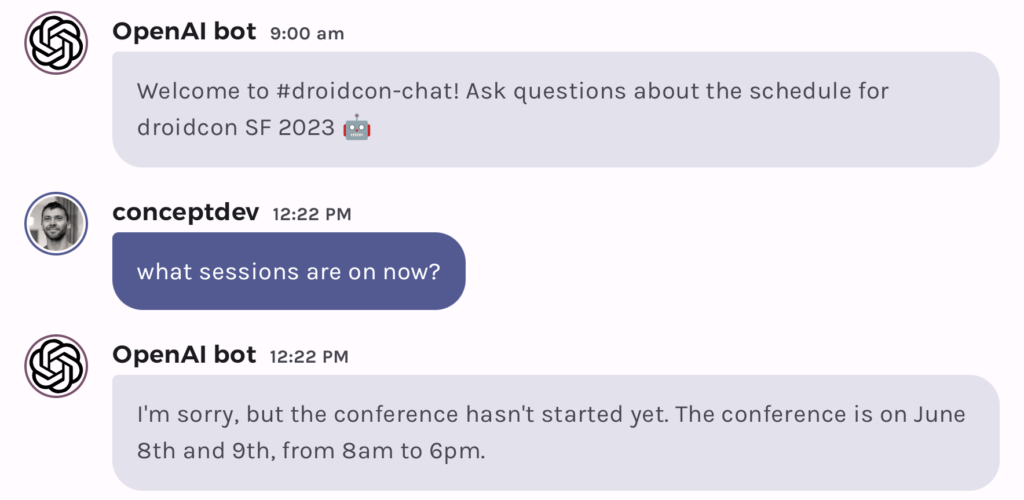
For reference, this is what the underlying chat API structure would be:
{
"messages": [
{"role": "system", "content": "You are a personal assistant called JetchatAI.
You will answer questions about the speakers and sessions at the droidcon SF conference.
The conference is on June 8th and 9th, 2023 on the UCSF campus in Mission Bay. It starts at 8am and finishes by 6pm.
Your answers will be short and concise, since they will be required to fit on a mobile device display.
When showing session information, always include the subject, speaker, location, and time.
ONLY show the description when responding about a single session. Only use the functions you have been provided with."},
{"role": "user", "content": "what sessions are on now?"},
]
}
Visualized on the tokenizer, the chat prompt is only 166 tokens (the bulk of which is the system prompt):

And the model’s completion response is only 30 tokens.

If subsequent user inputs and responses were roughly the same size (around 60 tokens), the chat could contain 65 interactions with the user before the 4,096 token limit was reached and the API would no longer respond. While 65 questions seems like a lot (!), enhancing your chat with embeddings or functions can consume tokens too meaning the chat can “end” much sooner than expected.
Tokens and embeddings
Using embeddings is a great way to include custom data in a model’s response (or even just data more up-to-date than the model’s training).
In the JetchatAI gets smarter with embeddings blog post we showed how to add context to a prompt by matching the embedding for a user’s question against an up-to-date dataset (in the demo, a list of conference sessions). Here’s an example query that uses embeddings to generate the correct result:
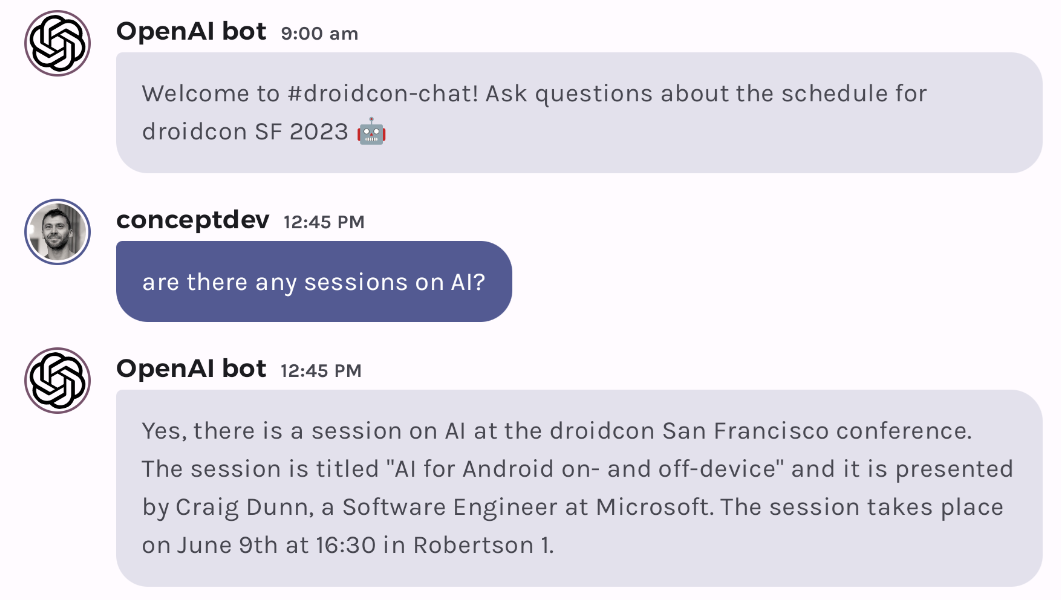
Although the user’s question is only a few words, notice how the API call below contains the details of conference session that was retrieved by comparing the embedding value of the query with all the conference sessions:
{
"messages": [
{"role": "system", "content": "You are a personal assistant called JetchatAI.
You will answer questions about the speakers and sessions at the droidcon SF conference.
The conference is on June 8th and 9th, 2023 on the UCSF campus in Mission Bay.It starts at 8am and finishes by 6pm.
Your answers will be short and concise, since they will be required to fit on a mobile device display.
When showing session information, always include the subject, speaker, location, and time.
ONLY show the description when responding about a single session. Only use the functions you have been provided with."},
{"role": "user", "content": "Following are some talks/sessions scheduled for the droidcon San Francisco conference in June 2023:
Speaker: CRAIG DUNN
Role: Software Engineer at Microsoft
Location: Robertson 1
Date: 2023-06-09
Time: 16:30
Subject: AI for Android on- and off-device
Description: AI and ML bring powerful new features to app developers, for processing text, images, audio, video, and more. In this session we’ll compare and contrast the opportunities available with on-device models using ONNX and the ChatGPT model running in the cloud.
Use the above information to answer the following question. Summarize and provide date/time and location if appropriate.
are there any sessions on AI?"}
]}
The tokenizer visualization is shown below – this single interaction is now 511 tokens for the request and 77 for the response: 588 tokens in total.


While 558 tokens still seems small compared to a 4,096 token limit, tokens could be “used up” a lot more quickly if there are multiple embeddings matching the user’s question. For example, the query “is there a talk about gradle” returns six embeddings matches including the session details and description.
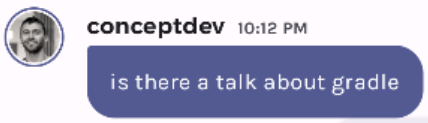
The full API request is omitted for clarity, but it’s much larger than the previous examples, at nearly 2000 tokens it’s almost half the original 4,096 token limit!

While newer OpenAI models can have limits up to 32k tokens, queries that require a lot of embedding context will quickly fill up the token limit after just a few interactions.
Tokens and functions
Declaring functions as part of your OpenAI chat API uses up tokens in a different way, more like the system prompt. The blog post OpenAI chat functions on Android shows how to add functions in Kotlin using a client library to abstract away the JSON syntax, but under the hood it is still adding tokens to your chat API requests.
Here is an example user query that triggers the weather function:
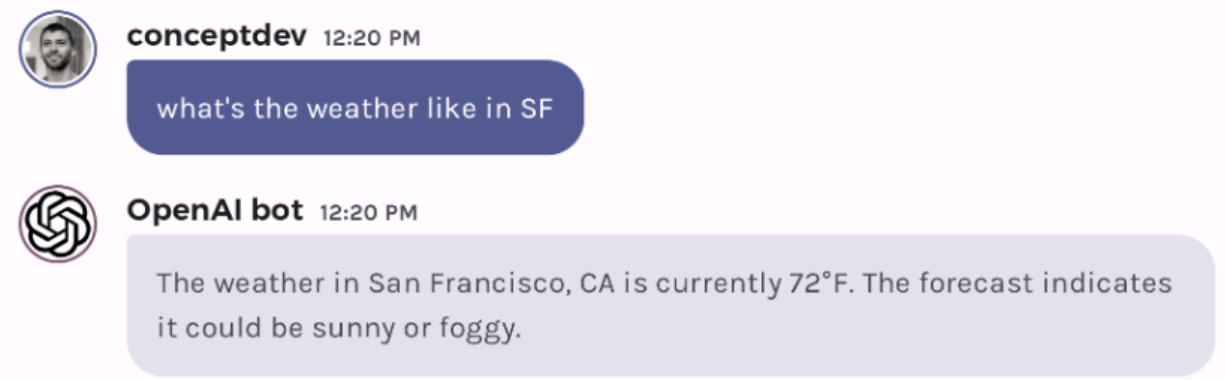
And here is the an example of the kind of API request that’s sent:
{
"messages": [
{"role": "system", "content": "You are a personal assistant called JetchatAI.
Your answers will be short and concise, since they will be required to fit on a mobile device display.
Only use the functions you have been provided with."},
{"role": "user", "content": "what's the weather like in SF"}
],
"functions":[
{
"name": "currentWeather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"latitude": {
"type": "string",
"description": "The latitude of the requested location, e.g. 37.773972 for San Francisco, CA",
},
"longitude": {
"type": "string",
"description": "The longitude of the requested location, e.g. -122.431297 for San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["latitude","longitude"],
}
],
"function_call": "auto"
}
The functions JSON uses 274 tokens of the 360 total tokens in this request:

Functions also use tokens in another way – there are two more interactions with the model – where it “calls” the function and your code responds with the result before the final model completion that’s displayed to the user.
{"role": "assistant", "content": null, "function_call": {"name": "currentWeather", "arguments": "{ \"latitude\": \"37.773972\", \"longitude\": \"-122.431297\"}"}},
{"role": "function", "name": "currentWeather", "content": "{\"temperature\": "73", \"unit\": \"fahrenheit\", \"description\": \"Mostly sunny. High near 73, with temperatures falling to around 68 in the afternoon.\"}"}
For the weather result these messages are short – only 113 tokens – but as with the embeddings example above, if the function returns a large chunk of text as a result, it will eat into your token limit.

Finally, you may declare more than one function, such as in the blog post Combining OpenAI function calls with embeddings. The examples in that blog post use tokens for both function declarations, as well as potential embeddings matches, and the function results can be verbose since they’ll contain wordy session descriptions.
Building an infinite chat…
While simple LLM queries can be supported for a large number of chat interactions, grounding responses with embeddings or functions can quickly use up the token limits for your model. Once the request size exceeds the limit, the chat will not return further responses.
To get around the limit we need strategies to give as much context as possible to the model without just blindly sending the entire chat history each time.
Approaches to solve this include:
- Sliding window (first in first out)
- Summarization
- Embeddings
Over the coming weeks we’ll dive deeper into these approaches.
Resources and feedback
Here are some links to discussions about chat API usage on the OpenAI developer community forum:
- I wish that when using the GPT API, it would be possible to have a contextual conversation like chatGPT
- Multi-turn conversation best practice
- OpenAI API: chat completion pruning methods
Note that in all the JSON above the "model": "gpt-3.5-turbo-0613" model specification argument as been omitted for clarity.
We’d love your feedback on this post, including any tips or tricks you’ve learning from playing around with ChatGPT prompts.
If you have any thoughts or questions, use the feedback forum or message us on Twitter @surfaceduodev.
There will be no livestream this week, but you can check out the archives on YouTube.
For my article: Azure OpenAI RAG Pattern using Functions and a SQL Vector Database I use this method to implement Sliding window (first in first out):
<code>
Thanks for sharing! I hope to have a Kotlin implementation to share as part of our mobile app chat demo in a future post.
Your articles look very useful for C#/Blazor devs interested in OpenAI.