

Hello prompt engineers,
The last few posts have been about the different ways to create an ‘infinite chat’, where the conversation between the user and an LLM model is not limited by the token size limit and as much historical context as possible can be used to answer future queries. We previously covered:
These are techniques to help better manage the message history, but they don’t really provide for “infinite” memory. This week, we will investigate storing the entire chat history with embeddings, which should get us closer to the idea of “infinite chat”.
One of the first features added to the Jetchat droidcon demo was using embeddings to answer questions about conference sessions. In this post, we’ll use the same technique to (hopefully) create a chat which “remembers” the conversation history. Spoiler alert – it’s relatively easy to build the mechanism, but it also exposes the challenges of saving the right data, in the right format, and retrieving it at the right time. You can play around with all of these aspects in your own implementations 😊
For more information on the underlying theory of chat memory using a vector store, see the LangChain docs, which discuss a similar approach.
Background and testing
The JetchatAI sample has multiple chat “channels”:
- #jetchat-ai – Basic open-ended chat with the OpenAI endpoint, including the live US weather function and using the image generation endpoint.
- #droidcon-chat – Directed chat aimed at answering questions about the droidcon SF conference, includes embeddings of the conference sessions and functions to list conference info as well as save and view favorites.
The #droidcon-chat channel already includes the sliding window and history summary discussed in the past few weeks, and it’s already backed by a static embedding data store. In this post, we’re going back to the basics and adding the chat history embeddings to the #jetchat-ai channel.
Figure 1: switching “channels” in JetchatAI
Because the #jetchat-ai channel is just an open discussion, testing will be based on questions and answers about travel, food, and any of the kinds of things that people like asking ChatGPT!
First implement the sliding window
In the pull request for this feature, you will see that before building the embeddings history, we first added the sliding window feature that was previously implemented in the #droidcon-chat. The code changes in OpenAIWrapper.kt, SlidingWindow.kt and SummarizeHistory.kt are mostly to port this already built-and-tested feature. Refer to the earlier blog post for details on how this works.
With the sliding window implemented, the chat will not hit the API token limit and can be conducted over a long period of time.
Note that the demo app doesn’t persist chats beyond the app restarting, so while we’re building the functionality for an “infinite chat”, it can’t be literally infinite just yet! For now, we’re focusing on when the context would otherwise be outside the API token limit.
Embedding the chat history
The mechanism for creating and retrieving embeddings of messages is basically the same approach used for the droidcon conference schedule:
- Call the embedding API with text from each chat message (we’ll combine the user query and the model response into one).
- Store the resulting vector along with the text (preferably in a database, but we’ll start with in-memory).
- Create an embedding vector for each new user query.
- Match the new vector against everything in history, looking for similar context (high embedding similarity).
- Add the text from similar embeddings to the prompt along with the new user query. If there are no matches, no additional context is added to the prompt.
- The model’s response will take the included context into account, and hopefully answer with the expected historical knowledge.
Make history
The code for steps 1 and 2 is shown in Figure 2. Every time an interaction occurs (a user query, and a response from the model), this will be concatenated together and an embedding generated. These will be added to a datastore that will be referenced in subsequent user queries.
The query and response are concatenated together so that the embedding created will have the best chance of matching future user queries that might be related. Choosing what to embed is a huge part of the success (or not) of this approach (and similar approaches like chunking and embedding documents), and the right design choice for your application could be different.
suspend fun storeInHistory (openAI: OpenAI, dbHelper: HistoryDbHelper, user: CustomChatMessage, bot: CustomChatMessage) {
val contentToEmbed = user.userContent + " " + bot.userContent // concatenate query and response
val embeddingRequest = EmbeddingRequest(
model = ModelId(Constants.OPENAI_EMBED_MODEL),
input = listOf(contentToEmbed)
)
val embedding = openAI.embeddings(embeddingRequest)
val vector = embedding.embeddings[0].embedding.toDoubleArray()
historyCache[vector] = contentToEmbed // add to in-memory history cache
}
Figure 2: This function creates an embedding for each user interaction with the model
RAG-time
Steps 3, 4 and 5 are addressed in the code in Figure 3 below. Just like the droidcon conference demo, we’ve created a “retrieval-augmented generation” where the query will include the historical context with close vector similarity, wrapped in prompt text that guides the model to answer:
suspend fun groundInHistory (openAI: OpenAI, dbHelper: HistoryDbHelper, message: String): String {
var messagePreamble = ""
var messageVector: DoubleArray? = null
val embeddingRequest = EmbeddingRequest(
model = ModelId(Constants.OPENAI_EMBED_MODEL),
input = listOf(message)
)
val embedding = openAI.embeddings(embeddingRequest)
val messsageVector = embedding.embeddings[0].embedding.toDoubleArray()
// find the best matches history items
var sortedVectors: SortedMap<Double, String> = sortedMapOf()
for (pastMessagePair in historyCache) {
val v = messageVector!! dot pastMessagePair.key
sortedVectors[v] = pastMessagePair.value
}
if (sortedVectors.size <= 0) return "" // nothing found
if (sortedVectors.lastKey() > 0.8) { // arbitrary match threshold
messagePreamble =
"Following are some older interactions from this chat:\n\n"
for (pastMessagePair in sortedVectors.tailMap(0.8)) {
messagePreamble += pastMessagePair.value + "\n\n"
}
messagePreamble += "\n\nUse the above information to answer the following question:\n\n"
}
return messagePreamble
}
Figure 3: Code that creates an embedding for the user query, finds similar entries in the history, and pulls that content into the prompt as grounding
There are two important implementation choices to call out in this function:
-
The arbitrary match threshold of
0.8determines how much historical context is pulled in. The value of0.8was selected purely on how successful it was in the droidcon demo. Each application will need to adapt the criteria for matching historical context according to your user scenarios. -
The historical context itself is wrapped in a prompt to guide the model. The wording of this prompt should try to ensure the model only refers to the context when needed, and that it doesn’t rely on it too heavily. The basic format is like this:
Following are some older interactions from this chat: <MATCHING EMBEDDINGS> Use the above information to answer the following question: <USER QUERY GOES HERE>
Once the grounding prompt has been created, we just need to pass it back to the model along with the new user query:
val relevantHistory = EmbeddingHistory.groundInHistory(openAI, dbHelper, message)
val userMessage = CustomChatMessage(
role = ChatRole.User,
grounding = relevantHistory,
userContent = message
)
conversation.add(userMessage)
Figure 4: The history returned from the embeddings is added as grounding context before the user query is sent to the model
The model will respond using the retrieved historical context to generate the correct answer, which itself will be added to the history datastore for future reference!
Example retrieval
The screenshots below show a conversation where facts discussed early in the conversation are correctly recalled after the sliding window limit has been exceeded. In this case, I commented that I liked the Eiffel Tower, and this context was used to answer the query “what’s my favorite paris landmark”:
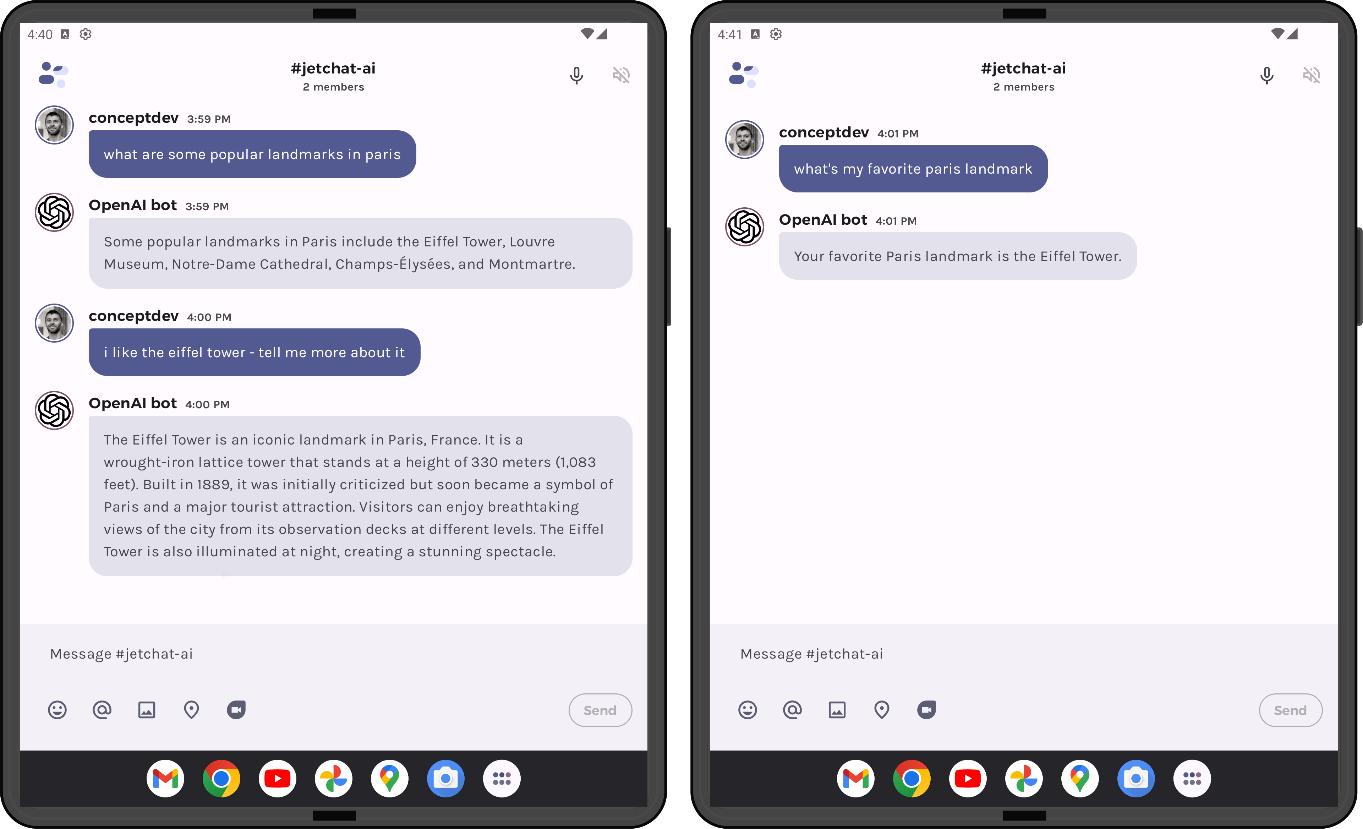
Figure 5: chat history where the initial interactions are ‘remembered’ even after they’ve slipped out of the sliding window
If you try these queries and watch the logcat, you’d see that both the query+response pairs on the left screen are vector similarity matches for the query “what’s my favorite paris landmark” (0.844 and 0.855 respectively) even though the first query won’t help answer the question. The prompt looked like this:
Following are some older interactions from this chat: i like the eiffel tower - tell me more about it The Eiffel Tower is an iconic landmark in Paris, France. It is a wrought-iron lattice tower that stands at a height of 330 meters (1,083 feet). Built in 1889, it was initially criticized but soon became a symbol of Paris and a major tourist attraction. Visitors can enjoy breathtaking views of the city from its observation decks at different levels. The Eiffel Tower is also illuminated at night, creating a stunning spectacle. what are some popular landmarks in paris Some popular landmarks in Paris include the Eiffel Tower, Louvre Museum, Notre-Dame Cathedral, Champs-Élysées, and Montmartre. Use the above information to answer the following question: What’s my favorite paris landmark
Compare this result with a different question about “what’s my favorite sydney landmark”. Sydney has not been mentioned in this chat before, however the previous query “what’s my favorite paris landmark” still has a strong vector similarity and that is included in the prompt:
Following are some older interactions from this chat: What’s my favorite paris landmark Your favorite Paris landmark is the Eiffel Tower. Use the above information to answer the following question What’s my favorite sydney landmark
The model figures it out – ignoring the irrelevant context we retrieved – and answers with a figurative shrug:
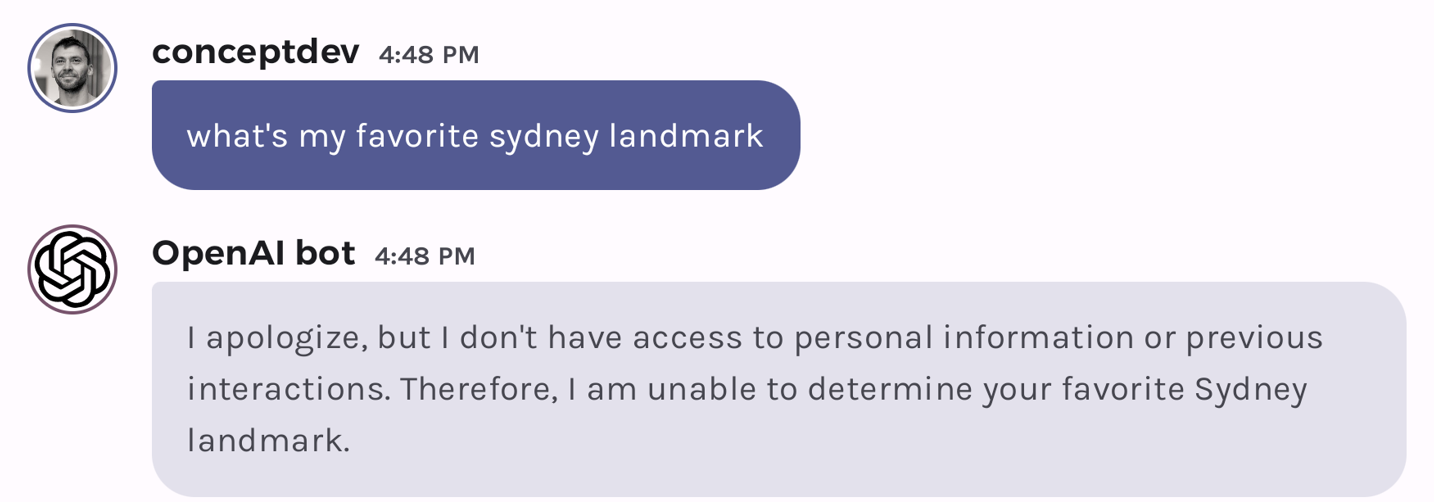
Figure 6: When grounding doesn’t answer the question
Easier said than done
As I hinted at the start of this blog, writing the mechanism is easy, but tuning it for best results can be a challenge. There are at least three important design choices made in just the few lines of code shared above:
- Format and content of the embeddings text
- Threshold for matching historical embeddings with the current user query
- Prompt text used to introduce the context as grounding
You’ll notice I’ve also conveniently neglected to discuss the other context that is still in the sliding window. In a more sophisticated embodiment, we’d probably keep track of which messages are still “in the window” and omit those from the vector comparison… or would we?!
This channel also includes the live weather function. The implementation above would add those interactions to the history along with everything else, but it might make sense to exclude function results, since it makes more sense to get the live data each time?
And then there’s the question of what to do as the history datastore grows larger and larger. We will need to de-duplicate and/or summarize context that we use for grounding, possibly keeping track of dates and times so we can make inferences about stale data. Some of these problems might even be solved with additional LLM queries – but with the added cost and latency before providing an answer.
Resources and feedback
The OpenAI developer community forum has lots of discussion about API usage and other developer questions, and the LangChain docs have lots of interesting examples and discussion of LLM theory.
We’d love your feedback on this post, including any tips or tricks you’ve learned from playing around with ChatGPT prompts.
If you have any thoughts or questions, use the feedback forum or message us on Twitter @surfaceduodev.
There will be no livestream this week, but you can check out the archives on YouTube.
0 comments