
Hello prompt engineers,
In last week’s discussion on improving embedding efficiency, we mentioned the concept of “chunking”. Chunking is the process of breaking up a longer document (ie. too big to fit under a model’s token limit) into smaller pieces of text, which will be used to generate embeddings for vector similarity comparisons with user queries (just like the droidcon conference session data).
Inspired by this Azure Search OpenAI demo, and also the fact that ChatGPT itself released a PDF-ingestion feature this week, we’ve added a “document chat” feature to the JetchatAI Android sample app. To access the document chat demo, open JetchatAI and use the navigation panel to change to the #document-chat conversation:
Figure 1: access the #document-chat
To build the #document-chat we re-used a lot of code and added some PDF document content from an Azure chat sample.
Code foundations
In the pull-request for this feature, you’ll see a number of new files that were cloned from existing code to create the #document-chat channel:
-
DocumentChatWrapper– sets the system prompt to guide the model to only answer “Contoso employee” questions -
DocumentDatabase– functions to store the text chunks and embeddings in Sqlite so they are persisted across app restarts -
AskDocumentFunction– SQL generating function that can attempt searches on the text chunks in the database. Ideally, we would provide a semantic full-text search backend, but in this example only basic SQL text matching is supported.
The bulk of this code is identical to the droidcon conference chat demo, except instead of a hardcoded database of session details, we needed to write new code to parse and store the content from PDF documents. This new code exists mainly in the loadVectorCache and initVectorCache functions (as well as a new column in the embeddings Sqlite database to hold the corresponding content).
Reading the source documents
To create the data store, we used the test data associated with the Azure Search demo on GitHub: six documents that describe the fictitious Contoso company’s employee handbook and benefits. These are provided as PDFs, but to keep our demo simple I manually copied the text into .txt files which are added to the JetchatAI raw resources folder. This means we don’t have to worry about PDF file format parsing, but can still play around with different ways of chunking the content.
The code to load these documents from the resources folder is shown in Figure 2:
var documentId = -1
val rawResources = listOf(R.raw.benefit_options) // R.raw.employee_handbook, R.raw.perks_plus, R.raw.role_library, R.raw.northwind_standard_benefits_details, R.raw.northwind_health_plus_benefits_details
for (resId in rawResources) {
documentId++
val inputStream = context.resources.openRawResource(resId)
val documentText = inputStream.bufferedReader().use { it.readText() }
Figure 2: loading the source document contents
Once we’ve loaded the contents of each document, we need to break it up before creating embeddings that can be used to match against user queries (and ultimately answer their questions with retrieval augmented generation).
Chunking the documents
This explanation of chunking strategies outlines some of the considerations and methods for breaking up text to use for RAG-style LLM interactions. For our initial implementation we are going to take a very simplistic approach, which is to create an embedding for each sentence:
val documentSentences = documentText.split(Regex("[.!?]\\s*"))
var sentenceId = -1
for (sentence in documentSentences){
if (sentence.isNotEmpty()){
sentenceId++
val embeddingRequest = EmbeddingRequest(
model = ModelId(Constants.OPENAI_EMBED_MODEL),
input = listOf(sentence)
)
val embedding = openAI.embeddings(embeddingRequest)
val vector = embedding.embeddings[0].embedding.toDoubleArray()
// add to in-memory cache
vectorCache["$documentId-$sentenceId"] = vector
documentCache["$documentId-$sentenceId"] = sentence
Figure 3: uses regex to break into sentences and creates/stores an embedding vector for each sentence
Although this is the simplest chunking method, there are some drawbacks:
- Headings and short sentences probably don’t have enough information to make useful prompt grounding.
- Longer sentences might still lack context that would help the model answer questions accurately.
Even so, short embeddings like this can be functional, as shown in the next section.
NOTE: The app needs to parse and generate embeddings for ALL the documents before it can answer any user queries. Generating the embeddings can take a few minutes because of the large number of embedding API requests required. Be prepared to wait the first time you use the demo if parsing all six source files. Alternatively, changing the
rawResourcesarray to only load a single document (likeR.raw.benefit_options) will start faster and still be able to answer basic questions (as shown in the examples below). The app saves the embeddings to Sqlite so subsequent executions will be faster (unless the Sqlite schema is changed or the app is deleted and re-installed).
Document answers from embeddings and SQL search
With just this relatively minor change to our existing chat code (and adding the embedded files), we can ask fictitious employee questions (similar to those shown in the Azure Search OpenAI demo):
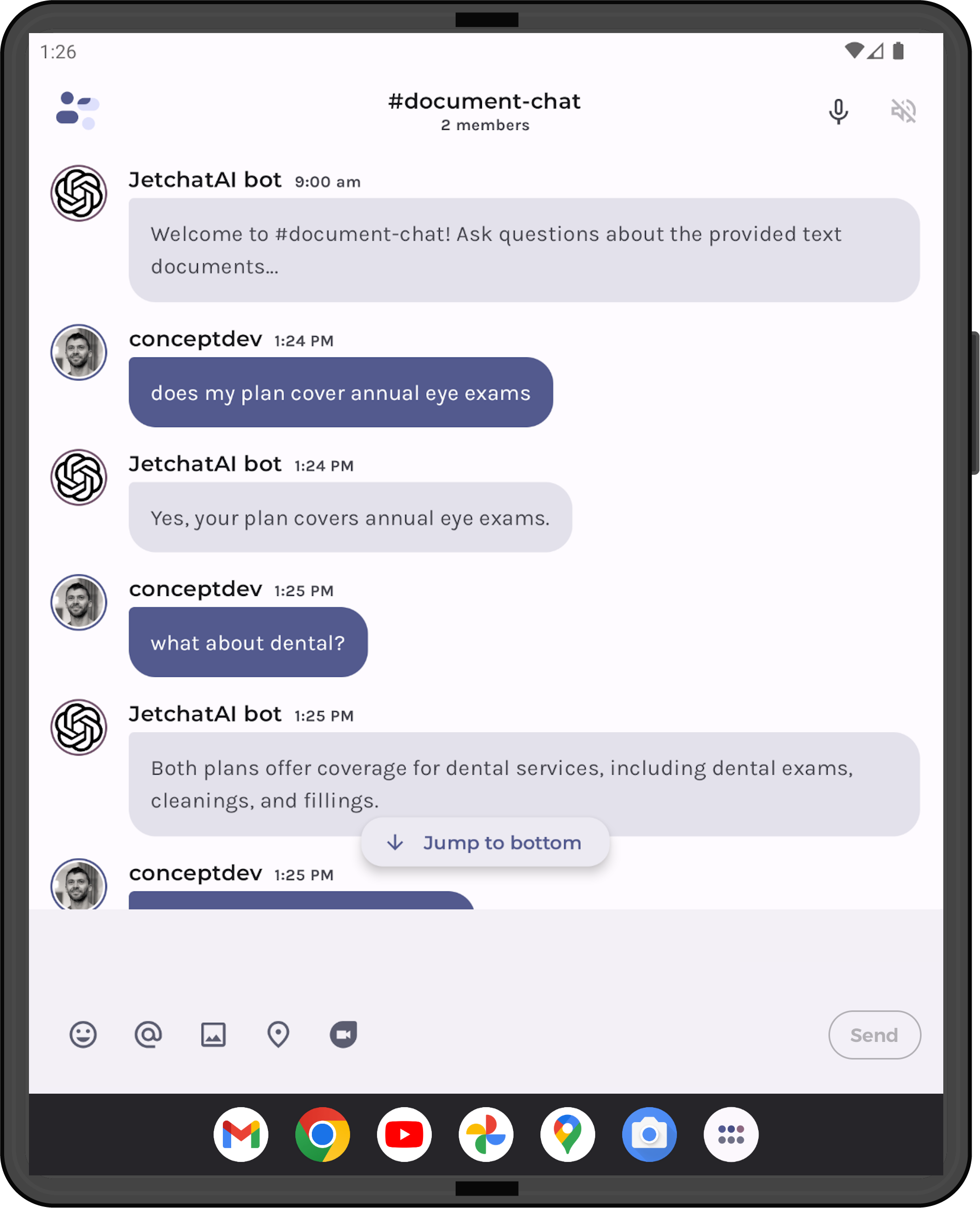
Figure 4: Ask questions about documents in JetchatAI
These two example queries are discussed below, showing the text chunks that are used for grounding.
“does my plan cover annual eye exams”
The first test user query returns ten chunks where the vector similarity score was above the arbitrary 0.8 threshold. Figure 5 shows a selection of the matches (some removed for space), but you can also see that the grounding prompt has the introduction The following information is extract from Contoso employee handbooks and help plans: and instruction Use the above information to answer the following question: to guide the model when this is included in the prompt:
The following information is extract from Contoso employee handbooks and health plans: Comparison of Plans Both plans offer coverage for routine physicals, well-child visits, immunizations, and other preventive care services This plan also offers coverage for preventive care services, as well as prescription drug coverage Northwind Health Plus offers coverage for vision exams, glasses, and contact lenses, as well as dental exams, cleanings, and fillings Northwind Standard only offers coverage for vision exams and glasses Both plans offer coverage for vision and dental services, as well as medical services Use the above information to answer the following question:
Figure 5: the grounding information for the user query “does my plan have annual eye exams”
Because we have also registered the AskDocumentFunction an SQL query (Figure 6) is also generated for the query, however the exact phrase “annual eye exam” does not have any matches and no additional grounding is provided by the function call.
SELECT DISTINCT content FROM embedding WHERE content LIKE '%annual eye exams%'
Figure 6: text search is too specific and returns zero results
The grounding in Figure 5 is enough for the model to answer the question with “Yes your plan covers annual eye exams”.
Note that the user query mentioned “my plan”, and the model’s response asserts that “your plan covers…”, probably because in the grounding data the statements include “Both plans offer coverage…”. We have not provided any grounding on what plan the user is signed up for, but that could be another improvement (perhaps in the system prompt) that would help answer more accurately.
“what about dental”
The second test query only returns three chunks with a vector similarity score above 0.8 (shown in Figure 7)
The following information is extract from Contoso employee handbooks and health plans: Northwind Health Plus offers coverage for vision exams, glasses, and contact lenses, as well as dental exams, cleanings, and fillings Both plans offer coverage for vision and dental services, as well as medical services Both plans offer coverage for vision and dental services Use the above information to answer the following question:
Figure 7: the grounding information for the user query “what about dental”
The model once again triggers the dynamic SQL function to perform a text search for “%dental%”, which returns the four matches shown in Figure 8.
SELECT DISTINCT content FROM embedding WHERE content LIKE '%dental%'
-------
[('Northwind Health Plus
Northwind Health Plus is a comprehensive plan that provides comprehensive coverage for medical, vision, and dental services')
,('Northwind Standard Northwind Standard is a basic plan that provides coverage for medical, vision, and dental services')
,('Both plans offer coverage for vision and dental services')
,('Northwind Health Plus offers coverage for vision exams, glasses, and contact lenses, as well as dental exams, cleanings, and fillings')
,('Both plans offer coverage for vision and dental services, as well as medical services')]
Figure 8: SQL function results for the user query “what about dental?”
The chunks returned from the SQL query mostly overlap with the embeddings matches. The model uses this information to generate the response “Both plans offer coverage for dental services, including dental exams, cleanings, and fillings.”
If you look closely at the grounding data, there’s only evidence that the “Health Plus” plan covers fillings (there is no explicit mention that the “Standard” plan offers anything beyond “dental services”). This means that the answer given could be giving misleading information about fillings being covered by both plans – it may be a reasonable assumption given the grounding, or it could fall into the ‘hallucination’ category. If the chunks were larger then the model might have more context to understand which features are associated with which plan.
This example uses the simplest possible chunking strategy, and while some questions can be answered it’s likely that a more sophisticated chunking strategy will support more accurate responses. In addition, including more information about the user could result in more personalized responses.
Resources and feedback
Some additional samples that demonstrate building document chat services with more sophisticated search support:
- Revolutionize your Enterprise Data with ChatGPT: Next-gen Apps w/ Azure OpenAI and Cognitive Search is the blog post that introduces the Azure demo mentioned above.
- Teach ChatGPT to Answer Questions: Using Azure Cognitive Search & Azure OpenAI Services to work with large files and large numbers of files as input for a ChatGPT question-answering service.
- Build a chatbot to query your documentation using Langchain and Azure OpenAI for an example using LangChain.
We’d love your feedback on this post, including any tips or tricks you’ve learned from playing around with ChatGPT prompts.
If you have any thoughts or questions, use the feedback forum or message us on Twitter @surfaceduodev.
0 comments