
Hello prompt engineers,
I’ve been reading about how to improve the process of reasoning over long documents by optimizing the chunking process (how to break up the text into pieces) and then summarizing before creating embeddings to achieve better responses. In this blog post we’ll try to apply that philosophy to the Jetchat demo’s conference chat, hopefully achieving better chat responses and maybe saving a few cents as well.
Basic RAG embedding
When we first wrote about building a Retrieval Augmented Generation (RAG) chat feature, we created a ‘chunk’ of information for each conference session. This text contains all the information we have about the session, and it was used to:
- Create an embedding vector that we compare against user queries, AND
- Add to the chat prompt as grounding context when there is a high vector similarity between the embeddings for the chunk and the user query.
Figure 1 shows an example of how the text was formatted (with key:value pairs) and the types of information provided:
Speaker: Craig Dunn Role: Software Engineer at Microsoft Location: Robertson 1 Date: 2023-06-09 Time: 16:30 Subject: AI for Android on- and off-device Description: AI and ML bring powerful new features to app developers, for processing text, images, audio, video, and more. In this session we’ll compare and contrast the opportunities available with on-device models using ONNX and the ChatGPT model running in the cloud.
Figure 1: an example of the session description data format used in the original Jetchat sample app
Using all the information fields for embeddings and grounding worked fine for our use case, and we’ve continued to build additional features like sliding window and history caching based on this similarity matching logic. However, that doesn’t mean it couldn’t be further improved!
More efficient embeddings
When you consider how the embedding vector is used – to compare against the user query to match on general topics and subject similarity – it seems like we could simplify the information we use to create the embedding, such as removing the speaker name, date, time, and location keys and values. This information is not well suited to matching embeddings anyway (chat functions and dynamic SQL querying work much better for questions about those attributes), so we can reduce the text chunk used for generating embeddings to the speaker role, subject, and description as shown in Figure 2:
Speaker role: Software Engineer at Microsoft Subject: AI for Android on- and off-device Description: AI and ML bring powerful new features to app developers, for processing text, images, audio, video, and more. In this session we’ll compare and contrast the opportunities available with on-device models using ONNX and the ChatGPT model running in the cloud.
Figure 2: a more focused text chunk for embedding. The role was included since for this dataset and expected query usage it often contains relevant context.
There is an immediate improvement in cost efficiency, as the new text chunk is only 73 tokens, versus 104 tokens for the complete text in Figure 1 (which would be a 25% saving in the cost of calculating all the embeddings; although note that some have longer descriptions than others so the amount of cost savings will vary). While embedding API calls are much cheaper (at $0.0004 per 1000 tokens) than the chat API ($0.002 to $0.06 per 1000 tokens), it’s still a cost that can add up over time so it makes sense to reduce the amount of tokens used to create embeddings if possible.
Note that the shorter text chunk is ONLY used for creating the embedding vector. When the vector similarity with the user query is high enough, the ORIGINAL text with all the fields is what is added to the chat prompt grounding. This ensures that the chat model can still respond with speaker, date, time, and location information in the chat.
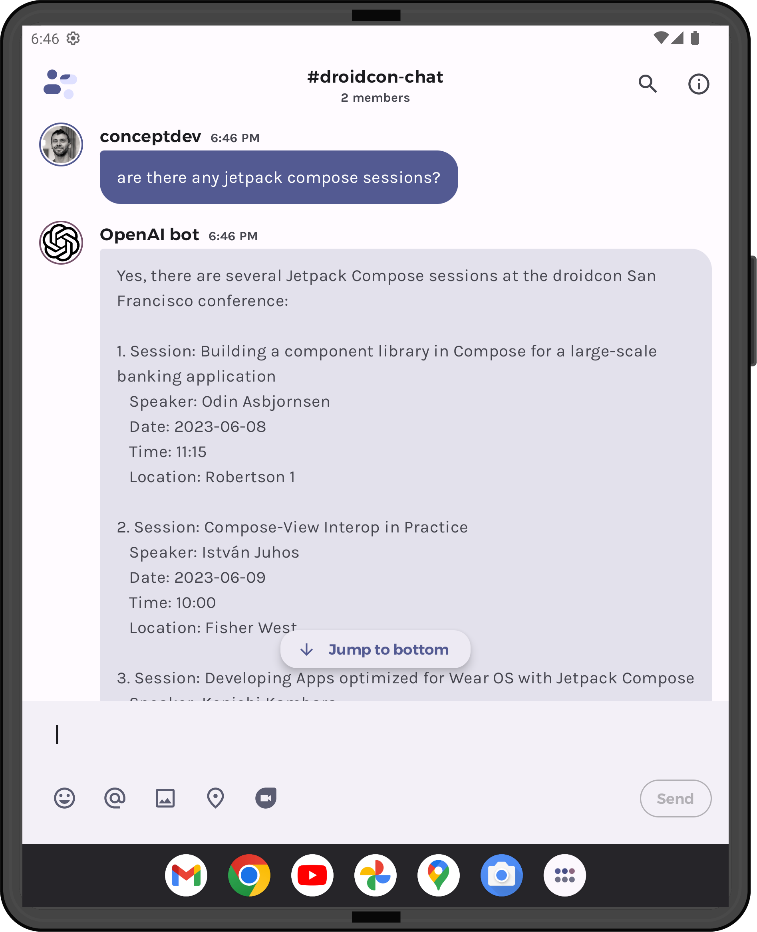
Figure 3: Screenshot showing the generated response still includes speaker, date, time, and location information
Better results?
Testing with some common user queries from other blog posts in this series, the vector similarity scores are very close when comparing the query embedding vector against the larger text chunk (old score) and the smaller text chunk (new score). About a quarter of the sample were slightly lower scoring (highlighted in red), but the rest resulted in higher similarity scores.
|
User query |
Matching session |
Old similarity score |
New similarity score |
|
Are there any sessions on AI |
AI for Android on- and off-device |
0.807 |
0.810 |
|
Are there any sessions on gradle |
Improving Developer Experience with Gradle Build Scans (Rooz Mohazzabi) |
0.802 |
0.801 |
|
Improving Developer Experience with Gradle Build Scans |
0.810 |
0.806 |
|
|
Improving Developer Experience with Gradle Build Scans (Iury Souza) |
0.816 |
0.823 |
|
|
Crash Course in building your First Gradle Plugin |
0.821 |
0.827 |
|
|
Are there any sessions on Jetpack Compose |
Material You Review |
0.802 |
0.801 |
|
Building a component library in Compose for a large-scale banking application |
0.814 |
0.824 |
|
|
Developing Apps optimized for Wear OS with Jetpack Compose |
0.815 |
0.814 |
|
|
Animating content changes with Jetpack Compose |
0.819 |
0.827 |
|
|
Practical Compose Navigation with a Red Siren |
0.823 |
0.825 |
|
|
Compose-View Interop in Practice |
0.824 |
0.838 |
|
|
Panel Discussion: Adopting Jetpack Compose @ Scale (Christina Lee) |
0.829 |
0.842 |
|
|
Panel Discussion: Adopting Jetpack Compose @ Scale (Alejandro Sanchez) |
0.831 |
0.849 |
|
|
Creative Coding with Compose: The Next Chapter |
0.832 |
0.840 |
|
|
Panel Discussion: Adopting Jetpack Compose @ Scale (Vinay Gaba) |
0.834 |
0.850 |
Figure 4: comparing vector similarity scores with the full text chunk embedding versus (old) the shorter version (new). Scores truncated to three decimal places for clarity.
The results seem to show the arbitrary cut-off of “0.8” for measuring whether a session was a good match seemed to still apply, and the actual results displayed to the user was unchanged.
Since (for these test cases at least) the chat responses in the app are identical, this improvement hasn’t affected the user experience positively or negatively (but it has reduced our embeddings API costs). Further testing on other conference queries might reveal different effects, and certainly for other use cases (such as reasoning over long documents using embedding chunks), “summarizing” the text used for embedding to better capture context that will match expected user queries could lead to better chat completions.
Code
I’ve left the code changes to the end of the post, since very few lines of code were changed! You can see in the pull request that the key updates were:
-
Two new methods on the
SessionInfoclass, the first one to emit the shorter text chunk for embedding, and the larger one to emit the full text for grounding:fun forEmbedding () : String { return "Speaker role: $role\nSubject: $subject\nDescription:$description" } fun toRagString () : String { return """ Speaker: $speaker Role: $role Location: $location Date: $date Time: $time Subject: $subject Description: $description""".trimIndent() } -
The
DroidconEmbeddingsWrapper.initVectorCacheuses theDroidconSessionObjectscollection and theforEmbeddingfunction to create embeddings vectors with the summarized session info:for (session in DroidconSessionObjects.droidconSessions) { val embeddingRequest = EmbeddingRequest( model = ModelId(Constants.OPENAI_EMBED_MODEL), input = listOf(session.value.forEmbedding()) ) -
The
DroidconEmbeddingsWrapper.grounding()function usestoRagString()to use the full text in the chat prompt:messagePreamble += DroidconSessionObjects.droidconSessions[dpKey.value]?.toRagString()
These changes are very specific to our conference session data source. When the source data is less structured, you might consider generating an LLM completion to summarize each text chuck before generating the embedding.
Resources and feedback
We’d love your feedback on this post, including any tips or tricks you’ve learned from playing around with ChatGPT prompts.
If you have any thoughts or questions, use the feedback forum or message us on Twitter @surfaceduodev.
There will be no livestream this week, but you can check out the archives on YouTube.
0 comments