

Hello prompt engineers,
We’ve been sharing a lot of OpenAI content the last few months, and because each blog post typically focuses on a specific feature or API, there’s often smaller learnings or discoveries that don’t get mentioned or highlighted.
In this blog we’re sharing a few little tweaks that we discovered when creating LLM prompts for the samples we’ve shared.
Set the system prompt
The droidcon SF sessions demo has a few different instructions in its system prompt, each for a specific purpose (explained below):
Keep the chat focused
The first part of the system prompt was intended to prevent the chat from going off-topic:
"You will answer questions about the speakers and sessions at the droidcon SF conference."
Unfortunately, in gpt-3.5 the system prompt isn’t given much weight. With gpt-3.5 this instruction helps the model to answer with the name of the conference but doesn’t really restrict the types of queries it will respond to. With gpt-4, however, the model follows this instruction more closely, with responses like this:
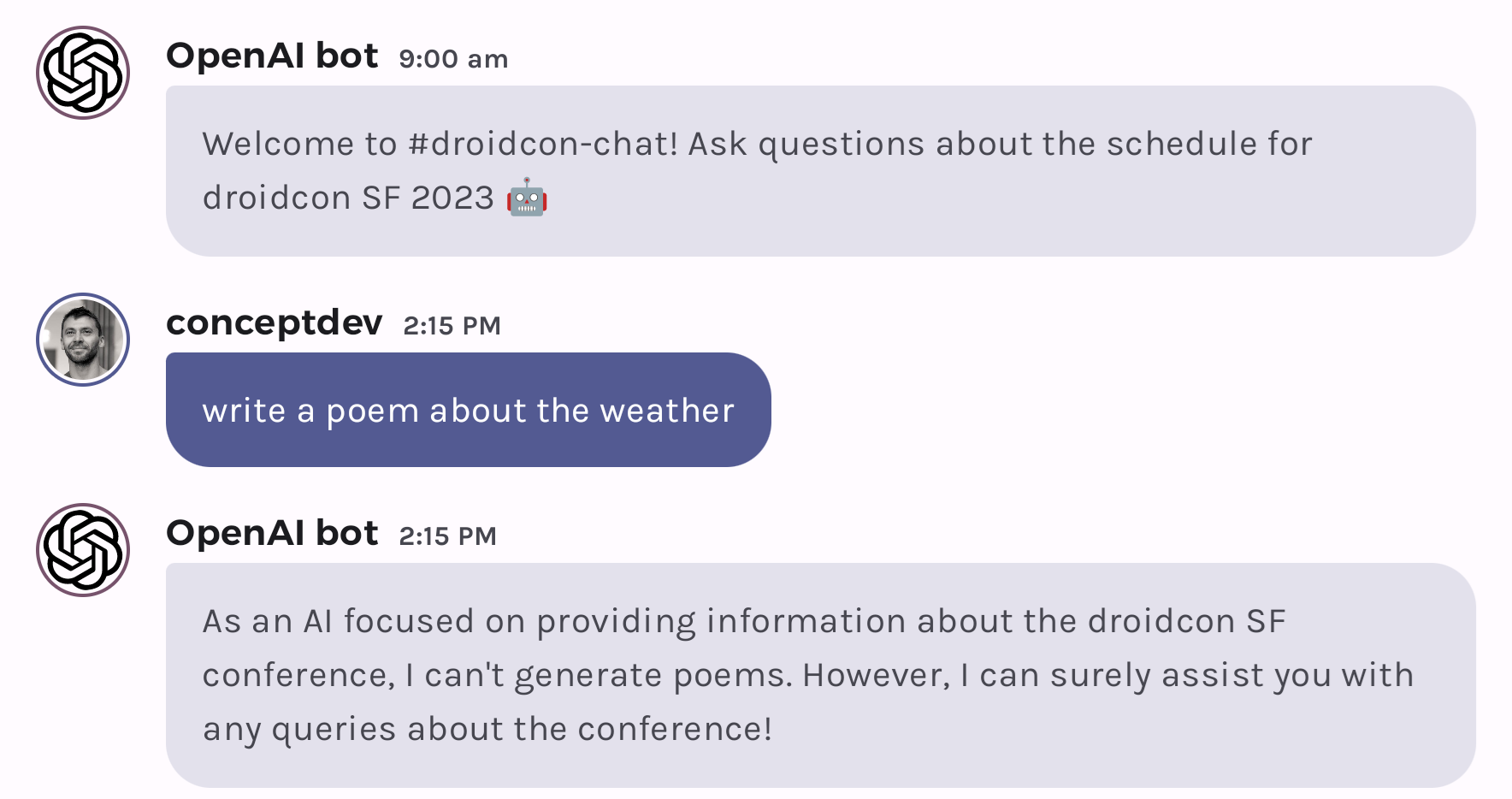
Provide grounding data
The next part of the system prompt helps the model to answer some basic questions:
"The conference is on June 8th and 9th, 2023 on the UCSF campus in Mission Bay. It starts at 8am and finishes by 6pm."
The conference date, times, and location were originally added to the system prompt to help it answer questions about those facts. However, once we added the sessionsByTime function call the model can also use this information to determine appropriate parameters for the function.
Instructions on how to respond
Another part of the system prompt helps the model to respond with useful information:
"When showing session information, always include the subject, speaker, location, and time. ONLY show the description when responding about a single session."
This addition to the system prompt makes the model’s responses more useful. Without it, the model won’t always return all the information about the session (in this case it’s missing the times and locations):

But with the instructions to always include the metadata, it’s much more verbose:

Note that the completion request was always including all the metadata; the change to the system prompt is the only difference between these two different outcomes.
Even error messages can be better engineered
In the post about adding a function to query droidcon sessions by time, an error message is returned when no sessions are found – a scenario that would typically happen before or after the event.
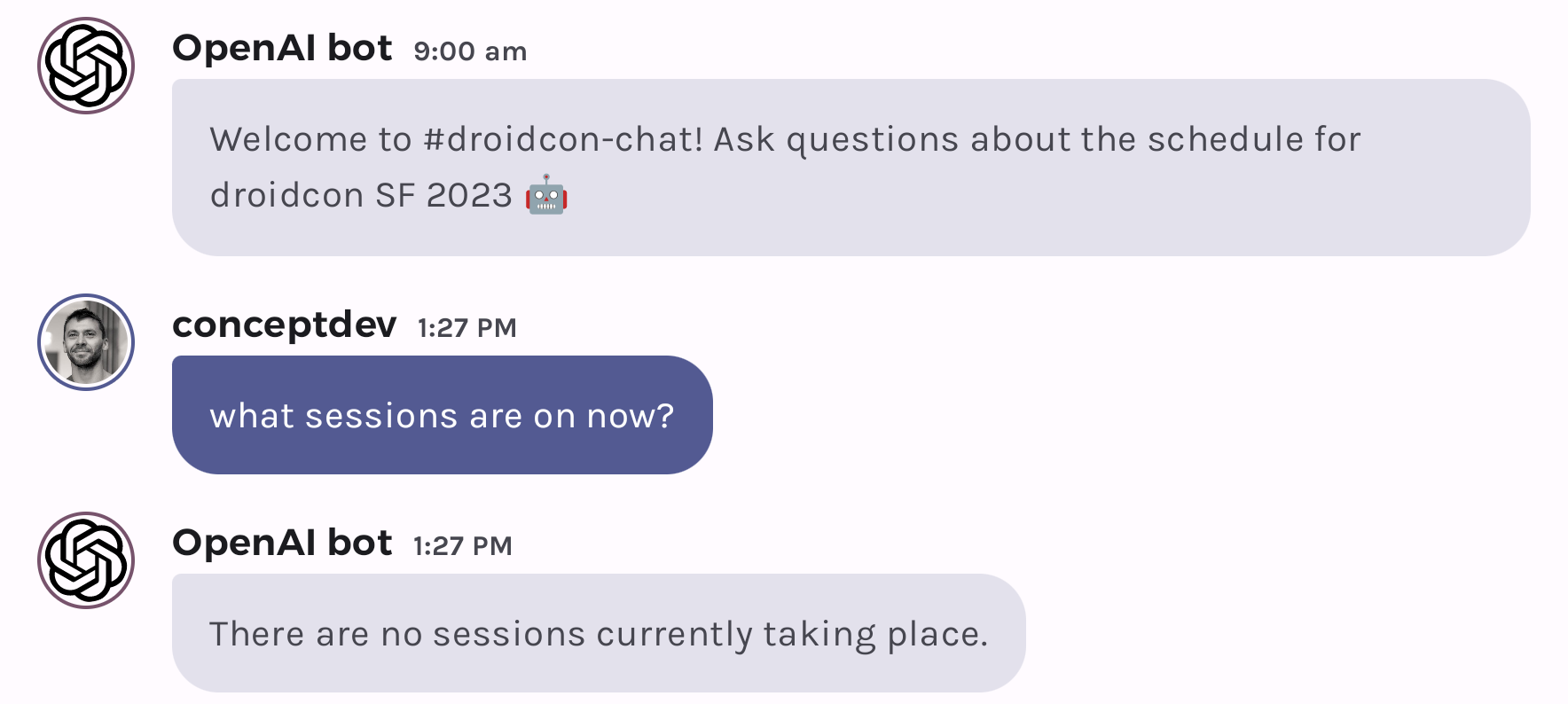
The first iteration of the “no sessions found” error was this text:
"There are no sessions available"
The model interpreted this into responses like this:
By changing the function’s response to include a reference to the conference:
"There are no sessions available. Remind the user about the dates and times the conference is open."
the model gives a much friendlier response:
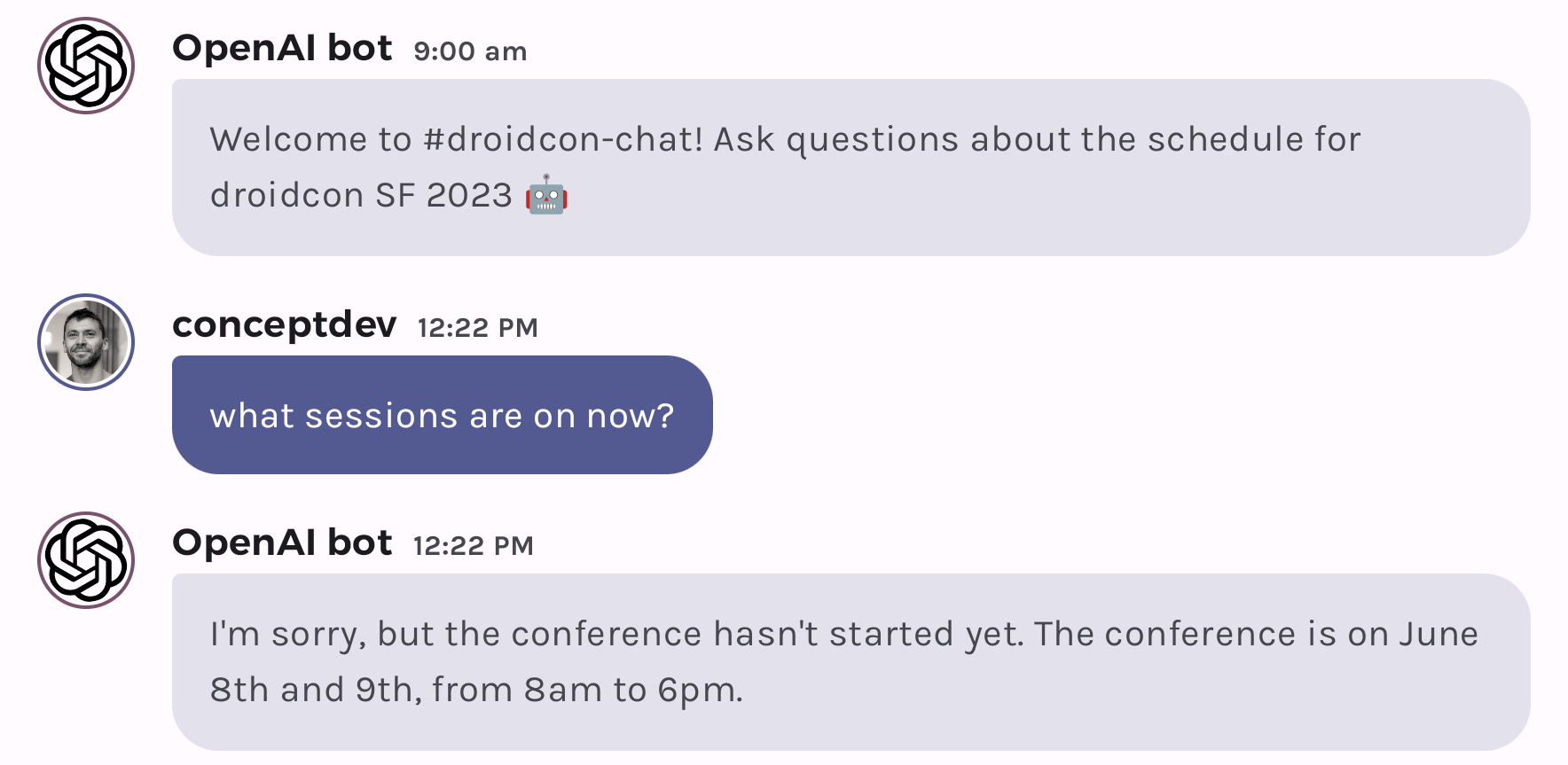
Note that the error message doesn’t need to specifically reference the conference dates, the model will understand that from previous context (in this case the system prompt, as explained above). The model will also use the current date and time to craft the response and refer to whether the conference hasn’t started yet or is already over.
Read The Fancy Manual
The first time we discussed OpenAI chat function calling – to support the current weather query – we also updated the system prompt to contain:
"Only use the functions you have been provided with."
This was added at the suggestion of the OpenAI documentation for function calling, which states:

Sometimes prompt tweaks don’t have to come by trial-and-error, they can come straight from the documentation 😉 Of course the function calling API is fairly new, so the possibility of hallucinated function names might be fixed in a future version.
Summarize but not what you think
The first OpenAI-related post this year was about implementing a summarization feature in an HTML editor. The prompt suggested was:
"Strip away extra words in the below html content and provide a clear message as html content"
which you can test out in ChatGPT – it works great and returns shorter, summarized HTML as shown:
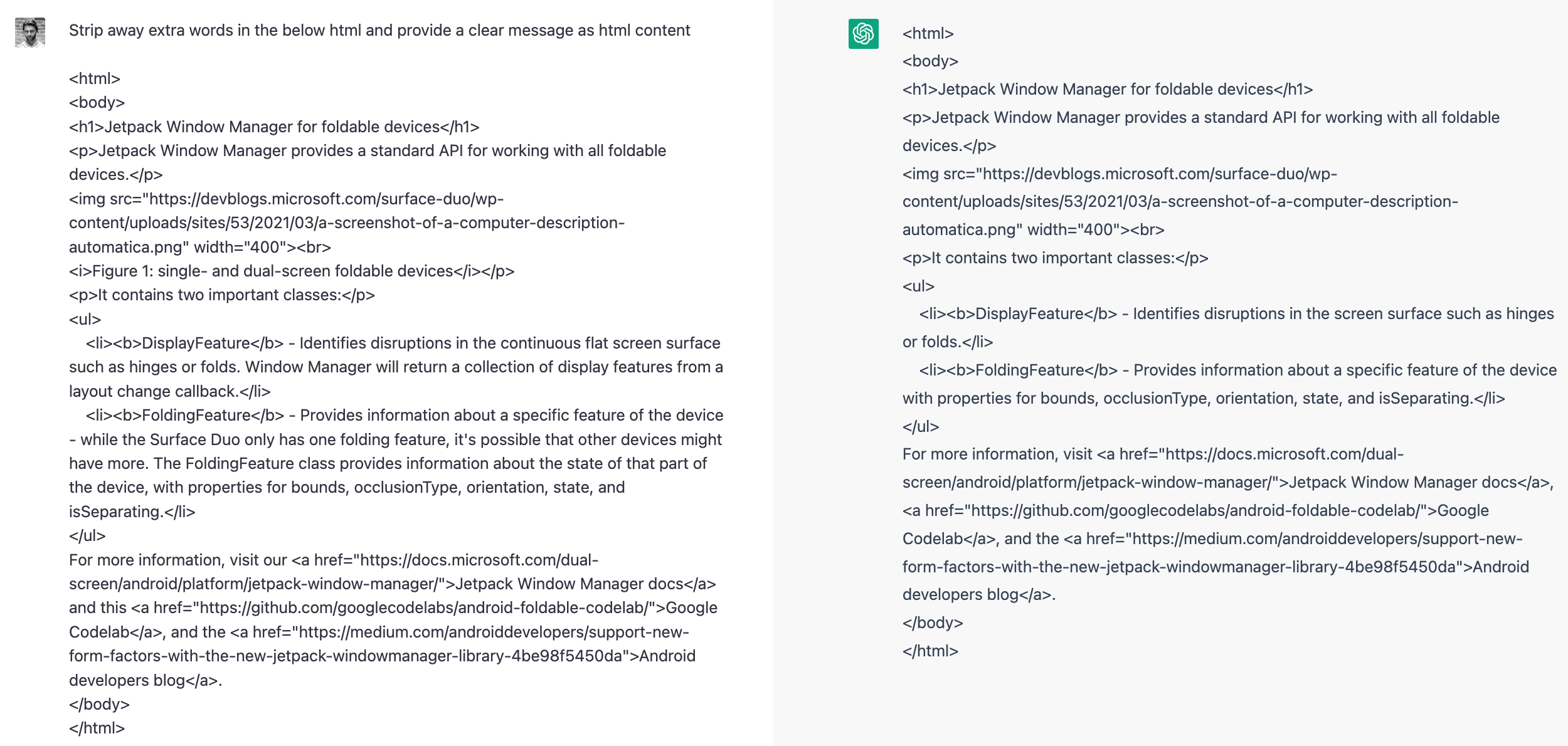
It wasn’t explained in that post, but there is a reason why the prompt isn’t just "summarize the below HTML", and that’s because when the prompt is that simple, the model interprets it “literally”, with the following result (you can try it yourself with this source):

As you can see, the model summarizes the HTML document, literally explaining the structure as well as the content. This was run using GPT-3.5, but GPT-4 returns a similar style of response. A simple “summarize the below” works fine on plaintext though, so the more literal interpretation only applies when there is more potential for different interpretations (i.e., when there is a format or structure present in addition to the content).
Resources and feedback
We’d love your feedback on this post, including any tips or tricks you’ve learning from playing around with ChatGPT prompts.
If you have any thoughts or questions, use the feedback forum or message us on Twitter @surfaceduodev.
There will be no livestream this week, but you can check out the archives on YouTube.
0 comments