
Hello prompt engineers,
Over the course of this blog series, we have investigated different ways of augmenting the information available to an LLM when answering user queries, such as:
- Embeddings generated against static data
- Function calls that use an external web service (eg. to get a weather report)
- Function calls against a local database, both to retrieve data and to store context
- Embeddings from conversation history to remember earlier interactions
However, there is still a challenge getting the model to answer with up-to-date “general information” (for example, if the question relates to events that have occurred after the model’s training). You can see a “real life” example of this when you use Bing Chat versus ChatGPT to search for a new TV show called “Poker Face” which first appeared in 2023:
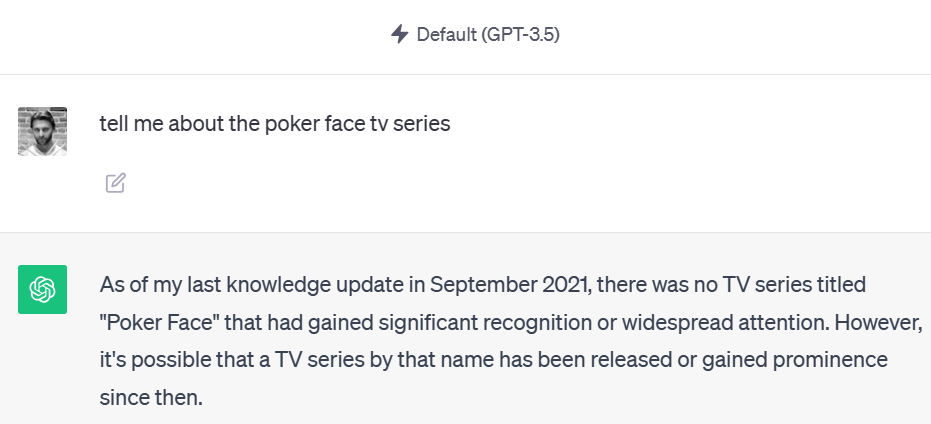
Figure 1: ChatGPT 3.5 training ended in September 2021. It does not know about the latest shows.
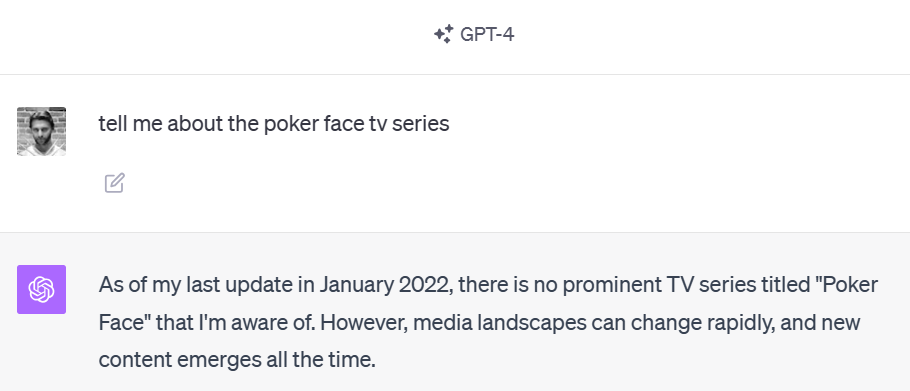
Figure 2: ChatGPT 4 training ended in January 2022. It doesn’t know about the TV show we are asking about either.
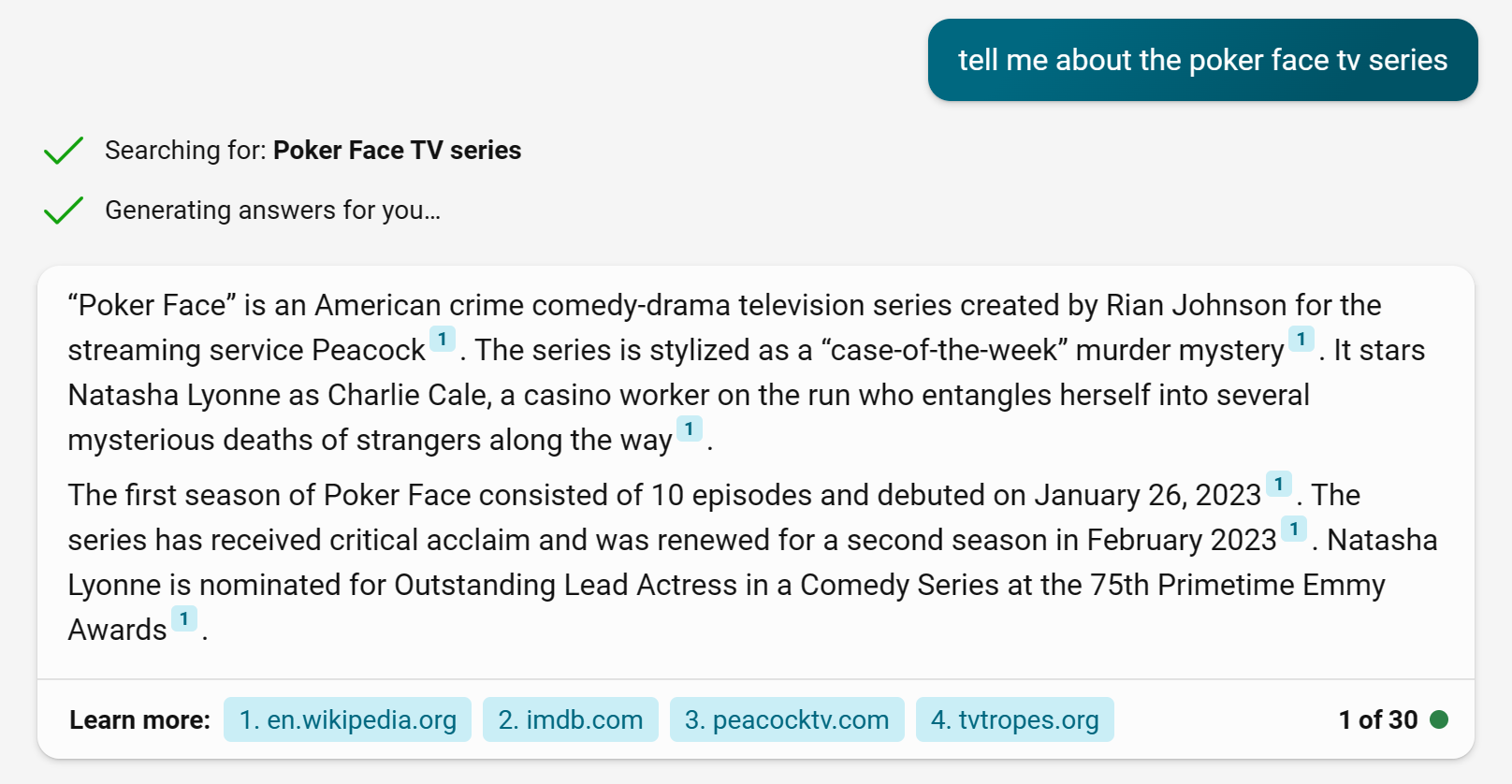
Figure 3: Bing Chat extracts the intent of the question, performs an internet search, and summarizes the results with up-to-date knowledge
You can see from the Bing Chat screenshot in Figure 3 that it takes an intermediate step before answering the question, which is to extract the intent of my question and perform an internet search. The Bing Chat answer specifically references Wikipedia.org as its primary source (as shown by the footnote indicator on the results) that helped it to answer this question.
To illustrate how to build an internet search that will let JetchatAI answer questions about recent topics, we’ll create a new function (similar to the weather function) that searches Wikipedia and uses the results to augment our OpenAI chat requests.
NOTE: this post is not intended to be a production-quality implementation of a Bing Chat-like feature. Rather, it walks through the principles whereby the chat function API can extract meaning from the user’s query and execute a search on their behalf, and then summarize the results and thereby answer questions on topics that did not exist in the training data.
Figure 4 shows how JetchatAI would answer this query before adding the ability to search more current data. The app is configured with the gpt-3.5-turbo-16k model, which returns details of an old TV show…

Figure 4: Without up-to-date context, the app answers with details which I suspect are a hallucination
I’m reasonably sure the model is hallucinating the answer because the ChatGPT website did not respond with an answer, and every time I restart JetchatAI, it produces a different answer. This is probably due to configuration differences (e.g., temperature) between the model being used in JetchatAI and the ChatGPT website examples in Figures 1 and 2.
HttpClient as a chat function
In order to access more accurate, up-to-date information, we’ll need to implement a way for the app to query an internet search index. For this demo, we’ll just use Wikipedia’s MediaWiki API – it’s not as comprehensive as an internet search engine like Bing, but it will provide enough data to build a working prototype.
The existing currentWeather function performs two HTTP requests (to locate the user and then to retrieve the weather for that location). The pull-request for this blogpost shows that we can copy-paste that exact code to perform a ‘search’ on Wikipedia and then retrieve the content for the first matching result:
val wikiSearchUrl = "https://en.wikipedia.org/w/api.php?action=opensearch&search=$query&limit=1&namespace=0&format=json"
val wikiSearchResponse = httpClient.get(wikiSearchUrl) {contentType(ContentType.Application.Json)}
if (wikiSearchResponse.status == HttpStatusCode.OK) {
// CODE OMITTED to parse the Wikipedia search response
wikipediaTitle = responseJsonElement[1].jsonArray[0].jsonPrimitive.content
}
val wikiTitleUrl = "https://en.wikipedia.org/w/api.php?action=query&prop=extracts&exsentences=10&exlimit=1&titles=$wikipediaTitle&explaintext=1&format=json"
val wikiTitleResponse = httpClient.get(wikiTitleUrl) {contentType(ContentType.Application.Json)}
if (wikiTitleResponse.status == HttpStatusCode.OK) {
// CODE OMITTED to parse the Wikipedia content response
wikipediaText = itemPageElement?.get("extract")?.jsonPrimitive?.content
}
Figure 5: HTTP requests to Wikipedia to implement the ‘search’
With these two HTTP requests we can now create a chat function askWikipedia, which will attempt to use the Wikipedia search engine to identify a top result, and then visit that entry and use the page summary as context for our chat request. The query is hardcoded to only return a single result – in a production application, we might choose to return a number of top results (possibly using embeddings to evaluate how likely they are to be useful)…
Prompt engineering challenges
There are four different spots in the function declaration that act like a “prompt” that affects how the model interacts with the function. I tested two different styles of “prompt”, one that was very broad and another that was designed to limit answers to TV/Movie topics only. These values are all set in the AskWikipedia.kt file.
|
Chat Function attributes |
Broad implementation |
Subject-specific implementation |
|
Function name |
|
|
|
Function description |
|
|
|
Parameter name |
|
|
|
Parameter description |
|
Tested both |
Notes on testing these two different implementations:
-
The function name can have a huge impact on when the model chooses to call it. When it’s set to
askWikipedia, the function is called for lots of different types of query, including single word queries like “platypus”. When testing with the function nameaskMediaQuestion, it was much less likely to be called for questions about geography or animals, for example. I suspect that the model actually understands what “Wikipedia” is and this causes it to favor calling this function when “Wikipedia” is part of the function name. -
The function description can further guide the model to use the function only for certain types of queries. When the name is
askWikipedia, changing the description doesn’t seem to have much effect, but when the name is more generic, the function description has more impact on guiding the model on what sorts of queries it is intended to handle. - The parameter name can provide a hint to the model as to what sorts of data should be sent. Whether the parameter is required or not can also have an impact.
-
The parameter description can have a material impact on the function working. For example, using the phrase “Extract the subject from the sentence or phrase” can ensure that the model attempts to interpret the user intent rather than just sending the entire query string.
Also, when testing asaskMediaQuery, if the parameter description was “Search query”, then the model would send “Poker Face TV series” as the parameter; but if the description was “Movie or TV show name” then it would only send “Poker Face” (omitting the “TV series” qualifying string). This seemingly minor change resulted in different search results from Wikipedia which did not return the correct results!
Tweaking each of these values can cause the model responses to change dramatically. It may take some trial-and-error to set the function attributes correctly for your use-case. Ultimately, I chose the broader implementation, as it succeeded more frequently than when I was trying to create restrictions on the types of data that could be acted on.
The final “prompt” challenge for this feature was ensuring that the model attributes its answers to Wikipedia. When the function retrieves data from Wikipedia, the following text is added to the return string: If this information is used in the response, add [sourced from Wikipedia] to the end of the response. Figure 6 shows how this looks in the app.
How it works
Here’s a step-by-step walkthrough of how the query is processed:
Step 1: Model determines that a function call is needed
User query: “tell me about the poker face tv series”
Function parameter: Poker Face TV series
The model extracts the intent of the query and removes unnecessary words (“tell me about”) and uses the result as the function parameter.
Step 2: Function call visits Wikipedia
The first HTTPS request calls the Wikipedia search API and returns JSON that includes a valid page “Poker Face (TV Series)”.
The second HTTPS request calls the Wikipedia query API and returns JSON that includes a summary of the content on that page.
The Wikipedia page summary is then returned to the model as context for the query “tell me about the poker face tv series”
Step 3: Wikipedia content sent back to model for answer
The final response from the model returns a lightly summarized version of the Wikipedia content, and the model has effectively answered a question from data that did not exist when it was trained! The function appends the note “[sourced from Wikipedia]” as instructed in our prompt.
And it works!
The screenshot below shows the output of the query to Wikipedia:
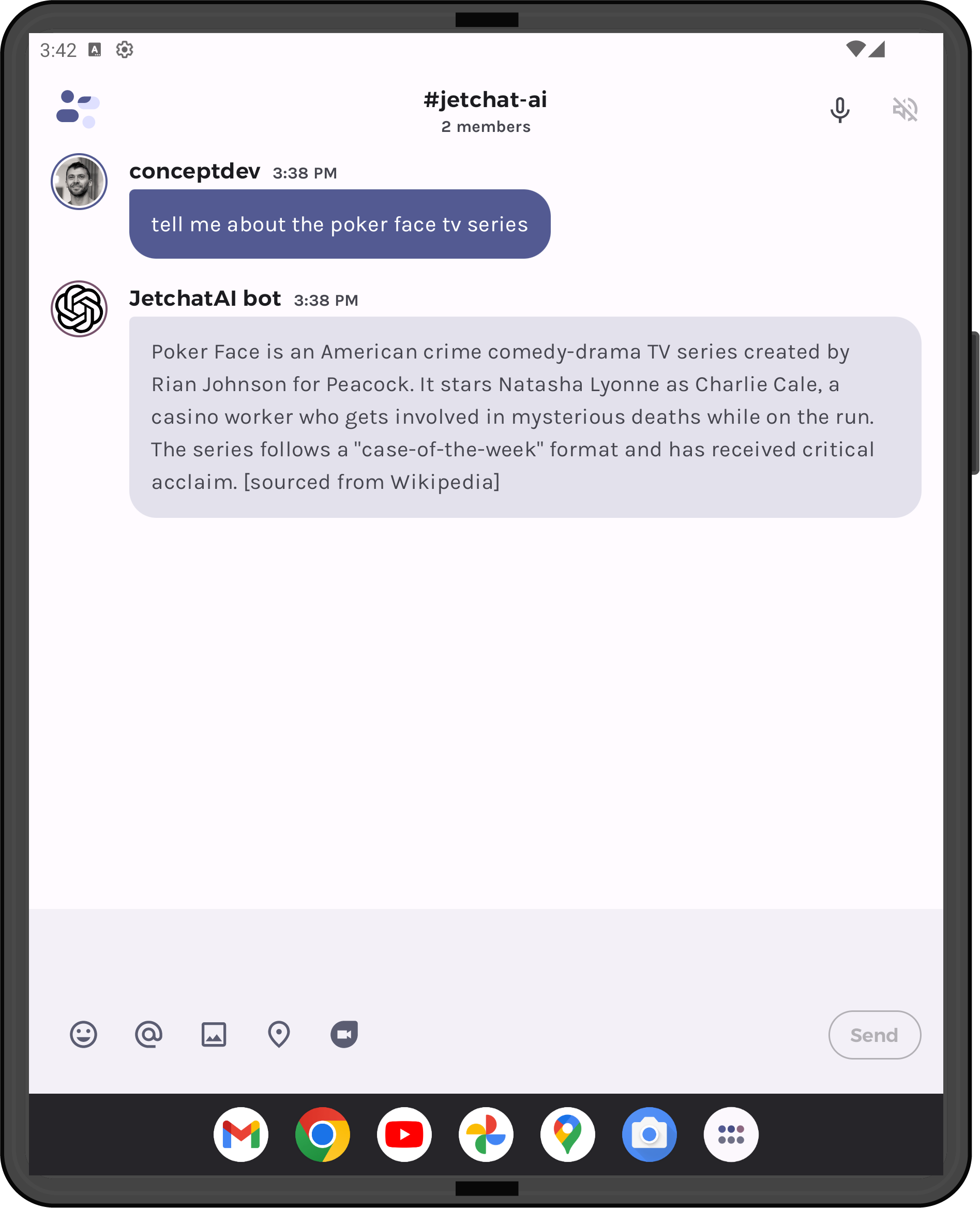
Figure 6: JetchatAI will now extract search terms from the user query, and use Wikipedia’s results to answer with up-to-date information
Side effects of a broadly applicable chat function
The downside of a function that can be applied to most or almost all user queries is that the model falls into a pattern of calling it for every user query, even queries that the model could adequately answer from its training. The model may or may not use the function when answering queries like:
- What is a platypus?
- What’s the top tourist attraction in Paris?
- Where is the city of Cairns?
In my testing, I found that for some of these (e.g., the platypus), Wikipedia returns content, and the model summarizes that in preference to its training data. In others, like the question about Paris attractions, Wikipedia’s search does not find a result and the model answers from its training data. For the question about Cairns, the model answers immediately and does not call the askWikipedia function.
It’s interesting to note that the model can switch modes: the answer to “what is a platypus?” is retrieved and summarized from the Wikipedia response, but a follow-up question “tell me more detail about the platypus” might result in the model returning a much longer response from its training data (containing details that were not in the Wikipedia content).
Prompt jailbreaking
The user-query can also be structured to bypass the function, simply by saying “without using any functions”, e.g.:
- Tell me about monotremes without using any functions
- Tell me about the poker face tv series without using any functions
In both these cases, the askWikipedia function is not called and the model answers from its training data – which still results in the correct answer for factual queries (eg. “definition of a monotreme”), but returns a hallucinated reference for the tv show question. When the user’s input affects how the model responds in this way, it could be considered a kind of ‘jailbreak’ that you would want to avoid with more specific prompts in the system prompt and the function attributes.
Hilariously, the infinite chat embeddings history remembers the incorrect answer, and subsequent queries for “Tell me about the poker face tv series” always repeat the hallucinated response that was first generated. However, we can specifically ask it to refer to Wikipedia, and it will call the function and tell us the right answer (click on Figure 7 to see the full discussion):
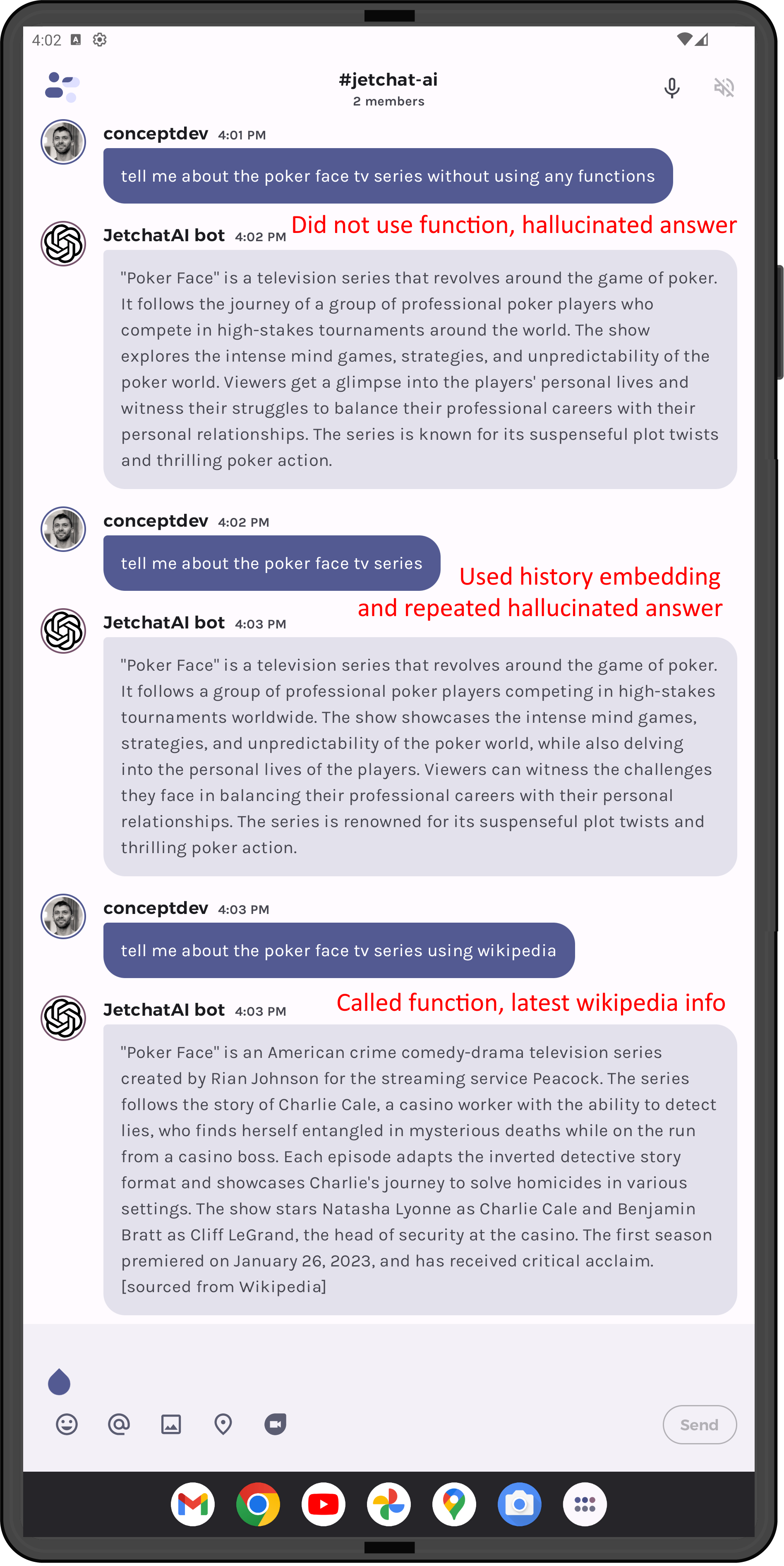
Figure 7: Arguing with a model confused by jailbreaking to get the right answer
Notice that the hallucinated answer in Figure 7 describes a different “Poker Face” than the hallucinated answer in Figure 4, because this was after a fresh restart of the application (embeddings history was blank).
Ultimately, a lot of testing is required to observe how the model behaves in response to the various types of questions you expect from your users.
NOTE: the fact that the chat embeddings history remembers and recalls hallucinated facts exposes a weakness in the design. One idea to address this could be to add another layer of processing to the history data store, so that if a new fact (especially from a function call) is learned for a given user-query, the earlier saved response is deleted. More embeddings comparisons would be required to decide what user-queries were equivalent, along with more code to manage the history database and decide which responses to save and which to delete.
Feedback and resources
We’d love your feedback on this post, including any tips or tricks you’ve learned from playing around with ChatGPT prompts.
If you have any thoughts or questions, use the feedback forum or message us on Twitter @surfaceduodev.
There will be no livestream this week, but you can check out the archives on YouTube.
Text from Wikipedia is shared under the Creative Commons Attribution-ShareAlike license 4.0. The text may be summarized and adapted from the source. Refer to the API etiquette page for advice on how to be a responsible client of Wikipedia APIs.
0 comments