

Hello AI enthusiasts,
This week, we’ll be talking about how you can use Azure Cognitive Services to enhance the types of inputs your Android AI scenarios can support.
What makes an LLM multimodal?
Popular LLMs like ChatGPT are trained on vast amounts of text from the internet. They accept text as input and provide text as output.
Extending that logic a bit further, multimodal models like GPT4 are trained on various datasets containing different types of data, like text and images. As a result, the model can accept multiple data types as input.
In a paper titled Language Is Not All You Need: Aligning Perception with Language Models, researchers listed the datasets that they used to train their multimodal LLM, KOSMOS-1, and shared some outputs where the model can recognize images and answer questions about them (Figure 1).

Figure 1 – KOSMOS-1 multimodal LLM responding to image and text prompts (Huang et al., Language is not all you need: Aligning perception with language models 2023)
By that logic, if we can figure out a way to pass image data to ChatGPT (Figure 2 & Figure 3), does that mean we’ve made ChatGPT multimodal? Well, not really. But it’s better than nothing.
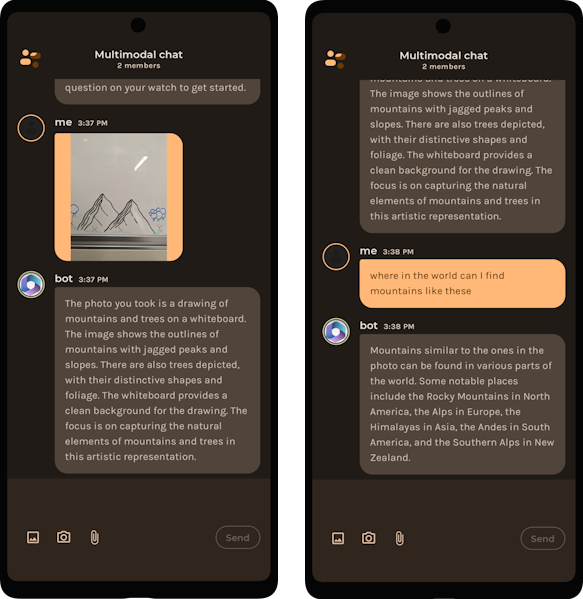
Figure 2 & 3 – Chatbot running ChatGPT responding to image and text inputs.
In this blog we’ll try to achieve the multimodal nature of KOSMOS-1 in the text-based model GPT 3.5.
How does this apply to Android?
Mobile users interact with their devices in a variety of ways. It’s a language of taps, swipes, pictures, recordings, and quick messages. The language of mobile is complex, and the LLMs that support them should embrace as much of that as they can.
Analyzing complex data types
Since the LLM that we want to experiment with (GPT 3.5) has no concept of audio, video, images, or other complex data types, we need to process the data in some way to convert it into a text format before adding it to a prompt and passing it to the LLM.
Azure Cognitive Services (ACS) is a set of APIs that developers can leverage to perform different AI tasks. These APIs cover a broad range of AI scenarios, including:
- Speech
- Language
- Vision
- Decision
Input types like audio and video can be passed through Azure Cognitive Services, analyzed, and added as context to the LLM prompt (Figure 4).
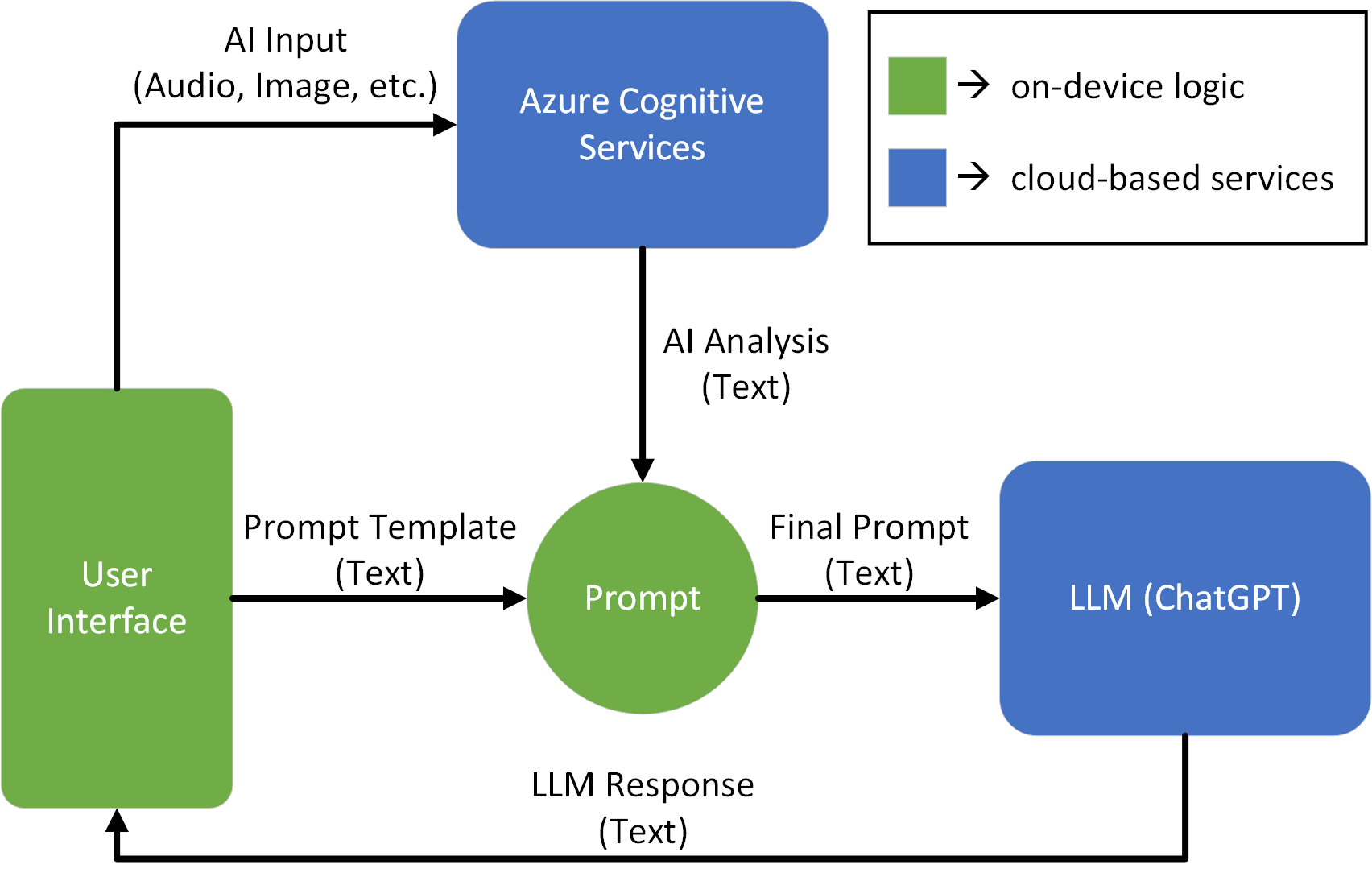
Figure 4 – Data flow diagram showing data being passed to ACS before being sent to ChatGPT.
Pictures and the camera are an integral part of the mobile experience, so we’ll focus on passing images to our LLM.
Figuring out which services to use
Like the Graph Explorer for Microsoft Graph, Azure Cognitive Services has an explorer for vision endpoints called “Vision Studio” – https://portal.vision.cognitive.azure.com/
When you first sign into Vision Studio, you will get prompted to choose a resource (Figure 5). This resource will be used to cover any costs accrued while using the Vision APIs.
Feel free to select “Do this later”, Vision Studio is a great way to explore what resources you would need to create for any given feature.

Figure 5 – Vision Studio dialogue to help users select an Azure Cognitive Resource to test with.
Since we’re trying to provide as much information about images as we can to our LLM, the “Image Analysis” section is a good starting point (Figure 6).
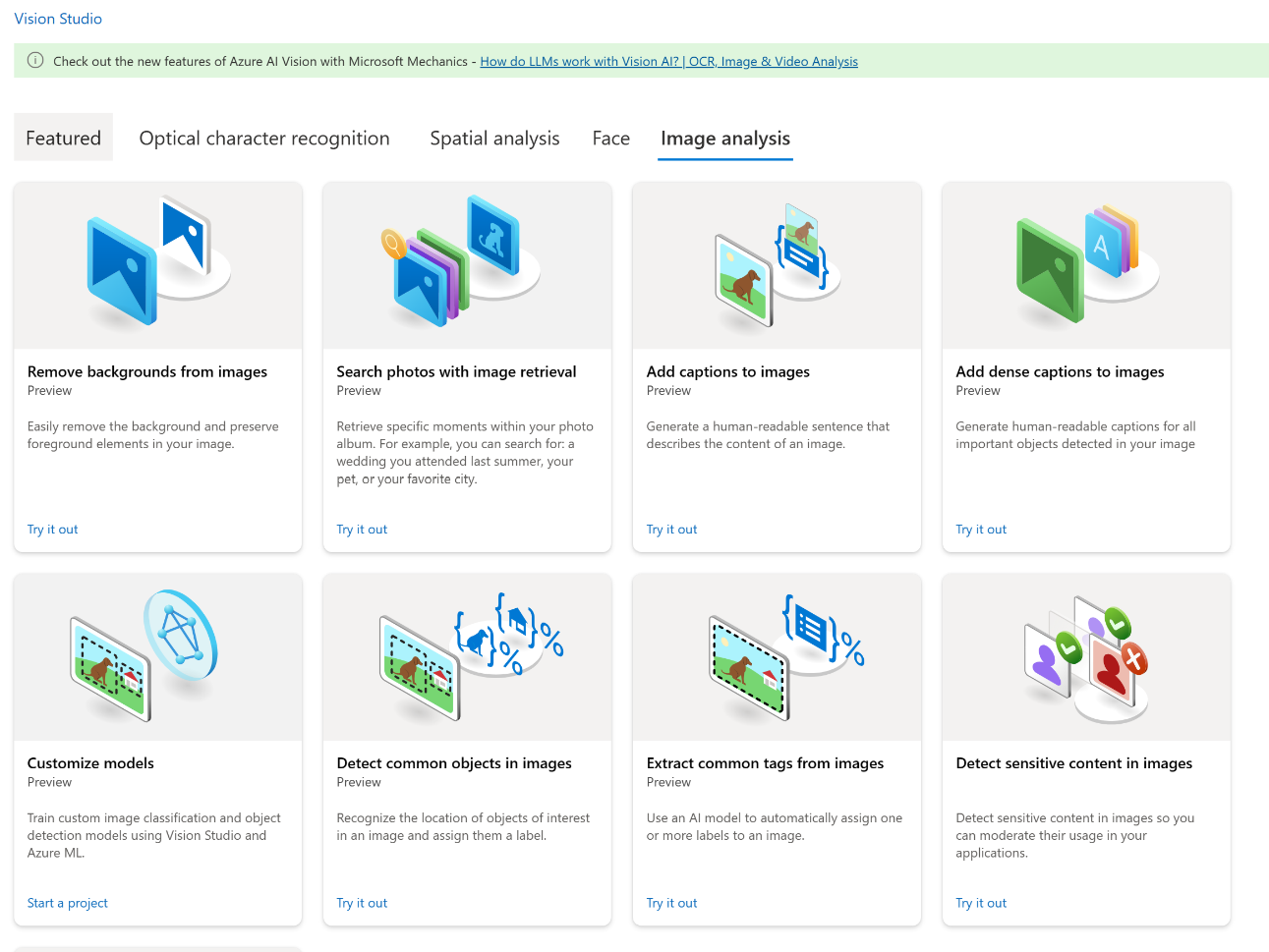
Figure 6 – Vision Studio’s image analysis catalogue.
Setting up a Computer Vision resource
Once we know what ACS features we’d like to use, we can set up an Azure resource. This will work similarly to the API key needed for using OpenAI endpoints.
You can either follow the Vision Studio dialog boxes from Figure 5 to set up a resource, or follow this Microsoft Learn tutorial to Create a Cognitive Services Resource with Azure Portal.
In our case, we want to use the Captions endpoint to help our LLM understand what the image represents. After testing the endpoint in Vision Studio, we know there are only a couple of valid Azure regions our resource can be assigned to (Figure 7).

Figure 7 – Image Analysis endpoint caveats.
Analyzing an image
Now that we have a valid Azure resource and know that the Captions endpoint is the one for us, the next step is calling it in our app!
The Image Analysis APIs that we’ve been testing in Vision Studio can be found here: https://learn.microsoft.com/azure/cognitive-services/computer-vision/how-to/call-analyze-image-40?tabs=rest.
Since there isn’t an Android Client SDK to make these calls, we’ll use the REST API to pass in our image, getting a JSON response from the Captions endpoint.
val request = Request.Builder()
.url(
"${Constants.AZURE_ENDPOINT_WEST_US}computervision/imageanalysis:analyze?api-version=2023-02-01-preview&features=caption"
)
.addHeader("Ocp-Apim-Subscription-Key", Constants.AZURE_SUBSCRIPTION_KEY)
.addHeader("Content-Type", "application/octet-stream")
.post(encodeToRequestBody(image))
.build()
val client = OkHttpClient.Builder()
.build()
val response = client.newCall(request).execute()
The encodeToRequestBody() function converts our in-app Bitmap image into a PNG formatted ByteArray.
private fun encodeToRequestBody(image: Bitmap): RequestBody {
ByteArrayOutputStream().use { baos ->
image.compress(Bitmap.CompressFormat.PNG, 100, baos)
return baos.toByteArray().toRequestBody("image/png".toMediaType())
}
}
Given the image in Figure 8…

Figure 8 – Whiteboard drawing of mountains.
… we get the following result from the Captions ACS endpoint!
{"captionResult":{"text":"a drawing of mountains and trees on a whiteboard"}}
This result can be passed to the LLM as the final prompt (Figure 9) or added to a prompt template, augmenting the prompt and helping add context to a different request.
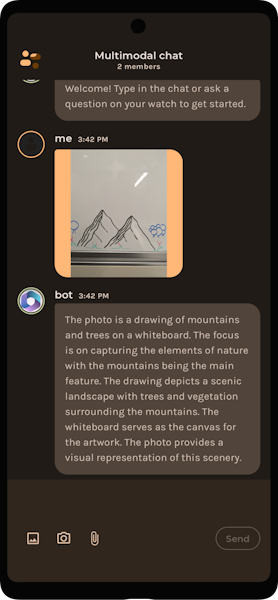
Figure 9 – Final result of requesting an image caption from ACS, passing it to ChatGPT, and getting a response.
And now our chatbot can accept images as input even though our LLM is text-based! Notice how the results are similar to Figure 1 – we have the Generative AI component of LLMs, with an extra added layer of AI preprocessing from ACS that traditional multimodal models don’t have.
Tradeoffs with Actual Multimodal Models
In this blog we’ve been ignoring one big question – why would anyone want to do this instead of using a multimodal LLM?
As with many other LLM evaluations, the decision comes down to a couple major factors.
- Cost – Multimodal models like GPT4 are substantially more expensive than their text-based counterparts. Using other AI services like Azure Cognitive Services can help offset the cost of supporting image inputs.
- Performance – Any amount of AI preprocessing on images is going to cause lost data. We’re essentially mapping a 3-dimensional shape into a 2-D plane. But for many use cases, a simplified version of multimodal behavior is fine.
- Availability – This factor is arguably the most variable to change in the future. Not everyone currently has access to the best, most cutting-edge models. For those who only have access to mid-tier models, this can be a good way to close the gap.
Resources and feedback
Here’s a summary of the links shared in this post:
- Language Is Not All You Need: Aligning Perception with Language Models
- Azure Cognitive Services
- Vision Studio
- Image Analysis API
If you have any questions, use the feedback forum or message us on Twitter @surfaceduodev.
There won’t be a livestream this week, but you can check out the archives on YouTube.
Citations
Huang, S., Dong, L., Wang, W., Hao, Y., Singhal, S., Ma, S., Lv, T., Cui, L., Mohammed, O. K., Patra, B., Liu, Q., Aggarwal, K., Chi, Z., Bjorck, J., Chaudhary, V., Som, S., Song, X., & Wei, F. (2023, March 1). Language is not all you need: Aligning perception with language models. https://arxiv.org/pdf/2302.14045.pdf
0 comments