
App Dev Manager Greg Roe shares insights on the importance of designing cloud application to be resilient to transient errors.
I was recently working with a large customer who was having repeated thermostat device connection issues to Azure IoT Hub due to transient cloud conditions (aka “outage”). It seemed every week there was a new outage, a new set of device disconnects, and a critical support ticket to fix the issue to understand why Microsoft took their devices offline!
This raises the larger question on how customers should think about Cloud Design Patterns that use the Retry pattern on a failed operation. The inherent nature of the cloud is that there can be momentary loss of network connectivity, temporary loss of service, and timeouts that can occur for a variety of reasons. By designing your application to handle these types of events gracefully, you can improve availability and minimize impact from transient events.
Context and problem
An application that communicates with elements running in the cloud has to be sensitive to transient faults that can occur in this environment. Faults include the momentary loss of network connectivity to components and services, the temporary unavailability of a service, or timeouts that occur when a service is busy or throttled.
These faults are typically self-correcting, and if the action that triggered a fault is repeated after a suitable delay it’s likely to be successful. For example, a database service that’s processing a large number of concurrent requests can implement a throttling strategy that temporarily rejects any further requests until its workload has eased. An application trying to access the database might fail to connect, but if it tries again after a delay it might succeed.
Solution
In the cloud, transient faults aren’t uncommon and an application should be designed to handle them elegantly and transparently. This minimizes the effects faults can have on the business tasks the application is performing.
If an application detects a failure when it tries to send a request to a remote service, it can handle the failure using the following strategies:
- Cancel. If the fault indicates that the failure isn’t transient or is unlikely to be successful if repeated, the application should cancel the operation and report an exception. For example, an authentication failure caused by providing invalid credentials is not likely to succeed no matter how many times it’s attempted.
- Retry. If the specific fault reported is unusual or rare, it might have been caused by unusual circumstances such as a network packet becoming corrupted while it was being transmitted. In this case, the application could retry the failing request again immediately because the same failure is unlikely to be repeated and the request will probably be successful.
- Retry after delay. If the fault is caused by one of the more commonplace connectivity or busy failures, the network or service might need a short period while the connectivity issues are corrected or the backlog of work is cleared. The application should wait for a suitable time before retrying the request
A little background on this particular Application. Their device (thermostat) was designed to be low cost, with limited compute and memory. As a result, they could not leverage Microsoft’s IoT SDK which has built in retry logic for free. As a result the customer developed their own custom AMQP connection software and retry logic.
The overall architecture looks something similar to:
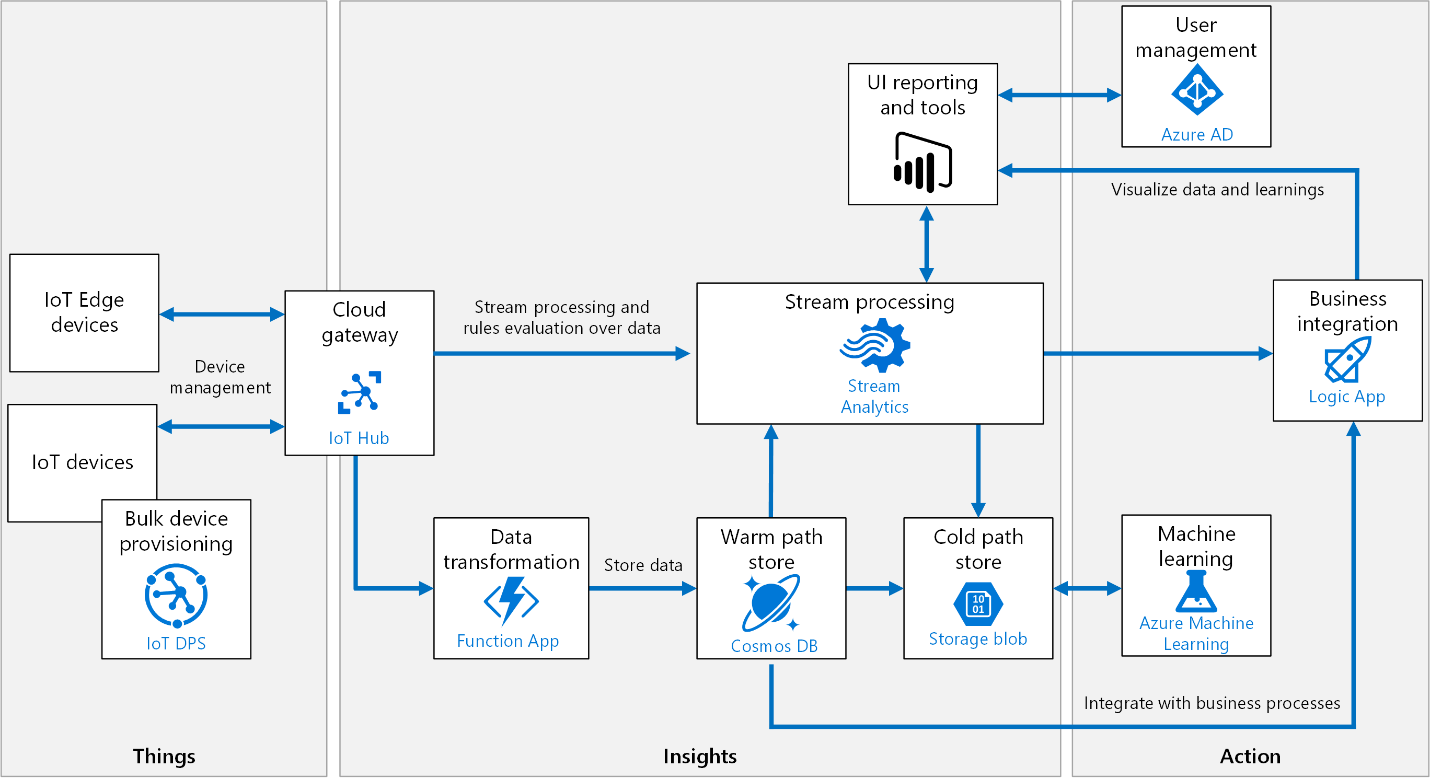
Before:
- Transient cloud condition occurs, usually millisecond to seconds
- Network outage
- Service Degradation
- Service Update –partial degradation.
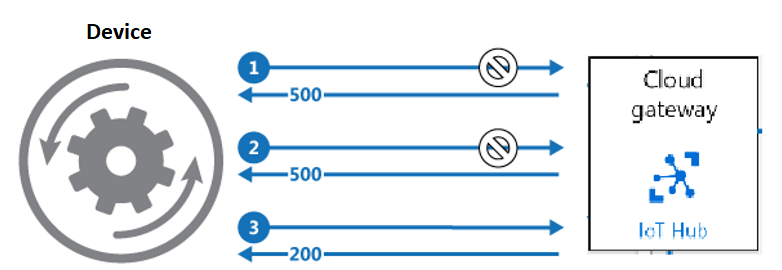
- Device sense outage. Custom retry logic. Retry many times in 10 seconds
- Devices fail to reconnect even though service has been restored
- Devices go thru custom re-provisioning. Offline many minutes
After: Retry Solution (After) Exponential Back off With Jitter
Upon review, the customer implemented an exponential back-off with Jitter retry strategy. The function to calculate the next interval is the following (x is the xth retry): F(x) = min(Cmin+ (2^(x-1)-1) * rand(C * (1 – Jd), C*(1-Ju)), Cmax)
This is a well-known retry strategy is exponential back off, allowing retries to be made initially quickly, but then at progressively longer intervals: for example, after 2, 4, 8, 15, and then 30 seconds.
In conclusion, transient conditions are a phenomenon of any modern cloud provider. To improve the stability of your application, implement a Cloud Design Pattern where your connections implement a retry algorithm that can handle a failed operation. You can use the IoT SDK and get the retry logic for free or you can write your own code to handle the retry. The result is your devices and app will be have an improved level of connectivity and stability.
Additional Learning
0 comments