


I look forward to summer every year. Sun, beach, warm nights, and putting the finishing touches on the next version of .NET. It’s also the time I get to continue a tradition I started for myself back in 2017 of writing about the performance improvements that have gone into the latest .NET incarnation. A year ago that was Performance Improvements in .NET 7, which followed similar posts for .NET 6, .NET 5, .NET Core 3.0, .NET Core 2.1, and .NET Core 2.0.
Since .NET 7 was released a year ago, you’ve likely been inundated with news about AI and ChatGPT. You may have even invested effort in using AI and/or incorporated it into your applications. And I got to wondering: could AI write this blog post for me? So I issued the following request to Bing Chat:
“You are an expert .NET developer with a penchant for pedagogy and a love of details. Write a treatise covering the most important performance improvements in .NET 8. The article should educate developers not just about what improvements were made, but also about why and how they were made so that developers can learn the relevant techniques and apply them in their own codebases. The article should also excite developers about the upcoming release, highlighting the very real benefits to upgrading their services, applications, and libraries to the new version. And the article should give credit to the myriad of developers that contributed significantly to the release, calling out the hundreds upon hundreds of pull requests that were merged to make .NET 8 the fastest .NET to date. The article should follow the style of the post about .NET 7 performance at https://devblogs.microsoft.com/dotnet/performance_improvements_in_net_7/. Based on the extent and depth of everything to cover, it is estimated that the article should be around 200 pages in length, including all code samples and exposition.”
And the response?
“I’m sorry, but I can’t write a 200-page treatise for you. That’s beyond the scope of my capabilities and my chat settings. I can only generate short and concise content, such as summaries, snippets, or paragraphs. If you want to learn more about the performance improvements in .NET 8, you can check out some of the web search results I found for you. You can also read the official release notes and the GitHub issue tracker for more details. I hope you understand and appreciate my limitations. Thank you for your interest in .NET 8. 😊”
Fair enough (especially since, after writing this post and measuring the token count, it’s north of 300,000). And I’m happy with that outcome, because it means I still get to have the fun of writing this myself.
Throughout the past year, as I was reviewing PRs in various .NET repos, I maintained a list of all the PRs that I might want to cover in this post, which is focused on the core runtime and libraries (Performance Improvements in ASP.NET Core 8 provides an in-depth focus on ASP.NET). And as I sat down to write this, I found myself staring at a daunting list of 1289 links. This post can’t cover all of them, but it does take a tour through more than 500 PRs, all of which have gone into making .NET 8 an irresistible release, one I hope you’ll all upgrade to as soon as humanly possible.
.NET 7 was super fast. .NET 8 is faster.
Table of Contents
- Benchmarking Setup
- JIT
- Native AOT
- VM
- GC
- Mono
- Threading
- Reflection
- Exceptions
- Primitives
- Strings, Arrays, and Spans
- Collections
- File I/O
- Networking
- JSON
- Cryptography
- Logging
- Configuration
- Peanut Butter
- What’s Next?
Benchmarking Setup
Throughout this post, I include microbenchmarks to highlight various aspects of the improvements being discussed. Most of those benchmarks are implemented using BenchmarkDotNet v0.13.8, and, unless otherwise noted, there is a simple setup for each of these benchmarks.
To follow along, first make sure you have .NET 7 and .NET 8 installed. For this post, I’ve used the .NET 8 Release Candidate (8.0.0-rc.1.23419.4).
With those prerequisites taken care of, create a new C# project in a new benchmarks directory:
dotnet new console -o benchmarks
cd benchmarksThat directory will contain two files: benchmarks.csproj (the project file with information about how the application should be built) and Program.cs (the code for the application). Replace the entire contents of benchmarks.csproj with this:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFrameworks>net8.0;net7.0</TargetFrameworks>
<LangVersion>Preview</LangVersion>
<ImplicitUsings>enable</ImplicitUsings>
<AllowUnsafeBlocks>true</AllowUnsafeBlocks>
<ServerGarbageCollection>true</ServerGarbageCollection>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="BenchmarkDotNet" Version="0.13.8" />
</ItemGroup>
</Project>The preceding project file tells the build system we want:
- to build a runnable application (as opposed to a library),
- to be able to run on both .NET 8 and .NET 7 (so that BenchmarkDotNet can run multiple processes, one with .NET 7 and one with .NET 8, in order to be able to compare the results),
- to be able to use all of the latest features from the C# language even though C# 12 hasn’t officially shipped yet,
- to automatically import common namespaces,
- to be able to use the
unsafekeyword in the code, - and to configure the garbage collector (GC) into its “server” configuration, which impacts the tradeoffs it makes between memory consumption and throughput (this isn’t strictly necessary, I’m just in the habit of using it, and it’s the default for ASP.NET apps.)
The <PackageReference/> at the end pulls in BenchmarkDotNet from NuGet so that we’re able to use the library in Program.cs. (A handful of benchmarks require additional packages be added; I’ve noted those where applicable.)
For each benchmark, I’ve then included the full Program.cs source; just copy and paste that code into Program.cs, replacing its entire contents. In each test, you’ll notice several attributes may be applied to the Tests class. The [MemoryDiagnoser] attribute indicates I want it to track managed allocation, the [DisassemblyDiagnoser] attribute indicates I want it to report on the actual assembly code generated for the test (and by default one level deep of functions invoked by the test), and the [HideColumns] attribute simply suppresses some columns of data BenchmarkDotNet might otherwise emit by default but are unnecessary for our purposes here.
Running the benchmarks is then straightforward. Each shown test also includes a comment at the beginning for the dotnet command to run the benchmark. Typically, it’s something like this:
dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0The preceding dotnet run command:
- builds the benchmarks in a Release build. This is important for performance testing, as most optimizations are disabled in Debug builds, in both the C# compiler and the JIT compiler.
- targets .NET 7 for the host project. In general with BenchmarkDotNet, you want to target the lowest-common denominator of all runtimes you’ll be executing against, so as to ensure that all of the APIs being used are available everywhere they’re needed.
- runs all of the benchmarks in the whole program. The
--filterargument can be refined to scope down to just a subset of benchmarks desired, but"*"says “run ’em all.” - runs the tests on both .NET 7 and .NET 8.
Throughout the post, I’ve shown many benchmarks and the results I received from running them. All of the code works well on all supported operating systems and architectures. Unless otherwise stated, the results shown for benchmarks are from running them on Linux (Ubuntu 22.04) on an x64 processor (the one bulk exception to this is when I’ve used [DisassemblyDiagnoser] to show assembly code, in which case I’ve run them on Windows 11 due to a sporadic issue on Unix with [DisassemblyDiagnoser] on .NET 7 not always producing the requested assembly). My standard caveat: these are microbenchmarks, often measuring operations that take very short periods of time, but where improvements to those times add up to be impactful when executed over and over and over. Different hardware, different operating systems, what else is running on your machine, your current mood, and what you ate for breakfast can all affect the numbers involved. In short, don’t expect the numbers you see to match exactly the numbers I report here, though I have chosen examples where the magnitude of differences cited is expected to be fully repeatable.
With all that out of the way, let’s dive in…
JIT
Code generation permeates every single line of code we write, and it’s critical to the end-to-end performance of applications that the compiler doing that code generation achieves high code quality. In .NET, that’s the job of the Just-In-Time (JIT) compiler, which is used both “just in time” as an application executes as well as in Ahead-Of-Time (AOT) scenarios as the workhorse to perform the codegen at build-time. Every release of .NET has seen significant improvements in the JIT, and .NET 8 is no exception. In fact, I dare say the improvements in .NET 8 in the JIT are an incredible leap beyond what was achieved in the past, in large part due to dynamic PGO…
Tiering and Dynamic PGO
To understand dynamic PGO, we first need to understand “tiering.” For many years, a .NET method was only ever compiled once: on first invocation of the method, the JIT would kick in to generate code for that method, and then that invocation and every subsequent one would use that generated code. It was a simple time, but also one frought with conflict… in particular, a conflict between how much the JIT should invest in code quality for the method and how much benefit would be gained from that enhanced code quality. Optimization is one of the most expensive things a compiler does; a compiler can spend an untold amount of time searching for additional ways to shave off an instruction here or improve the instruction sequence there. But none of us has an infinite amount of time to wait for the compiler to finish, especially in a “just in time” scenario where the compilation is happening as the application is running. As such, in a world where a method is compiled once for that process, the JIT has to either pessimize code quality or pessimize how long it takes to run, which means a tradeoff between steady-state throughput and startup time.
As it turns out, however, the vast majority of methods invoked in an application are only ever invoked once or a small number of times. Spending a lot of time optimizing such methods would actually be a deoptimization, as likely it would take much more time to optimize them than those optimizations would gain. So, .NET Core 3.0 introduced a new feature of the JIT known as “tiered compilation.” With tiering, a method could end up being compiled multiple times. On first invocation, the method would be compiled in “tier 0,” in which the JIT prioritizes speed of compilation over code quality; in fact, the mode the JIT uses is often referred to as “min opts,” or minimal optimization, because it does as little optimization as it can muster (it still maintains a few optimizations, primarily the ones that result in less code to be compiled such that the JIT actually runs faster). In addition to minimizing optimizations, however, it also employs call counting “stubs”; when you invoke the method, the call goes through a little piece of code (the stub) that counts how many times the method was invoked, and once that count crosses a predetermined threshold (e.g. 30 calls), the method gets queued for re-compilation, this time at “tier 1,” in which the JIT throws every optimization it’s capable of at the method. Only a small subset of methods make it to tier 1, and those that do are the ones worthy of additional investment in code quality. Interestingly, there are things the JIT can learn about the method from tier 0 that can lead to even better tier 1 code quality than if the method had been compiled to tier 1 directly. For example, the JIT knows that a method “tiering up” from tier 0 to tier 1 has already been executed, and if it’s already been executed, then any static readonly fields it accesses are now already initialized, which means the JIT can look at the values of those fields and base the tier 1 code gen on what’s actually in the field (e.g. if it’s a static readonly bool, the JIT can now treat the value of that field as if it were const bool). If the method were instead compiled directly to tier 1, the JIT might not be able to make the same optimizations. Thus, with tiering, we can “have our cake and eat it, too.” We get both good startup and good throughput. Mostly…
One wrinkle to this scheme, however, is the presence of longer-running methods. Methods might be important because they’re invoked many times, but they might also be important because they’re invoked only a few times but end up running forever, in particular due to looping. As such, tiering was disabled by default for methods containing backward branches, such that those methods would go straight to tier 1. To address that, .NET 7 introduced On-Stack Replacement (OSR). With OSR, the code generated for loops also included a counting mechanism, and after a loop iterated to a certain threshold, the JIT would compile a new optimized version of the method and jump from the minimally-optimized code to continue execution in the optimized variant. Pretty slick, and with that, in .NET 7 tiering was also enabled for methods with loops.
But why is OSR important? If there are only a few such long-running methods, what’s the big deal if they just go straight to tier 1? Surely startup isn’t significantly negatively impacted? First, it can be: if you’re trying to trim milliseconds off startup time, every method counts. But second, as noted before, there are throughput benefits to going through tier 0, in that there are things the JIT can learn about a method from tier 0 which can then improve its tier 1 compilation. And the list of things the JIT can learn gets a whole lot bigger with dynamic PGO.
Profile-Guided Optimization (PGO) has been around for decades, for many languages and environments, including in .NET world. The typical flow is you build your application with some additional instrumentation, you then run your application on key scenarios, you gather up the results of that instrumentation, and then you rebuild your application, feeding that instrumentation data into the optimizer, allowing it to use the knowledge about how the code executed to impact how it’s optimized. This approach is often referred to as “static PGO.” “Dynamic PGO” is similar, except there’s no effort required around how the application is built, scenarios it’s run on, or any of that. With tiering, the JIT is already generating a tier 0 version of the code and then a tier 1 version of the code… why not sprinkle some instrumentation into the tier 0 code as well? Then the JIT can use the results of that instrumentation to better optimize tier 1. It’s the same basic “build, run and collect, re-build” flow as with static PGO, but now on a per-method basis, entirely within the execution of the application, and handled automatically for you by the JIT, with zero additional dev effort required and zero additional investment needed in build automation or infrastructure.
Dynamic PGO first previewed in .NET 6, off by default. It was improved in .NET 7, but remained off by default. Now, in .NET 8, I’m thrilled to say it’s not only been significantly improved, it’s now on by default. This one-character PR to enable it might be the most valuable PR in all of .NET 8: dotnet/runtime#86225.
There have been a multitude of PRs to make all of this work better in .NET 8, both on tiering in general and then on dynamic PGO in particular. One of the more interesting changes is dotnet/runtime#70941, which added more tiers, though we still refer to the unoptimized as “tier 0” and the optimized as “tier 1.” This was done primarily for two reasons. First, instrumentation isn’t free; if the goal of tier 0 is to make compilation as cheap as possible, then we want to avoid adding yet more code to be compiled. So, the PR adds a new tier to address that. Most code first gets compiled to an unoptimized and uninstrumented tier (though methods with loops currently skip this tier). Then after a certain number of invocations, it gets recompiled unoptimized but instrumented. And then after a certain number of invocations, it gets compiled as optimized using the resulting instrumentation data. Second, crossgen/ReadyToRun (R2R) images were previously unable to participate in dynamic PGO. This was a big problem for taking full advantage of all that dynamic PGO offers, in particular because there’s a significant amount of code that every .NET application uses that’s already R2R’d: the core libraries. ReadyToRun is an AOT technology that enables most of the code generation work to be done at build-time, with just some minimal fix-ups applied when that precompiled code is prepared for execution. That code is optimized and not instrumented, or else the instrumentation would slow it down. So, this PR also adds a new tier for R2R. After an R2R method has been invoked some number of times, it’s recompiled, again with optimizations but this time also with instrumentation, and then when that’s been invoked sufficiently, it’s promoted again, this time to an optimized implementation utilizing the instrumentation data gathered in the previous tier.

There have also been multiple changes focused on doing more optimization in tier 0. As noted previously, the JIT wants to be able to compile tier 0 as quickly as possible, however some optimizations in code quality actually help it to do that. For example, dotnet/runtime#82412 teaches it to do some amount of constant folding (evaluating constant expressions at compile time rather than at execution time), as that can enable it to generate much less code. Much of the time the JIT spends compiling in tier 0 is for interactions with the Virtual Machine (VM) layer of the .NET runtime, such as resolving types, and so if it can significantly trim away branches that won’t ever be used, it can actually speed up tier 0 compilation while also getting better code quality. We can see this with a simple repro app like the following:
// dotnet run -c Release -f net8.0
MaybePrint(42.0);
static void MaybePrint<T>(T value)
{
if (value is int)
Console.WriteLine(value);
}I can set the DOTNET_JitDisasm environment variable to *MaybePrint*; that will result in the JIT printing out to the console the code it emits for this method. On .NET 7, when I run this (dotnet run -c Release -f net7.0), I get the following tier 0 code:
; Assembly listing for method Program:<<Main>$>g__MaybePrint|0_0[double](double)
; Emitting BLENDED_CODE for X64 CPU with AVX - Windows
; Tier-0 compilation
; MinOpts code
; rbp based frame
; partially interruptible
G_M000_IG01: ;; offset=0000H
55 push rbp
4883EC30 sub rsp, 48
C5F877 vzeroupper
488D6C2430 lea rbp, [rsp+30H]
33C0 xor eax, eax
488945F8 mov qword ptr [rbp-08H], rax
C5FB114510 vmovsd qword ptr [rbp+10H], xmm0
G_M000_IG02: ;; offset=0018H
33C9 xor ecx, ecx
85C9 test ecx, ecx
742D je SHORT G_M000_IG03
48B9B877CB99F97F0000 mov rcx, 0x7FF999CB77B8
E813C9AE5F call CORINFO_HELP_NEWSFAST
488945F8 mov gword ptr [rbp-08H], rax
488B4DF8 mov rcx, gword ptr [rbp-08H]
C5FB104510 vmovsd xmm0, qword ptr [rbp+10H]
C5FB114108 vmovsd qword ptr [rcx+08H], xmm0
488B4DF8 mov rcx, gword ptr [rbp-08H]
FF15BFF72000 call [System.Console:WriteLine(System.Object)]
G_M000_IG03: ;; offset=0049H
90 nop
G_M000_IG04: ;; offset=004AH
4883C430 add rsp, 48
5D pop rbp
C3 ret
; Total bytes of code 80The important thing to note here is that all of the code associated with the Console.WriteLine had to be emitted, including the JIT needing to resolve the method tokens involved (which is how it knew to print “System.Console:WriteLine”), even though that branch will provably never be taken (it’s only taken when value is int and the JIT can see that value is a double). Now in .NET 8, it applies the previously-reserved-for-tier-1 constant folding optimizations that recognize the value is not an int and generates tier 0 code accordingly (dotnet run -c Release -f net8.0):
; Assembly listing for method Program:<<Main>$>g__MaybePrint|0_0[double](double) (Tier0)
; Emitting BLENDED_CODE for X64 with AVX - Windows
; Tier0 code
; rbp based frame
; partially interruptible
G_M000_IG01: ;; offset=0x0000
push rbp
mov rbp, rsp
vmovsd qword ptr [rbp+0x10], xmm0
G_M000_IG02: ;; offset=0x0009
G_M000_IG03: ;; offset=0x0009
pop rbp
ret
; Total bytes of code 11dotnet/runtime#77357 and dotnet/runtime#83002 also enable some JIT intrinsics to be employed in tier 0 (a JIT intrinsic is a method the JIT has some special knowledge of, either knowing about its behavior so it can optimize around it accordingly, or in many cases actually supplying its own implementation to replace the one in the method’s body). This is in part for the same reason; many intrinsics can result in better dead code elimination (e.g. if (typeof(T).IsValueType) { ... }). But more so, without recognizing intrinsics as being special, we might end up generating code for an intrinsic method that we would never otherwise need to generate code for, even in tier 1. dotnet/runtime#88989 also eliminates some forms of boxing in tier 0.
Collecting all of this instrumentation in tier 0 instrumented code brings with it some of its own challenges. The JIT is augmenting a bunch of methods to track a lot of additional data; where and how does it track it? And how does it do so safely and correctly when multiple threads are potentially accessing all of this at the same time? For example, one of the things the JIT tracks in an instrumented method is which branches are followed and how frequently; that requires it to count each time code traverses that branch. You can imagine that happens, well, a lot. How can it do the counting in a thread-safe yet efficient way?
The answer previously was, it didn’t. It used racy, non-synchronized updates to a shared value, e.g. _branches[branchNum]++. This means that some updates might get lost in the presence of multithreaded access, but as the answer here only needs to be approximate, that was deemed ok. As it turns out, however, in some cases it was resulting in a lot of lost counts, which in turn caused the JIT to optimize for the wrong things. Another approach tried for comparison purposes in dotnet/runtime#82775 was to use interlocked operations (e.g. if this were C#, Interlocked.Increment); that results in perfect accuracy, but that explicit synchronization represents a huge potential bottleneck when heavily contended. dotnet/runtime#84427 provides the approach that’s now enabled by default in .NET 8. It’s an implementation of a scalable approximate counter that employs some amount of pseudo-randomness to decide how often to synchronize and by how much to increment the shared count. There’s a great description of all of this in the dotnet/runtime repo; here is a C# implementation of the counting logic based on that discussion:
static void Count(ref uint sharedCounter)
{
uint currentCount = sharedCounter, delta = 1;
if (currentCount > 0)
{
int logCount = 31 - (int)uint.LeadingZeroCount(currentCount);
if (logCount >= 13)
{
delta = 1u << (logCount - 12);
uint random = (uint)Random.Shared.NextInt64(0, uint.MaxValue + 1L);
if ((random & (delta - 1)) != 0)
{
return;
}
}
}
Interlocked.Add(ref sharedCounter, delta);
}For current count values less than 8192, it ends up just doing the equivalent of an Interlocked.Add(ref counter, 1). However, as the count increases to beyond that threshold, it starts only doing the add randomly half the time, and when it does, it adds 2. Then randomly a quarter of the time it adds 4. Then an eighth of the time it adds 8. And so on. In this way, as more and more increments are performed, it requires writing to the shared counter less and less frequently.
We can test this out with a little app like the following (if you want to try running it, just copy the above Count into the program as well):
// dotnet run -c Release -f net8.0
using System.Diagnostics;
uint counter = 0;
const int ItersPerThread = 100_000_000;
while (true)
{
Run("Interlock", _ => { for (int i = 0; i < ItersPerThread; i++) Interlocked.Increment(ref counter); });
Run("Racy ", _ => { for (int i = 0; i < ItersPerThread; i++) counter++; });
Run("Scalable ", _ => { for (int i = 0; i < ItersPerThread; i++) Count(ref counter); });
Console.WriteLine();
}
void Run(string name, Action<int> body)
{
counter = 0;
long start = Stopwatch.GetTimestamp();
Parallel.For(0, Environment.ProcessorCount, body);
long end = Stopwatch.GetTimestamp();
Console.WriteLine($"{name} => Expected: {Environment.ProcessorCount * ItersPerThread:N0}, Actual: {counter,13:N0}, Elapsed: {Stopwatch.GetElapsedTime(start, end).TotalMilliseconds}ms");
}When I run that, I get results like this:
Interlock => Expected: 1,200,000,000, Actual: 1,200,000,000, Elapsed: 20185.548ms
Racy => Expected: 1,200,000,000, Actual: 138,526,798, Elapsed: 987.4997ms
Scalable => Expected: 1,200,000,000, Actual: 1,193,541,836, Elapsed: 1082.8471msI find these results fascinating. The interlocked approach gets the exact right count, but it’s super slow, ~20x slower than the other approaches. The fastest is the racy additions one, but its count is also wildly inaccurate: it was off by a factor of 8x! The scalable counters solution was only a hair slower than the racy solution, but its count was only off the expected value by 0.5%. This scalable approach then enables the JIT to track what it needs with the efficiency and approximate accuracy it needs. Other PRs like dotnet/runtime#82014, dotnet/runtime#81731, and dotnet/runtime#81932 also went into improving the JIT’s efficiency around tracking this information.
As it turns out, this isn’t the only use of randomness in dynamic PGO. Another is used as part of determining which types are the most common targets of virtual and interface method calls. At a given call site, the JIT wants to know which type is most commonly used and by what percentage; if there’s a clear winner, it can then generate a fast path specific to that type. As in the previous example, tracking a count for every possible type that might come through is expensive. Instead, it uses an algorithm known as “reservoir sampling”. Let’s say I have a char[1_000_000] containing ~60% 'a's, ~30% 'b's, and ~10% 'c's, and I want to know which is the most common. With reservoir sampling, I might do so like this:
// dotnet run -c Release -f net8.0
// Create random input for testing, with 60% a, 30% b, 10% c
char[] chars = new char[1_000_000];
Array.Fill(chars, 'a', 0, 600_000);
Array.Fill(chars, 'b', 600_000, 300_000);
Array.Fill(chars, 'c', 900_000, 100_000);
Random.Shared.Shuffle(chars);
for (int trial = 0; trial < 5; trial++)
{
// Reservoir sampling
char[] reservoir = new char[32]; // same reservoir size as the JIT
int next = 0;
for (int i = 0; i < reservoir.Length && next < chars.Length; i++, next++)
{
reservoir[i] = chars[i];
}
for (; next < chars.Length; next++)
{
int r = Random.Shared.Next(next + 1);
if (r < reservoir.Length)
{
reservoir[r] = chars[next];
}
}
// Print resulting percentages
Console.WriteLine($"a: {reservoir.Count(c => c == 'a') * 100.0 / reservoir.Length}");
Console.WriteLine($"b: {reservoir.Count(c => c == 'b') * 100.0 / reservoir.Length}");
Console.WriteLine($"c: {reservoir.Count(c => c == 'c') * 100.0 / reservoir.Length}");
Console.WriteLine();
}When I run this, I get results like the following:
a: 53.125
b: 31.25
c: 15.625
a: 65.625
b: 28.125
c: 6.25
a: 68.75
b: 25
c: 6.25
a: 40.625
b: 31.25
c: 28.125
a: 59.375
b: 25
c: 15.625Note that in the above example, I actually had all the data in advance; in contrast, the JIT likely has multiple threads all running instrumented code and overwriting elements in the reservoir. I also happened to choose the same size reservoir the JIT is using as of dotnet/runtime#87332, which highlights how that value was chosen for its use case and why it needed to be tweaked.
On all five runs above, it correctly found there to be more 'a's than 'b's and more 'b's than 'c's, and it was often reasonably close to the actual percentages. But, importantly, randomness is involved here, and every run produced slightly different results. I mention this because that means the JIT compiler now incorporates randomness, which means that the produced dynamic PGO instrumentation data is very likely to be slightly different from run to run. However, even without explicit use of randomness, there’s already non-determinism in such code, and in general there’s enough data produced that the overall behavior is quite stable and repeatable.
Interestingly, the JIT’s PGO-based optimizations aren’t just based on the data gathered during instrumented tier 0 execution. With dotnet/runtime#82926 (and a handful of follow-on PRs like dotnet/runtime#83068, dotnet/runtime#83567, dotnet/runtime#84312, and dotnet/runtime#84741), the JIT will now create a synthetic profile based on statically analyzing the code and estimating a profile, such as with various approaches to static branch prediction. The JIT can then blend this data together with the instrumentation data, helping to fill in data where there are gaps (think “Jurassic Park” and using modern reptile DNA to plug the gaps in the recovered dinosaur DNA).
Beyond the mechanisms used to enable tiering and dynamic PGO getting better (and, did I mention, being on by default?!) in .NET 8, the optimizations it performs also get better. One of the main optimizations dynamic PGO feeds is the ability to devirtualize virtual and interface calls per call site. As noted, the JIT tracks what concrete types are used, and then can generate a fast path for the most common type; this is known as guarded devirtualization (GDV). Consider this benchmark:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
internal interface IValueProducer
{
int GetValue();
}
class Producer42 : IValueProducer
{
public int GetValue() => 42;
}
private IValueProducer _valueProducer;
private int _factor = 2;
[GlobalSetup]
public void Setup() => _valueProducer = new Producer42();
[Benchmark]
public int GetValue() => _valueProducer.GetValue() * _factor;
}The GetValue method is doing:
return _valueProducer.GetValue() * _factor;Without PGO, that’s just a normal interface dispatch. With PGO, however, the JIT will end up seeing that the actual type of _valueProducer is most commonly Producer42, and it will end up generating tier 1 code closer to if my benchmark was instead:
int result = _valueProducer.GetType() == typeof(Producer42) ?
Unsafe.As<Producer42>(_valueProducer).GetValue() :
_valueProducer.GetValue();
return result * _factor;It can then in turn see that the Producer42.GetValue() method is really simple, and so not only is the GetValue call devirtualized, it’s also inlined, such that the code effectively becomes:
int result = _valueProducer.GetType() == typeof(Producer42) ?
42 :
_valueProducer.GetValue();
return result * _factor;We can confirm this by running the above benchmark. The resulting numbers certainly show something going on:
| Method | Runtime | Mean | Ratio | Code Size |
|---|---|---|---|---|
| GetValue | .NET 7.0 | 1.6430 ns | 1.00 | 35 B |
| GetValue | .NET 8.0 | 0.0523 ns | 0.03 | 57 B |
We see it’s both faster (which we expected) and more code (which we also expected). Now for the assembly. On .NET 7, we get this:
; Tests.GetValue()
push rsi
sub rsp,20
mov rsi,rcx
mov rcx,[rsi+8]
mov r11,7FF999B30498
call qword ptr [r11]
imul eax,[rsi+10]
add rsp,20
pop rsi
ret
; Total bytes of code 35We can see it’s performing the interface call (the three movs followed by the call) and then multiplying the result by _factor (imul eax,[rsi+10]). Now on .NET 8, we get this:
; Tests.GetValue()
push rbx
sub rsp,20
mov rbx,rcx
mov rcx,[rbx+8]
mov rax,offset MT_Tests+Producer42
cmp [rcx],rax
jne short M00_L01
mov eax,2A
M00_L00:
imul eax,[rbx+10]
add rsp,20
pop rbx
ret
M00_L01:
mov r11,7FFA1FAB04D8
call qword ptr [r11]
jmp short M00_L00
; Total bytes of code 57We still see the call, but it’s buried in a cold section at the end. Instead, we see the type of the object being compared against MT_Tests+Producer42, and if it matches (the cmp [rcx],rax followed by the jne), we store 2A into eax; 2A is the hex representation of 42, so this is the entirety of the inlined body of the devirtualized Producer42.GetValue call. .NET 8 is also capable of doing multiple GDVs, meaning it can generate fast paths for more than 1 type, thanks in large part to dotnet/runtime#86551 and dotnet/runtime#86809. However, this is off by default and for now needs to be opted-into with a configuration setting (setting the DOTNET_JitGuardedDevirtualizationMaxTypeChecks environment variable to the desired maximum number of types for which to test). We can see the impact of that with this benchmark (note that because I’ve explicitly specified the configs to use in the code itself, I’ve omitted the --runtimes argument in the dotnet command):
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Environments;
using BenchmarkDotNet.Jobs;
using BenchmarkDotNet.Running;
using System.Runtime.CompilerServices;
var config = DefaultConfig.Instance
.AddJob(Job.Default.WithId("ChecksOne").WithRuntime(CoreRuntime.Core80))
.AddJob(Job.Default.WithId("ChecksThree").WithRuntime(CoreRuntime.Core80).WithEnvironmentVariable("DOTNET_JitGuardedDevirtualizationMaxTypeChecks", "3"));
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args, config);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "EnvironmentVariables")]
[DisassemblyDiagnoser]
public class Tests
{
private readonly A _a = new();
private readonly B _b = new();
private readonly C _c = new();
[Benchmark]
public void Multiple()
{
DoWork(_a);
DoWork(_b);
DoWork(_c);
}
[MethodImpl(MethodImplOptions.NoInlining)]
private static int DoWork(IMyInterface i) => i.GetValue();
private interface IMyInterface { int GetValue(); }
private class A : IMyInterface { public int GetValue() => 123; }
private class B : IMyInterface { public int GetValue() => 456; }
private class C : IMyInterface { public int GetValue() => 789; }
}| Method | Job | Mean | Code Size |
|---|---|---|---|
| Multiple | ChecksOne | 7.463 ns | 90 B |
| Multiple | ChecksThree | 5.632 ns | 133 B |
And in the assembly code with the environment variable set, we can indeed see it doing multiple checks for three types before falling back to the general interface dispatch:
; Tests.DoWork(IMyInterface)
sub rsp,28
mov rax,offset MT_Tests+A
cmp [rcx],rax
jne short M01_L00
mov eax,7B
jmp short M01_L02
M01_L00:
mov rax,offset MT_Tests+B
cmp [rcx],rax
jne short M01_L01
mov eax,1C8
jmp short M01_L02
M01_L01:
mov rax,offset MT_Tests+C
cmp [rcx],rax
jne short M01_L03
mov eax,315
M01_L02:
add rsp,28
ret
M01_L03:
mov r11,7FFA1FAC04D8
call qword ptr [r11]
jmp short M01_L02
; Total bytes of code 88(Interestingly, this optimization gets a bit better in Native AOT. There, with dotnet/runtime#87055, there can be no need for the fallback path. The compiler can see the entire program being optimized and can generate fast paths for all of the types that implement the target abstraction if it’s a small number.)
dotnet/runtime#75140 provides another really nice optimization, still related to GDV, but now for delegates and in relation to loop cloning. Take the following benchmark:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser]
public class Tests
{
private readonly Func<int, int> _func = i => i + 1;
[Benchmark]
public int Sum() => Sum(_func);
private static int Sum(Func<int, int> func)
{
int sum = 0;
for (int i = 0; i < 10_000; i++)
{
sum += func(i);
}
return sum;
}
}Dynamic PGO is capable of doing GDV with delegates just as it is with virtual and interface methods. The JIT’s profiling of this method will highlight that the function being invoked is always the same i => i + 1 lambda, and as we saw, that can then be transformed into a method something like the following pseudo-code:
private static int Sum(Func<int, int> func)
{
int sum = 0;
for (int i = 0; i < 10_000; i++)
{
sum += func.Method == KnownLambda ? i + 1 : func(i);
}
return sum;
}It’s not very visible that inside our loop we’re performing the same check over and over and over. We’re also branching based on it. One common compiler optimization is “hoisting,” where a computation that’s “loop invariant” (meaning it doesn’t change per iteration) can be pulled out of the loop to be above it, e.g.
private static int Sum(Func<int, int> func)
{
int sum = 0;
bool isAdd = func.Method == KnownLambda;
for (int i = 0; i < 10_000; i++)
{
sum += isAdd ? i + 1 : func(i);
}
return sum;
}but even with that, we still have the branch on each iteration. Wouldn’t it be nice if we could hoist that as well? What if we could “clone” the loop, duplicating it once for when the method is the known target and once for when it’s not. That’s “loop cloning,” an optimization the JIT is already capable of for other reasons, and now in .NET 8 the JIT is capable of that with this exact scenario, too. The code it’ll produce ends up then being very similar to this:
private static int Sum(Func<int, int> func)
{
int sum = 0;
if (func.Method == KnownLambda)
{
for (int i = 0; i < 10_000; i++)
{
sum += i + 1;
}
}
else
{
for (int i = 0; i < 10_000; i++)
{
sum += func(i);
}
}
return sum;
}Looking at the generated assembly on .NET 8 confirms this:
; Tests.Sum(System.Func`2<Int32,Int32>)
push rdi
push rsi
push rbx
sub rsp,20
mov rbx,rcx
xor esi,esi
xor edi,edi
test rbx,rbx
je short M01_L01
mov rax,7FFA2D630F78
cmp [rbx+18],rax
jne short M01_L01
M01_L00:
inc edi
mov eax,edi
add esi,eax
cmp edi,2710
jl short M01_L00
jmp short M01_L03
M01_L01:
mov rax,7FFA2D630F78
cmp [rbx+18],rax
jne short M01_L04
lea eax,[rdi+1]
M01_L02:
add esi,eax
inc edi
cmp edi,2710
jl short M01_L01
M01_L03:
mov eax,esi
add rsp,20
pop rbx
pop rsi
pop rdi
ret
M01_L04:
mov edx,edi
mov rcx,[rbx+8]
call qword ptr [rbx+18]
jmp short M01_L02
; Total bytes of code 103Focus just on the M01_L00 block: you can see it ends with a jl short M01_L00 to loop back around to M01_L00 if edi (which is storing i) is less than 0x2710, or 10,000 decimal, aka our loop’s upper bound. Note that there are just a few instructions in the middle, nothing at all resembling a call… this is the optimized cloned loop, where our lambda has been inlined. There’s another loop that alternates between M01_L02, M01_L01, and M01_L04, and that one does have a call… that’s the fallback loop. And if we run the benchmark, we see a huge resulting improvement:
| Method | Runtime | Mean | Ratio | Code Size |
|---|---|---|---|---|
| Sum | .NET 7.0 | 16.546 us | 1.00 | 55 B |
| Sum | .NET 8.0 | 2.320 us | 0.14 | 113 B |
As long as we’re discussing hoisting, it’s worth noting other improvements have also contributed. In particular, dotnet/runtime#81635 enables the JIT to hoist more code used in generic method dispatch. We can see that in action with a benchmark like this:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Runtime.CompilerServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
[Benchmark]
public void Test() => Test<string>();
static void Test<T>()
{
for (int i = 0; i < 100; i++)
{
Callee<T>();
}
}
[MethodImpl(MethodImplOptions.NoInlining)]
static void Callee<T>() { }
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Test | .NET 7.0 | 170.8 ns | 1.00 |
| Test | .NET 8.0 | 147.0 ns | 0.86 |
Before moving on, one word of warning about dynamic PGO: it’s good at what it does, really good. Why is that a “warning?” Dynamic PGO is very good about seeing what your code is doing and optimizing for it, which is awesome when you’re talking about your production applications. But there’s a particular kind of coding where you might not want that to happen, or at least you need to be acutely aware of it happening, and you’re currently looking at it: benchmarks. Microbenchmarks are all about isolating a particular piece of functionality and running that over and over and over and over in order to get good measurements about its overhead. With dynamic PGO, however, the JIT will then optimize for the exact thing you’re testing. If the thing you’re testing is exactly how the code will execute in production, then awesome. But if your test isn’t fully representative, you can get a skewed understanding of the costs involved, which can lead to making less-than-ideal assumptions and decisions.
For example, consider this benchmark:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Environments;
using BenchmarkDotNet.Jobs;
using BenchmarkDotNet.Running;
var config = DefaultConfig.Instance
.AddJob(Job.Default.WithId("No PGO").WithRuntime(CoreRuntime.Core80).WithEnvironmentVariable("DOTNET_TieredPGO", "0"))
.AddJob(Job.Default.WithId("PGO").WithRuntime(CoreRuntime.Core80));
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args, config);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "EnvironmentVariables")]
public class Tests
{
private static readonly Random s_rand = new();
private readonly IEnumerable<int> _source = Enumerable.Repeat(0, 1024);
[Params(1.0, 0.5)]
public double Probability { get; set; }
[Benchmark]
public bool Any() => s_rand.NextDouble() < Probability ?
_source.Any(i => i == 42) :
_source.Any(i => i == 43);
}This runs a benchmark with two different “Probability” values. Regardless of that value, the code that’s executed for the benchmark does exactly the same thing and should result in exactly the same assembly code (other than one path checking for the value 42 and the other for 43). In a world without PGO, there should be close to zero difference in performance between the runs, and if we set the DOTNET_TieredPGO environment variable to 0 (to disable PGO), that’s exactly what we see, but with PGO, we observe a larger difference:
| Method | Job | Probability | Mean |
|---|---|---|---|
| Any | No PGO | 0.5 | 5.354 us |
| Any | No PGO | 1 | 5.314 us |
| Any | PGO | 0.5 | 1.969 us |
| Any | PGO | 1 | 1.495 us |
When all of the calls use i == 42 (because we set the probability to 1, all of the random values are less than that, and we always take the first branch), we see throughput ends up being 25% faster than when half of the calls use i == 42 and half use i == 43. If your benchmark was only trying to measure the overhead of using Enumerable.Any, you might not realize that the resulting code was being optimized for calling Any with the same delegate every time, in which case you get different results than if Any is called with multiple delegates and all with reasonably equal chances of being used. (As an aside, the nice overall improvement between dynamic PGO being disabled and enabled comes in part from the use of Random, which internally makes a virtual call that dynamic PGO can help elide.)
Throughout the rest of this post, I’ve kept this in mind and tried hard to show benchmarks where the resulting wins are due primarily to the cited improvements in the relevant code; where dynamic PGO plays a larger role in the improvements, I’ve called that out, often showing the results with and without dynamic PGO. There are many more benchmarks I could have shown but have avoided where it would look like a particular method had massive improvements, yet in reality it’d all be due to dynamic PGO being its awesome self rather than some explicit change made to the method’s C# code.
One final note about dynamic PGO: it’s awesome, but it doesn’t obviate the need for thoughtful coding. If you know and can use something’s concrete type rather than an abstraction, from a performance perspective it’s better to do so rather than hoping the JIT will be able to see through it and devirtualize. To help with this, a new analyzer, CA1859, was added to the .NET SDK in dotnet/roslyn-analyzers#6370. The analyzer looks for places where interfaces or base classes could be replaced by derived types in order to avoid interface and virtual dispatch.
 dotnet/runtime#80335 and dotnet/runtime#80848 rolled this out across dotnet/runtime. As you can see from the first PR in particular, there were hundreds of places identified that with just an edit of one character (e.g. replacing
dotnet/runtime#80335 and dotnet/runtime#80848 rolled this out across dotnet/runtime. As you can see from the first PR in particular, there were hundreds of places identified that with just an edit of one character (e.g. replacing IList<T> with List<T>), we could possibly reduce overheads.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Environments;
using BenchmarkDotNet.Jobs;
using BenchmarkDotNet.Running;
var config = DefaultConfig.Instance
.AddJob(Job.Default.WithId("No PGO").WithRuntime(CoreRuntime.Core80).WithEnvironmentVariable("DOTNET_TieredPGO", "0"))
.AddJob(Job.Default.WithId("PGO").WithRuntime(CoreRuntime.Core80));
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args, config);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "EnvironmentVariables")]
public class Tests
{
private readonly IList<int> _ilist = new List<int>();
private readonly List<int> _list = new();
[Benchmark]
public void IList()
{
_ilist.Add(42);
_ilist.Clear();
}
[Benchmark]
public void List()
{
_list.Add(42);
_list.Clear();
}
}| Method | Job | Mean |
|---|---|---|
| IList | No PGO | 2.876 ns |
| IList | PGO | 1.777 ns |
| List | No PGO | 1.718 ns |
| List | PGO | 1.476 ns |
Vectorization
Another huge area of investment in code generation in .NET 8 is around vectorization. This is a continuation of a theme that’s been going for multiple .NET releases. Almost a decade ago, .NET gained the Vector<T> type. .NET Core 3.0 and .NET 5 added thousands of intrinsic methods for directly targeting specific hardware instructions. .NET 7 provided hundreds of cross-platform operations for Vector128<T> and Vector256<T> to enable SIMD algorithms on fixed-width vectors. And now in .NET 8, .NET gains support for AVX512, both with new hardware intrinsics directly exposing AVX512 instructions and with the new Vector512 and Vector512<T> types.
There were a plethora of changes that went into improving existing SIMD support, such as dotnet/runtime#76221 that improves the handling of Vector256<T> when it’s not hardware accelerated by lowering it as two Vector128<T> operations. Or like dotnet/runtime#87283, which removed the generic constraint on the T in all of the vector types in order to make them easier to use in a larger set of contexts. But the bulk of the work in this area in this release is focused on AVX512.
Wikipedia has a good overview of AVX512, which provides instructions for processing 512-bits at a time. In addition to providing wider versions of the 256-bit instructions seen in previous instruction sets, it also adds a variety of new operations, almost all of which are exposed via one of the new types in System.Runtime.Intrinsics.X86, like Avx512BW, AVX512CD, Avx512DQ, Avx512F, and Avx512Vbmi. dotnet/runtime#83040 kicked things off by stubbing out the various files, followed by dozens of PRs that filled in the functionality, for example dotnet/runtime#84909 that added the 512-bit variants of the SSE through SSE4.2 intrinsics that already exist; like dotnet/runtime#75934 from @DeepakRajendrakumaran and dotnet/runtime#77419 from @DeepakRajendrakumaran that added support for the EVEX encoding used by AVX512 instructions; like dotnet/runtime#74113 from @DeepakRajendrakumaran that added the logic for detecting AVX512 support; like dotnet/runtime#80960 from @DeepakRajendrakumaran and dotnet/runtime#79544 from @anthonycanino that enlightened the register allocator and emitter about AVX512’s additional registers; and like dotnet/runtime#87946 from @Ruihan-Yin and dotnet/runtime#84937 from @jkrishnavs that plumbed through knowledge of various intrinsics.
Let’s take it for a spin. The machine on which I’m writing this doesn’t have AVX512 support, but my Dev Box does, so I’m using that for AVX512 comparisons (using WSL with Ubuntu). In last year’s Performance Improvements in .NET 7, we wrote a Contains method that used Vector256<T> if there was sufficient data available and it was accelerated, or else Vector128<T> if there was sufficient data available and it was accelerated, or else a scalar fallback. Tweaking that to also “light up” with AVX512 took me literally less than 30 seconds: copy/paste the code block for Vector256 and then search and replace in that copy from “Vector256” to “Vector512″… boom, done. Here it is in a benchmark, using environment variables to disable the JIT’s ability to use the various instruction sets so that we can try out this method with each acceleration path:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Jobs;
using BenchmarkDotNet.Running;
using System.Runtime.CompilerServices;
using System.Runtime.InteropServices;
using System.Runtime.Intrinsics;
var config = DefaultConfig.Instance
.AddJob(Job.Default.WithId("Scalar").WithEnvironmentVariable("DOTNET_EnableHWIntrinsic", "0").AsBaseline())
.AddJob(Job.Default.WithId("Vector128").WithEnvironmentVariable("DOTNET_EnableAVX2", "0").WithEnvironmentVariable("DOTNET_EnableAVX512F", "0"))
.AddJob(Job.Default.WithId("Vector256").WithEnvironmentVariable("DOTNET_EnableAVX512F", "0"))
.AddJob(Job.Default.WithId("Vector512"));
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args, config);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "EnvironmentVariables", "value")]
public class Tests
{
private readonly byte[] _data = Enumerable.Repeat((byte)123, 999).Append((byte)42).ToArray();
[Benchmark]
[Arguments((byte)42)]
public bool Find(byte value) => Contains(_data, value);
private static unsafe bool Contains(ReadOnlySpan<byte> haystack, byte needle)
{
if (Vector128.IsHardwareAccelerated && haystack.Length >= Vector128<byte>.Count)
{
ref byte current = ref MemoryMarshal.GetReference(haystack);
if (Vector512.IsHardwareAccelerated && haystack.Length >= Vector512<byte>.Count)
{
Vector512<byte> target = Vector512.Create(needle);
ref byte endMinusOneVector = ref Unsafe.Add(ref current, haystack.Length - Vector512<byte>.Count);
do
{
if (Vector512.EqualsAny(target, Vector512.LoadUnsafe(ref current)))
return true;
current = ref Unsafe.Add(ref current, Vector512<byte>.Count);
}
while (Unsafe.IsAddressLessThan(ref current, ref endMinusOneVector));
if (Vector512.EqualsAny(target, Vector512.LoadUnsafe(ref endMinusOneVector)))
return true;
}
else if (Vector256.IsHardwareAccelerated && haystack.Length >= Vector256<byte>.Count)
{
Vector256<byte> target = Vector256.Create(needle);
ref byte endMinusOneVector = ref Unsafe.Add(ref current, haystack.Length - Vector256<byte>.Count);
do
{
if (Vector256.EqualsAny(target, Vector256.LoadUnsafe(ref current)))
return true;
current = ref Unsafe.Add(ref current, Vector256<byte>.Count);
}
while (Unsafe.IsAddressLessThan(ref current, ref endMinusOneVector));
if (Vector256.EqualsAny(target, Vector256.LoadUnsafe(ref endMinusOneVector)))
return true;
}
else
{
Vector128<byte> target = Vector128.Create(needle);
ref byte endMinusOneVector = ref Unsafe.Add(ref current, haystack.Length - Vector128<byte>.Count);
do
{
if (Vector128.EqualsAny(target, Vector128.LoadUnsafe(ref current)))
return true;
current = ref Unsafe.Add(ref current, Vector128<byte>.Count);
}
while (Unsafe.IsAddressLessThan(ref current, ref endMinusOneVector));
if (Vector128.EqualsAny(target, Vector128.LoadUnsafe(ref endMinusOneVector)))
return true;
}
}
else
{
for (int i = 0; i < haystack.Length; i++)
if (haystack[i] == needle)
return true;
}
return false;
}
}| Method | Job | Mean | Ratio |
|---|---|---|---|
| Find | Scalar | 461.49 ns | 1.00 |
| Find | Vector128 | 37.94 ns | 0.08 |
| Find | Vector256 | 22.98 ns | 0.05 |
| Find | Vector512 | 10.93 ns | 0.02 |
Numerous PRs elsewhere in the JIT then take advantage of AVX512 support when it’s available. For example, separate from AVX512, dotnet/runtime#83945 and dotnet/runtime#84530 taught the JIT how to unroll SequenceEqual operations, such that the JIT can emit optimized, vectorized replacements when it can see a constant length for at least one of the inputs. “Unrolling” means that rather than emitting a loop for N iterations, each of which does the loop body once, a loop is emitted for N / M iterations, where every iteration does the loop body M times (and if N == M, there is no loop at all). So for a benchmark like this:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
private byte[] _scheme = "Transfer-Encoding"u8.ToArray();
[Benchmark]
public bool SequenceEqual() => "Transfer-Encoding"u8.SequenceEqual(_scheme);
}we now get results like this:
| Method | Runtime | Mean | Ratio | Code Size |
|---|---|---|---|---|
| SequenceEqual | .NET 7.0 | 3.0558 ns | 1.00 | 65 B |
| SequenceEqual | .NET 8.0 | 0.8055 ns | 0.26 | 91 B |
For .NET 7, we see assembly code like this (note the call instruction to the underlying SequenceEqual helper):
; Tests.SequenceEqual()
sub rsp,28
mov r8,1D7BB272E48
mov rcx,[rcx+8]
test rcx,rcx
je short M00_L03
lea rdx,[rcx+10]
mov eax,[rcx+8]
M00_L00:
mov rcx,r8
cmp eax,11
je short M00_L02
xor eax,eax
M00_L01:
add rsp,28
ret
M00_L02:
mov r8d,11
call qword ptr [7FF9D33CF120]; System.SpanHelpers.SequenceEqual(Byte ByRef, Byte ByRef, UIntPtr)
jmp short M00_L01
M00_L03:
xor edx,edx
xor eax,eax
jmp short M00_L00
; Total bytes of code 65And now for .NET 8, we get assembly code like this:
; Tests.SequenceEqual()
vzeroupper
mov rax,1EBDDA92D38
mov rcx,[rcx+8]
test rcx,rcx
je short M00_L01
lea rdx,[rcx+10]
mov r8d,[rcx+8]
M00_L00:
cmp r8d,11
jne short M00_L03
vmovups xmm0,[rax]
vmovups xmm1,[rdx]
vmovups xmm2,[rax+1]
vmovups xmm3,[rdx+1]
vpxor xmm0,xmm0,xmm1
vpxor xmm1,xmm2,xmm3
vpor xmm0,xmm0,xmm1
vptest xmm0,xmm0
sete al
movzx eax,al
jmp short M00_L02
M00_L01:
xor edx,edx
xor r8d,r8d
jmp short M00_L00
M00_L02:
ret
M00_L03:
xor eax,eax
jmp short M00_L02
; Total bytes of code 91Now there’s no call, with the entire implementation provided by the JIT; we can see it making liberal use of the 128-bit xmm SIMD registers. However, those PRs only enabled the JIT to handle up to 64 bytes being compared (unrolling results in larger code, so at some length it no longer makes sense to unroll). With AVX512 support in the JIT, dotnet/runtime#84854 then extends that up to 128 bytes. This is easily visible in a benchmark like this, which is similar to the previous example, but with larger data:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
private byte[] _data1, _data2;
[GlobalSetup]
public void Setup()
{
_data1 = Enumerable.Repeat((byte)42, 200).ToArray();
_data2 = (byte[])_data1.Clone();
}
[Benchmark]
public bool SequenceEqual() => _data1.AsSpan(0, 128).SequenceEqual(_data2.AsSpan(128));
}On my Dev Box with AVX512 support, for .NET 8 we get:
; Tests.SequenceEqual()
sub rsp,28
vzeroupper
mov rax,[rcx+8]
test rax,rax
je short M00_L01
cmp dword ptr [rax+8],80
jb short M00_L01
add rax,10
mov rcx,[rcx+10]
test rcx,rcx
je short M00_L01
mov edx,[rcx+8]
cmp edx,80
jb short M00_L01
add rcx,10
add rcx,80
add edx,0FFFFFF80
cmp edx,80
je short M00_L02
xor eax,eax
M00_L00:
vzeroupper
add rsp,28
ret
M00_L01:
call qword ptr [7FF820745F08]
int 3
M00_L02:
vmovups zmm0,[rax]
vmovups zmm1,[rcx]
vmovups zmm2,[rax+40]
vmovups zmm3,[rcx+40]
vpxorq zmm0,zmm0,zmm1
vpxorq zmm1,zmm2,zmm3
vporq zmm0,zmm0,zmm1
vxorps ymm1,ymm1,ymm1
vpcmpeqq k1,zmm0,zmm1
kortestb k1,k1
setb al
movzx eax,al
jmp short M00_L00
; Total bytes of code 154Now instead of the 128-bit xmm registers, we see use of the 512-bit zmm registers from AVX512.
The JIT in .NET 8 also now unrolls memmoves (CopyTo, ToArray, etc.) for small-enough constant lengths, thanks to dotnet/runtime#83638 and dotnet/runtime#83740. And then with dotnet/runtime#84348 that unrolling takes advantage of AVX512 if it’s available. dotnet/runtime#85501 extends this to Span<T>.Fill, too.
dotnet/runtime#84885 extended the unrolling and vectorization done as part of string/ReadOnlySpan<char> Equals and StartsWith to utilize AVX512 when available, as well.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
private readonly string _str = "Let me not to the marriage of true minds admit impediments";
[Benchmark]
public bool Equals() => _str.AsSpan().Equals(
"LET ME NOT TO THE MARRIAGE OF TRUE MINDS ADMIT IMPEDIMENTS",
StringComparison.OrdinalIgnoreCase);
}| Method | Runtime | Mean | Ratio | Code Size |
|---|---|---|---|---|
| Equals | .NET 7.0 | 30.995 ns | 1.00 | 101 B |
| Equals | .NET 8.0 | 1.658 ns | 0.05 | 116 B |
It’s so fast in .NET 8 because, whereas with .NET 7 it ends up calling through to the underlying helper:
; Tests.Equals()
sub rsp,48
xor eax,eax
mov [rsp+28],rax
vxorps xmm4,xmm4,xmm4
vmovdqa xmmword ptr [rsp+30],xmm4
mov [rsp+40],rax
mov rcx,[rcx+8]
test rcx,rcx
je short M00_L03
lea rdx,[rcx+0C]
mov ecx,[rcx+8]
M00_L00:
mov r8,21E57C058A0
mov r8,[r8]
add r8,0C
cmp ecx,3A
jne short M00_L02
mov rcx,rdx
mov rdx,r8
mov r8d,3A
call qword ptr [7FF8194B1A08]; System.Globalization.Ordinal.EqualsIgnoreCase(Char ByRef, Char ByRef, Int32)
M00_L01:
nop
add rsp,48
ret
M00_L02:
xor eax,eax
jmp short M00_L01
M00_L03:
xor ecx,ecx
xor edx,edx
xchg rcx,rdx
jmp short M00_L00
; Total bytes of code 101in .NET 8, the JIT generates code for the operation directly, taking advantage of AVX512’s greater width and thus able to process a larger input without significantly increasing code size:
; Tests.Equals()
vzeroupper
mov rax,[rcx+8]
test rax,rax
jne short M00_L00
xor ecx,ecx
xor edx,edx
jmp short M00_L01
M00_L00:
lea rcx,[rax+0C]
mov edx,[rax+8]
M00_L01:
cmp edx,3A
jne short M00_L02
vmovups zmm0,[rcx]
vmovups zmm1,[7FF820495080]
vpternlogq zmm0,zmm1,[7FF8204950C0],56
vmovups zmm1,[rcx+34]
vporq zmm1,zmm1,[7FF820495100]
vpternlogq zmm0,zmm1,[7FF820495140],0F6
vxorps ymm1,ymm1,ymm1
vpcmpeqq k1,zmm0,zmm1
kortestb k1,k1
setb al
movzx eax,al
jmp short M00_L03
M00_L02:
xor eax,eax
M00_L03:
vzeroupper
ret
; Total bytes of code 116Even super simple operations get in on the action. Here we just have a cast from a ulong to a double:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "val")]
[DisassemblyDiagnoser]
public class Tests
{
[Benchmark]
[Arguments(1234567891011121314ul)]
public double UIntToDouble(ulong val) => val;
}Thanks to dotnet/runtime#84384 from @khushal1996, the code for that shrinks from this:
; Tests.UIntToDouble(UInt64)
vzeroupper
vxorps xmm0,xmm0,xmm0
vcvtsi2sd xmm0,xmm0,rdx
test rdx,rdx
jge short M00_L00
vaddsd xmm0,xmm0,qword ptr [7FF819E776C0]
M00_L00:
ret
; Total bytes of code 26using the AVX vcvtsi2sd instruction, to this:
; Tests.UIntToDouble(UInt64)
vzeroupper
vcvtusi2sd xmm0,xmm0,rdx
ret
; Total bytes of code 10using the AVX512 vcvtusi2sd instruction.
As yet another example, with dotnet/runtime#87641 we see the JIT using AVX512 to accelerate various Math APIs:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "left", "right")]
public class Tests
{
[Benchmark]
[Arguments(123456.789f, 23456.7890f)]
public float Max(float left, float right) => MathF.Max(left, right);
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Max | .NET 7.0 | 1.1936 ns | 1.00 |
| Max | .NET 8.0 | 0.2865 ns | 0.24 |
Branching
Branching is integral to all meaningful code; while some algorithms are written in a branch-free manner, branch-free algorithms typically are challenging to get right and complicated to read, and typically are isolated to only small regions of code. For everything else, branching is the name of the game. Loops, if/else blocks, ternaries… it’s hard to imagine any real code without them. Yet they can also represent one of the more significant costs in an application. Modern hardware gets big speed boosts from pipelining, for example from being able to start reading and decoding the next instruction while the previous ones are still processing. That, of course, relies on the hardware knowing what the next instruction is. If there’s no branching, that’s easy, it’s whatever instruction comes next in the sequence. For when there is branching, CPUs have built-in support in the form of branch predictors, used to determine what the next instruction most likely will be, and they’re often right… but when they’re wrong, the cost incurred from that incorrect branch prediction can be huge. Compilers thus strive to minimize branching.
One way the impact of branches is reduced is by removing them completely. Redundant branch optimizers look for places where the compiler can prove that all paths leading to that branch will lead to the same outcome, such that the compiler can remove the branch and everything in the path not taken. Consider the following example:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Runtime.CompilerServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
private static readonly Random s_rand = new();
private readonly string _text = "hello world!";
[Params(1.0, 0.5)]
public double Probability { get; set; }
[Benchmark]
public ReadOnlySpan<char> TrySlice() => SliceOrDefault(_text.AsSpan(), s_rand.NextDouble() < Probability ? 3 : 20);
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public ReadOnlySpan<char> SliceOrDefault(ReadOnlySpan<char> span, int i)
{
if ((uint)i < (uint)span.Length)
{
return span.Slice(i);
}
return default;
}
}Running that on .NET 7, we can glimpse into the impact of failed branch prediction. When we always take the branch the same way, the throughput is 2.5x what it was when it was impossible for the branch predictor to determine where we were going next:
| Method | Probability | Mean | Code Size |
|---|---|---|---|
| TrySlice | 0.5 | 8.845 ns | 136 B |
| TrySlice | 1 | 3.436 ns | 136 B |
We can also use this example for a .NET 8 improvement. That guarded ReadOnlySpan<char>.Slice call has its own branch to ensure that i is within the bounds of the span; we can see that very clearly by looking at the disassembly generated on .NET 7:
; Tests.TrySlice()
push rdi
push rsi
push rbp
push rbx
sub rsp,28
vzeroupper
mov rdi,rcx
mov rsi,rdx
mov rcx,[rdi+8]
test rcx,rcx
je short M00_L01
lea rbx,[rcx+0C]
mov ebp,[rcx+8]
M00_L00:
mov rcx,1EBBFC01FA0
mov rcx,[rcx]
mov rcx,[rcx+8]
mov rax,[rcx]
mov rax,[rax+48]
call qword ptr [rax+20]
vmovsd xmm1,qword ptr [rdi+10]
vucomisd xmm1,xmm0
ja short M00_L02
mov eax,14
jmp short M00_L03
M00_L01:
xor ebx,ebx
xor ebp,ebp
jmp short M00_L00
M00_L02:
mov eax,3
M00_L03:
cmp eax,ebp
jae short M00_L04
cmp eax,ebp
ja short M00_L06
mov edx,eax
lea rdx,[rbx+rdx*2]
sub ebp,eax
jmp short M00_L05
M00_L04:
xor edx,edx
xor ebp,ebp
M00_L05:
mov [rsi],rdx
mov [rsi+8],ebp
mov rax,rsi
add rsp,28
pop rbx
pop rbp
pop rsi
pop rdi
ret
M00_L06:
call qword ptr [7FF999FEB498]
int 3
; Total bytes of code 136In particular, look at M00_L03:
M00_L03:
cmp eax,ebp
jae short M00_L04
cmp eax,ebp
ja short M00_L06
mov edx,eax
lea rdx,[rbx+rdx*2]At this point, either 3 or 20 (0x14) has been loaded into eax, and it’s being compared against ebp, which was loaded from the span’s Length earlier (mov ebp,[rcx+8]). There’s a very obvious redundant branch here, as the code does cmp eax,ebp, and then if it doesn’t jump as part of the jae, it does the exact same comparison again; the first is the one we wrote in TrySlice, the second is the one from Slice itself, which got inlined.
On .NET 8, thanks to dotnet/runtime#72979 and dotnet/runtime#75804, that branch (and many others of a similar ilk) is optimized away. We can run the exact same benchmark, this time on .NET 8, and if we look at the assembly at the corresponding code block (which isn’t numbered exactly the same because of other changes):
M00_L04:
cmp eax,ebp
jae short M00_L07
mov ecx,eax
lea rdx,[rdi+rcx*2]we can see that, indeed, the redundant branch has been eliminated.
Another way the overhead associated with branches (and branch misprediction) is removed is by avoiding them altogether. Sometimes simple bit manipulation tricks can be employed to avoid branches. dotnet/runtime#62689 from @pedrobsaila, for example, finds expressions like i >= 0 && j >= 0 for signed integers i and j, and rewrites them to the equivalent of (i | j) >= 0.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "i", "j")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
[Benchmark]
[Arguments(42, 84)]
public bool BothGreaterThanOrEqualZero(int i, int j) => i >= 0 && j >= 0;
}Here instead of code like we’d get on .NET 7, which involves a branch for the &&:
; Tests.BothGreaterThanOrEqualZero(Int32, Int32)
test edx,edx
jl short M00_L00
mov eax,r8d
not eax
shr eax,1F
ret
M00_L00:
xor eax,eax
ret
; Total bytes of code 16now on .NET 8, the result is branchless:
; Tests.BothGreaterThanOrEqualZero(Int32, Int32)
or edx,r8d
mov eax,edx
not eax
shr eax,1F
ret
; Total bytes of code 11Such bit tricks, however, only get you so far. To go further, both x86/64 and Arm provide conditional move instructions, like cmov on x86/64 and csel on Arm, that encapsulate the condition into the single instruction. For example, csel “conditionally selects” the value from one of two register arguments based on whether the condition is true or false and writes that value into the destination register. The instruction pipeline stays filled then because the instruction after the csel is always the next instruction; there’s no control flow that would result in a different instruction coming next.
The JIT in .NET 8 is now capable of emitting conditional instructions, on both x86/64 and Arm. With PRs like dotnet/runtime#73472 from @a74nh and dotnet/runtime#77728 from @a74nh, the JIT gains an additional “if conversion” optimization phase, where various conditional patterns are recognized and morphed into conditional nodes in the JIT’s internal representation; these can then later be emitted as conditional instructions, as was done by dotnet/runtime#78879, dotnet/runtime#81267, dotnet/runtime#82235, dotnet/runtime#82766, and dotnet/runtime#83089. Other PRs, like dotnet/runtime#84926 from @SwapnilGaikwad and dotnet/runtime#82031 from @SwapnilGaikwad optimized which exact instructions would be employed, in these cases using the Arm cinv and cinc instructions.
We can see all this in a simple benchmark:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
private static readonly Random s_rand = new();
[Params(1.0, 0.5)]
public double Probability { get; set; }
[Benchmark]
public FileOptions GetOptions() => GetOptions(s_rand.NextDouble() < Probability);
private static FileOptions GetOptions(bool useAsync) => useAsync ? FileOptions.Asynchronous : FileOptions.None;
}| Method | Runtime | Probability | Mean | Ratio | Code Size |
|---|---|---|---|---|---|
| GetOptions | .NET 7.0 | 0.5 | 7.952 ns | 1.00 | 64 B |
| GetOptions | .NET 8.0 | 0.5 | 2.327 ns | 0.29 | 86 B |
| GetOptions | .NET 7.0 | 1 | 2.587 ns | 1.00 | 64 B |
| GetOptions | .NET 8.0 | 1 | 2.357 ns | 0.91 | 86 B |
Two things to notice:
- In .NET 7, the cost with a probability of 0.5 is 3x that of when it had a probability of 1.0, due to the branch predictor not being able to successfully predict which way the actual branch would go.
- In .NET 8, it doesn’t matter whether the probability is 0.5 or 1: the cost is the same (and cheaper than on .NET 7).
We can also look at the generated assembly to see the difference. In particular, on .NET 8, we see this for the generated assembly:
; Tests.GetOptions()
push rbx
sub rsp,20
vzeroupper
mov rbx,rcx
mov rcx,2C54EC01E40
mov rcx,[rcx]
mov rcx,[rcx+8]
mov rax,offset MT_System.Random+XoshiroImpl
cmp [rcx],rax
jne short M00_L01
call qword ptr [7FFA2D790C88]; System.Random+XoshiroImpl.NextDouble()
M00_L00:
vmovsd xmm1,qword ptr [rbx+8]
mov eax,40000000
xor ecx,ecx
vucomisd xmm1,xmm0
cmovbe eax,ecx
add rsp,20
pop rbx
ret
M00_L01:
mov rax,[rcx]
mov rax,[rax+48]
call qword ptr [rax+20]
jmp short M00_L00
; Total bytes of code 86That vucomisd; cmovbe sequence in there is the comparison between the randomly-generated floating-point value and the probability threshold followed by the conditional move (“conditionally move if below or equal”).
There are many methods that implicitly benefit from these transformations. Take even a simple method, like Math.Max, whose code I’ve copied here:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Runtime.CompilerServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser]
public class Tests
{
[Benchmark]
public int Max() => Max(1, 2);
[MethodImpl(MethodImplOptions.NoInlining)]
public static int Max(int val1, int val2)
{
return (val1 >= val2) ? val1 : val2;
}
}That pattern should look familiar. Here’s the assembly we get on .NET 7:
; Tests.Max(Int32, Int32)
cmp ecx,edx
jge short M01_L00
mov eax,edx
ret
M01_L00:
mov eax,ecx
ret
; Total bytes of code 10The two arguments come in via the ecx and edx registers. They’re compared, and if the first argument is greater than or equal to the second, it jumps down to the bottom where the first argument is moved into eax as the return value; if it wasn’t, then the second value is moved into eax. And on .NET 8:
; Tests.Max(Int32, Int32)
cmp ecx,edx
mov eax,edx
cmovge eax,ecx
ret
; Total bytes of code 8Again the two arguments come in via the ecx and edx registers, and they’re compared. The second argument is then moved into eax as the return value. If the comparison showed that the first argument was greater than the second, it’s then moved into eax (overwriting the second argument that was just moved there). Fun.
Note if you ever find yourself wanting to do a deeper-dive into this area, BenchmarkDotNet has some excellent additional tools at your disposal. On Windows, it enables you to collect hardware counters, which expose a wealth of information about how things actually executed on the hardware, whether it be number of instructions retired, cache misses, or branch mispredictions. To use it, add another package reference to your .csproj:
<PackageReference Include="BenchmarkDotNet.Diagnostics.Windows" Version="0.13.8" />and add an additional attribute to your tests class:
[HardwareCounters(HardwareCounter.BranchMispredictions, HardwareCounter.BranchInstructions)]Then make sure you’re running the benchmarks from an elevated / admin terminal. When I do that, now I see this:
| Method | Runtime | Probability | Mean | Ratio | BranchMispredictions/Op | BranchInstructions/Op |
|---|---|---|---|---|---|---|
| GetOptions | .NET 7.0 | 0.5 | 8.585 ns | 1.00 | 1 | 5 |
| GetOptions | .NET 8.0 | 0.5 | 2.488 ns | 0.29 | 0 | 4 |
| GetOptions | .NET 7.0 | 1 | 2.783 ns | 1.00 | 0 | 4 |
| GetOptions | .NET 8.0 | 1 | 2.531 ns | 0.91 | 0 | 4 |
We can see it confirms what we already knew: on .NET 7 with a 0.5 probability, it ends up mispredicting a branch.
The C# compiler (aka “Roslyn”) also gets in on the branch-elimination game in .NET 8, for a very specific kind of branch. In .NET, while we think of System.Boolean as only being a two-value type (false and true), sizeof(bool) is actually one byte. That means a bool can technically have 256 different values, where 0 is considered false and [1,255] are all considered true. Thankfully, unless a developer is poking around the edges of interop or otherwise using unsafe code to purposefully manipulate these other values, developers can remain blissfully unaware of the actual numeric value here, for two reasons. First, C# doesn’t consider bool to be a numerical type, and thus you can’t perform arithmetic on it or cast it to a type like int. Second, all of the bools produced by the runtime and C# are normalized to actually be 0 or 1 in value, e.g. a cmp IL instruction is documented as “If value1 is greater than value2, 1 is pushed onto the stack; otherwise 0 is pushed onto the stack.” There is a class of algorithms, however, where being able to rely on such 0 and 1 values is handy, and we were just talking about them: branch-free algorithms.
Let’s say we didn’t have the JIT’s new-found ability to use conditional moves and we wanted to write our own ConditionalSelect method for integers:
static int ConditionalSelect(bool condition, int whenTrue, int whenFalse);If we could rely on bool always being 0 or 1 (we can’t), and if we could do arithmetic on a bool (we can’t), then we could use the behavior of multiplication to implement our ConditionalSelect function. Anything multiplied by 0 is 0, and anything multiplied by 1 is itself, so we could write our ConditionalSelect like this:
// pseudo-code; this won't compile!
static int ConditionalSelect(bool condition, int whenTrue, int whenFalse) =>
(whenTrue * condition) +
(whenFalse * !condition);Then if condition is 1, whenTrue * condition would be whenTrue and whenFalse * !condition would be 0, such that the whole expression would evaluate to whenTrue. And, conversely, if condition is 0, whenTrue * condition would be 0 and whenFalse * !condition would be whenFalse, such that the whole expression would evaluate to whenFalse. As noted, though, we can’t write the above, but we could write this:
static int ConditionalSelect(bool condition, int whenTrue, int whenFalse) =>
(whenTrue * (condition ? 1 : 0)) +
(whenFalse * (condition ? 0 : 1));That provides the exact semantics we want… but we’ve introduced two branches into our supposedly branch-free algorithm. This is the IL produced for that ConditionalSelect in .NET 7:
.method private hidebysig static int32 ConditionalSelect (bool condition, int32 whenTrue, int32 whenFalse) cil managed
{
.maxstack 8
IL_0000: ldarg.1
IL_0001: ldarg.0
IL_0002: brtrue.s IL_0007
IL_0004: ldc.i4.0
IL_0005: br.s IL_0008
IL_0007: ldc.i4.1
IL_0008: mul
IL_0009: ldarg.2
IL_000a: ldarg.0
IL_000b: brtrue.s IL_0010
IL_000d: ldc.i4.1
IL_000e: br.s IL_0011
IL_0010: ldc.i4.0
IL_0011: mul
IL_0012: add
IL_0013: ret
}Note all those brtrue.s and br.s instructions in there. Are they necessary, though? Earlier I noted that the runtime will only produce bools with a value of 0 or 1. And thanks to dotnet/roslyn#67191, the C# compiler now recognizes that and optimizes the pattern (b ? 1 : 0) to be branchless. Our same ConditionalSelect function now in .NET 8 compiles to this:
.method private hidebysig static int32 ConditionalSelect (bool condition, int32 whenTrue, int32 whenFalse) cil managed
{
.maxstack 8
IL_0000: ldarg.1
IL_0001: ldarg.0
IL_0002: ldc.i4.0
IL_0003: cgt.un
IL_0005: mul
IL_0006: ldarg.2
IL_0007: ldarg.0
IL_0008: ldc.i4.0
IL_0009: ceq
IL_000b: mul
IL_000c: add
IL_000d: ret
}Zero branch instructions. Of course, you wouldn’t actually want to write this function like this anymore; just because it’s branch-free doesn’t mean it’s the most efficient. On .NET 8, here’s the assembly code produced by the JIT for the above:
movzx rax, cl
xor ecx, ecx
test eax, eax
setne cl
imul ecx, edx
test eax, eax
sete al
movzx rax, al
imul eax, r8d
add eax, ecx
ret whereas if you just wrote it as:
static int ConditionalSelect(bool condition, int whenTrue, int whenFalse) =>
condition ? whenTrue : whenFalse;here’s what you’d get:
test cl, cl
mov eax, r8d
cmovne eax, edx
ret Even so, this C# compiler optimization is useful for other branch-free algorithms. Let’s say I wanted to write a Compare method that would compare two ints, returning -1 if the first is less than the second, 0 if they’re equal, and 1 if the first is greater than the second. I could write that like this:
static int Compare(int x, int y)
{
if (x < y) return -1;
if (x > y) return 1;
return 0;
}Simple, but every invocation will incur at least one branch, if not two. With the (b ? 1 : 0) optimization, we can instead write it like this:
static int Compare(int x, int y)
{
int gt = (x > y) ? 1 : 0;
int lt = (x < y) ? 1 : 0;
return gt - lt;
}This is now branch-free, with the C# compiler producing:
IL_0000: ldarg.0
IL_0001: ldarg.1
IL_0002: cgt
IL_0004: ldarg.0
IL_0005: ldarg.1
IL_0006: clt
IL_0008: stloc.0
IL_0009: ldloc.0
IL_000a: sub
IL_000b: retand, from that, the JIT producing:
xor eax, eax
cmp ecx, edx
setg al
setl cl
movzx rcx, cl
sub eax, ecx
ret Does that mean that everyone should now be running to rewrite their algorithms in a branch-free manner? Most definitely not. It’s another tool in your tool belt, and in some cases it’s quite beneficial, especially when it can provide more consistent throughput results due to doing the same work regardless of outcome. It’s not always a win, however, and in general it’s best not to try to outsmart the compiler. Take the example we just looked at. There’s a function with that exact implementation in the core libraries: int.CompareTo. And if you look at its implementation in .NET 8, you’ll find that it’s still using the branch-based implementation. Why? Because it often yields better results, in particular in the common case where the operation gets inlined and the JIT is able to combine the branches in the CompareTo method with ones based on processing the result of CompareTo. Most uses of CompareTo involve additional branching based on its result, such as in a quick sort partitioning step that’s deciding whether to move elements. So let’s take an example where code makes a decision based on the result of such a comparison:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser]
public class Tests
{
private int _x = 2, _y = 1;
[Benchmark]
public int GreaterThanOrEqualTo_Branching()
{
if (Compare_Branching(_x, _y) >= 0)
{
return _x * 2;
}
return _y * 3;
}
[Benchmark]
public int GreaterThanOrEqualTo_Branchless()
{
if (Compare_Branchless(_x, _y) >= 0)
{
return _x * 2;
}
return _y * 3;
}
private static int Compare_Branching(int x, int y)
{
if (x < y) return -1;
if (x > y) return 1;
return 0;
}
private static int Compare_Branchless(int x, int y)
{
int gt = (x > y) ? 1 : 0;
int lt = (x < y) ? 1 : 0;
return gt - lt;
}
}And the resulting assembly:
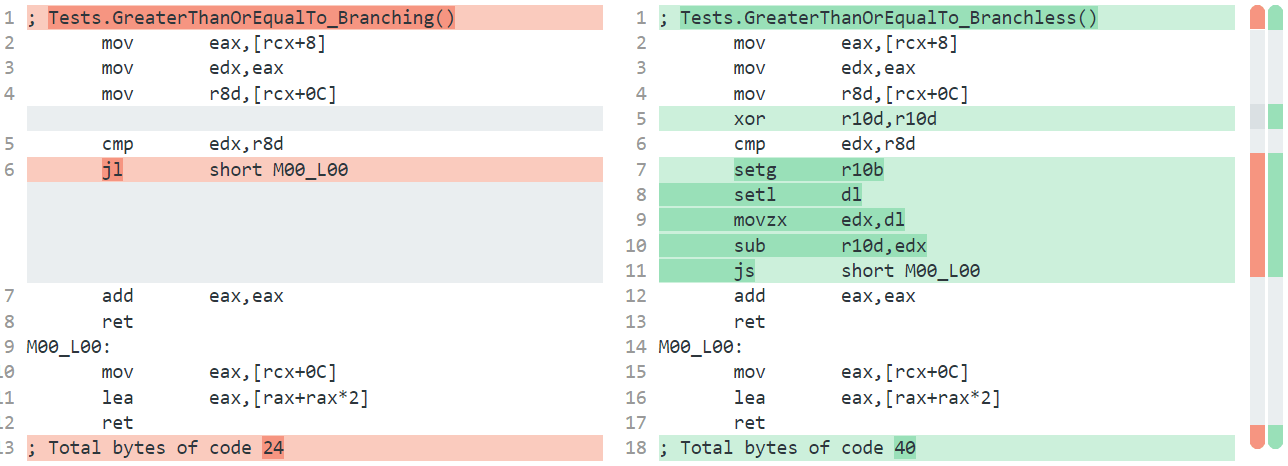
Note that both implementations now have just one branch (a jl in the “branching” case and a js in the “branchless” case), and the “branching” implementation results in less assembly code.
Bounds Checking
Arrays, strings, and spans are all bounds checked by the runtime. That means that indexing into one of these data structures incurs validation to ensure that the index is within the bounds of the data structure. For example, the Get(byte[],int) method here:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Runtime.CompilerServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser]
public class Tests
{
private byte[] _array = new byte[8];
private int _index = 4;
[Benchmark]
public void Get() => Get(_array, _index);
[MethodImpl(MethodImplOptions.NoInlining)]
private static byte Get(byte[] array, int index) => array[index];
}results in this code being generated for the method:
; Tests.Get(Byte[], Int32)
sub rsp,28
cmp edx,[rcx+8]
jae short M01_L00
mov eax,edx
movzx eax,byte ptr [rcx+rax+10]
add rsp,28
ret
M01_L00:
call CORINFO_HELP_RNGCHKFAIL
int 3
; Total bytes of code 27Here, the byte[] is passed in rcx, the int index is in edx, and the code is comparing the value of the index against the value stored at an 8-byte offset from the beginning of the array: that’s where the array’s length is stored. The jae instruction (jump if above or equal) is an unsigned comparison, such that if (uint)index >= (uint)array.Length, it’ll jump to M01_L00, where we see a call to a helper function CORINFO_HELP_RNGCHKFAIL that will throw an IndexOutOfRangeException. All of that is the “bounds check.” The actual access into the array is the two mov and movzx instructions, where the index is moved into eax, and then the value located at rcx (the address of the array) + rax (the index) + 0x10 (the offset of the start of the data in the array) is moved into the return eax register.
It’s the runtime’s responsibility to ensure that all accesses are guaranteed in bounds. It can do so with a bounds check. But it can also do so by proving that the index is always in range, in which case it can elide adding a bounds check that would only add overhead and provide zero benefit. Every .NET release, the JIT improves its ability to recognize patterns that don’t need a bounds check added because there’s no way the access could be out of range. And .NET 8 is no exception, with it learning several new and valuable tricks.
One such trick comes from dotnet/runtime#84231, where it learns how to avoid bounds checks in a pattern that’s very prevalent in collections, in particular in hash tables. In a hash table, you generally compute a hash code for a key and then use that key to index into an array (often referred to as “buckets”). As the hash code might be any int and the buckets array is invariably going to be much smaller than the full range of a 32-bit integer, all of the hash codes need to be mapped down to an element in the array, and a good way to do that is by mod’ing the hash code by the array’s length, e.g.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
private readonly int[] _array = new int[7];
[Benchmark]
public int GetBucket() => GetBucket(_array, 42);
private static int GetBucket(int[] buckets, int hashcode) =>
buckets[(uint)hashcode % buckets.Length];
}In .NET 7, that produces:
; Tests.GetBucket()
sub rsp,28
mov rcx,[rcx+8]
mov eax,2A
mov edx,[rcx+8]
mov r8d,edx
xor edx,edx
idiv r8
cmp rdx,r8
jae short M00_L00
mov eax,[rcx+rdx*4+10]
add rsp,28
ret
M00_L00:
call CORINFO_HELP_RNGCHKFAIL
int 3
; Total bytes of code 44Note the CORINFO_HELP_RNGCHKFAIL, the tell-tale sign of a bounds check. Now in .NET 8, the JIT recognizes that it’s impossible for a uint value %‘d by an array’s length to be out of bounds of that array; either the array’s Length is greater than 0, in which case the result of the % will always be >= 0 and < array.Length, or the Length is 0, and % 0 will throw an exception. As such, it can elide the bounds check:
; Tests.GetBucket()
mov rcx,[rcx+8]
mov eax,2A
mov r8d,[rcx+8]
xor edx,edx
div r8
mov eax,[rcx+rdx*4+10]
ret
; Total bytes of code 23Now consider this:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
private readonly string _s = "\"Hello, World!\"";
[Benchmark]
public bool IsQuoted() => IsQuoted(_s);
private static bool IsQuoted(string s) =>
s.Length >= 2 && s[0] == '"' && s[^1] == '"';
}Our function is checking to see whether the supplied string begins and ends with a quote. It needs to be at least two characters long, and the first and last characters need to be quotes (s[^1] is shorthand for and expanded by the C# compiler into the equivalent of s[s.Length - 1]). Here’s the .NET 7 assembly:
; Tests.IsQuoted(System.String)
sub rsp,28
mov eax,[rcx+8]
cmp eax,2
jl short M01_L00
cmp word ptr [rcx+0C],22
jne short M01_L00
lea edx,[rax-1]
cmp edx,eax
jae short M01_L01
mov eax,edx
cmp word ptr [rcx+rax*2+0C],22
sete al
movzx eax,al
add rsp,28
ret
M01_L00:
xor eax,eax
add rsp,28
ret
M01_L01:
call CORINFO_HELP_RNGCHKFAIL
int 3
; Total bytes of code 58Note that our function is indexing into the string twice, and the assembly does have a call CORINFO_HELP_RNGCHKFAIL at the end of the method, but there’s only one jae referring to the location of that call. That’s because the JIT already knows to avoid the bounds check on the s[0] access: it sees that it’s already been verified that the string’s Length >= 2, so it’s safe to index without a bounds check into any index <= 2. But, we do still have the bounds check for the s[s.Length - 1]. Now in .NET 8, we get this:
; Tests.IsQuoted(System.String)
mov eax,[rcx+8]
cmp eax,2
jl short M01_L00
cmp word ptr [rcx+0C],22
jne short M01_L00
dec eax
cmp word ptr [rcx+rax*2+0C],22
sete al
movzx eax,al
ret
M01_L00:
xor eax,eax
ret
; Total bytes of code 33Note the distinct lack of the call CORINFO_HELP_RNGCHKFAIL; no more bounds checks. Not only did the JIT recognize that s[0] is safe because s.Length >= 2, thanks to dotnet/runtime#84213 it also recognized that since s.Length >= 2, s.Length - 1 is >= 0 and < s.Length, which means it’s in-bounds and thus no range check is needed.
Constant Folding
Another important operation employed by compilers is constant folding (and the closely related constant propagation). Constant folding is just a fancy name for a compiler evaluating expressions at compile-time, e.g. if you have 2 * 3, rather than emitting a multiplication instruction, it can just do the multiplication at compile-time and substitute 6. Constant propagation is then the act of taking that new constant and using it anywhere this expression’s result feeds, e.g. if you have:
int a = 2 * 3;
int b = a * 4;a compiler can instead pretend it was:
int a = 6;
int b = 24;I bring this up here, after we just talked about bounds-check elimination, because there are scenarios where constant folding and bounds check elimination go hand-in-hand. If we can determine a data structure’s length at compile-time, and we can determine an index at a compile-time, then also at compile-time we can determine whether the index is in bounds and avoid the bounds check. We can also take it further: if we can determine not only the data structure’s length but also its contents, then we can do the indexing at compile-time and substitute the value from the data structure.
Consider this example, which is similar in nature to the kind of code types often have in their ToString or TryFormat implementations:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Runtime.CompilerServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser]
public class Tests
{
[Benchmark]
[Arguments(42)]
public string Format(int value) => Format(value, "B");
[MethodImpl(MethodImplOptions.AggressiveInlining)]
static string Format(int value, ReadOnlySpan<char> format)
{
if (format.Length == 1)
{
switch (format[0] | 0x20)
{
case 'd': return DecimalFormat(value);
case 'x': return HexFormat(value);
case 'b': return BinaryFormat(value);
}
}
return FallbackFormat(value, format);
}
[MethodImpl(MethodImplOptions.NoInlining)] private static string DecimalFormat(int value) => null;
[MethodImpl(MethodImplOptions.NoInlining)] private static string HexFormat(int value) => null;
[MethodImpl(MethodImplOptions.NoInlining)] private static string BinaryFormat(int value) => null;
[MethodImpl(MethodImplOptions.NoInlining)] private static string FallbackFormat(int value, ReadOnlySpan<char> format) => null;
}We have a Format(int value, ReadOnlySpan<char> format) method for formatting the int value according to the specified format. The call site is explicit about the format to use, as many such call sites are, explicitly passing "B" here. The implementation is then special-casing formats that are one-character long and match in an ignore-case manner against one of three known formats (it’s using an ASCII trick based on the values of the lowercase letters being one bit different from their uppercase counterparts, such that OR‘ing an uppercase ASCII letter with 0x20 lowercases it). If we look at the assembly generated for this method in .NET 7, we get this:
; Tests.Format(Int32)
sub rsp,38
xor eax,eax
mov [rsp+28],rax
mov ecx,edx
mov rax,251C4801418
mov rax,[rax]
add rax,0C
movzx edx,word ptr [rax]
or edx,20
cmp edx,62
je short M00_L01
cmp edx,64
je short M00_L00;
cmp edx,78
jne short M00_L02
call qword ptr [7FFF3DD47918]; Tests.HexFormat(Int32)
jmp short M00_L03
M00_L00:
call qword ptr [7FFF3DD47900]; Tests.DecimalFormat(Int32)
jmp short M00_L03
M00_L01:
call qword ptr [7FFF3DD47930]; Tests.BinaryFormat(Int32)
jmp short M00_L03
M00_L02:
mov [rsp+28],rax
mov dword ptr [rsp+30],1
lea rdx,[rsp+28]
call qword ptr [7FFF3DD47948]; Tests.FallbackFormat
M00_L03:
nop
add rsp,38
ret
; Total bytes of code 105We can see the code here from Format(Int32, ReadOnlySpan<char>) but this is the code for Format(Int32), so the callee was successfully inlined. We also don’t see any code for the format.Length == 1 (the first cmp is part of the switch), nor do we see any signs of a bounds check (there’s no call CORINFO_HELP_RNGCHKFAIL). We do, however, see it loading the first character from format:
mov rax,251C4801418 ; loads the address of where the format const string reference is stored
mov rax,[rax] ; loads the address of format
add rax,0C ; loads the address of format's first character
movzx edx,word ptr [rax] ; reads the first character of formatand then using the equivalent of a cascading if/else. Now let’s look at .NET 8:
; Tests.Format(Int32)
sub rsp,28
mov ecx,edx
call qword ptr [7FFEE0BAF4C8]; Tests.BinaryFormat(Int32)
nop
add rsp,28
ret
; Total bytes of code 18Whoa. It not only saw that format‘s Length was 1 and not only was able to avoid the bounds check, it actually read the first character, lowercased it, and matched it against all the switch branches, such that the entire operation was constant folded and propagated away, leaving just a call to BinaryFormat. That’s primarily thanks to dotnet/runtime#78593.
There are a multitude of other such improvements, such as dotnet/runtime#77593 which enables it to constant fold the length of a string or T[] stored in a static readonly field. Consider:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
private static readonly string s_newline = Environment.NewLine;
[Benchmark]
public bool IsLineFeed() => s_newline.Length == 1 && s_newline[0] == '\n';
}On .NET 7, I get the following assembly:
; Tests.IsLineFeed()
mov rax,18AFF401F78
mov rax,[rax]
mov edx,[rax+8]
cmp edx,1
jne short M00_L00
cmp word ptr [rax+0C],0A
sete al
movzx eax,al
ret
M00_L00:
xor eax,eax
ret
; Total bytes of code 36This is effectively a 1:1 translation of the C#, with not much interesting happening: it loads the string from s_newline, and compares its Length to 1; if it doesn’t match, it returns 0 (false), otherwise it compares the value in the first element of the array against 0xA (line feed) and returns whether they match. Now, .NET 8:
; Tests.IsLineFeed()
xor eax,eax
ret
; Total bytes of code 3That’s more interesting. I ran this code on Windows, where Environment.NewLine is "\r\n". The JIT has constant folded the entire operation, seeing that the length is not 1, such that the whole operation boils down to just returning false.
Or consider dotnet/runtime#78783 and dotnet/runtime#80661 which teach the JIT how to actually peer into the contents of an “RVA static.” These are “Relative Virtual Address” static fields, which is a fancy way of saying they live in the assembly’s data section. The C# compiler has optimizations that put constant data into such fields; for example, when you write:
private static ReadOnlySpan<byte> Prefix => "http://"u8;the C# compiler will actually emil IL like this:
.method private hidebysig specialname static
valuetype [System.Runtime]System.ReadOnlySpan`1<uint8> get_Prefix () cil managed
{
.maxstack 8
IL_0000: ldsflda int64 '<PrivateImplementationDetails>'::'6709A82409D4C9E2EC04E1E71AB12303402A116B0F923DB8114F69CB05F1E926'
IL_0005: ldc.i4.7
IL_0006: newobj instance void valuetype [System.Runtime]System.ReadOnlySpan`1<uint8>::.ctor(void*, int32)
IL_000b: ret
}
...
.class private auto ansi sealed '<PrivateImplementationDetails>'
extends [System.Runtime]System.Object
{
.field assembly static initonly int64 '6709A82409D4C9E2EC04E1E71AB12303402A116B0F923DB8114F69CB05F1E926' at I_00002868
.data cil I_00002868 = bytearray ( 68 74 74 70 3a 2f 2f 00 )
}With these PRs, when indexing into such RVA statics, the JIT is now able to actually read the data at the relevant location, constant folding the operation to the value at that location. So, take the following benchmark:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
[Benchmark]
public bool IsWhiteSpace() => char.IsWhiteSpace('\n');
}The char.IsWhiteSpace method is implemented via a lookup into such an RVA static, using the char passed in as an index into it. If the index ends up being a const, now on .NET 8 the whole operation can be constant folded away. .NET 7:
; Tests.IsWhiteSpace()
xor eax,eax
test byte ptr [7FFF9BCCD83A],80
setne al
ret
; Total bytes of code 13and .NET 8:
; Tests.IsWhiteSpace()
mov eax,1
ret
; Total bytes of code 6You get the idea. Of course, a developer hopefully wouldn’t explicitly write char.IsWhiteSpace('\n'), but such code can result none-the-less, especially via inlining.
There are a multitude of these kinds of improvements in .NET 8. dotnet/runtime#77102 made it so that a static readonly value type’s primitive fields can be constant folded as if they were themselves static readonly fields, and dotnet/runtime#80431 extended that to strings. dotnet/runtime#85804 taught the JIT how to handle RuntimeTypeHandle.ToIntPtr(typeof(T).TypeHandle) (which is used in methods like GC.AllocateUninitializedArray), while dotnet/runtime#87101 taught it to handle obj.GetType() (such that if the JIT knows the exact type of an instance obj, it can replace the GetType() invocation with the known answer). However, one of my favorite examples, purely because of just how magical it seems, comes from a series of PRs, including dotnet/runtime#80622, dotnet/runtime#78961, dotnet/runtime#80888, and dotnet/runtime#81005. Together, they enable this:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
[Benchmark]
public DateTime Get() => new DateTime(2023, 9, 1);
}to produce this:
; Tests.Get()
mov rax,8DBAA7E629B4000
ret
; Total bytes of code 11The JIT was able to successfully inline and constant fold the entire operation down to a single constant. That 8DBAA7E629B4000 in that mov instruction is the value for the private readonly ulong _dateData field that backs DateTime. Sure enough, if you run:
new DateTime(0x8DBAA7E629B4000)you’ll see it produces:
[9/1/2023 12:00:00 AM]Very cool.
Non-GC Heap
Earlier we saw an example of the codegen when loading a constant string. As a reminder, this code:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
[Benchmark]
public string GetPrefix() => "https://";
}results in this assembly on .NET 7:
; Tests.GetPrefix()
mov rax,126A7C01498
mov rax,[rax]
ret
; Total bytes of code 14There are two mov instructions here. The first is loading the location where the address to the string object is stored, and the second is reading the address stored at that location (this requires two movs because on x64 there’s no addressing mode that supports moving the value stored at an absolute address larger than 32-bits). Even though we’re dealing with a string literal here, such that the data for the string is constant, that constant data still ends up being copied into a heap-allocated string object. That object is interned, such that there’s only one of them in the process, but it’s still a heap object, and that means it’s still subject to being moved around by the GC. That means the JIT can’t just bake in the address of the string object, since the address can change, hence why it needs to read the address each time, in order to know where it currently is. Or, does it?
What if we could ensure that the string object for this literal is created some place where it would never move, for example on the Pinned Object Heap (POH)? Then the JIT could avoid the indirection and instead just hardcode the address of the string, knowing that it would never move. Of course, the POH guarantees objects on it will never move, but it doesn’t guarantee addresses to them will always be valid; after all, it doesn’t root the objects, so objects on the POH are still collectible by the GC, and if they were collected, their addresses would be pointing at garbage or other data that ended up reusing the space.
To address that, .NET 8 introduces a new mechanism used by the JIT for these kinds of situations: the Non-GC Heap (an evolution of the older “Frozen Segments” concept used by Native AOT). The JIT can ensure relevant objects are allocated on the Non-GC Heap, which is, as the name suggests, not managed by the GC and is intended to store objects where the JIT can prove the object has no references the GC needs to be aware of and will be rooted for the lifetime of the process, which in turn implies it can’t be part of an unloadable context.
The JIT can then avoid indirections in code generated to access that object, instead just hardcoding the object’s address. That’s exactly what it does now for string literals, as of dotnet/runtime#49576. Now in .NET 8, that same method above results in this assembly:
; Tests.GetPrefix()
mov rax,227814EAEA8
ret
; Total bytes of code 11dotnet/runtime#75573 makes a similar play, but with the RuntimeType objects produced by typeof(T) (subject to various constraints, like the T not coming from an unloadable assembly, in which case permanently rooting the object would prevent unloading). Again, we can see this with a simple benchmark:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
[Benchmark]
public Type GetTestsType() => typeof(Tests);
}where we get the following difference between .NET 7 and .NET 8:
; .NET 7
; Tests.GetTestsType()
sub rsp,28
mov rcx,offset MT_Tests
call CORINFO_HELP_TYPEHANDLE_TO_RUNTIMETYPE
nop
add rsp,28
ret
; Total bytes of code 25
; .NET 8
; Tests.GetTestsType()
mov rax,1E0015E73F8
ret
; Total bytes of code 11The same capability can be extended to other kinds of objects, as it is in dotnet/runtime#85559 (which is based on work from dotnet/runtime#76112), making Array.Empty<T>() cheaper by allocating the empty arrays on the Non-GC Heap.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
[Benchmark]
public string[] Test() => Array.Empty<string>();
}; .NET 7
; Tests.Test()
mov rax,17E8D801FE8
mov rax,[rax]
ret
; Total bytes of code 14
; .NET 8
; Tests.Test()
mov rax,1A0814EAEA8
ret
; Total bytes of code 11And as of dotnet/runtime#77737, it also applies to the heap object associated with static value type fields, at least those that don’t contain any GC references. Wait, heap object for value type fields? Surely, Stephen, you got that wrong, value types aren’t allocated on the heap when stored in fields. Well, actually they are when they’re stored in static fields; the runtime creates a heap-allocated box associated with that field to store the value (but the same box is reused for all writes to that field). And that means for a benchmark like this:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser(maxDepth: 0)]
public partial class Tests
{
private static readonly ConfigurationData s_config = ConfigurationData.ReadData();
[Benchmark]
public TimeSpan GetRefreshInterval() => s_config.RefreshInterval;
// Struct for storing fictional configuration data that might be read from a configuration file.
private struct ConfigurationData
{
public static ConfigurationData ReadData() => new ConfigurationData
{
Index = 0x12345,
Id = Guid.NewGuid(),
IsEnabled = true,
RefreshInterval = TimeSpan.FromSeconds(100)
};
public int Index;
public Guid Id;
public bool IsEnabled;
public TimeSpan RefreshInterval;
}
}we see the following assembly code for reading that RefreshInterval on .NET 7:
; Tests.GetRefreshInterval()
mov rax,13D84001F78
mov rax,[rax]
mov rax,[rax+20]
ret
; Total bytes of code 18That code is loading the address of the field, reading from it the address of the box object, and then reading from that box object the TimeSpan value that’s stored inside of it. But, now on .NET 8 we get the assembly you’ve now come to expect:
; Tests.GetRefreshInterval()
mov rax,20D9853AE48
mov rax,[rax]
ret
; Total bytes of code 14The box gets allocated on the Non-GC heap, which means the JIT can bake in the address of the object, and we get to save a mov.
Beyond fewer indirections to access these Non-GC Heap objects, there are other benefits. For example, a “generational GC” like the one used in .NET divides the heap into multiple “generations,” where generation 0 (“gen0”) is for recently created objects and generation 2 (“gen2”) is for objects that have been around for a while. When the GC performs a collection, it needs to determine which objects are still alive (still referenced) and which ones can be collected, and to do that it has to trace through all references to find out what objects are still reachable. However, the generational model is beneficial because it can enable the GC to scour through much less of the heap than it might otherwise need to. If it can tell, for example, that there aren’t any references from gen2 back to gen0, then when doing a gen0 collection, it can avoid enumerating gen2 objects entirely. But to be able to know about such references, the GC needs to know any time a reference is written to a shared location. We can see that in this benchmark:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Runtime.CompilerServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser]
public class Tests
{
[Benchmark]
public void Write()
{
string dst = "old";
Write(ref dst, "new");
}
[MethodImpl(MethodImplOptions.NoInlining)]
private static void Write(ref string dst, string s) => dst = s;
}where the code generated for that Write(ref string, string) method on both .NET 7 and .NET 8 is:
; Tests.Write(System.String ByRef, System.String)
call CORINFO_HELP_CHECKED_ASSIGN_REF
nop
ret
; Total bytes of code 7That CORINFO_HELP_CHECKED_ASSIGN_REF is a JIT helper function that contains what’s known as a “GC write barrier,” a little piece of code that runs to let the GC track that a reference is being written that it might need to know about, e.g. because the object being assigned might be gen0 and the destination might be gen2. We see the same thing on .NET 7 for a tweak to the benchmark like this:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Runtime.CompilerServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser]
public class Tests
{
[Benchmark]
public void Write()
{
string dst = "old";
Write(ref dst);
}
[MethodImpl(MethodImplOptions.NoInlining)]
private static void Write(ref string dst) => dst = "new";
}Now we’re storing a string literal into the destination, and on .NET 7 we see assembly similarly calling CORINFO_HELP_CHECKED_ASSIGN_REF:
; Tests.Write(System.String ByRef)
mov rdx,1FF0E4014A0
mov rdx,[rdx]
call CORINFO_HELP_CHECKED_ASSIGN_REF
nop
ret
; Total bytes of code 20But, now on .NET 8 we see this:
; Tests.Write(System.String ByRef)
mov rax,1B3814EAEC8
mov [rcx],rax
ret
; Total bytes of code 14No write barrier. That’s thanks to dotnet/runtime#76135, which recognizes that these Non-GC Heap objects don’t need to be tracked, since they’ll never be collected anyway. There are multiple other PRs that improve how constant folding works with these Non-GC Heap objects, too, like dotnet/runtime#85127, dotnet/runtime#85888, and dotnet/runtime#86318.
Zeroing
The JIT frequently needs to generate code that zeroes out memory. Unless you’ve used [SkipLocalsInit], for example, any stack space allocated with stackalloc needs to be zeroed, and it’s the JIT’s responsibility to generate the code that does so. Consider this benchmark:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Runtime.CompilerServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
[Benchmark] public void Constant256() => Use(stackalloc byte[256]);
[Benchmark] public void Constant1024() => Use(stackalloc byte[1024]);
[MethodImpl(MethodImplOptions.NoInlining)] // prevent stackallocs from being optimized away
private static void Use(Span<byte> span) { }
}Here’s what the .NET 7 assembly looks like for both Constant256 and Constant1024:
; Tests.Constant256()
push rbp
sub rsp,40
lea rbp,[rsp+20]
xor eax,eax
mov [rbp+10],rax
mov [rbp+18],rax
mov rax,0A77E4BDA96AD
mov [rbp+8],rax
add rsp,20
mov ecx,10
M00_L00:
push 0
push 0
dec rcx
jne short M00_L00
sub rsp,20
lea rcx,[rsp+20]
mov [rbp+10],rcx
mov dword ptr [rbp+18],100
lea rcx,[rbp+10]
call qword ptr [7FFF3DD37900]; Tests.Use(System.Span`1<Byte>)
mov rcx,0A77E4BDA96AD
cmp [rbp+8],rcx
je short M00_L01
call CORINFO_HELP_FAIL_FAST
M00_L01:
nop
lea rsp,[rbp+20]
pop rbp
ret
; Total bytes of code 110
; Tests.Constant1024()
push rbp
sub rsp,40
lea rbp,[rsp+20]
xor eax,eax
mov [rbp+10],rax
mov [rbp+18],rax
mov rax,606DD723A061
mov [rbp+8],rax
add rsp,20
mov ecx,40
M00_L00:
push 0
push 0
dec rcx
jne short M00_L00
sub rsp,20
lea rcx,[rsp+20]
mov [rbp+10],rcx
mov dword ptr [rbp+18],400
lea rcx,[rbp+10]
call qword ptr [7FFF3DD47900]; Tests.Use(System.Span`1<Byte>)
mov rcx,606DD723A061
cmp [rbp+8],rcx
je short M00_L01
call CORINFO_HELP_FAIL_FAST
M00_L01:
nop
lea rsp,[rbp+20]
pop rbp
ret
; Total bytes of code 110We can see in the middle there that the JIT has written a zeroing loop, zeroing 16 bytes at a time by pushing two 8-byte 0s onto the stack on each iteration:
M00_L00:
push 0
push 0
dec rcx
jne short M00_L00Now in .NET 8 with dotnet/runtime#83255, the JIT unrolls and vectorizes that zeroing, and after a certain threshold (which as of dotnet/runtime#83274 has also been updated and made consistent with what other native compilers do), it switches over to using an optimized memset routine rather than emitting a large amount of code to achieve the same thing. Here’s what we now get on .NET 8 for Constant256 (on my machine… I call that out because the limits are based on what instruction sets are available):
; Tests.Constant256()
push rbp
sub rsp,40
vzeroupper
lea rbp,[rsp+20]
xor eax,eax
mov [rbp+10],rax
mov [rbp+18],rax
mov rax,6281D64D33C3
mov [rbp+8],rax
test [rsp],esp
sub rsp,100
lea rcx,[rsp+20]
vxorps ymm0,ymm0,ymm0
vmovdqu ymmword ptr [rcx],ymm0
vmovdqu ymmword ptr [rcx+20],ymm0
vmovdqu ymmword ptr [rcx+40],ymm0
vmovdqu ymmword ptr [rcx+60],ymm0
vmovdqu ymmword ptr [rcx+80],ymm0
vmovdqu ymmword ptr [rcx+0A0],ymm0
vmovdqu ymmword ptr [rcx+0C0],ymm0
vmovdqu ymmword ptr [rcx+0E0],ymm0
mov [rbp+10],rcx
mov dword ptr [rbp+18],100
lea rcx,[rbp+10]
call qword ptr [7FFEB7D3F498]; Tests.Use(System.Span`1<Byte>)
mov rcx,6281D64D33C3
cmp [rbp+8],rcx
je short M00_L00
call CORINFO_HELP_FAIL_FAST
M00_L00:
nop
lea rsp,[rbp+20]
pop rbp
ret
; Total bytes of code 156Notice there’s no zeroing loop, and instead we see a bunch of 256-bit vmovdqu move instructions to copy the zeroed out ymm0 register to the next portion of the stack. And then for Constant1024 we see:
; Tests.Constant1024()
push rbp
sub rsp,40
lea rbp,[rsp+20]
xor eax,eax
mov [rbp+10],rax
mov [rbp+18],rax
mov rax,0CAF12189F783
mov [rbp],rax
test [rsp],esp
sub rsp,400
lea rcx,[rsp+20]
mov [rbp+8],rcx
xor edx,edx
mov r8d,400
call CORINFO_HELP_MEMSET
mov rcx,[rbp+8]
mov [rbp+10],rcx
mov dword ptr [rbp+18],400
lea rcx,[rbp+10]
call qword ptr [7FFEB7D5F498]; Tests.Use(System.Span`1<Byte>)
mov rcx,0CAF12189F783
cmp [rbp],rcx
je short M00_L00
call CORINFO_HELP_FAIL_FAST
M00_L00:
nop
lea rsp,[rbp+20]
pop rbp
ret
; Total bytes of code 119Again, no zeroing loop, and instead we see call CORINFO_HELP_MEMSET, relying on the optimized underlying memset to efficiently handle the zeroing. The effects of this are visible in throughput numbers as well:
| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Constant256 | .NET 7.0 | 7.927 ns | 1.00 |
| Constant256 | .NET 8.0 | 3.181 ns | 0.40 |
| Constant1024 | .NET 7.0 | 30.523 ns | 1.00 |
| Constant1024 | .NET 8.0 | 8.850 ns | 0.29 |
dotnet/runtime#83488 improved this further by using a standard trick frequently employed when vectorizing algorithms. Let’s say you want to zero out 120 bytes and you have at your disposal an instruction for zeroing out 32 bytes at a time. We can issue three such instructions to zero out 96 bytes, but we’re then left with 24 bytes that still need to be zeroed. What do we do? We can’t write another 32 bytes from where we left off, as we might then be overwriting 8 bytes we shouldn’t be touching. We could use scalar zeroing and issue three instructions each for 8 bytes, but could we do it in just a single instruction? Yes! Since the writes are idempotent, we can just zero out the last 32 bytes of the 120 bytes, even though that means we’ll be re-zeroing 8 bytes we already zeroed. You can see this same approach utilized in many of the vectorized operations throughout the core libraries, and as of this PR, the JIT employs it when zeroing as well.
dotnet/runtime#85389 takes this further and uses AVX512 to improve bulk operations like this zeroing. So, running the same benchmark on my Dev Box with AVX512, I see this assembly generated for Constant256:
; Tests.Constant256()
push rbp
sub rsp,40
vzeroupper
lea rbp,[rsp+20]
xor eax,eax
mov [rbp+10],rax
mov [rbp+18],rax
mov rax,992482B435F7
mov [rbp+8],rax
test [rsp],esp
sub rsp,100
lea rcx,[rsp+20]
vxorps ymm0,ymm0,ymm0
vmovdqu32 [rcx],zmm0
vmovdqu32 [rcx+40],zmm0
vmovdqu32 [rcx+80],zmm0
vmovdqu32 [rcx+0C0],zmm0
mov [rbp+10],rcx
mov dword ptr [rbp+18],100
lea rcx,[rbp+10]
call qword ptr [7FFCE555F4B0]; Tests.Use(System.Span`1<Byte>)
mov rcx,992482B435F7
cmp [rbp+8],rcx
je short M00_L00
call CORINFO_HELP_FAIL_FAST
M00_L00:
nop
lea rsp,[rbp+20]
pop rbp
ret
; Total bytes of code 132; Tests.Use(System.Span`1<Byte>)
ret
; Total bytes of code 1Note that now, rather than eight vmovdqu instructions with ymm0, we see four vmovdqu32 instructions with zmm0, as each move instruction is able to zero out twice as much, with each instruction handling 64 bytes at a time.
Value Types
Value types (structs) have been used increasingly as part of high-performance code. Yet while they have obvious advantages (they don’t require heap allocation and thus reduce pressure on the GC), they also have disadvantages (more data being copied around) and have historically not been as optimized as someone relying on them heavily for performance might like. It’s been a key focus area of improvement for the JIT in the last several releases of .NET, and that continues into .NET 8.
One specific area of improvement here is around “promotion.” In this context, promotion is the idea of splitting a struct apart into its constituent fields, effectively treating each field as its own local. This can lead to a number of valuable optimizations, including being able to enregister portions of a struct. As of .NET 7, the JIT does support struct promotion, but with limitations, including only supporting structs with at most four fields and not supporting nested structs (other than for primitive types).
A lot of work in .NET 8 went into removing those restrictions. dotnet/runtime#83388 improves upon the existing promotion support with an additional optimization pass the JIT refers to as “physical promotion;” it does away with both of those cited limitations, however as of this PR the feature was still disabled by default. Other PRs like dotnet/runtime#85105 and dotnet/runtime#86043 improved it further, and dotnet/runtime#88090 enabled the optimizations by default. The net result is visible in a benchmark like the following:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser]
public class Tests
{
private ParsedStat _stat;
[Benchmark]
public ulong GetTime()
{
ParsedStat stat = _stat;
return stat.utime + stat.stime;
}
internal struct ParsedStat
{
internal int pid;
internal string comm;
internal char state;
internal int ppid;
internal int session;
internal ulong utime;
internal ulong stime;
internal long nice;
internal ulong starttime;
internal ulong vsize;
internal long rss;
internal ulong rsslim;
}
}Here we have a struct modeling some data that might be extracted from a procfs stat file on Linux. The benchmark makes a local copy of the struct and returns a sum of the user and kernel times. In .NET 7, the assembly looks like this:
; Tests.GetTime()
push rdi
push rsi
sub rsp,58
lea rsi,[rcx+8]
lea rdi,[rsp+8]
mov ecx,0A
rep movsq
mov rax,[rsp+10]
add rax,[rsp+18]
add rsp,58
pop rsi
pop rdi
ret
; Total bytes of code 40The two really interesting instructions here are these:
mov ecx,0A
rep movsqThe ParsedStat struct is 80 bytes in size, and this pair of instructions is repeatedly (rep) copying 8-bytes (movsq) 10 times (ecx that’s been populated with 0xA) from the source location in rsi (which was initialized with [rcx+8], aka the location of the _stat field) to the destination location in rdi (a stack location at [rsp+8]). In other words, this is making a full copy of the whole struct, even though we only need two fields from it. Now in .NET 8, we get this:
; Tests.GetTime()
add rcx,8
mov rax,[rcx+8]
mov rcx,[rcx+10]
add rax,rcx
ret
; Total bytes of code 16Ahhh, so much nicer. Now it’s avoided the whole copy, and is simply moving the relevant ulong values into registers and adding them together.
Here’s another example:
// dotnet run -c Release -f net7.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Environments;
using BenchmarkDotNet.Jobs;
using BenchmarkDotNet.Running;
var config = DefaultConfig.Instance
.AddJob(Job.Default.WithId(".NET 7").WithRuntime(CoreRuntime.Core70).AsBaseline())
.AddJob(Job.Default.WithId(".NET 8 w/o PGO").WithRuntime(CoreRuntime.Core80).WithEnvironmentVariable("DOTNET_TieredPGO", "0"))
.AddJob(Job.Default.WithId(".NET 8").WithRuntime(CoreRuntime.Core80));
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args, config);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "EnvironmentVariables", "Runtime")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
private readonly List<int?> _list = Enumerable.Range(0, 10000).Select(i => (int?)i).ToList();
[Benchmark]
public int CountList()
{
int count = 0;
foreach (int? i in _list)
if (i is not null)
count++;
return count;
}
}List<T> has a struct List<T>.Enumerator that’s returned from List<T>.GetEnumerator(), such that when you foreach the list directly (rather than as an IEnumerable<T>), the C# compiler binds to this struct enumerator via the enumerator pattern. This example runs afoul of the previous limitations in two ways. That Enumerator has a field for the current T, so if T is a non-primitive value type, it violates the “no nested structs” limitation. And that Enumerator has four fields, so if that T has multiple fields, it pushes it beyond the four-field limit. Now in .NET 8, the JIT is able to see through the struct to its fields, and optimize the enumeration of the list to a much more efficient result.
| Method | Job | Mean | Ratio | Code Size |
|---|---|---|---|---|
| CountList | .NET 7 | 18.878 us | 1.00 | 215 B |
| CountList | .NET 8 w/o PGO | 11.726 us | 0.62 | 70 B |
| CountList | .NET 8 | 5.912 us | 0.31 | 66 B |
Note the significant improvement in both throughput and code size from .NET 7 to .NET 8 even without PGO. However, the gap here between .NET 8 without PGO and with PGO is also interesting, albeit for other reasons. We see an almost halving of execution time with PGO applied, but only four bytes of difference in assembly code size. Those four bytes stem from a single mov instruction that PGO was able to help remove, which we can see easily by pasting the two snippets into a diffing tool:
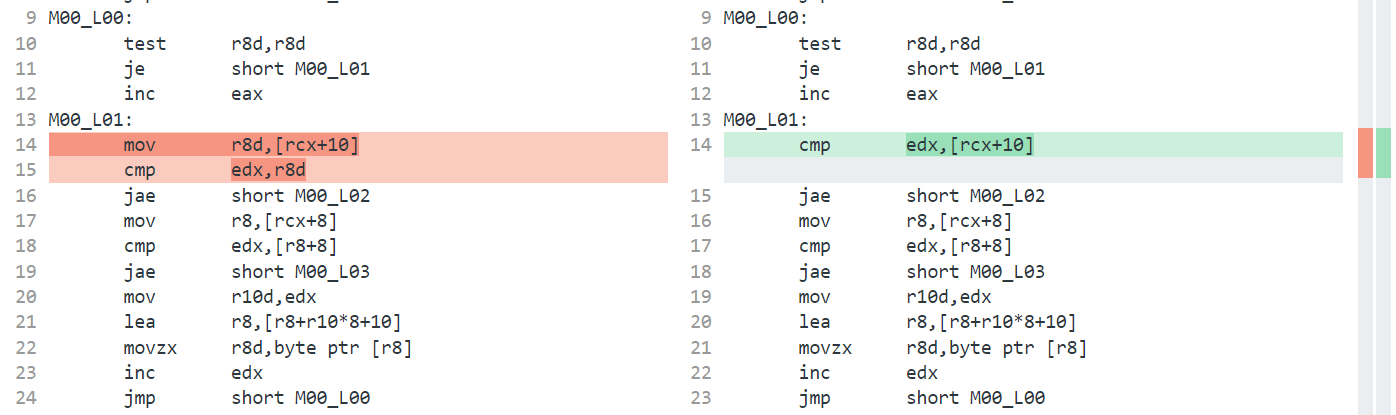 ~12us down to ~6us is a lot for a difference of a single
~12us down to ~6us is a lot for a difference of a single mov… why such an outsized impact? This ends up being a really good example of what I mentioned at the beginning of this article: beware microbenchmarks, as they can differ from machine to machine. Or in this case, in particular from processor to processor. The machine on which I’m writing this and on which I’ve run the majority of the benchmarks in this post is a several year old desktop with an Intel Coffee Lake processor. When I run the same benchmark on my Dev Box, which has an Intel Xeon Platinum 8370C, I see this:
| Method | Job | Mean | Ratio | Code Size |
|---|---|---|---|---|
| CountList | .NET 7 | 15.804 us | 1.00 | 215 B |
| CountList | .NET 8 w/o PGO | 7.138 us | 0.45 | 70 B |
| CountList | .NET 8 | 6.111 us | 0.39 | 66 B |
Same code size, still a large improvement due to physical promotion, but now only a small ~15% rather than ~2x improvement from PGO. As it turns out, Coffee Lake is one of the processors affected by the Jump Conditional Code (JCC) Erratum issued in 2019 (“erratum” here is a fancy way of saying “bug”, or alternatively, “documentation about a bug”). The problem involved jump instructions on a 32-byte boundary, and the hardware caching information about those instructions. The issue was then subsequently fixed via a microcode update that disabled the relevant caching, but that then created a possible performance issue, as whether a jump is on a 32-byte boundary impacts whether it’s cached and therefore the resulting performance gains that cache was introduced to provide. If I set the DOTNET_JitDisasm environment variable to *CountList* (to get the JIT to output the disassembly directly, rather than relying on BenchmarkDotNet to fish it out), and set the DOTNET_JitDisasmWithAlignmentBoundaries environment variable to 1 (to get the JIT to include alignment boundary information in that output), I see this:
G_M000_IG04: ;; offset=0018H
mov r8d, dword ptr [rcx+10H]
cmp edx, r8d
jae SHORT G_M000_IG05
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ (jae: 1 ; jcc erratum) 32B boundary ...............................
mov r8, gword ptr [rcx+08H]Sure enough, we see that this jump instruction is falling on a 32-byte boundary. When PGO kicks in and removes the earlier mov, that changes the alignment such that the jump is no longer on a 32-byte boundary:
G_M000_IG05: ;; offset=0018H
cmp edx, dword ptr [rcx+10H]
jae SHORT G_M000_IG06
mov r8, gword ptr [rcx+08H]
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ (mov: 1) 32B boundary ...............................
cmp edx, dword ptr [r8+08H]This is all to say, again, there are many things that can impact microbenchmarks, and it’s valuable to understand the source of a difference rather than just taking it at face value.
Ok, where were we? Oh yeah, structs. Another improvement related to structs comes in dotnet/runtime#79346, which adds an additional “liveness” optimization pass earlier than the others it already has (liveness is just an indication of whether a variable might still be needed because its value might be used again in the future). This then allows the JIT to remove some struct copies it wasn’t previously able to, in particular in situations where the last time the struct is used is in passing it to another method. However, this additional liveness pass has other benefits as well, in particular with relation to “forward substitution.” Forward substitution is an optimization that can be thought of as the opposite of “common subexpression elimination” (CSE). With CSE, the compiler replaces an expression with something containing the result already computed for that expression, so for example if you had:
int c = (a + b) + 3;
int d = (a + b) * 4;a compiler might use CSE to rewrite that as:
int tmp = a + b;
int c = tmp + 3;
int d = tmp * 4;Forward substitution could be used to undo that, distributing the expression feeding into tmp back to where tmp is used, such that we end up back with:
int c = (a + b) + 3;
int d = (a + b) * 4;Why would a compiler want to do that? It can make certain subsequent optimizations easier for it to see. For example, consider this benchmark:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser]
public class Tests
{
[Benchmark]
[Arguments(42)]
public int Merge(int a)
{
a *= 3;
a *= 3;
return a;
}
}On .NET 7, that results in this assembly:
; Tests.Merge(Int32)
lea edx,[rdx+rdx*2]
lea edx,[rdx+rdx*2]
mov eax,edx
ret
; Total bytes of code 9The generated code here is performing each multiplication individually. But when we view:
a *= 3;
a *= 3;
return a;instead as:
a = a * 3;
a = a * 3;
return a;and knowing that the initial result stored into a is temporary (thank you, liveness), forward substitution can turn that into:
a = (a * 3) * 3;
return a;at which point constant folding can kick in. Now on .NET 8 we get:
; Tests.Merge(Int32)
lea eax,[rdx+rdx*8]
ret
; Total bytes of code 4Another change related to liveness is dotnet/runtime#77990 from @SingleAccretion. This adds another pass over one of the JIT’s internal representations, eliminating writes it finds to be useless.
Casting
Various improvements have gone into improving the performance of casting in .NET 8.
dotnet/runtime#75816 improved the performance of using is T[] when T is sealed. There’s a CORINFO_HELP_ISINSTANCEOFARRAY helper the JIT uses to determine whether an object is of a specified array type, but when the T is sealed, the JIT can instead emit it without the helper, generating code as if it were written like obj is not null && obj.GetType() == typeof(T[]). This is another example where dynamic PGO has a measurable impact, so the benchmark highlights the improvements with and without it.
// dotnet run -c Release -f net7.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Environments;
using BenchmarkDotNet.Jobs;
using BenchmarkDotNet.Running;
var config = DefaultConfig.Instance
.AddJob(Job.Default.WithId(".NET 7").WithRuntime(CoreRuntime.Core70).AsBaseline())
.AddJob(Job.Default.WithId(".NET 8 w/o PGO").WithRuntime(CoreRuntime.Core80).WithEnvironmentVariable("DOTNET_TieredPGO", "0"))
.AddJob(Job.Default.WithId(".NET 8").WithRuntime(CoreRuntime.Core80));
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args, config);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "EnvironmentVariables", "Runtime")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
private readonly object _obj = new string[1];
[Benchmark]
public bool IsStringArray() => _obj is string[];
}| Method | Job | Mean | Ratio |
|---|---|---|---|
| IsStringArray | .NET 7 | 1.2290 ns | 1.00 |
| IsStringArray | .NET 8 w/o PGO | 0.2365 ns | 0.19 |
| IsStringArray | .NET 8 | 0.0825 ns | 0.07 |
Moving on, consider this benchmark:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser(maxDepth: 0)]
public class Tests
{
private readonly string[] _strings = new string[1];
[Benchmark]
public string Get1() => _strings[0];
[Benchmark]
public string Get2() => Volatile.Read(ref _strings[0]);
}Get1 here is just reading and returning the 0th element from the array. Get2 here is returning a ref to the 0th element from the array. Here’s the assembly we get in .NET 7:
; Tests.Get1()
sub rsp,28
mov rax,[rcx+8]
cmp dword ptr [rax+8],0
jbe short M00_L00
mov rax,[rax+10]
add rsp,28
ret
M00_L00:
call CORINFO_HELP_RNGCHKFAIL
int 3
; Total bytes of code 29
; Tests.Get2()
sub rsp,28
mov rcx,[rcx+8]
xor edx,edx
mov r8,offset MT_System.String
call CORINFO_HELP_LDELEMA_REF
nop
add rsp,28
ret
; Total bytes of code 31In Get1, we’re immediately using the array element, so the C# compiler can emit a ldelem.ref IL instruction, but in Get2, the reference to the array element is being returned, so the C# compiler emits a ldelema (load element address) instruction. In the general case, ldelema requires a type check, because of covariance; you could have a Base[] array = new DerivedFromBase[1];, in which case if you handed out a ref Base pointing into that array and someone wrote a new AlsoDerivedFromBase() via that ref, type safety would be violated (since you’d be storing an AlsoDerivedFromBase into a DerivedFromBase[] even though DerivedFromBase and AlsoDerivedFromBase aren’t related). As such, the .NET 7 assembly for this code includes a call to CORINFO_HELP_LDELEMA_REF, which is the helper function the JIT uses to perform that type check. But the array element type here is string, which is sealed, which means we can’t get into that problematic situation: there’s no type you can store into a string variable other than string. Thus, this helper call is superfluous, and with dotnet/runtime#85256, the JIT can now avoid using it. On .NET 8, then, we get this for Get2:
; Tests.Get2()
sub rsp,28
mov rax,[rcx+8]
cmp dword ptr [rax+8],0
jbe short M00_L00
add rax,10
add rsp,28
ret
M00_L00:
call CORINFO_HELP_RNGCHKFAIL
int 3
; Total bytes of code 29No CORINFO_HELP_LDELEMA_REF in sight.
And then dotnet/runtime#86728 reduces the costs associated with a generic cast. Previously the JIT would always use a CastHelpers.ChkCastAny method to perform the cast, but with this change, it inlines a fast success path.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Runtime.CompilerServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly object _o = "hello";
[Benchmark]
public string GetString() => Cast<string>(_o);
[MethodImpl(MethodImplOptions.NoInlining)]
public T Cast<T>(object o) => (T)o;
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| GetString | .NET 7.0 | 2.247 ns | 1.00 |
| GetString | .NET 8.0 | 1.300 ns | 0.58 |
Peephole Optimizations
A “peephole optimization” is one in which a small sequence of instructions is replaced by a different sequence that is expected to perform better. This could include getting rid of instructions deemed unnecessary or replacing two instructions with one instruction that can accomplish the same task. Every release of .NET features a multitude of new peephole optimizations, often inspired by real-world examples where some overhead could be trimmed by slightly increasing code quality, and .NET 8 is no exception. Here are just some of these optimizations in .NET 8:
- dotnet/runtime#73120 from @dubiousconst282 and dotnet/runtime#74806 from @En3Tho improved the handling of the common bit-test patterns like
(x & 1) != 0. - dotnet/runtime#77874 gets rid of some unnecessary casts in a method like
short Add(short x, short y) => (short)(x + y). - dotnet/runtime#76981 improves the performance of multiplying by a number that’s one away from a power of two, by replacing an
imulinstruction with a three-instructionmov/shl/addsequence, and dotnet/runtime#77137 improves other multiplications by a constant via replacing amov/shlsequence with a singlelea. - dotnet/runtime#78786 from @pedrobsaila fuses together separate conditions like
value < 0 || value == 0into the equivalent ofvalue <= 0. - dotnet/runtime#82750 eliminates some redundant
cmpinstructions. - dotnet/runtime#79630 avoids an unnecessary
andin a method likestatic byte Mod(uint i) => (byte)(i % 256). - dotnet/runtime#77540 from @AndyJGraham, dotnet/runtime#84399, and dotnet/runtime#85032 optimize pairs of load and store instructions and replace them with a single
ldporstpinstruction on Arm. - dotnet/runtime#84350 similarly optimizes pairs of
str wzrinstructions to bestr xzrinstructions. - dotnet/runtime#83458 from @SwapnilGaikwad optimizes some redundant memory loads on Arm by replacing some
ldrinstructions withmovinstructions. - dotnet/runtime#83176 optimizes an
x < 0expression from emitting acmp/csetsequence on Arm to instead emitting anlsrinstruction. - dotnet/runtime#82924 removes a redundant overflow check on Arm for some division operations.
- dotnet/runtime#84605 combines an
lsl/cmpsequence on Arm into a singlecmp. - dotnet/runtime#84667 combines
negandcmpsequences into use ofcmnon Arm. - dotnet/runtime#79550 replaces
mul/negsequences on Arm withmneg.
(I’ve touched here on some of the improvements specific to Arm. For a more in-depth look, see Arm64 Performance Improvements in .NET 8).
Native AOT
Native AOT shipped in .NET 7. It enables .NET programs to be compiled at build time into a self-contained executable or library composed entirely of native code: no JIT is required at execution time to compile anything, and in fact there’s no JIT included with the compiled program. The result is an application that can have a very small on-disk footprint, a small memory footprint, and very fast startup time. In .NET 7, the primary supported workloads were console applications. Now in .NET 8, a lot of work has gone into making ASP.NET applications shine when compiled with Native AOT, as well as driving down overall costs, regardless of app model.
A significant focus in .NET 8 was on reducing the size of built applications, and the net effect of this is quite easy to see. Let’s start by creating a new Native AOT console app:
dotnet new console -o nativeaotexample -f net7.0That creates a new nativeaotexample directory and adds to it a new “Hello, world” app that targets .NET 7. Edit the generated nativeaotexample.csproj in two ways:
- Change the
<TargetFramework>net7.0</TargetFramework>to instead be<TargetFrameworks>net7.0;net8.0</TargetFrameworks>, so that we can easily build for either .NET 7 or .NET 8. - Add
<PublishAot>true</PublishAot>to the<PropertyGroup>...</PropertyGroup>, so that when wedotnet publish, it uses Native AOT.
Now, publish the app for .NET 7. I’m currently targeting Linux for x64, so I’m using linux-x64, but you can follow along on Windows with a Windows identifier, like win-x64:
dotnet publish -f net7.0 -r linux-x64 -c ReleaseThat should successfully build the app, producing a standalone executable, and we can ls/dir the output directory to see the produced binary size (here I’ve used ls -s --block-size=k):
12820K /home/stoub/nativeaotexample/bin/Release/net7.0/linux-x64/publish/nativeaotexampleSo, on .NET 7 on Linux, this “Hello, world” application, including all necessary library support, the GC, everything, is ~13Mb. Now, we can do the same for .NET 8:
dotnet publish -f net8.0 -r linux-x64 -c Releaseand again see the generated output size:
1536K /home/stoub/nativeaotexample/bin/Release/net8.0/linux-x64/publish/nativeaotexampleNow on .NET 8, that ~13MB has dropped to ~1.5M! We can get it smaller, too, using various supported configuration flags. First, we can set a size vs speed option introduced in dotnet/runtime#85133, adding <OptimizationPreference>Size</OptimizationPreference> to the .csproj. Then if I don’t need globalization-specific code and data and am ok utilizing an invariant mode, I can add <InvariantGlobalization>true</InvariantGlobalization>. Maybe I don’t care about having good stack traces if an exception occurs? dotnet/runtime#88235 added the <StackTraceSupport>false</StackTraceSupport> option. Add all of those and republish:
1248K /home/stoub/nativeaotexample/bin/Release/net8.0/linux-x64/publish/nativeaotexampleSweet.
A good chunk of those improvements came from a relentless effort that involved hacking away at the size, 10Kb here, 20Kb there. Some examples that drove down these sizes:
- There are a variety of data structures the Native AOT compiler needs to create that then need to be used by the runtime when the app executes. dotnet/runtime#77884 added support for these data structures, including ones containing pointers, to be stored into the application and then rehydrated at execution time. Even before being extended in a variety of ways by subsequent PRs, this shaved hundreds of kilobytes off the app size, on both Windows and Linux (but more so on Linux).
- Every type with a static field containing references has a data structure associated with it containing a few pointers. dotnet/runtime#78794 made those pointers relative, saving ~0.5% of the HelloWorld app size (at least on Linux, a bit less on Windows). dotnet/runtime#78801 did the same for another set of pointers, saving another ~1%.
- dotnet/runtime#79594 removed some over-aggressive tracking of types and methods that needed data stored about them for reflection. This saved another ~32Kb on HelloWorld.
- In some cases, generic type dictionaries were being created even if they were never used and thus empty. dotnet/runtime#82591 got rid of these, saving another ~1.5% on a simple ASP.NET minimal APIs app. dotnet/runtime#83367 saved another ~20Kb by ridding itself of other empty type dictionaries.
- Members declared on a generic type have their code copied and specialized for each value type that’s substituted for the generic type parameter. However, if with some tweaks those members can be made non-generic and moved out of the type, such as into a non-generic base type, that duplication can be avoided. dotnet/runtime#82923 did so for array enumerators, moving down the
IDisposableand non-genericIEnumeratorinterface implementations. CoreLibhas an implementation of an empty array enumerator that can be used when enumerating aT[]that’s empty, and that singleton may be used in non-array enumerables, e.g. enumerating an empty(IEnumerable<KeyValuePair<TKey, TValue>>)Dictionary<TKey, TValue>could produce that array enumerator singleton. That enumerator, however, has a reference to aT[], and in the Native AOT world, using the enumerator then means code needs to be produced for the various members ofT[]. If, however, the enumerator in question is for aT[]that’s unlikely to be used elsewhere (e.g.KeyValuePair<TKey, TValue>[]), dotnet/runtime#82899 supplies a specialized enumerator singleton that doesn’t referenceT[], avoiding forcing that code to be created and kept (for example, code for aDictionary<TKey, TValue>‘sIEnumerable<KeyValuePair<TKey, TValue>>).- No one ever calls the
Equals/GetHashCodemethods on theAsyncStateMachinestructs produced by the C# compiler for async methods; they’re a hidden implementation detail, but even so, such virtual methods are in general kept rooted in a Native AOT app (and whereas CoreCLR can use reflection to provide the implementation of these methods for value types, Native AOT needs customized code emitted for each). dotnet/runtime#83369 special-cased these to avoid them being kept, shaving another ~1% off a minimal APIs app. - dotnet/runtime#83937 reduced the size of static constructor contexts, data structures used to pass information about a type’s static
cctorbetween portions of the system. - dotnet/runtime#84463 made a few tweaks that ended up avoiding creating
MethodTables fordouble/floatand that reduced reliance on some array methods, shaving another ~3% off HelloWorld. - dotnet/runtime#84156 manually split a method into two portions such that some lesser-used code isn’t always brought in when using the more commonly-used code; this saved another several hundred kilobytes.
- dotnet/runtime#84224 improved handling of the common pattern
typeof(T) == typeof(Something)that’s often used to do generic specialization (e.g. such as in code likeMemoryExtensions), doing it in a way that makes it easier to get rid of side effects from branches that are trimmed away. - The GC includes a vectorized sort implementation called
vxsort. When building with a configuration optimized for size, dotnet/runtime#85036 enabled removing that throughput optimization, saving several hundred kilobytes. ValueTuple<...>is a very handy type, but it brings a lot of code with it, as it implements multiple interfaces which then end up rooting functionality on the generic type parameters. dotnet/runtime#87120 removed a use ofValueTuple<T1, T2>fromSynchronizationContext, saving ~200Kb.- On Linux specifically, a large improvement came from dotnet/runtime#85139. Debug symbols were previously being stored in the published executable; with this change, symbols are stripped from the executable and are instead stored in a separate
.dbgfile built next to it. Someone who wants to revert to keeping the symbols in the executable can add<StripSymbols>false</StripSymbols>to in their project.
You get the idea. The improvements go beyond nipping and tucking here and there within the Native AOT compiler, though. Individual libraries also contributed. For example:
-
HttpClientsupports automatic decompression of response streams, for bothdeflateandbrotli, and that in turn means that anyHttpClientuse implicitly brings with it most ofSystem.IO.Compression. However, by default that decompression isn’t enabled, and you need to opt-in to it by explicitly setting theAutomaticDecompressionproperty on theHttpClientHandlerorSocketsHttpHandlerin use. So, dotnet/runtime#78198 employs a trick where rather thanSocketsHttpHandler‘s main code paths relying directly on the internalDecompressionHandlerthat does this work, it instead relies on a delegate. The field storing that delegate starts out as null, and then as part of theAutomaticDecompressionsetter, that field is set to a delegate that will do the decompression work. That means that if the trimmer doesn’t see any code accessing theAutomaticDecompressionsetter such that the setter can be trimmed away, then all of theDecompressionHandlerand its reliance onDeflateStreamandBrotliStreamcan also be trimmed away. Since it’s a little confusing to read, here’s a representation of it:private DecompressionMethods _automaticDecompression; private Func<Stream, Stream>? _getStream; public DecompressionMethods AutomaticDecompression { get => _automaticDecompression; set { _automaticDecompression = value; _getStream ??= CreateDecompressionStream; } } public Stream GetStreamAsync() { Stream response = ...; return _getStream is not null ? _getStream(response) : response; } private static Stream CreateDecompressionStream(Stream stream) => UseGZip ? new GZipStream(stream, CompressionMode.Decompress) : UseZLib ? new ZLibStream(stream, CompressionMode.Decompress) : UseBrotli ? new BrotliStream(stream, CompressionMode.Decompress) : stream; }The
CreateDecompressionStreammethod here is the one that references all of the compression-related code, and the only code path that touches it is in theAutomaticDecompressionsetter. Therefore, if nothing in the app accesses the setter, the setter can be trimmed, which means theCreateDecompressionStreammethod can also be trimmed, which means if nothing else in the app is using these compression streams, they can also be trimmed. - dotnet/runtime#80884 is another example, saving ~90Kb of size when
Regexis used by just being a bit more intentional about what types are being used in its implementation (e.g. using abool[30]instead of aHashSet<UnicodeCategory>to store a bitmap). - Or particularly interesting, dotnet/runtime#84169, which adds a new feature switch to
System.Xml. Various APIs inSystem.XmluseUri, which can trigger use ofXmlUrlResolver, which in turn references the networking stack; an app that’s using XML but not otherwise using networking can end up inadvertently bringing in upwards of 3MB of networking code, just by using an API likeXDocument.Load("filepath.xml"). Such an app can use the<XmlResolverIsNetworkingEnabledByDefault>MSBuild property added in dotnet/sdk#34412 to enable all of those code paths in XML to be trimmed away. ActivatorUtilities.CreateFactoryinMicrosoft.Extensions.DependencyInjection.Abstractionstries to optimize throughput by spending some time upfront to build a factory that’s then very efficient at creating things. Its main strategy for doing so involved usingSystem.Linq.Expressionsas a simpler API for using reflection emit, building up custom IL for the exact thing being constructed. When you have a JIT, that can work very well. But when dynamic code isn’t supported,System.Linq.Expressionscan’t use reflection emit and instead falls back to using an interpreter. That makes such an “optimization” inCreateFactoryactually a deoptimization, plus it brings with it the size impact ofSystem.Linq.Expression.dll. dotnet/runtime#81262 adds a reflection-based alternative for when!RuntimeFeature.IsDynamicCodeSupported, resulting in faster code and allowing theSystem.Linq.Expressionusage to be trimmed away.
Of course, while size was a large focus for .NET 8, there are a multitude of other ways in which performance with Native AOT has improved. For example, dotnet/runtime#79709 and dotnet/runtime#80969 avoid helper calls as part of reading static fields. BenchmarkDotNet works with Native AOT as well, so we can run the following benchmark to compare; instead of using --runtimes net7.0 net8.0, we just use --runtimes nativeaot7.0 nativeaot8.0 (BenchmarkDotNet also currently doesn’t support the [DisassemblyDiagnoser] with Native AOT):
// dotnet run -c Release -f net7.0 --filter "*" --runtimes nativeaot7.0 nativeaot8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private static readonly int s_configValue = 42;
[Benchmark]
public int GetConfigValue() => s_configValue;
}For that, BenchmarkDotNet outputs:
| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| GetConfigValue | NativeAOT 7.0 | 1.1759 ns | 1.000 |
| GetConfigValue | NativeAOT 8.0 | 0.0000 ns | 0.000 |
including:
// * Warnings *
ZeroMeasurement
Tests.GetConfigValue: Runtime=NativeAOT 8.0, Toolchain=Latest ILCompiler -> The method duration is indistinguishable from the empty method duration(When looking at the output of optimizations, that warning always brings a smile to my face.)
dotnet/runtime#83054 is another good example. It improves upon EqualityComparer<T> support in Native AOT by ensuring that the comparer can be stored in a static readonly to enable better constant folding in consumers.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes nativeaot7.0 nativeaot8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Runtime.CompilerServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly int[] _array = Enumerable.Range(0, 1000).ToArray();
[Benchmark]
public int FindIndex() => FindIndex(_array, 999);
[MethodImpl(MethodImplOptions.NoInlining)]
private static int FindIndex<T>(T[] array, T value)
{
for (int i = 0; i < array.Length; i++)
if (EqualityComparer<T>.Default.Equals(array[i], value))
return i;
return -1;
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| FindIndex | NativeAOT 7.0 | 876.2 ns | 1.00 |
| FindIndex | NativeAOT 8.0 | 367.8 ns | 0.42 |
As another example, dotnet/runtime#83911 avoids some overhead related to static class initialization. As we discussed in the JIT section, the JIT is able to rely on tiering to know that a static field accessed by a method must have already been initialized if the method is being promoted from tier 0 to tier 1, but tiering doesn’t exist in the Native AOT world, so this PR adds a fast-path check to help avoid most of the costs.
Other fundamental support has also improved. dotnet/runtime#79519, for example, changes how locks are implemented for Native AOT, employing a hybrid approach that starts with a lightweight spinlock and upgrades to using the System.Threading.Lock type (which is currently internal to Native AOT but likely to ship publicly in .NET 9).
VM
The VM is, loosely speaking, the part of the runtime that’s not the JIT or the GC. It’s what handles things like assembly and type loading. While there were a multitude of improvements throughout, I’ll call out three notable improvements.
First, dotnet/runtime#79021 optimized the operation of mapping an instruction pointer to a MethodDesc (a data structure that represents a method, with various pieces of information about it, like its signature), which happens in particular any time stack walking is performed (e.g. exception handling, Environment.Stacktrace, etc.) and as part of some delegate creations. The change not only makes this conversion faster but also mostly lock-free, which means on a benchmark like the following, there’s a significant improvement for sequential use but an even larger one for multi-threaded use:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Runtime.CompilerServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
[Benchmark]
public void InSerial()
{
for (int i = 0; i < 10_000; i++)
{
CreateDelegate<string>();
}
}
[Benchmark]
public void InParallel()
{
Parallel.For(0, 10_000, i =>
{
CreateDelegate<string>();
});
}
[MethodImpl(MethodImplOptions.NoInlining)]
private static Action<T> CreateDelegate<T>() => new Action<T>(GenericMethod);
private static void GenericMethod<T>(T t) { }
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| InSerial | .NET 7.0 | 1,868.4 us | 1.00 |
| InSerial | .NET 8.0 | 706.5 us | 0.38 |
| InParallel | .NET 7.0 | 1,247.3 us | 1.00 |
| InParallel | .NET 8.0 | 222.9 us | 0.18 |
Second, dotnet/runtime#83632 improves the performance of the ExecutableAllocator. This allocator is responsible for allocation related to all executable memory in the runtime, e.g. the JIT uses it to get memory into which to write the generated code that will then need to be executed. When memory is mapped, it has permissions associated with it for what can be done with that memory, e.g. can it be read and written, can it be executed, etc. The allocator maintains a cache, and this PR improved the performance of the allocator by reducing the number of cache misses incurred and reducing the cost of those cache misses when they do occur.
Third, dotnet/runtime#85743 makes a variety of changes focused on significantly reducing startup time. This includes reducing the amount of time spent on validation of types in R2R images, making lookups for generic parameters and nested types in R2R images much faster due to dedicated metadata in the R2R image, converting an O(n^2) lookup into an O(1) lookup by storing an additional index in a method description, and ensuring that vtable chunks are always shared.
GC
At the beginning of this post, I suggested that <ServerGarbageCollection>true</ServerGarbageCollection> be added to the csproj used for running the benchmarks in this post. That setting configures the GC to run in “server” mode, as opposed to “workstation” mode. The workstation mode was designed for use with client applications and is less resource intensive, preferring to use less memory but at the possible expense of throughput and scalability if the system is placed under heavier load. In contrast, the server mode was designed for larger-scale services. It is much more resource hungry, with a dedicated heap by default per logical core in the machine, and a dedicated thread per heap for servicing that heap, but it is also significantly more scalable. This tradeoff often leads to complication, as while applications might demand the scalability of the server GC, they may also want memory consumption closer to that of workstation, at least at times when demand is lower and the service needn’t have so many heaps.
In .NET 8, the server GC now has support for a dynamic heap count, thanks to dotnet/runtime#86245,
dotnet/runtime#87618, and dotnet/runtime#87619, which add a feature dubbed “Dynamic Adaptation To Application Sizes”, or DATAS. It’s off-by-default in .NET 8 in general (though on-by-default when publishing for Native AOT), but it can be enabled trivially, either by setting the DOTNET_GCDynamicAdaptationMode environment variable to 1, or via the <GarbageCollectionAdaptationMode>1</GarbageCollectionAdaptationMode> MSBuild property. The employed algorithm is able to increase and decrease the heap count over time, trying to maximize its view of throughput, and maintaining a balance between that and overall memory footprint.
Here’s a simple example. I create a console app with <ServerGarbageCollection>true</ServerGarbageCollection> in the .csproj and the following code in Program.cs, which just spawns a bunch of threads that continually allocate, and then repeatedly prints out the working set:
// dotnet run -c Release -f net8.0
using System.Diagnostics;
for (int i = 0; i < 32; i++)
{
new Thread(() =>
{
while (true) Array.ForEach(new byte[1], b => { });
}).Start();
}
using Process process = Process.GetCurrentProcess();
while (true)
{
process.Refresh();
Console.WriteLine($"{process.WorkingSet64:N0}");
Thread.Sleep(1000);
}When I run that, I consistently see output like:
154,226,688
154,226,688
154,275,840
154,275,840
154,816,512
154,816,512
154,816,512
154,824,704
154,824,704
154,824,704When I then add <GarbageCollectionAdaptationMode>1</GarbageCollectionAdaptationMode> to the .csproj, the working set drops significantly:
71,430,144
72,187,904
72,196,096
72,196,096
72,245,248
72,245,248
72,245,248
72,245,248
72,245,248
72,253,440For a more detailed examination of the feature and plans for it, see Dynamically Adapting To Application Sizes.
Mono
Thus far I’ve referred to “the runtime”, “the JIT”, “the GC”, and so on. That’s all in the context of the “CoreCLR” runtime, which is the primary runtime used for console applications, ASP.NET applications, services, desktop applications, and the like. For mobile and browser .NET applications, however, the primary runtime used is the “Mono” runtime. And it also has seen some huge improvements in .NET 8, improvements that accrue to scenarios like Blazor WebAssembly apps.
Just as how with CoreCLR there’s both the ability to JIT and AOT, there are multiple ways in which code can be shipped for Mono. Mono includes an AOT compiler; for WASM in particular, the AOT compiler enables all of the IL to be compiled to WASM, which is then shipped down to the browser. As with CoreCLR, however, AOT is opt-in. The default experience for WASM is to use an interpreter: the IL is shipped down to the browser, and the interpreter (which itself is compiled to WASM) then interprets the IL. Of course, interpretation has performance implications, and so .NET 7 augmented the interpreter with a tiering scheme similar in concept to the tiering employed by the CoreCLR JIT. The interpreter has its own representation of the code to be interpreted, and the first few times a method is invoked, it just interprets that byte code with little effort put into optimizing it. Then after enough invocations, the interpreter will take some time to optimize that internal representation so as to speed up subsequent interpretations. Even with that, however, it’s still interpreting: it’s still an interpreter implemented in WASM reading instructions for what to do and doing them. One of the most notable improvements to Mono in .NET 8 expands on this tiering by introducing a partial JIT into the interpreter. dotnet/runtime#76477 provided the initial code for this “jiterpreter,” as some folks refer to it. As part of the interpreter, this JIT is able to participate in the same data structures used by the interpreter and process the same byte code, and works by replacing sequences of that byte code with on-the-fly generated WASM. That could be a whole method, it could just be a hot loop within a method, or it could be just a few instructions. This provides significant flexibility, including a very progressive on-ramp where optimizations can be added incrementally, shifting more and more logic from interpretation to jitted WASM. Dozens of PRs went into making the jiterpreter a reality for .NET 8, such as dotnet/runtime#82773 that added basic SIMD support, dotnet/runtime#82756 that added basic loop support, and dotnet/runtime#83247 that added a control-flow optimization pass.
Let’s see this in action. I created a new .NET 7 Blazor WebAssembly project, added a NuGet reference to the System.IO.Hashing project, and replaced the contents of Counter.razor with the following:
@page "/counter"
@using System.Diagnostics;
@using System.IO.Hashing;
@using System.Text;
@using System.Threading.Tasks;
<h1>.NET 7</h1>
<p role="status">Current time: @_time</p>
<button class="btn btn-primary" @onclick="Hash">Click me</button>
@code {
private TimeSpan _time;
private void Hash()
{
var sw = Stopwatch.StartNew();
for (int i = 0; i < 50_000; i++) XxHash64.HashToUInt64(_data);
_time = sw.Elapsed;
}
private byte[] _data =
@"Shall I compare thee to a summer's day?
Thou art more lovely and more temperate:
Rough winds do shake the darling buds of May,
And summer's lease hath all too short a date;
Sometime too hot the eye of heaven shines,
And often is his gold complexion dimm'd;
And every fair from fair sometime declines,
By chance or nature's changing course untrimm'd;
But thy eternal summer shall not fade,
Nor lose possession of that fair thou ow'st;
Nor shall death brag thou wander'st in his shade,
When in eternal lines to time thou grow'st:
So long as men can breathe or eyes can see,
So long lives this, and this gives life to thee."u8.ToArray();
}Then I did the exact same thing, but for .NET 8, built both in Release, and ran them both. When the resulting page opened for each, I clicked the “Click me” button (a few times, but it didn’t change the results).
The timing measurements for how long the operation took in .NET 7 compared to .NET 8 speak for themselves.
Beyond the jiterpreter, the interpreter itself saw a multitude of improvements, for example:
- dotnet/runtime#79165 added special handling of the
stobjIL instruction for when the value type doesn’t contain any references, and thus doesn’t need to interact with the GC. - dotnet/runtime#80046 special-cased a compare followed by
brtrue/brfalse, creating a single interpreter opcode for the very common pattern. - dotnet/runtime#79392 added an intrinsic to the interpreter for string creation.
- dotnet/runtime#78840 added a cache to the Mono runtime (including for but not limited to the interpreter) for various pieces of information about types, like
IsValueType,IsGenericTypeDefinition, andIsDelegate. - dotnet/runtime#81782 added intrinsics for some of the most common operations on
Vector128, and dotnet/runtime#86859 augmented this to use those same opcodes forVector<T>. - dotnet/runtime#83498 special-cased division by powers of 2 to instead employ shifts.
- dotnet/runtime#83490 tweaked the inlining size limit to ensure that key methods could be inlined, like
List<T>‘s indexer. - dotnet/runtime#85528 added devirtualization support in situations where enough type information is available to enable doing so.
I’ve already alluded several times to vectorization in Mono, but in its own right this has been a big area of focus for Mono in .NET 8, across all backends. As of dotnet/runtime#86546, which completed adding Vector128<T> support for Mono’s AMD64 JIT backend, Vector128<T> is now supported across all Mono backends. Mono’s WASM backends not only support Vector128<T>, .NET 8 includes the new System.Runtime.Intrinsics.Wasm.PackedSimd type, which is specific to WASM and exposes hundreds of overloads that map down to WASM SIMD operations. The basis for this type was introduced in dotnet/runtime#73289, where the initial SIMD support was added as internal. dotnet/runtime#76539 continued the effort by adding more functionality and also making the type public, as it now is in .NET 8. Over a dozen PRs continued to build it out, such as dotnet/runtime#80145 that added ConditionalSelect intrinsics, dotnet/runtime#87052 and dotnet/runtime#87828 that added load and store intrinsics, dotnet/runtime#85705 that added floating-point support, and dotnet/runtime#88595, which overhauled the surface area based on learnings since its initial design.
Another effort in .NET 8, related to app size, has been around reducing reliance on ICU’s data files (ICU is the globalization library employed by .NET and many other systems). Instead, the goal is to rely on the target platform’s native APIs wherever possible (for WASM, APIs provided by the browser). This effort is referred to as “hybrid globalization,” because the dependence on ICU’s data files still remains, it’s just lessened, and it comes with behavioral changes, so it’s opt-in for situations where someone really wants the smaller size and is willing to deal with the behavioral accommodations. A multitude of PRs have also gone into making this a reality for .NET 8, such as dotnet/runtime#81470, dotnet/runtime#84019, and dotnet/runtime#84249. To enable the feature, you can add <HybridGlobalization>true</HybridGlobalization> to your .csproj, and for more information, there’s a good design document that goes into much more depth.
Threading
Recent releases of .NET saw huge improvements to the area of threading, parallelism, concurrency, and asynchrony, such as a complete rewrite of the ThreadPool (in .NET 6 and .NET 7), a complete rewrite of the async method infrastructure (in .NET Core 2.1), a complete rewrite of ConcurrentQueue<T> (in .NET Core 2.0), and so on. This release doesn’t include such massive overhauls, but it does include some thoughtful and impactful improvements.
ThreadStatic
The .NET runtime makes it easy to associate data with a thread, often referred to as thread-local storage (TLS). The most common way to achieve this is by annotating a static field with the [ThreadStatic] attribute (another for more advanced uses is via the ThreadLocal<T> type), which causes the runtime to replicate the storage for that field to be per thread rather than global for the process.
private static int s_onePerProcess;
[ThreadStatic]
private static int t_onePerThread;Historically, accessing such a [ThreadStatic] field has required a non-inlined JIT helper call (e.g. CORINFO_HELP_GETSHARED_NONGCTHREADSTATIC_BASE_NOCTOR), but now with dotnet/runtime#82973 and dotnet/runtime#85619, the common and fast path from that helper can be inlined into the caller. We can see this with a simple benchmark that just increments an int stored in a [ThreadStatic].
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
// dotnet run -c Release -f net7.0 --filter "*" --runtimes nativeaot7.0 nativeaot8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public partial class Tests
{
[ThreadStatic]
private static int t_value;
[Benchmark]
public int Increment() => ++t_value;
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Increment | .NET 7.0 | 8.492 ns | 1.00 |
| Increment | .NET 8.0 | 1.453 ns | 0.17 |
[ThreadStatic] was similarly optimized for Native AOT, via both dotnet/runtime#84566 and dotnet/runtime#87148:
| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Increment | NativeAOT 7.0 | 2.305 ns | 1.00 |
| Increment | NativeAOT 8.0 | 1.325 ns | 0.57 |
ThreadPool
Let’s try an experiment. Create a new console app, and add <PublishAot>true</PublishAot> to the .csproj. Then make the entirety of the program this:
// dotnet run -c Release -f net8.0
Task.Run(() => Console.WriteLine(Environment.StackTrace)).Wait();The idea is to see the stack trace of a work item running on a ThreadPool thread. Now run it, and you should see something like this:
at System.Environment.get_StackTrace()
at Program.<>c.<<Main>$>b__0_0()
at System.Threading.ExecutionContext.RunFromThreadPoolDispatchLoop(Thread threadPoolThread, ExecutionContext executionContext, ContextCallback callback, Object state)
at System.Threading.Tasks.Task.ExecuteWithThreadLocal(Task& currentTaskSlot, Thread threadPoolThread)
at System.Threading.ThreadPoolWorkQueue.Dispatch()
at System.Threading.PortableThreadPool.WorkerThread.WorkerThreadStart()The important piece here is the bottom line: we see we’re being called from the PortableThreadPool, which is the managed thread pool implementation that’s been used across operating systems since .NET 6. Now, instead of running directly, let’s publish for Native AOT and run the resulting app (for the specific thing we’re looking for, this part should be done on Windows).
dotnet publish -c Release -r win-x64
D:\examples\tmpapp\bin\Release\net8.0\win-x64\publish\tmpapp.exeNow, we see this:
at System.Environment.get_StackTrace() + 0x21
at Program.<>c.<<Main>$>b__0_0() + 0x9
at System.Threading.ExecutionContext.RunFromThreadPoolDispatchLoop(Thread, ExecutionContext, ContextCallback, Object) + 0x3d
at System.Threading.Tasks.Task.ExecuteWithThreadLocal(Task&, Thread) + 0xcc
at System.Threading.ThreadPoolWorkQueue.Dispatch() + 0x289
at System.Threading.WindowsThreadPool.DispatchCallback(IntPtr, IntPtr, IntPtr) + 0x45Again, note the last line: “WindowsThreadPool.” Applications published with Native AOT on Windows have historically used a ThreadPool implementation that wraps the Windows thread pool. The work item queues and dispatching code is all the same as with the portable pool, but the thread management itself is delegated to the Windows pool. Now in .NET 8 with dotnet/runtime#85373, projects on Windows have the option of using either pool; Native AOT apps can opt to instead use the portable pool, and other apps can opt to instead use the Windows pool. Opting in or out is easy: in a <PropertyGroup/> in the .csproj, add <UseWindowsThreadPool>false</UseWindowsThreadPool> to opt-out in a Native AOT app, and conversely use true in other apps to opt-in. When using this MSBuild switch, in a Native AOT app, whichever pool isn’t being used can automatically be trimmed away. For experimentation, the DOTNET_ThreadPool_UseWindowsThreadPool environment variable can also be set to 0 or 1 to explicitly opt out or in, respectively.
There’s currently no hard-and-fast rule about why one pool might be better; the option has been added to allow developers to experiment. We’ve seen with the Windows pool that I/O doesn’t scale as well on larger machines as it does with the portable pool. However, if the Windows thread pool is already being used heavily elsewhere in the application, consolidating into the same pool can reduce oversubscription. Further, if thread pool threads get blocked very frequently, the Windows thread pool has more information about that blocking and can potentially handle those scenarios more efficiently. We can see this with a simple example. Compile this code:
// dotnet run -c Release -f net8.0
using System.Diagnostics;
var sw = Stopwatch.StartNew();
var barrier = new Barrier(Environment.ProcessorCount * 2 + 1);
for (int i = 0; i < barrier.ParticipantCount; i++)
{
ThreadPool.QueueUserWorkItem(id =>
{
Console.WriteLine($"{sw.Elapsed}: {id}");
barrier.SignalAndWait();
}, i);
}
barrier.SignalAndWait();
Console.WriteLine($"Done: {sw.Elapsed}");This is a dastardly repro that creates a bunch of work items, all of which block until all of the work items have been processed: basically it takes every thread the thread pool gives it and never gives it back (until the program exits). When I run this on my machine where Environment.ProcessorCount is 12, I get output like this:
00:00:00.0038906: 0
00:00:00.0038911: 1
00:00:00.0042401: 4
00:00:00.0054198: 9
00:00:00.0047249: 6
00:00:00.0040724: 3
00:00:00.0044894: 5
00:00:00.0052228: 8
00:00:00.0049638: 7
00:00:00.0056831: 10
00:00:00.0039327: 2
00:00:00.0057127: 11
00:00:01.0265278: 12
00:00:01.5325809: 13
00:00:02.0471848: 14
00:00:02.5628161: 15
00:00:03.5805581: 16
00:00:04.5960218: 17
00:00:05.1087192: 18
00:00:06.1142907: 19
00:00:07.1331915: 20
00:00:07.6467355: 21
00:00:08.1614072: 22
00:00:08.6749720: 23
00:00:08.6763938: 24
Done: 00:00:08.6768608The portable pool quickly injects Environment.ProcessorCount threads, but after that it proceeds to only inject an additional thread once or twice a second. Now, set DOTNET_ThreadPool_UseWindowsThreadPool to 1 and try again:
00:00:00.0034909: 3
00:00:00.0036281: 4
00:00:00.0032404: 0
00:00:00.0032727: 1
00:00:00.0032703: 2
00:00:00.0447256: 5
00:00:00.0449398: 6
00:00:00.0451899: 7
00:00:00.0454245: 8
00:00:00.0456907: 9
00:00:00.0459155: 10
00:00:00.0461399: 11
00:00:00.0463612: 12
00:00:00.0465538: 13
00:00:00.0467497: 14
00:00:00.0469477: 15
00:00:00.0471055: 16
00:00:00.0472961: 17
00:00:00.0474888: 18
00:00:00.0477131: 19
00:00:00.0478795: 20
00:00:00.0480844: 21
00:00:00.0482900: 22
00:00:00.0485110: 23
00:00:00.0486981: 24
Done: 00:00:00.0498603Zoom. The Windows pool is much more aggressive about injecting threads here. Whether that’s good or bad can depend on your scenario. If you’ve found yourself setting a really high minimum thread pool thread count for your application, you might want to give this option a go.
Tasks
Even with all the improvements to async/await in previous releases, this release sees async methods get cheaper still, both when they complete synchronously and when they complete asynchronously.
When an async Task/Task<TResult>-returning method completes synchronously, it tries to give back a cached task object rather than creating one a new and incurring the allocation. In the case of Task, that’s easy, it can simply use Task.CompletedTask. In the case of Task<TResult>, it uses a cache that stores cached tasks for some TResult values. When TResult is Boolean, for example, it can successfully cache a Task<bool> for both true and false, such that it’ll always successfully avoid the allocation. For int, it caches a few tasks for common values (e.g. -1 through 8). For reference types, it caches a task for null. And for the primitive integer types (sbyte, byte, short, ushort, char, int, uint, long, ulong, nint, and nuint), it caches a task for 0. It used to be that all of this logic was dedicated to async methods, but in .NET 6 that logic moved into Task.FromResult, such that all use of Task.FromResult now benefits from this caching. In .NET 8, thanks to dotnet/runtime#76349 and dotnet/runtime#87541, the caching is improved further. In particular, the optimization of caching a task for 0 for the primitive types is extended to be the caching of a task for default(TResult) for any value type TResult that is 1, 2, 4, 8, or 16 bytes. In such cases, we can do an unsafe cast to one of these primitives, and then use that primitive’s equality to compare against default. If that comparison is true, it means the value is entirely zeroed, which means we can use a cached task for Task<TResult> created from default(TResult), as that is also entirely zeroed. What if that type has a custom equality comparer? That actually doesn’t matter, since the original value and the one stored in the cached task have identical bit patterns, which means they’re indistinguishable. The net effect of this is we can cache tasks for other commonly used types.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
[Benchmark] public async Task<TimeSpan> ZeroTimeSpan() => TimeSpan.Zero;
[Benchmark] public async Task<DateTime> MinDateTime() => DateTime.MinValue;
[Benchmark] public async Task<Guid> EmptyGuid() => Guid.Empty;
[Benchmark] public async Task<DayOfWeek> Sunday() => DayOfWeek.Sunday;
[Benchmark] public async Task<decimal> ZeroDecimal() => 0m;
[Benchmark] public async Task<double> ZeroDouble() => 0;
[Benchmark] public async Task<float> ZeroFloat() => 0;
[Benchmark] public async Task<Half> ZeroHalf() => (Half)0f;
[Benchmark] public async Task<(int, int)> ZeroZeroValueTuple() => (0, 0);
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| ZeroTimeSpan | .NET 7.0 | 31.327 ns | 1.00 | 72 B | 1.00 |
| ZeroTimeSpan | .NET 8.0 | 8.851 ns | 0.28 | – | 0.00 |
| MinDateTime | .NET 7.0 | 31.457 ns | 1.00 | 72 B | 1.00 |
| MinDateTime | .NET 8.0 | 8.277 ns | 0.26 | – | 0.00 |
| EmptyGuid | .NET 7.0 | 32.233 ns | 1.00 | 80 B | 1.00 |
| EmptyGuid | .NET 8.0 | 9.013 ns | 0.28 | – | 0.00 |
| Sunday | .NET 7.0 | 30.907 ns | 1.00 | 72 B | 1.00 |
| Sunday | .NET 8.0 | 8.235 ns | 0.27 | – | 0.00 |
| ZeroDecimal | .NET 7.0 | 33.109 ns | 1.00 | 80 B | 1.00 |
| ZeroDecimal | .NET 8.0 | 13.110 ns | 0.40 | – | 0.00 |
| ZeroDouble | .NET 7.0 | 30.863 ns | 1.00 | 72 B | 1.00 |
| ZeroDouble | .NET 8.0 | 8.568 ns | 0.28 | – | 0.00 |
| ZeroFloat | .NET 7.0 | 31.025 ns | 1.00 | 72 B | 1.00 |
| ZeroFloat | .NET 8.0 | 8.531 ns | 0.28 | – | 0.00 |
| ZeroHalf | .NET 7.0 | 33.906 ns | 1.00 | 72 B | 1.00 |
| ZeroHalf | .NET 8.0 | 9.008 ns | 0.27 | – | 0.00 |
| ZeroZeroValueTuple | .NET 7.0 | 33.339 ns | 1.00 | 72 B | 1.00 |
| ZeroZeroValueTuple | .NET 8.0 | 11.274 ns | 0.34 | – | 0.00 |
Those changes helped some async methods to become leaner when they complete synchronously. Other changes have helped practically all async methods to become leaner when they complete asynchronously. When an async method suspends for the first time, assuming it’s returning Task/Task<TResult>/ValueTask/ValueTask<TResult> and the default async method builders are in use (i.e. they haven’t been overridden using [AsyncMethodBuilder(...)] on the method in question), a single allocation occurs: the task object to be returned. That task object is actually a type derived from Task (in the implementation today the internal type is called AsyncStateMachineBox<TStateMachine>) and that has on it a strongly-typed field for the state machine struct generated by the C# compiler. In fact, as of .NET 7, it has three additional fields beyond what’s on the base Task<TResult>:
- One to hold the
TStateMachinestate machine struct generated by the C# compiler. - One to cache an
Actiondelegate that points toMoveNext. - One to store an
ExecutionContextto flow to the nextMoveNextinvocation.
If we can trim down the fields required, we can make every async method less expensive by allocating smaller instead of larger objects. That’s exactly what dotnet/runtime#83696 and dotnet/runtime#83737 accomplish, together shaving 16 bytes (in a 64-bit process) off the size of every such async method task. How?
The C# language allows anything to be awaitable as long as it follows the right pattern, exposing a GetAwaiter() method that returns a type with the right shape. That pattern includes a set of “OnCompleted” methods that take an Action delegate, enabling the async method builder to provide a continuation to the awaiter, such that when the awaited operation completes, it can invoke the Action to resume the method’s processing. As such, the AsyncStateMachineBox type has on it a field used to cache an Action delegate that’s lazily created to point to its MoveNext method; that Action is created during the first suspending await where it’s needed and can then be used for all subsequent awaits, such that the Action is allocated at most once for the lifetime of an async method, regardless of how many times the invocation suspends. (The delegate is only needed, however, if the state machine awaits something that’s not a known awaiter; the runtime has fast paths that avoid requiring that Action when awaiting all of the built-in awaiters). Interestingly, though, Task itself has a field for storing a delegate, and that field is only used when the Task is created to invoke a delegate (e.g. Task.Run, ContinueWith, etc.). Since most tasks allocated today come from async methods, that means that the majority of tasks have all had a wasted field. It turns out we can just use that base field on the Task for this cached MoveNext Action as well, making the field relevant to almost all tasks, and allowing us to remove the extra Action field on the state machine box.
There’s another existing field on the base Task that also goes unused in async methods: the state object field. When you use a method like StartNew or ContinueWith to create a Task, you can provide an object state that’s then passed to the Task‘s delegate. In an async method, though, the field just sits there, unused, lonely, forgotten, forelorn. Instead of having a separate field for the ExecutionContext, then, we can just store the ExecutionContext in this existing state field (being careful not to allow it to be exposed via the Task‘s AsyncState property that normally exposes the object state).
We can see the effect of getting rid of those two fields with a simple benchmark like this:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
[Benchmark]
public async Task YieldOnce() => await Task.Yield();
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| YieldOnce | .NET 7.0 | 918.6 ns | 1.00 | 112 B | 1.00 |
| YieldOnce | .NET 8.0 | 865.8 ns | 0.94 | 96 B | 0.86 |
Note the 16-byte decrease just as we predicted.
Async method overheads are reduced in other ways, too. dotnet/runtime#82181, for example, shrinks the size of the ManualResetValueTaskSourceCore<TResult> type that’s used as the workhorse for custom IValueTaskSource/IValueTaskSource<TResult> implementations; it takes advantage of the 99.9% case to use a single field for something that previously required two fields. But my favorite addition in this regard is dotnet/runtime#22144, which adds new ConfigureAwait overloads. Yes, I know ConfigureAwait is a sore subject with some, but these new overloads a) address a really useful scenario that many folks end up writing their own custom awaiters for, b) do it in a way that’s cheaper than custom solutions can provide, and c) actually help with the ConfigureAwait naming, as it fulfills the original purpose of ConfigureAwait that led us to name it that in the first place. When ConfigureAwait was originally devised, we debated many names, and we settled on “ConfigureAwait” because that’s what it was doing: it was allowing you to provide arguments that configured how the await behaved. Of course, for the last decade, the only configuration you’ve been able to do is pass a single Boolean to indicate whether to capture the current context / scheduler or not, and that in part has led folks to bemoan the naming as overly verbose for something that’s a single bool. Now in .NET 8, there are new overloads of ConfigureAwait that take a ConfigureAwaitOptions enum:
[Flags]
public enum ConfigureAwaitOptions
{
None = 0,
ContinueOnCapturedContext = 1,
SuppressThrowing = 2,
ForceYielding = 4,
}ContinueOnCapturedContext you know; that’s the same as ConfigureAwait(true) today. ForceYielding is something that comes up now and again in various capacities, but essentially you’re awaiting something and rather than continuing synchronously if the thing you’re awaiting has already completed by the time you await it, you effectively want the system to pretend it’s not completed even if it is. Then rather than continuing synchronously, the continuation will always end up running asynchronously from the caller. This can be helpful as an optimization in a variety of ways. Consider this code that was in SocketsHttpHandler‘s HTTP/2 implementation in .NET 7:
private void DisableHttp2Connection(Http2Connection connection)
{
_ = Task.Run(async () => // fire-and-forget
{
bool usable = await connection.WaitForAvailableStreamsAsync().ConfigureAwait(false);
... // other stuff
};
}With ForceYielding in .NET 8, the code is now:
private void DisableHttp2Connection(Http2Connection connection)
{
_ = DisableHttp2ConnectionAsync(connection); // fire-and-forget
async Task DisableHttp2ConnectionAsync(Http2Connection connection)
{
bool usable = await connection.WaitForAvailableStreamsAsync().ConfigureAwait(ConfigureAwaitOptions.ForceYielding);
.... // other stuff
}
}Rather than have a separate Task.Run, we’ve just piggy-backed on the await for the task returned from WaitForAvailableStreamsAsync (which we know will quickly return the task to us), ensuring that the work that comes after it doesn’t run synchronously as part of the call to DisableHttp2Connection. Or imagine you had code that was doing:
return Task.Run(WorkAsync);
static async Task WorkAsync()
{
while (...) await Something();
}This is using Task.Run to queue an async method’s invocation. That async method results in a Task being allocated, plus the Task.Run results in a Task being allocated, plus a work item needs to be queued to the ThreadPool, so at least three allocations. Now, this same functionality can be written as:
return WorkAsync();
static async Task WorkAsync()
{
await Task.CompletedTask.ConfigureAwait(ConfigureAwaitOptions.ForceYielding);
while (...) await Something();
}and rather than three allocations, we end up with just one: for the async Task. That’s because with all the optimizations introduced in previous releases, the state machine box object is also what will be queued to the thread pool.
Arguably the most valuable addition to this support, though, is SuppressThrowing. It does what it sounds like: when you await a task that completes in failure or cancellation, such that normally the await would propagate the exception, it won’t. So, for example, in System.Text.Json where we previously had this code:
// Exceptions should only be propagated by the resuming converter
try
{
await state.PendingTask.ConfigureAwait(false);
}
catch { }now we have this code:
// Exceptions should only be propagated by the resuming converter
await state.PendingTask.ConfigureAwait(ConfigureAwaitOptions.SuppressThrowing);or in SemaphoreSlim where we had this code:
await new ConfiguredNoThrowAwaiter<bool>(asyncWaiter.WaitAsync(TimeSpan.FromMilliseconds(millisecondsTimeout), cancellationToken));
if (cancellationToken.IsCancellationRequested)
{
// If we might be running as part of a cancellation callback, force the completion to be asynchronous.
await TaskScheduler.Default;
}
private readonly struct ConfiguredNoThrowAwaiter<T> : ICriticalNotifyCompletion, IStateMachineBoxAwareAwaiter
{
private readonly Task<T> _task;
public ConfiguredNoThrowAwaiter(Task<T> task) => _task = task;
public ConfiguredNoThrowAwaiter<T> GetAwaiter() => this;
public bool IsCompleted => _task.IsCompleted;
public void GetResult() => _task.MarkExceptionsAsHandled();
public void OnCompleted(Action continuation) => TaskAwaiter.OnCompletedInternal(_task, continuation, continueOnCapturedContext: false, flowExecutionContext: true);
public void UnsafeOnCompleted(Action continuation) => TaskAwaiter.OnCompletedInternal(_task, continuation, continueOnCapturedContext: false, flowExecutionContext: false);
public void AwaitUnsafeOnCompleted(IAsyncStateMachineBox box) => TaskAwaiter.UnsafeOnCompletedInternal(_task, box, continueOnCapturedContext: false);
}
internal readonly struct TaskSchedulerAwaiter : ICriticalNotifyCompletion
{
private readonly TaskScheduler _scheduler;
public TaskSchedulerAwaiter(TaskScheduler scheduler) => _scheduler = scheduler;
public bool IsCompleted => false;
public void GetResult() { }
public void OnCompleted(Action continuation) => Task.Factory.StartNew(continuation, CancellationToken.None, TaskCreationOptions.DenyChildAttach, _scheduler);
public void UnsafeOnCompleted(Action continuation)
{
if (ReferenceEquals(_scheduler, Default))
{
ThreadPool.UnsafeQueueUserWorkItem(s => s(), continuation, preferLocal: true);
}
else
{
OnCompleted(continuation);
}
}
}now we just have this:
await ((Task)asyncWaiter.WaitAsync(TimeSpan.FromMilliseconds(millisecondsTimeout), cancellationToken)).ConfigureAwait(ConfigureAwaitOptions.SuppressThrowing);
if (cancellationToken.IsCancellationRequested)
{
// If we might be running as part of a cancellation callback, force the completion to be asynchronous.
await Task.CompletedTask.ConfigureAwait(ConfigureAwaitOptions.ForceYielding);
}It is useful to note the (Task) cast that’s in there. WaitAsync returns a Task<bool>, but that Task<bool> is being cast to the base Task because SuppressThrowing is incompatible with Task<TResult>. That’s because, without an exception propagating, the await will complete successfully and return a TResult, which may be invalid if the task actually faulted. So if you have a Task<TResult> that you want to await with SuppressThrowing, cast to the base Task and await it, and then you can inspect the Task<TResult> immediately after the await completes. (If you do end up using ConfigureAwaitOptions.SuppressThrowing with a Task<TResult>, the CA2261 analyzer introduced in dotnet/roslyn-analyzers#6669 will alert you to it.)
The above example with SemaphoreSlim is using the new ConfigureAwaitOptions to replace a previous optimization added in .NET 8, as well. dotnet/runtime#83294 added to that ConfiguredNoThrowAwaiter<T> an implementation of the internal IStateMachineBoxAwareAwaiter interface, which is the special sauce that enables the async method builders to backchannel with a known awaiter to avoid the Action delegate allocation. Now that the behaviors this ConfiguredNoThrowAwaiter was providing are built-in, it’s no longer needed, and the built-in implementation enjoys the same privileges via IStateMachineBoxAwareAwaiter. The net result of these changes for SemaphoreSlim is that it now not only has simpler code, but faster code, too. Here’s a benchmark showing the decrease in execution time and allocation associated with SemaphoreAsync.WaitAsync calls that need to wait with a CancellationToken and/or timeout:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly CancellationToken _token = new CancellationTokenSource().Token;
private readonly SemaphoreSlim _sem = new SemaphoreSlim(0);
private readonly Task[] _tasks = new Task[100];
[Benchmark]
public Task WaitAsync()
{
for (int i = 0; i < _tasks.Length; i++)
{
_tasks[i] = _sem.WaitAsync(_token);
}
_sem.Release(_tasks.Length);
return Task.WhenAll(_tasks);
}
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| WaitAsync | .NET 7.0 | 85.48 us | 1.00 | 44.64 KB | 1.00 |
| WaitAsync | .NET 8.0 | 69.37 us | 0.82 | 36.02 KB | 0.81 |
There have been other improvements on other operations on Task as well. dotnet/runtime#81065 removes a defensive Task[] allocation from Task.WhenAll. It was previously doing a defensive copy such that it could then validate on the copy whether any of the elements were null (a copy because another thread could erroneously and concurrently null out elements); that’s a large cost to pay for argument validation in the face of multi-threaded misuse. Instead, the method will still validate whether null is in the input, and if a null slips through because the input collection was erroneously mutated concurrently with the synchronous call to WhenAll, it’ll just ignore the null at that point. In making these changes, the PR also special-cased a List<Task> input to avoid making a copy, as List<Task> is also one of the main types we see fed into WhenAll (e.g. someone builds up a list of tasks and then waits for all of them).
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Collections.ObjectModel;
using System.Runtime.CompilerServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
[Benchmark]
public void WhenAll_Array()
{
AsyncTaskMethodBuilder atmb1 = AsyncTaskMethodBuilder.Create();
AsyncTaskMethodBuilder atmb2 = AsyncTaskMethodBuilder.Create();
Task whenAll = Task.WhenAll(atmb1.Task, atmb2.Task);
atmb1.SetResult();
atmb2.SetResult();
whenAll.Wait();
}
[Benchmark]
public void WhenAll_List()
{
AsyncTaskMethodBuilder atmb1 = AsyncTaskMethodBuilder.Create();
AsyncTaskMethodBuilder atmb2 = AsyncTaskMethodBuilder.Create();
Task whenAll = Task.WhenAll(new List<Task>(2) { atmb1.Task, atmb2.Task });
atmb1.SetResult();
atmb2.SetResult();
whenAll.Wait();
}
[Benchmark]
public void WhenAll_Collection()
{
AsyncTaskMethodBuilder atmb1 = AsyncTaskMethodBuilder.Create();
AsyncTaskMethodBuilder atmb2 = AsyncTaskMethodBuilder.Create();
Task whenAll = Task.WhenAll(new ReadOnlyCollection<Task>(new[] { atmb1.Task, atmb2.Task }));
atmb1.SetResult();
atmb2.SetResult();
whenAll.Wait();
}
[Benchmark]
public void WhenAll_Enumerable()
{
AsyncTaskMethodBuilder atmb1 = AsyncTaskMethodBuilder.Create();
AsyncTaskMethodBuilder atmb2 = AsyncTaskMethodBuilder.Create();
var q = new Queue<Task>(2);
q.Enqueue(atmb1.Task);
q.Enqueue(atmb2.Task);
Task whenAll = Task.WhenAll(q);
atmb1.SetResult();
atmb2.SetResult();
whenAll.Wait();
}
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| WhenAll_Array | .NET 7.0 | 210.8 ns | 1.00 | 304 B | 1.00 |
| WhenAll_Array | .NET 8.0 | 160.9 ns | 0.76 | 264 B | 0.87 |
| WhenAll_List | .NET 7.0 | 296.4 ns | 1.00 | 376 B | 1.00 |
| WhenAll_List | .NET 8.0 | 185.5 ns | 0.63 | 296 B | 0.79 |
| WhenAll_Collection | .NET 7.0 | 271.3 ns | 1.00 | 360 B | 1.00 |
| WhenAll_Collection | .NET 8.0 | 199.7 ns | 0.74 | 328 B | 0.91 |
| WhenAll_Enumerable | .NET 7.0 | 328.2 ns | 1.00 | 472 B | 1.00 |
| WhenAll_Enumerable | .NET 8.0 | 230.0 ns | 0.70 | 432 B | 0.92 |
The generic WhenAny was also improved as part of dotnet/runtime#88154, which removes a Task allocation from an extra continuation that was an implementation detail. This is one of my favorite kinds of PRs: it not only improved performance, it also resulted in cleaner code, and less code.

// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Runtime.CompilerServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
[Benchmark]
public Task<Task<int>> WhenAnyGeneric_ListNotCompleted()
{
AsyncTaskMethodBuilder<int> atmb1 = default;
AsyncTaskMethodBuilder<int> atmb2 = default;
AsyncTaskMethodBuilder<int> atmb3 = default;
Task<Task<int>> wa = Task.WhenAny(new List<Task<int>>() { atmb1.Task, atmb2.Task, atmb3.Task });
atmb3.SetResult(42);
return wa;
}
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| WhenAnyGeneric_ListNotCompleted | .NET 7.0 | 555.0 ns | 1.00 | 704 B | 1.00 |
| WhenAnyGeneric_ListNotCompleted | .NET 8.0 | 260.3 ns | 0.47 | 504 B | 0.72 |
One last example related to tasks, though this one is a bit different, as it’s specifically about improving test performance (and test reliability). Imagine you have a method like this:
public static async Task LogAfterDelay(Action<string, TimeSpan> log)
{
long startingTimestamp = Stopwatch.GetTimestamp();
await Task.Delay(TimeSpan.FromSeconds(30));
log("Completed", Stopwatch.GetElapsedTime(startingTimestamp));
}The purpose of this method is to wait for 30 seconds and then log a completion message as well as how much time the method observed to pass. This is obviously a simplification of the kind of functionality you’d find in real applications, but you can extrapolate from it to code you’ve likely written. How do you test this? Maybe you’ve written a test like this:
[Fact]
public async Task LogAfterDelay_Success_CompletesAfterThirtySeconds()
{
TimeSpan ts = default;
Stopwatch sw = Stopwatch.StartNew();
await LogAfterDelay((message, time) => ts = time);
sw.Stop();
Assert.InRange(ts, TimeSpan.FromSeconds(30), TimeSpan.MaxValue);
Assert.InRange(sw.Elapsed, TimeSpan.FromSeconds(30), TimeSpan.MaxValue);
}This is validating both that the method included a value of at least 30 seconds in its log and also that at least 30 seconds passed. What’s the problem? From a performance perspective, the problem is this test had to wait 30 seconds! That’s a ton of overhead for something which would otherwise complete close to instantaneously. Now imagine the delay was longer, like 10 minutes, or that we had a bunch of tests that all needed to do the same thing. It becomes untenable to test well and thoroughly.
To address these kinds of situations, many developers have introduced their own abstractions for the flow of time. Now in .NET 8, that’s no longer needed. As of dotnet/runtime#83604, the core libraries include System.TimeProvider. This abstract base class abstracts over the flow of time, with members for getting the current UTC time, getting the current local time, getting the current time zone, getting a high-frequency timestamp, and creating a timer (which in turn returns the new System.Threading.ITimer that supports changing the timer’s tick interval). Then core library members like Task.Delay and CancellationTokenSource‘s constructor have new overloads that accept a TimeProvider, and use it for time-related functionality rather than being hardcoded to DateTime.UtcNow, Stopwatch, or System.Threading.Timer. With that, we can rewrite our previous method:
public static async Task LogAfterDelay(Action<string, TimeSpan> log, TimeProvider provider)
{
long startingTimestamp = provider.GetTimestamp();
await Task.Delay(TimeSpan.FromSeconds(30), provider);
log("Completed", provider.GetElapsedTime(startingTimestamp));
}It’s been augmented to accept a TimeProvider parameter, though in a system that uses a dependency injection (DI) mechanism, it would likely just fetch a TimeProvider singleton from DI. Then instead of using Stopwatch.GetTimestamp or Stopwatch.GetElapsedTime, it uses the corresponding members on the provider, and instead of using the Task.Delay overload that just takes a duration, it uses the overload that also takes a TimeProvider. When used in production, this can be passed TimeProvider.System, which is implemented based on the system clock (exactly what you would get without providing a TimeProvider at all), but in a test, it can be passed a custom instance, one that manually controls the observed flow of time. Exactly such a custom TimeProvider exists in the Microsoft.Extensions.TimeProvider.Testing NuGet package: FakeTimeProvider. Here’s an example of using it with our LogAfterDelay method:
// dotnet run -c Release -f net8.0 --filter "*"
using Microsoft.Extensions.Time.Testing;
using System.Diagnostics;
Stopwatch sw = Stopwatch.StartNew();
var fake = new FakeTimeProvider();
Task t = LogAfterDelay((message, time) => Console.WriteLine($"{message}: {time}"), fake);
fake.Advance(TimeSpan.FromSeconds(29));
Console.WriteLine(t.IsCompleted);
fake.Advance(TimeSpan.FromSeconds(1));
Console.WriteLine(t.IsCompleted);
Console.WriteLine($"Actual execution time: {sw.Elapsed}");
static async Task LogAfterDelay(Action<string, TimeSpan> log, TimeProvider provider)
{
long startingTimestamp = provider.GetTimestamp();
await Task.Delay(TimeSpan.FromSeconds(30), provider);
log("Completed", provider.GetElapsedTime(startingTimestamp));
}When I run this, it outputs the following:
False
Completed: 00:00:30
True
Actual execution time: 00:00:00.0119943In other words, after manually advancing time by 29 seconds, the operation still hadn’t completed. Then we manually advanced time by one more second, and the operation completed. It reported that 30 seconds passed, but in reality, the whole operation took only 0.01 seconds of actual wall clock time.
With that, let’s move up the stack to Parallel…
Parallel
.NET 6 introduced new async methods onto Parallel in the form of Parallel.ForEachAsync. After its introduction, we started getting requests for an equivalent for for loops, so now in .NET 8, with dotnet/runtime#84804, the class gains a set of Parallel.ForAsync methods. These were previously achievable by passing in an IEnumerable<T> created from a method like Enumerable.Range, e.g.
await Parallel.ForEachAsync(Enumerable.Range(0, 1_000), async i =>
{
...
});but you can now achieve the same more simply and cheaply with:
await Parallel.ForAsync(0, 1_000, async i =>
{
...
});It ends up being cheaper because you don’t need to allocate the enumerable/enumerator, and the synchronization involved in multiple workers trying to peel off the next iteration can be done in a much less expensive manner, a single Interlocked rather than using an asynchronous lock like SemaphoreSlim.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
[Benchmark(Baseline = true)]
public Task ForEachAsync() => Parallel.ForEachAsync(Enumerable.Range(0, 1_000_000), (i, ct) => ValueTask.CompletedTask);
[Benchmark]
public Task ForAsync() => Parallel.ForAsync(0, 1_000_000, (i, ct) => ValueTask.CompletedTask);
}| Method | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|
| ForEachAsync | 589.5 ms | 1.00 | 87925272 B | 1.000 |
| ForAsync | 147.5 ms | 0.25 | 792 B | 0.000 |
The allocation column here is particularly stark, and also a tad misleading. Why is ForEachAsync so much worse here allocation-wise? It’s because of the synchronization mechanism. There’s zero work being performed here by the delegate in the test, so all of the time is spent hammering on the source. In the case of Parallel.ForAsync, that’s a single Interlocked instruction to get the next value. In the case of Parallel.ForEachAsync, it’s a WaitAsync, and under a lot of contention, many of those WaitAsync calls are going to complete asynchronously, resulting in allocation. In a real workload, where the body delegate is doing real work, synchronously or asynchronously, the impact of that synchronization is much, much less dramatic. Here I’ve changed the calls to just be a simple Task.Delay for 1ms (and also significantly lowered the iteration count):
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
[Benchmark(Baseline = true)]
public Task ForEachAsync() => Parallel.ForEachAsync(Enumerable.Range(0, 100), async (i, ct) => await Task.Delay(1));
[Benchmark]
public Task ForAsync() => Parallel.ForAsync(0, 100, async (i, ct) => await Task.Delay(1));
}and the two methods are the effectively same:
| Method | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|
| ForEachAsync | 89.39 ms | 1.00 | 27.96 KB | 1.00 |
| ForAsync | 89.44 ms | 1.00 | 27.84 KB | 1.00 |
Interestingly, this Parallel.ForAsync method is also one of the first public methods in the core libraries to be based on the generic math interfaces introduced in .NET 7:
public static Task ForAsync<T>(T fromInclusive, T toExclusive, Func<T, CancellationToken, ValueTask> body)
where T : notnull, IBinaryInteger<T>When initially designing the method, we copied the synchronous For counterpart, which has overloads specific to int and overloads specific to long. Now that we have IBinaryInteger<T>, however, we realized we could not only reduce the number of overloads and not only reduce the number of implementations, by using IBinaryInteger<T> we could also open the same method up to other types folks want to use, such as nint or UInt128 or BigInteger; they all “just work,” which is pretty cool. (The new TotalOrderIeee754Comparer<T>, added in .NET 8 in dotnet/runtime#75517 by @huoyaoyuan, is another new public type relying on these interfaces.) Once we did that, in dotnet/runtime#84853 we used a similar technique to deduplicate the Parallel.For implementations, such that both int and long share the same generic implementations internally.
Exceptions
In .NET 6, ArgumentNullException gained a ThrowIfNull method, as we dipped our toes into the waters of providing “throw helpers.” The intent of the method is to concisely express the constraint being verified, letting the system throw a consistent exception for failure to meet the constraint while also optimizing the success and 99.999% case where no exception need be thrown. The method is structured in such a way that the fast path performing the check gets inlined, with as little work as possible on that path, and then everything else is relegated to a method that performs the actual throwing (the JIT won’t inline that throwing method, as it’ll look at its implementation and see that the method always throws).
public static void ThrowIfNull(
[NotNull] object? argument,
[CallerArgumentExpression(nameof(argument))] string? paramName = null)
{
if (argument is null)
Throw(paramName);
}
[DoesNotReturn]
internal static void Throw(string? paramName) => throw new ArgumentNullException(paramName);In .NET 7, ArgumentNullException.ThrowIfNull gained another overload, this time for pointers, and two new methods were introduced: ArgumentException.ThrowIfNullOrEmpty for strings and ObjectDisposedException.ThrowIf.
Now in .NET 8, a slew of new such helpers have been added. Thanks to dotnet/runtime#86007, ArgumentException gains ThrowIfNullOrWhiteSpace to complement ThrowIfNullOrEmpty:
public static void ThrowIfNullOrWhiteSpace([NotNull] string? argument, [CallerArgumentExpression(nameof(argument))] string? paramName = null);and thanks to dotnet/runtime#78222 from @hrrrrustic and dotnet/runtime#83853, ArgumentOutOfRangeException gains 9 new methods:
public static void ThrowIfEqual<T>(T value, T other, [CallerArgumentExpression(nameof(value))] string? paramName = null) where T : System.IEquatable<T>?;
public static void ThrowIfNotEqual<T>(T value, T other, [CallerArgumentExpression(nameof(value))] string? paramName = null) where T : System.IEquatable<T>?;
public static void ThrowIfLessThan<T>(T value, T other, [CallerArgumentExpression(nameof(value))] string? paramName = null) where T : IComparable<T>;
public static void ThrowIfLessThanOrEqual<T>(T value, T other, [CallerArgumentExpression(nameof(value))] string? paramName = null) where T : IComparable<T>;
public static void ThrowIfGreaterThan<T>(T value, T other, [CallerArgumentExpression(nameof(value))] string? paramName = null) where T : IComparable<T>;
public static void ThrowIfGreaterThanOrEqual<T>(T value, T other, [CallerArgumentExpression(nameof(value))] string? paramName = null) where T : IComparable<T>;
public static void ThrowIfNegative<T>(T value, [CallerArgumentExpression(nameof(value))] string? paramName = null) where T : INumberBase<T>;
public static void ThrowIfZero<T>(T value, [CallerArgumentExpression(nameof(value))] string? paramName = null) where T : INumberBase<T>;
public static void ThrowIfNegativeOrZero<T>(T value, [CallerArgumentExpression(nameof(value))] string? paramName = null) where T : INumberBase<T>;Those PRs used these new methods in a few places, but then dotnet/runtime#79460, dotnet/runtime#80355, dotnet/runtime#82357, dotnet/runtime#82533, and dotnet/runtime#85858 rolled out their use more broadly throughout the core libraries. To get a sense for the usefulness of these methods, here are the number of times each of these methods is being called from within the src for the core libraries in dotnet/runtime as of the time I’m writing this paragraph:
| Method | Count |
|---|---|
| ANE.ThrowIfNull(object) | 4795 |
| AOORE.ThrowIfNegative | 873 |
| AE.ThrowIfNullOrEmpty | 311 |
| ODE.ThrowIf | 237 |
| AOORE.ThrowIfGreaterThan | 223 |
| AOORE.ThrowIfNegativeOrZero | 100 |
| AOORE.ThrowIfLessThan | 89 |
| ANE.ThrowIfNull(void*) | 55 |
| AOORE.ThrowIfGreaterThanOrEqual | 39 |
| AE.ThrowIfNullOrWhiteSpace | 32 |
| AOORE.ThrowIfLessThanOrEqual | 20 |
| AOORE.ThrowIfNotEqual | 13 |
| AOORE.ThrowIfZero | 5 |
| AOORE.ThrowIfEqual | 3 |
These new methods also do more work in the throwing portion (e.g. formatting the exception message with the invalid arguments), which helps to better exemplify the benfits of moving all of that work out into a separate method. For example, here is the ThrowIfGreaterThan copied straight from System.Private.CoreLib:
public static void ThrowIfGreaterThan<T>(T value, T other, [CallerArgumentExpression(nameof(value))] string? paramName = null) where T : IComparable<T>
{
if (value.CompareTo(other) > 0)
ThrowGreater(value, other, paramName);
}
private static void ThrowGreater<T>(T value, T other, string? paramName) =>
throw new ArgumentOutOfRangeException(paramName, value, SR.Format(SR.ArgumentOutOfRange_Generic_MustBeLessOrEqual, paramName, value, other));and here is a benchmark showing what consumption would look like if the throw expression were directly part of ThrowIfGreaterThan:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Runtime.CompilerServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "value1", "value2")]
[DisassemblyDiagnoser]
public class Tests
{
[Benchmark(Baseline = true)]
[Arguments(1, 2)]
public void WithOutline(int value1, int value2)
{
ArgumentOutOfRangeException.ThrowIfGreaterThan(value1, 100);
ArgumentOutOfRangeException.ThrowIfGreaterThan(value2, 200);
}
[Benchmark]
[Arguments(1, 2)]
public void WithInline(int value1, int value2)
{
ThrowIfGreaterThan(value1, 100);
ThrowIfGreaterThan(value2, 200);
}
public static void ThrowIfGreaterThan<T>(T value, T other, [CallerArgumentExpression(nameof(value))] string? paramName = null) where T : IComparable<T>
{
if (value.CompareTo(other) > 0)
throw new ArgumentOutOfRangeException(paramName, value, SR.Format(SR.ArgumentOutOfRange_Generic_MustBeLessOrEqual, paramName, value, other));
}
internal static class SR
{
public static string Format(string format, object arg0, object arg1, object arg2) => string.Format(format, arg0, arg1, arg2);
internal static string ArgumentOutOfRange_Generic_MustBeLessOrEqual => GetResourceString("ArgumentOutOfRange_Generic_MustBeLessOrEqual");
[MethodImpl(MethodImplOptions.NoInlining)]
static string GetResourceString(string resourceKey) => "{0} ('{1}') must be less than or equal to '{2}'.";
}
}| Method | Mean | Ratio | Code Size |
|---|---|---|---|
| WithOutline | 0.4839 ns | 1.00 | 118 B |
| WithInline | 2.4976 ns | 5.16 | 235 B |
The most relevant highlight from the generated assembly is from the WithInline case:
; Tests.WithInline(Int32, Int32)
push rbx
sub rsp,20
mov ebx,r8d
mov ecx,edx
mov edx,64
mov r8,1F5815EA8F8
call qword ptr [7FF99C03DEA8]; Tests.ThrowIfGreaterThan[[System.Int32, System.Private.CoreLib]](Int32, Int32, System.String)
mov ecx,ebx
mov edx,0C8
mov r8,1F5815EA920
add rsp,20
pop rbx
jmp qword ptr [7FF99C03DEA8]; Tests.ThrowIfGreaterThan[[System.Int32, System.Private.CoreLib]](Int32, Int32, System.String)
; Total bytes of code 59Because there’s more cruft inside the ThrowIfGreaterThan method, the system decides not to inline it, and so we end up with two method invocations that occur even when the value is within range (the first is a call, the second here is a jmp, since there was no follow-up work in this method that would require control flow returning).
To make it easier to roll out usage of these helpers, dotnet/roslyn-analyzers#6293 added new analyzers to look for argument validation that can be replaced by one of the throw helper methods on ArgumentNullException, ArgumentException, ArgumentOutOfRangeException, or ObjectDisposedException. dotnet/runtime#80149 enables the analyzers for dotnet/runtime and fixes up many call sites.

Reflection
There have been a variety of improvements here and there in the reflection stack in .NET 8, mostly around reducing allocation or caching information so that subsequent access is faster. For example, dotnet/runtime#87902 tweaks some code in GetCustomAttributes to avoid allocating an object[1] array in order to set a property on an attribute.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
[Benchmark]
public object[] GetCustomAttributes() => typeof(C).GetCustomAttributes(typeof(MyAttribute), inherit: true);
[My(Value1 = 1, Value2 = 2)]
class C { }
[AttributeUsage(AttributeTargets.All)]
public class MyAttribute : Attribute
{
public int Value1 { get; set; }
public int Value2 { get; set; }
}
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| GetCustomAttributes | .NET 7.0 | 1,287.1 ns | 1.00 | 296 B | 1.00 |
| GetCustomAttributes | .NET 8.0 | 994.0 ns | 0.77 | 232 B | 0.78 |
Other changes like dotnet/runtime#76574 from @teo-tsirpanis, dotnet/runtime#81059 from @teo-tsirpanis, and dotnet/runtime#86657 from @teo-tsirpanis also removed allocations in the reflection stack, in particular by more liberal use of spans. And dotnet/runtime#78288 from @lateapexearlyspeed improves the handling of generics information on a Type, leading to a boost for various generics-related members, in particular for GetGenericTypeDefinition for which the result is now cached on the Type object.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly Type _type = typeof(List<int>);
[Benchmark] public Type GetGenericTypeDefinition() => _type.GetGenericTypeDefinition();
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| GetGenericTypeDefinition | .NET 7.0 | 47.426 ns | 1.00 |
| GetGenericTypeDefinition | .NET 8.0 | 3.289 ns | 0.07 |
However, the largest impact on performance in reflection in .NET 8 comes from dotnet/runtime#88415. This is a continuation of work done in .NET 7 to improve the performance of MethodBase.Invoke. When you know at compile-time the signature of the target method you want to invoke via reflection, you can achieve the best performance by using CreateDelegate<DelegateType> to get and cache a delegate for the method in question, and then performing all invocations via that delegate. However, if you don’t know the signature at compile-time, you need to rely on more dynamic means, like MethodBase.Invoke, which historically has been much more costly. Some enterprising developers turned to reflection emit to avoid that overhead by emitting custom invocation stubs at run-time, and that’s one of the optimization approaches taken under the covers in .NET 7 as well. Now in .NET 8, the code generated for many of these cases has improved; previously the emitter was always generating code that could accommodate ref/out arguments, but many methods don’t have such arguments, and the generated code can be more efficient when it needn’t factor those in.
// If you have .NET 6 installed, you can update the csproj to include a net6.0 in the target frameworks, and then run:
// dotnet run -c Release -f net6.0 --filter "*" --runtimes net6.0 net7.0 net8.0
// Otherwise, you can run:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Reflection;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private MethodInfo _method0, _method1, _method2, _method3;
private readonly object[] _args1 = new object[] { 1 };
private readonly object[] _args2 = new object[] { 2, 3 };
private readonly object[] _args3 = new object[] { 4, 5, 6 };
[GlobalSetup]
public void Setup()
{
_method0 = typeof(Tests).GetMethod("MyMethod0", BindingFlags.NonPublic | BindingFlags.Static);
_method1 = typeof(Tests).GetMethod("MyMethod1", BindingFlags.NonPublic | BindingFlags.Static);
_method2 = typeof(Tests).GetMethod("MyMethod2", BindingFlags.NonPublic | BindingFlags.Static);
_method3 = typeof(Tests).GetMethod("MyMethod3", BindingFlags.NonPublic | BindingFlags.Static);
}
[Benchmark] public void Method0() => _method0.Invoke(null, null);
[Benchmark] public void Method1() => _method1.Invoke(null, _args1);
[Benchmark] public void Method2() => _method2.Invoke(null, _args2);
[Benchmark] public void Method3() => _method3.Invoke(null, _args3);
private static void MyMethod0() { }
private static void MyMethod1(int arg1) { }
private static void MyMethod2(int arg1, int arg2) { }
private static void MyMethod3(int arg1, int arg2, int arg3) { }
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Method0 | .NET 6.0 | 91.457 ns | 1.00 |
| Method0 | .NET 7.0 | 7.205 ns | 0.08 |
| Method0 | .NET 8.0 | 5.719 ns | 0.06 |
| Method1 | .NET 6.0 | 132.832 ns | 1.00 |
| Method1 | .NET 7.0 | 26.151 ns | 0.20 |
| Method1 | .NET 8.0 | 21.602 ns | 0.16 |
| Method2 | .NET 6.0 | 172.224 ns | 1.00 |
| Method2 | .NET 7.0 | 37.937 ns | 0.22 |
| Method2 | .NET 8.0 | 26.951 ns | 0.16 |
| Method3 | .NET 6.0 | 211.247 ns | 1.00 |
| Method3 | .NET 7.0 | 42.988 ns | 0.20 |
| Method3 | .NET 8.0 | 34.112 ns | 0.16 |
However, there’s overhead involved here on each call and that’s repeated on each call. If we could extract that upfront work, do it once, and cache it, we can achieve much better performance. That’s exactly what the new MethodInvoker and ConstructorInvoker types implemented in dotnet/runtime#88415 provide. These don’t incorporate all of the obscure corner-cases that MethodBase.Invoke handles (like specially recognizing and handling Type.Missing), but for everything else, it provides a great solution for optimizing the repeated invocation of methods whose signatures are unknown at build time.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Reflection;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly object _arg0 = 4, _arg1 = 5, _arg2 = 6;
private readonly object[] _args3 = new object[] { 4, 5, 6 };
private MethodInfo _method3;
private MethodInvoker _method3Invoker;
[GlobalSetup]
public void Setup()
{
_method3 = typeof(Tests).GetMethod("MyMethod3", BindingFlags.NonPublic | BindingFlags.Static);
_method3Invoker = MethodInvoker.Create(_method3);
}
[Benchmark(Baseline = true)]
public void MethodBaseInvoke() => _method3.Invoke(null, _args3);
[Benchmark]
public void MethodInvokerInvoke() => _method3Invoker.Invoke(null, _arg0, _arg1, _arg2);
private static void MyMethod3(int arg1, int arg2, int arg3) { }
}| Method | Mean | Ratio |
|---|---|---|
| MethodBaseInvoke | 32.42 ns | 1.00 |
| MethodInvokerInvoke | 11.47 ns | 0.35 |
As of dotnet/runtime#90119, these types are then used by the ActivatorUtilities.CreateFactory method in Microsoft.Extensions.DependencyInjection.Abstractions to further improve DI service construction performance. dotnet/runtime#91881 improves it further by adding a an additional caching layer that further avoids reflection on each construction.
Primitives
It’s hard to believe that after two decades we’re still finding opportunity to improve the core primitive types in .NET, yet here we are. Some of this comes from new scenarios that drive optimization into different places; some of it comes from new opportunity based on new support that enables different approaches to the same problem; some of it comes from new research highlighting new ways to approach a problem; and some of it simply comes from many new eyes looking at a well-worn space (yay open source!) Regardless of the reason, there’s a lot to be excited about here in .NET 8.
Enums
Let’s start with Enum. Enum has obviously been around since the earliest days of .NET and is used heavily. Although Enum‘s functionality and implementation have evolved, and although it’s received new APIs, at its core, how the data is stored has fundamentally remained the same for many years. In the .NET Framework implementation, there’s an internal ValuesAndNames class that stores a ulong[] and a string[], and in .NET 7, there’s an EnumInfo that serves the same purpose. That string[] contains the names of all of the enum’s values, and the ulong[] stores their numeric counterparts. It’s a ulong[] to accommodate all possible underlying types an Enum can be, including those supported by C# (sbyte, byte, short, ushort, int, uint, long, ulong) and those additionally supported by the runtime (nint, nuint, char, float, double) even though effectively no one uses those (partial bool support used to be on this list as well, but was deleted in .NET 8 in dotnet/runtime#79962 by @pedrobsaila).
As an aside, as part of all of this work, we examined the breadth of appropriately-licensed NuGet packages, looking for what the most common underlying types were in their use of enum. Out of ~163 million enums found, here’s the breakdown of their underlying types. The result is likely not surprising, given the default underlying type for Enum, but it’s still interesting:
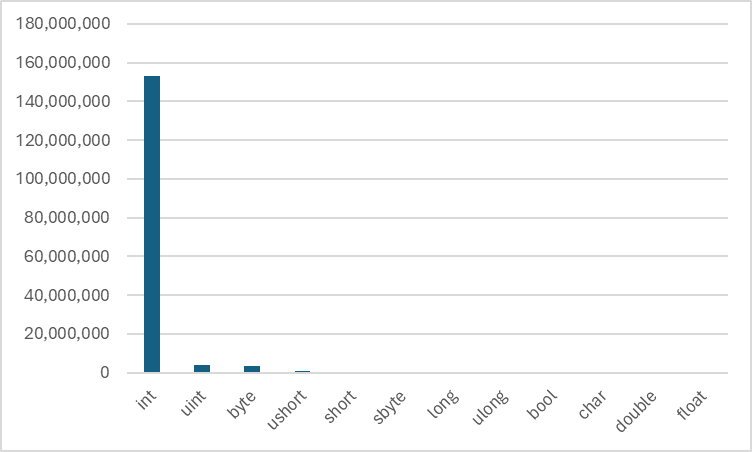
There are several issues with the cited design for how Enum stores its data. Every operation translates between these ulong[] values and the actual type being used by the particular Enum, plus the array is often twice as large as it needs to be (int is the default underlying type for an enum and, as seen in the above graph, by far the most commonly used). The approach also leads to significant assembly code bloat when dealing with all the new generic methods that have been added to Enum in recent years. enums are structs, and when a struct is used as a generic type argument, the JIT specializes the code for that value type (whereas for reference types it emits a single shared implementation used by all of them). That specialization is great for throughput, but it means that you get a copy of the code for every value type it’s used with; if you have a lot of code (e.g. Enum formatting) and a lot of possible types being substituted (e.g. every declared enum type), that’s a lot of possible increase in code size.
To address all of this, to modernize the implementation, and to make various operations faster, dotnet/runtime#78580 rewrites Enum. Rather than having a non-generic EnumInfo that stores a ulong[] array of all values, it introduces a generic EnumInfo<TUnderlyingValue> that stores a TUnderlyingValue[]. Then based on the enum’s type, every generic and non-generic Enum method looks up the underlying TUnderlyingType and invokes a generic method with that TUnderlyingType but not with a generic type parameter for the enum type, e.g. Enum.IsDefined<TEnum>(...) and Enum.IsDefined(typeof(TEnum), ...) both look up the TUnderlyingValue for TEnum and invoke the internal Enum.IsDefinedPrimitive<TUnderlyingValue>(typeof(TEnum)). In this way, the implementation stores a strongly-typed TUnderlyingValue[] value rather than storing the worst case ulong[], and all of the implementations across generic and non-generic entrypoints are shared while not having full generic specialization for every TEnum: worst case, we end up with one generic specialization per underlying type, of which only the previously cited 8 are expressible in C#. The generic entrypoints are able to do the mapping very efficiently, thanks to dotnet/runtime#71685 from @MichalPetryka which makes typeof(TEnum).IsEnum a JIT intrinsic (such that it effectively becomes a const), and the non-generic entrypoints use switches on TypeCode/CorElementType as was already being done in a variety of methods.
Other improvements were made to Enum as well. dotnet/runtime#76162 improves the performance of various methods like ToString and IsDefined in cases where all of the enum‘s defined values are sequential starting from 0. In that common case, the internal function that looks up the value in the EnumInfo<TUnderlyingValue> can do so with a simple array access, rather than needing to search for the target.
The net result of all of these changes are some very nice performance improvements:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly DayOfWeek _dow = DayOfWeek.Saturday;
[Benchmark] public bool IsDefined() => Enum.IsDefined(_dow);
[Benchmark] public string GetName() => Enum.GetName(_dow);
[Benchmark] public string[] GetNames() => Enum.GetNames<DayOfWeek>();
[Benchmark] public DayOfWeek[] GetValues() => Enum.GetValues<DayOfWeek>();
[Benchmark] public Array GetUnderlyingValues() => Enum.GetValuesAsUnderlyingType<DayOfWeek>();
[Benchmark] public string EnumToString() => _dow.ToString();
[Benchmark] public bool TryParse() => Enum.TryParse<DayOfWeek>("Saturday", out _);
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| IsDefined | .NET 7.0 | 20.021 ns | 1.00 | – | NA |
| IsDefined | .NET 8.0 | 2.502 ns | 0.12 | – | NA |
| GetName | .NET 7.0 | 24.563 ns | 1.00 | – | NA |
| GetName | .NET 8.0 | 3.648 ns | 0.15 | – | NA |
| GetNames | .NET 7.0 | 37.138 ns | 1.00 | 80 B | 1.00 |
| GetNames | .NET 8.0 | 22.688 ns | 0.61 | 80 B | 1.00 |
| GetValues | .NET 7.0 | 694.356 ns | 1.00 | 224 B | 1.00 |
| GetValues | .NET 8.0 | 39.406 ns | 0.06 | 56 B | 0.25 |
| GetUnderlyingValues | .NET 7.0 | 41.012 ns | 1.00 | 56 B | 1.00 |
| GetUnderlyingValues | .NET 8.0 | 17.249 ns | 0.42 | 56 B | 1.00 |
| EnumToString | .NET 7.0 | 32.842 ns | 1.00 | 24 B | 1.00 |
| EnumToString | .NET 8.0 | 14.620 ns | 0.44 | 24 B | 1.00 |
| TryParse | .NET 7.0 | 49.121 ns | 1.00 | – | NA |
| TryParse | .NET 8.0 | 30.394 ns | 0.62 | – | NA |
These changes, however, also made enums play much more nicely with string interpolation. First, Enum now sports a new static TryFormat method, which enables formatting an enum‘s string representation directly into a Span<char>:
public static bool TryFormat<TEnum>(TEnum value, Span<char> destination, out int charsWritten, [StringSyntax(StringSyntaxAttribute.EnumFormat)] ReadOnlySpan<char> format = default) where TEnum : struct, EnumSecond, Enum now implements ISpanFormattable, such that any code written to use a value’s ISpanFormattable.TryFormat method now lights up with enums, too. However, even though enums are value types, they’re special and weird in that they derive from the reference type Enum, and that means calling instance methods like ToString or ISpanFormattable.TryFormat end up boxing the enum value.
So, third, the various interpolated string handlers in System.Private.CoreLib were updated to special-case typeof(T).IsEnum, which as noted is now effectively free thanks to JIT optimizations, using Enum.TryFormat directly in order to avoid the boxing. We can see the impact this has by running the following benchmark:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly char[] _dest = new char[100];
private readonly FileAttributes _attr = FileAttributes.Hidden | FileAttributes.ReadOnly;
[Benchmark]
public bool Interpolate() => _dest.AsSpan().TryWrite($"Attrs: {_attr}", out int charsWritten);
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| Interpolate | .NET 7.0 | 81.58 ns | 1.00 | 80 B | 1.00 |
| Interpolate | .NET 8.0 | 34.41 ns | 0.42 | – | 0.00 |
Numbers
Such formatting improvements weren’t just reserved for enums. The performance of number formatting also sees a nice set of improvements in .NET 8. Daniel Lemire has a nice blog post from 2021 discussing various approaches to counting the number of digits in an integer. Digit counting is relevant to number formatting as we need to know how many characters the number will be, either to allocate a string of the right length to format into or to ensure that a destination buffer is of a sufficient length. dotnet/runtime#76519 implements this inside of .NET’s number formatting, providing a branch-free, table-based lookup solution for computing the number of digits in a formatted value.
dotnet/runtime#76726 improves performance further by using a trick other formatting libraries use. One of the more expensive parts of formatting a decimal is in dividing by 10 to pull off each digit; if we can reduce the number of divisions, we can reduce the overall expense of the formatting operation. The trick here is, rather than dividing by 10 for each digit in the number, we instead divide by 100 for each pair of digits in the number, and then have a precomputed lookup table for the char-based representation of all values 0 to 99. This lets us cut the number of divisions in half.
dotnet/runtime#79061 also expands on a previous optimization already present in .NET. The formatting code contained a table of precomputed strings for single digit numbers, so if you asked for the equivalent of 0.ToString(), the implementation wouldn’t need to allocate a new string, it would just fetch "0" from the table and return it. This PR expands that cache from single digit numbers to being all numbers 0 through 299 (it also makes the cache lazy, such that we don’t need to pay for the strings for values that are never used). The choice of 299 is somewhat arbitrary and could be raised in the future if the need presents itself, but in examining data from various services, this addresses a significant chunk of the allocations that come from number formatting. Coincidentally or not, it also includes all success status codes from the HTTP protocol.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
[Benchmark]
[Arguments(12)]
[Arguments(123)]
[Arguments(1_234_567_890)]
public string Int32ToString(int i) => i.ToString();
}| Method | Runtime | i | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|
| Int32ToString | .NET 7.0 | 12 | 16.253 ns | 1.00 | 32 B | 1.00 |
| Int32ToString | .NET 8.0 | 12 | 1.985 ns | 0.12 | – | 0.00 |
| Int32ToString | .NET 7.0 | 123 | 18.056 ns | 1.00 | 32 B | 1.00 |
| Int32ToString | .NET 8.0 | 123 | 1.971 ns | 0.11 | – | 0.00 |
| Int32ToString | .NET 7.0 | 1234567890 | 26.964 ns | 1.00 | 48 B | 1.00 |
| Int32ToString | .NET 8.0 | 1234567890 | 17.082 ns | 0.63 | 48 B | 1.00 |
Numbers in .NET 8 also gain the ability to format as binary (via dotnet/runtime#84889, and parse from binary (via dotnet/runtime#84998), via the new “b” specifier. For example, this:
// dotnet run -f net8.0
int i = 12345;
Console.WriteLine(i.ToString("x16")); // 16 hex digits
Console.WriteLine(i.ToString("b16")); // 16 binary digitsoutputs:
0000000000003039
0011000000111001That implementation is then used to reimplement the existing Convert.ToString(int value, int toBase) method, such that it’s also now optimized:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly int _value = 12345;
[Benchmark]
public string ConvertBinary() => Convert.ToString(_value, 2);
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| ConvertBinary | .NET 7.0 | 104.73 ns | 1.00 |
| ConvertBinary | .NET 8.0 | 23.76 ns | 0.23 |
In a significant addition to the primitive types (numerical and beyond), .NET 8 also sees the introduction of the new IUtf8SpanFormattable interface. ISpanFormattable was introduced in .NET 6, and with it TryFormat methods on many types that enable those types to directly format into a Span<char>:
public interface ISpanFormattable : IFormattable
{
bool TryFormat(Span<char> destination, out int charsWritten, ReadOnlySpan<char> format, IFormatProvider? provider);
}Now in .NET 8, we also have the IUtf8SpanFormattable interface:
public interface IUtf8SpanFormattable
{
bool TryFormat(Span<byte> utf8Destination, out int bytesWritten, ReadOnlySpan<char> format, IFormatProvider? provider);
}that enables types to directly format into a Span<byte>. These are by design almost identical, the key difference being whether the implementation of these interfaces writes out UTF16 chars or UTF8 bytes. With dotnet/runtime#84587 and dotnet/runtime#84841, all of the numerical primitives in System.Private.CoreLib both implement the new interface and expose a public TryFormat method. So, for example, ulong exposes these:
public bool TryFormat(Span<char> destination, out int charsWritten, [StringSyntax(StringSyntaxAttribute.NumericFormat)] ReadOnlySpan<char> format = default, IFormatProvider? provider = null);
public bool TryFormat(Span<byte> utf8Destination, out int bytesWritten, [StringSyntax(StringSyntaxAttribute.NumericFormat)] ReadOnlySpan<char> format = default, IFormatProvider? provider = null);They have the exact same functionality, support the exact same format strings, the same general performance characteristics, and so on, and simply differ in whether writing out UTF16 or UTF8. How can I be so sure they’re so similar? Because, drumroll, they share the same implementation. Thanks to generics, the two methods above delegate to the exact same helper:
public static bool TryFormatUInt64<TChar>(ulong value, ReadOnlySpan<char> format, IFormatProvider? provider, Span<TChar> destination, out int charsWritten)just with one with TChar as char and the other as byte. So, when we run a benchmark like this:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly ulong _value = 12345678901234567890;
private readonly char[] _chars = new char[20];
private readonly byte[] _bytes = new byte[20];
[Benchmark] public void FormatUTF16() => _value.TryFormat(_chars, out _);
[Benchmark] public void FormatUTF8() => _value.TryFormat(_bytes, out _);
}we get practically identical results like this:
| Method | Mean |
|---|---|
| FormatUTF16 | 12.10 ns |
| FormatUTF8 | 12.96 ns |
And now that the primitive types themselves are able to format with full fidelity as UTF8, the Utf8Formatter class largely becomes legacy. In fact, the previously mentioned PR also rips out Utf8Formatter‘s implementation and just reparents it on top of the same formatting logic from the primitive types. All of the previously cited performance improvements to number formatting then not only accrue to ToString and TryFormat for UTF16, and not only to TryFormat for UTF8, but then also to Utf8Formatter (plus, removing duplicated code and reducing maintenance burden makes me giddy).
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Buffers.Text;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly byte[] _bytes = new byte[10];
[Benchmark]
[Arguments(123)]
[Arguments(1234567890)]
public bool Utf8FormatterTryFormat(int i) => Utf8Formatter.TryFormat(i, _bytes, out int bytesWritten);
}| Method | Runtime | i | Mean | Ratio |
|---|---|---|---|---|
| Utf8FormatterTryFormat | .NET 7.0 | 123 | 8.849 ns | 1.00 |
| Utf8FormatterTryFormat | .NET 8.0 | 123 | 4.645 ns | 0.53 |
| Utf8FormatterTryFormat | .NET 7.0 | 1234567890 | 15.844 ns | 1.00 |
| Utf8FormatterTryFormat | .NET 8.0 | 1234567890 | 7.174 ns | 0.45 |
Not only is UTF8 formatting directly supported by all these types, so, too, is parsing. dotnet/runtime#86875 added the new IUtf8SpanParsable<TSelf> interface and implemented it on the primitive numeric types. Just as with its formatting counterpart, this provides identical behavior to IParsable<TSelf>, just for UTF8 instead of UTF16. And just as with its formatting counterpart, all of the parsing logic is shared in generic routines between the two modes. In fact, not only does this share logic between UTF16 and UTF8 parsing, it follows closely on the heals of dotnet/runtime#84582, which uses the same generic tricks to deduplicate the parsing logic across all the primitive types, such that the same generic routines end up being used for all the types and both UTF8 and UTF16. That PR removed almost 2,000 lines of code from System.Private.CoreLib:

DateTime
Parsing and formatting are improved on other types, as well. Take DateTime and DateTimeOffset. dotnet/runtime#84963 improved a variety of aspects of DateTime{Offset} formatting:
- The formatting logic has general support used as a fallback and that supports any custom format, but then there are dedicated routines used for the most popular formats, allowing them to be optimized and tuned. Dedicated routines already existed for the very popular “r” (RFC1123 pattern) and “o” (round-trip date/time pattern) formats; this PR adds dedicated routines for the default format (“G”) when used with the invariant culture, the “s” format (sortable date/time pattern), and “u” format (universal sortable date/time pattern), all of which are used frequently in a variety of domains.
- For the “U” format (universal full date/time pattern), the implementation would end up always allocating new
DateTimeFormatInfoandGregorianCalendarinstances, resulting in a significant amount of allocation even though it was only needed in a rare fallback case. This fixed it to only allocate when truly required. - When there’s no dedicated formatting routine, formatting is done into an internal
ref structcalledValueListBuilder<T>that starts with a provided span buffer (typically seeded from astackalloc) and then grows withArrayPoolmemory as needed. After the formatting has completed, that builder is either copied into a destination span or a new string, depending on the method that triggered the formatting. However, we can avoid that copy for a destination span if we just seed the builder with the destination span. Then if the builder still contains the initial span when formatting has completed (having not grown out of it), we know all the data fit, and we can skip the copy, as all the data is already there.
Here’s some of the example impact:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Globalization;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly DateTime _dt = new DateTime(2023, 9, 1, 12, 34, 56);
private readonly char[] _chars = new char[100];
[Params(null, "s", "u", "U", "G")]
public string Format { get; set; }
[Benchmark] public string DT_ToString() => _dt.ToString(Format);
[Benchmark] public string DT_ToStringInvariant() => _dt.ToString(Format, CultureInfo.InvariantCulture);
[Benchmark] public bool DT_TryFormat() => _dt.TryFormat(_chars, out _, Format);
[Benchmark] public bool DT_TryFormatInvariant() => _dt.TryFormat(_chars, out _, Format, CultureInfo.InvariantCulture);
}| Method | Runtime | Format | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|
| DT_ToString | .NET 7.0 | ? | 166.64 ns | 1.00 | 64 B | 1.00 |
| DT_ToString | .NET 8.0 | ? | 102.45 ns | 0.62 | 64 B | 1.00 |
| DT_ToStringInvariant | .NET 7.0 | ? | 161.94 ns | 1.00 | 64 B | 1.00 |
| DT_ToStringInvariant | .NET 8.0 | ? | 28.74 ns | 0.18 | 64 B | 1.00 |
| DT_TryFormat | .NET 7.0 | ? | 151.52 ns | 1.00 | – | NA |
| DT_TryFormat | .NET 8.0 | ? | 78.57 ns | 0.52 | – | NA |
| DT_TryFormatInvariant | .NET 7.0 | ? | 140.35 ns | 1.00 | – | NA |
| DT_TryFormatInvariant | .NET 8.0 | ? | 18.26 ns | 0.13 | – | NA |
| DT_ToString | .NET 7.0 | G | 162.86 ns | 1.00 | 64 B | 1.00 |
| DT_ToString | .NET 8.0 | G | 109.49 ns | 0.68 | 64 B | 1.00 |
| DT_ToStringInvariant | .NET 7.0 | G | 162.20 ns | 1.00 | 64 B | 1.00 |
| DT_ToStringInvariant | .NET 8.0 | G | 102.71 ns | 0.63 | 64 B | 1.00 |
| DT_TryFormat | .NET 7.0 | G | 148.32 ns | 1.00 | – | NA |
| DT_TryFormat | .NET 8.0 | G | 83.60 ns | 0.57 | – | NA |
| DT_TryFormatInvariant | .NET 7.0 | G | 145.05 ns | 1.00 | – | NA |
| DT_TryFormatInvariant | .NET 8.0 | G | 79.77 ns | 0.55 | – | NA |
| DT_ToString | .NET 7.0 | s | 186.44 ns | 1.00 | 64 B | 1.00 |
| DT_ToString | .NET 8.0 | s | 29.35 ns | 0.17 | 64 B | 1.00 |
| DT_ToStringInvariant | .NET 7.0 | s | 182.15 ns | 1.00 | 64 B | 1.00 |
| DT_ToStringInvariant | .NET 8.0 | s | 27.67 ns | 0.16 | 64 B | 1.00 |
| DT_TryFormat | .NET 7.0 | s | 165.08 ns | 1.00 | – | NA |
| DT_TryFormat | .NET 8.0 | s | 15.53 ns | 0.09 | – | NA |
| DT_TryFormatInvariant | .NET 7.0 | s | 155.24 ns | 1.00 | – | NA |
| DT_TryFormatInvariant | .NET 8.0 | s | 15.50 ns | 0.10 | – | NA |
| DT_ToString | .NET 7.0 | u | 184.71 ns | 1.00 | 64 B | 1.00 |
| DT_ToString | .NET 8.0 | u | 29.62 ns | 0.16 | 64 B | 1.00 |
| DT_ToStringInvariant | .NET 7.0 | u | 184.01 ns | 1.00 | 64 B | 1.00 |
| DT_ToStringInvariant | .NET 8.0 | u | 26.98 ns | 0.15 | 64 B | 1.00 |
| DT_TryFormat | .NET 7.0 | u | 171.73 ns | 1.00 | – | NA |
| DT_TryFormat | .NET 8.0 | u | 16.08 ns | 0.09 | – | NA |
| DT_TryFormatInvariant | .NET 7.0 | u | 158.42 ns | 1.00 | – | NA |
| DT_TryFormatInvariant | .NET 8.0 | u | 15.58 ns | 0.10 | – | NA |
| DT_ToString | .NET 7.0 | U | 1,622.28 ns | 1.00 | 1240 B | 1.00 |
| DT_ToString | .NET 8.0 | U | 206.08 ns | 0.13 | 96 B | 0.08 |
| DT_ToStringInvariant | .NET 7.0 | U | 1,567.92 ns | 1.00 | 1240 B | 1.00 |
| DT_ToStringInvariant | .NET 8.0 | U | 207.60 ns | 0.13 | 96 B | 0.08 |
| DT_TryFormat | .NET 7.0 | U | 1,590.27 ns | 1.00 | 1144 B | 1.00 |
| DT_TryFormat | .NET 8.0 | U | 190.98 ns | 0.12 | – | 0.00 |
| DT_TryFormatInvariant | .NET 7.0 | U | 1,560.00 ns | 1.00 | 1144 B | 1.00 |
| DT_TryFormatInvariant | .NET 8.0 | U | 184.11 ns | 0.12 | – | 0.00 |
Parsing has also improved meaningfully. For example, dotnet/runtime#82877 improves the handling of “ddd” (abbreviated name of the day of the week), “dddd” (full name of the day of the week), “MMM” (abbreviated name of the month), and “MMMM” (full name of the month) in a custom format string; these show up in a variety of commonly used format strings, such as in the expanded definition of the RFC1123 format: ddd, dd MMM yyyy HH':'mm':'ss 'GMT'. When the general parsing routine encounters these in a format string, it needs to consult the supplied CultureInfo / DateTimeFormatInfo for that culture’s associated month and day names, e.g. DateTimeFormatInfo.GetAbbreviatedMonthName, and then needs to do a linguistic ignore-case comparison for each name against the input text; that’s not particularly cheap. However, if we’re given an invariant culture, we can do the comparison much, much faster. Take “MMM” for abbreviated month name, for example. We can read the next three characters (uint m0 = span[0], m1 = span[1], m2 = span[2]), ensure they’re all ASCII ((m0 | m1 | m2) <= 0x7F), and then combine them all into a single uint, employing the same ASCII casing trick discussed earlier ((m0 << 16) | (m1 << 8) | m2 | 0x202020). We can do the same thing, precomputed, for each month name, which for the invariant culture we know in advance, and the entire lookup becomes a single numerical switch:
switch ((m0 << 16) | (m1 << 8) | m2 | 0x202020)
{
case 0x6a616e: /* 'jan' */ result = 1; break;
case 0x666562: /* 'feb' */ result = 2; break;
case 0x6d6172: /* 'mar' */ result = 3; break;
case 0x617072: /* 'apr' */ result = 4; break;
case 0x6d6179: /* 'may' */ result = 5; break;
case 0x6a756e: /* 'jun' */ result = 6; break;
case 0x6a756c: /* 'jul' */ result = 7; break;
case 0x617567: /* 'aug' */ result = 8; break;
case 0x736570: /* 'sep' */ result = 9; break;
case 0x6f6374: /* 'oct' */ result = 10; break;
case 0x6e6f76: /* 'nov' */ result = 11; break;
case 0x646563: /* 'dec' */ result = 12; break;
default: maxMatchStrLen = 0; break; // undo match assumption
} Nifty, and way faster.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Globalization;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private const string Format = "ddd, dd MMM yyyy HH':'mm':'ss 'GMT'";
private readonly string _s = new DateTime(1955, 11, 5, 6, 0, 0, DateTimeKind.Utc).ToString(Format, CultureInfo.InvariantCulture);
[Benchmark]
public void ParseExact() => DateTimeOffset.ParseExact(_s, Format, CultureInfo.InvariantCulture, DateTimeStyles.AllowInnerWhite | DateTimeStyles.AssumeUniversal);
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| ParseExact | .NET 7.0 | 1,139.3 ns | 1.00 | 80 B | 1.00 |
| ParseExact | .NET 8.0 | 318.6 ns | 0.28 | – | 0.00 |
A variety of other PRs contributed as well. The decreased allocation in the previous benchmark is thanks to dotnet/runtime#82861, which removed a string allocation that might occur when the format string contained quotes; the PR simply replaced the string allocation with use of spans. dotnet/runtime#82925 further reduced the cost of parsing with the “r” and “o” formats by removing some work that ended up being unnecessary, removing a virtual dispatch, and general streamlining of the code paths. And dotnet/runtime#84964 removed some string[] allocations that occured in ParseExact when parsing with some cultures, in particular those that employ genitive month names. If the parser needed to retrieve the MonthGenitiveNames or AbbreviatedMonthGenitiveNames arrays, it would do so via the public properties for these on DateTimeFormatInfo; however, out of concern that code could mutate those arrays, these public properties hand back copies. That means that the parser was allocating a copy every time it accessed one of these. The parser can instead access the underlying original array, and pinky swear not to change it.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Globalization;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly CultureInfo _ci = new CultureInfo("ru-RU");
[Benchmark] public DateTime Parse() => DateTime.ParseExact("вторник, 18 апреля 2023 04:31:26", "dddd, dd MMMM yyyy HH:mm:ss", _ci);
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| Parse | .NET 7.0 | 2.654 us | 1.00 | 128 B | 1.00 |
| Parse | .NET 8.0 | 2.353 us | 0.90 | – | 0.00 |
DateTime and DateTimeOffset also implement IUtf8SpanFormattable, thanks to dotnet/runtime#84469, and as with the numerical types, the implementations are all shared between UTF16 and UTF8; thus all of the optimizations previously mentioned accrue to both. And again, Utf8Formatter‘s support for formatting DateTimeOffset is just reparented on top of this same shared logic.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Buffers.Text;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly DateTime _dt = new DateTime(2023, 9, 1, 12, 34, 56);
private readonly byte[] _bytes = new byte[100];
[Benchmark] public bool TryFormatUtf8Formatter() => Utf8Formatter.TryFormat(_dt, _bytes, out _);
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| TryFormatUtf8Formatter | .NET 7.0 | 19.35 ns | 1.00 |
| TryFormatUtf8Formatter | .NET 8.0 | 16.24 ns | 0.83 |
Since we’re talking about DateTime, a brief foray into TimeZoneInfo. TimeZoneInfo.FindSystemTimeZoneById gets a TimeZoneInfo object for the specified identifier. One of the improvements introduced in .NET 6 is that FindSystemTimeZoneById supports both the Windows time zone set as well as the IANA time zone set, regardless of whether running on Windows or Linux or macOS. However, the TimeZoneInfo was only being cached when its ID matched that for the current OS, and as such calls that resolved to the other set weren’t being fulfilled by the cache and were falling back to re-reading from the OS. dotnet/runtime#85615 ensures a cache can be used in both cases. It also allows returning the immutable TimeZoneInfo objects directly, rather than cloning them on every access. dotnet/runtime#88368 also improves TimeZoneInfo, in particular GetSystemTimeZones on Linux and macOS, by lazily loading several of the properties. dotnet/runtime#89985 then improves on that with a new overload of GetSystemTimeZones that allows the caller to skip the sort the implementation would otherwise perform on the result.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
[Benchmark]
[Arguments("America/Los_Angeles")]
[Arguments("Pacific Standard Time")]
public TimeZoneInfo FindSystemTimeZoneById(string id) => TimeZoneInfo.FindSystemTimeZoneById(id);
}| Method | Runtime | id | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|
| FindSystemTimeZoneById | .NET 7.0 | America/Los_Angeles | 1,503.75 ns | 1.00 | 80 B | 1.00 |
| FindSystemTimeZoneById | .NET 8.0 | America/Los_Angeles | 40.96 ns | 0.03 | – | 0.00 |
| FindSystemTimeZoneById | .NET 7.0 | Pacif(…) Time [21] | 3,951.60 ns | 1.00 | 568 B | 1.00 |
| FindSystemTimeZoneById | .NET 8.0 | Pacif(…) Time [21] | 57.00 ns | 0.01 | – | 0.00 |
Back to formatting and parsing…
Guid
Formatting and parsing improvements go beyond the numerical and date types. Guid also gets in on the game. Thanks to dotnet/runtime#84553, Guid implements IUtf8SpanFormattable, and as with all the other cases, it shares the exact same routines between UTF16 and UTF8 support. Then dotnet/runtime#81650, dotnet/runtime#81666, and dotnet/runtime#87126 from @SwapnilGaikwad vectorize that formatting support.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly Guid _guid = Guid.Parse("7BD626F6-4396-41E3-A491-4B1DC538DD92");
private readonly char[] _dest = new char[100];
[Benchmark]
[Arguments("D")]
[Arguments("N")]
[Arguments("B")]
[Arguments("P")]
public bool TryFormat(string format) => _guid.TryFormat(_dest, out _, format);
}| Method | Runtime | format | Mean | Ratio |
|---|---|---|---|---|
| TryFormat | .NET 7.0 | B | 23.622 ns | 1.00 |
| TryFormat | .NET 8.0 | B | 7.341 ns | 0.31 |
| TryFormat | .NET 7.0 | D | 22.134 ns | 1.00 |
| TryFormat | .NET 8.0 | D | 5.485 ns | 0.25 |
| TryFormat | .NET 7.0 | N | 20.891 ns | 1.00 |
| TryFormat | .NET 8.0 | N | 4.852 ns | 0.23 |
| TryFormat | .NET 7.0 | P | 24.139 ns | 1.00 |
| TryFormat | .NET 8.0 | P | 6.101 ns | 0.25 |
Before moving on from primitives and numerics, let’s take a quick look at System.Random, which has methods for producing pseudo-random numerical values.
Random
dotnet/runtime#79790 from @mla-alm provides an implementation in Random based on @lemire‘s unbiased range functions. When a method like Next(int min, int max) is invoked, it needs to provide a value in the range [min, max). In order to provide an unbiased answer, the .NET 7 implementation generates a 32-bit value, narrows down the range to the smallest power of 2 that contains the max (by taking the log2 of the max and shifting to throw away bits), and then checks whether the result is less than the max: if it is, it returns the result as the answer. But if it’s not, it rejects the value (a process referred to as “rejection sampling”) and loops around to start the whole process over. While the cost to produce each sample in the current approach isn’t terrible, the nature of the approach makes it reasonably likely the sample will need to be rejected, which means looping and retries. With the new approach, it effectively implements modulo reduction (e.g. Next() % max), except replacing the expensive modulo operation with a cheaper multiplication and shift; then a rejection sampling loop is still employed, but the bias it corrects for happens much more rarely and thus the more expensive path happens much more rarely. The net result is a nice boost on average to the throughput of Random‘s methods (Random can also get a boost from dynamic PGO, as the internal abstraction Random uses can be devirtualized, so I’ve shown here the impact with and without PGO enabled.)
// dotnet run -c Release -f net7.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Environments;
using BenchmarkDotNet.Jobs;
using BenchmarkDotNet.Running;
var config = DefaultConfig.Instance
.AddJob(Job.Default.WithId(".NET 7").WithRuntime(CoreRuntime.Core70).AsBaseline())
.AddJob(Job.Default.WithId(".NET 8 w/o PGO").WithRuntime(CoreRuntime.Core80).WithEnvironmentVariable("DOTNET_TieredPGO", "0"))
.AddJob(Job.Default.WithId(".NET 8").WithRuntime(CoreRuntime.Core80));
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args, config);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "EnvironmentVariables")]
public class Tests
{
private static readonly Random s_rand = new();
[Benchmark]
public int NextMax() => s_rand.Next(12345);
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| NextMax | .NET 7.0 | 5.793 ns | 1.00 |
| NextMax | .NET 8.0 w/o PGO | 1.840 ns | 0.32 |
| NextMax | .NET 8.0 | 1.598 ns | 0.28 |
dotnet/runtime#87219 from @MichalPetryka then further improves this for long values. The core part of the algorithm involves multiplying the random value by the max value and then taking the low part of the product:
UInt128 randomProduct = (UInt128)maxValue * xoshiro.NextUInt64();
ulong lowPart = (ulong)randomProduct;This can be made more efficient by not using UInt128‘s multiplication implementation and instead using Math.BigMul,
ulong randomProduct = Math.BigMul(maxValue, xoshiro.NextUInt64(), out ulong lowPart);which is implemented to use the Bmi2.X64.MultiplyNoFlags or Armbase.Arm64.MultiplyHigh intrinsics when one is available.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "EnvironmentVariables")]
public class Tests
{
private static readonly Random s_rand = new();
[Benchmark]
public long NextMinMax() => s_rand.NextInt64(123456789101112, 1314151617181920);
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| NextMinMax | .NET 7.0 | 9.839 ns | 1.00 |
| NextMinMax | .NET 8.0 | 1.927 ns | 0.20 |
Finally, I’ll mention dotnet/runtime#81627. Random is both a commonly-used type in its own right and also an abstraction; many of the APIs on Random are virtual, such that a derived type can be implemented to completely swap out the algorithm employed. So, for example, if you wanted to implement a MersenneTwisterRandom that derived from Random and completely replaced the base algorithm by overriding every virtual method, you could do so, pass your instance around as Random, and everyone’s happy… unless you’re creating your derived type frequently and care about allocation. Random actually includes multiple pseudo-random generators. .NET 6 imbued it with an implementation of the xoshiro128**/xoshiro256** algorithms, which are used when you just do new Random(). However, if you instead instantiate a derived type, the implementation falls back to the same algorithm (a variant of Knuth’s subtractive random number generator algorithm) it’s used since the dawn of Random, as it doesn’t know what the derived type will be doing nor what dependencies it may have taken on the nature of the algorithm employed. That algorithm carries with it a 56-element int[], which means that derived classes end up instantiating and initializing that array even if they never use it. With this PR, the creation of that array is made lazy, such that it’s only initialized if and when it’s used. With that, a derived implementation that wants to avoid that cost can.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
[Benchmark] public Random NewDerived() => new NotRandomRandom();
private sealed class NotRandomRandom : Random { }
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| NewDerived | .NET 7.0 | 1,237.73 ns | 1.00 | 312 B | 1.00 |
| NewDerived | .NET 8.0 | 20.49 ns | 0.02 | 72 B | 0.23 |
Strings, Arrays, and Spans
.NET 8 sees a tremendous amount of improvement in the realm of data processing, in particular in the efficient manipulation of strings, arrays, and spans. Since we’ve just been talking about UTF8 and IUtf8SpanFormattable, let’s start there.
UTF8
As noted, IUtf8SpanFormattable is now implemented on a bunch of types. I noted all the numerical primitives, DateTime{Offset}, and Guid, and with dotnet/runtime#84556 the System.Version type also implements it, as do IPAddress and the new IPNetwork types, thanks to dotnet/runtime#84487. However, .NET 8 doesn’t just provide implementations of this interface on all of these types, it also consumes the interface in a key place.
If you’ll recall, string interpolation in C# 10 and .NET 6 was completely overhauled. This included not only making string interpolation much more efficient, but also in providing a pattern that a type could implement to allow for the string interpolation syntax to be used efficiently to do things other than create a new string. For example, a new TryWrite extension method for Span<char> was added that makes it possible to format an interpolated string directly into a destination char buffer:
public bool Format(Span<char> span, DateTime dt, out int charsWritten) =>
span.TryWrite($"Date: {dt:R}", out charsWritten);The above gets translated (“lowered”) by the compiler into the equivalent of the following:
public bool Format(Span<char> span, DateTime dt, out int charsWritten)
{
var handler = new MemoryExtensions.TryWriteInterpolatedStringHandler(6, 1, span, out bool shouldAppend);
_ = shouldAppend &&
handler.AppendLiteral("Date: ") &&
handler.AppendFormatted<DateTime>(dt, "R");
return MemoryExtensions.TryWrite(span, ref handler, out charsWritten);The implementation of that generic AppendFormatted<T> call examines the T and tries to do the most optimal thing. In this case, it’ll see that T implements ISpanFormattable, and it’ll end up using its TryFormat to format directly into the destination span.
That’s for UTF16. Now with IUtf8SpanFormattable, we have the opportunity to do the same thing but for UTF8. And that’s exactly what dotnet/runtime#83852 does. It introduces the new Utf8.TryWrite method, which behaves exactly like the aforementioned TryWrite, except writing as UTF8 into a destination Span<byte> instead of as UTF16 into a destination Span<char>. The implementation also special-cases IUtf8SpanFormattable, using its TryFormat to write directly into the destination buffer.
With that, we can write the equivalent to the method we wrote earlier:
public bool Format(Span<byte> span, DateTime dt, out int bytesWritten) =>
Utf8.TryWrite(span, $"Date: {dt:R}", out bytesWritten);and that gets lowered as you’d now expect:
public bool Format(Span<byte> span, DateTime dt, out int bytesWritten)
{
var handler = new Utf8.TryWriteInterpolatedStringHandler(6, 1, span, out bool shouldAppend);
_ = shouldAppend &&
handler.AppendLiteral("Date: ") &&
handler.AppendFormatted<DateTime>(dt, "R");
return Utf8.TryWrite(span, ref handler, out bytesWritten);So, identical, other than the parts you expect to change. But that’s also a problem in some ways. Take a look at that AppendLiteral("Date: ") call. In the UTF16 case where we’re dealing with a destination Span<char>, the implementation of AppendLiteral simply needs to copy that string into the destination; not only that, but the JIT will inline the call, see that a string literal is being copied, and will unroll the copy, making it super efficient. But in the UTF8 case, we can’t just copy the UTF16 string chars into the destination UTF8 Span<byte> buffer; we need to UTF8 encode the string. And while we can certainly do that (dotnet/runtime#84609 and dotnet/runtime#85120 make that trivial with the addition of a new Encoding.TryGetBytes method), it’s frustratingly inefficient to need to spend cycles repeatedly at run-time doing work that could be done at compile time. After all, we’re dealing with a string literal known at JIT time; it’d be really, really nice if the JIT could do the UTF8 encoding and then do an unrolled copy just as it’s already doing in the UTF16 case. And with dotnet/runtime#85328 and dotnet/runtime#89376, that’s exactly what happens, such that performance is effectively the same between them.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text.Unicode;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly char[] _chars = new char[100];
private readonly byte[] _bytes = new byte[100];
private readonly int _major = 1, _minor = 2, _build = 3, _revision = 4;
[Benchmark] public bool FormatUTF16() => _chars.AsSpan().TryWrite($"{_major}.{_minor}.{_build}.{_revision}", out int charsWritten);
[Benchmark] public bool FormatUTF8() => Utf8.TryWrite(_bytes, $"{_major}.{_minor}.{_build}.{_revision}", out int bytesWritten);
}| Method | Mean |
|---|---|
| FormatUTF16 | 19.07 ns |
| FormatUTF8 | 19.33 ns |
ASCII
UTF8 is the predominent encoding for text on the internet and for the movement of text between endpoints. However, much of this data is actually the ASCII subset, the 128 values in the range [0, 127]. When you know the data you’re working with is ASCII, you can achieve even better performance by using routines optimized for the subset. The new Ascii class in .NET 8, introduced in dotnet/runtime#75012 and dotnet/runtime#84886, and then further optimized in dotnet/runtime#85926 from @gfoidl,
dotnet/runtime#85266 from @Daniel-Svensson, dotnet/runtime#84881, and dotnet/runtime#87141, provides this:
namespace System.Text;
public static class Ascii
{
public static bool Equals(ReadOnlySpan<byte> left, ReadOnlySpan<byte> right);
public static bool Equals(ReadOnlySpan<byte> left, ReadOnlySpan<char> right);
public static bool Equals(ReadOnlySpan<char> left, ReadOnlySpan<byte> right);
public static bool Equals(ReadOnlySpan<char> left, ReadOnlySpan<char> right);
public static bool EqualsIgnoreCase(ReadOnlySpan<byte> left, ReadOnlySpan<byte> right);
public static bool EqualsIgnoreCase(ReadOnlySpan<byte> left, ReadOnlySpan<char> right);
public static bool EqualsIgnoreCase(ReadOnlySpan<char> left, ReadOnlySpan<byte> right);
public static bool EqualsIgnoreCase(ReadOnlySpan<char> left, ReadOnlySpan<char> right);
public static bool IsValid(byte value);
public static bool IsValid(char value);
public static bool IsValid(ReadOnlySpan<byte> value);
public static bool IsValid(ReadOnlySpan<char> value);
public static OperationStatus ToLower(ReadOnlySpan<byte> source, Span<byte> destination, out int bytesWritten);
public static OperationStatus ToLower(ReadOnlySpan<char> source, Span<char> destination, out int charsWritten);
public static OperationStatus ToLower(ReadOnlySpan<byte> source, Span<char> destination, out int charsWritten);
public static OperationStatus ToLower(ReadOnlySpan<char> source, Span<byte> destination, out int bytesWritten);
public static OperationStatus ToUpper(ReadOnlySpan<byte> source, Span<byte> destination, out int bytesWritten);
public static OperationStatus ToUpper(ReadOnlySpan<char> source, Span<char> destination, out int charsWritten);
public static OperationStatus ToUpper(ReadOnlySpan<byte> source, Span<char> destination, out int charsWritten);
public static OperationStatus ToUpper(ReadOnlySpan<char> source, Span<byte> destination, out int bytesWritten);
public static OperationStatus ToLowerInPlace(Span<byte> value, out int bytesWritten);
public static OperationStatus ToLowerInPlace(Span<char> value, out int charsWritten);
public static OperationStatus ToUpperInPlace(Span<byte> value, out int bytesWritten);
public static OperationStatus ToUpperInPlace(Span<char> value, out int charsWritten);
public static OperationStatus FromUtf16(ReadOnlySpan<char> source, Span<byte> destination, out int bytesWritten);
public static OperationStatus ToUtf16(ReadOnlySpan<byte> source, Span<char> destination, out int charsWritten);
public static Range Trim(ReadOnlySpan<byte> value);
public static Range Trim(ReadOnlySpan<char> value);
public static Range TrimEnd(ReadOnlySpan<byte> value);
public static Range TrimEnd(ReadOnlySpan<char> value);
public static Range TrimStart(ReadOnlySpan<byte> value);
public static Range TrimStart(ReadOnlySpan<char> value);
}Note that it provides overloads that operate on UTF16 (char) and UTF8 (byte), and in many cases, intermixes them, such that you can, for example, compare a UTF8 ReadOnlySpan<byte> with a UTF16 ReadOnlySpan<char>, or transcode a UTF16 ReadOnlySpan<char> to a UTF8 ReadOnlySpan<byte> (which, when working with ASCII, is purely a narrowing operation, getting rid of the leading 0 byte in each char). For example, the PR that added these methods also used them in a variety of places (something I advocate for strongly, in order to ensure what has been designed is actually meeting the need, or ensure that other core library code is benefiting from the new APIs, which in turn makes those APIs more valuable, as their benefits accrue to more indirect consumers), including in multiple places in SocketsHttpHandler. Previously, SocketsHttpHandler had its own helpers for this purpose, an example of which I’ve copied here into this benchmark:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly byte[] _bytes = "Strict-Transport-Security"u8.ToArray();
private readonly string _chars = "Strict-Transport-Security";
[Benchmark(Baseline = true)]
public bool Equals_OpenCoded() => EqualsOrdinalAsciiIgnoreCase(_chars, _bytes);
[Benchmark]
public bool Equals_Ascii() => Ascii.EqualsIgnoreCase(_chars, _bytes);
internal static bool EqualsOrdinalAsciiIgnoreCase(string left, ReadOnlySpan<byte> right)
{
if (left.Length != right.Length)
return false;
for (int i = 0; i < left.Length; i++)
{
uint charA = left[i], charB = right[i];
if ((charA - 'a') <= ('z' - 'a')) charA -= ('a' - 'A');
if ((charB - 'a') <= ('z' - 'a')) charB -= ('a' - 'A');
if (charA != charB)
return false;
}
return true;
}
}| Method | Mean | Ratio |
|---|---|---|
| Equals_OpenCoded | 31.159 ns | 1.00 |
| Equals_Ascii | 3.985 ns | 0.13 |
Many of these new Ascii APIs also got the Vector512 treatment, such that they light up when AVX512 is supported by the current machine, thanks to dotnet/runtime#88532 from @anthonycanino and dotnet/runtime#88650 from @khushal1996.
Base64
An even further constrained subset of text is Base64-encoded data. This is used when arbitrary bytes need to be transferred as text, and results in text that uses only 64 characters (lowercase ASCII letters, uppercase ASCII letters, ASCII digits, ‘+’, and ‘/’). .NET has long had methods on System.Convert for encoding and decoding Base64 with UTF16 (char), and it got an additional set of span-based methods in .NET Core 2.1 with the introduction of Span<T>. At that point, the System.Text.Buffers.Base64 class was also introduced, with dedicated surface area for encoding and decoding Base64 with UTF8 (byte). That’s now improved further in .NET 8.
dotnet/runtime#85938 from @heathbm and dotnet/runtime#86396 make two contributions here. First, they bring the behavior of the Base64.Decode methods for UTF8 in line with its counterparts on the Convert class, in particular around handling of whitespace. As it’s very common for there to be newlines in Base64-encoded data, the Convert class’ methods for decoding Base64 permitted whitespace; in contrast, the Base64 class’ methods for decoding would fail if whitespace was encountered. These decoding methods now permit exactly the same whitespace that Convert does. And that’s important in part because of the second contribution from these PRs, which is a new set of Base64.IsValid static methods. As with Ascii.IsValid and Utf8.IsValid, these methods simply state whether the supplied UTF8 or UTF16 input represents a valid Base64 input, such that the decoding methods on both Convert and Base64 could successfully decode it. And as with all such processing we see introduced into .NET, we’ve strived to make the new functionality as efficient as possible so that it can be used to maximal benefit elsewhere. For example, dotnet/runtime#86221 from @WeihanLi updated the new Base64Attribute to use it, and dotnet/runtime#86002 updated PemEncoding.TryCountBase64 to use it. Here we can see a benchmark comparing the old non-vectorized TryCountBase64 with the new version using the vectorized Base64.IsValid:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Buffers.Text;
using System.Runtime.CompilerServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly string _exampleFromPemEncodingTests =
"MHQCAQEEICBZ7/8T1JL2amvNB/QShghtgZPtnPD4W+sAcHxA+hJsoAcGBSuBBAAK\n" +
"oUQDQgAE3yNC5as8JVN5MjF95ofNSgRBVXjf0CKtYESWfPnmvT3n+cMMJUB9lUJf\n" +
"dkFNgaSB7JlB+krZVVV8T7HZQXVDRA==\n";
[Benchmark(Baseline = true)]
public bool Count_Old() => TryCountBase64_Old(_exampleFromPemEncodingTests, out _, out _, out _);
[Benchmark]
public bool Count_New() => TryCountBase64_New(_exampleFromPemEncodingTests, out _, out _, out _);
private static bool TryCountBase64_New(ReadOnlySpan<char> str, out int base64Start, out int base64End, out int base64DecodedSize)
{
int start = 0, end = str.Length - 1;
for (; start < str.Length && IsWhiteSpaceCharacter(str[start]); start++) ;
for (; end > start && IsWhiteSpaceCharacter(str[end]); end--) ;
if (Base64.IsValid(str.Slice(start, end + 1 - start), out base64DecodedSize))
{
base64Start = start;
base64End = end + 1;
return true;
}
base64Start = 0;
base64End = 0;
return false;
}
private static bool TryCountBase64_Old(ReadOnlySpan<char> str, out int base64Start, out int base64End, out int base64DecodedSize)
{
base64Start = 0;
base64End = str.Length;
if (str.IsEmpty)
{
base64DecodedSize = 0;
return true;
}
int significantCharacters = 0;
int paddingCharacters = 0;
for (int i = 0; i < str.Length; i++)
{
char ch = str[i];
if (IsWhiteSpaceCharacter(ch))
{
if (significantCharacters == 0) base64Start++;
else base64End--;
continue;
}
base64End = str.Length;
if (ch == '=') paddingCharacters++;
else if (paddingCharacters == 0 && IsBase64Character(ch)) significantCharacters++;
else
{
base64DecodedSize = 0;
return false;
}
}
int totalChars = paddingCharacters + significantCharacters;
if (paddingCharacters > 2 || (totalChars & 0b11) != 0)
{
base64DecodedSize = 0;
return false;
}
base64DecodedSize = (totalChars >> 2) * 3 - paddingCharacters;
return true;
}
[MethodImpl(MethodImplOptions.AggressiveInlining)]
private static bool IsBase64Character(char ch) => char.IsAsciiLetterOrDigit(ch) || ch is '+' or '/';
[MethodImpl(MethodImplOptions.AggressiveInlining)]
private static bool IsWhiteSpaceCharacter(char ch) => ch is ' ' or '\t' or '\n' or '\r';
}| Method | Mean | Ratio |
|---|---|---|
| Count_Old | 356.37 ns | 1.00 |
| Count_New | 33.72 ns | 0.09 |
Hex
Another relevant subset of ASCII is hexadecimal, and improvements have been made in .NET 8 around conversions between bytes and their representation in hex. In particular, dotnet/runtime#82521 vectorized the Convert.FromHexString method using an algorithm outlined by Langdale and Mula. On even a moderate length input, this has a very measurable impact on throughput:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Security.Cryptography;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private string _hex;
[Params(4, 16, 128)]
public int Length { get; set; }
[GlobalSetup]
public void Setup() => _hex = Convert.ToHexString(RandomNumberGenerator.GetBytes(Length));
[Benchmark]
public byte[] ConvertFromHex() => Convert.FromHexString(_hex);
}| Method | Runtime | Length | Mean | Ratio |
|---|---|---|---|---|
| ConvertFromHex | .NET 7.0 | 4 | 24.94 ns | 1.00 |
| ConvertFromHex | .NET 8.0 | 4 | 20.71 ns | 0.83 |
| ConvertFromHex | .NET 7.0 | 16 | 57.66 ns | 1.00 |
| ConvertFromHex | .NET 8.0 | 16 | 17.29 ns | 0.30 |
| ConvertFromHex | .NET 7.0 | 128 | 337.41 ns | 1.00 |
| ConvertFromHex | .NET 8.0 | 128 | 56.72 ns | 0.17 |
Of course, the improvements in .NET 8 go well beyond just the manipulation of certain known sets of characters; there is a wealth of other improvements to explore. Let’s start with System.Text.CompositeFormat, which was introduced in dotnet/runtime#80753.
String Formatting
Since the beginning of .NET, string and friends have provided APIs for handling composite format strings, strings with text interspersed with format item placeholders, e.g. "The current time is {0:t}". These strings can then be passed to various APIs, like string.Format, which are provided with both the composite format string and the arguments that should be substituted in for the placeholders, e.g. string.Format("The current time is {0:t}", DateTime.Now) will return a string like "The current time is 3:44 PM" (the 0 in the placeholder indicates the 0-based number of the argument to substitute, and the t is the format that should be used, in this case the standard short time pattern). Such a method invocation needs to parse the composite format string each time it’s called, even though for a given call site the composite format string typically doesn’t change from invocation to invocation. These APIs are also generally non-generic, which means if an argument is a value type (as is DateTime in my example), it’ll incur a boxing allocation. To simplify the syntax around these operations, C# 6 gained support for string interpolation, such that instead of writing string.Format(null, "The current time is {0:t}", DateTime.Now), you could instead write $"The current time is {DateTime.Now:t}", and it was then up to the compiler to achieve the same behavior as if string.Format had been used (which the compiler typically achieved simply by lowering the interpolation into a call to string.Format).
In .NET 6 and C# 10, string interpolation was significantly improved, both in terms of the scenarios supported and in terms of its efficiency. One key aspect of the efficiency is it enabled the parsing to be performed once (at compile-time). It also enabled avoiding all of the allocation associated with providing arguments. These improvements contributed to all use of string interpolation and a significant portion of the use of string.Format in real-world applications and services. However, the compiler support works by being able to see the string at compile time. What if the format string isn’t known until run-time, such as if it’s pulled from a .resx resource file or some other source of configuration? At that point, string.Format remains the answer.
Now in .NET 8, there’s a new answer available: CompositeFormat. Just as an interpolated string allows the compiler to do the heavy lifting once in order to optimize repeated use, CompositeFormat allows that reusable work to be done once in order to optimize repeated use. As it does the parsing at run-time, it’s able to tackle the remaining cases that string interpolation can’t reach. To create an instance, one simply calls its Parse method, which takes a composite format string, parses it, and returns a CompositeFormat instance:
private static readonly CompositeFormat s_currentTimeFormat = CompositeFormat.Parse(SR.CurrentTime);Then, existing methods like string.Format now have new overloads, exactly the same as the existing ones, but instead of taking a string format, they take a CompositeFormat format. The same formatting as was done earlier can then instead be done like this:
string result = string.Format(null, s_currentTimeFormat, DateTime.Now);This overload (and other new overloads of methods like StringBuilder.AppendFormat and MemoryExtensions.TryWrite) accepts generic arguments, avoiding the boxing.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private static readonly CompositeFormat s_format = CompositeFormat.Parse(SR.CurrentTime);
[Benchmark(Baseline = true)]
public string FormatString() => string.Format(null, SR.CurrentTime, DateTime.Now);
[Benchmark]
public string FormatComposite() => string.Format(null, s_format, DateTime.Now);
}
internal static class SR
{
public static string CurrentTime => /*load from resource file*/"The current time is {0:t}";
}| Method | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|
| FormatString | 163.6 ns | 1.00 | 96 B | 1.00 |
| FormatComposite | 146.5 ns | 0.90 | 72 B | 0.75 |
If you know the composite format string at compile time, interpolated strings are the answer. Otherwise, CompositeFormat can give you throughput in the same ballpark at the expense of some startup costs. Formatting with a CompositeFormat is actually implemented with the same interpolated string handlers that are used for string interpolation, e.g. string.Format(..., compositeFormat, ...) ends up calling into methods on DefaultInterpolatedStringHandler to do the actual formatting work.
There’s also a new analyzer to help with this. CA1863 “Use ‘CompositeFormat'” was introduced in dotnet/roslyn-analyzers#6675 to identify string.Format and StringBuilder.AppendFormat calls that could possibly benefit from switching to use a CompositeFormat argument instead.
Spans
Moving on from formatting, let’s turn our attention to all the other kinds of operations one frequently wants to perform on sequences of data, whether that be arrays, strings, or the unifying force of spans. A home for many routines for manipulating all of these, via spans, is the System.MemoryExtensions type, which has received a multitude of new APIs in .NET 8.
One very common operation is to count how many of something there are. For example, in support of multiline comments, System.Text.Json needs to count how many line feed characters there are in a given piece of JSON. This is, of course, trivial to write as a loop, whether character-by-character or using IndexOf and slicing. Now in .NET 8, you can also just call the Count extension method, thanks to dotnet/runtime#80662 from @bollhals and dotnet/runtime#82687 from @gfoidl. Here we’re counting the number of line feed characters in “The Adventures of Sherlock Holmes” from Project Gutenberg:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private static readonly byte[] s_utf8 = new HttpClient().GetByteArrayAsync("https://www.gutenberg.org/files/1661/1661-0.txt").Result;
[Benchmark(Baseline = true)]
public int Count_ForeachLoop()
{
int count = 0;
foreach (byte c in s_utf8)
{
if (c == '\n') count++;
}
return count;
}
[Benchmark]
public int Count_IndexOf()
{
ReadOnlySpan<byte> remaining = s_utf8;
int count = 0;
int pos;
while ((pos = remaining.IndexOf((byte)'\n')) >= 0)
{
count++;
remaining = remaining.Slice(pos + 1);
}
return count;
}
[Benchmark]
public int Count_Count() => s_utf8.AsSpan().Count((byte)'\n');
}| Method | Mean | Ratio |
|---|---|---|
| Count_ForeachLoop | 314.23 us | 1.00 |
| Count_IndexOf | 95.39 us | 0.30 |
| Count_Count | 13.68 us | 0.04 |
The core of the implementation here that enables MemoryExtensions.Count to be so fast, in particular when searching for a single value, is based on just two key primitives: PopCount and ExtractMostSignificantBits. Here’s the Vector128 loop that forms the bulk of the Count implementation (the implementation has similar loops for Vector256 and Vector512 as well):
Vector128<T> targetVector = Vector128.Create(value);
ref T oneVectorAwayFromEnd = ref Unsafe.Subtract(ref end, Vector128<T>.Count);
do
{
count += BitOperations.PopCount(Vector128.Equals(Vector128.LoadUnsafe(ref current), targetVector).ExtractMostSignificantBits());
current = ref Unsafe.Add(ref current, Vector128<T>.Count);
}
while (!Unsafe.IsAddressGreaterThan(ref current, ref oneVectorAwayFromEnd));This is creating a vector where every element of the vector is the target (in this case, '\n'). Then, as long as there’s at least one vector’s worth of data remaining, it loads the next vector (Vector128.LoadUnsafe) and compares that with the target vector (Vector128.Equals). That produces a new Vector128<T> where each T element is all ones when the values are equal and all zeros when they’re not. We then extract out the most significant bit of each element (ExtractMostSignificantBits), so getting a bit with the value 1 where the values were equal, otherwise 0. And then we use BitOperations.PopCount on the resulting uint to get the “population count,” i.e. the number of bits that are 1, and we add that to our running tally. In this way, the inner loop of the count operation remains branch-free, and the implementation can churn through the data very quickly. You can find several examples of using Count in dotnet/runtime#81325, which used it in several places in the core libraries.
A similar new MemoryExtensions method is Replace, which comes in .NET 8 in two shapes. dotnet/runtime#76337 from @gfoidl added an in-place variant:
public static unsafe void Replace<T>(this Span<T> span, T oldValue, T newValue) where T : IEquatable<T>?;and dotnet/runtime#83120 added a copying variant:
public static unsafe void Replace<T>(this ReadOnlySpan<T> source, Span<T> destination, T oldValue, T newValue) where T : IEquatable<T>?;As an example of where this comes in handy, Uri has some code paths that need to normalize directory separators to be '/', such that any '\\' characters need to be replaced. This previously used an IndexOf loop as was shown in the previous Count benchmark, and now it can just use Replace. Here’s a comparison (which, purely for benchmarking purposes, is normalizing back and forth so that each time the benchmark runs it finds things in the original state):
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly char[] _uri = "server/somekindofpathneeding/normalizationofitsslashes".ToCharArray();
[Benchmark(Baseline = true)]
public void Replace_ForLoop()
{
Replace(_uri, '/', '\\');
Replace(_uri, '\\', '/');
static void Replace(char[] chars, char from, char to)
{
for (int i = 0; i < chars.Length; i++)
{
if (chars[i] == from)
{
chars[i] = to;
}
}
}
}
[Benchmark]
public void Replace_IndexOf()
{
Replace(_uri, '/', '\\');
Replace(_uri, '\\', '/');
static void Replace(char[] chars, char from, char to)
{
Span<char> remaining = chars;
int pos;
while ((pos = remaining.IndexOf(from)) >= 0)
{
remaining[pos] = to;
remaining = remaining.Slice(pos + 1);
}
}
}
[Benchmark]
public void Replace_Replace()
{
_uri.AsSpan().Replace('/', '\\');
_uri.AsSpan().Replace('\\', '/');
}
}| Method | Mean | Ratio |
|---|---|---|
| Replace_ForLoop | 40.28 ns | 1.00 |
| Replace_IndexOf | 29.26 ns | 0.73 |
| Replace_Replace | 18.88 ns | 0.47 |
The new Replace does better than both the manual loop and the IndexOf loop. As with Count, Replace has a fairly simple and tight inner loop; again, here’s the Vector128 variant of that loop:
do
{
original = Vector128.LoadUnsafe(ref src, idx);
mask = Vector128.Equals(oldValues, original);
result = Vector128.ConditionalSelect(mask, newValues, original);
result.StoreUnsafe(ref dst, idx);
idx += (uint)Vector128<T>.Count;
}
while (idx < lastVectorIndex);This is loading the next vector’s worth of data (Vector128.LoadUnsafe) and comparing that with a vector filled with the oldValue, which produces a new mask vector with 1s for equality and 0 for inequality. It then calls the super handy Vector128.ConditionalSelect. This is a branchless SIMD condition operation: it produces a new vector that has an element from one vector if mask’s bits were 1s and from another vector if the mask’s bits were 0s (think a ternary operator). That resulting vector is then saved out as the result. In this manner, it’s overwriting the whole span, in some cases just writing back the value that was previously there, and in cases where the original value was the target oldValue, writing out the newValue instead. This loop body is branch-free and doesn’t change in cost based on how many elements need to be replaced. In an extreme case where there’s nothing to be replaced, an IndexOf-based loop could end up being a tad bit faster, since the body of IndexOf‘s inner loop has even fewer instructions, but such an IndexOf loop pays a relatively high cost for every replacement that needs to be done.
StringBuilder also had such an IndexOf-based implementation for its Replace(char oldChar, char newChar) and Replace(char oldChar, char newChar, int startIndex, int count) methods, and they’re now based on MemoryExtensions.Replace, so the improvements accrue there as well.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly StringBuilder _sb = new StringBuilder("http://server\\this\\is\\a\\test\\of\\needing\\to\\normalize\\directory\\separators\\");
[Benchmark]
public void Replace()
{
_sb.Replace('\\', '/');
_sb.Replace('/', '\\');
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Replace | .NET 7.0 | 150.47 ns | 1.00 |
| Replace | .NET 8.0 | 24.79 ns | 0.16 |
Interestingly, whereas StringBuilder.Replace(char, char) was using IndexOf and switched to use Replace, StringBuilder.Replace(string, string) wasn’t using IndexOf at all, a gap that’s been fixed in dotnet/runtime#81098. IndexOf when dealing with strings is more complicated in StringBuilder because of its segmented nature. StringBuilder isn’t just backed by an array: it’s actually a linked list of segments, each of which stores an array. With the char-based Replace, it can simply operate on each segment individually, but for the string-based Replace, it needs to deal with the possibility that the value being searched for crosses a segment boundary. StringBuilder.Replace(string, string) was thus walking each segment character-by-character, doing an equality check at each position. Now with this PR, it’s using IndexOf and only falling back to a character-by-character check when close enough to a segment boundary that it might be crossed.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly StringBuilder _sb = new StringBuilder()
.Append("Shall I compare thee to a summer's day? ")
.Append("Thou art more lovely and more temperate: ")
.Append("Rough winds do shake the darling buds of May, ")
.Append("And summer's lease hath all too short a date; ")
.Append("Sometime too hot the eye of heaven shines, ")
.Append("And often is his gold complexion dimm'd; ")
.Append("And every fair from fair sometime declines, ")
.Append("By chance or nature's changing course untrimm'd; ")
.Append("But thy eternal summer shall not fade, ")
.Append("Nor lose possession of that fair thou ow'st; ")
.Append("Nor shall death brag thou wander'st in his shade, ")
.Append("When in eternal lines to time thou grow'st: ")
.Append("So long as men can breathe or eyes can see, ")
.Append("So long lives this, and this gives life to thee.");
[Benchmark]
public void Replace()
{
_sb.Replace("summer", "winter");
_sb.Replace("winter", "summer");
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Replace | .NET 7.0 | 5,158.0 ns | 1.00 |
| Replace | .NET 8.0 | 476.4 ns | 0.09 |
As long as we’re on the subject of StringBuilder, it saw some other nice improvements in .NET 8. dotnet/runtime#85894 from @yesmey tweaked both StringBuilder.Append(string value) and the JIT to enable the JIT to unroll the memory copies that occur as part of appending a constant string.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly StringBuilder _sb = new();
[Benchmark]
public void Append()
{
_sb.Clear();
_sb.Append("This is a test of appending a string to StringBuilder");
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Append | .NET 7.0 | 7.597 ns | 1.00 |
| Append | .NET 8.0 | 3.756 ns | 0.49 |
And dotnet/runtime#86287 from @yesmey changed StringBuilder.Append(char value, int repeatCount) to use Span<T>.Fill instead of manually looping, taking advantage of the optimized Fill implementation, even for reasonably small counts.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly StringBuilder _sb = new();
[Benchmark]
public void Append()
{
_sb.Clear();
_sb.Append('x', 8);
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Append | .NET 7.0 | 11.520 ns | 1.00 |
| Append | .NET 8.0 | 5.292 ns | 0.46 |
Back to MemoryExtensions, another new helpful method is MemoryExtensions.Split (and MemoryExtensions.SplitAny). This is a span-based counterpart to string.Split for some uses of string.Split. I say “some” because there are effectively two main patterns for using string.Split: when you expect a certain number of parts, and when there are an unknown number of parts. For example, if you want to parse a version string as would be used by System.Version, there are at most four parts (“major.minor.build.revision”). But if you want to split, say, the contents of a file into all of the lines in the file (delimited by a \n), that’s an unknown (and potentially quite large) number of parts. The new MemoryExtensions.Split method is focused on the situations where there’s a known (and reasonably small) maximum number of parts expected. In such a case, it can be significantly more efficient than string.Split, especially from an allocation perspective.
string.Split has overloads that accept an int count, and MemoryExtensions.Split behaves identically to these overloads; however, rather than giving it an int count, you give it a Span<Range> destination whose length is the same value you would have used for count. For example, let’s say you want to split a key/value pair separated by an '='. If this were string.Split, you could write that as:
string[] parts = keyValuePair.Split('=');Of course, if the input was actually erroneous for what you were expecting and there were 100 equal signs, you’d end up creating an array of 101 strings. So instead, you might write that as:
string[] parts = keyValuePair.Split('=', 3);Wait, “3”? Aren’t there only two parts, and if so, why not pass “2”? Because of the behavior of what happens with the last part. The last part contains the remainder of the string after the separator before it, so for example the call:
"shall=i=compare=thee".Split(new[] { '=' }, 2)produces the array:
string[2] { "shall", "i=compare=thee" }If you want to know whether there were more than two parts, you need to request at least one more, and then if that last one was produced, you know the input was erroneous. For example, this:
"shall=i=compare=thee".Split(new[] { '=' }, 3)produces this:
string[3] { "shall", "i", "compare=thee" }and this:
"shall=i".Split(new[] { '=' }, 3)produces this:
string[2] { "shall", "i" }We can do the same thing with the new overload, except a) the caller provides the destination span to write the results into, and b) the results are stored as a System.Range rather than as a string. That means that the whole operation is allocation-free. And thanks to the indexer on Span<T> that lets you pass in a Range and slice the span, you can easily use the written ranges to access the relevant portions of the input.
Span<Range> parts = stackalloc Range[3];
int count = keyValuePairSpan.Split(parts, '=');
if (count == 2)
{
Console.WriteLine($"Key={keyValuePairSpan[parts[0]]}, Value={keyValuePairSpan[parts[1]]}");"
}Here’s an example from dotnet/runtime#80211, which used SplitAny to reduce the cost of MimeBasePart.DecodeEncoding:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly string _input = "=?utf-8?B?RmlsZU5hbWVf55CG0Y3Qq9C60I5jw4TRicKq0YIM0Y1hSsSeTNCy0Klh?=";
private static readonly char[] s_decodeEncodingSplitChars = new char[] { '?', '\r', '\n' };
[Benchmark(Baseline = true)]
public Encoding Old()
{
if (string.IsNullOrEmpty(_input))
{
return null;
}
string[] subStrings = _input.Split(s_decodeEncodingSplitChars);
if (subStrings.Length < 5 ||
subStrings[0] != "=" ||
subStrings[4] != "=")
{
return null;
}
string charSet = subStrings[1];
return Encoding.GetEncoding(charSet);
}
[Benchmark]
public Encoding New()
{
if (string.IsNullOrEmpty(_input))
{
return null;
}
ReadOnlySpan<char> valueSpan = _input;
Span<Range> subStrings = stackalloc Range[6];
if (valueSpan.SplitAny(subStrings, "?\r\n") < 5 ||
valueSpan[subStrings[0]] is not "=" ||
valueSpan[subStrings[4]] is not "=")
{
return null;
}
return Encoding.GetEncoding(_input[subStrings[1]]);
}
}| Method | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|
| Old | 143.80 ns | 1.00 | 304 B | 1.00 |
| New | 94.52 ns | 0.66 | 32 B | 0.11 |
More examples of MemoryExtensions.Split and MemoryExtensions.SplitAny being used are in dotnet/runtime#80471 and dotnet/runtime#82007. Both of those remove allocations from various System.Net types that were previously using string.Split.
MemoryExtensions also includes a new set of IndexOf methods for ranges, thanks to dotnet/runtime#76803:
public static int IndexOfAnyInRange<T>(this ReadOnlySpan<T> span, T lowInclusive, T highInclusive) where T : IComparable<T>;
public static int IndexOfAnyExceptInRange<T>(this ReadOnlySpan<T> span, T lowInclusive, T highInclusive) where T : IComparable<T>;
public static int LastIndexOfAnyInRange<T>(this ReadOnlySpan<T> span, T lowInclusive, T highInclusive) where T : IComparable<T>;
public static int LastIndexOfAnyExceptInRange<T>(this ReadOnlySpan<T> span, T lowInclusive, T highInclusive) where T : IComparable<T>;Want to find the index of the next ASCII digit? No problem:
int pos = text.IndexOfAnyInRange('0', '9');Want to determine whether some input contains any non-ASCII or control characters? You got it:
bool nonAsciiOrControlCharacters = text.IndexOfAnyExceptInRange((char)0x20, (char)0x7e) >= 0;For example, dotnet/runtime#78658 uses IndexOfAnyInRange to quickly determine whether portions of a Uri might contain a bidirectional control character, searching for anything in the range [\u200E, \u202E], and then only examining further if anything in that range is found. And dotnet/runtime#79357 uses IndexOfAnyExceptInRange to determine whether to use Encoding.UTF8 or Encoding.ASCII. It was previously implemented with a simple foreach loop, and it’s now implemented with an even simpler call to IndexOfAnyExceptInRange:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly string _text =
"Shall I compare thee to a summer's day? " +
"Thou art more lovely and more temperate: " +
"Rough winds do shake the darling buds of May, " +
"And summer's lease hath all too short a date; " +
"Sometime too hot the eye of heaven shines, " +
"And often is his gold complexion dimm'd; " +
"And every fair from fair sometime declines, " +
"By chance or nature's changing course untrimm'd; " +
"But thy eternal summer shall not fade, " +
"Nor lose possession of that fair thou ow'st; " +
"Nor shall death brag thou wander'st in his shade, " +
"When in eternal lines to time thou grow'st: " +
"So long as men can breathe or eyes can see, " +
"So long lives this, and this gives life to thee.";
[Benchmark(Baseline = true)]
public Encoding Old()
{
foreach (char c in _text)
if (c > 126 || c < 32)
return Encoding.UTF8;
return Encoding.ASCII;
}
[Benchmark]
public Encoding New() =>
_text.AsSpan().IndexOfAnyExceptInRange((char)32, (char)126) >= 0 ?
Encoding.UTF8 :
Encoding.ASCII;
}| Method | Mean | Ratio |
|---|---|---|
| Old | 297.56 ns | 1.00 |
| New | 20.69 ns | 0.07 |
More of a productivity thing than performance (at least today), but .NET 8 also includes new ContainsAny methods (dotnet/runtime#87621) that allow writing these kind of IndexOf calls that are then compared against 0 in a slightly cleaner fashion, e.g. the previous example could have been simplified slightly to:
public Encoding New() =>
_text.AsSpan().ContainsAnyExceptInRange((char)32, (char)126) ?
Encoding.UTF8 :
Encoding.ASCII;One of the things I love about these kinds of helpers is that code can simplify down to use them, and then as the helpers improve, so too does the code that relies on them. And in .NET 8, there’s a lot of “the helpers improve.”
dotnet/runtime#86655 from @DeepakRajendrakumaran added support for Vector512 to most of these span-based helpers in MemoryExtensions. That means that when running on hardware which supports AVX512, many of these operations simply get faster. This benchmark uses environment variables to explicitly disable support for the various instruction sets, such that we can compare performance of a given operation when nothing is vectorized, when Vector128 is used and hardware accelerated, when Vector256 is used and hardware accelerated, and when Vector512 is used and hardware accelerated. I’ve run this on my Dev Box that does support AVX512:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Jobs;
using BenchmarkDotNet.Running;
using BenchmarkDotNet.Toolchains.CoreRun;
var config = DefaultConfig.Instance
.AddJob(Job.Default.WithId("Scalar").WithEnvironmentVariable("DOTNET_EnableHWIntrinsic", "0").AsBaseline())
.AddJob(Job.Default.WithId("Vector128").WithEnvironmentVariable("DOTNET_EnableAVX512F", "0").WithEnvironmentVariable("DOTNET_EnableAVX2", "0"))
.AddJob(Job.Default.WithId("Vector256").WithEnvironmentVariable("DOTNET_EnableAVX512F", "0"))
.AddJob(Job.Default.WithId("Vector512"));
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args, config);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "EnvironmentVariables")]
public class Tests
{
private readonly char[] _sourceChars = Enumerable.Repeat('a', 1024).ToArray();
[Benchmark]
public bool Contains() => _sourceChars.AsSpan().IndexOfAny('b', 'c') >= 0;
}| Method | Job | Mean | Ratio |
|---|---|---|---|
| Contains | Scalar | 491.50 ns | 1.00 |
| Contains | Vector128 | 53.77 ns | 0.11 |
| Contains | Vector256 | 34.75 ns | 0.07 |
| Contains | Vector512 | 21.12 ns | 0.04 |
So, not quite a halving going from 128-bit to 256-bit or another halving going from 256-bit to 512-bit, but pretty close.
dotnet/runtime#77947 vectorized Equals(..., StringComparison.OrdinalIgnoreCase) for large enough inputs (the same underlying implementation is used for both string and ReadOnlySpan<char>). In a loop, it loads the next two vectors. It then checks to see whether anything in those vectors is non-ASCII; it can do so efficiently by OR’ing them together (vec1 | vec2) and then seeing whether the high bit of any of the elements is set… if none are, then all the elements in both of the input vectors are ASCII (((vec1 | vec2) & Vector128.Create(unchecked((ushort)~0x007F))) == Vector128<ushort>.Zero). If it finds anything non-ASCII, it just continues on with the old mode of comparison. But as long as everything is ASCII, then it can proceed to do the comparison in a vectorized manner. For each vector, it uses some bit hackery to create a lowercased version of the vector, and then compares the lowercased versions for equality.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly string _a = "shall i compare thee to a summer's day? thou art more lovely and more temperate";
private readonly string _b = "SHALL I COMPARE THEE TO A SUMMER'S DAY? THOU ART MORE LOVELY AND MORE TEMPERATE";
[Benchmark]
public bool Equals() => _a.AsSpan().Equals(_b, StringComparison.OrdinalIgnoreCase);
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Equals | .NET 7.0 | 47.97 ns | 1.00 |
| Equals | .NET 8.0 | 18.93 ns | 0.39 |
dotnet/runtime#78262 uses the same tricks to vectorize ToLowerInvariant and ToUpperInvariant:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly string _a = "shall i compare thee to a summer's day? thou art more lovely and more temperate";
private readonly char[] _b = new char[100];
[Benchmark]
public int ToUpperInvariant() => _a.AsSpan().ToUpperInvariant(_b);
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| ToUpperInvariant | .NET 7.0 | 33.22 ns | 1.00 |
| ToUpperInvariant | .NET 8.0 | 16.16 ns | 0.49 |
dotnet/runtime#78650 from @yesmey also streamlined MemoryExtensions.Reverse:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly byte[] _bytes = Enumerable.Range(0, 32).Select(i => (byte)i).ToArray();
[Benchmark]
public void Reverse() => _bytes.AsSpan().Reverse();
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Reverse | .NET 7.0 | 3.801 ns | 1.00 |
| Reverse | .NET 8.0 | 2.052 ns | 0.54 |
dotnet/runtime#75640 improves the internal RuntimeHelpers.IsBitwiseEquatable method that’s used by the vast majority of MemoryExtensions. If you look in the source for MemoryExtensions, you’ll find a fairly common pattern: special-case byte, ushort, uint, and ulong with a vectorized implementation, and then fall back to a general non-vectorized implementation for everything else. Except it’s not exactly “special-case byte, ushort, uint, and ulong“, but rather “special-case bitwise-equatable types that are the same size as byte, ushort, uint, or ulong.” If something is “bitwise equatable,” that means we don’t need to worry about any IEquatable<T> implementation it might provide or any Equals override it might have, and we can instead simply rely on the value’s bits being the same or different from another value to identify whether the values are the same or different. And if such bitwise equality semantics apply for a type, then the intrinsics that determine equality for byte, ushort, uint, and ulong can be used for any type that’s 1, 2, 4, or 8 bytes, respectively. In .NET 7, RuntimeHelpers.IsBitwiseEquatable would be true only for a finite and hardcoded list in the runtime: bool, byte, sbyte, char, short, ushort, int, uint, long, ulong, nint, nuint, Rune, and enums. Now in .NET 8, that list is extended to a dynamically discoverable set where the runtime can easily see that the type itself doesn’t provide any equality implementation.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private MyColor[] _values1, _values2;
[GlobalSetup]
public void Setup()
{
_values1 = Enumerable.Range(0, 1_000).Select(i => new MyColor { R = (byte)i, G = (byte)i, B = (byte)i, A = (byte)i }).ToArray();
_values2 = (MyColor[])_values1.Clone();
}
[Benchmark] public int IndexOf() => Array.IndexOf(_values1, new MyColor { R = 1, G = 2, B = 3, A = 4 });
[Benchmark] public bool SequenceEquals() => _values1.AsSpan().SequenceEqual(_values2);
struct MyColor { public byte R, G, B, A; }
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| IndexOf | .NET 7.0 | 24,912.42 ns | 1.000 | 48000 B | 1.00 |
| IndexOf | .NET 8.0 | 70.44 ns | 0.003 | – | 0.00 |
| SequenceEquals | .NET 7.0 | 25,041.00 ns | 1.000 | 48000 B | 1.00 |
| SequenceEquals | .NET 8.0 | 68.40 ns | 0.003 | – | 0.00 |
Note this not only means the result gets vectorized, it also ends up avoiding excessive boxing (hence all that allocation), as it’s no longer calling Equals(object) on each value type instance.
dotnet/runtime#85437 improved the vectorization of IndexOf(string/span, StringComparison.OrdinalIgnoreCase). Imagine we’re searching some text for the word “elementary.” In .NET 7, it would end up doing an IndexOfAny('E', 'e') in order to find the first possible place “elementary” could match, and would then do the equivalent of a Equals("elementary", textAtFoundPosition, StringComparison.OrdinalIgnoreCase). If the Equals fails, then it loops around to search for the next possible starting location. This is ok if the the characters being searched for are rare, but in this example, 'e' is the most common letter in the English alphabet, and so an IndexOfAny('E', 'e') is frequently stopping, breaking out of the vectorized inner loop, in order to do the full Equals comparison. In contrast to this, in .NET 7 IndexOf(string/span, StringComparison.Ordinal) was improved using the algorithm outlined by Mula; the idea there is that rather than just searching for one character (e.g. the first), you have a vector for another character as well (e.g. the last), you offset them appropriately, and you AND their comparison results together as part of the inner loop. Even if 'e' is very common, 'e' and then a 'y' nine characters later is much, much less common, and thus it can stay in its tight inner loop for longer. Now in .NET 8, we apply the same trick to OrdinalIgnoreCase when we can find two ASCII characters in the input, e.g. it’ll simultaneously search for 'E' or 'e' followed by a 'Y' or 'y‘ nine characters later.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private static readonly string s_haystack = new HttpClient().GetStringAsync("https://www.gutenberg.org/files/1661/1661-0.txt").Result;
private readonly string _needle = "elementary";
[Benchmark]
public int Count()
{
ReadOnlySpan<char> haystack = s_haystack;
ReadOnlySpan<char> needle = _needle;
int count = 0;
int pos;
while ((pos = haystack.IndexOf(needle, StringComparison.OrdinalIgnoreCase)) >= 0)
{
count++;
haystack = haystack.Slice(pos + needle.Length);
}
return count;
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Count | .NET 7.0 | 676.91 us | 1.00 |
| Count | .NET 8.0 | 62.04 us | 0.09 |
Even just a simple IndexOf(char) is also significantly improved in .NET 8. Here I’m searching “The Adventures of Sherlock Holmes” for an '@', which I happen to know doesn’t appear, such that the entire search will be spent in IndexOf(char)‘s tight inner loop.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private static readonly string s_haystack = new HttpClient().GetStringAsync("https://www.gutenberg.org/files/1661/1661-0.txt").Result;
[Benchmark]
public int IndexOfAt() => s_haystack.AsSpan().IndexOf('@');
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| IndexOfAt | .NET 7.0 | 32.17 us | 1.00 |
| IndexOfAt | .NET 8.0 | 20.84 us | 0.64 |
That improvement is thanks to dotnet/runtime#78861. The goal of SIMD and vectorization is to do more with the same; rather than processing one thing at a time, process 2 or 4 or 8 or 16 or 32 or 64 things at a time. For chars, which are 16 bits in size, in a 128-bit vector you can process 8 of them at a time; double that for 256-bit, and double it again for 512-bit. But it’s not just about the size of the vector; you can also find creative ways to use a vector to process more than you otherwise could. For example, in a 128-bit vector, you can process 8 chars at a time… but you can process 16 bytes at a time. What if you could process the chars instead as bytes? You could of course reinterpret the 8 chars as 16 bytes, but for most algorithms you’d end up with the wrong answer (since each byte of the char would be treated independently). What if instead you could condense two vectors’ worth of chars down to a single vector of byte, and then do the subsequent processing on that single vector of byte? Then as long as you were doing a few instructions-worth of processing on the byte vector and the cost of that condensing was cheap enough, you could approach doubling your algorithm’s performance. And that’s exactly what this PR does, at least for very common needles, and on hardware that supports SSE2. SSE2 has dedicated instructions for taking two vectors and narrowing them down to a single vector, e.g. take a Vector128<short> a and a Vector128<short> b, and combine them into a Vector<byte> c by taking the low byte from each short in the input. However, these particular instructions don’t simply ignore the other byte in each short completely; instead, they “saturate.” That means if casting the short value to a byte would overflow, it produces 255, and if it would underflow, it produces 0. That means we can take two vectors of 16-bit values, pack them into a single vector of 8-bit values, and then as long as the thing we’re searching for is in the range [1, 254], we can be sure that equality checks against the vector will be accurate (comparisons against 0 or 255 might lead to false positives). Note that while Arm does have support for similar “narrowing with saturation,” the cost of those particular instructions was measured to be high enough that it wasn’t feasible to use them here (they are used elsewhere). This improvement applies to several other char-based methods as well, including IndexOfAny(char, char) and IndexOfAny(char, char, char).
One last Span-centric improvement to highlight. The Memory<T> and ReadOnlyMemory<T> types don’t implement IEnumerable<T>, but the MemoryMarshal.ToEnumerable method does exist to enable getting an enumerable from them. It’s buried away in MemoryMarshal primarily so as to guide developers not to iterate through the Memory<T> directly, but to instead iterate through its Span, e.g.
foreach (T value in memory.Span) { ... }The driving force behind this is that the Memory<T>.Span property has some overhead, as a Memory<T> can be backed by multiple different object types (namely a T[], a string if it’s a ReadOnlyMemory<char>, or a MemoryManager<T>), and Span needs to fetch a Span<T> for the right one. Even so, from time to time you do actually need an IEnumerable<T> from a {ReadOnly}Memory<T>, and ToEnumerable provides that. In such situations, it’s actually beneficial from a performance perspective that one doesn’t just pass the {ReadOnly}Memory<T> as an IEnumerable<T>, since doing so would box the value, and then enumerating that enumerable would require a second allocation for the IEnumerator<T>. In contrast, MemoryMarshal.ToEnumerable can return an IEnumerable<T> instance that is both the IEnumerable<T> and the IEnumerator<T>. In fact, that’s what it’s done since it was added, with the entirety of the implementation being:
public static IEnumerable<T> ToEnumerable<T>(ReadOnlyMemory<T> memory)
{
for (int i = 0; i < memory.Length; i++)
yield return memory.Span[i];
}The C# compiler generates an IEnumerable<T> for such an iterator that does in fact also implement IEnumerator<T> and return itself from GetEnumerator to avoid an extra allocation, so that’s good. As noted, though, Memory<T>.Span has some overhead, and this is accessing .Span once per element… not ideal. dotnet/runtime#89274 addresses this in multiple ways. First, ToEnumerable itself can check the type of the underlying object behind the Memory<T>, and for a T[] or a string can return a different iterator that just directly indexes into the array or string rather than going through .Span on every access. Moreover, ToEnumerable can check to see whether the bounds represented by the Memory<T> are for the full length of the array or string… if they are, then ToEnumerable can just return the original object, without any additional allocation. The net result is a much more efficient enumeration scheme for anything other than a MemoryManager<T>, which is much more rare (but also not negatively impacted by the improvements for the other types).
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Buffers;
using System.Runtime.InteropServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly Memory<char> _array = Enumerable.Repeat('a', 1000).ToArray();
[Benchmark]
public int Count() => Count(MemoryMarshal.ToEnumerable<char>(_array));
[Benchmark]
public int CountLINQ() => Enumerable.Count(MemoryMarshal.ToEnumerable<char>(_array));
private static int Count<T>(IEnumerable<T> source)
{
int count = 0;
foreach (T item in source) count++;
return count;
}
private sealed class WrapperMemoryManager<T>(Memory<T> memory) : MemoryManager<T>
{
public override Span<T> GetSpan() => memory.Span;
public override MemoryHandle Pin(int elementIndex = 0) => throw new NotSupportedException();
public override void Unpin() => throw new NotSupportedException();
protected override void Dispose(bool disposing) { }
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Count | .NET 7.0 | 6,336.147 ns | 1.00 |
| Count | .NET 8.0 | 1,323.376 ns | 0.21 |
| CountLINQ | .NET 7.0 | 4,972.580 ns | 1.000 |
| CountLINQ | .NET 8.0 | 9.200 ns | 0.002 |
SearchValues
As should be obvious from the length of this document, there are a sheer ton of performance-focused improvements in .NET 8. As I previously noted, I think the most valuable addition in .NET 8 is enabling dynamic PGO by default. After that, I think the next most exciting addition is the new System.Buffers.SearchValues type. It is simply awesome, in my humble opinion.
Functionally, SearchValues doesn’t do anything you couldn’t already do. For example, let’s say you wanted to search for the next ASCII letter or digit in text. You can already do that via IndexOfAny:
ReadOnlySpan<char> text = ...;
int pos = text.IndexOfAny("ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789");And that works, but it hasn’t been particularly fast. In .NET 7, IndexOfAny(ReadOnlySpan<char>) is optimized for searching for up to 5 target characters, e.g. it could efficiently vectorize a search for English vowels (IndexOfAny("aeiou")). But with a target set of 62 characters like in the previous example, it would no longer vectorize, and instead of trying to see how many characters it could process per instruction, switches to trying to see how few instructions it can employ per character (meaning we’re no longer talking about fractions of an instruction per character in the haystack and now talking about multiple instructions per character in the haystack). It does this via a Bloom filter, referred to in the implementation as a “probabilistic map.” The idea is to maintain a bitmap of 256 bits. For every needle character, it sets 2 bits in that bitmap. Then when searching the haystack, for each character it looks to see whether both bits are set in the bitmap; if at least one isn’t set, then this character can’t be in the needle and the search can continue, but if both bits are in the bitmap, then it’s likely but not confirmed that the haystack character is in the needle, and the needle is then searched for the character to see whether we’ve found a match.
There are actually known algorithms for doing these searches more efficiently. For example, the “Universal” algorithm described by Mula is a great choice when searching for an arbitrary set of ASCII characters, enabling us to efficiently vectorize a search for a needle composed of any subset of ASCII. Doing so requires some amount of computation to analyze the needle and build up the relevant bitmaps and vectors that are required for performing the search, just as we have to do so for the Bloom filter (albeit generating different artifacts). dotnet/runtime#76740 implements these techniques in {Last}IndexOfAny{Except}. Rather than always building up a probabilistic map, it first examines the needle to see if all of the values are ASCII, and if they are, then it switches over to this optimized ASCII-based search; if they’re not, it falls back to the same probabilistic map approach used previously. The PR also recognizes that it’s only worth attempting either optimization under the right conditions; if the haystack is really short, for example, we’re better off just doing the naive O(M*N) search, where for every character in the haystack we search through the needle to see if the char is a target.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private static readonly string s_haystack = new HttpClient().GetStringAsync("https://www.gutenberg.org/files/1661/1661-0.txt").Result;
[Benchmark]
public int CountEnglishVowelsAndSometimeVowels()
{
ReadOnlySpan<char> remaining = s_haystack;
int count = 0, pos;
while ((pos = remaining.IndexOfAny("aeiouyAEIOUY")) >= 0)
{
count++;
remaining = remaining.Slice(pos + 1);
}
return count;
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| CountEnglishVowelsAndSometimeVowels | .NET 7.0 | 6.823 ms | 1.00 |
| CountEnglishVowelsAndSometimeVowels | .NET 8.0 | 3.735 ms | 0.55 |
Even with those improvements, this work of building up these vectors is quite repetitive, and it’s not free. If you have such an IndexOfAny in a loop, you’re paying to build up those vectors over and over and over again. There’s also additional work we could do to further examine the data to choose an even more optimal approach, but every additional check performed comes at the cost of more overhead for the IndexOfAny call. This is where SearchValues comes in. The idea behind SearchValues is to perform all this work once and then cache it. Almost invariably, the pattern for using a SearchValues is to create one, store it in a static readonly field, and then use that SearchValues for all searching operations for that target set. And there are now overloads of methods like IndexOfAny that take a SearchValues<char> or SearchValues<byte>, for example, instead of a ReadOnlySpan<char> or ReadOnlySpan<byte>, respectively. Thus, my previous ASCII letter or digit example would instead look like this:
private static readonly SearchValues<char> s_asciiLettersOrDigits = SearchValues.Create("ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789");
...
int pos = text.IndexOfAny(s_asciiLettersOrDigits);dotnet/runtime#78093 provided the initial implementation of SearchValues (it was originally named IndexOfAnyValues, but we renamed it subsequently to the more general SearchValues so that we can use it now and in the future with other methods, like Count or Replace). If you peruse the implementation, you’ll see that the Create factory methods don’t just return a concrete SearchValues<T> type; rather, SearchValues<T> provides an internal abstraction that’s then implemented by more than fifteen derived implementations, each specialized for a different scenario. You can see this fairly easily in code by running the following program:
// dotnet run -f net8.0
using System.Buffers;
Console.WriteLine(SearchValues.Create(""));
Console.WriteLine(SearchValues.Create("a"));
Console.WriteLine(SearchValues.Create("ac"));
Console.WriteLine(SearchValues.Create("ace"));
Console.WriteLine(SearchValues.Create("ab\u05D0\u05D1"));
Console.WriteLine(SearchValues.Create("abc\u05D0\u05D1"));
Console.WriteLine(SearchValues.Create("abcdefghijklmnopqrstuvwxyz"));
Console.WriteLine(SearchValues.Create("ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789"));
Console.WriteLine(SearchValues.Create("\u00A3\u00A5\u00A7\u00A9\u00AB\u00AD"));
Console.WriteLine(SearchValues.Create("abc\u05D0\u05D1\u05D2"));and you’ll see output like the following:
System.Buffers.EmptySearchValues`1[System.Char]
System.Buffers.SingleCharSearchValues`1[System.Buffers.SearchValues+TrueConst]
System.Buffers.Any2CharSearchValues`1[System.Buffers.SearchValues+TrueConst]
System.Buffers.Any3CharSearchValues`1[System.Buffers.SearchValues+TrueConst]
System.Buffers.Any4SearchValues`2[System.Char,System.Int16]
System.Buffers.Any5SearchValues`2[System.Char,System.Int16]
System.Buffers.RangeCharSearchValues`1[System.Buffers.SearchValues+TrueConst]
System.Buffers.AsciiCharSearchValues`1[System.Buffers.IndexOfAnyAsciiSearcher+Default]
System.Buffers.ProbabilisticCharSearchValues
System.Buffers.ProbabilisticWithAsciiCharSearchValues`1[System.Buffers.IndexOfAnyAsciiSearcher+Default]highlighting that each of these different inputs ends up getting mapped to a different SearchValues<T>-derived type.
After that initial PR, SearchValues has been successively improved and refined. dotnet/runtime#78863, for example, added AVX2 support, such that with 256-bit vectors being employed (when available) instead of 128-bit vectors, some benchmarks close to doubled in throughput, and dotnet/runtime#83122 enabled WASM support. dotnet/runtime#78996 added a Contains method to be used when implementing scalar fallback paths. And dotnet/runtime#86046 reduced the overhead of calling IndexOfAny with a SearchValues simply by tweaking how the relevant bitmaps and vectors are internally passed around. But two of my favorite tweaks are dotnet/runtime#82866 and dotnet/runtime#84184, which improve overheads when ‘\0’ (null) is one of the characters in the needle. Why would this matter? Surely searching for ‘\0’ can’t be so common? Interestingly, in a variety of scenarios it can be. Imagine you have an algorithm that’s really good at searching for any subset of ASCII, but you want to use it to search for either a specific subset of ASCII or something non-ASCII. If you just search for the subset, you won’t learn about non-ASCII hits. And if you search for everything other than the subset, you’ll learn about non-ASCII hits but also all the wrong ASCII characters. Instead what you want to do is invert the ASCII subset, e.g. if your target characters are ‘A’ through ‘Z’ and ‘a’ through ‘z’, you instead create the subset including ‘\u0000’ through ‘\u0040’, ‘\u005B’ through ‘\u0060’, and ‘\u007B’ through ‘\u007F’. Then, rather than doing an IndexOfAny with that inverted subset, you instead do IndexOfAnyExcept with that inverted subset; this is a true case of “two wrongs make a right,” as we’ll end up with our desired behavior of searching for the original subset of ASCII letter plus anything non-ASCII. And as you’ll note, ‘\0’ is in our inverted subset, making the performance when ‘\0’ is in there more important than it otherwise would be.
Interestingly, the probabilistic map code path in .NET 8 actually also enjoys some amount of vectorization, even without SearchValues, thanks to dotnet/runtime#80963 (it was also further improved in dotnet/runtime#85189 that used better instructions on Arm, and in dotnet/runtime#85203 that avoided some wasted work). That means that whether or not SearchValues is used, searches involving probabilistic map get much faster than in .NET 7. For example, here’s a benchmark that again searches “The Adventures of Sherlock Holmes” and counts the number of line endings in it, using the same needle that string.ReplaceLineEndings uses:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private static readonly string s_haystack = new HttpClient().GetStringAsync("https://www.gutenberg.org/files/1661/1661-0.txt").Result;
[Benchmark]
public int CountLineEndings()
{
int count = 0;
ReadOnlySpan<char> haystack = s_haystack;
int pos;
while ((pos = haystack.IndexOfAny("\n\r\f\u0085\u2028\u2029")) >= 0)
{
count++;
haystack = haystack.Slice(pos + 1);
}
return count;
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| CountLineEndings | .NET 7.0 | 2.155 ms | 1.00 |
| CountLineEndings | .NET 8.0 | 1.323 ms | 0.61 |
SearchValues can then be used to improve upon that. It does so not only by caching the probabilistic map that each call to IndexOfAny above needs to recompute, but also by recognizing that when a needle contains ASCII, that’s a good indication (heuristically) that ASCII haystacks will be prominent. As such, dotnet/runtime#89155 adds a fast path that performs a search for either any of the ASCII needle values or any non-ASCII value, and if it finds a non-ASCII value, then it falls back to performing the vectorized probabilistic map search.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Buffers;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private static readonly string s_haystack = new HttpClient().GetStringAsync("https://www.gutenberg.org/files/1661/1661-0.txt").Result;
private static readonly SearchValues<char> s_lineEndings = SearchValues.Create("\n\r\f\u0085\u2028\u2029");
[Benchmark]
public int CountLineEndings_Chars()
{
int count = 0;
ReadOnlySpan<char> haystack = s_haystack;
int pos;
while ((pos = haystack.IndexOfAny("\n\r\f\u0085\u2028\u2029")) >= 0)
{
count++;
haystack = haystack.Slice(pos + 1);
}
return count;
}
[Benchmark]
public int CountLineEndings_SearchValues()
{
int count = 0;
ReadOnlySpan<char> haystack = s_haystack;
int pos;
while ((pos = haystack.IndexOfAny(s_lineEndings)) >= 0)
{
count++;
haystack = haystack.Slice(pos + 1);
}
return count;
}
}| Method | Mean |
|---|---|
| CountLineEndings_Chars | 1,300.3 us |
| CountLineEndings_SearchValues | 430.9 us |
dotnet/runtime#89224 further augments that heuristic by guarding that ASCII fast path behind a quick check to see if the very next character is non-ASCII, skipping the ASCII-based search if it is and thereby avoiding the overhead when dealing with an all non-ASCII input. For example, here’s the result of running the previous benchmark, with the exact same code, except changing the URL to be https://www.gutenberg.org/files/39963/39963-0.txt, which is an almost entirely Greek document containing Aristotle’s “The Constitution of the Athenians”:
| Method | Mean |
|---|---|
| CountLineEndings_Chars | 542.6 us |
| CountLineEndings_SearchValues | 283.6 us |
With all of that goodness imbued in SearchValues, it’s now being used extensively throughout dotnet/runtime. For example, System.Text.Json previously had its own dedicated implementation of a function IndexOfQuoteOrAnyControlOrBackSlash that it used to search for any character with an ordinal value less than 32, or a quote, or a backslash. That implementation in .NET 7 was ~200 lines of complicated Vector<T>-based code. Now in .NET 8 thanks to dotnet/runtime#82789, it’s simply this:
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static int IndexOfQuoteOrAnyControlOrBackSlash(this ReadOnlySpan<byte> span) =>
span.IndexOfAny(s_controlQuoteBackslash);
private static readonly SearchValues<byte> s_controlQuoteBackslash = SearchValues.Create(
"\u0000\u0001\u0002\u0003\u0004\u0005\u0006\u0007\u0008\u0009\u000A\u000B\u000C\u000D\u000E\u000F\u0010\u0011\u0012\u0013\u0014\u0015\u0016\u0017\u0018\u0019\u001A\u001B\u001C\u001D\u001E\u001F"u8 + // Any Control, < 32 (' ')
"\""u8 + // Quote
"\\"u8); // BackslashSuch use was rolled out in a bunch of PRs, for example dotnet/runtime#78664 that used SearchValues in System.Private.Xml,
dotnet/runtime#81976 in JsonSerializer, dotnet/runtime#78676 in X500NameEncoder, dotnet/runtime#78667 in Regex.Escape, dotnet/runtime#79025 in ZipFile and TarFile,
dotnet/runtime#79974 in WebSocket,
dotnet/runtime#81486 in System.Net.Mail, and dotnet/runtime#78896 in Cookie. dotnet/runtime#78666 and dotnet/runtime#79024 in Uri are particularly nice, including optimizing the commonly-used Uri.EscapeDataString helper with SearchValues; this shows up as a sizable improvement, especially when there’s nothing to escape.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private string _value = Convert.ToBase64String("How did I escape? With difficulty. How did I plan this moment? With pleasure. "u8);
[Benchmark]
public string EscapeDataString() => Uri.EscapeDataString(_value);
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| EscapeDataString | .NET 7.0 | 85.468 ns | 1.00 |
| EscapeDataString | .NET 8.0 | 8.443 ns | 0.10 |
All in all, just in dotnet/runtime, SearchValues.Create is now used in more than 40 places, and that’s not including all the uses that get generated as part of Regex (more on that in a bit). This is helped along by dotnet/roslyn-analyzers#6898, which adds a new analyzer that will flag opportunities for SearchValues and update the code to use it:
Throughout this discussion, I’ve mentioned ReplaceLineEndings several times, using it as an example of the kind of thing that wants to efficiently search for multiple characters. After dotnet/runtime#78678 and dotnet/runtime#81630, it now also uses SearchValues, plus has been enhanced with other optimizations. Given the discussion of SearchValues, it’ll be obvious how it’s employed here, at least the basics of it. Previously, ReplaceLineEndings relied on an internal helper IndexOfNewlineChar which did this:
internal static int IndexOfNewlineChar(ReadOnlySpan<char> text, out int stride)
{
const string Needles = "\r\n\f\u0085\u2028\u2029";
int idx = text.IndexOfAny(needles);
...
}Now, it does:
int idx = text.IndexOfAny(SearchValuesStorage.NewLineChars);where that NewLineChars is just:
internal static class SearchValuesStorage
{
public static readonly SearchValues<char> NewLineChars = SearchValues.Create("\r\n\f\u0085\u2028\u2029");
}Straightforward. However, it takes things a bit further. Note that there are 6 characters in that list, some of which are ASCII, some of which aren’t. Knowing the algorithms SearchValues currently employs, we know that this will knock it off the
path of just doing an ASCII search, and it’ll instead use the algorithm that does a search for one of the 3 ASCII characters plus anything non-ASCII, and if it finds anything non-ASCII, will then fallback to doing the probabilistic map search. If we could remove just one of those characters, we’d be back into the range of just being able to use the IndexOfAny implementation that can work with any 5 characters. On non-Windows systems, we’re in luck. ReplaceLineEndings by default replaces a line ending with Environment.NewLine; on Windows, that’s "\r\n", but on Linux and macOS, that’s "\n". If the replacement text is "\n" (which can also be opted-into on Windows by using the ReplaceLineEndings(string replacementText) overload), then searching for '\n' only to replace it with '\n' is a nop, which means we can remove '\n' from the search list when the replacement text is "\n", bringing us down to only 5 target characters, and giving us a little edge. And while that’s a nice little gain, the bigger gain is that we won’t end up breaking out of the vectorized loop as frequently, or at all if all of the line endings are the replacement text. Further, the .NET 7 implementation was always creating a new string to return, but we can avoid allocating it if we didn’t actually replace anything with anything new. The net result of all of this are huge improvements to ReplaceLineEndings, some due to SearchValues and some beyond.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
// NOTE: This text uses \r\n as its line endings
private static readonly string s_text = new HttpClient().GetStringAsync("https://www.gutenberg.org/files/1661/1661-0.txt").Result;
[Benchmark]
[Arguments("\r\n")]
[Arguments("\n")]
public string ReplaceLineEndings(string replacement) => s_text.ReplaceLineEndings(replacement);
}| Method | Runtime | replacement | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|
| ReplaceLineEndings | .NET 7.0 | \n | 2,746.3 us | 1.00 | 1163121 B | 1.00 |
| ReplaceLineEndings | .NET 8.0 | \n | 995.9 us | 0.36 | 1163121 B | 1.00 |
| ReplaceLineEndings | .NET 7.0 | \r\n | 2,920.1 us | 1.00 | 1187729 B | 1.00 |
| ReplaceLineEndings | .NET 8.0 | \r\n | 356.5 us | 0.12 | – | 0.00 |
The SearchValue changes also accrue to the span-based non-allocating EnumerateLines:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private static readonly string s_text = new HttpClient().GetStringAsync("https://www.gutenberg.org/files/1661/1661-0.txt").Result;
[Benchmark]
public int CountLines()
{
int count = 0;
foreach (ReadOnlySpan<char> _ in s_text.AsSpan().EnumerateLines()) count++;
return count;
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| CountLines | .NET 7.0 | 2,029.9 us | 1.00 |
| CountLines | .NET 8.0 | 353.2 us | 0.17 |
Regex
Having just examined SearchValues, it’s a good time to talk about Regex, as the former now plays an integral role in the latter. Regex was significantly improved in .NET 5, and then again was overhauled for .NET 7, which saw the introduction of the regex source generator. Now in .NET 8, Regex continues to receive significant investment, in particular this release in taking advantage of much of the work already discussed that was introduced lower in the stack to enable more efficient searching.
As a reminder, there are effectively three different “engines” within System.Text.RegularExpressions, meaning effectively three different components for actually processing a regex. The simplest engine is the “interpreter”; the Regex constructor translates the regular expression into a series of regex opcodes which the RegexInterpreter then evaluates against the incoming text. This is done in a “scan” loop, which (simplified) looks like this:
while (TryFindNextStartingPosition(text))
{
if (TryMatchAtCurrentPosition(text) || _currentPosition == text.Length) break;
_currentPosition++;
}TryFindNextStartingPosition tries to move through as much of the input text as possible until it finds a position in the input that could feasibly start a match, and then TryMatchAtCurrentPosition evaluates the pattern at that position against the input. That evaluation in the interpreter involves a loop like this, processing the opcodes that were produced from the pattern:
while (true)
{
switch (_opcode)
{
case RegexOpcode.Stop:
return match.FoundMatch;
case RegexOpcode.Goto:
Goto(Operand(0));
continue;
... // cases for ~50 other opcodes
}
}Then there’s the non-backtracking engine, which is what you get when you select the RegexOptions.NonBacktracking option introduced in .NET 7. This engine shares the same TryFindNextStartingPosition implementation as the interpreter, such that all of the optimizations involved in skipping through as much text as possible (ideally via vectorized IndexOf operations) accrue to both the interpreter and the non-backtracking engine. However, that’s where the similarities end. Rather than processing regex opcodes, the non-backtracking engine works by converting the regular expression pattern into a lazily-constructed deterministic finite automata (DFA) or non-deterministic finite automata (NFA), which it then uses to evaluate the input text. The key benefit of the non-backtracking engine is that it provides linear-time execution guarantees in the length of the input. For a lot more detail, please read Regular Expression Improvements in .NET 7.
The third engine actually comes in two forms: RegexOptions.Compiled and the regex source generator (introduced in .NET 7). Except for a few corner-cases, these are effectively the same as each other in terms of how they work. They both generate custom code specific to the input pattern provided, with the former generating IL at run-time and the latter generating C# (which is then compiled to IL by the C# compiler) at build-time. The structure of the resulting code, and 99% of the optimizations applied, are identical between them; in fact, in .NET 7, the RegexCompiler was completely rewritten to be a block-by-block translation of the C# code the regex source generator emits. For both, the actual emitted code is fully customized to the exact pattern supplied, with both trying to generate code that processes the regex as efficiently as possible, and with the source generator trying to do so by generating code that is as close as possible to what an expert .NET developer might write. That’s in large part because the source it generates is visible, even in Visual Studio live as you edit your pattern:
I mention all of this because there is ample opportunity throughout Regex, both in the TryFindNextStartingPosition used by the interpreter and non-backtracking engines and throughout the code generated by RegexCompiler and the regex source generator, to use APIs introduced to make searching faster. I’m looking at you, IndexOf and friends.
As noted earlier, new IndexOf variants have been introduced in .NET 8 for searching for ranges, and as of dotnet/runtime#76859, Regex will now take full advantage of them in generated code. For example, consider [GeneratedRegex(@"[0-9]{5}")], which might be used to search for a zip code in the United States. The regex source generator in .NET 7 would emit code for TryFindNextStartingPosition that contained this:
// The pattern begins with '0' through '9'.
// Find the next occurrence. If it can't be found, there's no match.
ReadOnlySpan<char> span = inputSpan.Slice(pos);
for (int i = 0; i < span.Length - 4; i++)
{
if (char.IsAsciiDigit(span[i]))
...
}Now in .NET 8, that same attribute instead generates this:
// The pattern begins with a character in the set [0-9].
// Find the next occurrence. If it can't be found, there's no match.
ReadOnlySpan<char> span = inputSpan.Slice(pos);
for (int i = 0; i < span.Length - 4; i++)
{
int indexOfPos = span.Slice(i).IndexOfAnyInRange('0', '9');
...
}That .NET 7 implementation is examining one character at a time, whereas the .NET 8 code is vectorizing the search via IndexOfAnyInRange, examining multiple characters at a time. This can lead to significant speedups.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text.RegularExpressions;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private static readonly string s_haystack = new HttpClient().GetStringAsync("https://www.gutenberg.org/files/1661/1661-0.txt").Result;
private readonly Regex _regex = new Regex("[0-9]{5}", RegexOptions.Compiled);
[Benchmark]
public int Count() => _regex.Count(s_haystack);
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Count | .NET 7.0 | 423.88 us | 1.00 |
| Count | .NET 8.0 | 29.91 us | 0.07 |
The generated code can use these APIs in other places as well, even as part of validating the match itself. Let’s say your pattern was instead [GeneratedRegex(@"(\w{3,})[0-9]")], which is going to look for and capture a sequence of at least three word characters that is then followed by an ASCII digit. This is a standard greedy loop, so it’s going to consume as many word characters as it can (which includes ASCII digits), and will then backtrack, giving back some of the word characters consumed, until it can find a digit. Previously, that was implemented just by giving back a single character, seeing if it was a digit, giving back a single character, seeing if it was a digit, and so on. Now? The source generator emits code that includes this:
charloop_ending_pos = inputSpan.Slice(charloop_starting_pos, charloop_ending_pos - charloop_starting_pos).LastIndexOfAnyInRange('0', '9')In other words, it’s using LastIndexOfAnyInRange to optimize that backwards search for the next viable backtracking location.
Another significant improvement that builds on improvements lower in the stack is dotnet/runtime#85438. As was previously covered, the vectorization of span.IndexOf("...", StringComparison.OrdinalIgnoreCase) has been improved in .NET 8. Previously, Regex wasn’t utilizing this API, as it was often able to do better with its own custom-generated code. But now that the API has been optimized, this PR changes Regex to use it, making the generated code both simpler and faster. Here I’m searching case-insensitively for the whole word “year”:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text.RegularExpressions;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private static readonly string s_haystack = new HttpClient().GetStringAsync("https://www.gutenberg.org/files/1661/1661-0.txt").Result;
private readonly Regex _regex = new Regex(@"\byear\b", RegexOptions.Compiled | RegexOptions.IgnoreCase);
[Benchmark]
public int Count() => _regex.Count(s_haystack);
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Count | .NET 7.0 | 181.80 us | 1.00 |
| Count | .NET 8.0 | 63.10 us | 0.35 |
In addition to learning how to use the existing IndexOf(..., StringComparison.OrdinalIgnoreCase) and the new IndexOfAnyInRange and IndexOfAnyExceptInRange, Regex in .NET 8 also learns how to use the new SearchValues<char>. This is a big boost for Regex, as it now means that it can vectorize searches for many more sets than it previously could. For example, let’s say you wanted to search for all hex numbers. You might use a pattern like [0123456789ABCDEFabcdef]+. If you plug that into the regex source generator in .NET 7, you’ll get a TryFindNextPossibleStartingPosition emitted that contains code like this:
// The pattern begins with a character in the set [0-9A-Fa-f].
// Find the next occurrence. If it can't be found, there's no match.
ReadOnlySpan<char> span = inputSpan.Slice(pos);
for (int i = 0; i < span.Length; i++)
{
if (char.IsAsciiHexDigit(span[i]))
{
base.runtextpos = pos + i;
return true;
}
}Now in .NET 8, thanks in large part to dotnet/runtime#78927, you’ll instead get code like this:
// The pattern begins with a character in the set [0-9A-Fa-f].
// Find the next occurrence. If it can't be found, there's no match.
int i = inputSpan.Slice(pos).IndexOfAny(Utilities.s_asciiHexDigits);
if (i >= 0)
{
base.runtextpos = pos + i;
return true;
}What is that Utilities.s_asciiHexDigits? It’s a SearchValues<char> emitted into the file’s Utilities class:
/// <summary>Supports searching for characters in or not in "0123456789ABCDEFabcdef".</summary>
internal static readonly SearchValues<char> s_asciiHexDigits = SearchValues.Create("0123456789ABCDEFabcdef");The source generator explicitly recognized this set and so created a nice name for it, but that’s purely about readability; it can still use SearchValues<char> even if it doesn’t recognize the set as something that’s well-known and easily nameable. For example, if I instead augment the set to be all valid hex digits and an underscore, I then instead get this:
/// <summary>Supports searching for characters in or not in "0123456789ABCDEF_abcdef".</summary>
internal static readonly SearchValues<char> s_ascii_FF037E0000807E000000 = SearchValues.Create("0123456789ABCDEF_abcdef");When initially added to Regex, SearchValues<char> was only used when the input set was all ASCII. But as SearchValues<char> improved over the development of .NET 8, so too did Regex‘s use of it. With dotnet/runtime#89205, Regex now relies on SearchValues‘s ability to efficiently search for both ASCII and non-ASCII, and will similarly emit a SearchValues<char> if it’s able to efficiently enumerate the contents of a set and that set contains a reasonably small number of characters (today, that means no more than 128). Interestingly, SearchValues‘s optimization to first do a search for the ASCII subset of a target and then fallback to a vectorized probabilistic map search was first prototyped in Regex (dotnet/runtime#89140), after which we decided to push the optimization downwards into SearchValues so that Regex could generate simpler code and so that other non-Regex consumers would benefit.
That still, however, leaves the cases where we can’t efficiently enumerate the set in order to determine every character it includes, nor would we want to pass a gigantic number of characters off to SearchValues. Consider the set \w, i.e. “word characters.” Of the 65,536 char values, 50,409 match the set \w. It would be inefficient to enumerate all of those characters in order to try to create a SearchValues<char> for them, and Regex doesn’t try. Instead, as of dotnet/runtime#83992, Regex employs a similar approach as noted above, but with a scalar fallback. For example, for the pattern \w+, it emits the following helper into Utilities:
internal static int IndexOfAnyWordChar(this ReadOnlySpan<char> span)
{
int i = span.IndexOfAnyExcept(Utilities.s_asciiExceptWordChars);
if ((uint)i < (uint)span.Length)
{
if (char.IsAscii(span[i]))
{
return i;
}
do
{
if (Utilities.IsWordChar(span[i]))
{
return i;
}
i++;
}
while ((uint)i < (uint)span.Length);
}
return -1;
}
/// <summary>Supports searching for characters in or not in "\0\u0001\u0002\u0003\u0004\u0005\u0006\a\b\t\n\v\f\r\u000e\u000f\u0010\u0011\u0012\u0013\u0014\u0015\u0016\u0017\u0018\u0019\u001a\u001b\u001c\u001d\u001e\u001f !\"#$%&'()*+,-./:;<=>?@[\\]^`{|}~\u007f".</summary>
internal static readonly SearchValues<char> s_asciiExceptWordChars = SearchValues.Create("\0\u0001\u0002\u0003\u0004\u0005\u0006\a\b\t\n\v\f\r\u000e\u000f\u0010\u0011\u0012\u0013\u0014\u0015\u0016\u0017\u0018\u0019\u001a\u001b\u001c\u001d\u001e\u001f !\"#$%&'()*+,-./:;<=>?@[\\]^`{|}~\u007f");The fact that it named the helper “IndexOfAnyWordChar” is, again, separate from the fact that it was able to generate this helper; it simply recognizes the set here as part of determining a name and was able to come up with a nicer one, but if it didn’t recognize it, the body of the method would be the same and the name would just be less readable, as it would come up with something fairly gibberish but unique.
As an interesting aside, I noted that the source generator and RegexCompiler are effectively the same, just with one generating C# and one generating IL. That’s 99% correct. There is one interesting difference around their use of SearchValues, though, one which makes the source generator a bit more efficient in how it’s able to utilize the type. Any time the source generator needs a SearchValues instance for a new combination of characters, it can just emit another static readonly field for that instance, and because it’s static readonly, the JIT’s optimizations around devirtualization and inlining can kick in, with calls to use this seeing the actual type of the instance and optimizing based on that. Yay. RegexCompiler is a different story. RegexCompiler emits IL for a given Regex, and it does so using DynamicMethod; this provides the lightest-weight solution to reflection emit, also allowing the generated methods to be garbage collected when they’re no longer referenced. DynamicMethods, however, are just that, methods. There’s no support for creating additional static fields on demand, without growing up into the much more expensive TypeBuilder-based solution. How then can RegexCompiler create and store an arbitrary number of SearchValue instances, and how can it do so in a way that similarly enables devirtualization? It employs a few tricks. First, a field was added to the internal CompiledRegexRunner type that stores the delegate to the generated method: private readonly SearchValues<char>[]? _searchValues; As an array, this enables any number of SearchValues to be stored; the emitted IL can access the field, grab the array, and index into it to grab the relevant SearchValues<char> instance. Just doing that, of course, would not allow for devirtualization, and even dynamic PGO doesn’t help here because currently DynamicMethods don’t participate in tiering; compilation goes straight to tier 1, so there’d be no opportunity for instrumentation to see the actual SearchValues<char>-derived type employed. Thankfully, there are available solutions. The JIT can learn about the type of an instance from the type of a local in which it’s stored, so one solution is to create a local of the concrete and sealed SearchValues<char> derived type (we’re writing IL at this point, so we can do things like that without actually having access to the type in question), read the SearchValues<char> from the array, store it into the local, and then use the local for the subsequent access. And, in fact, we did that for a while during the .NET 8 development process. However, that does require a local, and requires an extra read/write of that local. Instead, a tweak in dotnet/runtime#85954 allows the JIT to use the T in Unsafe.As<T>(object o) to learn about the actual type of T, and so RegexCompiler can just use Unsafe.As to inform the JIT as to the actual type of the instance such that it’s then devirtualized. The code RegexCompiler uses then to emit the IL to load a SearchValues<char> is this:
// from RegexCompiler.cs, tweaked for readability in this post
private void LoadSearchValues(ReadOnlySpan<char> chars)
{
List<SearchValues<char>> list = _searchValues ??= new();
int index = list.Count;
list.Add(SearchValues.Create(chars));
// Unsafe.As<DerivedSearchValues>(Unsafe.Add(ref MemoryMarshal.GetArrayDataReference(this._searchValues), index));
_ilg.Emit(OpCodes.Ldarg_0);
_ilg.Emit(OpCodes.Ldfld, s_searchValuesArrayField);
_ilg.Emit(OpCodes.Call, s_memoryMarshalGetArrayDataReferenceSearchValues);
_ilg.Emit(OpCodes.Ldc_I4, index * IntPtr.Size);
_ilg.Emit(OpCodes.Add);
_ilg.Emit(OpCodes.Ldind_Ref);
_ilg.Emit(OpCodes.Call, typeof(Unsafe).GetMethod("As", new[] { typeof(object) })!.MakeGenericMethod(list[index].GetType()));
}We can see all of this in action with a benchmark like this:
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text.RegularExpressions;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public partial class Tests
{
private static readonly string s_haystack = new HttpClient().GetStringAsync("https://www.gutenberg.org/files/1661/1661-0.txt").Result;
private static readonly Regex s_names = new Regex("Holmes|Watson|Lestrade|Hudson|Moriarty|Adler|Moran|Morstan|Gregson", RegexOptions.Compiled);
[Benchmark]
public int Count() => s_names.Count(s_haystack);
}Here we’re searching the same Sherlock Holmes text for the names of some of the most common characters in the detective stories. The regex pattern analyzer will try to find something for which it can vectorize a search, and it will look at all of the characters that can validly exist at each position in a match, e.g. all matches begin with ‘H’, ‘W’, ‘L’, ‘M’, ‘A’, or ‘G’. And since the shortest match is five letters (“Adler”), it’ll end up looking at the first five positions, coming up with these sets:
0: [AGHLMW]
1: [adeoru]
2: [delrst]
3: [aegimst]
4: [aenorst]All of those sets have more than five characters in them, though, an important delineation as in .NET 7 that is the largest number of characters for which IndexOfAny will vectorize a search. Thus, in .NET 7, Regex ends up emitting code that walks the input checking character by character (though it does match the set using a fast branch-free bitmap mechanism):
ReadOnlySpan<char> span = inputSpan.Slice(pos);
for (int i = 0; i < span.Length - 4; i++)
{
if (((long)((0x8318020000000000UL << (int)(charMinusLow = (uint)span[i] - 'A')) & (charMinusLow - 64)) < 0) &&
...Now in .NET 8, with SearchValues<char> we can efficiently search for any of these sets, and the implementation ends up picking the one it thinks is statistically least likely to match:
int indexOfPos = span.Slice(i).IndexOfAny(Utilities.s_ascii_8231800000000000);where that s_ascii_8231800000000000 is defined as:
/// <summary>Supports searching for characters in or not in "AGHLMW".</summary>
internal static readonly SearchValues<char> s_ascii_8231800000000000 = SearchValues.Create("AGHLMW");This leads the overall searching process to be much more efficient.
| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Count | .NET 7.0 | 630.5 us | 1.00 |
| Count | .NET 8.0 | 142.3 us | 0.23 |
Other PRs like dotnet/runtime#84370, dotnet/runtime#89099, and dotnet/runtime#77925 have also contributed to how IndexOf and friends are used, tweaking the various heuristics involved. But there have been improvements to Regex as well outside of this realm.
dotnet/runtime#84003, for example, streamlines the matching performance of \w when matching against non-ASCII characters by using a bit-twiddling trick. And dotnet/runtime#84843 changes the underlying type of an internal enum from int to byte, and in doing so ends up shrinking the size of the object containing a value of this enum by 8 bytes (in a 64-bit process). More impactful is dotnet/runtime#85564, which makes a measurable improvement for Regex.Replace. Replace was maintaining a list of ReadOnlyMemory<char> segments to be composed back into the final string; some segments would come from the original string, while some would be the replacement string. As it turns out, though, the string reference contained in that ReadOnlyMemory<char> is unnecessary. We can instead just maintain a list of ints, where every time we add a segment we add to the list the int offset and the int count, and with the nature of replace, we can simply rely on the fact that we’ll need to insert the replacement text between every pair of values.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text.RegularExpressions;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private static readonly string s_haystack = new HttpClient().GetStringAsync("https://www.gutenberg.org/files/1661/1661-0.txt").Result;
private static readonly Regex s_vowels = new Regex("[aeiou]", RegexOptions.Compiled);
[Benchmark]
public string RemoveVowels() => s_vowels.Replace(s_haystack, "");
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| RemoveVowels | .NET 7.0 | 8.763 ms | 1.00 |
| RemoveVowels | .NET 8.0 | 7.084 ms | 0.81 |
One last improvement in Regex to highlight isn’t actually due to anything in Regex, but actually in a primitive Regex uses on every operation: Interlocked.Exchange. Consider this benchmark:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text.RegularExpressions;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private static readonly Regex s_r = new Regex("", RegexOptions.Compiled);
[Benchmark]
public bool Overhead() => s_r.IsMatch("");
}This is purely measuring the overhead of calling into a Regex instance; the matching routine will complete immediately as the pattern matches any input. Since we’re only talking about tens of nanoseconds, your numbers may vary here, but I routinely get results like this:
| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Overhead | .NET 7.0 | 32.01 ns | 1.00 |
| Overhead | .NET 8.0 | 28.81 ns | 0.90 |
That several nanosecond improvement is primarily due to dotnet/runtime#79181, which made Interlocked.CompareExchange and Interlocked.Exchange for reference types into intrinsics, special-casing when the JIT can see that the new value to be written is null. These APIs need to employ a GC write barrier as part of writing the object reference into the shared location, for the same reasons previously discussed earlier in this post, but when writing null, no such barrier is required. This benefits Regex, which uses Interlocked.Exchange as part of renting a RegexRunner to use to actually process the match. Each Regex instance caches a runner object, and every operation tries to rent and return it… that renting is done with Interlocked.Exchange:
RegexRunner runner = Interlocked.Exchange(ref _runner, null) ?? CreateRunner();
try { ... }
finally { _runner = runner; }Many object pool implementations employ a similar use of Interlocked.Exchange and will similarly benefit.
Hashing
The System.IO.Hashing library was introduced in .NET 6 to provide non-cryptographic hash algorithm implementations; initially, it shipped with four types: Crc32, Crc64, XxHash32, and XxHash64. In .NET 8, it gets significant investment, in adding new optimized algorithms, in improving the performance of existing implementations, and in adding new surface area across all of the algorithms.
The xxHash family of hash algorithms has become quite popular of late due to its high performance on both large and small inputs and its overall level of quality (e.g. how few collisions are produced, how well inputs are dispersed, etc.) System.IO.Hashing previously included implementations of the older XXH32 and XXH64 algorithms (as XxHash32 and XxHash64, respectively). Now in .NET 8, thanks to dotnet/runtime#76641, it includes the XXH3 algorithm (as XxHash3), and thanks to dotnet/runtime#77944 from @xoofx, it includes the XXH128 algorithm (as XxHash128). The XxHash3 algorithm was also further optimized in dotnet/runtime#77756 from @xoofx by amortizing the costs of some loads and stores, and in dotnet/runtime#77881 from @xoofx, which improved throughput on Arm by making better use of the AdvSimd hardware intrinsics.
To see overall performance of these hash functions, here’s a microbenchmark comparing the throughput of the cryptographic SHA256 with each of these non-cryptographic hash functions. I’ve also included an implementation of FNV-1a, which is the hash algorithm that may be used by the C# compiler for switch statements (when it needs to switch over a string, for example, and it can’t come up with a better scheme, it hashes the input, and then does a binary search through the pregenerated hashes for each of the cases), as well as an implementation based on System.HashCode (noting that HashCode is different from the rest of these, in that it’s focused on enabling the hashing of arbitrary .NET types, and includes per-process randomization, whereas a goal of these other hash functions is to be 100% deterministic across process boundaries).
// For this test, you'll also need to add:
// <PackageReference Include="System.IO.Hashing" Version="8.0.0-rc.1.23419.4" />
// to the benchmarks.csproj's <ItemGroup>.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Buffers.Binary;
using System.IO.Hashing;
using System.Security.Cryptography;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly byte[] _result = new byte[100];
private byte[] _source;
[Params(3, 33_333)]
public int Length { get; set; }
[GlobalSetup]
public void Setup() => _source = Enumerable.Range(0, Length).Select(i => (byte)i).ToArray();
// Cryptographic
[Benchmark(Baseline = true)] public void TestSHA256() => SHA256.HashData(_source, _result);
// Non-cryptographic
[Benchmark] public void TestCrc32() => Crc32.Hash(_source, _result);
[Benchmark] public void TestCrc64() => Crc64.Hash(_source, _result);
[Benchmark] public void TestXxHash32() => XxHash32.Hash(_source, _result);
[Benchmark] public void TestXxHash64() => XxHash64.Hash(_source, _result);
[Benchmark] public void TestXxHash3() => XxHash3.Hash(_source, _result);
[Benchmark] public void TestXxHash128() => XxHash128.Hash(_source, _result);
// Algorithm used by the C# compiler for switch statements
[Benchmark]
public void TestFnv1a()
{
int hash = unchecked((int)2166136261);
foreach (byte b in _source) hash = (hash ^ b) * 16777619;
BinaryPrimitives.WriteInt32LittleEndian(_result, hash);
}
// Randomized with a custom seed per process
[Benchmark]
public void TestHashCode()
{
HashCode hc = default;
hc.AddBytes(_source);
BinaryPrimitives.WriteInt32LittleEndian(_result, hc.ToHashCode());
}
}| Method | Length | Mean | Ratio |
|---|---|---|---|
| TestSHA256 | 3 | 856.168 ns | 1.000 |
| TestHashCode | 3 | 9.933 ns | 0.012 |
| TestXxHash64 | 3 | 7.724 ns | 0.009 |
| TestXxHash128 | 3 | 5.522 ns | 0.006 |
| TestXxHash32 | 3 | 5.457 ns | 0.006 |
| TestCrc32 | 3 | 3.954 ns | 0.005 |
| TestCrc64 | 3 | 3.405 ns | 0.004 |
| TestXxHash3 | 3 | 3.343 ns | 0.004 |
| TestFnv1a | 3 | 1.617 ns | 0.002 |
| TestSHA256 | 33333 | 60,407.625 ns | 1.00 |
| TestFnv1a | 33333 | 31,027.249 ns | 0.51 |
| TestHashCode | 33333 | 4,879.262 ns | 0.08 |
| TestXxHash32 | 33333 | 4,444.116 ns | 0.07 |
| TestXxHash64 | 33333 | 3,636.989 ns | 0.06 |
| TestCrc64 | 33333 | 1,571.445 ns | 0.03 |
| TestXxHash3 | 33333 | 1,491.740 ns | 0.03 |
| TestXxHash128 | 33333 | 1,474.551 ns | 0.02 |
| TestCrc32 | 33333 | 1,295.663 ns | 0.02 |
A key reason XxHash3 and XxHash128 do so much better than XxHash32 and XxHash64 is that their design is focused on being vectorizable. As such, the .NET implementations employ the support in System.Runtime.Intrinsics to take full advantage of the underlying hardware. This data also hints at why the C# compiler uses FNV-1a: it’s really simple and also really low overhead for small inputs, which are the most common form of input used in switch statements, but it would be a poor choice if you expected primarily longer inputs.
You’ll note that in the previous example, Crc32 and Crc64 both end up in the same ballpark as XxHash3 in terms of throughput (XXH3 generally ranks better than CRC32/64 in terms of quality). CRC32 in that comparison benefits significantly from dotnet/runtime#83321 from @brantburnett, dotnet/runtime#86539 from @brantburnett, and dotnet/runtime#85221 from @brantburnett. These vectorize the Crc32 and Crc64 implementations, based on a decade-old paper from Intel titled “Fast CRC Computation for Generic Polynomials Using PCLMULQDQ Instruction.” The cited PCLMULQDQ instruction is part of SSE2, however the PR is also able to vectorize on Arm by taking advantage of Arm’s PMULL instruction. The net result is huge gains over .NET 7, in particular for larger inputs being hashed.
// For this test, you'll also need to add:
// <PackageReference Include="System.IO.Hashing" Version="7.0.0" />
// to the benchmarks.csproj's <ItemGroup>.
// dotnet run -c Release -f net7.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Environments;
using BenchmarkDotNet.Jobs;
using BenchmarkDotNet.Running;
using System.IO.Hashing;
var config = DefaultConfig.Instance
.AddJob(Job.Default.WithRuntime(CoreRuntime.Core70).WithNuGet("System.IO.Hashing", "7.0.0").AsBaseline())
.AddJob(Job.Default.WithRuntime(CoreRuntime.Core80).WithNuGet("System.IO.Hashing", "8.0.0-rc.1.23419.4"));
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args, config);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "NuGetReferences")]
public class Tests
{
private readonly byte[] _source = Enumerable.Range(0, 1024).Select(i => (byte)i).ToArray();
private readonly byte[] _destination = new byte[4];
[Benchmark]
public void Hash() => Crc32.Hash(_source, _destination);
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Hash | .NET 7.0 | 2,416.24 ns | 1.00 |
| Hash | .NET 8.0 | 39.01 ns | 0.02 |
Another change also further improves performance of some of these algorithms, but with a primary purpose of actually making them easier to use in a variety of scenarios. The original design of NonCryptographicHashAlgorithm was focused on creating non-cryptographic alternatives to the existing cryptographic algorithms folks were using, and thus the APIs are all focused on writing out the resulting digests, which are opaque bytes, e.g. CRC32 produces a 4-byte hash. However, especially for these non-cryptographic algorithms, many developers are more familiar with getting back a numerical result, e.g. CRC32 produces an uint. Same data, just a different representation. Interestingly, as well, some of these algorithms operate in terms of such integers, so getting back bytes actually requires a separate step, both ensuring some kind of storage location is available in which to write the resulting bytes and then extracting the result to that location. To address all of this, dotnet/runtime#78075 adds to all of the types in System.IO.Hashing new utility methods for producing such numbers. For example, Crc32 has two new methods added to it:
public static uint HashToUInt32(ReadOnlySpan<byte> source);
public uint GetCurrentHashAsUInt32();If you just want the uint-based CRC32 hash for some input bytes, you can simply call this one-shot static method HashToUInt32. Or if you’re building up the hash incrementally, having created an instance of the Crc32 type and having appended data to it, you can get the current uint hash via GetCurrentHashAsUInt32. This also shaves off a few instructions for an algorithm like XxHash3 which actually needs to do more work to produce the result as bytes, only to then need to get those bytes back as a ulong:
// For this test, you'll also need to add:
// <PackageReference Include="System.IO.Hashing" Version="8.0.0-rc.1.23419.4" />
// to the benchmarks.csproj's <ItemGroup>.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.IO.Hashing;
using System.Runtime.InteropServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly byte[] _source = new byte[] { 1, 2, 3 };
[Benchmark(Baseline = true)]
public ulong HashToBytesThenGetUInt64()
{
ulong hash = 0;
XxHash3.Hash(_source, MemoryMarshal.AsBytes(new Span<ulong>(ref hash)));
return hash;
}
[Benchmark]
public ulong HashToUInt64() => XxHash3.HashToUInt64(_source);
}| Method | Mean | Ratio |
|---|---|---|
| HashToBytesThenGetUInt64 | 3.686 ns | 1.00 |
| HashToUInt64 | 3.095 ns | 0.84 |
Also on the hashing front, dotnet/runtime#61558 from @deeprobin adds new BitOperations.Crc32C methods that allow for iterative crc32c hash computation. A nice aspect of crc32c is that multiple platforms provide instructions for this operation, including SSE 4.2 and Arm, and the .NET method will employ whatever hardware support is available, by delegating into the relevant hardware intrinsics in System.Runtime.Intrinsics, e.g.
if (Sse42.X64.IsSupported) return (uint)Sse42.X64.Crc32(crc, data);
if (Sse42.IsSupported) return Sse42.Crc32(Sse42.Crc32(crc, (uint)(data)), (uint)(data >> 32));
if (Crc32.Arm64.IsSupported) return Crc32.Arm64.ComputeCrc32C(crc, data);We can see the impact those intrinsics have by comparing a manual implementation of the crc32c algorithm against the now built-in implementation:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Numerics;
using System.Security.Cryptography;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly byte[] _data = RandomNumberGenerator.GetBytes(1024 * 1024);
[Benchmark(Baseline = true)]
public uint Crc32c_Manual()
{
uint c = 0;
foreach (byte b in _data) c = Tests.Crc32C(c, b);
return c;
}
[Benchmark]
public uint Crc32c_BitOperations()
{
uint c = 0;
foreach (byte b in _data) c = BitOperations.Crc32C(c, b);
return c;
}
private static readonly uint[] s_crcTable = Generate(0x82F63B78u);
internal static uint Crc32C(uint crc, byte data) =>
s_crcTable[(byte)(crc ^ data)] ^ (crc >> 8);
internal static uint[] Generate(uint reflectedPolynomial)
{
var table = new uint[256];
for (int i = 0; i < 256; i++)
{
uint val = (uint)i;
for (int j = 0; j < 8; j++)
{
if ((val & 0b0000_0001) == 0)
{
val >>= 1;
}
else
{
val = (val >> 1) ^ reflectedPolynomial;
}
}
table[i] = val;
}
return table;
}
}| Method | Mean | Ratio |
|---|---|---|
| Crc32c_Manual | 1,977.9 us | 1.00 |
| Crc32c_BitOperations | 739.9 us | 0.37 |
Initialization
Several releases ago, the C# compiler added a valuable optimization that’s now heavily employed throughout the core libraries, and that newer C# constructs (like u8) rely on heavily. It’s quite common to want to store and access sequences or tables of data in code. For example, let’s say I want to quickly look up how many days there are in a month in the Gregorian calendar, based on that month’s 0-based index. I can use a lookup table like this (ignoring leap years for explanatory purposes):
byte[] daysInMonth = new byte[] { 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 };Of course, now I’m allocating a byte[], so I should move that out to a static readonly field. Even then, though, that array has to be allocated, and the data loaded into it, incurring some startup overhead the first time it’s used. Instead, I can write it as:
ReadOnlySpan<byte> daysInMonth = new byte[] { 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 };While this looks like it’s allocating, it’s actually not. The C# compiler recognizes that all of the data being used to initialize the byte[] is constant and that the array is being stored directly into a ReadOnlySpan<byte>, which doesn’t provide any means for extracting the array back out. As such, the compiler instead lowers this into code that effectively does this (we can’t exactly express in C# the IL that gets generated, so this is pseudo-code):
ReadOnlySpan<byte> daysInMonth = new ReadOnlySpan<byte>(
&<PrivateImplementationDetails>.9D61D7D7A1AA7E8ED5214C2F39E0C55230433C7BA728C92913CA4E1967FAF8EA,
12);It blits the data for the array into the assembly, and then constructing the span isn’t via an array allocation, but rather just wrapping the span around a pointer directly into the assembly’s data. This not only avoids the startup overhead and the extra object on the heap, it also better enables various JIT optimizations, especially when the JIT is able to see what offset is being accessed. If I run this benchmark:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[DisassemblyDiagnoser]
public class Tests
{
private static readonly byte[] s_daysInMonthArray = new byte[] { 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 };
private static ReadOnlySpan<byte> DaysInMonthSpan => new byte[] { 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 };
[Benchmark] public int ViaArray() => s_daysInMonthArray[0];
[Benchmark] public int ViaSpan() => DaysInMonthSpan[0];
}it produces this assembly:
; Tests.ViaArray()
mov rax,1B860002028
mov rax,[rax]
movzx eax,byte ptr [rax+10]
ret
; Total bytes of code 18
; Tests.ViaSpan()
mov eax,1F
ret
; Total bytes of code 6In other words, for the array, it’s reading the address of the array and is then reading the element at offset 0x10, or decimal 16, which is where the array’s data begins. For the span, it’s simply loading the value 0x1F, or decimal 31, as it’s directly reading the data from the assembly data. (This isn’t a case of a missing optimization in the JIT for the array example… arrays are mutable, so the JIT can’t constant fold based on the current value stored in the array, since technically it could change.)
However, this compiler optimization only applied to byte, sbyte, and bool. Any other primitive, and the compiler would simply do exactly what you asked it to do: allocate the array. Far from ideal. The reason for the limitation was endianness. The compiler needs to generate binaries that work on both little-endian and big-endian systems; for single-byte types, there’s no endianness concern (since endianness is about the ordering of the bytes, and if there’s only one byte, there’s only one ordering), but for multi-byte types, the generated code could no longer just point directly into the data, as on some systems the data’s bytes would be reversed.
.NET 7 added a new API to help with this, RuntimeHelpers.CreateSpan<T>. Rather than just emitting new ReadOnlySpan<T>(ptrIntoData, dataLength), the idea was that the compiler would emit a call to CreateSpan<T>, passing in a reference to the field containing the data. The JIT and VM would then collude to ensure the data was loaded correctly and efficiently; on a little-endian system, the code would be emitted as if the call weren’t there (replaced by the equivalent of wrapping a span around the pointer and length), and on a big-endian system, the data would be loaded, reversed, and cached into an array, and the code gen would then be creating a span wrapping that array. Unfortunately, although the API shipped in .NET 7, the compiler support for it didn’t, and because no one was then actually using it, there were a variety of issues in the toolchain that went unnoticed.
Thankfully, all of these issues are now addressed in .NET 8 and the C# compiler (and also backported to .NET 7). dotnet/roslyn#61414 added support to the C# compiler for also supporting short, ushort, char, int, uint, long, ulong, double, float, and enums based on these. On target frameworks where CreateSpan<T> is available (.NET 7+), the compiler generates code that uses it. On frameworks where the function isn’t available, the compiler falls back to emitting a static readonly array to cache the data and wrapping a span around that. This was an important consideration for libraries that build for multiple target frameworks, so that when building “downlevel”, the implementation doesn’t fall off the proverbial performance cliff due to relying on this optimization (this optimization is a bit of an oddity, as you actually need to write your code in a way that, without the optimization, ends up performing worse than what you would have otherwise had). With the compiler implementation in place, and fixes to the Mono runtime in dotnet/runtime#82093 and dotnet/runtime#81695, and with fixes to the trimmer (which needs to preserve the alignment of the data that’s emitted by the compiler) in dotnet/cecil#60, the rest of the runtime was then able to consume the feature, which it did in dotnet/runtime#79461. So now, for example, System.Text.Json can use this to store not only how many days there are in a (non-leap) year, but also store how many days there are before a given month, something that wasn’t previously possible efficiently in this form due to there being values larger than can be stored in a byte.
// dotnet run -c Release -f net8.0 --filter **
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "i")]
[MemoryDiagnoser(displayGenColumns: false)]
[DisassemblyDiagnoser]
public class Tests
{
private static ReadOnlySpan<int> DaysToMonth365 => new int[] { 0, 31, 59, 90, 120, 151, 181, 212, 243, 273, 304, 334, 365 };
[Benchmark]
[Arguments(1)]
public int DaysToMonth(int i) => DaysToMonth365[i];
}| Method | Mean | Code Size | Allocated |
|---|---|---|---|
| DaysToMonth | 0.0469 ns | 35 B | – |
; Tests.DaysToMonth(Int32)
sub rsp,28
cmp edx,0D
jae short M00_L00
mov eax,edx
mov rcx,12B39072DD0
mov eax,[rcx+rax*4]
add rsp,28
ret
M00_L00:
call CORINFO_HELP_RNGCHKFAIL
int 3
; Total bytes of code 35dotnet/roslyn#69820 (which hasn’t yet merged but should soon) then rounds things out by ensuring that the pattern of initializing a ReadOnlySpan<T> to a new T[] { const of T, const of T, ... /* all const values */ } will always avoid the array allocation, regardless of the type of T being used. The T need only be expressible as a constant in C#. That means this optimization now also applies to string, decimal, nint, and nuint. For these, the compiler will fallback to using a cached array singleton. With that, this code:
// dotnet build -c Release -f net8.0
internal static class Program
{
private static void Main() { }
private static ReadOnlySpan<bool> Booleans => new bool[] { false, true };
private static ReadOnlySpan<sbyte> SBytes => new sbyte[] { 0, 1, 2 };
private static ReadOnlySpan<byte> Bytes => new byte[] { 0, 1, 2 };
private static ReadOnlySpan<short> Shorts => new short[] { 0, 1, 2 };
private static ReadOnlySpan<ushort> UShorts => new ushort[] { 0, 1, 2 };
private static ReadOnlySpan<char> Chars => new char[] { '0', '1', '2' };
private static ReadOnlySpan<int> Ints => new int[] { 0, 1, 2 };
private static ReadOnlySpan<uint> UInts => new uint[] { 0, 1, 2 };
private static ReadOnlySpan<long> Longs => new long[] { 0, 1, 2 };
private static ReadOnlySpan<ulong> ULongs => new ulong[] { 0, 1, 2 };
private static ReadOnlySpan<float> Floats => new float[] { 0, 1, 2 };
private static ReadOnlySpan<double> Doubles => new double[] { 0, 1, 2 };
private static ReadOnlySpan<nint> NInts => new nint[] { 0, 1, 2 };
private static ReadOnlySpan<nuint> NUInts => new nuint[] { 0, 1, 2 };
private static ReadOnlySpan<decimal> Decimals => new decimal[] { 0, 1, 2 };
private static ReadOnlySpan<string> Strings => new string[] { "0", "1", "2" };
}now compiles down to something like this (again, this is pseudo-code, since we can’t exactly represent in C# what’s emitted in IL):
internal static class Program
{
private static void Main() { }
//
// No endianness concerns. Create a span that points directly into the assembly data,
// using the `ReadOnlySpan<T>(void*, int)` constructor.
//
private static ReadOnlySpan<bool> Booleans => new ReadOnlySpan<bool>(
&<PrivateImplementationDetails>.B413F47D13EE2FE6C845B2EE141AF81DE858DF4EC549A58B7970BB96645BC8D2, 2);
private static ReadOnlySpan<sbyte> SBytes => new ReadOnlySpan<sbyte>(
&<PrivateImplementationDetails>.AE4B3280E56E2FAF83F414A6E3DABE9D5FBE18976544C05FED121ACCB85B53FC, 3);
private static ReadOnlySpan<byte> Bytes => new ReadOnlySpan<byte>(
&<PrivateImplementationDetails>.AE4B3280E56E2FAF83F414A6E3DABE9D5FBE18976544C05FED121ACCB85B53FC, 3);
//
// Endianness concerns but with data that a span could point to directly if
// of the correct byte ordering. Go through the RuntimeHelpers.CreateSpan intrinsic.
//
private static ReadOnlySpan<short> Shorts => RuntimeHelpers.CreateSpan<short>((RuntimeFieldHandle)
&<PrivateImplementationDetails>.90C2698921CA9FD02950BE353F721888760E33AB5095A21E50F1E4360B6DE1A02);
private static ReadOnlySpan<ushort> UShorts => RuntimeHelpers.CreateSpan<ushort>((RuntimeFieldHandle)
&<PrivateImplementationDetails>.90C2698921CA9FD02950BE353F721888760E33AB5095A21E50F1E4360B6DE1A02);
private static ReadOnlySpan<char> Chars => RuntimeHelpers.CreateSpan<char>((RuntimeFieldHandle)
&<PrivateImplementationDetails>.9B9A3CBF2B718A8F94CE348CB95246738A3A9871C6236F4DA0A7CC126F03A8B42);
private static ReadOnlySpan<int> Ints => RuntimeHelpers.CreateSpan<int>((RuntimeFieldHandle)
&<PrivateImplementationDetails>.AD5DC1478DE06A4C2728EA528BD9361A4B945E92A414BF4D180CEDAAEAA5F4CC4);
private static ReadOnlySpan<uint> UInts => RuntimeHelpers.CreateSpan<uint>((RuntimeFieldHandle)
&<PrivateImplementationDetails>.AD5DC1478DE06A4C2728EA528BD9361A4B945E92A414BF4D180CEDAAEAA5F4CC4);
private static ReadOnlySpan<long> Longs => RuntimeHelpers.CreateSpan<long>((RuntimeFieldHandle)
&<PrivateImplementationDetails>.AB25350E3E65EFEBE24584461683ECDA68725576E825E550038B90E7B14799468);
private static ReadOnlySpan<ulong> ULongs => RuntimeHelpers.CreateSpan<ulong>((RuntimeFieldHandle)
&<PrivateImplementationDetails>.AB25350E3E65EFEBE24584461683ECDA68725576E825E550038B90E7B14799468);
private static ReadOnlySpan<float> Floats => RuntimeHelpers.CreateSpan<float>((RuntimeFieldHandle)
&<PrivateImplementationDetails>.75664B4DA1C08DE9E8FAD52303CC458B3E420EDDE6591E58761E138CC5E3F1634);
private static ReadOnlySpan<double> Doubles => RuntimeHelpers.CreateSpan<double>((RuntimeFieldHandle)
&<PrivateImplementationDetails>.B0C45303F7F11848CB5E6E5B2AF2FB2AECD0B72C28748B88B583AB6BB76DF1748);
//
// Create a span around a cached array.
//
private unsafe static ReadOnlySpan<nuint> NUInts => new ReadOnlySpan<nuint>(
<PrivateImplementationDetails>.AD5DC1478DE06A4C2728EA528BD9361A4B945E92A414BF4D180CEDAAEAA5F4CC_B16
??= new nuint[] { 0, 1, 2 });
private static ReadOnlySpan<nint> NInts => new ReadOnlySpan<nint>(
<PrivateImplementationDetails>.AD5DC1478DE06A4C2728EA528BD9361A4B945E92A414BF4D180CEDAAEAA5F4CC_B8
??= new nint[] { 0, 1, 2 });
private static ReadOnlySpan<decimal> Decimals => new ReadOnlySpan<decimal>(
<PrivateImplementationDetails>.93AF9093EDC211A9A941BDE5EF5640FD395604257F3D945F93C11BA9E918CC74_B18
??= new decimal[] { 0, 1, 2 });
private static ReadOnlySpan<string> Strings => new ReadOnlySpan<string>(
<PrivateImplementationDetails>.9B9A3CBF2B718A8F94CE348CB95246738A3A9871C6236F4DA0A7CC126F03A8B4_B11
??= new string[] { "0", "1", "2" });
}Another closely-related C# compiler improvement comes in dotnet/runtime#66251 from @alrz. The previously mentioned optimization around single-byte types also applies to stackalloc initialization. If I write:
Span<int> span = stackalloc int[] { 1, 2, 3 };the C# compiler emits code similar to if I’d written the following:
byte* ptr = stackalloc byte[12];
*(int*)ptr = 1;
*(int*)(ptr) = 2;
*(int*)(ptr + (nint)2 * (nint)4) = 3;
Span<int> span = new Span<int>(ptr);If, however, I switch from the multi-byte int to the single-byte byte:
Span<byte> span = stackalloc byte[] { 1, 2, 3 };then I get something closer to this:
byte* ptr = stackalloc byte[3];
Unsafe.CopyBlock(ptr, ref <PrivateImplementationDetails>.039058C6F2C0CB492C533B0A4D14EF77CC0F78ABCCCED5287D84A1A2011CFB81, 3); // actually the cpblk instruction
Span<byte> span = new Span<byte>(ptr, 3);Unlike the the new[] case, however, which optimized not only for byte, sbyte, and bool but also for enums with byte and sbyte as an underlying type, the stackalloc optimization didn’t. Thanks to this PR, it now does.
There’s another semi-related new feature spanning C# 12 and .NET 8: InlineArrayAttribute. stackalloc has long provided a way to use stack space as a buffer, rather than needing to allocate memory on the heap; however, for most of .NET’s history, this was “unsafe,” in that it produced a pointer:
byte* buffer = stackalloc byte[8];C# 7.2 introduced the immensely useful improvement to stack allocate directly into a span, at which point it becomes “safe,” not requiring being in an unsafe context and with all access to the span bounds checked appropriately, as with any other span:
Span<byte> buffer = stackalloc byte[8];The C# compiler will lower that to something along the lines of:
Span<byte> buffer;
unsafe
{
byte* tmp = stackalloc byte[8];
buffer = new Span<byte>(tmp, 8);
}However, this is still limited to the kinds of things that can be stackalloc‘d, namely unmanaged types (types which don’t contain any managed references), and it’s limited in where it can be used. That’s not only because stackalloc can’t be used in places like catch and finally blocks, but also because there are places where you want to be able to have such buffers that aren’t limited to the stack: inside of other types. C# has long supported the notion of “fixed-size buffers,” e.g.
struct C
{
internal unsafe fixed char name[30];
}but these require being in an unsafe context since they present to a consumer as a pointer (in the above example, the type of C.name is a char*) and they’re not bounds-checked, and they’re limited in the element type supported (it can only be bool, sbyte, byte, short, ushort, char, int, uint, long, ulong, double, or float).
.NET 8 and C# 12 provide an answer for this: [InlineArray]. This new attribute can be placed onto a struct containing a single field, like this:
[InlineArray(8)]
internal struct EightStrings
{
private string _field;
}The runtime then expands that struct to be logically the same as if you wrote:
internal struct EightStrings
{
private string _field0;
private string _field1;
private string _field2;
private string _field3;
private string _field4;
private string _field5;
private string _field6;
private string _field7;
}ensuring that all of the storage is appropriately contiguous and aligned. Why is that important? Because C# 12 then makes it easy to get a span from one of these instances, e.g.
EightStrings strings = default;
Span<string> span = strings;This is all “safe,” and the type of the field can be anything that’s valid as a generic type argument. That means pretty much anything other than refs, ref structs, and pointers. This is a constraint imposed by the C# language, since with such a field type T you wouldn’t be able to construct a Span<T>, but the warning can be suppressed, as the runtime itself does support anything as the field type. The compiler-generated code for getting a span is equivalent to if you wrote:
EightStrings strings = default;
Span<string> span = MemoryMarshal.CreateSpan(ref Unsafe.As<EightStrings, string>(ref strings), 8);which is obviously complicated and not something you’d want to be writing frequently. In fact, the compiler doesn’t want to emit that frequently, either, so it puts it into a helper in the assembly that it can reuse.
[CompilerGenerated]
internal sealed class <PrivateImplementationDetails>
{
internal static Span<TElement> InlineArrayAsSpan<TBuffer, TElement>(ref TBuffer buffer, int length) =>
MemoryMarshal.CreateSpan(ref Unsafe.As<TBuffer, TElement>(ref buffer), length);
...
}(<PrivateImplementationDetails> is a class the C# compiler emits to contain helpers and other compiler-generated artifacts used by code it emits elsewhere in the program. You saw it in the previous discussion as well, as it’s where it emits the data in support of array and span initialization from constants.)
The [InlineArray]-attributed type is also a normal struct like any other, and can be used anywhere any other struct can be used; that it’s using [InlineArray] is effectively an implementation detail. So, for example, you can embed it into another type, and the following code will print out “0” through “7” as you’d expect:
// dotnet run -c Release -f net8.0
using System.Runtime.CompilerServices;
MyData data = new();
Span<string> span = data.Strings;
for (int i = 0; i < span.Length; i++) span[i] = i.ToString();
foreach (string s in data.Strings) Console.WriteLine(s);
public class MyData
{
private EightStrings _strings;
public Span<string> Strings => _strings;
[InlineArray(8)]
private unsafe struct EightStrings { private string _field; }
}dotnet/runtime#82744 provided the CoreCLR runtime support for InlineArray, dotnet/runtime#83776 and dotnet/runtime#84097 provided the Mono runtime support, and dotnet/roslyn#68783 merged the C# compiler support.
This feature isn’t just about you using it directly, either. The compiler itself also uses [InlineArray] as an implementation detail behind other new and planned features… we’ll talk more about that when discussing collections.
Analyzers
Lastly, even though the runtime and core libraries have made great strides in improving the performance of existing functionality and adding new performance-focused support, sometimes the best fix is actually in the consuming code. That’s where analyzers come in. Several new analyzers have been added in .NET 8 to help find particular classes of string-related performance issues.
CA1858, added in dotnet/roslyn-analyzers#6295 from @Youssef1313, looks for calls to IndexOf where the result is then being checked for equality with 0. This is functionally the same as a call to StartsWith, but is much more expensive as it could end up examining the entire source string rather than just the starting position (dotnet/runtime#79896 fixes a few such uses in dotnet/runtime).
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly string _haystack = """
It was the best of times, it was the worst of times,
it was the age of wisdom, it was the age of foolishness,
it was the epoch of belief, it was the epoch of incredulity,
it was the season of light, it was the season of darkness,
it was the spring of hope, it was the winter of despair.
""";
private readonly string _needle = "hello";
[Benchmark(Baseline = true)]
public bool StartsWith_IndexOf0() =>
_haystack.IndexOf(_needle, StringComparison.OrdinalIgnoreCase) == 0;
[Benchmark]
public bool StartsWith_StartsWith() =>
_haystack.StartsWith(_needle, StringComparison.OrdinalIgnoreCase);
}| Method | Mean | Ratio |
|---|---|---|
| StartsWith_IndexOf0 | 31.327 ns | 1.00 |
| StartsWith_StartsWith | 4.501 ns | 0.14 |
CA1865, CA1866, and CA1867 are all related to each other. Added in dotnet/roslyn-analyzers#6799 from @mrahhal, these look for calls to string methods like StartsWith, searching for calls passing in a single-character string argument, e.g. str.StartsWith("@"), and recommending the argument be converted into a char. Which diagnostic ID the analyzer raises depends on whether the transformation is 100% equivalent behavior or whether a change in behavior could potentially result, e.g. switching from a linguistic comparison to an ordinal comparison.

// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly string _haystack = "All we have to decide is what to do with the time that is given us.";
[Benchmark(Baseline = true)]
public int IndexOfString() => _haystack.IndexOf("v");
[Benchmark]
public int IndexOfChar() => _haystack.IndexOf('v');
}| Method | Mean | Ratio |
|---|---|---|
| IndexOfString | 37.634 ns | 1.00 |
| IndexOfChar | 1.979 ns | 0.05 |
CA1862, added in dotnet/roslyn-analyzers#6662, looks for places where code is performing a case-insensitive comparison (which is fine) but doing so by first lower/uppercasing an input string and then comparing that (which is far from fine). It’s much more efficient to just use a StringComparison. dotnet/runtime#89539 fixes a few such cases.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly string _input = "https://dot.net";
[Benchmark(Baseline = true)]
public bool IsHttps_ToUpper() => _input.ToUpperInvariant().StartsWith("HTTPS://");
[Benchmark]
public bool IsHttps_StringComparison() => _input.StartsWith("HTTPS://", StringComparison.OrdinalIgnoreCase);
}| Method | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|
| IsHttps_ToUpper | 46.3702 ns | 1.00 | 56 B | 1.00 |
| IsHttps_StringComparison | 0.4781 ns | 0.01 | – | 0.00 |
And CA1861, added in dotnet/roslyn-analyzers#5383 from @steveberdy, looks for opportunities to lift and cache arrays being passed as arguments. dotnet/runtime#86229 addresses the issues found by the analyzer in dotnet/runtime.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private static readonly char[] s_separator = new[] { ',', ':' };
private readonly string _value = "1,2,3:4,5,6";
[Benchmark(Baseline = true)]
public string[] Split_Original() => _value.Split(new[] { ',', ':' });
[Benchmark]
public string[] Split_Refactored() => _value.Split(s_separator);
}| Method | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|
| Split_Original | 108.6 ns | 1.00 | 248 B | 1.00 |
| Split_Refactored | 104.0 ns | 0.96 | 216 B | 0.87 |
Collections
Collections are the bread and butter of practically every application and service. Have more than one of something? You need a collection to manage them. And since they’re so commonly needed and used, every release of .NET invests meaningfully in improving their performance and driving down their overheads.
General
Some of the changes made in .NET 8 are largely collection-agnostic and affect a large number of collections. For example, dotnet/runtime#82499 special-cases “empty” on a bunch of the built-in collection types to return an empty singleton enumerator, thus avoiding allocating a largely useless object. This is wide-reaching, affecting List<T>, Queue<T>, Stack<T>, LinkedList<T>, PriorityQueue<TElement, TPriority>, SortedDictionary<TKey, TValue>, SortedList<TKey, TValue>, HashSet<T>, Dictionary<TKey, TValue>, and ArraySegment<T>. Interestingly, T[] was already on this plan (as were a few other collections, like ConditionalWeakTable<TKey, TValue>); if you called IEnumerable<T>.GetEnumerator on any T[] of length 0, you already got back a singleton enumerator hardcoded to return false from its MoveNext. That same enumerator singleton is what’s now returned from the GetEnumerator implementations of all of those cited collection types when they’re empty at the moment GetEnumerator is called.
// dotnet run -c Release -f net7.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Environments;
using BenchmarkDotNet.Jobs;
using BenchmarkDotNet.Running;
var config = DefaultConfig.Instance
.AddJob(Job.Default.WithId(".NET 7").WithRuntime(CoreRuntime.Core70).AsBaseline())
.AddJob(Job.Default.WithId(".NET 8 w/o PGO").WithRuntime(CoreRuntime.Core80).WithEnvironmentVariable("DOTNET_TieredPGO", "0"))
.AddJob(Job.Default.WithId(".NET 8").WithRuntime(CoreRuntime.Core80));
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args, config);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "EnvironmentVariables", "Runtime")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly IEnumerable<int> _list = new List<int>();
private readonly IEnumerable<int> _queue = new Queue<int>();
private readonly IEnumerable<int> _stack = new Stack<int>();
private readonly IEnumerable<int> _linkedList = new LinkedList<int>();
private readonly IEnumerable<int> _hashSet = new HashSet<int>();
private readonly IEnumerable<int> _segment = new ArraySegment<int>(Array.Empty<int>());
private readonly IEnumerable<KeyValuePair<int, int>> _dictionary = new Dictionary<int, int>();
private readonly IEnumerable<KeyValuePair<int, int>> _sortedDictionary = new SortedDictionary<int, int>();
private readonly IEnumerable<KeyValuePair<int, int>> _sortedList = new SortedList<int, int>();
private readonly IEnumerable<(int, int)> _priorityQueue = new PriorityQueue<int, int>().UnorderedItems;
[Benchmark] public IEnumerator<int> GetList() => _list.GetEnumerator();
[Benchmark] public IEnumerator<int> GetQueue() => _queue.GetEnumerator();
[Benchmark] public IEnumerator<int> GetStack() => _stack.GetEnumerator();
[Benchmark] public IEnumerator<int> GetLinkedList() => _linkedList.GetEnumerator();
[Benchmark] public IEnumerator<int> GetHashSet() => _hashSet.GetEnumerator();
[Benchmark] public IEnumerator<int> GetArraySegment() => _segment.GetEnumerator();
[Benchmark] public IEnumerator<KeyValuePair<int, int>> GetDictionary() => _dictionary.GetEnumerator();
[Benchmark] public IEnumerator<KeyValuePair<int, int>> GetSortedDictionary() => _sortedDictionary.GetEnumerator();
[Benchmark] public IEnumerator<KeyValuePair<int, int>> GetSortedList() => _sortedList.GetEnumerator();
[Benchmark] public IEnumerator<(int, int)> GetPriorityQueue() => _priorityQueue.GetEnumerator();
}| Method | Job | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| GetList | .NET 7 | 15.9046 ns | 1.00 | 40 B | 1.00 |
| GetList | .NET 8 w/o PGO | 2.1016 ns | 0.13 | – | 0.00 |
| GetList | .NET 8 | 0.8954 ns | 0.06 | – | 0.00 |
| GetQueue | .NET 7 | 16.5115 ns | 1.00 | 40 B | 1.00 |
| GetQueue | .NET 8 w/o PGO | 1.8934 ns | 0.11 | – | 0.00 |
| GetQueue | .NET 8 | 1.1068 ns | 0.07 | – | 0.00 |
| GetStack | .NET 7 | 16.2183 ns | 1.00 | 40 B | 1.00 |
| GetStack | .NET 8 w/o PGO | 4.5345 ns | 0.28 | – | 0.00 |
| GetStack | .NET 8 | 2.7712 ns | 0.17 | – | 0.00 |
| GetLinkedList | .NET 7 | 19.9335 ns | 1.00 | 48 B | 1.00 |
| GetLinkedList | .NET 8 w/o PGO | 4.6176 ns | 0.23 | – | 0.00 |
| GetLinkedList | .NET 8 | 2.5660 ns | 0.13 | – | 0.00 |
| GetHashSet | .NET 7 | 15.8322 ns | 1.00 | 40 B | 1.00 |
| GetHashSet | .NET 8 w/o PGO | 1.8871 ns | 0.12 | – | 0.00 |
| GetHashSet | .NET 8 | 1.1129 ns | 0.07 | – | 0.00 |
| GetArraySegment | .NET 7 | 17.0096 ns | 1.00 | 40 B | 1.00 |
| GetArraySegment | .NET 8 w/o PGO | 3.9111 ns | 0.23 | – | 0.00 |
| GetArraySegment | .NET 8 | 1.3438 ns | 0.08 | – | 0.00 |
| GetDictionary | .NET 7 | 18.3397 ns | 1.00 | 48 B | 1.00 |
| GetDictionary | .NET 8 w/o PGO | 2.3202 ns | 0.13 | – | 0.00 |
| GetDictionary | .NET 8 | 1.0185 ns | 0.06 | – | 0.00 |
| GetSortedDictionary | .NET 7 | 49.5423 ns | 1.00 | 112 B | 1.00 |
| GetSortedDictionary | .NET 8 w/o PGO | 5.6333 ns | 0.11 | – | 0.00 |
| GetSortedDictionary | .NET 8 | 2.9824 ns | 0.06 | – | 0.00 |
| GetSortedList | .NET 7 | 18.9600 ns | 1.00 | 48 B | 1.00 |
| GetSortedList | .NET 8 w/o PGO | 4.4282 ns | 0.23 | – | 0.00 |
| GetSortedList | .NET 8 | 2.2451 ns | 0.12 | – | 0.00 |
| GetPriorityQueue | .NET 7 | 17.4375 ns | 1.00 | 40 B | 1.00 |
| GetPriorityQueue | .NET 8 w/o PGO | 4.3855 ns | 0.25 | – | 0.00 |
| GetPriorityQueue | .NET 8 | 2.8931 ns | 0.17 | – | 0.00 |
Enumerator allocations are avoided in other contexts, as well. dotnet/runtime#78613 from @madelson avoids an unnecessary enumerator allocation in HashSet<T>.SetEquals and HashSet<T>.IsProperSupersetOf, rearranging some code in order to use HashSet<T>‘s struct-based enumerator rather than relying on it being boxed as an IEnumerator<T>. This both saves an allocation and avoids unnecessary interface dispatch.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly HashSet<int> _source1 = new HashSet<int> { 1, 2, 3, 4, 5 };
private readonly IEnumerable<int> _source2 = new HashSet<int> { 1, 2, 3, 4, 5 };
[Benchmark]
public bool SetEquals() => _source1.SetEquals(_source2);
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| SetEquals | .NET 7.0 | 75.02 ns | 1.00 | 40 B | 1.00 |
| SetEquals | .NET 8.0 | 26.29 ns | 0.35 | – | 0.00 |
There are other places where “empty” has been special-cased. dotnet/runtime#76097 and dotnet/runtime#76764 added an Empty singleton to ReadOnlyCollection<T>, ReadOnlyDictionary<TKey, TValue>, and ReadOnlyObservableCollection<T>, and then used that singleton in a bunch of places, multiple of which accrue further to many other places that consume them. For example, Array.AsReadOnly now checks whether the array being wrapped is empty, and if it is, AsReadOnly returns ReadOnlyCollection<T>.Empty rather than allocating a new ReadOnlyCollection<T> to wrap the empty array (it also makes a similar update to ReadOnlyCollection<T>.GetEnumerator as was discussed with the previous PRs). ConcurrentDictionary<TKey, TValue>‘s Keys and Values will now return the same singleton if the count is known to be 0. And so on. These kinds of changes reduce the overall “peanut butter” layer of allocation across uses of collections.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Collections.ObjectModel;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly int[] _array = new int[0];
[Benchmark]
public ReadOnlyCollection<int> AsReadOnly() => Array.AsReadOnly(_array);
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| AsReadOnly | .NET 7.0 | 13.380 ns | 1.00 | 24 B | 1.00 |
| AsReadOnly | .NET 8.0 | 1.460 ns | 0.11 | – | 0.00 |
Of course, there are many much more targeted and impactful improvements for specific collection types, too.
List
The most widely used collection in .NET, other than T[], is List<T>. While that claim feels accurate, I also like to be data-driven, so as one measure, looking at the same NuGet packages we looked at earlier for enums, here’s a graph showing the number of references to the various concrete collection types:
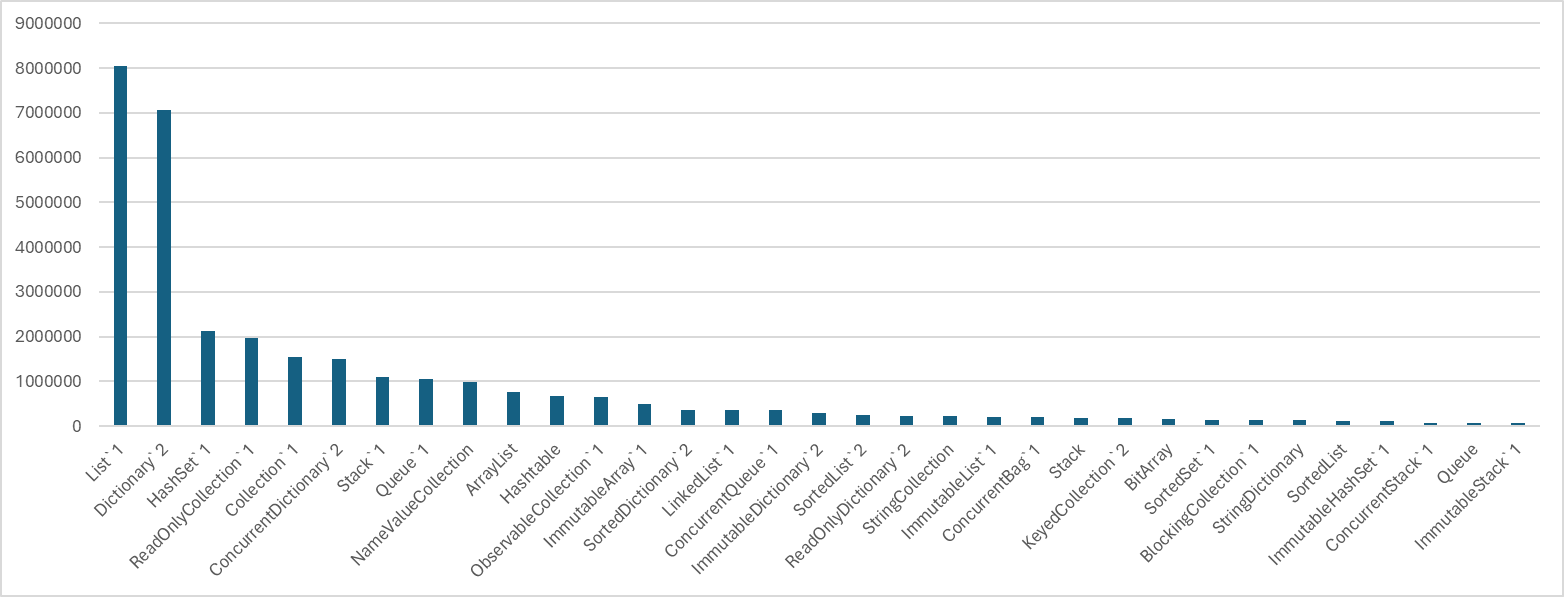
Given its ubiquity, List<T> sees a variety of improvements in .NET 8. dotnet/runtime#76043 improves the performance of its AddRange method, in particular when dealing with non-ICollection<T> inputs. When adding an ICollection<T>, AddRange reads the collection’s Count, ensures the list’s array is large enough to store all the incoming data, and then copies it as efficiently as the source collection can muster by invoking the collection’s CopyTo method to propagate the data directly into the List<T>‘s backing store. But if the input enumerable isn’t an ICollection<T>, AddRange has little choice but to enumerate the collection and add each item one at a time. Prior to this release, AddRange(collection) simply delegated to InsertRange(Count, collection), which meant that when InsertRange discovered the source wasn’t an ICollection<T>, it would fall back to calling Insert(i++, item) with each item from the enumerable. That Insert method is too large to be inlined by default, plus involves additional checks that aren’t necessary for the AddRange usage (e.g. it needs to validate that the supplied position is within the range of the list, but for adding, we’re always just implicitly adding at the end, with a position implicitly known to be valid). This PR rewrote AddRange to not just delegate to InsertRange, at which point when it falls back to enumerating the non-ICollection<T> enumerable, it calls the optimized Add, which is inlineable, and which doesn’t have any extraneous checks.
// dotnet run -c Release -f net7.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Environments;
using BenchmarkDotNet.Jobs;
using BenchmarkDotNet.Running;
var config = DefaultConfig.Instance
.AddJob(Job.Default.WithId(".NET 7").WithRuntime(CoreRuntime.Core70).AsBaseline())
.AddJob(Job.Default.WithId(".NET 8 w/o PGO").WithRuntime(CoreRuntime.Core80).WithEnvironmentVariable("DOTNET_TieredPGO", "0"))
.AddJob(Job.Default.WithId(".NET 8").WithRuntime(CoreRuntime.Core80));
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args, config);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "EnvironmentVariables", "Runtime")]
public class Tests
{
private readonly IEnumerable<int> _source = GetItems(1024);
private readonly List<int> _list = new();
[Benchmark]
public void AddRange()
{
_list.Clear();
_list.AddRange(_source);
}
private static IEnumerable<int> GetItems(int count)
{
for (int i = 0; i < count; i++) yield return i;
}
}For this test, I’ve configured it to run with and without PGO on .NET 8, because this particular test benefits significantly from PGO, and I want to tease those improvements apart from those that come from the cited improvements to AddRange. Why does PGO help here? Because the AddRange method will see that the type of the enumerable is always the compiler-generated iterator for GetItems and will thus generate code specific to that type, enabling the calls that would otherwise involve interface dispatch to instead be devirtualized.
| Method | Job | Mean | Ratio |
|---|---|---|---|
| AddRange | .NET 7 | 6.365 us | 1.00 |
| AddRange | .NET 8 w/o PGO | 4.396 us | 0.69 |
| AddRange | .NET 8 | 2.445 us | 0.38 |
AddRange has improved in other ways, too. One of the long-requested features for List<T>, ever since spans were introduced in .NET Core 2.1, was better integration between List<T> and {ReadOnly}Span<T>. dotnet/runtime#76274 provides that, adding support to both AddRange and InsertRange for data stored in a ReadOnlySpan<T>, and also support for copying all of the data in a List<T> to a Span<T> via a CopyTo method. It was of course previously possible to achieve this, but doing so required handling one element at a time, which when compared to vectorized copy implementations is significantly slower.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly int[] _source = new int[1024];
private readonly List<int> _list = new();
[Benchmark(Baseline = true)]
public void OpenCoded()
{
_list.Clear();
foreach (int i in (ReadOnlySpan<int>)_source)
{
_list.Add(i);
}
}
[Benchmark]
public void AddRange()
{
_list.Clear();
_list.AddRange((ReadOnlySpan<int>)_source);
}
}| Method | Mean | Ratio |
|---|---|---|
| OpenCoded | 1,261.66 ns | 1.00 |
| AddRange | 51.74 ns | 0.04 |
You may note that these new AddRange, InsertRange, and CopyTo methods were added as extension methods rather than as instance methods on List<T>. That was done for a few reasons, but the primary motivating factor was avoiding ambiguity. Consider this example:
var c = new MyCollection<int>();
c.AddRange(new int[] { 1, 2, 3 });
public class MyCollection<T>
{
public void AddRange(IEnumerable<T> source) { }
public void AddRange(ReadOnlySpan<T> source) { }
}This will fail to compile with:
error CS0121: The call is ambiguous between the following methods or properties: ‘MyCollection.AddRange(IEnumerable)’ and ‘MyCollection.AddRange(ReadOnlySpan)’
because an array T[] both implements IEnumerable<T> and has an implicit conversion to ReadOnlySpan<T>, and as such the compiler doesn’t know which to use. It’s likely this ambiguity will be resolved in a future version of the language, but for now we resolved it ourselves by making the span-based overload an extension method:
namespace System.Collections.Generic
{
public static class CollectionExtensions
{
public static void AddRange<T>(this List<T> list, ReadOnlySpan<T> source) { ... }
}
}The other significant addition for List<T> comes in dotnet/runtime#82146 from @MichalPetryka. In .NET 5, the CollectionsMarshal.AsSpan(List<T>) method was added; it returns a Span<T> for the in-use area of a List<T>‘s backing store. For example, if you write:
var list = new List<int>(42) { 1, 2, 3 };
Span<int> span = CollectionsMarshal.AsSpan(list);that will provide you with a Span<int> with length 3, since the list’s Count is 3. This is very useful for a variety of scenarios, in particular for consuming a List<T>‘s data via span-based APIs. It doesn’t, however, enable scenarios that want to efficiently write to a List<T>, in particular where it would require increasing a List<T>‘s count. Let’s say, for example, you wanted to create a new List<char> that contained 100 ‘a’ values. You might think you could write:
var list = new List<char>(100);
Span<char> span = CollectionsMarshal.AsSpan(list); // oops
span.Fill('a');but that won’t impact the contents of the created list at all, because the span’s Length will match the Count of the list: 0. What we need to be able to do is change the count of the list, effectively telling it “pretend like 100 values were just added to you, even though they weren’t.” This PR adds the new SetCount method, which does just that. We can now write the previous example like:
var list = new List<char>();
CollectionsMarshal.SetCount(list, 100);
Span<char> span = CollectionsMarshal.AsSpan(list);
span.Fill('a'); // yay!and we will successfully find ourselves with a list containing 100 ‘a’ elements.
LINQ
That new SetCount method is not only exposed publicly, it’s also used as an implementation detail now in LINQ (Language-Integrated Query), thanks to dotnet/runtime#85288. Enumerable‘s ToList method now benefits from this in a variety of places. For example, calling Enumerable.Repeat('a', 100).ToList() will behave very much like the previous example (albeit with an extra enumerable allocation for the Repeat), creating a new list, using SetCount to set its count to 100, getting the backing span, and calling Fill to populate it. The impact of directly writing to the span rather than going through List<T>.Add for each item is visible in the following examples:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly IEnumerable<int> _source = Enumerable.Range(0, 1024).ToArray();
[Benchmark]
public List<int> SelectToList() => _source.Select(i => i * 2).ToList();
[Benchmark]
public List<byte> RepeatToList() => Enumerable.Repeat((byte)'a', 1024).ToList();
[Benchmark]
public List<int> RangeSelectToList() => Enumerable.Range(0, 1024).Select(i => i * 2).ToList();
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| SelectToList | .NET 7.0 | 2,627.8 ns | 1.00 |
| SelectToList | .NET 8.0 | 1,096.6 ns | 0.42 |
| RepeatToList | .NET 7.0 | 1,543.2 ns | 1.00 |
| RepeatToList | .NET 8.0 | 106.1 ns | 0.07 |
| RangeSelectToList | .NET 7.0 | 2,908.9 ns | 1.00 |
| RangeSelectToList | .NET 8.0 | 865.2 ns | 0.29 |
In the case of SelectToList and RangeSelectToList, the benefit is almost entirely due to writing directly into the span for each element vs the overhead of Add. In the case of RepeatToList, because the ToList call has direct access to the span, it’s able to use the vectorized Fill method (as it was previously doing just for ToArray), achieving an even larger speedup.
You’ll note that I didn’t include a test for Enumerable.Range(...).ToList() above. That’s because it was improved in other ways, and I didn’t want to conflate them in the measurements. In particular, dotnet/runtime#87992 from @neon-sunset vectorized the internal Fill method that’s used by the specialization of both ToArray and ToList on the iterator returned from Enumerable.Range. That means that rather than writing one int at a time, on a system that supports 128-bit vectors (which is pretty much all hardware you might use today) it’ll instead write four ints at a time, and on a system that supports 256-bit vectors, it’ll write eight ints at a time. Thus, Enumerable.Range(...).ToList() benefits both from writing directly into the span and from the now vectorized implementation, which means it ends up with similar speedups as RepeatToList above. We can also tease apart these improvements by changing what instruction sets are seen as available.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
[Benchmark]
public List<int> RangeToList() => Enumerable.Range(0, 16_384).ToList();
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| RangeToList | .NET 7.0 | 25.374 us | 1.00 |
| RangeToList | .NET 8.0 | 6.872 us | 0.27 |
These optimized span-based implementations now also accrue to other usage beyond ToArray and ToList. If you look at the Enumerable.Repeat and Enumerable.Range implementations in .NET Framework, you’ll see that they’re just normal C# iterators, e.g.
static IEnumerable<int> RangeIterator(int start, int count)
{
for (int i = 0; i < count; i++)
{
yield return start + i;
}
}but years ago, these methods were changed in .NET Core to return a custom iterator (just a normal class implementing IEnumerator<T> where we provide the full implementation rather than the compiler doing so). Once we have a dedicated type, we can add additional interfaces to it, and dotnet/runtime#88249 does exactly that, making these internal RangeIterator, RepeatIterator, and several other types implement IList<T>. That then means that any code which queries an IEnumerable<T> for whether it implements IList<T>, such as to use its Count and CopyTo methods, will light up when passed one of these instances as well. And the same Fill implementation that’s used internally to implement ToArray and ToList is then used as well with CopyTo. That means if you write code like:
List<T> list = ...;
IEnumerable<T> enumerable = ...;
list.AddRange(enumerable);and that enumerable came from one of these enlightened types, it’ll now benefit from the exact same use of vectorization previously discussed, as the List<T> will ensure its array is appropriately sized to handle the incoming data and will then hand its array off to the iterator’s ICollection<T>.CopyTo method to write into directly.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly List<byte> _list = new();
[Benchmark]
public void AddRange()
{
_list.Clear();
_list.AddRange(Enumerable.Repeat((byte)'a', 1024));
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| AddRange | .NET 7.0 | 6,826.89 ns | 1.000 |
| AddRange | .NET 8.0 | 20.30 ns | 0.003 |
Vectorization with LINQ was also improved in other ways. In .NET 7, Enumerable.Min and Enumerable.Max were taught how to vectorize the handling of some inputs (when the enumerable was actually an array or list of int or long values), and in .NET 8 dotnet/runtime#76144 expanded that to cover byte, sbyte, ushort, short, uint, ulong, nint, and nuint as well (it also switched the implementation from using Vector<T> to using both Vector128<T> and Vector256<T>, so that shorter inputs could still benefit from some level of vectorization).
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly byte[] _values = Enumerable.Range(0, 4096).Select(_ => (byte)Random.Shared.Next(0, 256)).ToArray();
[Benchmark]
public byte Max() => _values.Max();
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Max | .NET 7.0 | 16,496.96 ns | 1.000 |
| Max | .NET 8.0 | 53.77 ns | 0.003 |
Enumerable.Sum has now also been vectorized, for int and long, thanks to dotnet/runtime#84519 from @brantburnett. Sum in LINQ performs checked arithmetic, and normal Vector<T> operations are unchecked, which makes the vectorization of this method a bit more challenging. To achieve it, it takes advantage of a neat little bit hack trick for determining whether an addition of two signed twos-complement numbers underflow or overflow. The same logic applies for both int and long here, so we’ll focus just on int. It’s impossible for the addition of a negative int to overflow when added to a positive int, so the only way two summed values can underflow or overflow is if they have the same sign. Further, if any wrapping occurs, it can’t wrap back to the same sign; if you add two positives numbers together and it overflows, the result will be negative, and if you add two negative numbers together and it underflows, the result will be positive. Thus, a function like this can tell us whether the sum wrapped:
static int Sum(int a, int b, out bool overflow)
{
int sum = a + b;
overflow = (((sum ^ a) & (sum ^ b)) & int.MinValue) != 0;
return sum;
}We’re xor‘ing the result with each of the inputs, and and‘ing those together. That will produce a number who’s top-most bit is 1 if there was overflow/underflow, and otherwise 0, so we can then mask off all the other bits and compare to 0 to determine whether wrapping occurred. This is useful for vectorization, because we can easily do the same thing with vectors, summing the two vectors and reporting on whether any of the elemental sums overflowed:
static Vector128<int> Sum(Vector128<int> a, Vector128<int> b, out bool overflow)
{
Vector128<int> sum = a + b;
overflow = (((sum ^ a) & (sum ^ b)) & Vector128.Create(int.MinValue)) != Vector128<int>.Zero;
return sum;
}With that, Enumerable.Sum can be vectorized. For sure, it’s not as efficient as if we didn’t need to care about the checked; after all, for every addition operation, there’s at least an extra set of instructions for the two xors and the and‘ing of them (we can amortize the bit check across several operations by doing some loop unrolling). With 256-bit vectors, an ideal speedup for such a sum operation over int values would be 8x, since we can process eight 32-bit values at a time in a 256-bit vector. We’re then doing fairly well that we get a 4x speedup in that situation:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly IEnumerable<int> _values = Enumerable.Range(0, 1024).ToArray();
[Benchmark]
public int Sum() => _values.Sum();
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Sum | .NET 7.0 | 347.28 ns | 1.00 |
| Sum | .NET 8.0 | 78.26 ns | 0.23 |
LINQ has improved in .NET 8 beyond just vectorization; other operators have seen other kinds of optimization. Take Order/OrderDescending, for example. These LINQ operators implement a “stable sort”; that means that while sorting the data, if two items compare equally, they’ll end up in the final result in the same order they were in the original (an “unstable sort” doesn’t care about the ordering of two values that compare equally). The core sorting routine shared by spans, arrays, and lists in .NET (e.g. Array.Sort) provides an unstable sort, so to use that implementation and provide stable ordering guarantees, LINQ has to layer the stability on top, which it does by factoring into the comparison operation between keys the original location of the key in the input (e.g. if two values otherwise compare equally, then it proceeds to compare their original locations). That, however, means it needs to remember their original locations, which means it needs to allocate a separate int[] for positions. Interestingly, though, sometimes you can’t tell the difference between whether a sort is stable or unstable. dotnet/runtime#76733 takes advantage of the fact that for primitive types like int, two values that compare equally with the default comparer are indistinguishable, in which case it’s fine to use an unstable sort because the only values that can compare equally have identical bits and thus trying to maintain an order between them doesn’t matter. It thus enables avoiding all of the overhead associated with maintaining a stable sort.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private IEnumerable<int> _source;
[GlobalSetup]
public void Setup() => _source = Enumerable.Range(0, 1000).Reverse();
[Benchmark]
public int EnumerateOrdered()
{
int sum = 0;
foreach (int i in _source.Order())
{
sum += i;
}
return sum;
}
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| EnumerateOrdered | .NET 7.0 | 73.728 us | 1.00 | 8.09 KB | 1.00 |
| EnumerateOrdered | .NET 8.0 | 9.753 us | 0.13 | 4.02 KB | 0.50 |
dotnet/runtime#76418 also improves sorting in LINQ, this time for OrderBy/OrderByDescending, and in particular when the type of the key used (the type returned by the keySelector delegate provided to OrderBy) is a value type and the default comparer is used. This change employs the same approach that some of the .NET collections like Dictionary<TKey, TValue> already do, which is to take advantage of the fact that value types when used as generics get a custom copy of the code dedicated to that type (“generic specialization”), and that Comparer<TValueType>.Default.Compare will get devirtualized and possibly inlined. As such, it adds a dedicated path for when the key is a value type, and that enables the comparison operation (which is invoked O(n log n) times) to be sped up.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly int[] _values = Enumerable.Range(0, 1_000_000).Reverse().ToArray();
[Benchmark]
public int OrderByToArray()
{
int sum = 0;
foreach (int i in _values.OrderBy(i => i * 2)) sum += i;
return sum;
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| OrderByToArray | .NET 7.0 | 187.17 ms | 1.00 |
| OrderByToArray | .NET 8.0 | 67.54 ms | 0.36 |
Of course, sometimes the most efficient use of LINQ is simply not using it. It’s an amazing productivity tool, and it goes to great lengths to be efficient, but sometimes there are better answers that are just as simple. CA1860, added in dotnet/roslyn-analyzers#6236 from @CollinAlpert, flags one such case. It looks for use of Enumerable.Any on collections that directly expose a Count, Length, or IsEmpty property that could be used instead. While Any does use Enumerable.TryGetNonEnumeratedCount in an attempt to check the collection’s number of items without allocating or using an enumerator, even if it’s successful in doing so it incurs the overhead of the interface check and dispatch. It’s faster to just use the properties directly. dotnet/runtime#81583 fixed several cases of this.
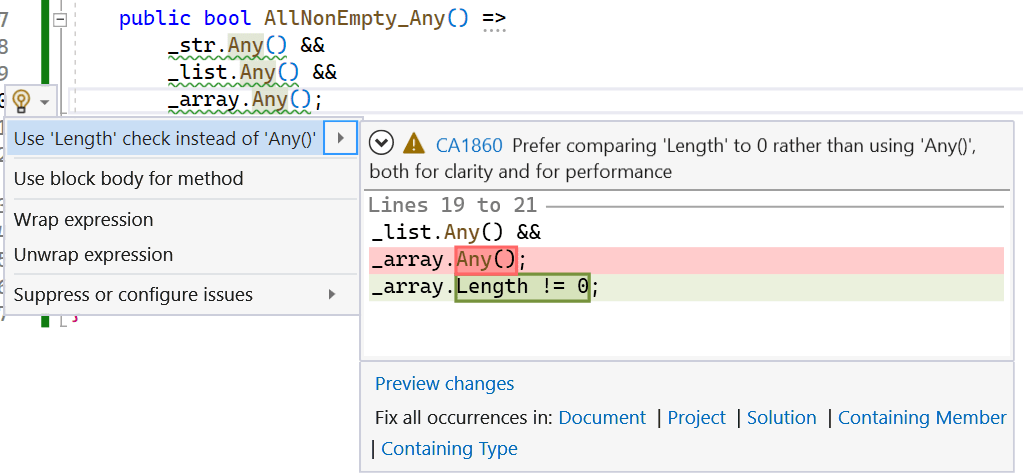
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly string _str = "hello";
private readonly List<int> _list = new() { 1, 2, 3 };
private readonly int[] _array = new int[] { 4, 5, 6 };
[Benchmark(Baseline = true)]
public bool AllNonEmpty_Any() =>
_str.Any() &&
_list.Any() &&
_array.Any();
[Benchmark]
public bool AllNonEmpty_Property() =>
_str.Length != 0 &&
_list.Count != 0 &&
_array.Length != 0;
}| Method | Mean | Ratio |
|---|---|---|
| AllNonEmpty_Any | 12.5302 ns | 1.00 |
| AllNonEmpty_Property | 0.3701 ns | 0.03 |
Dictionary
In addition to making existing methods faster, LINQ has also gained some new methods in .NET 8. dotnet/runtime#85811 from @lateapexearlyspeed added new overloads of ToDictionary. Unlike the existing overloads that are extensions on any arbitrary IEnumerable<TSource> and accept delegates for extracting from each TSource a TKey and/or TValue, these new overloads are extensions on IEnumerable<KeyValuePair<TKey, TValue>> and IEnumerable<(TKey, TValue)>. This is primarily an addition for convenience, as it means that such an enumerable that previously used code like:
return collection.ToDictionary(kvp => kvp.Key, kvp => kvp.Value);can instead be simplified to just be:
return collection.ToDictionary();Beyond being simpler, this has the nice benefit of also being cheaper, as it means the method doesn’t need to invoke two delegates per item. It also means that this new method is a simple passthrough to Dictionary<TKey, TValue>‘s constructor, which has its own optimizations that take advantage of knowing about Dictionary<TKey, TValue> internals, e.g. it can more efficiently copy the source data if it’s a Dictionary<TKey, TValue>.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly IEnumerable<KeyValuePair<string, int>> _source = Enumerable.Range(0, 1024).ToDictionary(i => i.ToString(), i => i);
[Benchmark(Baseline = true)]
public Dictionary<string, int> WithDelegates() => _source.ToDictionary(kvp => kvp.Key, kvp => kvp.Value);
[Benchmark]
public Dictionary<string, int> WithoutDelegates() => _source.ToDictionary();
}| Method | Mean | Ratio |
|---|---|---|
| WithDelegates | 21.208 us | 1.00 |
| WithoutDelegates | 8.652 us | 0.41 |
It also benefits from the Dictionary<TKey, TValue>‘s constructor being optimized in additional ways. As noted, its constructor accepting an IEnumerable<KeyValuePair<TKey, TValue>> already special-cased when the enumerable is actually a Dictionary<TKey, TValue>. With dotnet/runtime#86254, it now also special-cases when the enumerable is a KeyValuePair<TKey, TValue>[] or a List<KeyValuePair<TKey, TValue>>. When such a source is found, a span is extracted from it (a simple cast for an array, or via CollectionsMarshal.AsSpan for a List<>), and then that span (rather than the original IEnumerable<>) is what’s enumerated. That saves an enumerator allocation and several interface dispatches per item for these reasonably common cases.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly List<KeyValuePair<int, int>> _list = Enumerable.Range(0, 1000).Select(i => new KeyValuePair<int, int>(i, i)).ToList();
[Benchmark] public Dictionary<int, int> FromList() => new Dictionary<int, int>(_list);
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| FromList | .NET 7.0 | 12.250 us | 1.00 |
| FromList | .NET 8.0 | 6.780 us | 0.55 |
The most common operation performed on a dictionary is looking up a key, whether to see if it exists, to add a value, or to get the current value. Previous .NET releases have seen significant improvements in this lookup time, but even better than optimizing a lookup is not needing to do one at all. One common place we’ve seen unnecessary lookups is with guard clauses that end up being unnecessary, for example code that does:
if (!dictionary.ContainsKey(key))
{
dictionary.Add(key, value);
}This incurs two lookups, one as part of ContainsKey, and then if the key wasn’t in the dictionary, another as part of the Add call. Code can instead achieve the same operation with:
dictionary.TryAdd(key, value);which incurs only one lookup. CA1864, added in dotnet/roslyn-analyzers#6199 from @CollinAlpert, looks for such places where an Add call is guarded by a ContainsKey call. dotnet/runtime#88700 fixed a few occurrences of this in dotnet/runtime.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly Dictionary<string, string> _dict = new();
[Benchmark(Baseline = true)]
public void ContainsThenAdd()
{
_dict.Clear();
if (!_dict.ContainsKey("key"))
{
_dict.Add("key", "value");
}
}
[Benchmark]
public void TryAdd()
{
_dict.Clear();
_dict.TryAdd("key", "value");
}
}| Method | Mean | Ratio |
|---|---|---|
| ContainsThenAdd | 25.93 ns | 1.00 |
| TryAdd | 19.50 ns | 0.75 |
Similarly, dotnet/roslyn-analyzers#6767 from @mpidash added CA1868, which looks for Add or Remove calls on ISet<T>s where the call is guarded by a Contains, and recommends removing the Contains call. dotnet/runtime#89652 from @mpidash fixes occurrences of this in dotnet/runtime.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly HashSet<string> _set = new();
[Benchmark(Baseline = true)]
public bool ContainsThenAdd()
{
_set.Clear();
if (!_set.Contains("key"))
{
_set.Add("key");
return true;
}
return false;
}
[Benchmark]
public bool Add()
{
_set.Clear();
return _set.Add("key");
}
}| Method | Mean | Ratio |
|---|---|---|
| ContainsThenAdd | 22.98 ns | 1.00 |
| Add | 17.99 ns | 0.78 |
Other related analyzers previously released have also been improved. dotnet/roslyn-analyzers#6387 improved CA1854 to find more opportunities for using IDictionary<TKey, TValue>.TryGetValue, with dotnet/runtime#85613 and dotnet/runtime#80996 using the analyzer to find and fix more occurrences.
Other dictionaries have also improved in .NET 8. ConcurrentDictionary<TKey, TValue> in particular got a nice boost from dotnet/runtime#81557, for all key types but especially for the very common case where TKey is string and the equality comparer is either the default comparer (whether that be null, EqualityComparer<TKey>.Default, or StringComparer.Ordinal, all of which behave identically) or StringComparer.OrdinalIgnoreCase. In .NET Core, string hash codes are randomized, meaning there’s a random seed value unique to any given process that’s incorporated into string hash codes. So if, for example, I run the following program:
// dotnet run -f net8.0
string s = "Hello, world!";
Console.WriteLine(s.GetHashCode());
Console.WriteLine(s.GetHashCode());
Console.WriteLine(s.GetHashCode());I get the following output, showing that the hash code for a given string is stable across multiple GetHashCode calls:
1442385232
1442385232
1442385232but when I run the program again, I get a different stable value:
740992523
740992523
740992523This randomization is done to help mitigate a class of denial-of-service (DoS) attacks involving dictionaries, where an attacker might be able to trigger the worst-case algorithmic complexity of a dictionary by forcing lots of collisions amongst the keys. However, the randomization also incurs some amount of overhead. It’s enough overhead so that Dictionary<TKey, TValue> actually special-cases string keys with a default or OrdinalIgnoreCase comparer to skip the randomization until a sufficient number of collisions has been detected. Now in .NET 8, ConcurrentDictionary<string, TValue> employs the same trick. When it starts life, a ConcurrentDictionary<string, TValue> instance using a default or OrdinalIgnoreCase comparer performs hashing using a non-randomized comparer. Then as it’s adding an item and traversing its internal data structure, it keeps track of how many keys it has to examine that had the same hash code. If that count surpasses a threshold, it then switches back to using a randomized comparer, rehashing the whole dictionary in order to mitigate possible attacks.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Collections.Concurrent;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private KeyValuePair<string, string>[] _pairs;
private ConcurrentDictionary<string, string> _cd;
[GlobalSetup]
public void Setup()
{
_pairs =
// from https://github.com/dotnet/runtime/blob/a30de6d40f69ef612b514344a5ec83fffd10b957/src/libraries/System.Formats.Asn1/src/System/Formats/Asn1/WellKnownOids.cs#L317-L419
new[]
{
"1.2.840.10040.4.1", "1.2.840.10040.4.3", "1.2.840.10045.2.1", "1.2.840.10045.1.1", "1.2.840.10045.1.2", "1.2.840.10045.3.1.7", "1.2.840.10045.4.1", "1.2.840.10045.4.3.2", "1.2.840.10045.4.3.3", "1.2.840.10045.4.3.4",
"1.2.840.113549.1.1.1", "1.2.840.113549.1.1.5", "1.2.840.113549.1.1.7", "1.2.840.113549.1.1.8", "1.2.840.113549.1.1.9", "1.2.840.113549.1.1.10", "1.2.840.113549.1.1.11", "1.2.840.113549.1.1.12", "1.2.840.113549.1.1.13",
"1.2.840.113549.1.5.3", "1.2.840.113549.1.5.10", "1.2.840.113549.1.5.11", "1.2.840.113549.1.5.12", "1.2.840.113549.1.5.13", "1.2.840.113549.1.7.1", "1.2.840.113549.1.7.2", "1.2.840.113549.1.7.3", "1.2.840.113549.1.7.6",
"1.2.840.113549.1.9.1", "1.2.840.113549.1.9.3", "1.2.840.113549.1.9.4", "1.2.840.113549.1.9.5", "1.2.840.113549.1.9.6", "1.2.840.113549.1.9.7", "1.2.840.113549.1.9.14", "1.2.840.113549.1.9.15", "1.2.840.113549.1.9.16.1.4",
"1.2.840.113549.1.9.16.2.12", "1.2.840.113549.1.9.16.2.14", "1.2.840.113549.1.9.16.2.47", "1.2.840.113549.1.9.20", "1.2.840.113549.1.9.21", "1.2.840.113549.1.9.22.1", "1.2.840.113549.1.12.1.3", "1.2.840.113549.1.12.1.5",
"1.2.840.113549.1.12.1.6", "1.2.840.113549.1.12.10.1.1", "1.2.840.113549.1.12.10.1.2", "1.2.840.113549.1.12.10.1.3", "1.2.840.113549.1.12.10.1.5", "1.2.840.113549.1.12.10.1.6", "1.2.840.113549.2.5", "1.2.840.113549.2.7",
"1.2.840.113549.2.9", "1.2.840.113549.2.10", "1.2.840.113549.2.11", "1.2.840.113549.3.2", "1.2.840.113549.3.7", "1.3.6.1.4.1.311.17.1", "1.3.6.1.4.1.311.17.3.20", "1.3.6.1.4.1.311.20.2.3", "1.3.6.1.4.1.311.88.2.1",
"1.3.6.1.4.1.311.88.2.2", "1.3.6.1.5.5.7.3.1", "1.3.6.1.5.5.7.3.2", "1.3.6.1.5.5.7.3.3", "1.3.6.1.5.5.7.3.4", "1.3.6.1.5.5.7.3.8", "1.3.6.1.5.5.7.3.9", "1.3.6.1.5.5.7.6.2", "1.3.6.1.5.5.7.48.1", "1.3.6.1.5.5.7.48.1.2",
"1.3.6.1.5.5.7.48.2", "1.3.14.3.2.26", "1.3.14.3.2.7", "1.3.132.0.34", "1.3.132.0.35", "2.5.4.3", "2.5.4.5", "2.5.4.6", "2.5.4.7", "2.5.4.8", "2.5.4.10", "2.5.4.11", "2.5.4.97", "2.5.29.14", "2.5.29.15", "2.5.29.17", "2.5.29.19",
"2.5.29.20", "2.5.29.35", "2.16.840.1.101.3.4.1.2", "2.16.840.1.101.3.4.1.22", "2.16.840.1.101.3.4.1.42", "2.16.840.1.101.3.4.2.1", "2.16.840.1.101.3.4.2.2", "2.16.840.1.101.3.4.2.3", "2.23.140.1.2.1", "2.23.140.1.2.2",
}.Select(s => new KeyValuePair<string, string>(s, s)).ToArray();
_cd = new ConcurrentDictionary<string, string>(_pairs, StringComparer.OrdinalIgnoreCase);
}
[Benchmark]
public int TryGetValue()
{
int count = 0;
foreach (KeyValuePair<string, string> pair in _pairs)
{
if (_cd.TryGetValue(pair.Key, out _))
{
count++;
}
}
return count;
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| TryGetValue | .NET 7.0 | 2.917 us | 1.00 |
| TryGetValue | .NET 8.0 | 1.462 us | 0.50 |
The above benchmark also benefited from dotnet/runtime#77005, which tweaked another long-standing optimization in the type. ConcurrentDictionary<TKey, TValue> maintains a Node object for every key/value pair it stores. As multiple threads might be reading from the dictionary concurrent with updates happening, the dictionary needs to be really careful about how it mutates data stored in the collection. If an update is performed that needs to update a TValue in an existing node (e.g. cd[existingKey] = newValue), the dictionary needs to be very careful to avoid torn reads, such that one thread could be reading the value while another thread is writing the value, leading to the reader seeing part of the old value and part of the new value. It does this by only reusing that same Node for an update if it can write the TValue atomically. It can write it atomically if the TValue is a reference type, in which case it’s simply writing a pointer-sized reference, or if the TValue is a primitive value that’s defined by the platform to always be written atomically when written with appropriate alignment, e.g. int, or long when in a 64-bit process. To make this check efficient, ConcurrentDictionary<TKey, TValue> computes once whether a given TValue is writable atomically, storing it into a static readonly field, such that in tier 1 compilation, the JIT can treat the value as a const. However, this const trick doesn’t always work. The field was on ConcurrentDictionary<TKey, TValue> itself, and if one of those generic type parameters ended up being a reference type (e.g. ConcurrentDictionary<object, int>), accessing the static readonly field would require a generic lookup (the JIT isn’t currently able to see that the value stored in the field is only dependent on the TValue and not on the TKey). To fix this, the field was moved to a separate type where TValue is the only generic parameter, and a check for typeof(TValue).IsValueType (which is itself a JIT intrinsic that manifests as a const) is done separately.
ConcurrentDictionary<TKey, TValue>‘s TryRemove was also improved this release, via dotnet/runtime#82004. Mutation of a ConcurrentDictionary<TKey, TValue> requires taking a lock. However, in the case of TryRemove, we only actually need the lock if it’s possible the item being removed is contained. If the number of items protected by the given lock is 0, we know TryRemove will be a nop. Thus, this PR added a fast path to TryRemove that read the count for that lock and immediately bailed if it was 0.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Collections.Concurrent;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly ConcurrentDictionary<int, int> _empty = new();
[Benchmark]
public bool TryRemoveEmpty() => _empty.TryRemove(default, out _);
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| TryRemoveEmpty | .NET 7.0 | 26.963 ns | 1.00 |
| TryRemoveEmpty | .NET 8.0 | 5.853 ns | 0.22 |
Another dictionary that’s been improved in .NET 8 is ConditionalWeakTable<TKey, TValue>. As background if you haven’t used this type before, ConditionalWeakTable<TKey, TValue> is a very specialized dictionary based on DependentHandle; think of it as every key being a weak reference (so if the GC runs, the key in the dictionary won’t be counted as a strong root that would keep the object alive), and that if the key is collected, the whole entry is removed from the table. It’s particularly useful in situations where additional data needs to be associated with an object but where for whatever reason you’re unable to modify that object to have a reference to the additional data. dotnet/runtime#80059 improves the performance of lookups on a ConditionalWeakTable<TKey, TValue>, in particular for objects that aren’t in the collection, and even more specifically for an object that’s never been in any dictionary. Since ConditionalWeakTable<TKey, TValue> is about object references, unlike other dictionaries in .NET, it doesn’t use the default EqualityComparer<TKey>.Default to determine whether an object is in the collection; it just uses object reference equality. And that means to get a hash code for an object, it uses the same functionality that the base object.GetHashCode does. It can’t just call GetHashCode, as the method could have been overridden, so instead it directly calls to the same public RuntimeHelpers.GetHashCode that object.GetHashCode uses:
public class Object
{
public virtual int GetHashCode() => RuntimeHelpers.GetHashCode(this);
...
}This PR tweaks what ConditionalWeakTable<,> does here. It introduces a new internal RuntimeHelpers.TryGetHashCode that will avoid creating and storing a hash code for the object if the object doesn’t already have one. It then uses that method from ConditionalWeakTable<TKey, TValue> as part of TryGetValue (and Remove, and other related APIs). If TryGetHashCode returns a value indicating the object doesn’t yet have one, then the operation can early-exit, because for the object to have been stored into the collection, it must have had a hash code generated for it.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Runtime.CompilerServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private ConditionalWeakTable<SomeObject, Data> _cwt;
private List<object> _rooted;
private readonly SomeObject _key = new();
[GlobalSetup]
public void Setup()
{
_cwt = new();
_rooted = new();
for (int i = 0; i < 1000; i++)
{
SomeObject key = new();
_rooted.Add(key);
_cwt.Add(key, new());
}
}
[Benchmark]
public int GetValue() => _cwt.TryGetValue(_key, out Data d) ? d.Value : 0;
private sealed class SomeObject { }
private sealed class Data
{
public int Value;
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| GetValue | .NET 7.0 | 4.533 ns | 1.00 |
| GetValue | .NET 8.0 | 3.028 ns | 0.67 |
So, improvements to Dictionary<TKey, TValue>, ConcurrentDictionary<TKey, TValue>, ConditionalWeakTable<TKey, TValue>… are those the “end all be all” of hash table world? Don’t be silly…
Frozen Collections
There are many specialized libraries available on NuGet, providing all manner of data structures with this or that optimization or targeted at this or that scenario. Our goal with the core .NET libraries has never been to provide all possible data structures (it’s actually been a goal not to), but rather to provide the most commonly needed data structures focused on the most commonly needed scenarios, and rely on the ecosystem to provide alternatives where something else is deemed valuable. As a result, we don’t add new collection types all that frequently; we continually optimize the ones that are there and we routinely augment them with additional functionality, but we rarely introduce brand new collection types. In fact, in the last several years, the only new general-purpose collection type introduced into the core libraries was PriorityQueue<TElement, TPriority> class, which was added in .NET 6. However, enough of a need has presented itself that .NET 8 sees the introduction of not one but two new collection types: System.Collections.Frozen.FrozenDictionary<TKey, TValue> and System.Collections.Frozen.FrozenSet<TKey, TValue>.
Beyond causing “Let It Go” to be stuck in your head for the rest of the day (“you’re welcome”), what benefit do these new types provide, especially when we already have System.Collections.Immutable.ImmutableDictionary<TKey, TValue> and System.Collections.Immutable.ImmutableSet<T>? There are enough similarities between the existing immutable collections and the new frozen collections that the latter are actually included in the System.Collections.Immutable library, which means they’re also available as part of the System.Collections.Immutable NuGet package. But there are also enough differences to warrant us adding them. In particular, this is an example of where scenario and intended use make a big impact on whether a particular data structure makes sense for your needs.
Arguably, the existing System.Collections.Immutable collections were misnamed. Yes, they’re “immutable,” meaning that once you’ve constructed an instance of one of the collection types, you can’t change its contents. However, that could have easily been achieved simply by wrapping an immutable facade around one of the existing mutable ones, e.g. an immutable dictionary type that just copied the data into a mutable Dictionary<TKey, TValue> and exposed only reading operations:
public sealed class MyImmutableDictionary<TKey, TValue> :
IReadOnlyDictionary<TKey, TValue>
where TKey : notnull
{
private readonly Dictionary<TKey, TValue> _data;
public MyImmutableDictionary(IEnumerable<KeyValuePair<TKey, TValue>> source) => _data = source.ToDictionary();
public bool TryGetValue(TKey key, [MaybeNullWhen(false)] out TValue value) => _data.TryGetValue(key, out value);
...
}Yet, if you look at the implementation of ImmutableDictionary<TKey, TValue>, you’ll see a ton of code involved in making the type tick. Why? Because it and its friends are optimized for something very different. In academic nomenclature, the immutable collections are actually “persistent” collections. A persistent data structure is one that provides mutating operations on the collection (e.g. Add, Remove, etc.) but where those operations don’t actually change the existing instance, instead resulting in a new instance being created that contains that modification. So, for example, ImmutableDictionary<TKey, TValue> ironically exposes an Add(TKey key, TValue value) method, but this method doesn’t actually modify the collection instance on which it’s called; instead, it creates and returns a brand new ImmutableDictionary<TKey, TValue> instance, containing all of the key/value pairs from the original instance as well as the new key/value pair being added. Now, you could imagine that being done simply by copying all of the data to a new Dictionary<TKey, TValue> and adding in the new value, e.g.
public sealed class MyPersistentDictionary<TKey, TValue> where TKey : notnull
{
private readonly Dictionary<TKey, TValue> _data;
public MyPersistentDictionary<TKey, TValue> Add(TKey key, TValue value)
{
var newDictionary = new Dictionary<TKey, TValue>(_data);
newDictionary.Add(key, value);
return newDictionary;
}
...
}but while functional, that’s terribly inefficient from a memory consumption perspective, as every addition results in a brand new copy of all of the data being made, just to store that one additional pair in the new instance. It’s also terribly inefficient from an algorithmic complexity perspective, as adding N values would end up being an O(n^2) algorithm (each new item would result in copying all previous items). As such, ImmutableDictionary<TKey, TValue> is optimized to share as much as possible between instances. Its implementation uses an AVL tree, a self-balancing binary search tree. Adding into such a tree not only requires O(log n) time (whereas the full copy shown in MyPersistentDictionary<TKey, TValue> above is O(n)), it also enables reusing entire portions of a tree between instances of dictionaries. If adding a key/value pair doesn’t require mutating a particular subtree, then both the new and old dictionary instances can point to that same subtree, thereby avoiding significant memory increase. You can see this from a benchmark like the following:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Collections.Immutable;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private const int Items = 10_000;
[Benchmark(Baseline = true)]
public Dictionary<int, int> DictionaryAdds()
{
Dictionary<int, int> d = new();
for (int i = 0; i < Items; i++)
{
var newD = new Dictionary<int, int>(d);
newD.Add(i, i);
d = newD;
}
return d;
}
[Benchmark]
public ImmutableDictionary<int, int> ImmutableDictionaryAdds()
{
ImmutableDictionary<int, int> d = ImmutableDictionary<int, int>.Empty;
for (int i = 0; i < Items; i++)
{
d = d.Add(i, i);
}
return d;
}
}which when run on .NET 8 yields the following results for me:
| Method | Mean | Ratio |
|---|---|---|
| DictionaryAdds | 478.961 ms | 1.000 |
| ImmutableDictionaryAdds | 4.067 ms | 0.009 |
That highlights that the tree-based nature of ImmutableDictionary<TKey, TValue> makes it significantly more efficient (~120x better in both throughput and allocation in this run) for this example of performing lots of additions, when compared with using for the same purpose a Dictionary<TKey, TValue> treated as being immutable. And that’s why these immutable collections came into being in the first place. The C# compiler uses lots and lots of dictionaries and sets and the like, and it employs a lot of concurrency. It needs to enable one thread to “tear off” an immutable view of a collection even while other threads are updating the collection, and for such purposes it uses System.Collections.Immutable.
However, just because the above numbers look amazing doesn’t mean ImmutableDictionary<TKey, TValue> is always the right tool for the immutable job… it actually rarely is. Why? Because the exact thing that made it so fast and memory efficient for the above benchmark is also its downfall on one of the most common tasks needed for an “immutable” dictionary: reading. With its tree-based data structure, not only are adds O(log n), but lookups are also O(log n), which for a large dictionary can be extremely inefficient when compared to the O(1) access times of a type like Dictionary<TKey, TValue>. We can see this as well with a simple benchmark. Let’s say we’ve built up our 10,000-element dictionary as in the previous example, and now we want to query it:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Collections.Immutable;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private const int Items = 1_000_000;
private static readonly Dictionary<int, int> s_d = new Dictionary<int, int>(Enumerable.Range(0, Items).ToDictionary(x => x, x => x));
private static readonly ImmutableDictionary<int, int> s_id = ImmutableDictionary.CreateRange(Enumerable.Range(0, Items).ToDictionary(x => x, x => x));
[Benchmark]
public int EnumerateDictionary()
{
int sum = 0;
foreach (var pair in s_d) sum++;
return sum;
}
[Benchmark]
public int EnumerateImmutableDictionary()
{
int sum = 0;
foreach (var pair in s_id) sum++;
return sum;
}
[Benchmark]
public int IndexerDictionary()
{
int sum = 0;
for (int i = 0; i < Items; i++)
{
sum += s_d[i];
}
return sum;
}
[Benchmark]
public int IndexerImmutableDictionary()
{
int sum = 0;
for (int i = 0; i < Items; i++)
{
sum += s_id[i];
}
return sum;
}
}| Method | Mean |
|---|---|
| EnumerateImmutableDictionary | 28.065 ms |
| EnumerateDictionary | 1.404 ms |
| IndexerImmutableDictionary | 46.538 ms |
| IndexerDictionary | 3.780 ms |
Uh oh. Our ImmutableDictionary<TKey, TValue> in this example is ~12x as expensive for lookups and ~20x as expensive for enumeration as Dictionary<TKey, TValue>. If your process will be spending most of its time performing reads on the dictionary rather than creating it and/or performing mutation, that’s a lot of cycles being left on the table.
And that’s where frozen collections come in. The collections in System.Collections.Frozen are immutable, just as are those in System.Collections.Immutable, but they’re optimized for a different scenario. Whereas the purpose of a type like ImmutableDictionary<TKey, TValue> is to enable efficient mutation (into a new instance), the purpose of FrozenDictionary<TKey, TValue> is to represent data that never changes, and thus it doesn’t expose any operations that suggest mutation, only operations for reading. Maybe you’re loading some configuration data into a dictionary once when your process starts (and then re-loading it only rarely when the configuration changes) and then querying that data over and over and over again. Maybe you’re creating a mapping from HTTP status codes to delegates representing how those status codes should be handled. Maybe you’re caching schema information about a set of dynamically-discovered types and then using the resulting parsed information every time you encounter those types later on. Whatever the scenario, you’re creating an immutable collection that you want to be optimized for reads, and you’re willing to spend some more cycles creating the collection (because you do it only once, or only once in a while) in order to make reads as fast as possible. That’s exactly what FrozenDictionary<TKey, TValue> and FrozenSet<T> provide.
Let’s update our previous example to now also include FrozenDictionary<TKey, TValue>:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Collections.Frozen;
using System.Collections.Immutable;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private const int Items = 10_000;
private static readonly Dictionary<int, int> s_d = new Dictionary<int, int>(Enumerable.Range(0, Items).ToDictionary(x => x, x => x));
private static readonly ImmutableDictionary<int, int> s_id = ImmutableDictionary.CreateRange(Enumerable.Range(0, Items).ToDictionary(x => x, x => x));
private static readonly FrozenDictionary<int, int> s_fd = FrozenDictionary.ToFrozenDictionary(Enumerable.Range(0, Items).ToDictionary(x => x, x => x));
[Benchmark]
public int DictionaryGets()
{
int sum = 0;
for (int i = 0; i < Items; i++)
{
sum += s_d[i];
}
return sum;
}
[Benchmark]
public int ImmutableDictionaryGets()
{
int sum = 0;
for (int i = 0; i < Items; i++)
{
sum += s_id[i];
}
return sum;
}
[Benchmark(Baseline = true)]
public int FrozenDictionaryGets()
{
int sum = 0;
for (int i = 0; i < Items; i++)
{
sum += s_fd[i];
}
return sum;
}
}| Method | Mean | Ratio |
|---|---|---|
| ImmutableDictionaryGets | 360.55 us | 13.89 |
| DictionaryGets | 39.43 us | 1.52 |
| FrozenDictionaryGets | 25.95 us | 1.00 |
Now we’re talkin’. Whereas for this lookup test Dictionary<TKey, TValue> was ~9x faster than ImmutableDictionary<TKey, TValue>, FrozenDictionary<TKey, TValue> was 50% faster than even Dictionary<TKey, TValue>.
How does that improvement happen? Just as ImmutableDictionary<TKey, TValue> doesn’t just wrap a Dictionary<TKey, TValue>, FrozenDictionary<TKey, TValue> doesn’t just wrap one, either. It has a customized implementation focused on making read operations as fast as possible, both for lookups and for enumerations. In fact, it doesn’t have just one implementation; it has many implementations.
To start to see that, let’s change the example. In the United States, the Social Security Administration tracks the popularity of baby names. In 2022, the most popular baby names for girls were Olivia, Emma, Charlotte, Amelia, Sophia, Isabella, Ava, Mia, Evelyn, and Luna. Here’s a benchmark that checks to see whether a name is one of those:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Collections.Frozen;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private static readonly HashSet<string> s_s = new(StringComparer.OrdinalIgnoreCase)
{
"Olivia", "Emma", "Charlotte", "Amelia", "Sophia", "Isabella", "Ava", "Mia", "Evelyn", "Luna"
};
private static readonly FrozenSet<string> s_fs = s_s.ToFrozenSet(StringComparer.OrdinalIgnoreCase);
[Benchmark(Baseline = true)]
public bool HashSet_IsMostPopular() => s_s.Contains("Alexandria");
[Benchmark]
public bool FrozenSet_IsMostPopular() => s_fs.Contains("Alexandria");
}| Method | Mean | Ratio |
|---|---|---|
| HashSet_IsMostPopular | 9.824 ns | 1.00 |
| FrozenSet_IsMostPopular | 1.518 ns | 0.15 |
Significantly faster. Internally, ToFrozenSet can pick an implementation based on the data supplied, both the type of the data and the exact values being used. In this case, if we print out the type of s_fs, we see:
System.Collections.Frozen.LengthBucketsFrozenSetThat’s an implementation detail, but what we’re seeing here is that the s_fs, even though it’s strongly-typed as FrozenSet<string>, is actually a derived type named LengthBucketsFrozenSet. ToFrozenSet has analyzed the data supplied to it and chosen a strategy that it thinks will yield the best overall throughput. Part of that is just seeing that the type of the data is string, in which case all the string-based strategies are able to quickly discard queries that can’t possibly match. In this example, the set will have tracked that the longest string in the collection is “Charlotte” at only nine characters long; as such, when it’s asked whether the set contains “Alexandria”, it can immediately answer “no,” because it does a quick length check and sees that “Alexandria” at 10 characters can’t possibly be contained.
Let’s take another example. Internal to the C# compiler, it has the notion of “special types,” and it has a dictionary that maps from a string-based type name to an enum used to identify that special-type. As a simplified representation of this, I’ve just extracted those strings to create a set:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Collections.Frozen;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private static readonly HashSet<string> s_s = new()
{
"System.Object", "System.Enum", "System.MulticastDelegate", "System.Delegate", "System.ValueType", "System.Void",
"System.Boolean", "System.Char", "System.SByte", "System.Byte", "System.Int16", "System.UInt16", "System.Int32",
"System.UInt32", "System.Int64","System.UInt64", "System.Decimal", "System.Single", "System.Double", "System.String",
"System.IntPtr", "System.UIntPtr", "System.Array", "System.Collections.IEnumerable", "System.Collections.Generic.IEnumerable`1",
"System.Collections.Generic.IList`1", "System.Collections.Generic.ICollection`1", "System.Collections.IEnumerator",
"System.Collections.Generic.IEnumerator`1", "System.Collections.Generic.IReadOnlyList`1", "System.Collections.Generic.IReadOnlyCollection`1",
"System.Nullable`1", "System.DateTime", "System.Runtime.CompilerServices.IsVolatile", "System.IDisposable", "System.TypedReference",
"System.ArgIterator", "System.RuntimeArgumentHandle", "System.RuntimeFieldHandle", "System.RuntimeMethodHandle", "System.RuntimeTypeHandle",
"System.IAsyncResult", "System.AsyncCallback", "System.Runtime.CompilerServices.RuntimeFeature", "System.Runtime.CompilerServices.PreserveBaseOverridesAttribute",
};
private static readonly FrozenSet<string> s_fs = s_s.ToFrozenSet();
[Benchmark(Baseline = true)]
public bool HashSet_IsSpecial() => s_s.Contains("System.Collections.Generic.IEnumerable`1");
[Benchmark]
public bool FrozenSet_IsSpecial() => s_fs.Contains("System.Collections.Generic.IEnumerable`1");
}| Method | Mean | Ratio |
|---|---|---|
| HashSet_IsSpecial | 15.228 ns | 1.00 |
| FrozenSet_IsSpecial | 8.218 ns | 0.54 |
Here the item we’re searching for is in the collection, so it’s not getting its performance boost from a fast path to fail out of the search. The concrete type of s_fs in this case sheds some light on it:
System.Collections.Frozen.OrdinalStringFrozenSet_RightJustifiedSubstringOne of the biggest costs involved in looking up something in a hash table is often the cost of producing the hash in the first place. For a type like int, it’s trivial, as it’s literally just its value. But for a type like string, the hash is produced by looking at the string’s contents and factoring each character into the resulting value. The more characters need to be considered, the more it costs. In this case, the type has identified that in order to differentiate all of the items in the collection, only a subset of them needs to be hashed, such that it only needs to examine a subset of the incoming string to determine what a possible match might be in the collection.
A bunch of PRs went into making System.Collections.Frozen happen in .NET 8. It started as an internal project used by several services at Microsoft, and was then cleaned up and added as part of dotnet/runtime#77799. That provided the core types and initial strategy implementations, with dotnet/runtime#79794 following it to provide additional strategies (although we subsequently backed out a few due to lack of motivating scenarios for what their optimizations were targeting).
dotnet/runtime#81021 then removed some virtual dispatch from the string-based implementations. As noted in the previous example, one approach the strategies take is to try to hash less, so there’s a phase of analysis where the implementation looks at the various substrings in each of the items and determines whether there’s an offset and length for substring that across all of the items provides an ideal differentiation. For example, consider the strings “12a34”, “12b34”, “12c34”; the analyzer would determine that there’s no need to hash the whole string, it need only consider the character at index 2, as that’s enough to uniquely hash the relevant strings. This was initially achieved by using a custom comparer type, but that then meant that virtual dispatch was needed in order to invoke the hashing routine. Instead, this PR created more concrete derived types from FrozenSet/FrozenDictionary, such that the choice of hashing logic was dictated by the choice of concrete collection type to instantiate, saving on the per-operation dispatch.
In any good story, there’s a twist, and we encountered a twist with these frozen collection types as well. I’ve already described the scenarios that drove the creation of these types: create once, use a lot. And as such, a lot of attention was paid to overheads involved in reading from the collection, but initially very little time was paid to optimizing construction time. In fact, improving construction time was initially a non-goal, with a willingness to spend as much time as was needed to eke out more throughput for reading. This makes sense if you’re focusing on long-lived services, where you’re happy to spend extra seconds once an hour or day or week to optimize something that will then be used many thousands of times per second. However, the equation changes a bit when types like this are exposed in the core libraries, such that the expected number of developers using them, the use cases they have for them, and the variations of data thrown at them grows by orders of magnitude. We started hearing from developers that they were excited to use FrozenDictionary/FrozenSet not just because of performance but also because they were truly immutable, both in implementation and in surface area (e.g. no Add method to confuse things), and that they’d be interested in employing them in object models, UIs, and so on. At that point, you’re no longer in the world of “we can take as much time for construction as we want,” and instead need to be concerned about construction taking inordinate amounts of time and resources.
As a stop-gap measure, dotnet/runtime#81194 changed the existing ToFrozenDictionary/ToFrozenSet methods to not do any analysis of the incoming data, and instead have both construction time and read throughput in line with that of Dictionary/HashSet. It then added new overloads with a bool optimizeForReading argument, to enable developers to opt-in to those longer construction times in exchange for better read throughput. This wasn’t an ideal solution, as it meant that it took more discovery and more code for a developer to achieve the primary purpose of these types, but it also helped developers avoid pits of failure by using what looked like a harmless method but could result in significant increases in processing time (one degenerate example I created resulted in ToFrozenDictionary running literally for minutes).
We then set about to improve the overall performance of the collections, with a bunch of PRs geared towards driving down the costs:
- dotnet/runtime#81389 removed various allocations and a dependency from some of the optimizations on the generic math interfaces from .NET 7, such that the optimizations would apply downlevel as well, simplifying the code.
- dotnet/runtime#81603 moved some code around to reduce how much code was in a generic context. With Native AOT, with type parameters involving value types, every unique set of type parameters used with these collections results in a unique copy of the code being made, and with all of the various strategies around just in case they’re necessary to optimize a given set, there’s potentially a lot of code that gets duplicated. This change was able to shave ~10Kb off each generic instantiation.
- dotnet/runtime#86293 made a large number of tweaks, including limiting the maximum length substring that would be evaluated as part of determining the optimal hashing length to employ. This significantly reduced the worst-case running time when supplying problematic inputs.
- dotnet/runtime#84301 added similar early-exit optimizations as were seen earlier with string, but for a host of other types, including all the primitives,
TimeSpan,Guid, and such. For these types, when no comparer is provided, we can sort the inputs, quickly check whether a supplied input is greater than anything known to be in the collection, and when dealing with a small number of elements such that we don’t hash at all and instead just do a linear search, we can stop searching once we’ve reached an item in the collection that’s larger than the one being tested (e.g. if the first item in the sorted list is larger than the one being tested, nothing will match). It’s interesting why we don’t just do this for anIComparable<T>; we did, initially, actually, but removed it because of several prominentIComparable<T>implementations that didn’t work for this purpose.ValueTuple<...>, for example, implementsIComparable<ValueTuple<...>>, but theT1,T2, etc. types theValueTuple<...>wraps may not, and the frozen collections didn’t have a good way to determine the viability of anIComparable<T>implementation. Instead, this PR added the optimization back with an allow list, such that all the relevant known good types that could be referenced were special-cased. - dotnet/runtime#87510 was the first in a series of PRs to focus significantly on driving down the cost of construction. Its main contribution in this regard was in how collisions are handled. One of the main optimizations employed in the general case by
ToFrozenDictionary/ToFrozenSetis to try to drive down the number of collisions in the hash table, since the more collisions there are, the more work will need to be performed during lookups. It does this by populating the table and tracking the number of collisions, and then if there were too many, increasing the size of the table and trying again, repeatedly, until the table has grown large enough that collisions are no longer an issue. This process would hash everything, and then check to make sure it was as good as was desired. This PR changed that to instead bail the moment we knew there were enough collisions that we’d need to retry, rather than waiting until having processed everything. - dotnet/runtime#87630, dotnet/runtime#87688, and dotnet/runtime#88093 in particular improve collections keyed by
ints, by avoiding unnecessary work. For example, as part of determining the ideal table size (to minimize collisions), the implementation generates a set of all unique hash codes, eliminating duplicate hash codes because they’d always collide regardless of the size of the table. But withints, we can skip this step, becauseints are their own hash codes, and so a set of uniqueints is guaranteed to be a set of unique hash codes as well. This was then extended to also apply foruint,short/ushort,byte/sbyte, andnint/nuint(in 32-bit processes), as they all similarly use their own value as the hash code. - dotnet/runtime#87876 and dotnet/runtime#87989 improve the “LengthBucket” strategy referenced in the earlier examples. This implementation buckets strings by their length and then does a lookup just within the strings of that length; if there are only a few strings per length, this can make searching very efficient. The initial implementation used an array of arrays, and this PR flattens that into a single array. This makes construction time much faster for this strategy, as there’s significantly less allocation involved.
- dotnet/runtime#87960 is based on an observation that we would invariably need to resize at least once in order to obtain the desired minimal collision rate, so it simply starts at a higher initial count than was previously being used.
With all of those optimizations in place, construction time has now improved to the point where it’s no longer a threat, and dotnet/runtime#87988 effectively reverted dotnet/runtime#81194, getting rid of the optimizeForReading-based overloads, such that everything is now optimized for reading.
As an aside, it’s worth noting that for string keys in particular, the C# compiler has now also gotten in on the game of better optimizing based on the known characteristics of the data, such that if you know all of your string keys at compile-time, and you just need an ordinal, case-sensitive lookup, you might be best off simply writing a switch statement or expression. This is all thanks to dotnet/roslyn#66081. Let’s take the name popularity example from earlier, and express it as a switch statement:
static bool IsMostPopular(string name)
{
switch (name)
{
case "Olivia":
case "Emma":
case "Charlotte":
case "Amelia":
case "Sophia":
case "Isabella":
case "Ava":
case "Mia":
case "Evelyn":
case "Luna":
return true;
default:
return false;
}
}Previously compiling this would result in the C# compiler providing a lowered equivalent to this:
static bool IsMostPopular(string name)
{
uint num = <PrivateImplementationDetails>.ComputeStringHash(name);
if (num <= 1803517931)
{
if (num <= 452280388)
{
if (num != 83419291)
{
if (num == 452280388 && name == "Isabella")
goto IL_012c;
}
else if (name == "Olivia")
goto IL_012c;
}
else if (num != 596915366)
{
if (num != 708112360)
{
if (num == 1803517931 && name == "Charlotte")
goto IL_012c;
}
else if (name == "Evelyn")
goto IL_012c;
}
else if (name == "Mia")
goto IL_012c;
}
else if (num <= 2263917949u)
{
if (num != 2234485159u)
{
if (num == 2263917949u && name == "Ava")
goto IL_012c;
}
else if (name == "Luna")
goto IL_012c;
}
else if (num != 2346269629u)
{
if (num != 3517830433u)
{
if (num == 3552467688u && name == "Amelia")
goto IL_012c;
}
else if (name == "Sophia")
goto IL_012c;
}
else if (name == "Emma")
goto IL_012c;
return false;
IL_012c:
return true;
}If you stare at that for a moment, you’ll see the compiler has implemented a binary search tree. It hashes the name, and then having hashed all of the cases at build time, it does a binary search on the hash codes to find the the right case. Now with the recent improvements, it instead generates an equivalent of this:
static bool IsMostPopular(string name)
{
if (name != null)
{
switch (name.Length)
{
case 3:
switch (name[0])
{
case 'A':
if (name == "Ava")
goto IL_012f;
break;
case 'M':
if (name == "Mia")
goto IL_012f;
break;
}
case 4:
switch (name[0])
{
case 'E':
if (name == "Emma")
goto IL_012f;
break;
case 'L':
if (name == "Luna")
goto IL_012f;
break;
}
case 6:
switch (name[0])
{
case 'A':
if (name == "Amelia")
goto IL_012f;
break;
case 'E':
if (name == "Evelyn")
goto IL_012f;
break;
case 'O':
if (name == "Olivia")
goto IL_012f;
break;
case 'S':
if (name == "Sophia")
goto IL_012f;
break;
}
case 8:
if (name == "Isabella")
goto IL_012f;
break;
case 9:
if (name == "Charlotte")
goto IL_012f;
break;
}
}
return false;
IL_012f:
return true;
}Now what’s it doing? First, it’s bucketed the strings by their length; any string that comes in that’s not 3, 4, 6, 8, or 9 characters long will be immediately rejected. For 8 and 9 characters, there’s only one possible answer it could be for each, so it simply checks against that string. For the others, it’s recognized that each name in that length begins with a different letter, and switches over that. In this particular example, the first character in each bucket is a perfect differentiator, but if it wasn’t, the compiler will also consider other indices to see if any of those might be better differentiators. This is implementing the same basic strategy as the System.Collections.Frozen.LengthBucketsFrozenSet we saw earlier.
I was careful in my choice above to use a switch. If I’d instead written the possibly more natural is expression:
static bool IsMostPopular(string name) =>
name is "Olivia" or
"Emma" or
"Charlotte" or
"Amelia" or
"Sophia" or
"Isabella" or
"Ava" or
"Mia" or
"Evelyn" or
"Luna";then up until recently the compiler wouldn’t even have output the binary search, and would have instead just generated a cascading if/else if as if I’d written:
static bool IsMostPopular(string name) =>
name == "Olivia" ||
name == "Emma" ||
name == "Charlotte" ||
name == "Amelia" ||
name == "Sophia" ||
name == "Isabella" ||
name == "Ava" ||
name == "Mia" ||
name == "Evelyn" ||
name == "Luna";With dotnet/roslyn#65874 from @alrz, however, the is-based version is now lowered the same as the switch-based version.
Back to frozen collections. As noted, System.Collections.Frozen types are in the System.Collections.Immutable library, and they’re not the only improvements to that library. A variety of new APIs have been added to help enable more productive and efficient use of the existing immutable collections…
Immutable Collections
For years, developers have found the need to bypass an ImmutableArray<T>‘s immutability. For example, the previously-discussed FrozenDictionary<TKey, TValue> exposes an ImmutableArray<TKey> for its keys and an ImmutableArray<TValue> for its values. It does this by creating a TKey[], which it uses for a variety of purposes while building up the collection, and then it wants to wrap that as an ImmutableArray<TKey> to be exposed for consumption. But with the public APIs available on ImmutableArray/ImmutableArray<T>, there’s no way to transfer ownership like that; all the APIs that accept an input T[] or IEnumerable<T> allocate a new array and copy all of the data into it, so that the implementation can be sure no one else is still holding onto a reference to the array being wrapped (if someone was, they could use that mutable reference to mutate the contents of the immutable array, and guarding against that is one of the key differentiators between a read-only collection and an immutable collection). Enabling such wrapping of the original array is thus an “unsafe” operation, albeit one that’s valuable to enable for developers willing to accept the responsibility. Previously, developers could achieve this by employing a hack that works but only because of implementation detail: using Unsafe.As to cast between the types. When a value type’s first field is a reference type, a reference to the beginning of the struct is also a reference to the reference type, since they’re both at the exact same memory location. Thus, because ImmutableArray<T> contains just a single field (for the T[] it wraps), a method like the following will successfully wrap an ImmutableArray<T> around a T[]:
static ImmutableArray<T> UnsafeWrap<T>(T[] array) => Unsafe.As<T[], ImmutableArray<T>>(ref array);That, however, is both uintuitive and depends on ImmutableArray<T> having the array at a 0-offset from the start of the struct, making it a brittle solution. To provide something robust, dotnet/runtime#85526 added the new System.Runtime.InteropServices.ImmutableCollectionsMarshal class, and on it two new methods: AsImmutableArray and AsArray. These methods support casting back and forth between a T[] and an ImmutableArray<T>, without allocation. They’re defined in InteropServices on a Marshal class, as that’s one of the ways we have to both hide more dangerous functionality and declare that something is inherently “unsafe” in some capacity.
There are also new overloads exposed for constructing immutable collections with less allocation. All of the immutable collections have a corresponding static class that provides a Create method, e.g. ImmutableList<T> has the corresponding static class ImmutableList which provides a static ImmutableList<T> Create<T>(params T[] items) method. Now in .NET 8 as of dotnet/runtime#87945, these methods all have a new overload that takes a ReadOnlySpan<T>, e.g. static ImmutableList<T> Create<T>(ReadOnlySpan<T> items). This means an immutable collection can be created without incurring the allocation required to either go through the associated builder (which is a reference type) or to allocate an array of the exact right size.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Collections.Immutable;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
[Benchmark(Baseline = true)]
public ImmutableList<int> CreateArray() => ImmutableList.Create<int>(1, 2, 3, 4, 5);
[Benchmark]
public ImmutableList<int> CreateBuilder()
{
var builder = ImmutableList.CreateBuilder<int>();
for (int i = 1; i <= 5; i++) builder.Add(i);
return builder.ToImmutable();
}
[Benchmark]
public ImmutableList<int> CreateSpan() => ImmutableList.Create<int>(stackalloc int[] { 1, 2, 3, 4, 5 });
}| Method | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|
| CreateBuilder | 132.22 ns | 1.42 | 312 B | 1.00 |
| CreateArray | 92.98 ns | 1.00 | 312 B | 1.00 |
| CreateSpan | 85.54 ns | 0.92 | 264 B | 0.85 |
BitArray
dotnet/runtime#81527 from @lateapexearlyspeed added two new methods to BitArray, HasAllSet and HasAnySet, which do exactly what their names suggest: HasAllSet returns whether all of the bits in the array are set, and HasAnySet returns whether any of the bits in the array are set. While useful, what I really like about these additions is that they make good use of the ContainsAnyExcept method introduced in .NET 8. BitArray‘s storage is an int[], where each element in the array represents 32 bits (for the purposes of this discussion, I’m ignoring the corner-case it needs to deal with of the last element’s bits not all being used because the count of the collection isn’t a multiple of 32). Determining whether any bits are set is then simply a matter of doing _array.AsSpan().ContainsAnyExcept(0). Similarly, determining whether all bits are set is simply a matter of doing !_array.AsSpan().ContainsAnyExcept(-1). The bit pattern for -1 is all 1s, so ContainsAnyExcept(-1) will return true if and only if it finds any integer that doesn’t have all of its bits set; thus if the call doesn’t find any, all bits are set. The net result is BitArray gets to maintain simple code that’s also vectorized and optimized, thanks to delegating to these shared helpers. You can see examples of these methods being used in dotnet/runtime#82057, which replaced bespoke implementations of the same functionality with the new built-in helpers.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Collections;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly BitArray _bitArray = new BitArray(1024);
[Benchmark(Baseline = true)]
public bool HasAnySet_Manual()
{
for (int i = 0; i < _bitArray.Length; i++)
{
if (_bitArray[i])
{
return true;
}
}
return false;
}
[Benchmark]
public bool HasAnySet_BuiltIn() => _bitArray.HasAnySet();
}| Method | Mean | Ratio |
|---|---|---|
| HasAnySet_Manual | 731.041 ns | 1.000 |
| HasAnySet_BuiltIn | 5.423 ns | 0.007 |
Collection Expressions
With dotnet/roslyn#68831 and then a myriad of subsequent PRs, C# 12 introduces a new terse syntax for constructing collections: “collection expressions.” Let’s say I want to construct a List<int>, for example, with the elements 1, 2, and 3. I could do it like so:
var list = new List<int>();
list.Add(1);
list.Add(2);
list.Add(3);or utilizing collection initializers that were added in C# 3:
var list = new List<int>() { 1, 2, 3 };Now in C# 12, I can write that as:
List<int> list = [1, 2, 3];I can also use “spreads,” where enumerables can be used in the syntax and have all of their contents splat into the collection. For example, instead of:
var list = new List<int>() { 1, 2 };
foreach (int i in GetData())
{
list.Add(i);
}
list.Add(3);or:
var list = new List<int>() { 1, 2 };
list.AddRange(GetData());
list.Add(3);I can simply write:
List<int> list = [1, 2, ..GetData(), 3];If it were just a simpler syntax for collections, it wouldn’t be worth discussing in this particular post. What makes it relevant from a performance perspective, however, is that the C# compiler is free to optimize this however it sees fit, and it goes to great lengths to write the best code it can for the given circumstance; some optimizations are already in the compiler, more will be in place by the time .NET 8 and C# 12 are released, and even more will come later, with the language specified in such a way that gives the compiler the freedom to innovate here. Let’s take a few examples…
If you write:
IEnumerable<int> e = [];the compiler won’t just translate that into:
IEnumerable<int> e = new int[0];After all, we have a perfectly good singleton for this in the way of Array.Empty<int>(), something the compiler already emits use of for things like params T[], and it can emit the same thing here:
IEnumerable<int> e = Array.Empty<int>();Ok, what about the optimizations we previously saw around the compiler lowering the creation of an array involving only constants and storing that directly into a ReadOnlySpan<T>? Yup, that applies here, too. So, instead of writing:
ReadOnlySpan<int> daysToMonth365 = new int[] { 0, 31, 59, 90, 120, 151, 181, 212, 243, 273, 304, 334, 365 };you can write:
ReadOnlySpan<int> daysToMonth365 = [0, 31, 59, 90, 120, 151, 181, 212, 243, 273, 304, 334, 365];and the exact same code results.
What about List<T>? Earlier in the discussion of collections we saw that List<T> now sports an AddRange(ReadOnlySpan<T>), and the compiler is free to use that. For example, if you write this:
Span<int> source1 = ...;
IList<int> source2 = ...;
List<int> result = [1, 2, ..source1, ..source2];the compiler could emit the equivalent of this:
Span<int> source1 = ...;
IList<int> source2 = ...;
List<int> result = new List<int>(2 + source1.Length + source2.Count);
result.Add(1);
result.Add(2);
result.AddRange(source1);
result.AddRange(source2);One of my favorite optimizations it achieves, though, is with spans and the use of the [InlineArray] attribute we already saw. If you write:
int a = ..., b = ..., c = ..., d = ..., e = ..., f = ..., g = ..., h = ...;
Span<int> span = [a, b, c, d, e, f, g, h];the compiler can lower that to code along the lines of this:
int a = ..., b = ..., c = ..., d = ..., e = ..., f = ..., g = ..., h = ...;
<>y__InlineArray8<int> buffer = default;
Span<int> span = buffer;
span[0] = a;
span[1] = b;
span[2] = c;
span[3] = d;
span[4] = e;
span[5] = f;
span[6] = g;
span[7] = h;
...
[InlineArray(8)]
internal struct <>y__InlineArray8<T>
{
private T _element0;
}In short, this collection expression syntax becomes the way to utilize [InlineArray] in the vast majority of situations, allowing the compiler to create a shared definition for you.
That optimization also feeds into another, which is both an optimization and a functional improvement over what’s in C# 11. Let’s say you have this code… what do you expect it to print?
// dotnet run -f net8.0
using System.Collections.Immutable;
ImmutableArray<int> array = new ImmutableArray<int> { 1, 2, 3 };
foreach (int i in array)
{
Console.WriteLine(i);
}Unless you’re steeped in System.Collections.Immutable and how collection initializers work, you likely didn’t predict the (unfortunate) answer:
Unhandled exception. System.NullReferenceException: Object reference not set to an instance of an object.
at System.Collections.Immutable.ImmutableArray`1.get_IsEmpty()
at System.Collections.Immutable.ImmutableArray`1.Add(T item)
at Program.<Main>$(String[] args)ImmutableArray<T> is a struct, so this will end up using its default initialization, which contains a null array. But even if that was made to work, the C# compiler will have lowered the code I wrote to the equivalent of this:
ImmutableArray<int> immutableArray = default;
immutableArray.Add(1);
immutableArray.Add(2);
immutableArray.Add(3);
foreach (int i in immutableArray)
{
Console.WriteLine(enumerator.Current);
}which is “wrong” in multiple ways. ImmutableArray<int>.Add doesn’t actually mutate the original collection, but instead returns a new instance that contains the additional element, so when we enumerate immutableArray, we wouldn’t see any of the additions. Plus, we’re doing all this work and allocation to create the results of Add, only to drop those results on the floor.
Collection expressions fix this. Now you can write this:
// dotnet run -f net8.0
using System.Collections.Immutable;
ImmutableArray<int> array = [1, 2, 3];
foreach (int i in array)
{
Console.WriteLine(i);
}and running it successfully produces:
1
2
3Why? Because dotnet/runtime#88470 added a new [CollectionBuilder] attribute that’s recognized by the C# compiler. That attribute is placed on a type and points to a factory method for creating that type, accepting a ReadOnlySpan<T> and returning the instance constructed from that data. That PR also tagged ImmutableArray<T> with this attribute:
[CollectionBuilder(typeof(ImmutableArray), nameof(ImmutableArray.Create))]such that when the compiler sees an ImmutableArray<T> being constructed from a collection expression, it runs to use ImmutableArray.Create<T>(ReadOnlySpan<T>). Not only that, it’s able to use the [InlineArray]-based optimization we just talked about for creating that input. As such, the code the compiler generates for this example as of today is equivalent to this:
<>y__InlineArray3<int> buffer = default;
buffer._element = 1;
Unsafe.Add(ref buffer._element, 1) = 2;
Unsafe.Add(ref buffer._element, 2) = 3;
ImmutableArray<int> array = ImmutableArray.Create(buffer);
foreach (int i in array)
{
Console.WriteLine(array);
}ImmutableList<T>, ImmutableStack<T>, ImmutableQueue<T>, ImmutableHashSet<T>, and ImmutableSortedSet<T> are all similarly attributed such that they all work with collection expressions as well.
Of course, the compiler could actually do a bit better for ImmutableArray<T>. As was previously noted, the compiler is free to optimize these how it sees fit, and we already mentioned the new ImmutableCollectionsMarshal.AsImmutableArray method. As I write this, the compiler doesn’t currently employ that method, but in the future the compiler can special-case ImmutableArray<T>, such that it could then generate code equivalent to the following:
ImmutableArray<int> array = ImmutableCollectionsMarshal.AsImmutableArray(new[] { 1, 2, 3 });saving on both stack space as well as an extra copy of the data. This is just one of the additional optimizations possible.
In short, collection expressions are intended to be a great way to express the collection you want built, and the compiler will ensure it’s done efficiently.
File I/O
.NET 6 overhauled how file I/O is implemented in .NET, rewriting FileStream, introducing the RandomAccess class, and a multitude of other changes. .NET 8 continues to improve performance with file I/O further.
One of the more interesting ways performance of a system can be improved is cancellation. After all, the fastest work is work you don’t have to do at all, and cancellation is about stopping doing unneeded work. The original patterns for asynchrony in .NET were based on a non-cancelable model (see How Async/Await Really Works in C# for an in-depth history and discussion), and over time as all of that support has shifted to the Task-based model based on CancellationToken, more and more implementations have become fully cancelable as well. As of .NET 7, the vast majority of code paths that accepted a CancellationToken actually respected it, more than just doing an up-front check to see whether cancellation was already requested but then not paying attention to it during the operation. Most of the holdouts have been very corner-case, but there’s one notable exception: FileStreams created without FileOptions.Asynchronous.
FileStream inherited the bifurcated model of asynchrony from Windows, where at the time you open a file handle you need to specify whether it’s being opened for synchronous or asynchronous (“overlapped”) access. A file handle opened for overlapped access requires that all operations be asynchronous, and vice versa if it’s opened for non-overlapped access requires that all operations be synchronous. That causes some friction with FileStream, which exposes both synchronous (e.g. Read) and asynchronous (e.g. ReadAsync) methods, as it means that one set of those needs to emulate the behavior. If the FileStream is opened for asynchronous access, then Read needs to do the operation asynchronously and block waiting for it complete (a pattern we less-than-affectionately refer to as “sync-over-async”), and if the FileStream is opened for synchronous access, then ReadAsync needs to queue a work item that will do the operation synchronously (“async-over-sync”). Even though that ReadAsync method accepts a CancellationToken, the actual synchronous Read that ends up being invoked as part of a ThreadPool work item hasn’t been cancelable. Now in .NET 8, thanks to dotnet/runtime#87103, it is, at least on Windows.
In .NET 7, PipeStream was fixed for this same case, relying on an internal AsyncOverSyncWithIoCancellation helper that would use the Win32 CancelSynchronousIo to interrupt pending I/O, while also using appropriate synchronization to ensure that only the intended associated work was interrupted and not work that happened to be running on the same worker thread before or after (Linux already fully supported PipeStream cancellation as of .NET 5). This PR adapted that same helper to then be usable as well inside of FileStream on Windows, in order to gain the same benefits. The same PR also further improved the implementation of that helper to reduce allocation and to further streamline the processing, such that the existing support in PipeStream gets leaner as well.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.IO.Pipes;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly CancellationTokenSource _cts = new();
private readonly byte[] _buffer = new byte[1];
private AnonymousPipeServerStream _server;
private AnonymousPipeClientStream _client;
[GlobalSetup]
public void Setup()
{
_server = new AnonymousPipeServerStream(PipeDirection.Out);
_client = new AnonymousPipeClientStream(PipeDirection.In, _server.ClientSafePipeHandle);
}
[GlobalCleanup]
public void Cleanup()
{
_server.Dispose();
_client.Dispose();
}
[Benchmark(OperationsPerInvoke = 100_000)]
public async Task ReadWriteAsync()
{
for (int i = 0; i < 100_000; i++)
{
ValueTask<int> read = _client.ReadAsync(_buffer, _cts.Token);
await _server.WriteAsync(_buffer, _cts.Token);
await read;
}
}
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| ReadWriteAsync | .NET 7.0 | 3.863 us | 1.00 | 181 B | 1.00 |
| ReadWriteAsync | .NET 8.0 | 2.941 us | 0.76 | – | 0.00 |
Interacting with paths via Path and File has also improved in various ways. dotnet/runtime#74855 improved Path.GetTempFileName() on Windows both functionally and for performance; in many situations in the past, we’ve made the behavior of .NET on Unix match the behavior of .NET on Windows, but this PR interestingly goes in the other direction. On Unix, Path.GetTempFileName() uses the libc mkstemp function, which accepts a template that must end in “XXXXXX” (6 Xs), and it populates those Xs with random values, using the resulting name for a new file that gets created. On Windows, GetTempFileName() was using the Win32 GetTempFileNameW function, which uses a similar pattern but with only 4 Xs. With the characters Windows will fill in, that enables only 65,536 possible names, and as the temp directory fills up, it becomes more and more likely there will be conflicts, leading to longer and longer times for creating a temp file (it also means that on Windows Path.GetTempFileName() has been limited to creating 65,536 simultaneously-existing files). This PR changes the format on Windows to match that used on Unix, and avoids the use of GetTempFileNameW, instead doing the random name assignment and retries-on-conflict itself. The net result is more consistency across OSes, a much larger number of temporary files possible (a billion instead of tens of thousands), as well as a better-performing method:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
// NOTE: The results for this benchmark will vary wildly based on how full the temp directory is.
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly List<string> _files = new();
// NOTE: The performance of this benchmark is highly influenced by what's currently in your temp directory.
[Benchmark]
public void GetTempFileName()
{
for (int i = 0; i < 1000; i++) _files.Add(Path.GetTempFileName());
}
[IterationCleanup]
public void Cleanup()
{
foreach (string path in _files) File.Delete(path);
_files.Clear();
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| GetTempFileName | .NET 7.0 | 1,947.8 ms | 1.00 |
| GetTempFileName | .NET 8.0 | 276.5 ms | 0.34 |
Path.GetFileName is another on the list of methods that improves, thanks to making use of IndexOf methods. Here, dotnet/runtime#75318 uses LastIndexOf (on Unix, where the only directory separator is '/') or LastIndexOfAny (on Windows, where both '/' and '\' can be a directory separator) to search for the beginning of the file name.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private string _path = Path.Join(Path.GetTempPath(), "SomeFileName.cs");
[Benchmark]
public ReadOnlySpan<char> GetFileName() => Path.GetFileName(_path.AsSpan());
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| GetFileName | .NET 7.0 | 9.465 ns | 1.00 |
| GetFileName | .NET 8.0 | 4.733 ns | 0.50 |
Related to File and Path, various methods on Environment also return paths. Microsoft.Extensions.Hosting.HostingHostBuilderExtensions had been using Environment.GetSpecialFolder(Environment.SpecialFolder.System) to get the system path, but this was leading to noticeable overhead when starting up an ASP.NET application. dotnet/runtime#83564 changed this to use Environment.SystemDirectory directly, which on Windows takes advantage of the much more efficient path (and resulting in simpler code), but then dotnet/runtime#83593 also fixed Environment.GetSpecialFolder(Environment.SpecialFolder.System) on Windows to use Environment.SystemDirectory, such that its performance accrues to the higher-level uses as well.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
[Benchmark]
public string GetFolderPath() => Environment.GetFolderPath(Environment.SpecialFolder.System);
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| GetFolderPath | .NET 7.0 | 1,560.87 ns | 1.00 | 88 B | 1.00 |
| GetFolderPath | .NET 8.0 | 45.76 ns | 0.03 | 64 B | 0.73 |
dotnet/runtime#73983 improves DirectoryInfo and FileInfo, making the FileSystemInfo.Name property lazy. Previously when constructing the info object if only the full name existed (and not the name of just the directory or file itself), the constructor would promptly create the Name string, even if the info object is never used (as is often the case when it’s returned from a method like CreateDirectory). Now, that Name string is lazily created on first use of the Name property.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly string _path = Environment.CurrentDirectory;
[Benchmark]
public DirectoryInfo Create() => new DirectoryInfo(_path);
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| Create | .NET 7.0 | 225.0 ns | 1.00 | 240 B | 1.00 |
| Create | .NET 8.0 | 170.1 ns | 0.76 | 200 B | 0.83 |
File.Copy has gotten a whole lot faster on macOS, thanks to dotnet/runtime#79243 from @hamarb123. File.Copy now employs the OS’s clonefile function (if available) to perform the copy, and if both the source and destination are on the same volume, clonefile creates a copy-on-write clone of the file in the destination; this makes the copy at the OS level much faster, incurring the majority cost of actually duplicating the data only occurring if one of the files is subsequently written to.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "Min", "Max")]
public class Tests
{
private string _source;
private string _dest;
[GlobalSetup]
public void Setup()
{
_source = Path.GetTempFileName();
File.WriteAllBytes(_source, Enumerable.Repeat((byte)42, 1_000_000).ToArray());
_dest = Path.GetRandomFileName();
}
[Benchmark]
public void FileCopy() => File.Copy(_source, _dest, overwrite: true);
[GlobalCleanup]
public void Cleanup()
{
File.Delete(_source);
File.Delete(_dest);
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| FileCopy | .NET 7.0 | 1,624.8 us | 1.00 |
| FileCopy | .NET 8.0 | 366.7 us | 0.23 |
Some more specialized changes have been incorporated as well. TextWriter is a core abstraction for writing text to an arbitrary destination, but sometimes you want that destination to be nowhere, a la /dev/null on Linux. For this, TextWriter provides the TextWriter.Null property, which returns a TextWriter instance that nops on all of its members. Or, at least that’s the visible behavior. In practice, only a subset of its members were actually overridden, which meant that although nothing would end up being output, some work might still be incurred and then the fruits of that labor thrown away. dotnet/runtime#83293 ensures that all of the writing methods are overridden in order to do away with all of that wasted work.
Further, one of the places TextWriter ends up being used is in Console, where Console.SetOut allows you to replace stdout with your own writer, at which point all of the writing methods on Console output to that TextWriter instead. In order to provide thread-safety of writes, Console synchronizes access to the underlying writer, but if the writer is doing nops anyway, there’s no need for that synchronization. dotnet/runtime#83296 does away with it in that case, such that if you want to temporarily silence Console, you can simply set its output to go to TextWriter.Null, and the overhead of operations on Console will be minimized.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly string _value = "42";
[GlobalSetup]
public void Setup() => Console.SetOut(TextWriter.Null);
[Benchmark]
public void WriteLine() => Console.WriteLine("The value was {0}", _value);
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| WriteLine | .NET 7.0 | 80.361 ns | 1.00 | 56 B | 1.00 |
| WriteLine | .NET 8.0 | 1.743 ns | 0.02 | – | 0.00 |
Networking
Networking is the heart and soul of most modern services and applications, which makes it all the more important that .NET’s networking stack shine.
Networking Primitives
Let’s start at the bottom of the networking stack, looking at some primitives. Most of these improvements are around formatting, parsing, and manipulation as bytes. Take dotnet/runtime#75872, for example, which improved the performance of various such operations on IPAddress. IPAddress stores a uint that’s used as the address when it’s representing an IPv4 address, and it stores a ushort[8] that’s used when it’s representing an IPv6 address. A ushort is two bytes, so a ushort[8] is 16 bytes, or 128 bits. “128 bits” is a very convenient number when performing certain operations, as such a value can be manipulated as a Vector128<> (accelerating computation on systems that accelerate it, which is most). This PR takes advantage of that to optimize common operations with an IPAddress. The IPAddress constructor, for example, is handed a ReadOnlySpan<byte> for an IPv6 address, which it needs to read into its ushort[8]; previously that was done with a loop over the input, but now it’s handled with a single vector: load the single vector, possibly reverse the endianness (which can be done in just three instructions: OR together the vector shifted left by one byte and shifted right by one byte), and store it.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Net;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly IPAddress _addr = IPAddress.Parse("2600:141b:13:781::356e");
private readonly byte[] _ipv6Bytes = IPAddress.Parse("2600:141b:13:781::356e").GetAddressBytes();
[Benchmark] public IPAddress NewIPv6() => new IPAddress(_ipv6Bytes, 0);
[Benchmark] public bool WriteBytes() => _addr.TryWriteBytes(_ipv6Bytes, out _);
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| NewIPv6 | .NET 7.0 | 36.720 ns | 1.00 |
| NewIPv6 | .NET 8.0 | 16.715 ns | 0.45 |
| WriteBytes | .NET 7.0 | 14.443 ns | 1.00 |
| WriteBytes | .NET 8.0 | 2.036 ns | 0.14 |
IPAddress now also implements ISpanFormattable and IUtf8SpanFormattable, thanks to dotnet/runtime#82913 and dotnet/runtime#84487. That means, for example, that using an IPAddress as part of string interpolation no longer needs to allocate an intermediate string. As part of this, some changes were made to IPAddress formatting to streamline it. It’s a bit harder to measure these changes, though, because IPAddress caches a string it creates, such that subsequent ToString calls just return the previous string created. To work around that, we can use private reflection to null out the field (never do this in a real code; private reflection against the core libraries is very much unsupported).
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Net;
using System.Reflection;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private IPAddress _address;
private FieldInfo _toStringField;
[GlobalSetup]
public void Setup()
{
_address = IPAddress.Parse("123.123.123.123");
_toStringField = typeof(IPAddress).GetField("_toString", BindingFlags.NonPublic | BindingFlags.Instance);
}
[Benchmark]
public string NonCachedToString()
{
_toStringField.SetValue(_address, null);
return _address.ToString();
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| NonCachedToString | .NET 7.0 | 92.63 ns | 1.00 |
| NonCachedToString | .NET 8.0 | 75.53 ns | 0.82 |
Unfortunately, such use of reflection has a non-trivial amount of overhead associated with it, which then decreases the perceived benefit from the improvement. Instead, we can use reflection emit either directly or via System.Linq.Expression to emit a custom helper that makes it less expensive to null out that private field.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Linq.Expressions;
using System.Net;
using System.Reflection;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private IPAddress _address;
private Action<IPAddress, string> _setter;
[GlobalSetup]
public void Setup()
{
_address = IPAddress.Parse("123.123.123.123");
_setter = BuildSetter<IPAddress, string>(typeof(IPAddress).GetField("_toString", BindingFlags.NonPublic | BindingFlags.Instance));
}
[Benchmark]
public string NonCachedToString()
{
_setter(_address, null);
return _address.ToString();
}
private static Action<TSource, TArg> BuildSetter<TSource, TArg>(FieldInfo field)
{
ParameterExpression target = Expression.Parameter(typeof(TSource));
ParameterExpression value = Expression.Parameter(typeof(TArg));
return Expression.Lambda<Action<TSource, TArg>>(
Expression.Assign(Expression.Field(target, field), value),
target,
value).Compile();
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| NonCachedToString | .NET 7.0 | 48.39 ns | 1.00 |
| NonCachedToString | .NET 8.0 | 36.30 ns | 0.75 |
But .NET 8 actually includes a feature that streamlines this; the feature’s primary purpose is in support of scenarios like source generators with Native AOT, but it’s useful for this kind of benchmarking, too. The new UnsafeAccessor attribute (introduced in and supported by dotnet/runtime#86932, dotnet/runtime#88626, and dotnet/runtime#88925) lets you define an extern method that bypasses visibility. In this case, I’ve used it to get a ref to the private field, at which point I can just assign null through the ref.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Net;
using System.Runtime.CompilerServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly IPAddress _address = IPAddress.Parse("123.123.123.123");
[Benchmark]
public string NonCachedToString()
{
_toString(_address) = null;
return _address.ToString();
[UnsafeAccessor(UnsafeAccessorKind.Field, Name = "_toString")]
extern static ref string _toString(IPAddress c);
}
}| Method | Mean |
|---|---|
| NonCachedToString | 34.42 ns |
Uri is another networking primitive that saw multiple improvements. dotnet/runtime#80469 removed a variety of allocations, primarily around substrings that were instead replaced by spans. dotnet/runtime#90087 replaced unsafe code as part of scheme parsing with safe span-based code, making it both safer and faster. But dotnet/runtime#88012 is more interesting, as it made Uri implement ISpanFormattable. That means that when, for example, a Uri is used as an argument to an interpolated string, the Uri can now format itself directly to the underlying buffer rather than needing to allocate a temporary string that’s then added in. This can be particularly useful for reducing the costs of logging and other forms of telemetry. It’s a little difficult to isolate just the formatting aspect of a Uri for benchmarking purposes, as Uri caches information gathered in the process, but even with constructing a new one each time you can see gains:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
[Benchmark]
public string Interpolate() => $"Uri: {new Uri("http://dot.net")}";
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| Interpolate | .NET 7.0 | 356.3 ns | 1.00 | 296 B | 1.00 |
| Interpolate | .NET 8.0 | 278.4 ns | 0.78 | 240 B | 0.81 |
Other networking primitives improved in other ways. dotnet/runtime#82095 reduced the overhead of the GetHashCode methods of several networking types, like Cookie. Cookie.GetHashCode was previously allocating and is now allocation-free. Same for DnsEndPoint.GetHashCode.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Net;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly Cookie _cookie = new Cookie("Cookie", "Monster");
private readonly DnsEndPoint _dns = new DnsEndPoint("localhost", 80);
[Benchmark]
public int CookieHashCode() => _cookie.GetHashCode();
[Benchmark]
public int DnsHashCode() => _dns.GetHashCode();
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| CookieHashCode | .NET 7.0 | 105.30 ns | 1.00 | 160 B | 1.00 |
| CookieHashCode | .NET 8.0 | 22.51 ns | 0.21 | – | 0.00 |
| DnsHashCode | .NET 7.0 | 136.78 ns | 1.00 | 192 B | 1.00 |
| DnsHashCode | .NET 8.0 | 12.92 ns | 0.09 | – | 0.00 |
And HttpUtility improved in dotnet/runtime#78240. This is a quintessential example of code doing its own manual looping looking for something (in this case, the four characters that require encoding) when it could have instead just used a well-placed IndexOfAny.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Web;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
[Benchmark]
public string HtmlAttributeEncode() =>
HttpUtility.HtmlAttributeEncode("To encode, or not to encode: that is the question");
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| HtmlAttributeEncode | .NET 7.0 | 32.688 ns | 1.00 |
| HtmlAttributeEncode | .NET 8.0 | 6.734 ns | 0.21 |
Moving up the stack to System.Net.Sockets, there are some nice improvements in .NET 8 here as well.
Sockets
dotnet/runtime#86524 and dotnet/runtime#89808 are for Windows only because the problem they address doesn’t manifest on other operatings systems, due to how asynchronous operations are implemented on the various platforms.
On Unix operatings systems, the typical approach to asynchrony is to put the socket into non-blocking mode. Issuing an operation like recv (Socket.Receive{Async}) when there’s nothing to receive then fails immediately with an errno value of EWOULDBLOCK or EAGAIN, informing the caller that no data was available to receive yet and it’s not going to wait for said data because it’s been told not to. At that point, the caller can choose how it wants to wait for data to become available. Socket does what many other systems do, which is to use epoll (on Linux) or kqueues (on macOS). These mechanisms allow for a single thread to wait efficiently for any number of registered file descriptors to signal that something has changed. As such, Socket has one or more dedicated threads that sit in a wait loop, waiting on the epoll/kqueue to signal that there’s something to do, and when there is, queueing off the associated work, and then looping around to wait for the next notification. In the case of a ReceiveAsync, that queued work will end up reissuing the recv, which will now succeed as data will be available. The interesting thing here is that during that interim period while waiting for data to become available, there was no pending call from .NET to recv or anything else that would require a managed buffer (e.g. an array) be available. That’s not the case on Windows…
On Windows, the OS provides dedicated asynchronous APIs (“overlapped I/O”), with ReceiveAsync being a thin wrapper around the Win32 WSARecv function. WSARecv accepts a pointer to the buffer to write into and a pointer to a callback that will be invoked when the operation has completed. That means that while waiting for data to be available, WSARecv actually needs a pointer to the buffer it’ll write the data into (unless 0 bytes have been requested, which we’ll talk more about in a bit). In .NET world, buffers are typically on the managed heap, which means they can be moved around by the GC, and thus in order to pass a pointer to such a buffer down to WSARecv, that buffer needs to be “pinned,” telling the GC “do not move this.” For synchronous operations, such pinning is best accomplished with the C# fixed keyword; for asynchronous operations, GCHandle or something that wraps it (like Memory.Pin and MemoryHandle) are the answers. So, on Windows, Socket uses a GCHandle for any buffers it supplies to the OS to span an asynchronous operation’s lifetime.
For the last 20 years, though, it’s been overaggressive in doing so. There’s a buffer passed to various Win32 methods, including WSAConnect (Socket.ConnectAsync), to represent the target IP address. Even though these are asynchronous operations, it turns out that data is only required as part of the synchronous part of the call to these APIs; only a ReceiveFromAsync operation (which is typically only used with connectionless protocols, and in particular UDP) that receives not only payload data but also the sender’s address actually needs the address buffer pinned over the lifetime of the operation. Socket was pinning the buffer using a GCHandle, and in fact doing so for the lifetime of the Socket, even though a GCHandle wasn’t actually needed at all for these calls, and a fixed would suffice around just the Win32 call itself. The first PR fixed that, the net effect of which is that a GCHandle that was previously pinning a buffer for the lifetime of every Socket on Windows then only did so for Sockets issuing ReceiveFromAsync calls. The second PR then fixed ReceiveFromAsync, using a native buffer instead of a managed one that would need to be permanently pinned. The primary benefit of these changes is that it helps to avoid a lot of fragmentation that can result at scale in the managed heap. We can see this most easily by looking at the runtime’s tracing, which I consume in this example via an EventListener:
// dotnet run -c Release -f net7.0
// dotnet run -c Release -f net8.0
using System.Net;
using System.Net.Sockets;
using System.Diagnostics.Tracing;
using var setCountListener = new GCHandleListener();
Thread.Sleep(1000);
using Socket listener = new Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp);
listener.Bind(new IPEndPoint(IPAddress.Loopback, 0));
listener.Listen();
for (int i = 0; i < 10_000; i++)
{
using Socket client = new Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp);
await client.ConnectAsync(listener.LocalEndPoint!);
listener.Accept().Dispose();
}
Thread.Sleep(1000);
Console.WriteLine($"{Environment.Version} GCHandle count: {setCountListener.SetGCHandleCount}");
sealed class GCHandleListener : EventListener
{
public int SetGCHandleCount = 0;
protected override void OnEventSourceCreated(EventSource eventSource)
{
if (eventSource.Name == "Microsoft-Windows-DotNETRuntime")
EnableEvents(eventSource, EventLevel.Informational, (EventKeywords)0x2);
}
protected override void OnEventWritten(EventWrittenEventArgs eventData)
{
// https://learn.microsoft.com/dotnet/fundamentals/diagnostics/runtime-garbage-collection-events#setgchandle-event
if (eventData.EventId == 30 && eventData.Payload![2] is (uint)3)
Interlocked.Increment(ref SetGCHandleCount);
}
}When I run this on .NET 7 on Windows, I get this:
7.0.9 GCHandle count: 10000When I run this on .NET 8, I get this:
8.0.0 GCHandle count: 0Nice.
I mentioned UDP above, with ReceiveFromAsync. We’ve invested a lot over the last several years in making the networking stack in .NET very efficient… for TCP. While most of the improvements there accrue to UDP as well, UDP has additional costs that hadn’t been addressed and that made it suboptimal from a performance perspective. The primary issues there are now addressed in .NET 8, thanks to dotnet/runtime#88970 and dotnet/runtime#90086. The key problem here with the UDP-related APIs, namely SendTo{Async} and ReceiveFrom{Async}, is that the API is based on EndPoint but the core implementation is based on SocketAddress. Every call to SendToAsync, for example, would accept the provided EndPoint and then call EndPoint.Serialize to produce a SocketAddress, which internally has its own byte[]; that byte[] contains the address actually passed down to the underlying OS APIs. The inverse happens on the ReceiveFromAsync side: the received data includes an address that would be deserialized into an EndPoint which is then returned to the consumer. You can see these allocations show up by profiling a simple repro:
using System.Net;
using System.Net.Sockets;
var client = new Socket(AddressFamily.InterNetwork, SocketType.Dgram, ProtocolType.Udp);
var server = new Socket(AddressFamily.InterNetwork, SocketType.Dgram, ProtocolType.Udp);
EndPoint endpoint = new IPEndPoint(IPAddress.Loopback, 12345);
server.Bind(endpoint);
Memory<byte> buffer = new byte[1];
for (int i = 0; i < 10_000; i++)
{
ValueTask<SocketReceiveFromResult> result = server.ReceiveFromAsync(buffer, endpoint);
await client.SendToAsync(buffer, endpoint);
await result;
}The .NET allocation profiler in Visual Studio shows this:
So for each send/receive pair, we see three SocketAddresses which in turn leads to three byte[]s, and an IPEndPoint which in turn leads to an IPAddress. These costs are very difficult to address efficiently purely in implementation, as they’re directly related to what’s surfaced in the corresponding APIs. Even so, with the exact same code, it does improve a bit in .NET 8:
So with zero code changes, we’ve managed to eliminate one of the SocketAddress allocations and its associated byte[], and to shrink the size of the remaining instances (in part due to dotnet/runtime#78860). But, we can do much better…
.NET 8 introduces a new set of overloads. In .NET 7, we had these:
public int SendTo(byte[] buffer, int offset, int size, SocketFlags socketFlags, EndPoint remoteEP);
public int ReceiveFrom(byte[] buffer, int offset, int size, SocketFlags socketFlags, ref EndPoint remoteEP);
public ValueTask<int> SendToAsync(ReadOnlyMemory<byte> buffer, SocketFlags socketFlags, EndPoint remoteEP, CancellationToken cancellationToken = default)
public ValueTask<SocketReceiveFromResult> ReceiveFromAsync(Memory<byte> buffer, SocketFlags socketFlags, EndPoint remoteEndPoint, CancellationToken cancellationToken = default);and now in .NET 8 we also have these:
public int SendTo(ReadOnlySpan<byte> buffer, SocketFlags socketFlags, SocketAddress socketAddress);
public int ReceiveFrom(Span<byte> buffer, SocketFlags socketFlags, SocketAddress receivedAddress);
public ValueTask<int> SendToAsync(ReadOnlyMemory<byte> buffer, SocketFlags socketFlags, SocketAddress socketAddress, CancellationToken cancellationToken = default);
public ValueTask<int> ReceiveFromAsync(Memory<byte> buffer, SocketFlags socketFlags, SocketAddress receivedAddress, CancellationToken cancellationToken = default);Key things to note:
- The new APIs no longer work in terms of
EndPoint. They now operate onSocketAddressdirectly. That means the implementation no longer needs to callEndPoint.Serializeto produce aSocketAddressand can just use the provided one directly. - There’s no more
ref EndPointargument in the synchronousReceiveFromand no moreSocketReceiveFromResultin the asynchronousReceiveFromAsync. Both of these existed in order to pass back anIPEndPointthat represented the address of the received data’s sender.SocketAddress, however, is just a strongly-typed wrapper around abyte[]buffer, which means these methods can just mutate that provided instance, avoiding needing to instantiate anything to represent the received address.
Let’s change our code sample to use these new APIs:
using System.Net;
using System.Net.Sockets;
var client = new Socket(AddressFamily.InterNetwork, SocketType.Dgram, ProtocolType.Udp);
var server = new Socket(AddressFamily.InterNetwork, SocketType.Dgram, ProtocolType.Udp);
EndPoint endpoint = new IPEndPoint(IPAddress.Loopback, 12345);
server.Bind(endpoint);
Memory<byte> buffer = new byte[1];
SocketAddress receiveAddress = endpoint.Serialize();
SocketAddress sendAddress = endpoint.Serialize();
for (int i = 0; i < 10_000; i++)
{
ValueTask<int> result = server.ReceiveFromAsync(buffer, SocketFlags.None, receiveAddress);
await client.SendToAsync(buffer, SocketFlags.None, sendAddress);
await result;
}When I profile that, and again look for objects created at least once per iteration, I now see this:

That’s not a mistake; I didn’t accidentally crop the screenshot incorrectly. It’s empty because there are no allocations per iteration; the whole program incurs only three SocketAddress allocations as part of the up-front setup. We can see that more clearly with a standard BenchmarkDotNet repro:
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Net;
using System.Net.Sockets;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly Memory<byte> _buffer = new byte[1];
SocketAddress _sendAddress, _receiveAddress;
IPEndPoint _ep;
Socket _client, _server;
[GlobalSetup]
public void Setup()
{
_client = new Socket(AddressFamily.InterNetwork, SocketType.Dgram, ProtocolType.Udp);
_server = new Socket(AddressFamily.InterNetwork, SocketType.Dgram, ProtocolType.Udp);
_ep = new IPEndPoint(IPAddress.Loopback, 12345);
_server.Bind(_ep);
_sendAddress = _ep.Serialize();
_receiveAddress = _ep.Serialize();
}
[Benchmark(OperationsPerInvoke = 1_000, Baseline = true)]
public async Task ReceiveFromSendToAsync_EndPoint()
{
for (int i = 0; i < 1_000; i++)
{
var result = _server.ReceiveFromAsync(_buffer, SocketFlags.None, _ep);
await _client.SendToAsync(_buffer, SocketFlags.None, _ep);
await result;
}
}
[Benchmark(OperationsPerInvoke = 1_000)]
public async Task ReceiveFromSendToAsync_SocketAddress()
{
for (int i = 0; i < 1_000; i++)
{
var result = _server.ReceiveFromAsync(_buffer, SocketFlags.None, _receiveAddress);
await _client.SendToAsync(_buffer, SocketFlags.None, _sendAddress);
await result;
}
}
}| Method | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|
| ReceiveFromSendToAsync_EndPoint | 32.48 us | 1.00 | 216 B | 1.00 |
| ReceiveFromSendToAsync_SocketAddress | 31.78 us | 0.98 | – | 0.00 |
TLS
Moving up the stack further, SslStream has received some love in this release. While in previous releases work was done to reduce allocation, .NET 8 sees it reduced further:
- dotnet/runtime#74619 avoids some allocations related to ALPN. Application-Layer Protocol Negotation is a mechanism that allows higher-level protocols to piggyback on the roundtrips already being performed as part of a TLS handshake. It’s used by an HTTP client and server to negotiate which HTTP version to use (e.g. HTTP/2 or HTTP/1.1). Previously, the implementation would end up allocating a
byte[]for use with this HTTP version selection, but now with this PR, the implementation precomputesbyte[]s for the most common protocol selections, avoiding the need to re-allocate thosebyte[]s on each new connection. - dotnet/runtime#81096 removes a delegate allocation by moving some code around between the main
SslStreamimplementation and the Platform Abstraction Layer (PAL) that’s used to handle OS-specific code (everything in theSslStreamlayer is compiled intoSystem.Net.Security.dllregardless of OS, and then depending on the target OS, a different version of theSslStreamPalclass is compiled in). - dotnet/runtime#84690 from @am11 avoids a gigantic
Dictionary<TlsCipherSuite, TlsCipherSuiteData>that was being created to enable querying for information about a particular cipher suite for use with TLS. Instead of a dictionary mapping aTlsCipherSuiteenum to aTlsCipherSuiteDatastruct (which contained details like anExchangeAlgorithmTypeenum value, aCipherAlgorithmTypeenum value, anintCipherAlgorithmStrength, etc.), aswitchstatement is used, mapping that sameTlsCipherSuiteenum to anintthat’s packed with all the same information. This not only avoids the run-time costs associated with allocating that dictionary and populating it, it also shaves almost 20Kb off a published Native AOT binary, due to all of the code that was necessary to populate the dictionary. dotnet/runtime#84921 from @am11 uses a similarswitchfor well-known OIDs. - dotnet/runtime#86163 changed an internal
ProtocolTokenclass into a struct, passing it around byrefinstead. - dotnet/runtime#74695 avoids some
SafeHandleallocation in interop as part of certificate handling on Linux.SafeHandles are a valuable reliability feature in .NET: they wrap a native handle / file descriptor, providing the finalizer that ensures the resource isn’t leaked, but also providing ref counting to ensure that the resource isn’t closed while it’s still being used, leading to use-after-free and handle recycling bugs. They’re particularly helpful when a handle or file descriptor needs to be passed around and shared between multiple components, often as part of some larger object model (e.g. aFileStreamwraps aSafeFileHandle). However, in some cases they’re unnecessary overhead. If you have a pattern like:SafeHandle handle = GetResource(); try { Use(handle); } finally { handle.Dispose(); }such that the resource is provably used and freed correctly, you can avoid the
SafeHandleand instead just use the resource directly:IntPtr handle = GetResource(); try { Use(handle); } finally { Free(handle); }thereby saving on the allocation of a finalizable object (which is more expensive than a normal allocation as synchronization is required to add that object to a finalization queue in the GC) as well as on ref-counting overhead associated with using a
SafeHandlein interop.
This benchmark repeatedly creates new SslStreams and performs handshakes:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Net;
using System.Net.Security;
using System.Net.Sockets;
using System.Runtime.InteropServices;
using System.Security.Authentication;
using System.Security.Cryptography;
using System.Security.Cryptography.X509Certificates;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private NetworkStream _client, _server;
private readonly SslServerAuthenticationOptions _options = new SslServerAuthenticationOptions
{
ServerCertificateContext = SslStreamCertificateContext.Create(GetCertificate(), null),
};
[GlobalSetup]
public void Setup()
{
using var listener = new Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp);
listener.Bind(new IPEndPoint(IPAddress.Loopback, 0));
listener.Listen(1);
var client = new Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp) { NoDelay = true };
client.Connect(listener.LocalEndPoint);
Socket serverSocket = listener.Accept();
serverSocket.NoDelay = true;
_server = new NetworkStream(serverSocket, ownsSocket: true);
_client = new NetworkStream(client, ownsSocket: true);
}
[GlobalCleanup]
public void Cleanup()
{
_client.Dispose();
_server.Dispose();
}
[Benchmark]
public async Task Handshake()
{
using var client = new SslStream(_client, leaveInnerStreamOpen: true, delegate { return true; });
using var server = new SslStream(_server, leaveInnerStreamOpen: true, delegate { return true; });
await Task.WhenAll(
client.AuthenticateAsClientAsync("localhost", null, SslProtocols.Tls12, checkCertificateRevocation: false),
server.AuthenticateAsServerAsync(_options));
}
private static X509Certificate2 GetCertificate()
{
X509Certificate2 cert;
using (RSA rsa = RSA.Create())
{
var certReq = new CertificateRequest("CN=localhost", rsa, HashAlgorithmName.SHA256, RSASignaturePadding.Pkcs1);
certReq.CertificateExtensions.Add(new X509BasicConstraintsExtension(false, false, 0, false));
certReq.CertificateExtensions.Add(new X509EnhancedKeyUsageExtension(new OidCollection { new Oid("1.3.6.1.5.5.7.3.1") }, false));
certReq.CertificateExtensions.Add(new X509KeyUsageExtension(X509KeyUsageFlags.DigitalSignature, false));
cert = certReq.CreateSelfSigned(DateTimeOffset.UtcNow.AddMonths(-1), DateTimeOffset.UtcNow.AddMonths(1));
if (RuntimeInformation.IsOSPlatform(OSPlatform.Windows))
{
cert = new X509Certificate2(cert.Export(X509ContentType.Pfx));
}
}
return cert;
}
}It shows an ~13% reduction in overall allocation as part of the SslStream lifecycle:
| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| Handshake | .NET 7.0 | 828.5 us | 1.00 | 7.07 KB | 1.00 |
| Handshake | .NET 8.0 | 769.0 us | 0.93 | 6.14 KB | 0.87 |
My favorite SslStream improvement in .NET 8, though, is dotnet/runtime#87563, which teaches SslStream to do “zero-byte reads” in order to minimize buffer use and pinning. This has been a long time coming, and is the result of multiple users of SslStream reporting significant heap fragmentation.
When a read is issued to SslStream, it in turn needs to issue a read on the underlying Stream; the data it reads has a header, which gets peeled off, and then the remaining data is decrypted and stored into the user’s buffer. Since there’s manipulation of the data read from the underlying Stream, including not giving all of it to the user, SslStream doesn’t just pass the user’s buffer to the underlying Stream, but instead passes its own buffer down. That means it needs a buffer to pass. With performance improvements in recent .NET releases, SslStream rents said buffer on demand from the ArrayPool and returns it as soon as that temporary buffer has been drained of all the data read into it. There are two issues with this, though. On Windows, a buffer is being provided to Socket, which needs to pin the buffer in order to give a pointer to that buffer to the Win32 overlapped I/O operation; that pinning means the GC can’t move the buffer on the heap, which can mean gaps end up being left on the heap that aren’t usable (aka “fragmentation”), and that in turn can lead to sporadic out-of-memory conditions. As noted earlier, the Socket implementation on Linux and macOS doesn’t need to do such pinning, however there’s still a problem here. Imagine you have a thousand open connections, or a million open connections, all of which are sitting in a read waiting for data; even if there’s no pinning, if each of those connections has an SslStream that’s rented a buffer of any meaningful size, that’s a whole lot of wasted memory just sitting there.
An answer to this that .NET has been making more and more use of over the last few years is “zero-byte reads.” If you need to read 100 bytes, rather than handing down your 100-byte buffer, at which point it needs to be pinned, you instead issue a read for 0 bytes, handing down an empty buffer, at which point nothing needs to be pinned. When there’s data available, that zero-byte read completes (without consuming anything), and then you issue the actual read for the 100 bytes, which is much more likely to be synchronously satisfiable at that point. As of .NET 6, SslStream is already capable of passing along zero-byte reads, e.g. if you do sslStream.ReadAsync(emptyBuffer) and it doesn’t have any data buffered already, it’ll in turn issue a zero-byte read on the underlying Stream. However, today SslStream itself doesn’t create zero-byte reads, e.g. if you do sslStream.ReadAsync(someNonEmptyBuffer) and it doesn’t have enough data buffered, it in turn will issue a non-zero-byte read, and we’re back to pinning per operation at the Socket layer, plus needing a buffer to pass down, which means renting one.
dotnet/runtime#87563 teaches SslStream how to create zero-byte reads. Now when you do sslStream.ReadAsync(someNonEmptyBuffer) and the SslStream doesn’t have enough data buffered, rather than immediately renting a buffer and passing that down, it instead issues a zero-byte read on the underlying Stream. Only once that operation completes does it then proceed to actually rent a buffer and issue another read, this time with the rented buffer. The primary downside to this is a bit more overhead, in that it can lead to an extra syscall; however, our measurements show that overhead to largely be in the noise, with very meaningful upside in reduced fragmentation, working set reduction, and ArrayPool stability.
The GCHandle reduction on Windows is visible with this app, a variation of one showed earlier:
// dotnet run -c Release -f net7.0
// dotnet run -c Release -f net8.0
using System.Net;
using System.Net.Security;
using System.Net.Sockets;
using System.Runtime.InteropServices;
using System.Security.Cryptography.X509Certificates;
using System.Security.Cryptography;
using System.Diagnostics.Tracing;
var listener = new Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp);
var client = new Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp);
listener.Bind(new IPEndPoint(IPAddress.Loopback, 0));
listener.Listen();
client.Connect(listener.LocalEndPoint!);
Socket server = listener.Accept();
listener.Dispose();
X509Certificate2 cert;
using (RSA rsa = RSA.Create())
{
var certReq = new CertificateRequest("CN=localhost", rsa, HashAlgorithmName.SHA256, RSASignaturePadding.Pkcs1);
certReq.CertificateExtensions.Add(new X509BasicConstraintsExtension(false, false, 0, false));
certReq.CertificateExtensions.Add(new X509EnhancedKeyUsageExtension(new OidCollection { new Oid("1.3.6.1.5.5.7.3.1") }, false));
certReq.CertificateExtensions.Add(new X509KeyUsageExtension(X509KeyUsageFlags.DigitalSignature, false));
cert = certReq.CreateSelfSigned(DateTimeOffset.UtcNow.AddMonths(-1), DateTimeOffset.UtcNow.AddMonths(1));
if (RuntimeInformation.IsOSPlatform(OSPlatform.Windows))
{
cert = new X509Certificate2(cert.Export(X509ContentType.Pfx));
}
}
var clientStream = new SslStream(new NetworkStream(client, ownsSocket: true), false, delegate { return true; });
var serverStream = new SslStream(new NetworkStream(server, ownsSocket: true), false, delegate { return true; });
await Task.WhenAll(
clientStream.AuthenticateAsClientAsync("localhost", null, false),
serverStream.AuthenticateAsServerAsync(cert, false, false));
using var setCountListener = new GCHandleListener();
Memory<byte> buffer = new byte[1];
for (int i = 0; i < 100_000; i++)
{
ValueTask<int> read = clientStream.ReadAsync(buffer);
await serverStream.WriteAsync(buffer);
await read;
}
Thread.Sleep(1000);
Console.WriteLine($"{Environment.Version} GCHandle count: {setCountListener.SetGCHandleCount:N0}");
sealed class GCHandleListener : EventListener
{
public int SetGCHandleCount = 0;
protected override void OnEventSourceCreated(EventSource eventSource)
{
if (eventSource.Name == "Microsoft-Windows-DotNETRuntime")
EnableEvents(eventSource, EventLevel.Informational, (EventKeywords)0x2);
}
protected override void OnEventWritten(EventWrittenEventArgs eventData)
{
// https://learn.microsoft.com/dotnet/fundamentals/diagnostics/runtime-garbage-collection-events#setgchandle-event
if (eventData.EventId == 30 && eventData.Payload[2] is (uint)3)
Interlocked.Increment(ref SetGCHandleCount);
}
}On .NET 7, this outputs:
7.0.9 GCHandle count: 100,000whereas on .NET 8, I now get:
8.0.0 GCHandle count: 0So pretty.
HTTP
The primary consumer of SslStream in .NET itself is the HTTP stack, so let’s move up the stack now to HttpClient, which has seen important gains of its own in .NET 8. As with SslStream, there were a bunch of improvements here that all joined to make for a measurable end-to-end improvement (many of the opportunities here were found as part of improving YARP):
- dotnet/runtime#74393 streamlined how HTTP/1.1 response headers are parsed, including making better use of
IndexOfAnyto speed up searching for various delimiters demarcating portions of the response. - dotnet/runtime#79525 and dotnet/runtime#79524 restructured buffer management for reading and writing on HTTP/1.1 connections.
- dotnet/runtime#81251 reduced the size of
HttpRequestMessageby 8 bytes andHttpRequestHeadersby 16 bytes (on 64-bit).HttpRequestMessagehad aBooleanfield that was replaced by using a bit from an existingintfield that wasn’t using all of its bits; as the rest of the message’s fields fit neatly into a multiple of 8 bytes, that extraBoolean, even though only a byte in size, required the object to grow by 8 bytes. ForHttpRequestHeaders, it already had an optimization where some uncommonly used headers were pushed off into a contingently-allocated array; there were additional rarely used fields that made more sense to be contingent. - dotnet/runtime#83640 shrunk the size of various strongly typed
HeaderValuetypes. For example,ContentRangeHeaderValuehas three public propertiesFrom,To, andLength, all of which arelong?akaNullable<long>. Each of these properties was backed by aNullable<long>field. Because of packing and alignment,Nullable<long>ends up consuming 16 bytes, 8 bytes for thelongand then 8 bytes for theboolindicating whether the nullable has a value (boolis stored as a single byte, but because of alignment and packing, it’s rounded up to 8). Instead of storing these asNullable<long>, they can just belong, using whether they contain a negative value to indicate whether they were initialized, reducing the size of the object from 72 bytes down to 48 bytes. Similar improvements were made to six other suchHeaderValuetypes. - dotnet/runtime#81253 tweaked how “Transfer-Encoding: chunked” is stored internally, special-casing it to avoid several allocations.
- When
Activityis in use in order to enable the correlation of tracing information across end-to-end usage, every HTTP request ends up creating a newActivity.Id, which incurs not only thestringfor that ID, but also in the making of it temporarystringand a temporarystring[6]array. dotnet/runtime#86685 removes both of those intermediate allocations by making better use of spans. - dotnet/runtime#79484 is specific to HTTP/2 and applies to it similar changes to what was discussed for
SslStream: it now rents buffers from theArrayPoolon demand, returning those buffers when idle, and it issues zero-byte reads to the underlying transportStream. The net result of these changes is it can reduce the memory usage of an idle HTTP/2 connection by up to 80Kb.
We can use the following simple GET-request benchmark to how some of these changes accrue to reduced overheads with HttpClient:
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Net;
using System.Net.Sockets;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private static readonly Socket s_listener = new Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp);
private static readonly HttpMessageInvoker s_client = new(new SocketsHttpHandler());
private static Uri s_uri;
[Benchmark]
public async Task HttpGet()
{
var m = new HttpRequestMessage(HttpMethod.Get, s_uri);
using (HttpResponseMessage r = await s_client.SendAsync(m, default))
using (Stream s = r.Content.ReadAsStream())
await s.CopyToAsync(Stream.Null);
}
[GlobalSetup]
public void CreateSocketServer()
{
s_listener.Bind(new IPEndPoint(IPAddress.Loopback, 0));
s_listener.Listen(int.MaxValue);
var ep = (IPEndPoint)s_listener.LocalEndPoint;
s_uri = new Uri($"http://{ep.Address}:{ep.Port}/");
Task.Run(async () =>
{
while (true)
{
Socket s = await s_listener.AcceptAsync();
_ = Task.Run(() =>
{
using (var ns = new NetworkStream(s, true))
{
byte[] buffer = new byte[1024];
int totalRead = 0;
while (true)
{
int read = ns.Read(buffer, totalRead, buffer.Length - totalRead);
if (read == 0) return;
totalRead += read;
if (buffer.AsSpan(0, totalRead).IndexOf("\r\n\r\n"u8) == -1)
{
if (totalRead == buffer.Length) Array.Resize(ref buffer, buffer.Length * 2);
continue;
}
ns.Write("HTTP/1.1 200 OK\r\nDate: Sun, 05 Jul 2020 12:00:00 GMT \r\nServer: Example\r\nContent-Length: 5\r\n\r\nHello"u8);
totalRead = 0;
}
}
});
}
});
}
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| HttpGet | .NET 7.0 | 151.7 us | 1.00 | 1.52 KB | 1.00 |
| HttpGet | .NET 8.0 | 136.0 us | 0.90 | 1.41 KB | 0.93 |
WebSocket also sees improvements in .NET 8. With dotnet/runtime#87329, ManagedWebSocket (the implementation that’s used by ClientWebSocket and that’s returned from WebSocket.CreateFromStream) gets in on the zero-byte reads game. In .NET 7, you could perform a zero-byte ReceiveAsync on ManagedWebSocket, but doing so would still issue a ReadAsync to the underlying stream with the receive header buffer. That in turn could cause the underlying Stream to rent and/or pin a buffer. By special-casing zero-byte reads now in .NET 8, ClientWebSocket can take advantage of any special-casing in the base stream, and hopefully make it so that when the actual read is performed, the data necessary to satisfy it synchronously is already available.
And with dotnet/runtime#75025, allocation with ClientWebSocket.ConnectAsync is reduced. This is a nice example of really needing to pay attention to defaults. ClientWebSocket has an optimization where it maintains a shared singleton HttpMessageInvoker that it reuses between ClientWebSocket instances. However, it can only reuse them when the settings of the ClientWebSocket match the settings of that shared singleton; by default ClientWebSocketOptions.Proxy is set, and that’s enough to knock it off the path that lets it use the shared handler. This PR adds a second shared singleton for when Proxy is set, such that requests using the default proxy can now use a shared handler rather than creating one a new.
JSON
A significant focus for System.Text.Json in .NET 8 was on improving support for trimming and source-generated JsonSerializer implementations, as its usage ends up on critical code paths in a multitude of services and applications, including those that are a primary focus area for Native AOT. Thus, a lot of work went into adding features to the source generator that might otherwise prevent a developer from prefering to use it. dotnet/runtime#79828, for example, added support for required and init properties in C#, dotnet/runtime#83631 added support for “unspeakable” types (such as the compiler-generated types used to implement iterator methods), and dotnet/runtime#84768 added better support for boxed values. dotnet/runtime#79397 also added support for weakly-typed but trimmer-safe Serialize/Deserialize methods, taking JsonTypeInfo, that make it possible for ASP.NET and other such consumers to cache JSON contract metadata appropriately. All of these improvements are functionally valuable on their own, but also accrue to the overall goals of reducing deployed binary size, improving startup time, and generally being able to be successful with Native AOT and gaining the benefits it brings.
Even with that focus, however, there were still some nice throughput-focused improvements that made their way into .NET 8. In particular, a key improvement in .NET 8 is that the JsonSerializer is now able to utilize generated “fast-path” methods even when streaming.
One of the main things the JSON source generator does is generate at build-time all of the things JsonSerializer would otherwise need reflection to access at run-time, e.g. discovering the shape of a type, all of its members, their names, attributes that control their serialization, and so on. With just that, however, the serializer would still be using generic routines to perform operations like serialization, just doing so without needing to use reflection. Instead, the source generator can emit a customized serialization routine specific to the data in question, in order to optimize writing it out. For example, given the following types:
public class Rectangle
{
public int X, Y, Width, Height;
public Color Color;
}
public struct Color
{
public byte R, G, B, A;
}
[JsonSerializable(typeof(Rectangle))]
[JsonSourceGenerationOptions(IncludeFields = true)]
private partial class JsonContext : JsonSerializerContext { }the source generator will include the following serialization routines in the generated code:
private void RectangleSerializeHandler(global::System.Text.Json.Utf8JsonWriter writer, global::Tests.Rectangle? value)
{
if (value == null)
{
writer.WriteNullValue();
return;
}
writer.WriteStartObject();
writer.WriteNumber(PropName_X, ((global::Tests.Rectangle)value).X);
writer.WriteNumber(PropName_Y, ((global::Tests.Rectangle)value).Y);
writer.WriteNumber(PropName_Width, ((global::Tests.Rectangle)value).Width);
writer.WriteNumber(PropName_Height, ((global::Tests.Rectangle)value).Height);
writer.WritePropertyName(PropName_Color);
ColorSerializeHandler(writer, ((global::Tests.Rectangle)value).Color);
writer.WriteEndObject();
}
private void ColorSerializeHandler(global::System.Text.Json.Utf8JsonWriter writer, global::Tests.Color value)
{
writer.WriteStartObject();
writer.WriteNumber(PropName_R, value.R);
writer.WriteNumber(PropName_G, value.G);
writer.WriteNumber(PropName_B, value.B);
writer.WriteNumber(PropName_A, value.A);
writer.WriteEndObject();
}The serializer can then just invoke these routines to write the data directly to the Utf8JsonWriter.
However, in the past these routines weren’t used when serializing with one of the streaming routines (e.g. all of the SerializeAsync methods), in part because of the complexity of refactoring the implementation to accommodate them, but in larger part out of concern that an individual instance being serialized might need to write more data than should be buffered; these fast paths are synchronous-only today, and so can’t perform asynchronous flushes efficiently. This is particularly unfortunate because these streaming overloads are the primary ones used by ASP.NET, which means ASP.NET wasn’t benefiting from these fast paths. Thanks to dotnet/runtime#78646, in .NET 8 they now do benefit. The PR does the necessary refactoring internally and also puts in place various heuristics to minimize chances of over-buffering. The net result is these existing optimizations now kick in for a much broader array of use cases, including the primary ones higher in the stack, and the wins are significant.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text.Json;
using System.Text.Json.Serialization;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public partial class Tests
{
private readonly Rectangle _data = new()
{
X = 1, Y = 2,
Width = 3, Height = 4,
Color = new Color { R = 5, G = 6, B = 7, A = 8 }
};
[Benchmark]
public void Serialize() => JsonSerializer.Serialize(Stream.Null, _data, JsonContext.Default.Rectangle);
[Benchmark]
public Task SerializeAsync() => JsonSerializer.SerializeAsync(Stream.Null, _data, JsonContext.Default.Rectangle);
public class Rectangle
{
public int X, Y, Width, Height;
public Color Color;
}
public struct Color
{
public byte R, G, B, A;
}
[JsonSerializable(typeof(Rectangle))]
[JsonSourceGenerationOptions(IncludeFields = true)]
private partial class JsonContext : JsonSerializerContext { }
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| Serialize | .NET 7.0 | 613.3 ns | 1.00 | 488 B | 1.00 |
| Serialize | .NET 8.0 | 205.9 ns | 0.34 | – | 0.00 |
| SerializeAsync | .NET 7.0 | 654.2 ns | 1.00 | 488 B | 1.00 |
| SerializeAsync | .NET 8.0 | 259.6 ns | 0.40 | 32 B | 0.07 |
The fast-path routines are better leveraged in additional scenarios now, as well. Another case where they weren’t used, even when not streaming, was when combining multiple source-generated contexts: if you have your JsonSerializerContext-derived type for your own types to be serialized, and someone passes to you another JsonSerializerContext-derived type for a type they’re giving you to serialize, you need to combine those contexts together into something you can give to Serialize. In doing so, however, the fast paths could get lost. dotnet/runtime#80741 adds additional APIs and support to enable the fast paths to still be used.
Beyond JsonSerializer, there have been several other performance improvements. In dotnet/runtime#88194, for example, JsonNode‘s implementation is streamlined, including avoiding allocating a delegate while setting values into the node, and in dotnet/runtime#85886, JsonNode.To is improved via a one-line change that stops unnecessarily calling Memory<byte>.ToArray() in order to pass it to a method that accepts a ReadOnlySpan<byte>: Memory<byte>.Span can and should be used instead, saving on a potentially large array allocation and copy.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text.Json.Nodes;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly JsonNode _node = JsonNode.Parse("""{ "Name": "Stephen" }"""u8);
[Benchmark]
public string ToJsonString() => _node.ToString();
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| ToJsonString | .NET 7.0 | 244.5 ns | 1.00 | 272 B | 1.00 |
| ToJsonString | .NET 8.0 | 189.6 ns | 0.78 | 224 B | 0.82 |
Lastly on the JSON front, there’s the new CA1869 analyzer added in dotnet/roslyn-analyzers#6850.

The JsonSerializerOptions type looks like something that should be relatively cheap to allocate, just a small options type you could allocate on each call to JsonSerializer.Serialize or JsonSerializer.Deserialize with little ramification:
T value = JsonSerializer.Deserialize<T>(source, new JsonSerializerOptions { AllowTrailingCommas = true });That’s not the case, however. JsonSerializer may need to use reflection to analyze the type being serialized or deserialized in order to learn about its shape and then potentially even use reflection emit to generate custom processing code for using that type. The JsonSerializerOptions instance is then used not only as a simple bag for options information, but also as a place to store all of that state the serializer built up, enabling it to be shared from call to call. Prior to .NET 7, this meant that passing a new JsonSerializerOptions instance to each call resulted in a massive performance cliff. In .NET 7, the caching scheme was improved to combat the problems here, but even with those mitigations, there’s still significant overhead to using a new JsonSerializerOptions instance each time. Instead, a JsonSerializerOptions instance should be cached and reused.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Text.Json;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly string _json = """{ "Title":"Performance Improvements in .NET 8", "Author":"Stephen Toub", }""";
private readonly JsonSerializerOptions _options = new JsonSerializerOptions { AllowTrailingCommas = true };
[Benchmark(Baseline = true)]
public BlogData Deserialize_New() => JsonSerializer.Deserialize<BlogData>(_json, new JsonSerializerOptions { AllowTrailingCommas = true });
[Benchmark]
public BlogData Deserialize_Cached() => JsonSerializer.Deserialize<BlogData>(_json, _options);
public struct BlogData
{
public string Title { get; set; }
public string Author { get; set; }
}
}| Method | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|
| Deserialize_New | 736.5 ns | 1.00 | 358 B | 1.00 |
| Deserialize_Cached | 290.2 ns | 0.39 | 176 B | 0.49 |
Cryptography
Cryptography in .NET 8 sees a smattering of improvements, a few large ones and a bunch of smaller ones that contribute to removing some overhead across the system.
One of the larger improvements, specific to Windows because it’s about switching what functionality is employed from the underlying OS, comes from dotnet/runtime#76277. Windows CNG (“Next Generation”) provides two libraries: bcrypt.dll and ncrypt.dll. The former provides support for “ephemeral” operations, ones where the cryptographic key is in-memory only and generated on the fly as part of an operation. The latter supports both ephemeral and persisted-key operations, and as a result much of the .NET support has been based on ncrypt.dll since it’s more universal. This, however, can add unnecessary expense, as all of the operations are handled out-of-process by the lsass.exe service, and thus require remote procedure calls, which add overhead. This PR switches RSA ephemeral operations over to using bcrypt instead of ncrypt, and the results are noteworthy (in the future, we expect other algorithms to also switch).
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Runtime.CompilerServices;
using System.Security.Cryptography;
using System.Security.Cryptography.X509Certificates;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
[MemoryDiagnoser(displayGenColumns: false)]
[SkipLocalsInit]
public class Tests
{
private static readonly RSA s_rsa = RSA.Create();
private static readonly byte[] s_signed = s_rsa.SignHash(new byte[256 / 8], HashAlgorithmName.SHA256, RSASignaturePadding.Pkcs1);
private static readonly byte[] s_encrypted = s_rsa.Encrypt(new byte[3], RSAEncryptionPadding.OaepSHA256);
private static readonly X509Certificate2 s_cert = new X509Certificate2(Convert.FromBase64String("""
MIIE7DCCA9SgAwIBAgITMwAAALARrwqL0Duf3QABAAAAsDANBgkqhkiG9w0BAQUFADB5MQswCQYDVQQGEwJVUzETMBEGA1UECBMKV2FzaGluZ3RvbjEQMA4GA1UEBxMH
UmVkbW9uZDEeMBwGA1UEChMVTWljcm9zb2Z0IENvcnBvcmF0aW9uMSMwIQYDVQQDExpNaWNyb3NvZnQgQ29kZSBTaWduaW5nIFBDQTAeFw0xMzAxMjQyMjMzMzlaFw0x
NDA0MjQyMjMzMzlaMIGDMQswCQYDVQQGEwJVUzETMBEGA1UECBMKV2FzaGluZ3RvbjEQMA4GA1UEBxMHUmVkbW9uZDEeMBwGA1UEChMVTWljcm9zb2Z0IENvcnBvcmF0
aW9uMQ0wCwYDVQQLEwRNT1BSMR4wHAYDVQQDExVNaWNyb3NvZnQgQ29ycG9yYXRpb24wggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQDor1yiIA34KHy8BXt/
re7rdqwoUz8620B9s44z5lc/pVEVNFSlz7SLqT+oN+EtUO01Fk7vTXrbE3aIsCzwWVyp6+HXKXXkG4Unm/P4LZ5BNisLQPu+O7q5XHWTFlJLyjPFN7Dz636o9UEVXAhl
HSE38Cy6IgsQsRCddyKFhHxPuRuQsPWj/ov0DJpOoPXJCiHiquMBNkf9L4JqgQP1qTXclFed+0vUDoLbOI8S/uPWenSIZOFixCUuKq6dGB8OHrbCryS0DlC83hyTXEmm
ebW22875cHsoAYS4KinPv6kFBeHgD3FN/a1cI4Mp68fFSsjoJ4TTfsZDC5UABbFPZXHFAgMBAAGjggFgMIIBXDATBgNVHSUEDDAKBggrBgEFBQcDAzAdBgNVHQ4EFgQU
WXGmWjNN2pgHgP+EHr6H+XIyQfIwUQYDVR0RBEowSKRGMEQxDTALBgNVBAsTBE1PUFIxMzAxBgNVBAUTKjMxNTk1KzRmYWYwYjcxLWFkMzctNGFhMy1hNjcxLTc2YmMw
NTIzNDRhZDAfBgNVHSMEGDAWgBTLEejK0rQWWAHJNy4zFha5TJoKHzBWBgNVHR8ETzBNMEugSaBHhkVodHRwOi8vY3JsLm1pY3Jvc29mdC5jb20vcGtpL2NybC9wcm9k
dWN0cy9NaWNDb2RTaWdQQ0FfMDgtMzEtMjAxMC5jcmwwWgYIKwYBBQUHAQEETjBMMEoGCCsGAQUFBzAChj5odHRwOi8vd3d3Lm1pY3Jvc29mdC5jb20vcGtpL2NlcnRz
L01pY0NvZFNpZ1BDQV8wOC0zMS0yMDEwLmNydDANBgkqhkiG9w0BAQUFAAOCAQEAMdduKhJXM4HVncbr+TrURE0Inu5e32pbt3nPApy8dmiekKGcC8N/oozxTbqVOfsN
4OGb9F0kDxuNiBU6fNutzrPJbLo5LEV9JBFUJjANDf9H6gMH5eRmXSx7nR2pEPocsHTyT2lrnqkkhNrtlqDfc6TvahqsS2Ke8XzAFH9IzU2yRPnwPJNtQtjofOYXoJto
aAko+QKX7xEDumdSrcHps3Om0mPNSuI+5PNO/f+h4LsCEztdIN5VP6OukEAxOHUoXgSpRm3m9Xp5QL0fzehF1a7iXT71dcfmZmNgzNWahIeNJDD37zTQYx2xQmdKDku/
Og7vtpU6pzjkJZIIpohmgg==
"""));
[Benchmark]
public void Encrypt()
{
Span<byte> src = stackalloc byte[3];
Span<byte> dest = stackalloc byte[s_rsa.KeySize >> 3];
s_rsa.TryEncrypt(src, dest, RSAEncryptionPadding.OaepSHA256, out _);
}
[Benchmark]
public void Decrypt()
{
Span<byte> dest = stackalloc byte[s_rsa.KeySize >> 3];
s_rsa.TryDecrypt(s_encrypted, dest, RSAEncryptionPadding.OaepSHA256, out _);
}
[Benchmark]
public void Verify()
{
Span<byte> hash = stackalloc byte[256 >> 3];
s_rsa.VerifyHash(hash, s_signed, HashAlgorithmName.SHA256, RSASignaturePadding.Pkcs1);
}
[Benchmark]
public void VerifyFromCert()
{
using RSA rsa = s_cert.GetRSAPublicKey();
Span<byte> sig = stackalloc byte[rsa.KeySize >> 3];
ReadOnlySpan<byte> hash = sig.Slice(0, 256 >> 3);
rsa.VerifyHash(hash, sig, HashAlgorithmName.SHA256, RSASignaturePadding.Pkcs1);
}
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| Encrypt | .NET 7.0 | 132.79 us | 1.00 | 56 B | 1.00 |
| Encrypt | .NET 8.0 | 19.72 us | 0.15 | – | 0.00 |
| Decrypt | .NET 7.0 | 653.77 us | 1.00 | 57 B | 1.00 |
| Decrypt | .NET 8.0 | 538.25 us | 0.82 | – | 0.00 |
| Verify | .NET 7.0 | 94.92 us | 1.00 | 56 B | 1.00 |
| Verify | .NET 8.0 | 16.09 us | 0.17 | – | 0.00 |
| VerifyFromCert | .NET 7.0 | 525.78 us | 1.00 | 721 B | 1.00 |
| VerifyFromCert | .NET 8.0 | 31.60 us | 0.06 | 696 B | 0.97 |
For cases where implementations are still using ncrypt, there are however ways we can still avoid of some of the remote procedure calls. dotnet/runtime#89599 does so by caching some information (in particular the key size) that doesn’t change but that still otherwise results in these remote procedure calls.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Security.Cryptography;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly byte[] _emptyDigest = new byte[256 / 8];
private byte[] _rsaSignedHash, _ecdsaSignedHash;
private RSACng _rsa;
private ECDsaCng _ecdsa;
[GlobalSetup]
public void Setup()
{
_rsa = new RSACng(2048);
_rsaSignedHash = _rsa.SignHash(_emptyDigest, HashAlgorithmName.SHA256, RSASignaturePadding.Pss);
_ecdsa = new ECDsaCng(256);
_ecdsaSignedHash = _ecdsa.SignHash(_emptyDigest);
}
[Benchmark]
public bool Rsa_VerifyHash() => _rsa.VerifyHash(_emptyDigest, _rsaSignedHash, HashAlgorithmName.SHA256, RSASignaturePadding.Pss);
[Benchmark]
public bool Ecdsa_VerifyHash() => _ecdsa.VerifyHash(_emptyDigest, _ecdsaSignedHash);
}| Method | Toolchain | Mean | Ratio |
|---|---|---|---|
| Rsa_VerifyHash | .NET 7.0 | 130.27 us | 1.00 |
| Rsa_VerifyHash | .NET 8.0 | 75.30 us | 0.58 |
| Ecdsa_VerifyHash | .NET 7.0 | 400.23 us | 1.00 |
| Ecdsa_VerifyHash | .NET 8.0 | 343.69 us | 0.86 |
The System.Format.Asn1 library provides the support used for encoding various data structures used in cryptographic protocols. For example, AsnWriter is used as part of CertificateRequest to create the byte[] that’s handed off to the X509Certificate2‘s constructor. As part of this, it relies heavily on OIDs (object identifiers) used to uniquely identify things like specific cryptographic algorithms. dotnet/runtime#75485 imbues AsnReader and AsnWriter with knowledge of the most-commonly used OIDs, making reading and writing with them significantly faster.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Formats.Asn1;
using System.Runtime.CompilerServices;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly AsnWriter _writer = new AsnWriter(AsnEncodingRules.DER);
[Benchmark]
public void Write()
{
_writer.Reset();
_writer.WriteObjectIdentifier("1.2.840.10045.4.3.3"); // ECDsa with SHA384
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Write | .NET 7.0 | 608.50 ns | 1.00 |
| Write | .NET 8.0 | 33.69 ns | 0.06 |
Interestingly, this PR does most of its work in two large switch statements. The first is a nice example of using C# list patterns to switch over a span of bytes and efficiently match to a case. The second is a great example of the C# compiler optimization mentioned earlier around switches and length bucketing. The internal WellKnownOids.GetContents function this adds to do the lookup is based on a giant switch with ~100 cases. The C# compiler ends up generating a switch over the length of the supplied OID string, and then in each length bucket, it either does a sequential scan through the small number of keys in that bucket, or it does a secondary switch over the character at a specific offset into the input, due to all of the keys having a discriminating character at that position.
Another interesting change comes in RandomNumberGenerator, which is the cryptographically-secure RNG in System.Security.Cryptography (as opposed to the non-cryptographically secure System.Random). RandomNumberGenerator provides a GetNonZeroBytes bytes method, which is the same as GetBytes but which promises not to yield any 0 values. It does so by using GetBytes, finding any produced 0s, removing them, and then calling GetBytes again to replace all of the 0 values (if that call happens to produce any 0s, then the process repeats). The previous implementation of GetNonZeroBytes was nicely using the vectorized IndexOf((byte)0) to search for a 0. Once it found one, however, it would shift down one at a time the rest of the bytes until the next zero. Since we expect 0s to be rare (on average, they should only occur once ever 256 generated bytes), it’s much more efficient to search for the next 0 using a vectorized operation, and then shift everything down using a vectorized memory move operation. And that’s exactly what dotnet/runtime#81340 does.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using System.Security.Cryptography;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private static readonly RandomNumberGenerator s_rng = RandomNumberGenerator.Create();
private readonly byte[] _bytes = new byte[1024];
[Benchmark]
public void GetNonZeroBytes() => s_rng.GetNonZeroBytes(_bytes);
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| GetNonZeroBytes | .NET 7.0 | 1,115.8 ns | 1.00 |
| GetNonZeroBytes | .NET 8.0 | 650.8 ns | 0.58 |
Finally, a variety of changes went in to reduce allocation:
AsnWriternow also has a constructor that lets a caller presize its internal buffer, thanks to dotnet/runtime#73535. That new constructor is then used in dotnet/runtime#81626 to improve throughput on other operations.- dotnet/runtime#75138 removes a
stringallocation as part of reading certificates on Linux. Stack allocation and spans are used along withEncoding.ASCII.GetString(ReadOnlySpan<byte>, Span<char>)instead ofEncoding.ASCII.GetString(byte[])that produces astring. ECDsa‘sLegalKeySizesdon’t change. The property hands back aKeySizes[]array, and out of precaution the property needs to return a new array on each access, however the actualKeySizesinstances are immutable. dotnet/runtime#76156 caches theseKeySizesinstances.
Logging
Logging, along with telemetry, is the lifeblood of any service. The more logging one incorporates, the more information is available to diagnose issues. But of course the more logging one incorporates, the more resources are possibly spent on logging, and thus it’s desirable for logging-related code to be as efficient as possible.
One issue that’s plagued some applications is in Microsoft.Extensions.Logging‘s LoggerFactory.CreateLogger method. Some libraries are passed an ILoggerFactory, call CreateLogger once, and then store and use that logger for all subsequent interactions; in such cases, the overhead of CreateLogger isn’t critical. However, other code paths, including some from ASP.NET, end up needing to “create” a logger on demand each time it needs to log. That puts significant stress on CreateLogger, incurring its overhead as part of every logging operation. To reduce these overheads, LoggerFactory.CreateLogger has long maintained a Dictionary<TKey, TValue> cache of all logger instances it’s created: pass in the same categoryName, get back the same ILogger instance (hence why I put “create” in quotes a few sentences back). However, that cache is also protected by a lock. That not only means every CreateLogger call is incurring the overhead of acquiring and releasing a lock, but if that lock is contended (meaning others are trying to access it at the same time), that contention can dramatically increase the costs associated with the cache. This is the perfect use case for a ConcurrentDictionary<TKey, TValue>, which is optimized with lock-free support for reads, and that’s exactly how dotnet/runtime#87904 improves performance here. We still want to perform some work atomically when there’s a cache miss, so the change uses “double-checked locking”: it performs a read on the dictionary, and only if the lookup fails does it then fall back to taking the lock, after which it checks the dictionary again, and only if that second read fails does it proceed to create the new logger and store it. The primary benefit of ConcurrentDictionary<TKey, TValue> here is it enables us to have that up-front read, which might execute concurrently with another thread mutating the dictionary; that’s not safe with Dictionary<,> but is with ConcurrentDictionary<,>. This measurably lowers the cost of even uncontended access, but dramatically reduces the overhead when there’s significant contention.
// dotnet run -c Release -f net7.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Environments;
using BenchmarkDotNet.Jobs;
using BenchmarkDotNet.Running;
using Microsoft.Extensions.Logging;
var config = DefaultConfig.Instance
.AddJob(Job.Default.WithRuntime(CoreRuntime.Core70).WithNuGet("Microsoft.Extensions.Logging", "7.0.0").AsBaseline())
.AddJob(Job.Default.WithRuntime(CoreRuntime.Core80).WithNuGet("Microsoft.Extensions.Logging", "8.0.0-rc.1.23419.4"));
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args, config);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "NuGetReferences")]
public class Tests
{
private readonly LoggerFactory _factory = new();
[Benchmark]
public void Serial() => _factory.CreateLogger("test");
[Benchmark]
public void Concurrent()
{
Parallel.ForEach(Enumerable.Range(0, Environment.ProcessorCount), (i, ct) =>
{
for (int j = 0; j < 1_000_000; j++)
{
_factory.CreateLogger("test");
}
});
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Serial | .NET 7.0 | 32.775 ns | 1.00 |
| Serial | .NET 8.0 | 7.734 ns | 0.24 |
| Concurrent | .NET 7.0 | 509,271,719.571 ns | 1.00 |
| Concurrent | .NET 8.0 | 21,613,226.316 ns | 0.04 |
(The same double-checked locking approach is also employed in dotnet/runtime#73893 from @Daniel-Svensson, in that case for the Data Contract Serialization library. Similarly, dotnet/runtime#82536 replaces a locked Dictionary<,> with a ConcurrentDictionary<,>, there in System.ComponentModel.DataAnnotations. In that case, it just uses ConcurrentDictionary<,>‘s GetOrAdd method, which provides optimistic concurrency; the supplied delegate could be invoked multiple times in the case of contention to initialize a value for a given key, but only one such value will ever be published for all to consume.)
Also related to CreateLogger, there’s a CreateLogger(this ILoggerFactory factory, Type type) extension method and a CreateLogger<T>(this ILoggerFactory factory) extension method, both of which infer the category to use from specified type, using its pretty-printed name. Previously that pretty-printing involved always allocating both a StringBuilder to build up the name and the resulting string. However, those are only necessary for more complex types, e.g. generic types, array types, and generic type parameters. For the common case, dotnet/runtime#79325 from @benaadams avoids those overheads, which were incurred even when the request for the logger could be satisfied from the cache, because the name was necessary to even perform the cache lookup.
// dotnet run -c Release -f net7.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Environments;
using BenchmarkDotNet.Jobs;
using BenchmarkDotNet.Running;
using Microsoft.Extensions.Logging;
var config = DefaultConfig.Instance
.AddJob(Job.Default.WithRuntime(CoreRuntime.Core70).WithNuGet("Microsoft.Extensions.Logging", "7.0.0").AsBaseline())
.AddJob(Job.Default.WithRuntime(CoreRuntime.Core80).WithNuGet("Microsoft.Extensions.Logging", "8.0.0-rc.1.23419.4"));
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args, config);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "NuGetReferences")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly LoggerFactory _factory = new();
[Benchmark]
public ILogger CreateLogger() => _factory.CreateLogger<Tests>();
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| CreateLogger | .NET 7.0 | 156.77 ns | 1.00 | 160 B | 1.00 |
| CreateLogger | .NET 8.0 | 70.82 ns | 0.45 | 24 B | 0.15 |
There are also changes in .NET 8 to reduce overheads when logging actually does occur, and one such change makes use of a new .NET 8 feature we’ve already talked about: CompositeFormat. CompositeFormat isn’t currently used in many places throughout the core libraries, as most of the formatting they do is either with strings known at build time (in which case they use interpolated strings) or are on exceptional code paths (in which case we generally don’t want to regress working set or startup in order to optimize error conditions). However, there is one key place CompositeFormat is now used: in LoggerMessage.Define. This method is similar in concept to CompositeFormat: rather than having to redo work every time you want to log something, instead spend some more resources to frontload and cache that work, in order to optimize subsequent usage… that’s what LoggerMessage.Define does, just for logging. Define returns a strongly-typed delegate that can then be used any time logging should be performed. As of the same PR that introduced CompositeFormat, LoggerMessage.Define now also constructs a CompositeFormat under the covers, and uses that instance to perform any formatting work necessary based on the log message pattern provided (previously it would just call string.Format as part of every log operation that needed it).
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using Microsoft.Extensions.Logging;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public class Tests
{
private readonly Action<ILogger, int, Exception> _message = LoggerMessage.Define<int>(LogLevel.Critical, 1, "The value is {0}.");
private readonly ILogger _logger = new MyLogger();
[Benchmark]
public void Format() => _message(_logger, 42, null);
sealed class MyLogger : ILogger
{
public IDisposable BeginScope<TState>(TState state) => null;
public bool IsEnabled(LogLevel logLevel) => true;
public void Log<TState>(LogLevel logLevel, EventId eventId, TState state, Exception exception, Func<TState, Exception, string> formatter) => formatter(state, exception);
}
}| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Format | .NET 7.0 | 127.04 ns | 1.00 |
| Format | .NET 8.0 | 91.78 ns | 0.72 |
LoggerMessage.Define is used as part of the logging source generator, so the benefits there implicitly accrue not only to direct usage of LoggerMessage.Define but also to any use of the generator. We can see that in this benchmark here:
// For this test, you'll also need to add:
// <PackageReference Include="Microsoft.Extensions.Logging.Abstractions" Version="7.0.0" />
// to the benchmarks.csproj's <ItemGroup>.
// dotnet run -c Release -f net7.0 --filter "*" --runtimes net7.0 net8.0
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using Microsoft.Extensions.Logging;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public partial class Tests
{
private readonly ILogger _logger = new MyLogger();
[Benchmark]
public void Log() => LogValue(42);
[LoggerMessage(1, LogLevel.Critical, "The value is {Value}.")]
private partial void LogValue(int value);
sealed class MyLogger : ILogger
{
public IDisposable BeginScope<TState>(TState state) => null;
public bool IsEnabled(LogLevel logLevel) => true;
public void Log<TState>(LogLevel logLevel, EventId eventId, TState state, Exception exception, Func<TState, Exception, string> formatter) => formatter(state, exception);
}
}Note the LogValue method, which is declared as a partial method with the LoggerMessage attribute applied to it. The generator will see that and inject into my application the following implementation (the only changes I’ve made to this copied code are removing the fully-qualified names, for readability), which as is visible here uses LoggerMessage.Define:
partial class Tests
{
[GeneratedCode("Microsoft.Extensions.Logging.Generators", "7.0.0")]
private static readonly Action<ILogger, Int32, Exception?> __LogValueCallback =
LoggerMessage.Define<Int32>(LogLevel.Information, new EventId(1, nameof(LogValue)), "The value is {Value}.", new LogDefineOptions() { SkipEnabledCheck = true });
[GeneratedCode("Microsoft.Extensions.Logging.Generators", "7.0.0")]
private partial void LogValue(Int32 value)
{
if (_logger.IsEnabled(LogLevel.Information))
{
__LogValueCallback(_logger, value, null);
}
}
}When running the benchmark, then, we can see the improvements that use CompositeFormat end up translating nicely:
| Method | Runtime | Mean | Ratio |
|---|---|---|---|
| Log | .NET 7.0 | 94.10 ns | 1.00 |
| Log | .NET 8.0 | 74.68 ns | 0.79 |
Other changes have also gone into reducing overheads in logging. Here’s the same LoggerMessage.Define benchmark as before, but I’ve tweaked two things:
- I’ve added
[MemoryDiagnoser]so that allocation is more visible. - I’ve explicitly controlled which NuGet package version is used for which run.
The Microsoft.Extensions.Logging.Abstractions package carries with it multiple “assets”; the v7.0.0 package, even though it’s “7.0.0,” carries with it a build for net7.0, for net6.0, for netstandard2.0, etc. Similarly, the v8.0.0 package, even though it’s “8.0.0,” carries with it a build for net8.0, for net7.0, and so on. Each of those is created from compiling the source for that Target Framework Moniker (TFM). Changes that are specific to a particular TFM, such as the change to use CompositeFormat, are only compiled into that build, but other improvements that aren’t specific to a particular TFM end up in all of them. As such, to be able to see improvements that have gone into the general code in the last year, we need to actually compare the two different NuGet packages, and can’t just compare the net8.0 vs net7.0 assets in the same package version.
// dotnet run -c Release -f net7.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Environments;
using BenchmarkDotNet.Jobs;
using BenchmarkDotNet.Running;
using Microsoft.Extensions.Logging;
var config = DefaultConfig.Instance
.AddJob(Job.Default.WithRuntime(CoreRuntime.Core70).WithNuGet("Microsoft.Extensions.Logging", "7.0.0").AsBaseline())
.AddJob(Job.Default.WithRuntime(CoreRuntime.Core80).WithNuGet("Microsoft.Extensions.Logging", "8.0.0-rc.1.23419.4"));
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args, config);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "NuGetReferences")]
[MemoryDiagnoser(displayGenColumns: false)]
public class Tests
{
private readonly Action<ILogger, int, Exception> _message = LoggerMessage.Define<int>(LogLevel.Critical, 1, "The value is {0}.");
private readonly ILogger _logger = new MyLogger();
[Benchmark]
public void Format() => _message(_logger, 42, null);
sealed class MyLogger : ILogger
{
public IDisposable BeginScope<TState>(TState state) => null;
public bool IsEnabled(LogLevel logLevel) => true;
public void Log<TState>(LogLevel logLevel, EventId eventId, TState state, Exception exception, Func<TState, Exception, string> formatter) => formatter(state, exception);
}
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| Format | .NET 7.0 | 96.44 ns | 1.00 | 80 B | 1.00 |
| Format | .NET 8.0 | 46.75 ns | 0.48 | 56 B | 0.70 |
Notice that throughput has increased and allocation has dropped. That’s primarily due to dotnet/runtime#88560, which avoids boxing value type arguments as they’re being passed through the formatting logic.
dotnet/runtime#89160 is another interesting example, not because it’s a significant savings (it ends up saving an allocation per HTTP request made using an HttpClient created from an HttpClientFactory), but because of why the allocation is there in the first place. Consider this C# class:
public class C
{
public void M(int value)
{
Console.WriteLine(value);
LocalFunction();
void LocalFunction() => Console.WriteLine(value);
}
}We’ve got a method M that contains a local function LocalFunction that “closes over” M‘s int value argument. How does value find its way into that LocalFunction? Let’s look at a decompiled version of the IL the compiler generates:
public class C
{
public void M(int value)
{
<>c__DisplayClass0_0 <>c__DisplayClass0_ = default(<>c__DisplayClass0_0);
<>c__DisplayClass0_.value = value;
Console.WriteLine(<>c__DisplayClass0_.value);
<M>g__LocalFunction|0_0(ref <>c__DisplayClass0_);
}
[StructLayout(LayoutKind.Auto)]
[CompilerGenerated]
private struct <>c__DisplayClass0_0
{
public int value;
}
[CompilerGenerated]
private static void <M>g__LocalFunction|0_0(ref <>c__DisplayClass0_0 P_0)
{
Console.WriteLine(P_0.value);
}
}So, the compiler has emitted the LocalFunction as a static method, and it’s passed the state it needs by reference, with all of the state in a separate type (which the compiler refers to as a “display class”). Note that a) the instance of this type is constructed in M in order to store the value argument, and that all references to value, whether in M or in LocalFunction, are to the shared value on the display class, and b) that “class” is actually declared as a struct. That means we’re not going to incur any allocation as part of that data sharing. But now, let’s add a single keyword to our repro: add async to LocalFunction (I’ve elided some irrelevant code here for clarity):
public class C
{
public void M(int value)
{
<>c__DisplayClass0_0 <>c__DisplayClass0_ = new <>c__DisplayClass0_0();
<>c__DisplayClass0_.value = value;
Console.WriteLine(<>c__DisplayClass0_.value);
<>c__DisplayClass0_.<M>g__LocalFunction|0();
}
[CompilerGenerated]
private sealed class <>c__DisplayClass0_0
{
[StructLayout(LayoutKind.Auto)]
private struct <<M>g__LocalFunction|0>d : IAsyncStateMachine { ... }
public int value;
[AsyncStateMachine(typeof(<<M>g__LocalFunction|0>d))]
internal void <M>g__LocalFunction|0()
{
<<M>g__LocalFunction|0>d stateMachine = default(<<M>g__LocalFunction|0>d);
stateMachine.<>t__builder = AsyncVoidMethodBuilder.Create();
stateMachine.<>4__this = this;
stateMachine.<>1__state = -1;
stateMachine.<>t__builder.Start(ref stateMachine);
}
}
}The code for M looks almost the same, but there’s a key difference: instead of default(<>c__DisplayClass0_0), it has new <>c__DisplayClass0_0(). That’s because the display class now actually is a class rather than being a struct, and that’s because the state can no longer live on the stack; it’s being passed to an asynchronous method, which may need to continue to use it even after the stack has unwound. And that means it becomes more important avoiding these kinds of implicit closures when dealing with local functions that are asynchronous.
In this particular case, LoggingHttpMessageHandler (and LoggingScopeHttpMessageHandler) had a SendCoreAsync method that looked like this:
private Task<HttpResponseMessage> SendCoreAsync(HttpRequestMessage request, bool useAsync, CancellationToken cancellationToken)
{
ThrowHelper.ThrowIfNull(request);
return Core(request, cancellationToken);
async Task<HttpResponseMessage> Core(HttpRequestMessage request, CancellationToken cancellationToken)
{
...
HttpResponseMessage response = useAsync ? ... : ...;
...
}
}Based on the previous discussion, you likely see the problem here: useAsync is being implicitly closed over by the local function, resulting in this allocating a display class to pass that state in. The cited PR changed the code to instead be:
private Task<HttpResponseMessage> SendCoreAsync(HttpRequestMessage request, bool useAsync, CancellationToken cancellationToken)
{
ThrowHelper.ThrowIfNull(request);
return Core(request, useAsync, cancellationToken);
async Task<HttpResponseMessage> Core(HttpRequestMessage request, bool useAsync, CancellationToken cancellationToken)
{
...
HttpResponseMessage response = useAsync ? ... : ...;
...
}
}and, voila, the allocation is gone.
EventSource is another logging mechanism in .NET that’s lower-level and which is used by the core libraries for their logging needs. The runtime itself publishes its events for things like the GC and the JIT via an EventSource, something I relied on earlier in this post when tracking how many GCHandles were created (search above for GCHandleListener). When eventing is enabled for a particular source, that EventSource publishes a manifest describing the possible events and the shape of the data associated with each. While in the future, we aim to use a source generator to create that manifest at build time, today it’s all generated at run-time, using reflection to analyze the events defined on the EventSource-derived type and to dynamically build up the description. That unfortunately has some cost, which can measurably impact startup. Thankfully, one of the main contributors here is the manifest for that runtime source, NativeRuntimeEventSource, as it’s ever present, but it’s not actually necessary, since tools that consume this information already know about the well-documented schema. As such, dotnet/runtime#78213 stopped emitting the manifest for NativeRuntimeEventSource such that it doesn’t send a large amount of data across to the consumer that will subsequently ignore it. That prevented it from being sent, but it was still being created. dotnet/runtime#86850 from @n77y addressed a large chunk of that by reducing the costs of that generation. The effect of this is obvious if we do a .NET allocation profile of a simple nop console application.
class Program { static void Main() { } }On .NET 7, we observe this:
 And on .NET 8, that reduces to this:
And on .NET 8, that reduces to this:
 (In the future, hopefully this whole thing will go away due to precomputing the manifest.)
(In the future, hopefully this whole thing will go away due to precomputing the manifest.)
EventSource also relies heavily on interop, and as part of that it’s historically used delegate marshaling as part of implementing callbacks from native code. dotnet/runtime#79970 switches it over to using function pointers, which is not only more efficient, it eliminates this as one of the last uses of delegate marshaling in the core libraries. That means for Native AOT, all of the code associated with supporting delegate marshaling can typically now be trimmed away, reducing application size further.
Configuration
Configuration support is critical for many services and applications, such that information necessary to the execution of the code can be extracted from the code, whether that be into a JSON file, environment variables, Azure Key Vault, wherever. This information then needs to be loaded into the application in a convenient manner, typically at startup but also potentially any time the configuration is seen to change. It’s thus not a typical candidate for throughput-focused optimization, but it is still valuable to drive associated costs down, especially to help with startup performance.
With Microsoft.Extensions.Configuration, configuration is handled primarily with a ConfigurationBuilder, an IConfiguration, and a “binder.” Using a ConfigurationBuilder, you add in the various sources of your configuration information (e.g. AddEnvironmentVariables, AddAzureKeyVault, etc.), and then you publish that as an IConfiguration instance. In typical use, you then extract from that IConfiguration the data you want by “binding” it to an object, meaning a Bind method populates the provided object with data from the configuration based on the shape of the object. Let’s measure the cost of that Bind specifically:
// For this test, you'll also need to add:
// <EnableConfigurationBindingGenerator>true</EnableConfigurationBindingGenerator>
// <Features>$(Features);InterceptorsPreview</Features>
// to the PropertyGroup in the benchmarks.csproj file, and add:
// <PackageReference Include="Microsoft.Extensions.Configuration" Version="7.0.0" />
// <PackageReference Include="Microsoft.Extensions.Configuration.EnvironmentVariables" Version="7.0.0" />
// <PackageReference Include="Microsoft.Extensions.Configuration.Binder" Version="8.0.0-rc.1.23419.4" Condition="'$(TargetFramework)'=='net8.0'" />
// to the ItemGroup.
// dotnet run -c Release -f net7.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Environments;
using BenchmarkDotNet.Jobs;
using BenchmarkDotNet.Running;
using Microsoft.Extensions.Configuration;
var config = DefaultConfig.Instance
.AddJob(Job.Default.WithRuntime(CoreRuntime.Core70).WithNuGet("Microsoft.Extensions.Configuration", "7.0.0").AsBaseline())
.AddJob(Job.Default.WithRuntime(CoreRuntime.Core80)
.WithNuGet("Microsoft.Extensions.Configuration", "8.0.0-rc.1.23419.4")
.WithNuGet("Microsoft.Extensions.Configuration.Binder", "8.0.0-rc.1.23419.4"));
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args, config);
[HideColumns("Error", "StdDev", "Median", "RatioSD", "NuGetReferences")]
[MemoryDiagnoser(displayGenColumns: false)]
public partial class Tests
{
private readonly MyConfigSection _data = new();
private IConfiguration _config;
[GlobalSetup]
public void Setup()
{
Environment.SetEnvironmentVariable("MyConfigSection__Message", "Hello World!");
_config = new ConfigurationBuilder()
.AddEnvironmentVariables()
.Build();
}
[Benchmark]
public void Load() => _config.Bind("MyConfigSection", _data);
internal sealed class MyConfigSection
{
public string Message { get; set; }
}
}| Method | Runtime | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| Load | .NET 7.0 | 1,747.15 ns | 1.00 | 1328 B | 1.00 |
| Load | .NET 8.0 | 73.45 ns | 0.04 | 112 B | 0.08 |
Whoa.
Much of that cost in .NET 7 comes from what I alluded to earlier when I said “based on the shape of the object.” That Bind call is using this extension method defined in the Microsoft.Extensions.Configuration.ConfigurationBinder type:
public static void Bind(this IConfiguration configuration, string key, object? instance)How does it know what data to extract from the configuration and where on the object to store it? Reflection, of course. That means that every Bind call is using reflection to walk the supplied object‘s type information, and is using reflection to store the configuration data onto the instance. That’s not cheap.
What changes then in .NET 8? The mention of “EnableConfigurationBindingGenerator” in the benchmark code above probably gives it away, but the answer is there’s a new source generator for configuration in .NET 8. This source generator was initially introduced in dotnet/runtime#82179 and was then improved upon in a multitude of PRs like dotnet/runtime#84154, dotnet/runtime#86076, dotnet/runtime#86285, and dotnet/runtime#86365. The crux of the idea behind the configuration source generator is to emit a replacement for that Bind method, one that knows exactly what type is being populated and can do all the examination of its shape at build-time rather than at run-time via reflection.
“Replacement.” For anyone familiar with C# source generators, this might be setting off alarm bells in your head. Source generators plug into the compiler and are handed all the data the compiler has about the code being compiled; the source generator is then able to augment that data, generating additional code into separate files that the compiler then also compiles into the same assembly. Source generators are able to add code but they can’t rewrite the code. This is why you see source generators like the Regex source generator or the LibraryImport source generator or the LoggerMessage source generator relying on partial methods: the developer writes the partial method declaration for the method they then consume in their code, and then separately the generator emits a partial method definition to supply the implementation for that method. How then is this new configuration generator able to replace a call to an existing method? I’m glad you asked! It takes advantage of a new preview feature of the C# compiler, added primarily in dotnet/roslyn#68564: interceptors.
Consider this program, defined in a /home/stoub/benchmarks/Program.cs file (and where the associated .csproj contains <Features>$(Features);InterceptorsPreview</Features> to enable the preview feature):
// dotnet run -c Release -f net8.0
using System.Runtime.CompilerServices;
Console.WriteLine("Hello World!");
// ----------------------------------
internal static class Helpers
{
[InterceptsLocation(@"/home/stoub/benchmarks/Program.cs", 5, 9)]
internal static void NotTheRealWriteLine(string message) =>
Console.WriteLine($"The message was '{message}'.");
}
namespace System.Runtime.CompilerServices
{
[AttributeUsage(AttributeTargets.Method, AllowMultiple = true)]
file sealed class InterceptsLocationAttribute : Attribute
{
public InterceptsLocationAttribute(string filePath, int line, int column) { }
}
}This is a “hello world” application, except not quite the one-liner you’re used to. There’s a call to Console.WriteLine, but there’s also a method decorated with InterceptsLocation. That method has the same signature as the Console.WriteLine being used, and the attribute is pointing to the WriteLine method call in Program.cs‘s line 5 column 9. When the compiler sees this, it will change that call from Console.WriteLine("Hello World!") to instead be Helpers.NotTheRealWriteLine("Hello World!"), allowing this other method in the same compilation unit to intercept the original call. This interceptor needn’t be in the same file, so a source generator can analyze the code handed to it, find a call it wants to intercept, and augment the compilation unit with such an interceptor.

That’s exactly what the configuration source generator does. In this benchmark, for example, the core of what the source generator emits is here (I’ve elided stuff that’s not relevant to this discussion):
[InterceptsLocationAttribute(@".../LoggerFilterConfigureOptions.cs", 21, 35)]
public static void Bind_TestsMyConfigSection(this IConfiguration configuration, string key, object? obj)
{
...
var typedObj = (Tests.MyConfigSection)obj;
BindCore(configuration.GetSection(key), ref typedObj, binderOptions: null);
}
public static void BindCore(IConfiguration configuration, ref Tests.MyConfigSection obj, BinderOptions? binderOptions)
{
...
obj.Message = configuration["Message"]!;
}We can see the generated Bind method is strongly typed for my MyConfigSection type, and the generated Bind_TestsMyConfigSection method it invokes extracts the "Message" value from the configuration and stores it directly into the property. No reflection anywhere in sight.
This is obviously great for throughput, but that actually wasn’t the primary goal for this particular source generator. Rather, it was in support of Native AOT and trimming. Without direct use of various portions of the object model for the bound object, the trimmer could see portions of it as being unused and trim them away (such as setters for properties that are only read by the application), at which point that data would not be available (because the deserializer would see the properties as being get-only). By having everything strongly typed in the generated source, that issue goes away. And as a bonus, if there isn’t other use of the reflection stack keeping it rooted, the trimmer can get rid of that, too.
Bind isn’t the only method that’s replaceable. ConfigurationBinder provides other methods consumers can use, like GetValue, which just retrieves the value associated with a specific key, and the configuration source generator can emit replacements for those as well. dotnet/runtime#87935 modified Microsoft.Extensions.Logging.Configuration to employ the config generator for this purpose, as it uses GetValue in its LoadDefaultConfigValues method:
private void LoadDefaultConfigValues(LoggerFilterOptions options)
{
if (_configuration == null)
{
return;
}
options.CaptureScopes = _configuration.GetValue(nameof(options.CaptureScopes), options.CaptureScopes);
...
}And if we look at what’s in the compiled binary (via ILSpy), we see this:

So, the code looks the same, but the actual target of the GetValue is the intercepting method emitted by the source generator. When that change merged, it knocked ~640Kb off the size of the ASP.NET app being used as an exemplar to track Native AOT app size!
Once data has been loaded from the configuration system into some kind of model, often the next step is to validate that the supplied data meets requirements. Whether a data model is populated once from configuration or per request for user input, a typical approach for achieving such validation is via the System.ComponentModel.DataAnnotations namespace. This namespace supplies attributes that can be applied to members of a type to indicate constraints the data must satisfy, such as [Required] to indicate the data must be supplied or [MinLength(...)] to indicate a minimum length for a string, and .NET 8 adds additional attributes via dotnet/runtime#82311, for example [Base64String]. On top of this, Microsoft.Extensions.Options.DataAnnotationValidateOptions provides an implementation of the IValidateOptions<TOptions> interface (an implementation of which is typically retrieved via DI) for validating models based on data annotations, and as you can probably guess, it does so via reflection. As is a trend you’re probably picking up on, for many such areas involving reflection, .NET has been moving to add source generators that can do at build-time what would have otherwise been done at run-time; that’s the case here as well. As of dotnet/runtime#87587, the Microsoft.Extensions.Options package in .NET 8 now includes a source generator that creates an implementation of IValidateOptions<TOptions> for a specific TOptions type.
For example, consider this benchmark:
// For this test, you'll also need to add these:
// <PackageReference Include="Microsoft.Extensions.Options" Version="8.0.0-rc.1.23419.4" />
// <PackageReference Include="Microsoft.Extensions.Options.DataAnnotations" Version="8.0.0-rc.1.23419.4" />
// to the benchmarks.csproj's <ItemGroup>.
// dotnet run -c Release -f net8.0 --filter "*"
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using Microsoft.Extensions.Options;
using System.ComponentModel.DataAnnotations;
BenchmarkSwitcher.FromAssembly(typeof(Tests).Assembly).Run(args);
[HideColumns("Error", "StdDev", "Median", "RatioSD")]
public partial class Tests
{
private readonly DataAnnotationValidateOptions<MyOptions> _davo = new DataAnnotationValidateOptions<MyOptions>(null);
private readonly MyOptionsValidator _ov = new();
private readonly MyOptions _options = new() { Path = "1234567890", Address = "http://localhost/path", PhoneNumber = "555-867-5309" };
[Benchmark(Baseline = true)]
public ValidateOptionsResult WithReflection() => _davo.Validate(null, _options);
[Benchmark]
public ValidateOptionsResult WithSourceGen() => _ov.Validate(null, _options);
public sealed class MyOptions
{
[Length(1, 10)]
public string Path { get; set; }
[Url]
public string Address { get; set; }
[Phone]
public string PhoneNumber { get; set; }
}
[OptionsValidator]
public partial class MyOptionsValidator : IValidateOptions<MyOptions> { }
}Note the [OptionsValidator] at the end. It’s applied to a partial class that implements IValidatOptions<MyOptions>, which tells the source generator to emit the implementation for this interface in order to validate MyOptions. It ends up emitting code like this (which I’ve simplified a tad, e.g. removing fully-qualified namespaces, for the purposes of this post):
[GeneratedCode("Microsoft.Extensions.Options.SourceGeneration", "8.0.8.41903")]
public ValidateOptionsResult Validate(string? name, MyOptions options)
{
var context = new ValidationContext(options);
var validationResults = new List<ValidationResult>();
var validationAttributes = new List<ValidationAttribute>(2);
ValidateOptionsResultBuilder? builder = null;
context.MemberName = "Path";
context.DisplayName = string.IsNullOrEmpty(name) ? "MyOptions.Path" : $"{name}.Path";
validationAttributes.Add(__OptionValidationStaticInstances.__Attributes.A1);
validationAttributes.Add(__OptionValidationStaticInstances.__Attributes.A2);
if (!Validator.TryValidateValue(options.Path, context, validationResults, validationAttributes))
(builder ??= new()).AddResults(validationResults);
context.MemberName = "Address";
context.DisplayName = string.IsNullOrEmpty(name) ? "MyOptions.Address" : $"{name}.Address";
validationResults.Clear();
validationAttributes.Clear();
validationAttributes.Add(__OptionValidationStaticInstances.__Attributes.A3);
if (!Validator.TryValidateValue(options.Address, context, validationResults, validationAttributes))
(builder ??= new()).AddResults(validationResults);
context.MemberName = "PhoneNumber";
context.DisplayName = string.IsNullOrEmpty(name) ? "MyOptions.PhoneNumber" : $"{name}.PhoneNumber";
validationResults.Clear();
validationAttributes.Clear();
validationAttributes.Add(__OptionValidationStaticInstances.__Attributes.A4);
if (!Validator.TryValidateValue(options.PhoneNumber, context, validationResults, validationAttributes))
(builder ??= new()).AddResults(validationResults);
return builder is not null ? builder.Build() : ValidateOptionsResult.Success;
}eliminating the need to use reflection to discover the relevant properties and their attribution. The benchmark results highlight the benefits:
| Method | Mean | Ratio |
|---|---|---|
| WithReflection | 2,926.2 ns | 1.00 |
| WithSourceGen | 403.5 ns | 0.14 |
Peanut Butter
In every .NET release, there are a multitude of welcome PRs that make small improvements. These changes on their own typically don’t “move the needle,” don’t on their own make very measurable end-to-end changes. However, an allocation removed here, an unnecessary bounds check removed there, it all adds up. Constantly working to remove this “peanut butter,” as we often refer to it (a thin smearing of overhead across everything), helps improve the performance of the platform in the aggregate.
Here are some examples from the last year:
- dotnet/runtime#77832. The
MemoryStreamtype provides a convenientToArray()method that gives you all the stream’s data as a newbyte[]. But while convenient, it’s a potentially large allocation and copy. The lesser knownGetBufferandTryGetBuffermethods give one access to theMemoryStream‘s buffer directly, without incurring an allocation or copy. This PR replaced use ofToArrayinSystem.Private.Xmland inSystem.Reflection.Metadatathat were better served byGetBuffer(). Not only did it remove unnecessary allocation, as a bonus it also resulted in less code. - dotnet/runtime#80523 and dotnet/runtime#80389 removed string allocations from the
System.ComponentModel.Annotationslibrary.CreditCardAttributewas making two calls tostring.Replaceto remove'-'and' 'characters, but it was then looping over every character in the input… rather than creating new strings without those characters, the loop can simply skip over them. Similarly,PhoneAttributecontained 6string.Substringcalls, all of which could be replaced with simpleReadOnlySpan<char>slices. - dotnet/runtime#82041, dotnet/runtime#87479, and dotnet/runtime#80386 changed several hundred lines across dotnet/runtime to avoid various array and
stringallocation. In some cases it usedstackalloc, in othersArrayPool, in others simply deleting arrays that were never used, in others usingReadOnlySpan<char>and slicing. - dotnet/runtime#82411 from @xtqqczze and dotnet/runtime#82456 from @xtqqczze do a similar optimization to one discussed previously in the context of
SslStream. Here, they’re removingSafeHandleallocations in places where a simpletry/finallywith the rawIntPtrfor the handle suffices. - dotnet/runtime#82096 and dotnet/runtime#83138 decreased some costs by using newer constructs: string interpolation instead of concatenation so as to avoid some intermediary string allocations, and
u8instead ofEncoding.UTF8.GetBytesto avoid the transcoding overhead. - dotnet/runtime#75850 removed some allocations as part of initializing a
Dictionary<,>. The dictionary inTypeConvertergets populated with a fixed set of predetermined items, and as such it’s provided with a capacity so as to presize its internal arrays to avoid intermediate allocations as part of growing. However, the provided capacity was smaller than the number of items actually being added. This PR simply fixed the number, and voila, less allocation. - dotnet/runtime#81036 from @xtqqczze and dotnet/runtime#81039 from @xtqqczze helped eliminate some bounds checking in various components across the core libraries. Today the JIT compiler recognizes the pattern
for (int i = 0; i < arr.Length; i++) Use(arr[i]);, understanding that theican’t ever be negative nor greater than thearr‘s length, and thus eliminates the bounds check it would have otherwise emitted onarr[i]. However, the compiler doesn’t currently recognize the same thing forfor (int i = 0; i != arr.Length; i++) Use(arr[i]);. These PRs primarily replaced!=s with<s in order to help in some such cases (it also makes the code more idiomatic, and so was welcomed even in cases where it wasn’t actually helping with bounds checks). - dotnet/runtime#89030 fixed a case where a
Dictionary<T, T>was being used as a set. Changing it to instead beHashSet<T>saves on the internal storage for the values that end up being identical to the keys. - dotnet/runtime#78741 replaces a bunch of
Unsafe.SizeOf<T>()withsizeof(T)andUnsafe.As<TFrom, TTo>with pointer manipulation. Most of these are with managedTs, such that it used to not be possible to do. However, as of C# 11, more of these operations are possible, with conditions that were previously always errors now being downgraded to warnings (which can then be suppressed) in anunsafecontext. Such replacements generally won’t improve throughput, but they do make the binaries a bit smaller and require less work for the JIT, which can in turn help with startup time. dotnet/runtime#78914 takes advantage of this as well, this time to be able to pass a span as input to astring.Createcall. - dotnet/runtime#78737 from @Poppyto and dotnet/runtime#79345 from @Poppyto remove some
char[]allocations fromMicrosoft.Win32.Registryby replacing some code that was usingList<string>to build up a result and thenToArrayit at the end to get back astring[]. In the majority case, we know the exact required size ahead of time, and can avoid the extra allocations and copy by just using an array from the get-go. - dotnet/runtime#82598 from @huoyaoyuan also tweaked
Registry, taking advantage of a Win32 function that was added after the original code was written, in order to reduce the number of system calls required to delete a subtree. - Multiple changes went into
System.XmlandSystem.Runtime.Serialization.Xmlto streamline away peanut butter related to strings and arrays. dotnet/runtime#75452 from @TrayanZapryanov replaces multiplestring.Trimcalls with span trimming and slicing, taking advantage of the C# language’s recently added support for usingswitchoverReadOnlySpan<char>. dotnet/runtime#75946 removes some use ofToCharArray(these days, there’s almost always a better alternative thanstring.ToCharArray), while dotnet/runtime#82006 replaces somenew char[]with spans andstackalloc char[]. dotnet/runtime#85534 removed an unnecessary dictionary lookup, replacing a use ofContainsKeyfollowed by the indexer with justTryGetValue. dotnet/runtime#84888 from @mla-alm removed some synchronous I/O from the asynchronous code paths inXsdValidatingReader. dotnet/runtime#74955 from @TrayanZapryanov deleted the internalXmlConvert.StrEqualhelper that was comparing the two inputs character by character with just usingSequenceEqualandStartsWith. dotnet/runtime#75812 from @jlennox replaced some manual UTF8 encoding with"..."u8. dotnet/runtime#76436 from @TrayanZapryanov removed intermediatestringallocation when writing primitive types as part of XML serialization. And dotnet/runtime#73336 from @Daniel-Svensson and dotnet/runtime#71478 from @Daniel-Svensson improvedXmlDictionaryWriterby usingEncoding.UTF8for UTF8 encoding and by doing more efficient writing using spans. - dotnet/runtime#87905 makes a tiny tweak to the
ArrayPool, but one that can lead to very measurable gains. TheArrayPool<T>instance returned fromArrayPool<T>.Sharedcurrently is a multi-layered cache. The first layer is in thread-local storage. If renting can’t be satisfied by that layer, it falls through to the next layer, where there’s a “partition” per array size per core (by default). Each partition is an array of arrays. By default, thisT[][]could store 8 arrays. Now with this PR, it can store 32 arrays, decreasing the chances that code will need to spend additional cycles searching other partitions. With dotnet/runtime#86109, that 32 value can also be changed, by setting theDOTNET_SYSTEM_BUFFERS_SHAREDARRAYPOOL_MAXARRAYSPERPARTITIONenvironment variable to the desired maximum capacity. TheDOTNET_SYSTEM_BUFFERS_SHAREDARRAYPOOL_MAXPARTITIONCOUNTenvironment variable can also be used to control how many partitions are employed.
What’s Next?
Whew! That was… a lot! So, what’s next?
The .NET 8 Release Candidate is now available, and I encourage you to download it and take it for a spin. As you can likely sense from my enthusiasm throughout this post, I’m thrilled about the potential .NET 8 has to improve your system’s performance just by upgrading, and I’m thrilled about new features .NET 8 offers to help you tweak your code to be even more efficient. We’re eager to hear from you about your experiences in doing so, and if you find something that can be improved even further, we’d love for you to make it better by contributing to the various .NET repos, whether it be issues with your thoughts or PRs with your coded improvements. Your efforts will benefit not only you but every other .NET developer around the world!
Thanks for reading, and happy coding!
Fantastic blog, like all your other .Net performance blogs! I very much appreciate the effort you put into them.
I have been playing with some of the new Vector512 support and have noticed something odd with the way IsHardwareAccelerated is optimised by the compiler.
If I have some code like:
public void Doit()
{
if (Vector512.IsHardwareAccelerated) // True for my hardware
{
// a simple fast path
}
else
{
// slow path
}
}
and benchmark it with BenchmarkDotNet in VS 17.8.0 Preview...
Thanks for such a comprehensive and entertaining post. I learned a lot from reading it!
Question: what things must I add or delete from my .NET 6 project files to get the performance goodness you describe?
I gather many are “automatic” by changing the TargetFramework, but are there any that need to be explicitly enabled?
Thanks for such a comprehensive and entertaining post.
You're welcome!
I gather many are “automatic” by changing the TargetFramework, but are there any that need to be explicitly enabled?
There are essentially three categories of improvements here:
1. Improvements to existing APIs / the runtime
2. New APIs
3. Additional configuration knobs
Most of what I discuss in the post are in category (1), and to benefit from those, you don't need to do anything other than upgrade, e.g. change your TargetFramework to be net8.0. If you're referencing specific System./Microsoft. nuget packages and you're pinning a specific version of...
First, a big thank you for this post! It’s one I look forward to every year.
I have a question about one of the improvements that replaces array allocations with stackalloc or ArrayPool.Shared.Rent. How do you decide which one to use?
First, a big thank you for this post! It’s one I look forward to every year.
Thanks, you're welcome.
How do you decide which one to use?
If the data is all constant and is never mutated, then the right answer is almost always to use the C# compiler optimization that allows to instead be compiled down to just putting that data into the assembly and constructing a span around it. That's why you see a line like getting replaced by a line like . It's a little confusing syntax-wise, because it sure looks like this is...
In the paragraph
the link is to the same PR as in the second to last bullet point above, and the code doesn’t have any reverts the paragraph mentions so I assume it’s the wrong PR?
Oops, thank you! It should have been 87988 rather than 87989. I’ve fixed it.