
Wow. Just wow. I don’t know of a better way to describe my feelings right now. Open source is probably one of the most energizing projects our team has been working on. It’s been a blast so far and the stream of enthusiastic contributors and interactions doesn’t seem to stop any time soon.
In this post, I want to give you a long overdue update on where we are, interesting changes we made, and give an overview of what’s coming next. Read to the end, this is a post you don’t want to miss.
A good problem to have: Too many forks to display
In the first update on open source I hinted at the fact that we’ve several teams at Microsoft whose focus is on collecting telemetry. The reason we invest so much in this space is due to the shift from many-year release cycles to quasi real-time delivery. For services, continuous deployment is a very common paradigm today. As a result, the industry has come up with various tools and metrics to measure the health of services. Why is this necessary? Because you need to know when a problem is about to happen, not when it already happened. You want to make small adjustments over time instead of drastic changes every once in a while because it’s much less risky.
Open source is no different from that perspective. We want to know how we’re doing and somewhat predict how this might change over time by recognizing trends. It’s interesting to point out that the metrics aren’t used by management to evaluate my team or even individuals. We use the metrics to evaluate ourselves. (In fact, I believe that evaluating engineers with metrics is a game you can’t win – engineers are smart little buggers that always find a way to game the system).
One metric totally made my day. When browsing the graphs of the corefx repo, GitHub displays the following:
Indeed we’ve more than 1,000 forks! Of course, this a total vanity metric and not indicative of the true number of engagements we have. But we’re still totally humbled by the massive amount of interest we see from the community. And we’re also a tiny bit proud.
But the total number of pull requests is pretty high. In total, we’re approaching 250 pull requests since last November (which includes both, contributors from community as well as Microsoft):
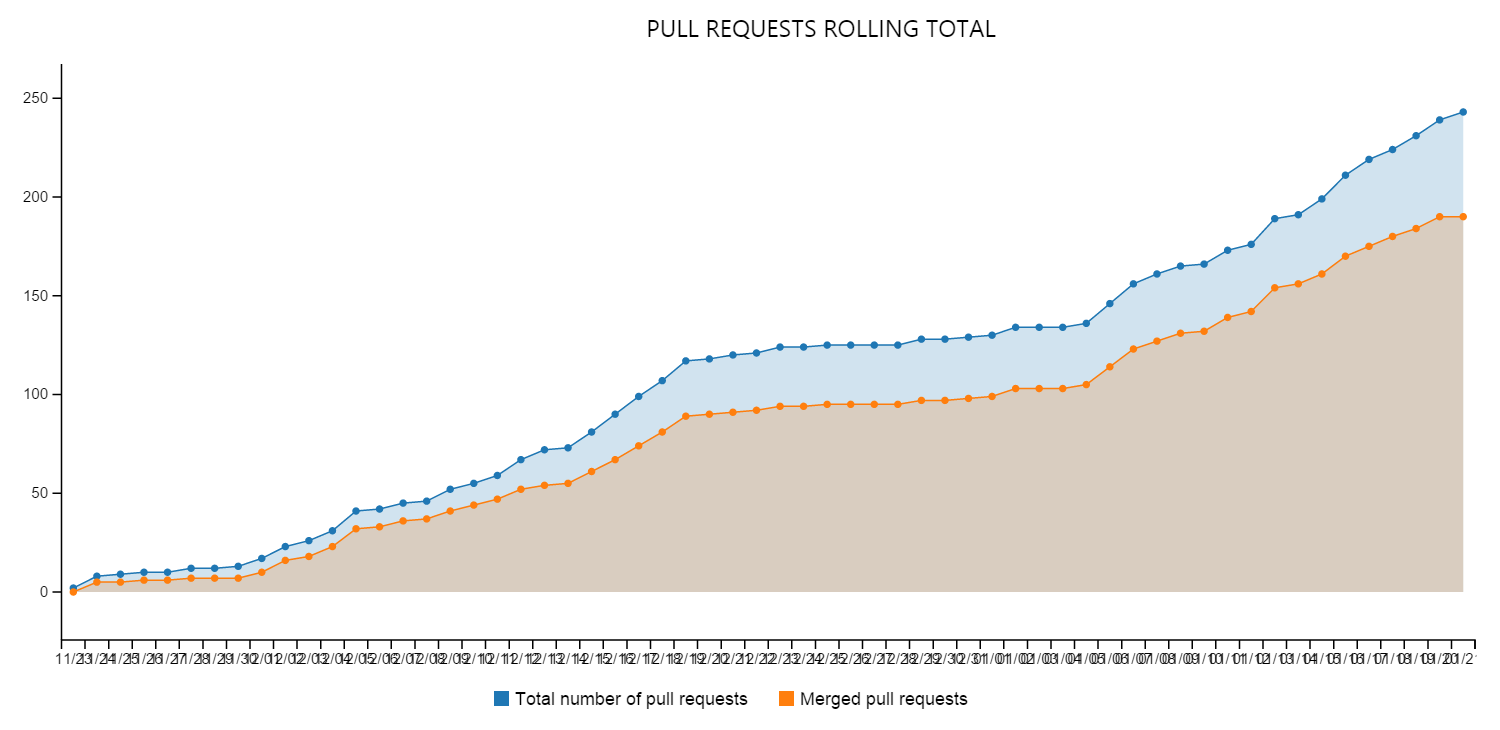
(In case you wonder, I also have a hypothesis what the plateau means).
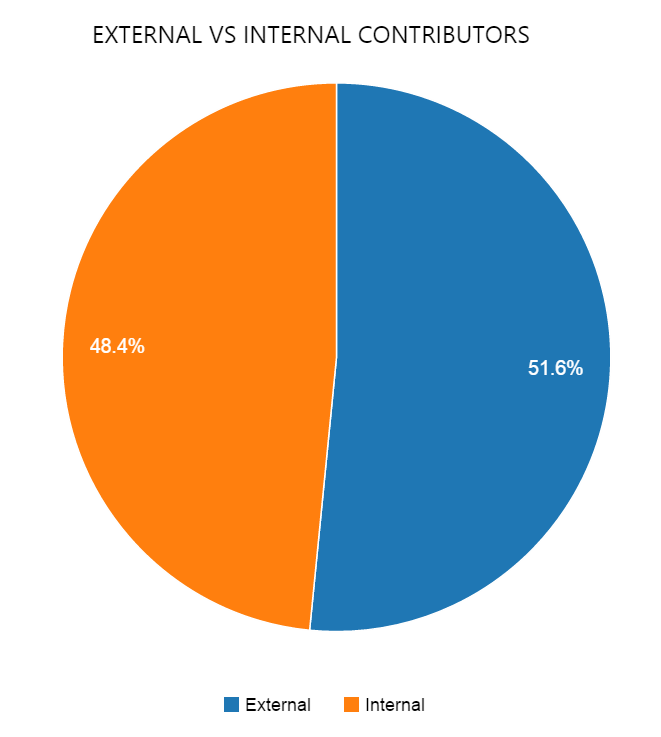
We’re also thrilled to learn that we’re already outnumbered by the community: the number of community contributions is higher than the number of contributions from us. That’s the reason why open source scales so well – the community acts as a strong multiplication force.
Real-time communication
One of the reasons why we decided to open source .NET Core was the ability to build and leverage a stronger ecosystem. Specifically, this is what I wrote last year:
To us, open sourcing the stack also means we’re able to engage with customers in real-time. Of course, not every customer wants interact with us that closely. But the ones who do make the stack better for all of us because they provide us with early & steady feedback.
Of course, the real-time aspect cuts both ways. It’s great if we hear from you in real-time. But how are we responding? If you ever filed a bug on Connect, you may not have had the impression that real-time is a concept that the people outside of the Skype organization have heard of. No offense to my fellow Microsofties; I’m guilty too. It’s incredibly difficult to respond in a timely manner if the worlds of the product team and their active customers are separated by several years.
In order to understand how responsive we are, we collect these two metrics:
- How quickly do we respond to an issue? This is the time it takes us to add the first comment.
- How quickly do we close an issue? This is the time it takes us to close an issue, regardless of whether it was addressed or discarded.
Here are the two graphs:
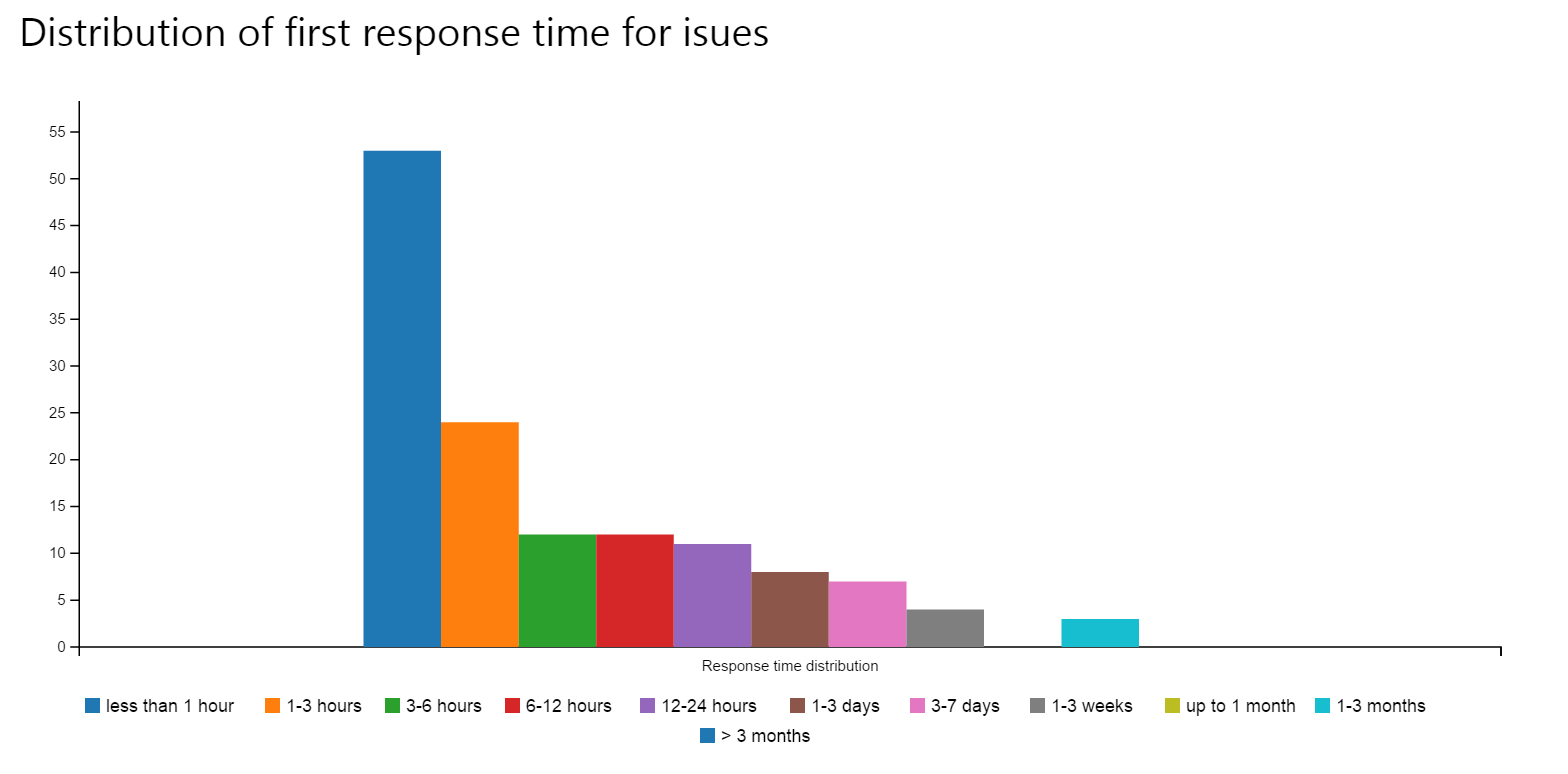
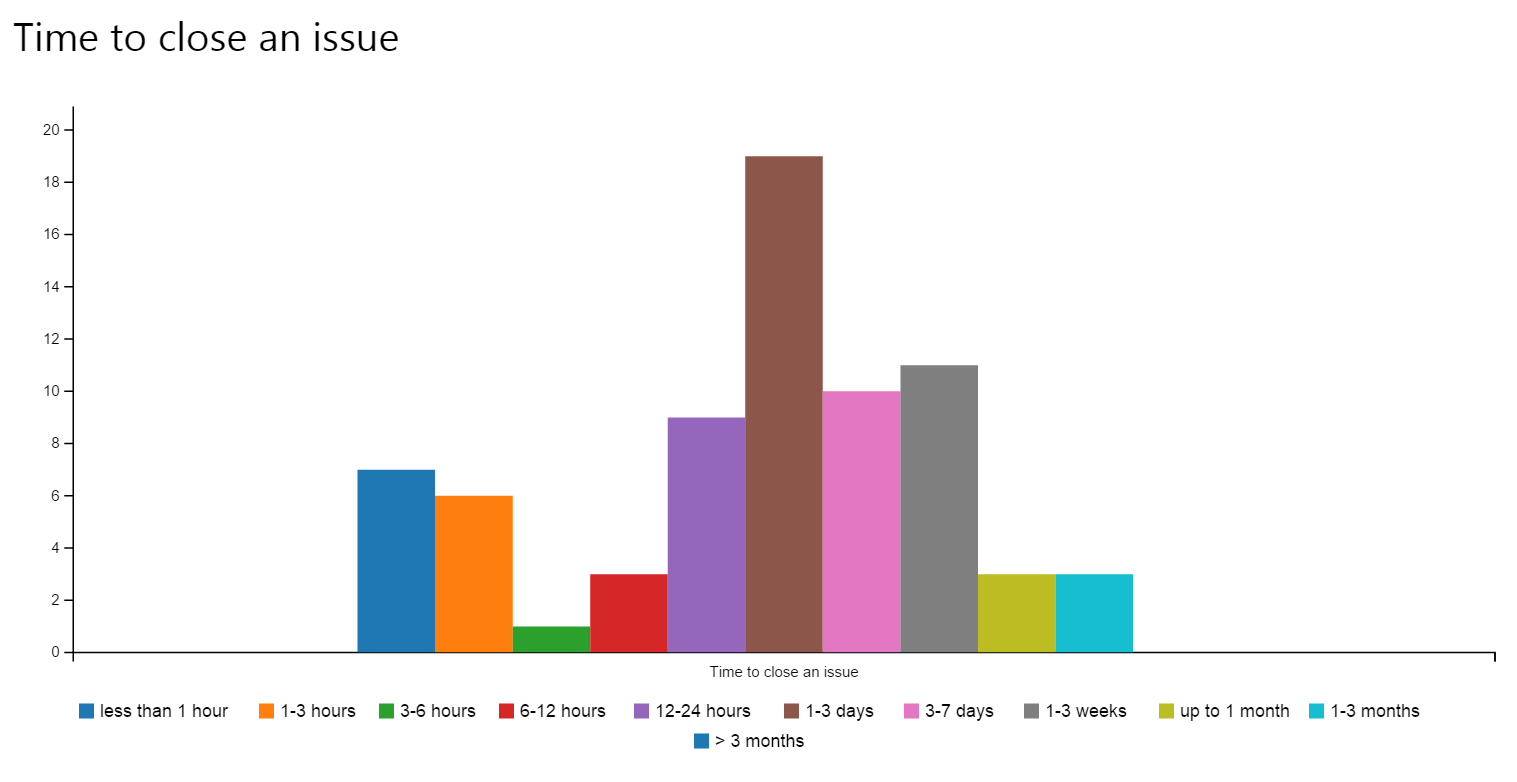
So far these look pretty good, and are in the realm of real-time collaboration. But there is also some room for improvement: getting a first response shouldn’t take more than a week. We’ll try to improve in this area.
Open development process
Part of the reason I share these metrics is to underline that we’re fully committed to an open development process.
But establishing an open development process is more than just sharing metrics and writing blog posts. It’s about rethinking the engineering process for an open source world. In a Channel 9 interview we said that we want to be mindful of the new opportunities that open source brings and not simply expose our existing engineering and processes. The reason isn’t so much that we fear giving anything away; it’s about realizing that our existing processes were geared for multi-year release cycles, so not all of them make sense for open source and agile delivery. In order to get there, we generally want to start with less process and only add if it’s necessary.
This requires adapting existing processes and adding some new processes. Let me give you a quick update of which processes we currently have and what tweaks we made.
Code reviews
To me, this is by far the most valuable part of collaborative software engineering. Realizing how many mistakes you can prevent by just letting somebody else see your code is a very liberating experience. It’s also the easiest way to spread knowledge across the team. If you haven’t done code reviews, you should start immediately. Once you did them, you’ll ever go back, I promise.
If you look at our GitHub pull requests, you’ll find that they aren’t just from the community – we also leverage pull requests for performing our code reviews. In fact, for parts of the .NET Core that are already on GitHub, there are no internal code reviews – all code reviews fully happen on GitHub, in public.
This has many advantages:
- Sharing expectations. You can understand what feedback we’re providing our peers with, and hence expect contributors to follow, too.
- Community participation. Anybody can comment on our pull requests which enables both, you and us, to benefit from the feedback of the entire community.
- Our pull request metric looks better. Just kidding. A nice side effect of using pull requests for code reviews is that everything is in one place. There is, tooling wise, no difference between me code reviewing my coworker’s code and reviewing a community pull request. In other words, doing code reviews in public makes our lives easier, not harder.
API reviews
My team spends a lot of time on API design. This includes making sure an API is very usable, leverages established patterns, can be meaningfully versioned, and is compatible with the previous version.
The way we’ve approached API design is as follows:
- Guidance. We’ve documented what constitutes good .NET API design. This information is available publicly as well, via the excellent book Framework Design Guidelines, written by our architect Krzysztof Cwalina. A super-tiny digest is available on our wiki.
- Static analysis. We’ve invested into static analysis (formerly known as FxCop) to find common violations, such as incorrect naming or not following established patterns.
- API reviews. On top of that, a board of API review experts reviews every single API that goes out. We usually don’t do this on a daily basis, because that wouldn’t efficient. Instead, we review the general API design once a prototype or proposal is available by the team building the API. Depending on the complexity we sometimes review additional iterations. For example, we reviewed the Roslyn APIs many, many times because the number of APIs and concepts is quite large.
We’ve found this process to be invaluable because the guidelines themselves are also evolving. For example, when we add new language features and patterns it’s important to come up with a set of good practices that eventually get codified into guidelines. However, it’s rare that the correct guidelines are known at day one; in most cases guidelines are formed based on experience. It’s super helpful to have a somewhat smaller group that is involved in a large number of API reviews because this focuses the attention and allows those folks to discover similarities and patterns.
With open source, we thought hard about how we can incorporate API reviews into an open development process. We’ve published a proposal on GitHub and based on your feedback put into production. The current API review process is now documented on our wiki.
But having a documented process is just one piece of the puzzle. As many of you pointed out, it’s a huge burden if the reviews are black boxes. After all, the point of having an open development process is to empower the community to be successful with contributing features. This requires infusing the community with the tribal knowledge we have. To do this, we started to record the reviews and upload them to Channel 9. We also upload detailed notes and link them to the corresponding parts in the video.
Of course, a complex topic like API design isn’t something that one can learn by simply watching a review. However, watching these reviews will give you a good handle on what aspects we’re looking for and how we approach the problem space.
We’ve also started to document some less documented areas, such as breaking changes and performance considerations for the BCL. Neither page claims to be complete but we’re curious to get your feedback.
Contributor license agreements (CLAs)
Another change we recently did was requiring contributors to sign a contributor license agreement (CLA). You can find a copy of the CLA on the .NET Foundation. The basic idea is making sure that all code contributed to projects in the .NET Foundation can be distributed under their respective licenses.
This is how CLAs are exposed to you:
- You submit a pull request
- We’ve an automated system to check if the change requires a CLA. For example, trivial typo fixes usually don’t require a CLA. If no CLA is required, the pull request is labelled as cla-not-required and you’re done.
- If the change requires a CLA, the system checks whether you already signed one. If you did, then the pull request is labelled as cla-signed and you’re done.
- If you need to sign a CLA, the bot will label the request as cla-required and post a comment pointing you to the web site to sign the CLA (fully electronic, no faxing involved). Once you signed a CLA, the pull request is labelled as cla-signed and you’re done.
Moving forward, we’ll only accept pull requests that are labelled as either cla-not-required or cla-signed.
It’s worth pointing out that we intend to have a single CLA for the entire .NET Foundation. So once you signed a CLA for any project in the .NET Foundation, you’re done. This means, for example, if you signed a CLA as part of a pull request for corefx, you won’t have to sign another CLA for roslyn.
Automated CI system
We’ve always had an automated build system. The triggers varies between teams, but the most common approach is a daily build in conjunction with a gate that performs some validation before any changes go in. For an open source world, having an internal build system isn’t helping much.
The most common practice on GitHub is to use a continuous integration (CI) system that builds on every push, including pull requests. This way, reviewers on the pull requests don’t have to guess whether the change will pass the build or not – the registered CI system simply updates the PR accordingly.
GitHub itself doesn’t provide a CI system, it relies on 3rd parties to provide one. Originally, we used AppVeyor. It’s free for open source projects and I use it on all my personal projects now. If you haven’t, I highly recommend checking them out. Unfortunately, AppVeyor currently only supports building on Windows. In order to enable our cross-platform work we wanted a system that we can run other systems, especially Linux. So we went ahead and now host our own Jenkins servers to perform the CI service.
We’re still learning
Our team is still learning and we believe it’s best to be transparent about it. As David Kean said in our initial open source interview:
Don’t be afraid to call us on it. If we do something wrong, overstep our boundaries, or do something that you thing we should have done better, call us out on it.
The earlier you can tell us, the better. So why not share our thinking and learning before we make decisions based on it? Here are a few examples.
- Bots talking to bots. When we started to roll our own CI system and added the CLA process, we got a bit trigger happy with using bots, which are essentially automated systems posting comments. This resulted in a flood of comments which caused a lot of noise in the PR discussions and in some cases even dominated the number of comments. Nobody on our side quite liked it, but we also didn’t think it was the end of the world. But then one customer said: “I am losing a little bit interest because is hard to track real things going on”. Statements like this are helpful because they make us aware of potential problems. We quickly realized that the number of folks annoyed is actually quite high so we prioritized this work and made our bots a lot less chatty. Instead of C3PO, we now have R2D2. No chitchatting, but few, short and actionable comments.
- Using Git. Most of our team members have a lot of experience with using centralized version control, especially Team Foundation Version Control (TFVC). While we also have a set of quite experienced Git users, our team as a whole is still adapting to a decentralized workflow, including usage of topic branches and flowing code between many remotes. Andrew Arnott, who some of you probably know from the Channel 9 interview on immutable collections, recently did a Git training for the .NET team. We recorded it and uploaded it to Channel 9. We’d love to hear from you if sharing these kind of videos is interesting to you!
- Up-for-grabs. There is an established pattern in the open source community to mark issues in a specific way that the community can query for when they want to find opportunities to jump in. We’ve started to label issues with up-for-grabs to indicate bugs or features that we believe are easy to get started with and we don’t currently plan on tackling ourselves. Thanks to Brendan Forster, the corefx project is now also listed on up-for-grabs.net, which is a website devoted to document on how open source projects ask the community for support. Based on some questions Brandon raised, this also started a discussion of what up-for-grabs actually means. Feel free to jump in and let us know what you think!
Are there any other topics you’d interested in? Let us know!
Library availability
At the time of the Connect() event, we only had a fraction of the libraries available on GitHub:
- System.Collections.Immutable
- System.Numerics.Vectors
- System.Reflection.Metadata
- System.Xml
Those four libraries totaled about 145k lines of code. Since then, we’ve added many more libraries which more than tripled the code size to now more than half a million lines of code:
- Microsoft.Win32.Primitives
- Microsoft.Win32.Registry
- System.Collections.Concurrent
- System.Collections.Immutable
- System.Collections.NonGeneric
- System.Collections.Specialized
- System.Console
- System.Diagnostics.FileVersionInfo
- System.Diagnostics.Process
- System.IO.FileSystem
- System.IO.FileSystem.DriveInfo
- System.IO.Pipes
- System.IO.UnmanagedMemoryStream
- System.Linq.Parallel
- System.Numerics.Vectors
- System.Reflection.Metadata
- System.Text.RegularExpressions
- System.Threading.Tasks.Dataflow
- System.Xml
And we’re not even done yet. In fact, we’ve only tackled about 25% of what is to come for .NET Core. A full list is available in an Excel spread sheet.

Summary
Since November, we’ve made several improvements towards an open development model. Code reviews are in the open and so are API reviews. And – best of all – we’ve a very active community which already outnumbers the contributions from our team. We couldn’t have hoped for more.
Nonetheless, we’re still at the beginning of our open source journey. We’re heads-down with bringing more .NET Core libraries onto GitHub. On top of that, the runtime team is busy getting the CoreCLR repository ready. You can expect an update on this topic quite soon.
As always, we’d love hearing what you guys think! Let us know via the comments, by posting to .NET Foundation Forums or by tweeting @dotnet.
0 comments