
The Challenge
Querying specific content areas quickly and easily is a common enterprise need. Fast traversal of specialized publications, customer support knowledge bases or document repositories allows enterprises to deliver service efficiently and effectively. Simple FAQs don’t cover enough ground, and a string search isn’t effective or efficient for those not familiar with the domain or the document set. Instead, enterprises can deliver a custom search experience that saves their clients time and provides them better service through a question and answer format.
We worked with Ernst & Young, a leading global professional services firm, to help them develop and improve a custom search engine to power a self-service expert system leveraging their EY Tax Guide for the US. The users of their expert system require an efficient and reliable experience, with a high degree of accuracy in the set of answers provided. We share our learnings, process, and custom code in this code story.

Consumer search engines combine many sophisticated techniques in each step of the process, from augmenting query and answer content, to indexing target content , to retrieval ranking and performance measurement. Augmenting content requires natural language processing (NLP) techniques like keyword and key phrase extraction, n-gram analysis, and word treatments including stemming and stop-word filtering. Ranking and retrieval of the right responses to queries use machine learning algorithms to measure the similarity of target content units of retrieval and the query itself. Finally, measuring retrieval performance is key to optimizing the quality of the experience, as managing the quality of the consumer search engine experience is an ongoing task.
Despite the sophistication of consumer search engine development and the promises of AI and expert systems, designing an enterprise custom search experience that delivers against users’ high expectations can be challenging. Few guidelines exist to provide developers with a comprehensive view of processes and best practices to design, optimize, and improve custom search. Moreover, there are few tools that aid developers in the process of measuring how well their custom search engine performs at retrieving what the user intended to retrieve. From text pre-processing and enrichment to interactive querying and testing, each step could benefit from a process road map, how-to guidelines, and better tools. Enterprises have questions such as: Which techniques should be used at what time? What is the performance impact of different optimization choices on retrieval quality? Which set of optimizations performs the best?
In this project, we addressed the challenge of creating a custom domain experience. We leveraged Azure Search and Cognitive Services and we share our custom code for iterative testing, measurement and indexer redeployment. In our solution, the customized search engine forms the foundation for delivering a question and answer experience in a specific domain area. Below, we provide guidelines on designing your own custom search experience, followed by a step-by-step description of our work on this particular project with code and data that you can use to learn from and modify our approach for your projects. In future posts, we’ll discuss the presentation layer as well as the work of integrating a custom Azure Search experience and Cognitive Services into a bot presentation experience.
Designing a Custom Search Experience
Before we describe the solution for our project, we outline search design considerations. These design considerations will help you create an enterprise search experience that rivals the best consumer search engines.
The first step is to understand the custom search life cycle, which involves designing the search experience, collecting and processing content, preparing the content for serving, serving and monitoring, and finally collecting feedback. Designing in continuous measurement and improvement is essential to developing and optimizing your search experience.
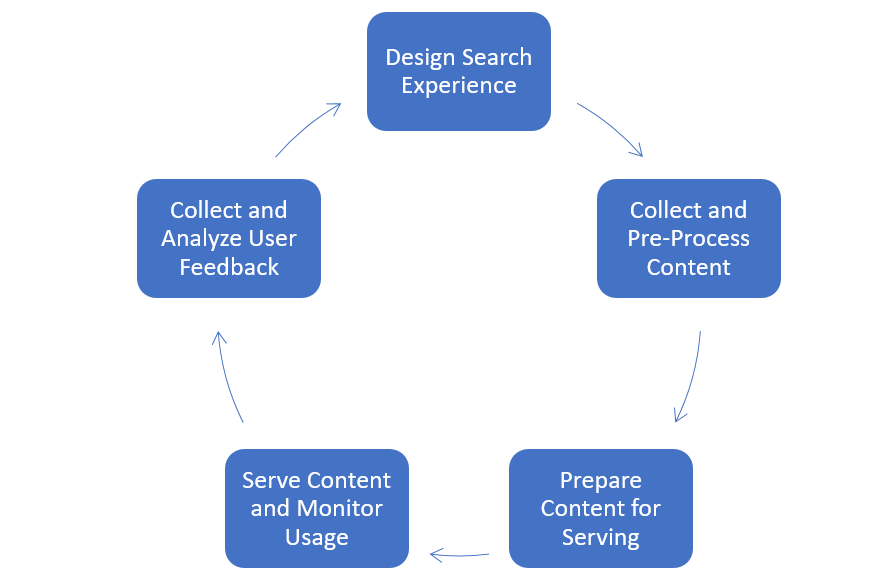
Determine Your Target User and Intent
Defining your target user allows you to characterize the experience that they need and the query language that they will use. If your target user is a domain expert, their query terminology reflects this expertise and if your target user is not familiar with the domain area covered, their queries won’t include expert vocabulary. For example, a domain expert may ask about a “Roth IRA” by name. A non-expert may ask about a “retirement savings accounts” instead.
Characterizing the intents of your target users guide your experience design and content strategy. In Web search engines, for instance, the user intent falls into one of three categories:
- Navigational: Surfing directly to a specific website (e.g., MSN, Amazon or Wikipedia)
- Transactional: Completing a specific task (e.g., find a restaurant, reserve a table, sign up for a service)
- Informational: Browsing for general information about a topic using free-form queries (e.g., who is the director of Inception, artificial intelligence papers, upcoming events in Seattle)
Beyond these three categories, user intent may be further categorized into more specific sub-intents, especially for transactional and informational queries. Clarifying your user intents is key to serving the most relevant content in the clearest form. If possible, obtain a set of potential queries and characterize them by user intent.
Consider the End-to-End Design
A good custom search design encompasses the end-to-end experience. Answering these ten key questions will give you a high-level set of requirements for your end-to-end custom search design.
- Which user intents will be supported?
- Is the content available to answer the user queries? Is there any data acquisition or collection that is required to assemble the necessary pieces of content?
- What type of content will be served: text, voice, multimedia or other?
- How will the content be served for each intent or sub-intent? How will the user interface work?
- Which delivery interface(s) will be supported (e.g., web page, mobile web page, chatbot, text, speech or other)?
- Will the experience include content from more than one source?
- Which user signals will be automatically captured for analysis? How?
- What type of user feedback will be solicited? How will it be solicited: implicitly or explicitly or both?
- What success metrics are there? Are they objective, subjective or both? How will they be computed?
- How do you compare alternative experiences? Will you run A/B testing or other testing protocol? How will you decide which experience is better in the potential situation of conflicting metrics?
Characterize the Query and Consumption Interface and Experience
Once you have planned for the end-to-end experience, outline the content servicing and consumption experience. As you consider the query and results serving page layout, consider how many results you will need to deliver. The number of results you can serve is often a function of the screen size of the device where you are serving the experience, the character of the answers you are delivering, and the requirements of your target audience. It’s key to think through delivering them in a consistent layout that is visually and cognitively appealing.
Define Success Measures and Feedback
Define your desired objective success metrics. Is success displaying the best answer in the top five responses, the top three responses, or only in the first response? The success measures will be used in the optimization of the search experience, as well as for ongoing management. Consider measures you will need to optimize for launch and for ongoing performance management. Also consider your approach to experimentation. Will you support A/B testing or other controlled experiments with variants to test different ranking mechanisms or user experiences?
In addition, define how users will provide feedback on the quality of the answers or the quality of the experience. For example, you might rely on implicit feedback from usage logs, or explicit feedback that the user provides based on the results served. Your UI affordances for explicit feedback might allow users to rate the usefulness of the specific result served, identify which result is the best, and rate the quality of the overall experience.
To help you determine how you measure success for your custom search project, here are a few resources to consider:
- Search relevance (how to define and measure search success including objective and subjective success metrics)
- Information retrieval ranking metrics
Our Project Solution
A variety of services, tools, and platforms are available to assist in the content preparation and results serving, as well as in the online response to the incoming user queries. We reviewed the following services to identify which would serve the custom search experience requirements for our project.
- Detection of user query intent/sub-intent via Language Understanding Intelligent Service (LUIS)
- Serving frequently asked questions via QnA Maker API
- Indexing and serving general search content via Azure Search
- Text analytics supporting tools, such as language detection, key phrase extraction, topic detection, sentiment analysis via Text Analytics API
- Other APIs supporting language, knowledge, speech, vision and more via Microsoft Cognitive Services
Based on our content and target user requirements we identified Azure Search and the Language Understanding Intelligent Service as services we would use in our design.
Custom Search Engine Development Process and Tools
The diagram below describes our development process and the tools used. The development and optimization process flow for our project is illustrated in gray. The services we leverage are in blue. We completed work on the steps with the solid outline in this project.
Azure Search is the foundation for our custom search experience. We leverage many of the Azure Search features including custom analyzer, custom scoring, and custom synonyms. We complement these services with custom scripts to iteratively optimize and measure our search experience. We have shared links to this custom code within this post and in our GitHub repo.
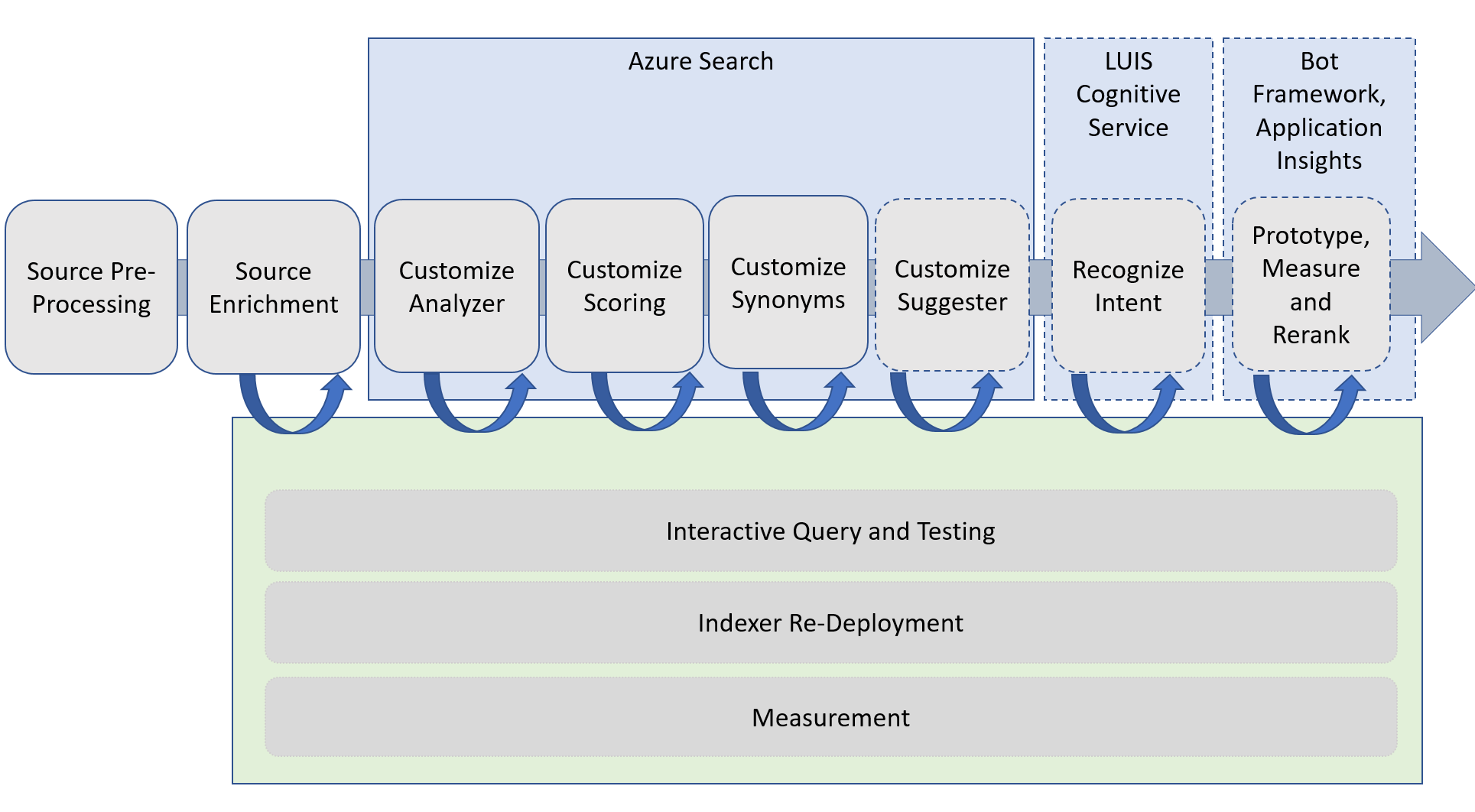
To illustrate this development and optimization process we used in this project in this code story, we take a set of public domain data and walk through the development and refinement of a custom search experience step-by-step. In this case, we’ll reference a subset of the US Tax Code.
The Project Process
Source Content Text Pre-Processing
Creating a custom search experience starts with clean and well-structured source text. Our objective in the first step was to structure source text by defining a well-characterized unit of retrieval, with metadata for each of these ‘answers.’ For this project, this involved some restructuring of content originally formatted for consumption on paper.
In order to prepare the data for search, we parsed the source based on formatting characteristics in order to transform it into a data table. We also standardized the text being used within the content by applying standard formatting. We organized by one row for each candidate response, sometimes referred to as a ‘unit of retrieval’ or answer. In the screenshot below, you can see the column ‘ParaText’ is the ‘answer’ unit.
Metadata is used by Azure Search to better identify and disambiguate the target content the user is seeking. We created metadata for each row, or answer, in our content table. For example, we identified which chapter, section, and subsection the content came from. Because our source corpus was designed for written publication, we had some unique transformations to perform on the text. In this Python script, you can follow some of the basic source content cleaning approaches we took, leveraging off-the shelf text libraries like Beautiful Soup.

The condition of your source text will vary. You may need to interpret less deterministic and consistent formatting of source content.
Content Enrichment, Upload, and Index Deployment
Augmenting the source text with additional descriptive metadata, or ‘content enrichment’, helps Azure Search understand the subject and meaning of the target text. In this case, we enriched each row with key phrases extracted from the unit of retrieval text. We used open source key phrase extraction libraries with some customizations, including custom stop word exclusion. You can find this in the end-to-end content extraction Jupyter Notebook.
As an additional content enrichment step, we added the title of the content section of the publication to the keyword list. In our case, the title of the content section was a very descriptive categorization of the answer, and thus very useful for our search engine in disambiguating this answer.
Once this was complete, we uploaded the content and created the initial index in Azure Search. We used the Azure search REST API to create the index and upload the new content via a Jupyter Notebook Python script. You can also use Fiddler, Postman or your favorite REST client.

Azure Search Custom Analyzer, Scoring, Synonyms, and Suggesters
We found that tweaking the custom search analyzer improved the meaning that the Azure Search indexer detected from our source text. Azure Search Custom Analyzer has a number of elements one could customize. In our project, we had many terms that were in fact numbers and letters with a dash or other character between them. We found that that standard Azure Search analyzer interpreted these as separate words and mistakenly split them apart. For example “401k” would be interpreted as “401” and “k”. In this case, the CHAR filter settings in the custom analyzer allowed us to call out this pattern via regex, and to tell the custom analyzer to leave these strings together as one unit. Weighting and boosting of certain fields in the content can also boost performance. We specifically boosted keywords with titles in the custom analyzer JSON.
Here is the example of our Azure search custom analyzer JSON.
{
"name": "taxcodejune",
"fields":
[
{
"name": "Index",
"type": "Edm.String",
"searchable": false,
"filterable": false,
"retrievable": true,
"sortable": true,
"facetable": false,
"key": true,
"indexAnalyzer": null,
"searchAnalyzer": null,
"analyzer": null,
"synonymMaps": []
}
],
"scoringProfiles":
[
{
"name": "boostexperiment",
"text":
{
"weights":
{
"Title": 1,
"Keywords": 1
}
}
}
],
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "english_search_analyzer",
"tokenizer": "english_search",
"tokenFilters": [
"lowercase"
],
"charFilters": ["form_suffix"]
},
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "english_indexing_analyzer",
"tokenizer": "english_indexing",
"tokenFilters": [
"lowercase"
],
"charFilters": ["form_suffix"]
}
],
"tokenizers": [
{
"@odata.type": "#Microsoft.Azure.Search.MicrosoftLanguageStemmingTokenizer",
"name": "english_indexing",
"language": "english",
"isSearchTokenizer": false
},
{
"@odata.type": "#Microsoft.Azure.Search.MicrosoftLanguageStemmingTokenizer",
"name": "english_search",
"language": "english",
"isSearchTokenizer": false
}
],
"tokenFilters": [],
"charFilters": [
{
"name":"form_suffix",
"@odata.type":"#Microsoft.Azure.Search.PatternReplaceCharFilter",
"pattern":"([0-9]{4})-([A-Z]*)",
"replacement":"$1$2"
}
]
}
Azure Search Custom Analyzer offers more elements to customize than we used in this instance, and you can read more details about it in the API documentation. For more frequent queries, you can use the suggester functionality to suggest and autocomplete.
We also found that adding synonyms and acronyms to the metadata improved our performance, given the jargon-intensive specialized content in the US Tax Code. In the case where the user’s query uses synonyms of the keyword in the original content, this synonym and acronym metadata helps match it to its intended answer. For our project we wrote a custom script in a Jupyter Notebook to generate synonyms and acronyms, comparing our target content to synonym and acronym references. We added these to the metadata for our content. With this acronym-heavy corpus, adding synonyms and acronyms helped performance substantially. We also create a Jupyter Notebook to demonstrate how to upload the synonym map you created to an Azure Search service.
Batch Testing, Measurement and Indexer Redeployment
At every iteration step, we tested the impact of the changes and optimized our choices. In order to upload reparsed content interactively and do custom analyzer updates — a step that we took many, many times as we optimized our custom search engine — we created a management script. This saved time and eliminated errors. Then we used the batch-testing script featured in this Jupyter Notebook, which retrieves the top ‘N’ search results for all questions in the batch. This approach allowed us to review and measure the impact of each refinement step we took, from content enrichment to tweaking the custom analyzer settings.
We compared all of the retrieved results per question vs. the ground-truth answers from the training set, collated the measurements from each iterative run manually, and confirmed whether or not the optimization changes had improved performance.
Performance Improvement for Each Refinement
Once we had our search index deployed, we measured performance and compared every refinement step’s impact on this performance. Some refinements were more beneficial than others — a function of our source content and, in part, the extent and character of our ground-truth answers.
Overall, we found that adding titles to our extracted keywords was the most beneficial refinement. Given this result, we boosted the weight of the title and keyword metadata and saw even more benefits. Second-most impactful was creating a CHAR filter in the custom analyzer to recognize strings like ‘401k’ and avoid splitting them. Finally, the third most impactful addition was adding acronyms and synonyms to our metadata. Based on these refinements we were able to optimize results to a performance level that was now ready for human testing and feedback.
As an example of our iterative approach to performance improvement, we generated a toy example of performance improvements of recall of correct answers. In this example, we highlight hypothetical performance improvement for each additional augmentation and analyzer customization.

The next experimentation and measurement phase is to combine these features listed above, then evaluate and compare relevance in the final presentation to the user. The overall relevance metrics will likely vary based on user’s expectations, background, and usage behavior.
Future Work
Follow-on work for the project includes recognizing intent using the Language Understanding Intelligence Service (LUIS). By looking at frequent queries, we can identify and characterize intents using distinctive phrases. For example, there are a number of phrases associated with retirement accounts including ‘Roth IRA’ and ‘401K’; we could augment the metadata when these phrases are used to include the topic ‘retirement.’
The team plans to prototype the question and answer experience with the help of the Bot Framework. The bot will express the intended purpose of the chatbot following design principles outlined in the documentation and the code base.
After launching, the prototype will be used to display realistic usage information and metrics with Azure App Insights and the Bot Framework Analytics dashboard.
Conclusions
In this code story, we described creating a custom domain search question and answer experience using Azure Search and Cognitive Services and custom testing and measurement code. We have shared our custom code on this GitHub repository where you can find the end-to-end examples in Jupyter Notebooks, as well as the individual Python scripts. We have also provided guidelines for the design of your custom search experience to help you get started. We hope this makes your experience creating a custom search experience faster and more effective. We invite you to contribute to the GitHub repository and to provide feedback in the comments section below.