
ISE Developer Blog
Solving global tech challenges, sharing insights, and empowering developers
Latest posts
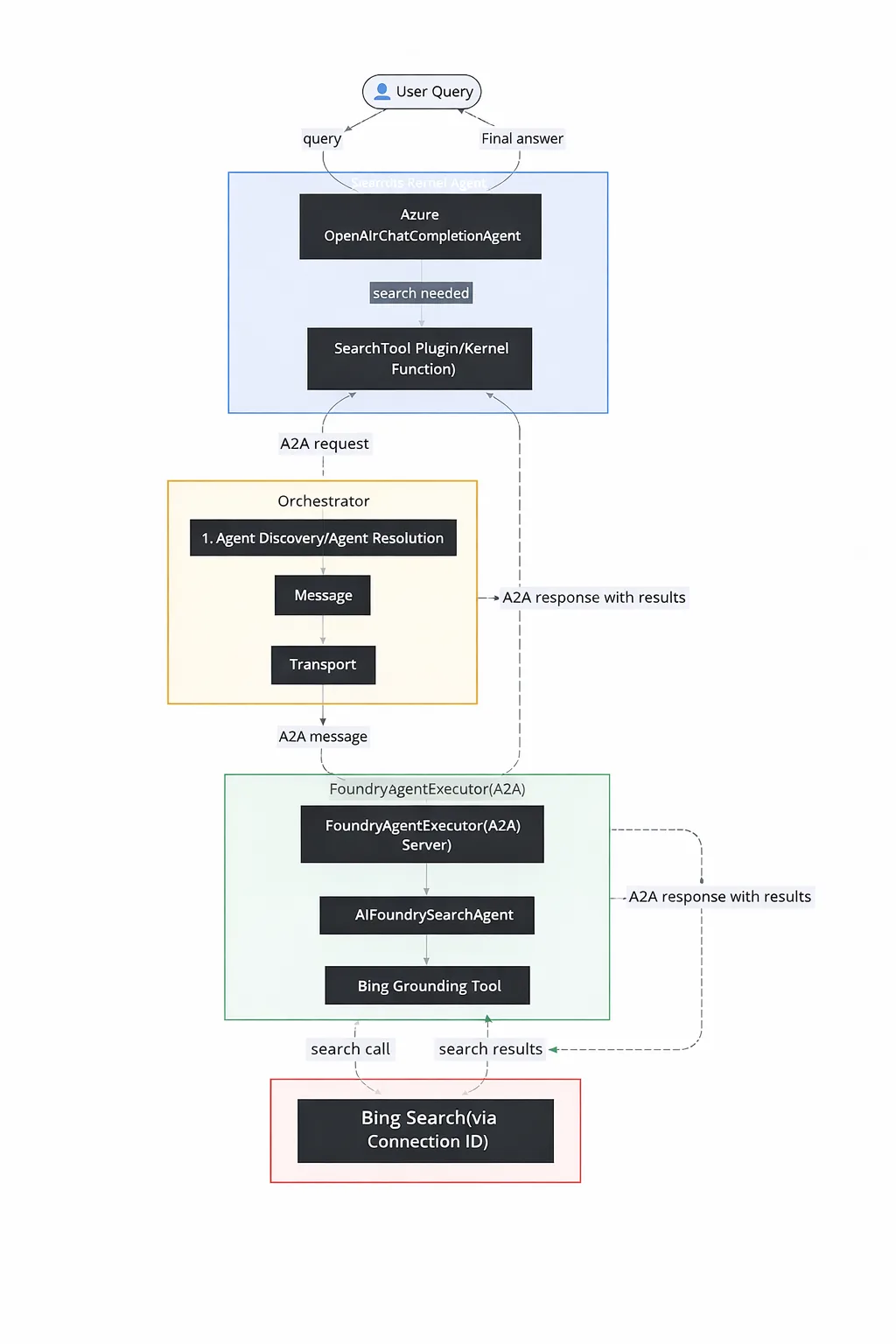
Building Search-Enabled Agents with Azure AI Foundry and Semantic Kernel and A2A
A step-by-step guide to enable search in the semantic kernel agents using bing grounding in Azure Foundry AI Agent using A2A.

From Azure IoT Operations Data Processor Pipelines to Dataflows
In this post we explore the evolution from Azure IoT Operations Data Processor Pipelines to Dataflows, why we adopted a hybrid strategy with custom Rust pods, and the architectural lessons we learned building event detection systems at the edge.

Using Agents to Setup Experiments
When setting up an experiment is complex, agents can automate the process to make it faster and more reliable.
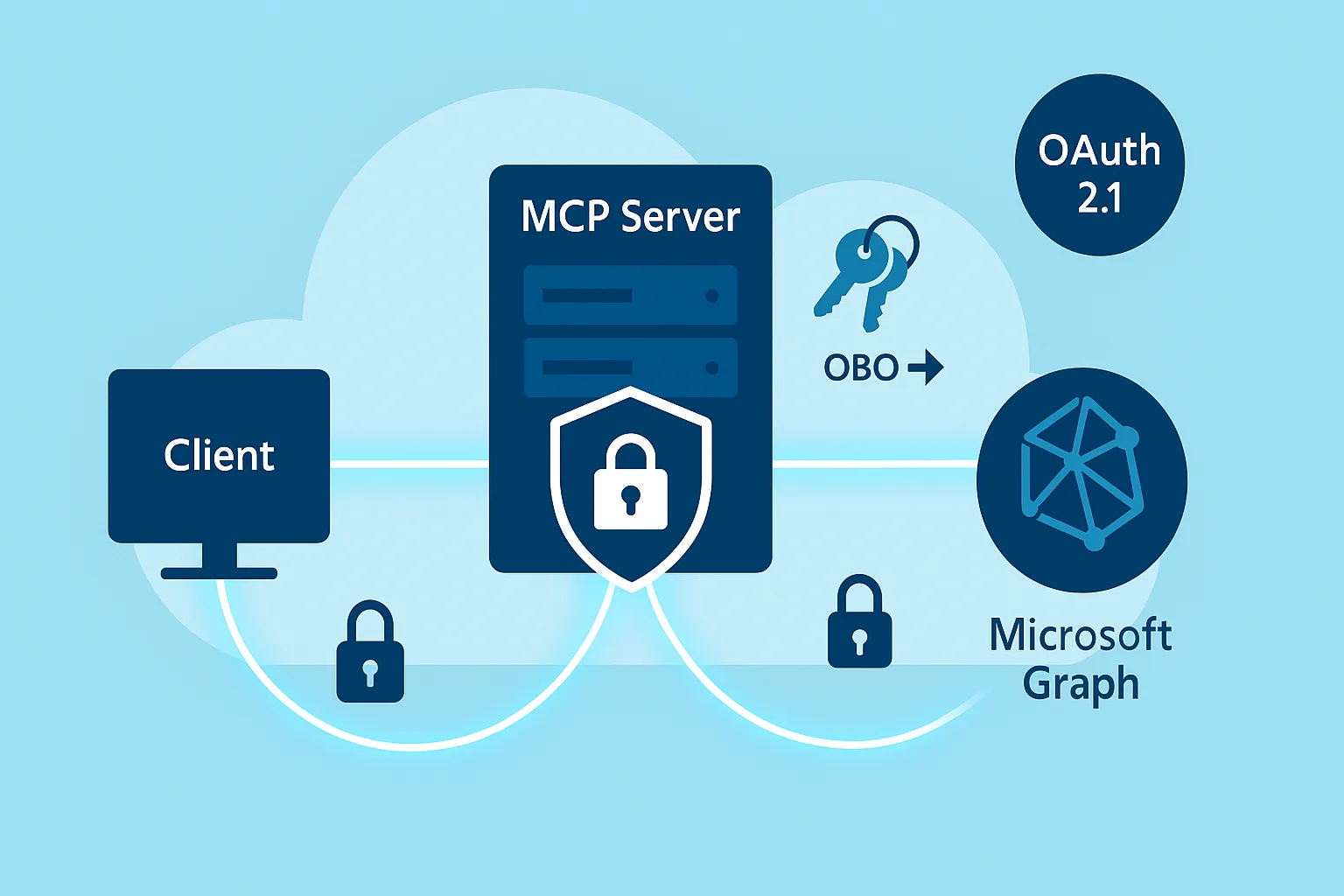
Building a Secure MCP Server with OAuth 2.1 and Azure AD: Lessons from the Field
How we built a production-ready MCP server with OAuth 2.1 authentication and On-Behalf-Of flow for Microsoft Graph, navigating a rapidly evolving specification.

Using Codes to Increase Adherence to Prompts
Agentic systems have some discretion in the parameters they sent to tooling, but there are cases, such as experimentation, when you need 100% adherence to a set of parameters.

Minimal GitOps for Edge Applications with Azure IoT Operations and Azure DevOps
How we built a minimal, scalable GitOps workflow for edge applications using Azure IoT Operations, Azure DevOps, and a multi-repo strategy. Includes pipeline templates and scripts for real-world deployments.
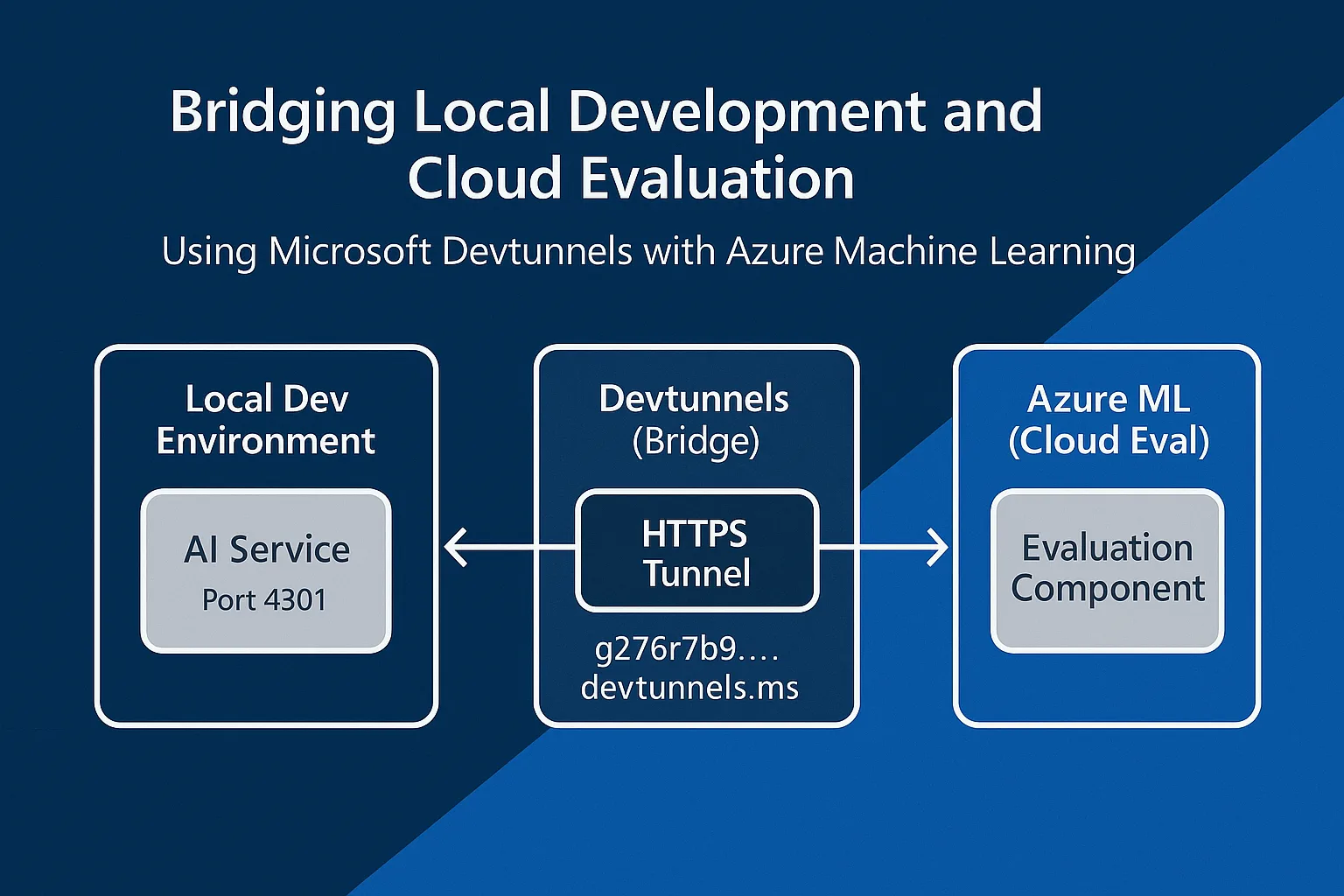
Bridging Local Development and Cloud Evaluation: Using Microsoft Devtunnels with Azure Machine Learning
Learn how to streamline AI development by using Microsoft Devtunnels to connect local services with Azure Machine Learning evaluation pipelines, eliminating deployment delays while maintaining comprehensive cloud-based validation.
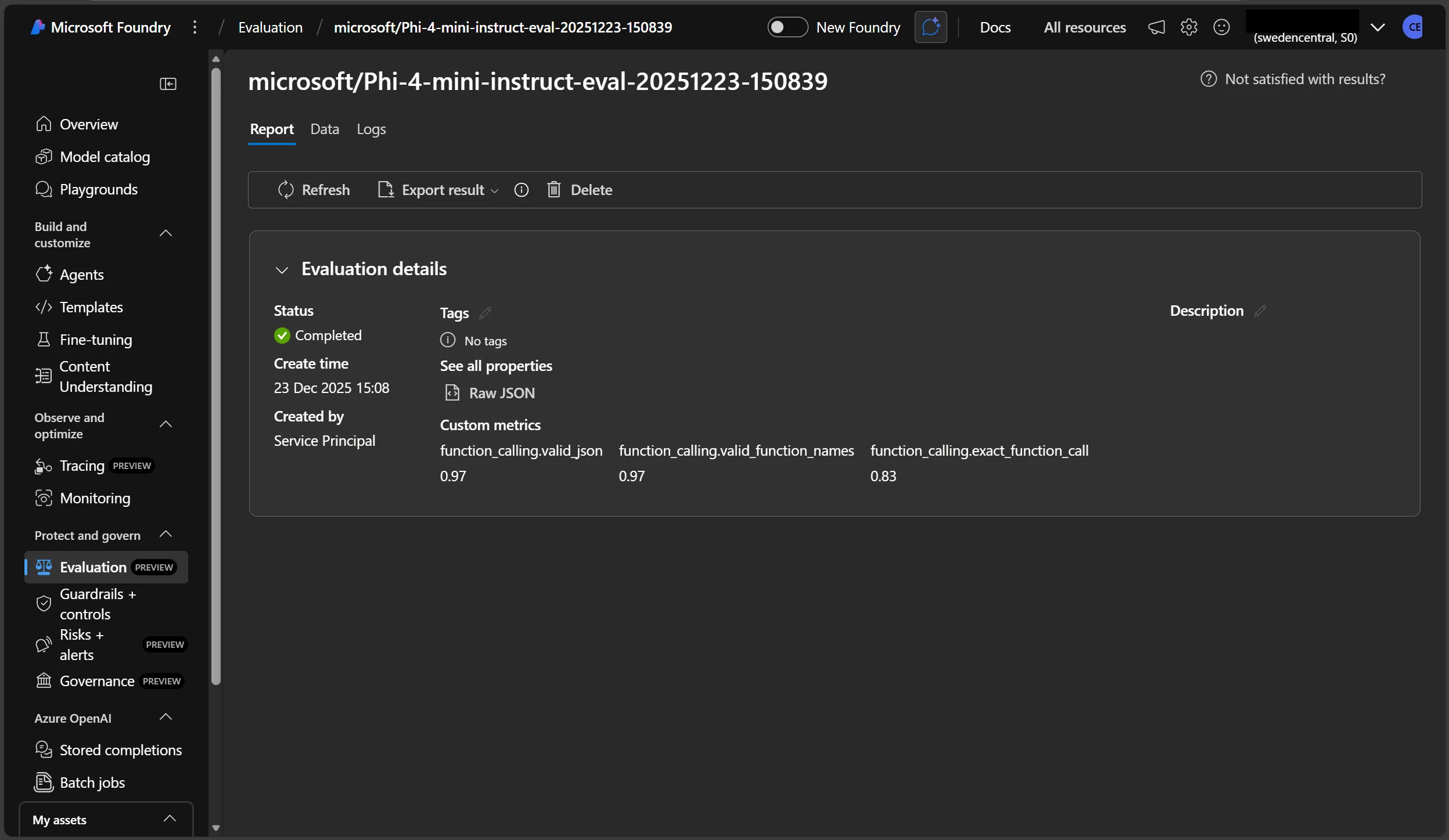
Evaluate Small Language Model Function Calling using the Azure AI Evaluation SDK
This blog details how the Azure AI Evaluation SDK can be used to assess the performance of a small language model for function calling, such as Phi-4-mini-instruct, and view the results in Microsoft Foundry.

Introducing the Copilot Studio + Azure AI Search Solution
Introduction to a scaleable and secure turnkey architecture for deploying Copilots connected to Azure AI Search.
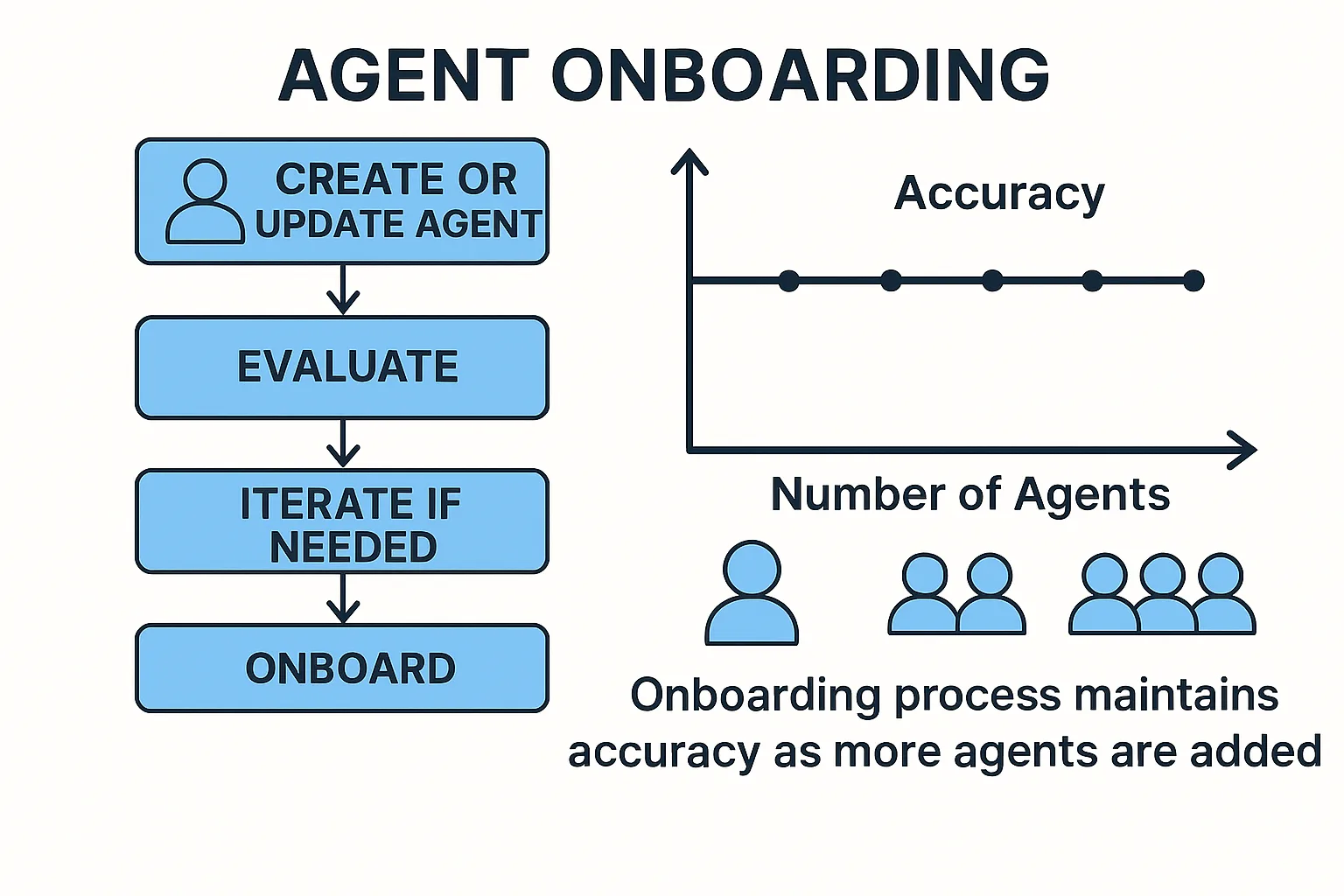
Agent Onboarding Process for Agentic Systems: Maintain accuracy at scale
A robust agent onboarding process is the backbone of scalable, reliable multi-agent AI systems—enforcing uniqueness, rigorous evaluation, and responsible AI practices at every step.

Accelerating AI Development with GitHub Copilot: Real-World Use-Cases
This blog post shares real-world experiences from Microsoft's ISE team using GitHub Copilot to accelerate AI development workflows, demonstrating how AI tools can significantly speed up tasks like creating documentation, class diagrams, data visualizations, and demo scripts when used by experienced developers.

Ensuring Seamless User Experience in Modernization Projects with AI‑Generated Stagehand and Playwright UI Tests
Using AI‑generated tools like Stagehand with Microsoft's Playwright helps ensure a smooth user experience during modernization efforts such as Hyper Velocity Engineering and monolith-to-microservices migrations.
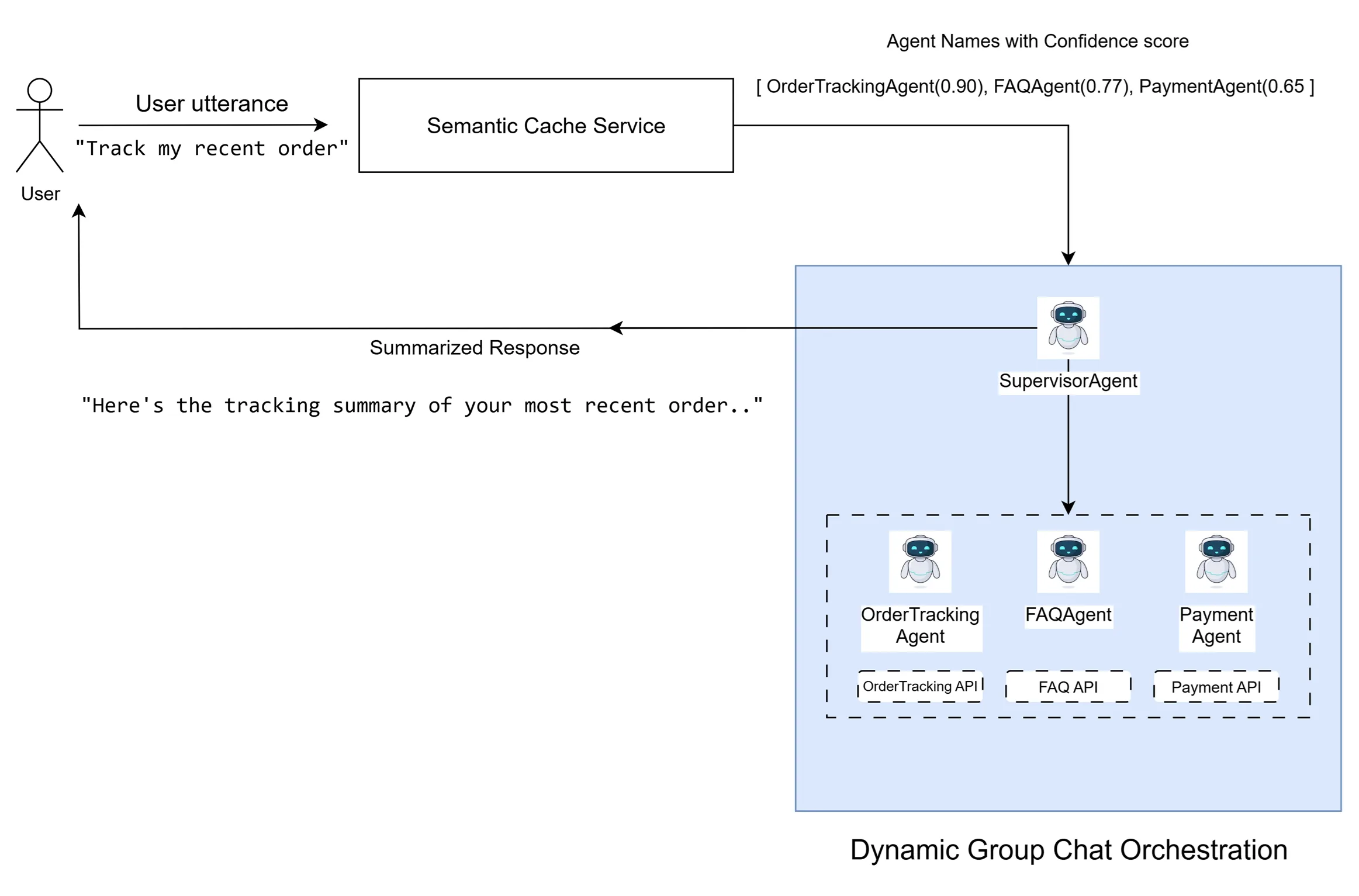
Patterns for Building a Scalable Multi-Agent System
Practical patterns for designing scalable, high-performing multi-agent systems—grounded in real implementation experience.

Tuning and Optimization of Speech-to-Text (STT), Text-to-Speech (TTS), and Custom Keyword Recognition in Azure Speech Services
This blog outlines best practices for optimizing Speech-to-Text (STT), Text-to-Speech (TTS), and Custom Keyword Recognition in Azure Speech Services, helping developers build more accurate and responsive voice-enabled applications.
Integration Testing with Testcontainers
How to leverage Testcontainers for integration testing

Managing secrets on Azure KeyVault with a Tagging strategy to perform automations
Cloud and Infrastructure teams can manage secrets on Azure KeyVault with a Tagging strategy to perform automations.
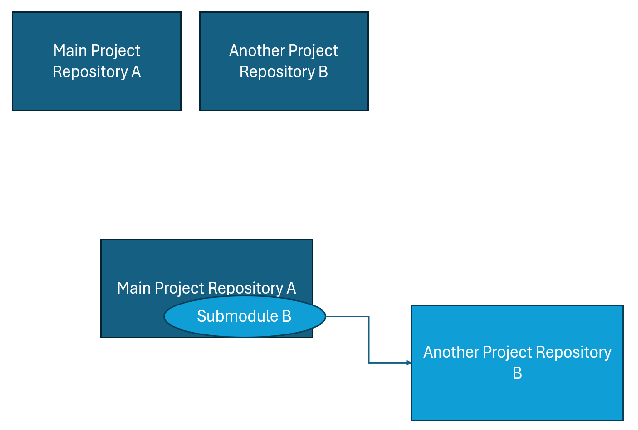
Working with Git Submodules: Managing Dependencies Across Repositories
Working with Git Submodules and creating actions.
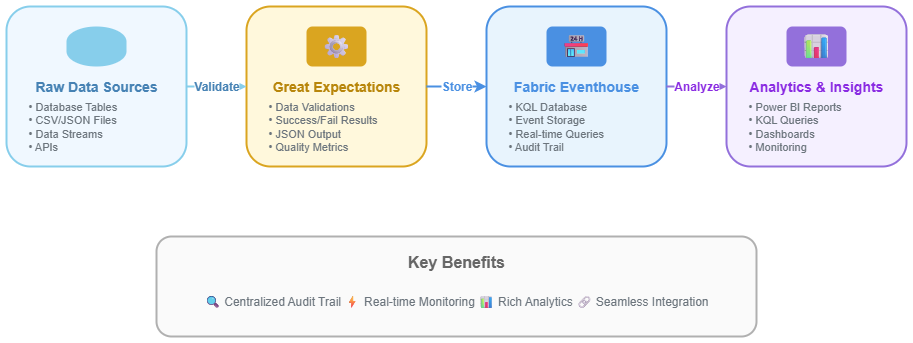
Leveraging Fabric Eventhouse to Store Great Expectations Validation Results
A step-by-step guide to storing data validation results into the Eventhouse & visualize data using queries and dashboard.
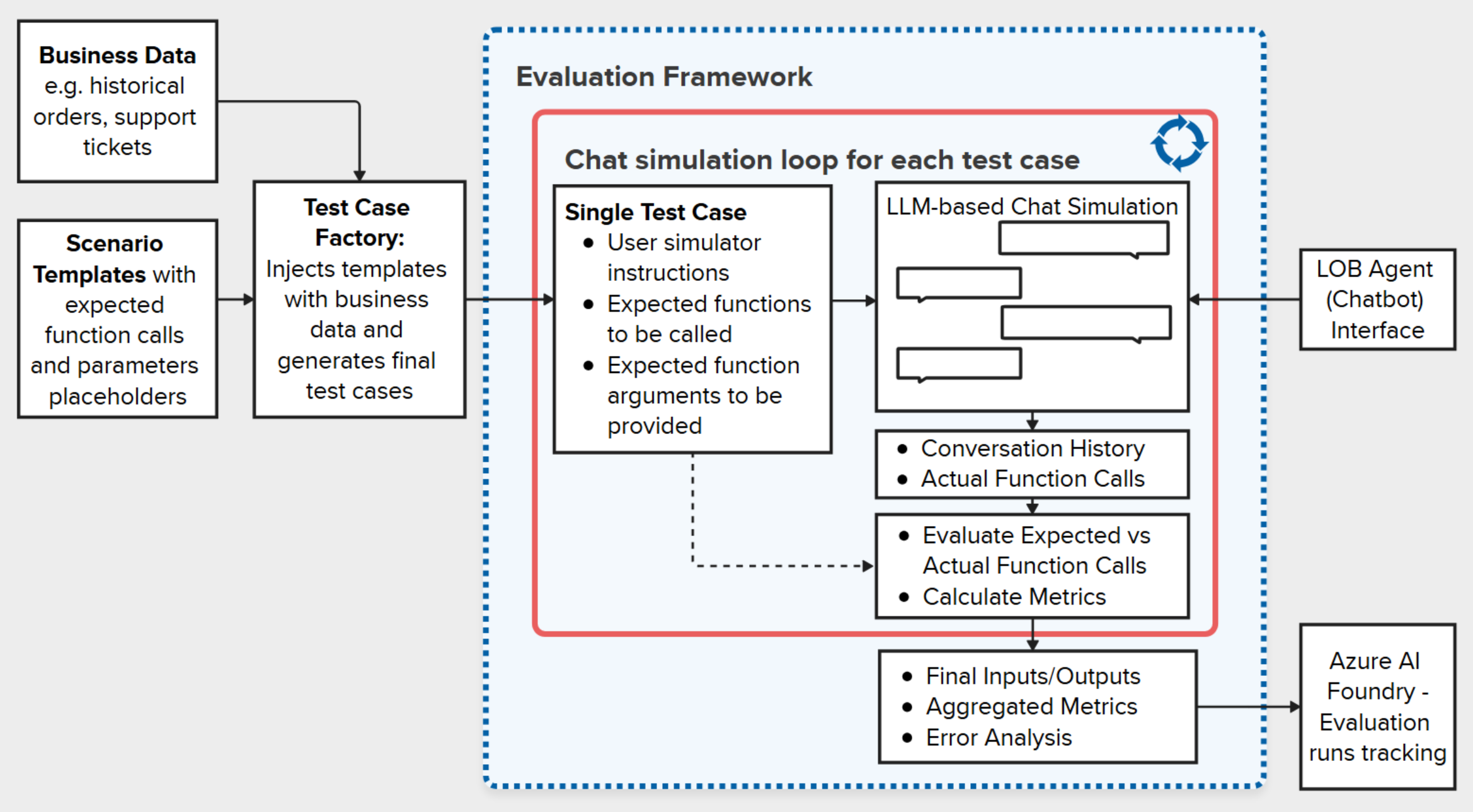
Taming Complexity: Intuitive Evaluation Framework for Agentic Chatbots in Business-Critical Environments
This blog post introduces a comprehensive evaluation framework for enterprise chatbots powered by large language models (LLMs), specifically addressing the challenges of assessing Line of Business (LOB) agents in business-critical environments. The authors tackle the fundamental problem that traditional chatbot evaluation metrics fail to capture the nuanced, non-deterministic performance of modern LLM-based systems, proposing a solution that combines realistic chat simulation using an LLM-powered User Agent, automated ground truth generation at scale, and comprehensive metrics including function call precision, r...
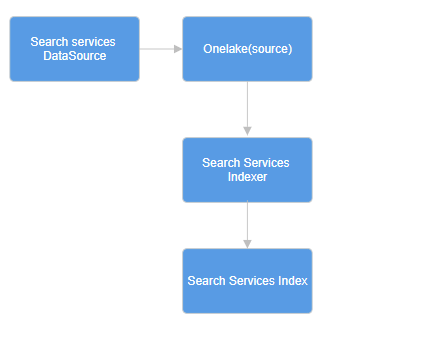
Unlocking Vector Search with OneLake Indexer and OpenAI Integration in Microsoft Fabric
Exploring how Microsoft Fabric OneLake indexer integrates with OpenAI

Ground Truth Curation Process for AI Systems
Steps to Produce High Quality Ground Truth Pairs for AI Systems

Customizable and Extensible Evaluation of a GenAI Application
Suggestions on how to evaluate a generative AI application in an adaptable and extensible manner.
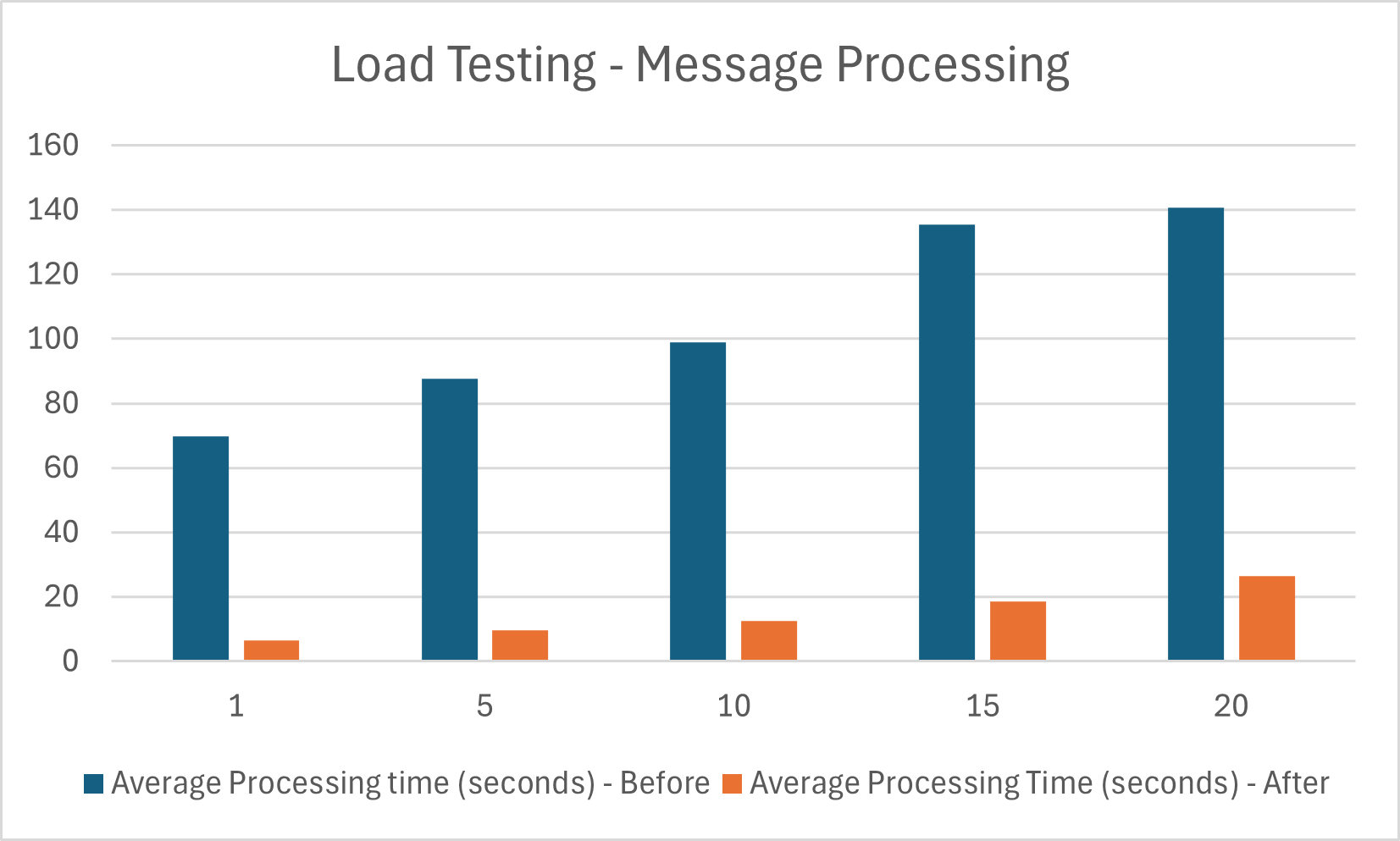
Learnings from External Data Handling
This blog post discusses the challenges and solutions encountered by the ISE team at Microsoft while making a distributed system production-ready. It focuses on issues including slow processing speeds and out-of-memory exceptions, and provides insights into the methods used to address these problems.

Enhancing Analytical Queries with Semantic Kernel and In-Memory SQL Processing
Integrating Semantic Kernel with an ephemeral in-memory SQL plugin, enabling secure and efficient analytical queries over structured data.

AI Model Promotion with dstoolkit-mlops-v2
Evaluates various repository structures and designs for maximizing the efficiency of Data Scientists and Software Engineers developing, promoting and deploying AI models on the same project.

Use Agent to Update Dataverse Table Content
Create an agent using Copilot Studio to update the content of a Dataverse table.
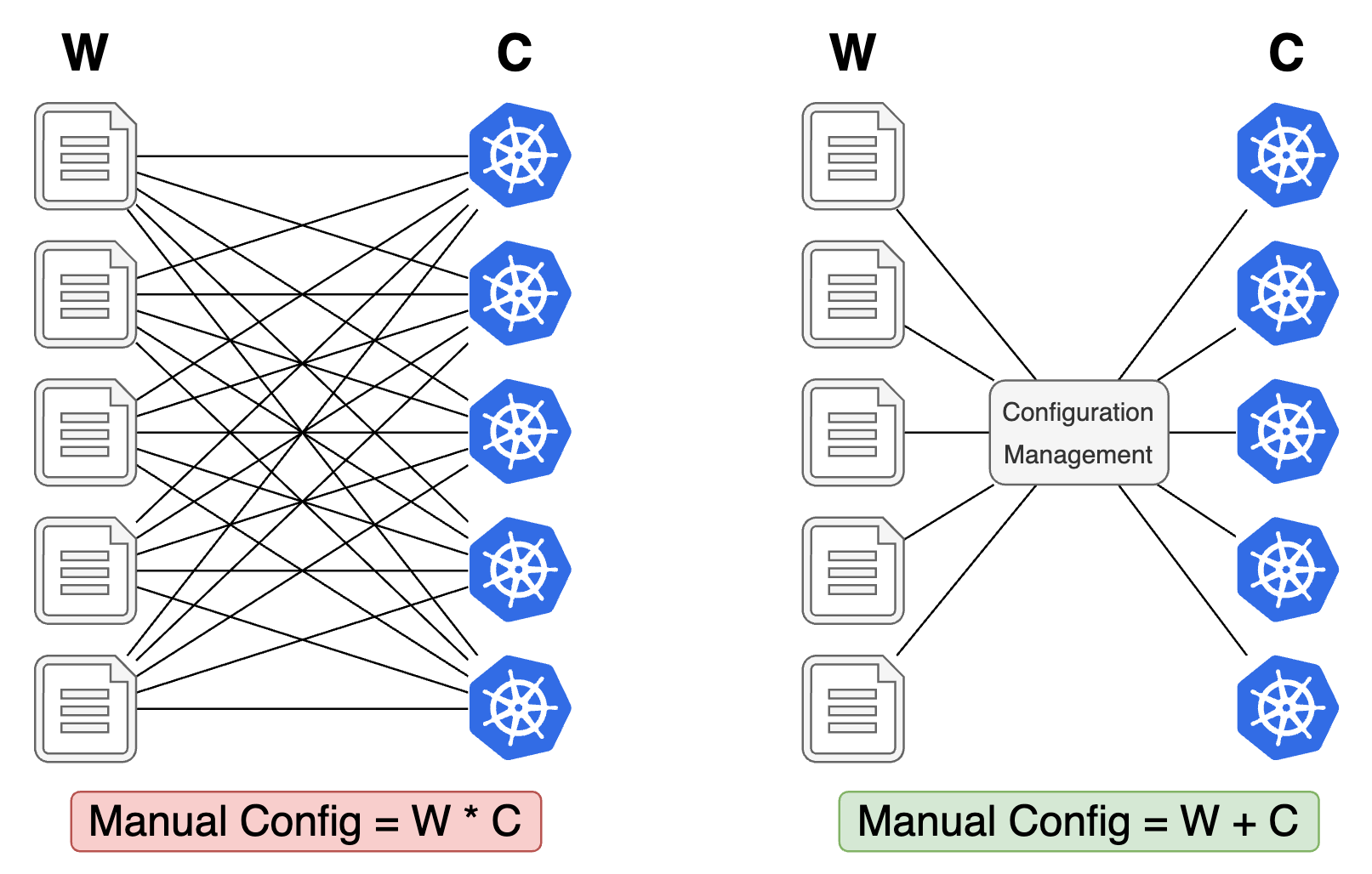
Fleet Configuration Management
This post explains the challenge of fleet configuration management, the role of an automated fleet configuration management system, and describes key considerations for building such a system.