

The original title of this article was “Using Azure Container Instances for a serverless, stateless, and scalable data generation and ingestion pipeline”. That seemed too long, but it does describe our use-case more explicitly. However, we also wanted you to think about using ACI for a variety of jobs, not just this use-case.
When deploying container applications, there are lots of options, but generally we tend towards Azure Kubernetes Service and now Azure Container Apps. However, when deploying container jobs, ACI can be a suitable option that is very inexpensive and easy to use. For the purposes of this article, an “application” is a long-running process that likely comprised of multiple containers and likely interfaces with users. A “job” is a short-running process that is typically a single container and likely does not provide an interactive interface.
From https://learn.microsoft.com/en-us/azure/container-apps/compare-options#azure-container-instances:
Azure Container Instances (ACI) provides a single pod of Hyper-V isolated containers on demand. It can be thought of as a lower-level "building block" option compared to Container Apps. Concepts like scale, load balancing, and certificates are not provided with ACI containers.In our latest project, our team used ACI for synthetic data generation and ingestion of millions of records into a system. This article will describe how we used ACI for this purpose and why we feel it was a good fit.
Serverless
Azure Container Instances can be deployed as a resource directly into a Resource Group. They do not require any additional infrastructure such as a Kubernetes cluster. They are also billed by the second, so you only pay for the time they are running (although there is a minimum charge of 1 CPU and 1 GB of memory). This makes them a great option for jobs that are not running all the time.
Stateless and Scalable
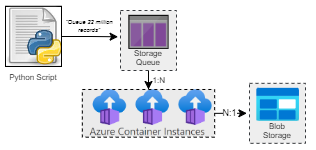
We needed to generate ~22 million records in groups of 3k-4k that were related. That means a full generation job is comprised of about 6k units of work. We might spin up as few as 4 instances of ACI or as many 20 to process a job like that. Ideally we do not want to manage any state, but we want our units of work to be processed reliably and be distributed across the instances we have available.
We used a Python script to populate an Azure Storage Queue (each message containing the configuration for 1 unit of work) and then a Powershell script to provision x number of Azure Container Instances to drain that queue. A message that processes successfully, generates a document in Azure Blob Storage. If a message fails to process, it will go back in the queue for re-processing. If it fails too many times we put it in a dead letter queue for manual inspection. As each message contains all configuration information needed for generation, there is no external state to manage. Once all the work is complete, we simply ran the Powershell script again to delete the ACI instances.
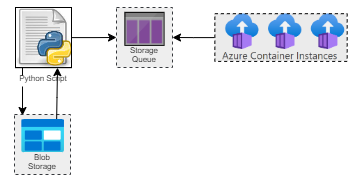
The ingestion process was very similar. We used a Python script to read all the files in Azure Blob Storage and populate an Azure Storage Queue. Again, each message contained all configuration information necessary for ingestion. We then used a Powershell script to provision x number of Azure Container Instances to drain that queue. Message durability was the same as before and at the end we used the script to delete the resources.
Alternatives
There is certainly nothing wrong with using AKS or Container Apps for this purpose, in fact, because you could use KEDA with those services, you could scale your instances >0 when there are message in the queue and to 0 when there aren’t. However, we felt ACI was a very simple and inexpensive option for this use-case.