Hello Jetpack Compose developers,
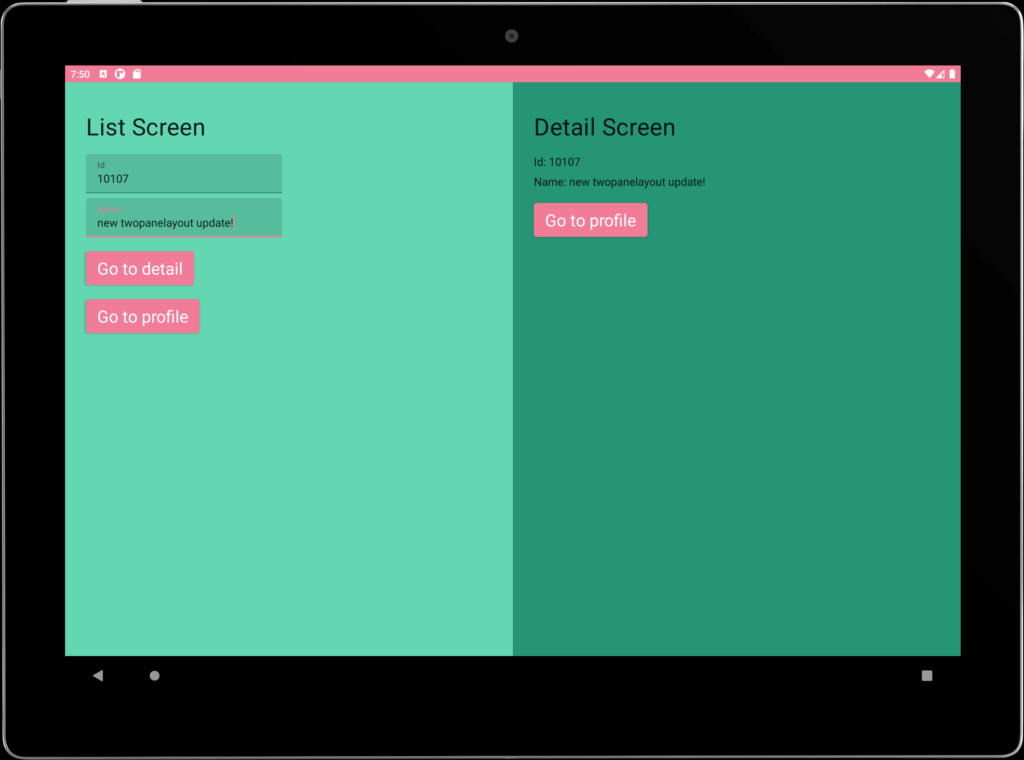
This week, we’re super excited to announce the release of ! This new component is part of Accompanist, Google’s “sandbox” for experimental Jetpack Compose APIs. The Accompanist Adaptive library already contains the component, which we tested out late last year, so will be the second ...






 Light
Light Dark
Dark