

Hello prompt engineers,
A few weeks ago we finished a series of posts building an AI chatbot using the Jetchat sample with OpenAI. The sample uses the chat and image endpoints, but has the same limitation as many LLMs, which is that its knowledge is limited to the training data (for example, anything after September 2021 is not included). A common requirement for extending these models is to respond with newer data, or internal corporate data, that isn’t part of the model. Re-training isn’t an option, so other patterns have emerged to incorporate additional datasets into chat conversations.
I presented a session at droidcon SF last week, so it seemed appropriate to take our existing JetchatAI sample and enable it to answer questions about the conference schedule.
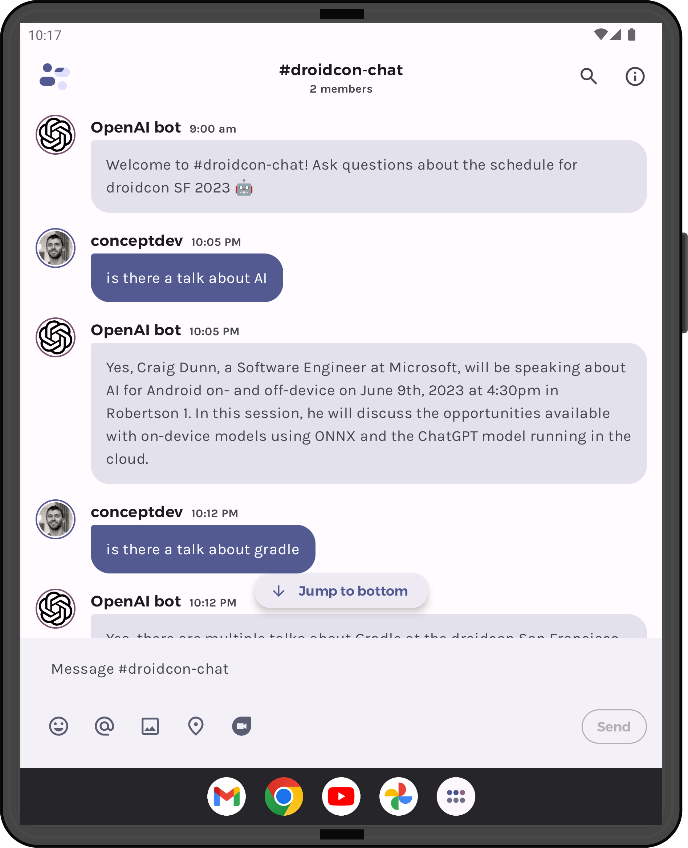
Figure 1: JetchatAI with droidcon embeddings
It’s RAG time
RAG is short for Retrieval Augmented Generation (see also this paper from Meta) and describes a pattern for querying LLMs where we first examine the user’s input and try to determine what data they’re interested in, and then if needed pre-fetch related information to include as ‘context’ in the actual request to the model.
This additional context could come from the internet, a database, or any other query-able source, including internal documentation or personal content.
The hard part is figuring out, from the user’s input, exactly what information do we need to pre-fetch? There could be a number of approaches, from a custom model trained on extracting query intent for a given use-case, to something simple like extracting keywords and conducting a search. Some different approaches for generating responses are discussed in this blog about using OpenAI with Azure Cognitive Search.
NOTE: A common question on this approach is “once you’ve pre-fetched information, why not just show that to the user? Why send the augmented query to the LLM at all?”. The answer lies in the model’s ability to summarize the collected information, hopefully ignoring irrelevant data, and crafting a text response that most directly answers the original question.
This diagram from the Azure blog helps to visualize the process:
- User enters their question into a chat session.
- The orchestrator looks at the query and decides if more information is required.
- The orchestrator “retrieves” relevant content from its data sources. Information should be relevant and concise (there are size limits on LLM queries).
- The final prompt is constructed by concatenating (“augmenting”!) the user question with the pre-fetched data. Additional “meta-prompt” text may be added to instruct the model to use the additional data to answer the question.
- The LLM will incorporate the pre-fetched data into its answer, appearing to have knowledge not included in its training dataset!
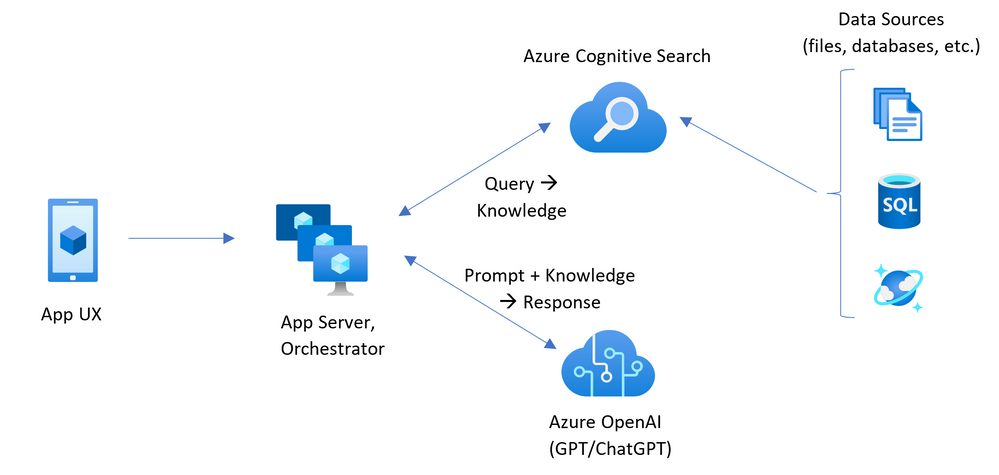
Figure 2: Architecture diagram showing cognitive search being used to augment a ChatGPT prompt
For the droidcon demo I extracted the session information into a collection of text chunks to serve as the data source. To determine whether there were any relevant conference sessions in a given user question, I used another LLM feature: embeddings.
What are embeddings?
The OpenAI blog has a great introduction to embeddings. An embedding is a numerical representation of content within an LLMs conceptual space, a vector with hundreds or thousands of dimensions. OpenAI has an embedding endpoint that will return the vector for any text input.
This visualization from the OpenAI blog shows how text snippets with related concepts cluster together in the embedding space. The number of dimensions in the vectors has been mathematically reduced from 2,048 to 3 dimensions to make it easier to read. Each colored point on the chart represents one or two sentences, such as “Phil Gilbert (born 15 November 1969) is an Australian rules footballer. He played for both the Melbourne and Freemantle Football clubs in the Australian Football League” or “TSS Olga was a steam turbine cargo vessel operated by the London and North Western Railway from 1887 to 1908”. The chart shows how the embeddings (the vector, or coordinates) for similar concepts are clustered together in the embedding space, and color coded to show how text about different categories is distributed.
![]()
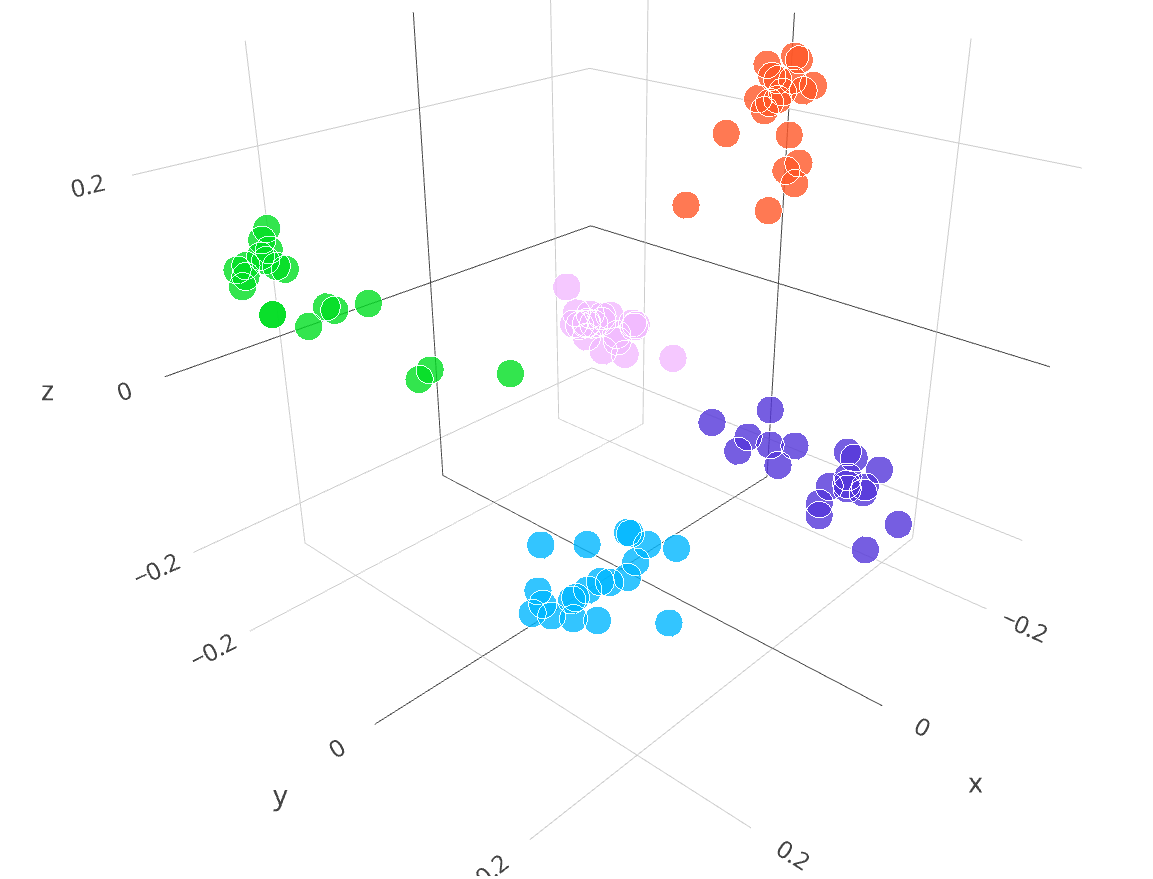
Figure 3: simplified visualization of different embeddings (source: OpenAI.com/blog)
This property of embeddings – where similar concepts are “close” to each other – can be used evaluate similarities between two chunks of text using vector operations like dot product. For additional chunks of text, we can create an embedding vector, “map” it in the visualization, and determine whether that text fits into one of these five categories based on how close it is to other embeddings.
Use embeddings to augment chat completions
To extend JetchatAI to be able to answer questions about the droidcon schedule:
- Create a “database” of the droidcon session information
- Generate an embedding vector for each session
- For each chat input message, generate an embedding vector, and then compare it (via dot product) with each of the sessions
- Construct LLM prompt including relevant session information (determined by dot product similarity scores)
- Show LLM response in chat
1. Session “database”
Although you can use vector databases to efficiently store embeddings and their associated content, this simple demo just stores the data in memory using a Map. An example of the raw session data is shown below. Note that the data has been semi-structured as key-value pairs – this helps the LLM understand context when formulating its final response.
val droidconSessions: Map<String, String> = mapOf( "craig-dunn" to """Speaker: CRAIG DUNN Role: Software Engineer at Microsoft Location: Robertson 1 Date: 2023-06-09 Time: 16:30 Subject: AI for Android on- and off-device Description: AI and ML bring powerful new features to app developers, for processing text, images, audio, video, and more. In this session we’ll compare and contrast the opportunities available with on-device models using ONNX and the ChatGPT model running in the cloud.""" //...
There are about 70 sessions in the example file DroidconSessionData.kt.
2. Generate embeddings
The code to generate embeddings is in the initVectorCache method in DroidconEmbeddingsWrapper.kt. Once again, in a production app you would pre-calculate and store these in a database of some kind. For this demo, they are calculated on-the-fly.
This code uses the OpenAI embedding endpoint to loop through all the sessions and create an embedding vector to be stored in memory:
for (session in DroidconSessionData.droidconSessions) {
val embeddingRequest = EmbeddingRequest(
model = ModelId("text-embedding-ada-002"),
input = listOf(session.value)
)
val embeddingResult = openAI.embeddings(embeddingRequest)
val vector = embeddingResult.embeddings[0].embedding.toDoubleArray()
vectorCache[session.key] = vector
}
3. Process new chat messages
Creating an embedding for each message is done in the grounding method using the same OpenAI endpoint. The message vector is then compared against the embeddings for each session – similar to an inefficient index lookup in a database. The results are sorted so that the best matches can be easily extracted:
for (session in vectorCache) {
val v = messageVector dot session.value
sortedVectors[v] = session.key
}
4. Construct augmented prompt
When the similarity (calculated by the dot product) is above a certain threshold (0.8 for this demo), the session text is included in the prompt that will be sent to the LLM.
This code builds the augmented prompt, adding additional context and instructions at the end.
if (sortedVectors.lastKey() > 0.8) { // arbitrary match threshold
messagePreamble =
"Following are some talks/sessions scheduled for the droidcon San Francisco conference in June 2023:\n\n"
for (dpKey in sortedVectors.tailMap(0.8)) {
messagePreamble += DroidconSessionData.droidconSessions[dpKey.value] + "\n\n"
}
messagePreamble += "\n\nUse the above information to answer the following question. Summarize and provide date/time and location if appropriate.\n\n"
}
The initial chat message will be added to the end of this prompt before being appended to the conversation data structure and sent to the model. The augmented prompt is never shown in the app.
5. Show response
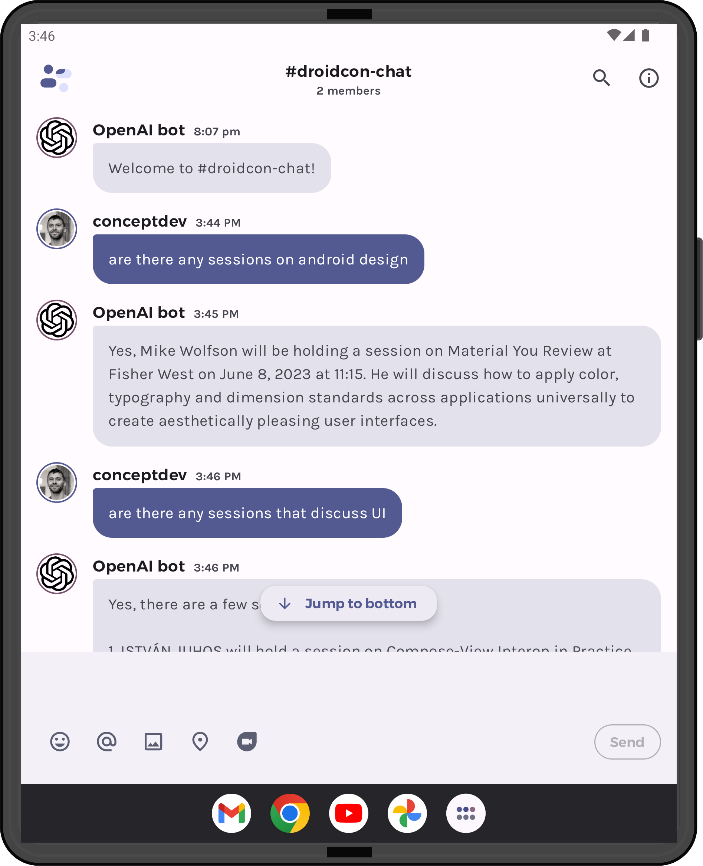
The response from the LLM is displayed directly in the chat. If the prompt was augmented with additional data, the response will probably include some of that information, although the model may also decide to ignore information that it doesn’t feel relevant.
The additional instructions added to the augmented prompt – "Summarize and provide date/time and location if appropriate" – help the model give better answers by ensuring this information is included each time.

You can download and try out the sample from the droidcon-sf-23 repo by adding your own OpenAI API key.
NOTE: A number of shortcuts have been created to keep this demo simple – such as calculating embeddings on-the-fly, including the session metadata for embedding, picking an arbitrary 0.8 cutoff to test similarity, and probably other hacks. While it shows how easy it is to bring additional data to LLM responses, please look for better solutions if you take the next step and start incorporating LLM chat into your production apps.
Resources and feedback
The code for this sample and the others that were presented at droidcon SF 2023 is available on GitHub.
If you have any questions, use the feedback forum or message us on Twitter @surfaceduodev.
There will be no livestream this week, but you can check out the archives on YouTube.
0 comments