

Background
A scenario commonly encountered in public safety and justice is the need to collect, store and index digital data recovered from devices, so that investigating officers can perform objective, evidence-based analysis. This evidence can be in the form of media files (video, audio, or image files) or computer readable documents (documents, spreadsheets etc.) and is typically collected from devices using digital forensics systems and compiled into case specific ‘workspaces’ using legal e-discovery tools.
CSE recently partnered with a customer to develop an advanced evidence analysis platform that use Azure AI technology for automatic labelling of media and documents collected as evidence.
Problem
The customer has an investigation team that collects, preserves and stores multiple terabytes of evidence in the form of images, audio, video, and digital text files that have been recovered directly from devices (e.g., laptops and mobiles) and other relevant sources.
The data consists of multiple TBs of raw data files and metadata that is recovered using an on-premise digital forensic software, NUIX. A team of twenty to thirty investigators and legal officers search, examine, and compile this data as evidence using Relativity, a legal e-discovery system.
The investigator needed better methods to review the significantly large volume of data to identify the files needed for evidence. Typically, content moderators and translators manually examine each file and tag it based on their interpretation of the content. This process was time consuming, potentially error- and bias-prone, with a large backlog of digital evidence building up waiting to be analysed. They wanted to utilize AI to “look inside” the recovered files to identify relevant information and enable investigators to build evidence more effectively and efficiently.
Challenges we needed to consider
- The data was highly sensitive and confidential which meant that security at rest and in transit was an important area of focus.
- The solution needed to use pre-built AI services as much as possible to limit the need to train staff in machine learning and be able to quickly reap the benefits of the suite of tools offered by Azure’s Cognitive services
- The services and the data storage needed to support large data volumes (between 500 TB and 1 PB) of raw data over a low bandwidth connection to the on-prem office batches of up to 100,000 files.
- Since Azure Cognitive Services has rate limits, concurrency control and throttling had to be implemented in the workflow.
Solution
The solution we proposed would focus on secure upload and preparation of raw data for processing in the cloud, labelling the data with the insights derived from AI and providing them to the investigation team in an easy to consume form so that they may process the evidence more effectively.
Secure Data ingest and storage
- Data recovered by the NUIX e-forensics tool is uploaded to a secure data lake.
- The data is validated, cleaned, and prepared for enrichment.
Secure AI enrichment and orchestration
- The uploaded data is run through Azure AI technologies to automatically extract insights and provide language translation.
- The first phase focussed on video, image, and digital text files.
Search and E-discovery
- The native data, it’s metadata and the AI enrichments are exported to the Relativity e-discovery tool providing the ability to search on these insights and create reports. For example, if video evidence was analysed, the user would get searchable insights such as known places or objects, text on screen, and transcript of the audio
Personas
 |
Content Administrator |
The Content Administrator’s objective is to make sure that the evidence retrieved from the e-forensics system is available for processing on the cloud platform. They are responsible for correcting any validation errors in the metadata and index file (for e.g., missing files, incorrect format, incomplete upload) with the help of the e-forensics system.
 |
Investigator |
The Investigator’s objective is to use the data in the e-discovery system as evidence in legal prosecution. They will log in to the e-discovery tool and search for and collate the files needed for their investigation. They can also leverage the Video Indexer portal to help with the search and discovery of video files.
Outcome
Design considerations
Logic apps v/s durable functions v/s Azure Cognitive search
Early in the project, the team had to make a design choice between Logic Apps, Durable functions, and Azure Cognitive search for implementing the enrichment workflow. We decided to go with the serverless technologies instead of a container-based implementation to free the customer from the burden of managing the hosting platform. There were various considerations that informed this choice:
- Cognitive search does not support easy integration of long running functions. One of the main AI services we planned to leverage was Video Indexer, which can take many minutes to process a large video, while a Cognitive Search custom skill has a fixed 230 second limit.
- This project did not need a search index to be created as indexing and searching were already provided by the e-discovery system.
- Complex branching logic is not easily represented in Cognitive Search pipelines.
- Logic apps have a lot of built-in connectors for Cognitive services and storage (with retry and exponential backoff) making it relatively easy to get start delivering value out-of-the-box.
- Logic apps provide built in support for throttling which is crucial when considering the rate limits imposed Azure Cognitive services
- The graphical design interface of Logic Apps made the design and review of conditional logic easier, especially for the MVP phase, which had a high degree of iterative design and implementation based on customer feedback
Based on the above reasons, for this project we decided to use Logic Apps for the branching logic and connections to Cognitive services and storage and Azure functions for any custom implementation
Architecture
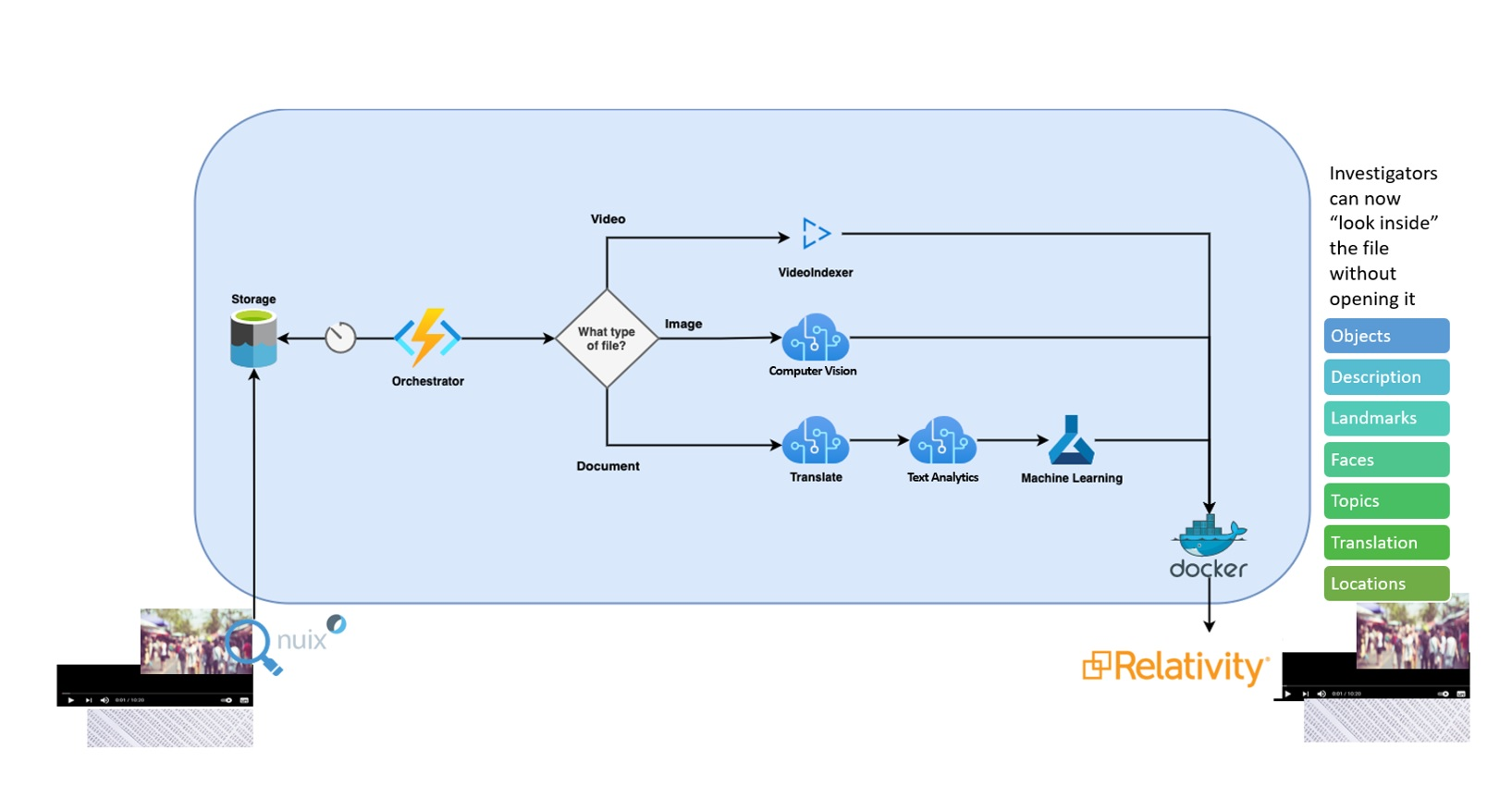
Nuix (a digital forensics tool) is used by field personnel to extract the image (i.e., contents of the hard drive) from devices. This is in the form of native files and metadata associated with these files. The device image is then securely uploaded to Azure Data Lake, where it is picked up for validation and preparation.
The is a Logic Apps workflow that examines the native files and triggers different workflows based on whether they are videos, images, or machine-readable documents. These are then passed through Azure Cognitive and ML services such as Video Indexer, Computer Vision, Text Translate and Text Analytics for AI based enrichment.
The output of the AI services, along with the native file and the e-forensics metadata are now exported to the RelativityOne e-discovery system. Here, the Investigators are now able to perform a search based on much richer context such as image descriptions, locations, landmarks, video transcripts etc.
Technologies used
- Azure Cognitive Services
- Azure Logic Apps
- Azure Functions
- Azure Service Bus
- Azure Data Lake
- Azure Cosmos DB
Enrichment workflow details
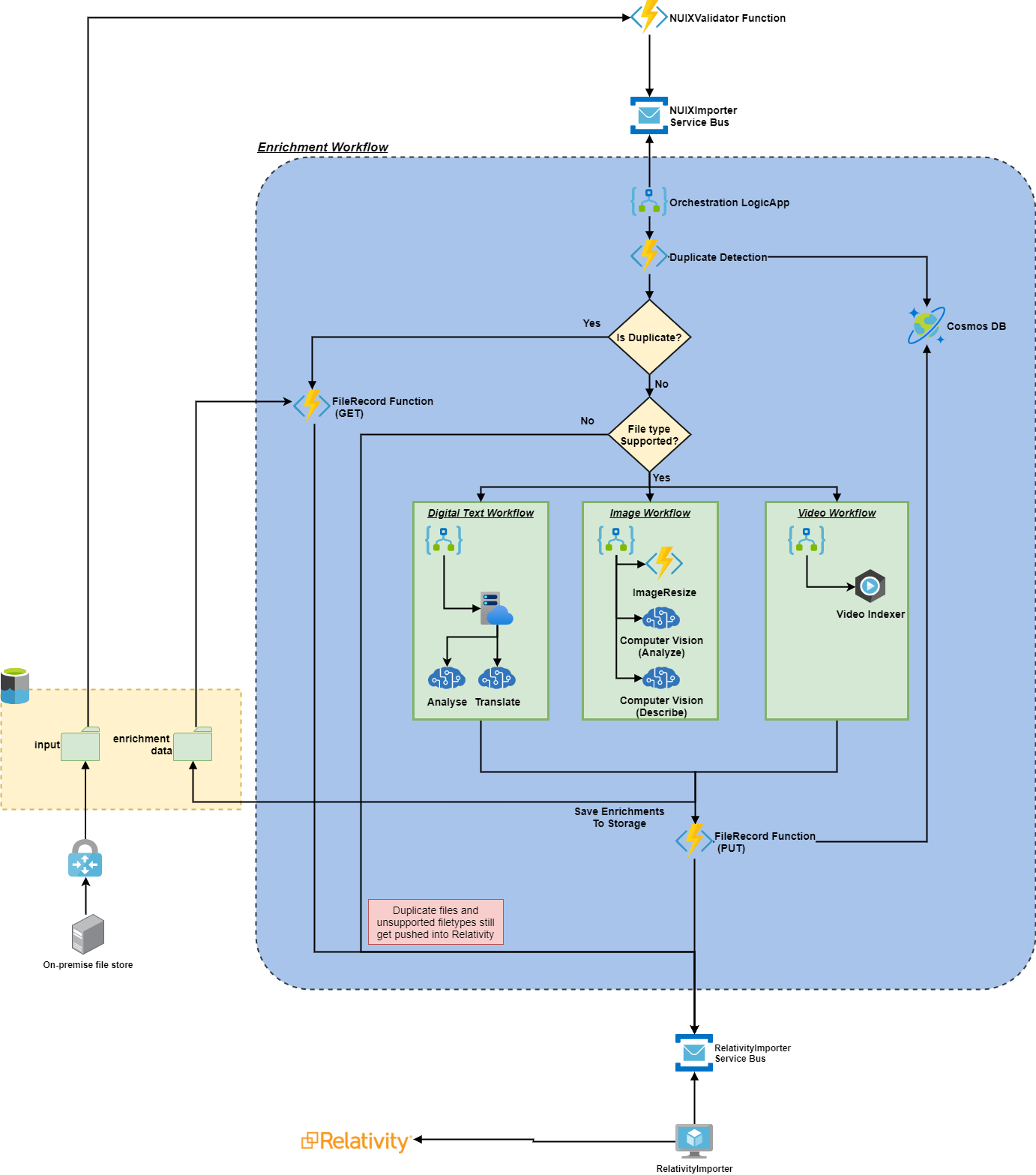
- The image of a device is securely uploaded to an Azure Data Lake. This contains the native file, any extracted text and the “loadData” i.e., the metadata extracted by NUIX. We referred to this as a ‘batch’.
- The NUIXValidator function validates and cleans the incoming data and create a message per native file on the NUIXImporter Service bus
- The main orchestration function is triggered by messages appearing on the service bus.
- The duplicate detection function checks if the same was processed before, and if it was it skips the entire AI enrichment branch of the workflow.
- Based on the file type, it is now processed by either a video, image, or digital text workflow. Each of these call out to specific Cognitive services to derive AI based insights into the content of the file. The digital text workflow is further augmented by a custom model that is trained to extract entities that are specific to the customer.
- The AI enrichments are saved back to the data lake and a message consisting of the location of the native file, the NUIX metadata and the AI enrichments is put on the RelativityImporter service bus.
- The RelativityImporter maps the incoming message to the configured fields in the Relativity workspace and the file is now ready for search and e-discovery!
De-duplication
There is a high likelihood in evidence analysis systems that we will encounter the same files extracted from multiple sources/devices, so we need a way of identifying duplicates and therefore preventing wasted compute resource and costly AI analysis for same result.
The approach we took was to create a duplicate detection function to calculate a hash of each file that went into the enrichment pipeline. If the file does not match an existing hash, it meant that the system had not seen this file before, so it was processed through the AI services. After processing, the AI insights were collated as json and save to the data lake with the hash as a filename. If the hash of the file was already in the system, the AI insights were simply retrieved from the data lake instead of re-running enrichment on the file again. Each time the AI insights were saved to the data lake, they were stamped with the system version that generated the insights.
For example, if the system had not seen a video file previously it would be sent to the Azure Video Indexer for processing. The insights from the Video Indexer would then be stored back to the data lake and sent to the RelativityImporter. Alternatively, if the file hash was found, the Video Indexer enrichments would be retrieved from the data lake (skipping the Azure Video Indexer step) and sent in the message to the RelativityImporter. Thus, the cost of running AI processing on the same video content was avoided.
There is a possible extension to this system where similar content can also be excluded from re-processing, for e.g., videos with different encoding or images with different resolutions.
Re-processing
It may be required at times to re-run content that has already been exported to the e-discovery tool again through the enrichment workflow. Situations that call for this include when an Azure AI service is upgraded, when the enrichment workflow is enhanced, or if there has been an error in the processing that is now fixed.
For example, consider the scenario where videos recorded in a language unsupported by Video Indexer were processed through the workflow and exported to Relativity. Later, Video Indexer made improvements to their service and added support for this language. In this case, the Content Administrator might decide to re-run all such videos and update the records in Relativity with the additional insights now available. The De-duplication logic would prevent these videos from being processed by Video Indexer as they would be considered duplicates of existing data. Hence, we designed a solution whereby the enrichment pipeline could be run for files even if they were flagged as duplicates.
For the MVP, we took a straight-forward approach allowing the Content Administrator Persona to flag either an entire batch or specific documents within a batch for re-processing. This would be done by creating a simple text file containing identifiers of the files to re-process, and for re-processing the entire batch, the text file will be left empty, alongside the batch of data uploaded to the data lake. This would signal the system to “force-enrich” the files from the batch even if they were duplicates.
Observability and Monitoring
As with any distributed system, the ability to observe and monitor the system in a consistent manner was key to successfully operating it in production. We leveraged the capabilities of Azure Monitor which provided various mechanisms to collect and present logs, metrics, and trace data.
For coded components (like Azure Functions, APIs, and containers) Application Insights was used to collect logs and telemetry. Azure Logic Apps is already integrated into Azure Monitor and provides trace logs. These can be supplemented by adding tracked properties. The gathered log data was queried and analysed using Log Analytics and Azure Dashboards were created for common scenarios.
The logs and metrics generated in code also logged additional contextual properties that made it possible to consistently query across multiple components. This helped when tracing the path of a file through a workflow (using correlationID), the errors in a batch of files (using batchId) or the current version of the system (using SystemVersion and ComponentVersion)
Performance considerations
By default, Logic Apps have no limit to the number of concurrent triggers. There are limits on the number of actions which are 100,000 (default) up to 300,000 (maximum) per 5-minute period, but that can be increased by enabling High Throughput Mode .
However, the downstream systems (Video Indexer, Computer Vision etc) will all have rate limits in place which the Logic App could easily hit if left to run in its default mode of operation (in normal operation we expected the customer to be processing up to 100,000 files in one batch). To mitigate the impact on downstream systems, we enabled concurrency control. Concurrency control is a Logic App mode which limits the number of concurrent triggers the Logic App will process at a given time. Concurrency control can be set to allow up to 50 concurrent instances.
In our solution, we enabled concurrency control on the main orchestration Logic App and ran load tests to derive the concurrency setting suited for the tiers of Cognitive Services selected by the customer. The NUIXValidator service bus served as temporary store for incoming files as they waited to be processed by the orchestrator workflow.
The solution can be extended further to make it possible set different concurrency settings for the file specific ‘child’ logic apps. This way, the concurrency can be tuned according to the rate limits of the Cognitive Services specific to that file type. Also, to increase the throughput of the system, multiple instances of Cognitive Services can be used in a load-balanced manner.
Benefits for the customer
As the customer starts to use this solution in production there will be an initial phase where they load their existing backlog of data into the cloud to be analysed by this system and uploaded to Relativity leading to a substantial improvement in the discoverability of files to use as evidence. Since the Investigators are already proficient in using Relativity, there is no need to train them in new tooling, but now they have the additional option to use the Video Indexer portal for finer grained interactions with video data.
As the solution largely uses pre-built AI services and serverless technologies, as these services are improved, the customer automatically receives these changes. The re-processing scenario gives them the ability to re-run the improved AI processing on already imported data.
The asynchronous nature of the Logic Apps workflow solution is better suited for low bandwidth connection from on prem servers and for the processing of large media files. Concurrency controls allow them to tune the processing of large batches to prevent hitting the consumption limits of the AI services.
Lastly, the solution has some strategies built in for cost savings. When Video indexer processes video files, these get stored in a Media Services account. Hence, to save storage cost, the native video files are not exported to Relativity but a pointer to the Video Indexer portal is exported in its place. Also, the strategy to skip processing of duplicate files saves on unnecessary AI processing costs.
Conclusion
Our project tackled a common scenario in public safety and justice where large amounts of data has been gathered during an investigation that needed to be analysed and labelled so that it may be used as evidence for prosecution. The design decision to use out-of-the-box AI services and serverless technology gave the customer faster onboarding onto Azure, and the ability to unlock more value from their data and move into production with agility.
We hope that this code story will encourage other digital transformations where Azure’s AI services are leveraged to gain insights easily and quickly from large data sets, without the need to deploy custom machine learning models.
For additional information
For a generalised code sample that demonstrates how this solution was built using Logic Apps, Azure Functions and Azure Cognitive services refer to the AI Enrichment Pipeline sample on the Video Indexer Azure samples git repo.
Contributors
Alysha Arshad, Peter Daukintis, April Edwards, Adrian Gonzalez, Lawrence Gripper, Randy Guthrie, Martin Kearn, Peter Maynard, David Moore, Martin Peck, Shane Peckham, Dave Storey
Cover Photo by Markus Spiske on Unsplash