
This blog post was co-authored with Anastasia Zolochevska
Background
In the last eight years, poaching in Africa has been happening at an alarming rate. Currently, the continent loses three rhinos a day. As part of our team’s mission to find new ways that technology can positively impact our world, we’ve been collaborating with the Combating Wildlife Crime team from Peace Parks Foundation (PPF), in partnership with the South African conservation agency Ezemvelo KZN Wildlife (Ezemvelo). Together, we’re working to support rhino anti-poaching efforts through the power of Cloud Computing and AI on Azure. PPF facilitates the establishment and sustainable development of transfrontier conservation areas throughout southern Africa, with the aim of restoring critical ecosystems to the benefit of man and nature alike.
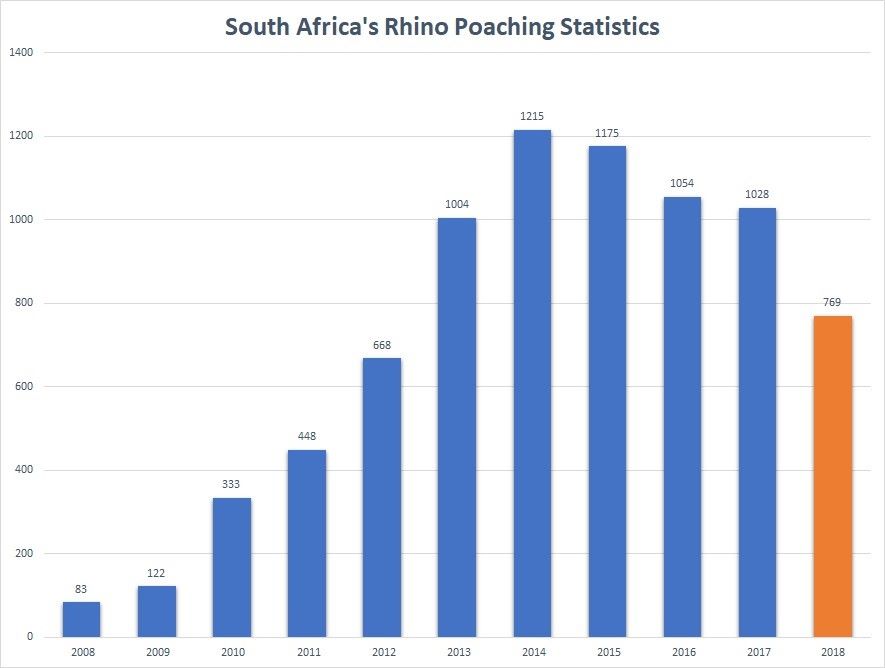
Figure 1
Rate of rhino poaching in recent years
Digital transformation in the AI for Good domain assists PPF and Ezemvelo to take a holistic view on how to strategically plan rhino anti-poaching activities. The smart park initiative coordinates collaboration across various players in the wildlife crime prevention space and empowers timely decision making by providing tools for data analysis.
In 2018, PPF piloted the approach of using images taken by camera traps as the source of additional insights on what’s happening in conservation areas:
This blog post describes the challenges, solutions, and technical details related to building a scalable and reliable system that can trigger rangers’ rapid response through a real-time alert announcing if a person has been detected in the monitored area. A subsequent blog post will cover more in depth Machine Learning specifics of the problem space.
Challenges and Objectives
Our plan was to build a reliable end-to-end system that could rapidly detect suspicious human activity in the conservation areas and alert rangers. The challenges included:
- Designing a system to achieve balance between price, complexity and fault tolerance.
- Addressing privacy, compliance, and security.
- Ensuring the pipeline is resilient to intermittent failures.
- Having an AI solution that can detect people in conditions with very limited light (e.g., nighttime photos taken in the savanna).
Solution
Design considerations
In designing the architecture of the alerting system, we adhered to the following requirements:
- Build a scalable solution that can handle a variable (through day, night and seasons) load of camera trap based input.
- Guarantee the resilience of the solution to expansion of the camera trap installations over time.
- Ensure a quick turnaround time so that rangers receive an alert as fast as possible.
- Make it easy to deploy the alert system to additional conservation parks.
- Embed our system in a smart park.
- Find a solution that takes into consideration price, complexity and fault tolerance.
- Ensure privacy, compliance and security are handled with the high standard required by the crime prevention use case.
- Enable PPF and its partners to have automatic build and deployment processes.
In the subsequent sections we describe the architectural design of the system that satisfies the above requirements.
Azure Functions-based pipeline
As PPF doesn’t have resources to manage server infrastructure on its own (i.e., a virtual or physical server, the operating system, and other web server hosting processes required for an application to run), we were considering Platform as a Service (PaaS) and Serverless approaches for hosting our application. Both of these approaches eliminate the need for management of server hardware and software. The primary difference is in the way the application is composed and deployed, and therefore the scalability of the application.
- Azure offers Web Apps for PaaS. With Web apps, an application is deployed as a single unit. Scaling is only done at the entire application level.
- With a Serverless approach using Azure Functions, an application is composed into individual, autonomous functions. Each function is hosted by an Azure Function and can be scaled automatically as the number of requests increases or decreases. It’s a very cost-effective way of paying for compute resources, as we only pay for the time that the functions get called, rather than paying to have an application always running.
We chose Serverless deployment with Azure Functions as our hosting platform. An additional benefit to choosing Azure Functions is the built-in auto-retry mechanism. Some pieces of our code (which we isolated into functions) depend on third-party services that can be down or have connectivity issues. The auto-retry mechanism becomes important to ensure fault tolerance. We decided to use queues for communication between functions. When a function fails, Azure Functions retries the function up to five times for a given queue message, including the first try. If all five attempts fail, the functions runtime adds the message to a poison queue. We can monitor the poison queue and take appropriate actions.
Architectural overview
Regardless of the model, any motion-activated devices (camera traps) support an ability to send photos by email, so we leveraged this feature to move images from a device to the cloud. As our email service we used SendGrid, which provides reliable transactional email delivery and supports the ability to setup webhook to intercept email. This webhook becomes the entrance to our image-processing pipeline.
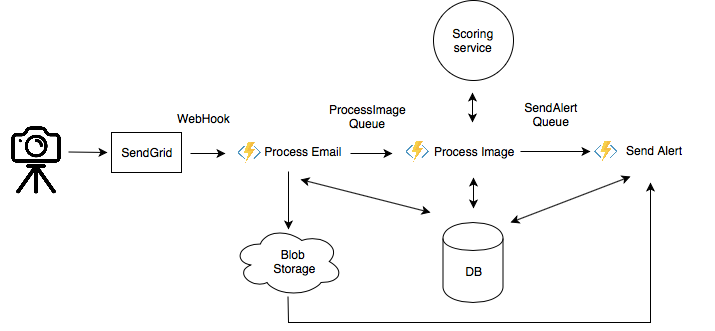
Figure 2
The solution architecture
The SendGrid webhook triggers the Process Email Azure Function. This function parses the email to extract information about the organization and camera, saves this metadata to an Azure PostgreSQL Database, and uploads the images to Azure Blob Storage. An output binding of the function is the Process Image queue where the function puts blob URLs.
The Process Image Azure Function is then triggered from this queue. Its main job is to call our scoring service to get a probability of people detected in the image. More details about the scoring service will be covered in the next section. Based on the detection results and business logic, the function decides if an alert should be sent to rangers. If that’s the case, it delivers the blob URL to the SendAlert queue.
Each park can have a specific tool that rangers use for notifications, for example Command and Control Collaborator (CMORE), Domain Awareness System (DAS), emails etc. The SendAlert Azure function sends alerts to the appropriate notification system. The alert contains the location of the camera, the timestamp of the photo, the results of the detection, and the photo attached. Here is an example of an alert in CMORE:
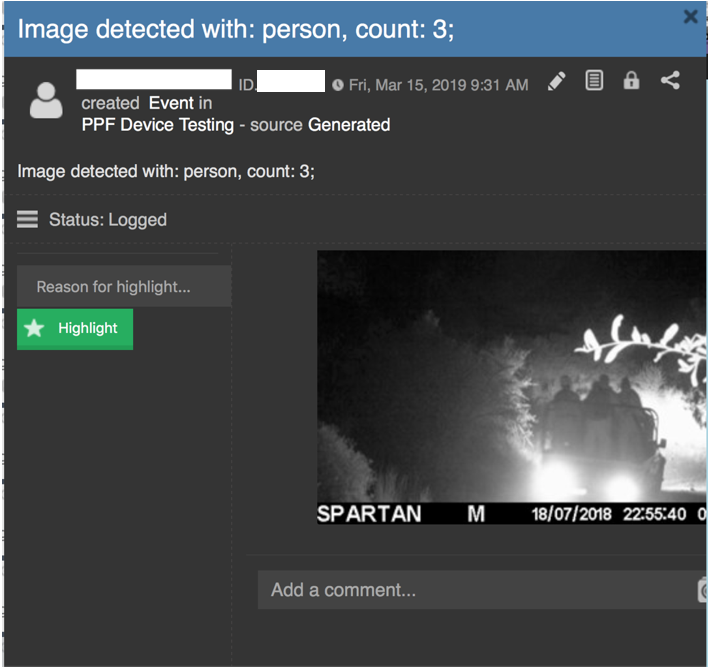
Figure 3
(Please note: partial view due to sensitivity of the data)
When deploying a complex service to Azure, it’s important to have at least one test environment to check the system’s health before proceeding with deployment to production. We used Azure resource groups that have an identical list of resources in order to separate Dev and Production environments.
To automate the initial deployment of Azure resources, we used Azure Resource Management (ARM) templates. Using ARM templates, we can repeatedly deploy the solution throughout the development lifecycle and have confidence that resources are deployed in a consistent state. It is also important that with automated initial deployment we can make sure resources for Dev and Prod resource groups were created based on the same templates.
We used Key Vault for secure storing of secrets such as the SendGrid API key, password for database, etc. To optimize performance and cost, Azure Functions don’t read secrets from Key Vault directly. Instead, when Azure Functions are created with ARM templates, it reads the secrets from Key Vault and puts them as environment variables in the appropriate function app.
For continuous integration and deployment we used Azure DevOps. Each time a pull request (PR) is created with suggested changes, it triggers a PR build that runs unit tests and linting. When a pull request is completed and changes are merged to master, it starts a Master build that archives functions and puts them to artifacts. Completion of a Master build triggers automatic deployment of functions to the Dev stage. When changes are verified in the Dev stage and approved to be applied to production, a release of those changes to the Prod resource group can be triggered manually and requires at least one person’s approval. This whole process ensures that features are delivered safely as soon as they’re ready.
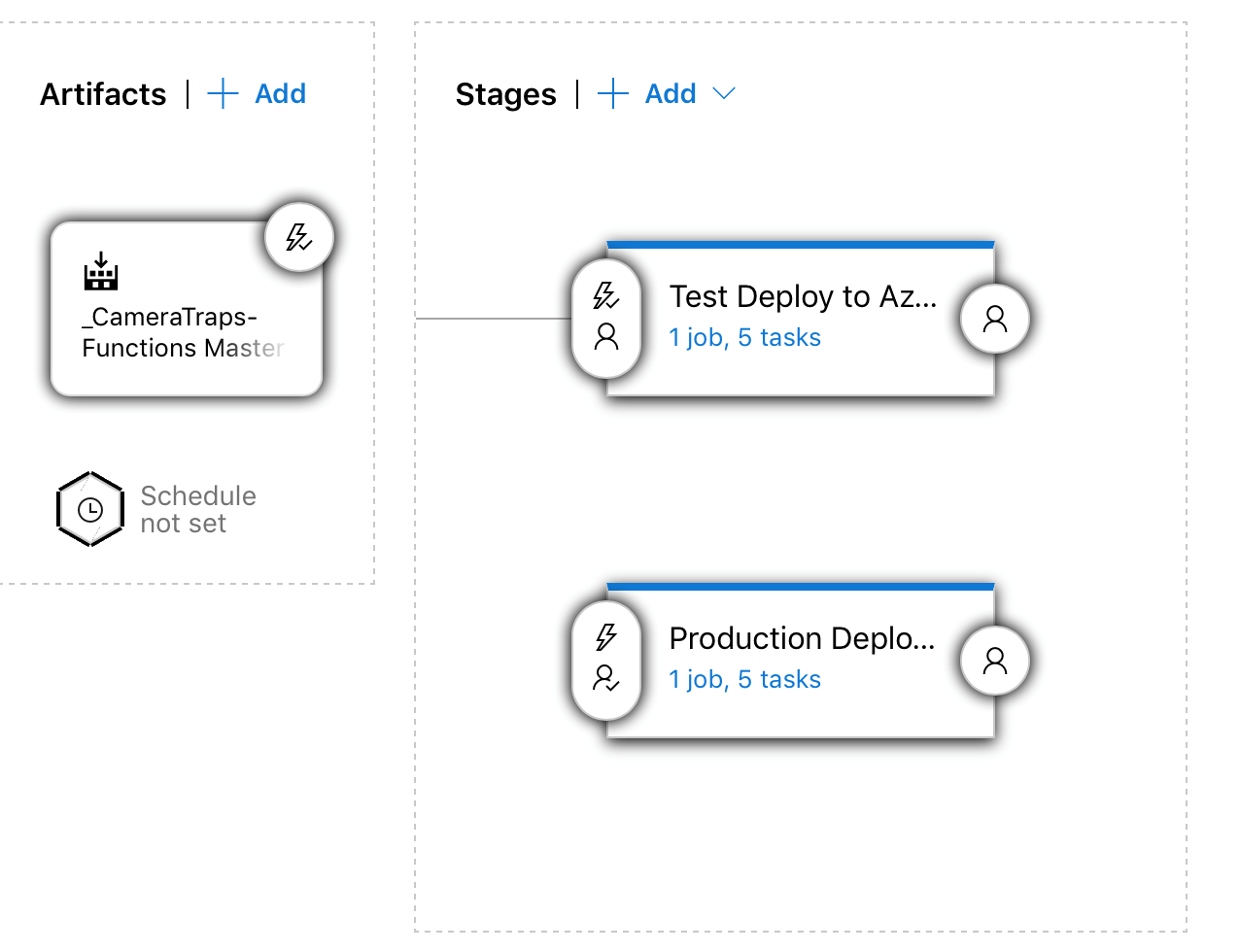
Figure 4
Azure DevOps
Machine learning operationalization
In this section we will cover the deployment of the Scoring Service.
Scoring is the process of generating prediction values based on a trained Machine Learning model given new input data – an image in our scenario. As we trained our custom model to detect people within the specific African game park environment, the result of the scoring service is the probability of detecting people on the given image.
The scoring flow end-to-end interaction with the trained Machine Learning model was done via sending POST messages to a web service. From a hosting/deployment perspective, we can treat the scoring service as a black box that takes images as input and returns results of people detected as an output.
To achieve the goal of having high-quality detection results we trained an object detection model using Python Deep Learning libraries Keras and Tensorflow.
It is worth mentioning that the current state-of-the-art algorithms are highly computationally- and memory-intensive, as they involve significant amounts of matrix-related calculations.
Design considerations
We identified the following requirements for the scoring service deployment:
- Response time should be less than 2 minutes
- Should be easy to maintain
- Reasonable price
- Scalable
- Fault tolerant
- Option to use GPU Compute
As the serverless architecture of the system is built on Azure Functions, it would be natural to consider Azure Function as hosting infrastructure for the scoring service as well. As of December 2018 (when we started the project), Python support in Azure Functions hasn’t been released to general availability. Hosting our model through Azure Functions would additionally limit the underlying infrastructure to being CPU only. With more and more cameras being deployed into parks, and even more advanced Machine Learning image analytics being developed, using GPU machines for scoring may eventually be not only faster but cheaper. We faced the same constraint with the App Service option.
Deployment of the scoring service manually as a web service on Azure Virtual Machine (VM) doesn’t make it scalable and resilient to faults. Deployment of a number of distributed VMs with a load balancer would solve that problem, but deployment and management of the system becomes cumbersome.
Further investigation brought us to the Azure Machine Learning service that became generally available in December 2018. Azure ML is a cloud service that can be used for the end-to-end Machine Learning model management life cycle – including training and deployment of Machine Learning models – all at the broad scale that the cloud provides. At the time of creation of this blog post there are 3 compute options available for the scenario of deploying a model to the cloud:
- Azure Kubernetes Service (AKS)
- Azure ML Compute
- Azure Container Instances (ACI).
The AKS option is recommended for real-time scenarios in production, as it is good for high-scale production deployments, provides autoscaling, and enables fast response times. It satisfied all our requirements and we chose Azure ML AKS as a hosting platform for our scoring service.
Scoring service hosting on Azure Machine Learning Kubernetes Cluster
Kubernetes is a container orchestration system for automating application deployment, scaling, and management across clusters of hosts. Azure offers an Azure Kubernetes Service (AKS) to make it simple to deploy a managed Kubernetes cluster in Azure. AKS reduces the complexity and operational overhead of managing Kubernetes by offloading much of that responsibility to Azure.
Azure Machine Learning builds front-end services on top of AKS for predictably fast latency. The default cluster deployed to Azure ML will have 3 front-end services. For fault tolerance all services should land on different VMs (nodes) – thus it’s required to have at least 3 VMs (nodes) in the cluster. Front-end Azure ML services, in addition to AKS services, consume resources – so it’s recommended to have at least 12 cores in the cluster. As a result of these considerations, the smallest AKS cluster will have 3 nodes of Standard_D3_v2 VMs, where each VM has 4 cores.
One of the benefits of using Azure ML AKS cluster is that it can be used for hosting multiple services. For example, different models can be deployed as a separate service to the same cluster. If that’s the case, autoscaling settings for each service will enable setting up resource distribution rules across the scoring web services: such as CPU and memory. At time of the creation of this blog post, Azure ML AKS did not support scaling on nodes level – the number of nodes (VMs) is defined during deployment. Autoscaling on the pods level (also called containers or replicas in this context) is supported. A pod is the basic building block of Kubernetes – the smallest and simplest unit in Kubernetes that you create or deploy and represents a running process on the cluster. Azure ML AKS autoscaler adjusts the number of containers (pods, replicas) depending on the current request rate. Currently for the PPF scenario we deployed only 1 type of scoring to Azure AML AKS – the model that detects people. We therefore turned off autoscaling.
In preparation for deployment we calculated the number of containers required for the service – how many parallel requests we can and need to process. The parameters below were taken into account to calculate the estimate:
- target rps (request per second);
- required time – duration of processing 1 request;
- CPU/RAM requirements for a container;
- maximum concurrent requests per container if model can process internally concurrent requests.
Here is the formula with an example calculation (when autoscaler is turned off):
targetRps = 20 req/s reqTime = 10 s/req maxReqPerContainer = 1 concurrentRequests = targetRps * reqTime => 286 containers = ceil(concurrentRequests / maxReqPerContainer) => 286 _16core machines = ceil(containers / 16) => 18
In this example, a cluster of 18 16-core nodes should be deployed. And, when choosing specific VM configuration, CPU/memory requirements should be taken into account. For example, if a container needs 4 GB of RAM and we deploy 16 of them per VM, nodes should have at least 64GB of RAM.
Deployment flow with Azure ML Python SDK
We used the Azure Machine Learning SDK to create the cluster and deploy the model.
First we created a workspace and registered the model:
print('Creating %s workspace...' % amlWorkspaceName)
ws = Workspace.create(amlWorkspaceName,
exist_ok=deploymentSettings['update_if_exists'],
resource_group=resource_group,
subscription_id=deploymentSettings['subscription_id'],
location=deploymentSettings['location'],
auth=AzureCliAuthentication())
print('Workspace created. Registering %s model from %s directory path...' %
(deploymentSettings['modelName'], deploymentSettings['scoringScriptsPath']))
model = Model.register(ws, deploymentSettings['scoringScriptsPath'],
deploymentSettings['modelName'])
Then we created an AKS cluster using just a few lines of code:
print('Model registered. Creating compute %s...' % compute_name)
provisioning_config = AksCompute.provisioning_configuration(vm_size=deploymentSettings['vm_size'],
agent_count=deploymentSettings['agent_count'])
compute = ComputeTarget.create(ws, compute_name, provisioning_config)
compute.wait_for_completion(show_output=True)
We packaged the few extra dependencies needed for model scoring and created an image of the model as well as the web service itself:
app_settings_file = 'app_settings.p'
pickle.dump(app_settings, open(app_settings_file, 'wb'))
model_image_config = ContainerImage.image_configuration(execution_script="scoringService.py",
enable_gpu=deploymentSettings['enable_gpu'],
docker_file="DockerSteps",
runtime="python",
dependencies=[app_settings_file, 'modelSetup.tar.gz'])
model_image = ContainerImage.create(name=imageName, models=[model], image_config=model_image_config, workspace = ws)
webservices = Webservice.list(ws, image_name=imageName)We provided custom docker steps at the stage of creating the web ser
These steps describe how to instal the system and python libraries needed for our Python-based (Keras and Tensorfow) scoring service:
RUN apt-get update && apt-get install -y libglib2.0-0 libsm6 libxext6 libxrender1 gcc libgtk2.0-0 RUN pip install azureml azureml-core applicationinsights RUN pip install azure-storage-blob keras==2.2.4 numpy pillow==5.4.1 progressbar2==3.37.1 RUN pip install pytest==4.1.1 setuptools==40.6.3 six==1.12.0 tensorflow==1.11.0 matplotlib==3.0.2 RUN pip install opencv-python RUN conda install -c menpo opencv3 RUN pip install keras_resnet
The people detection Machine Learning model had C dependencies that needed compilation. Here is how we did that:
# /var/azureml-app/ is where dependencies from ContainerImage.image_configuration are uploaded RUN mkdir model_dependencies RUN cd model_dependencies RUN tar -xvzf /var/azureml-app/modelSetup.tar.gz RUN python setup.py build_ext --inplace RUN pip install -e . RUN cd ..
Conclusion
During our collaboration with Peace Parks Foundation and Ezemvelo we built a scalable pipeline for processing images and alerting rangers of the presence of persons within a restricted territory. The pipeline design is extendable and could be adopted for processing additional sources of data – for example, audio. The approach we have covered in this article could be applied to any domain where independent stability is important (for example, manufacturing).
Digital transformation empowered by AI can make a difference in various areas of critical importance to our world: global climate issues, sustainable farming, biodiversity and water conservation, just to name a few.
We hope our narrative will spark ideas and help turn concepts into reliable software – perhaps even software with an AI for Good story.
Cover photo by Kevin Folk on Unsplash