
Partner Scenario – Guide Dogs
Over the last two years, we partnered with the Guide Dogs association to build Cities Unlocked. An iOS voice-guided navigation platform that aims to improve the overall mobility and safety of blind people. The goal of Cities Unlocked is empowering blind users to feel more independent to embark on journeys, and act in much the same way as a sighted person would. Cities Unlocked runs in the background while the phone remains in a users pocket or bag, freeing both hands to use for their cane and guide dog. We built a custom remote control and wearable headset with head-tracking motion sensors and a microphone to listen for voice commands like "Where Am I", "Take me to <<the park>>", "What's around me". spatial audio is used to provide more context for spatial direction of the information being called out to lighten their cognitive load and deliver an immersive user experience.
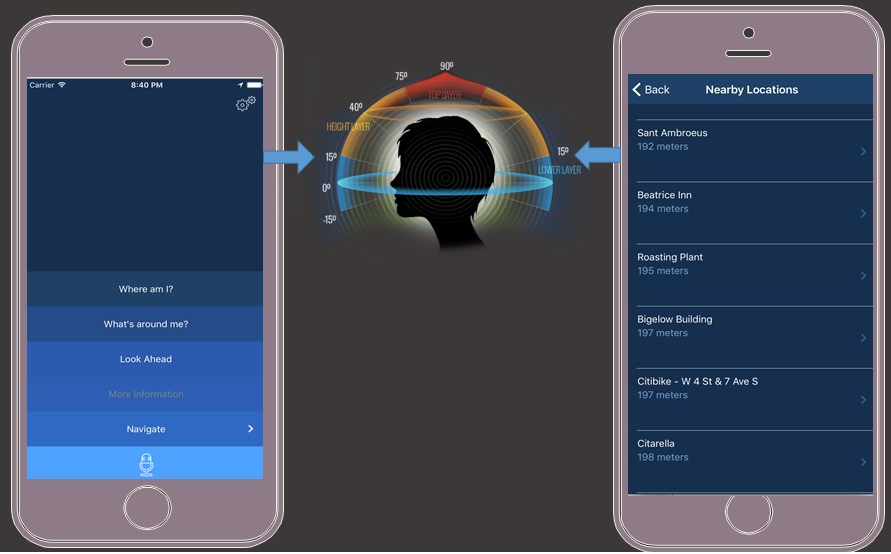
Features / Functionalities
- Take Me To – turn-by-turn navigation routing instructions.
- Location Context – automatic announcement of nearby points of interest(i.e. landmarks, sidewalks, crossings, etc) and location surroundings(i.e. roads, intersections, etc).
- More Information – providing more contextual information about the closest points of interest.
Technical Requirements / Challenges
Cities Unlocked announces location information throughout positional or head turn movements. The responsiveness and availability of our backend service had to be realtime. The planetary shapes we’re working with are often comprised of complex geometry structures(i.e. parks and buildings). The expectation was our services can seamlessly onboard new cities to the platform, while maintaining acceptable performance for data volume growth.
Our mapping data provider would also have to have a strong story around accessibility(i.e. crossings, curbs, sidewalks, stairs, etc). The data model also had to be flexible so we can easily add new places, features and tags.
Elasticsearch Overview
Elasticsearch is an open source search engine based on Lucene, and engineered to take data from any source to search and analyze it in realtime. Elasticsearch is considered an industry leader for developers seeking a distributed and highly scalable search solution.
Elasticsearch is a document database ideal for high search volume scenarios such as full text-relevancy scoring or geo-spatial search. Data documents are serialized in JSON format and held in indexes internally managed by Lucene.
Elasticsearch follows a clustered architecture where indices are evenly divided into shards, and horizontally scaled and distributed across a network of data nodes. Each data node on the cluster manages the delegated operations for its hosted shards. Elasticsearch offers a RESTful JSON based service API over HTTP allowing you to manage data indices and cluster nodes.
Overview of the Solution
Architecture
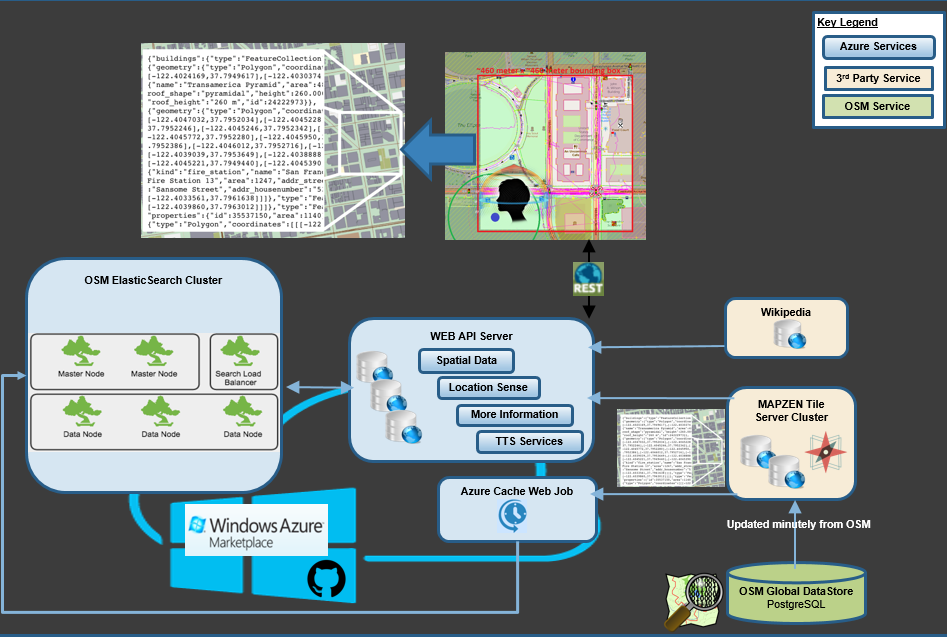
All our mapping data is sourced from OpenStreetmap which allowed us to tap into a growing community of mapping enthusiasts contributing location information on a daily basis. OSM is a free, open and editable map of the world, which is often referred to as the Wikipedia for Maps. Our backend navigation services query OSM data using Elasticsearch running on Azure. Azure offers a managed search service based on Lucene, but in this case study we’ll discuss deploying our own Elasticsearch cluster to gain access to geo-spatial features not available in the Azure platform offering.
Vector Tiles

Image Credit: Mapzen
We implemented a vector tile based solution that collects mapping data as square shaped GeoTiles into Elasticsearch. Each tile is a square area of land with a defined size and location, identified by a row, height and zoom level(X/Y/Z). The highest zoom level comprises of 4 tiles. Each zoom level divides the parent tile into four separate tiles. We used a zoom level of 16(so an average bounding box of ~460 meters x ~460 meters)
We crowdsourced nearby geotile data based on the users position and a 3 kilometer radius distance. We’re using Mapzens GeoJSON-based Vector Tile Service. Streets, buildings and parks are stored as GeoJSON LineString, while addresses and points of interest as a single GeoJSON point.
The summary description for nearby points of interest is sourced from Wikipedia. We have created an Azure WebJob that keeps EleasticSearch up-to-date with any recent changes made in OpenStreetMap.
Why Elasticsearch
- We preferred an architecture that can scale horizontally and adapt to the expected data growth rate, support a multitenancy architecture, data-schema agnostic, support search/filter/analyze operations off complex geo-shape indices under 50 milliseconds.
- The search engine needed to be distributed, fault-tolerant and load-balanced.
- Full-Text Search – With no visual interface available to validate the results of arbitrary user navigation request(s), finding an accurate full-text search engine was crucial. Lucene is a natural language search engine by design, supporting natural language relevancy ranking and fuzzy queries.
- Our search ranking requirement was one of the reasons why we decided to not integrate with a more traditional geo-spatial offering like Postgres /PostGIS.
- Combining geoshape search with full-text search is powerful.
Deploy Elasticsearch on Azure
Developers can now utilize preconfigured templates built by the Elasticsearch team to simplify the process of deploying a cluster to Azure.
Prerequisites
- Understand the fundamentals of working with Elasticsearch indexes and queries.
- An active azure subscription.
Elasticsearch Cluster Setup
You can checkout this Gist which will help you get started with setting up Elasticsearch on Azure.
Verify your Cluster Nodes are Online
Elasticsearch is packaged with Marvel: a visualization tool for monitoring your cluster status and health. At this point, your cluster should be showing a green status state in Marvel(http://my-kibana-url:5601/app/marvel).
Loading planetary files into Elasticsearch
This section covers loading an OpenStreetmap planet file into the Elasticsearch cluster you created. I wrote a utility to automate the file parsing and data import here. This utility works with binary planetary files(.pbf) as a data source. You can follow the detailed instructions in the readme to get started.
Geofabrik provides pbf files at the continent, country and state / regional level. These files are updated on a daily basis.
Mapzen recently released metro extracts, which generates a custom planet file at the city or locality level. Custom bounding boxes are also supported. planet files from metro can take up to 20 minutes to generate. Metro extracts are updated on a weekly basis.
You can start small with Rhode Island for your first import.
You can confirm that the OSM data was imported into your places index by accessing the document count API http://your-elastic-cluster:9200/places/place/_count
The utility uses a Go based pbf parser called pb2json.
let config = {
tags: featureTags.FEATURE_TAGS,
leveldb: './tmp',
batch: 5000,
file: process.env.PBF_DIRECTORY + '/' + filename
};
pbf2json.createReadStream(config).pipe(denormalizer.stream(elasticService.elasticConnection()));
I’m using the elasticsearch.js client to connect to my cluster.
function elasticClient(){
if(VerifyEnvironmentVarsExist(["ES_HOST", "ES_PORT", "ES_AUTH_USER", "PBF_DIRECTORY", "ES_AUTH_PWD"])){
return new elasticsearch.Client({
host: [
{
host: process.env.ES_HOST,
auth: process.env.ES_AUTH_USER + ":" + process.env.ES_AUTH_PWD
}
],
log: {
type: 'file',
level: 'info',
path: './logs/elasticsearch.log'
},
requestTimeout: 20000
});
}
}
The bulk API is useful for writing a list of documents across multiple indexes. Elasticsearch provides the detailed response status code for all requested documents in the batch, as well as the processing time.
let body = [];
body = body.concat(transformToElasticBulk(tilesToIndex, tilesIndexHeader));
body = body.concat(transformToElasticBulk(placesToIndex, placeIndexHeader));
console.log('Requesting ' + body.length + ' for elastic indexing.');
elasticClient().bulk({
body: body
},
(err, response) => {
if(err){
Realtime On-Demand OpenStreetmap Elasticsearch
We open sourced the vector maps elastic library that’s also used in Cities Unlocked. This library caches the resulting map data from Mapzens Vector Tile Service into Elasticsearch and exposes a service allowing you to interface with the location data. The idea is to use this library as a starting point to build custom location-based queries and filters that solves a spatial data problem. All the services are abstracted out, so extending them is a breeze. Appveyor can be used as a continuous integration solution to deploy your services to a cloud provider.
Getting Started
The library is well documented. You can follow these steps to help get yourself started. You can skip the Elasticsearch cluster and index setup step if you completed that from the previous section.
Validate Setup – Fetch Elasticsearch location information
Once the library is installed / configured locally you can test the setup by making a POST request to http://localhost:port/api/explore
The Service API
The main implementation service is LocationExploreElasticService. You can directly call the service as highlighted below
var requestFactory = new HttpRequestFactory();
var tileServerBaseUri = ConfigurationHelper.GetSetting("TileServer");
var tileKey = ConfigurationHelper.GetSetting("TileServerAPIKey");
var service = new LocationExploreElasticService(tileServerBaseUri, tileKey, TelemetryInstance.Current, requestFactory)
{
ResultLimit = request.Limit
};
var response = default(IEnumerable<Place>);
response = await service.SearchAsync(request.CurrentLocation, request.SearchRadius);
You can invoke this example directly by running the SpatialDataServiceHandlerTests_SuccessWhatsAroundMeCheck unit test in Tests.Microsoft.PCT.OSM / ElasticServiceTest.cs
To implement your own service just extend off BaseElasticService, and implement your own QueryPlacesAsync method.
protected override async Task<IEnumerable<Place>> QueryPlacesAsync(IGeoCoordinate userLocation, double searchRadiusMeters)
{
if (searchRadiusMeters == 0)
{
throw new ArgumentNullException(nameof(searchRadiusMeters));
}
if (!ResultLimit.HasValue)
{
ResultLimit = SPATIAL_DATA_DEFAULT_RESPONSE_LIMIT;
}
var places = await InvokeElasticSearchQueryAsync(userLocation, searchRadiusMeters, null);
return places.Take(ResultLimit.Value);
}
BaseElasticService’s InvokeElasticSearchQueryAsync method will use the provided location and radius to verify that all nearby tile data is cached before POI data is queried from elastic.
Each geo tile fetch results in a single request to Mapzens Tile Server, which are made in parallel as Rx Observable subscriptions(Thanks Eric Rozell).
var headers = ParseRelevantHeaders(requestHeaders);
var tileRequests = serviceProviders.Select(provider => SendPostRequestAsync(provider, request, token, headers));
//Continous check if the response queue has been fully processed until the time to live has been triggered
return await tileRequests
.ToObservable(token)
.Where(tileResponse => !tileResponse.HasValue || tileResponse.Value != null)
.Select(Validate)
.Do(tileResponse => Log(tileResponse, deserializedRequest, headers))
.ToList();
Performance
This table provides some details about the cluster I used for my benchmark testing.
| Nodes | Shards | Node Size | Geo Shape Documents | |
|---|---|---|---|---|
| Cluster | 5(2 Data, 2 Master, 1 Client) | 29 per data node | Standard DS1 v2 | > 15 Million |
Indexing Performance
I ran a test to clock the bulk indexing API for 500,000 documents.
| Avg Per Document | Avg Per Batch | Avg Batch Size | Slowest Batch | Fastest Batch | |
|---|---|---|---|---|---|
| Bulk Indexing | 1.5 ms | 300 ms | ~320 Documents | 4,174 ms | 100 ms |
Geo-Distance Search Performance
The second test measures the response time of 1000 geo distance search queries fanned out in parallel. Search areas were New York City, London and Paris.
| Mean | Median | Max | Min | |
|---|---|---|---|---|
| Geo Search | 25 ms | 26 ms | 51 ms | 2 ms |
Summary / Challenges
I was pleasantly surprised of how well Elasticsearch scaled with our data volume. Utilizing an open spatial data solution like OpenStreetMap was critical to our success, as we needed full read/write access to sidewalk objects(hydrants, mailboxes, trash cans, etc) to maintain an acceptable level of data quality. The current population of sidewalks and crossings in OSM are sparse. This presented a challenge as the open source Valhalla routing engine factors roads and intersections in the absence of pedestrian data in OSM. We’re currently undergoing an exploratory effort that uses machine learning models paired with aerial and streetview imagery to infer sidewalk and crossing mapping features, with the goal of contributing that dataset back to OpenStreetMap to improve the data quality of Valhalla pedestrian routes.
Contributing
We welcome pull requests in all shapes and sizes for the repos mentioned above. If you happen to have experience with using ML with streetview imagery then drop me a note via twitter @erikschlegel1.