
Earlier, we announced the commit-graph feature in Git 2.18 and talked about some of its performance benefits. Today, we’ll discuss some if the technical details about how the commit-graph feature works, including some helpful properties of its file format. This file speeds up commit-graph walks so much that we were able to identify other ways to speed up these walks using small optimizations. If you prefer a video, I talked about the commit-graph format in the second half of a talk at Git Merge 2018.
What makes a commit?
In Git, a commit consists of a few pieces of information:
- The hash of the root tree. This stores the state of the working directory at that point in time.
-
A list of hashes of the commit parents. These are the commits from which this commit is based. There may be any number of parents.
- No parents mean the commit is a “root” or “initial” commit.
- The commits created by a single developer doing work typically have exactly one commit.
- Two or more parents means the commit is a “merge” commit, combining the history of previously independent commits; commits with three or more commits are “octopus” merges.
-
Parent order matters! For instance, you can use
git log --first-parentto only traverse the relationships between a commit and its first parent.
- Name and email information for the author and committer, including the time that the commit was authored and committed. See this StackOverflow answer on the difference between “author” and “committer”. It is important to our discussion that these times are stored as seconds since Unix epoch.
- A commit message.
If we think of the commits as vertices and the commit-to-parent relationship as an edge, then the set of commits creates a
directed acyclic graph. This graph stores interesting structure about your commit history. For example, the figure below shows the commit graph for a small Git repository. 
R is a root commit. Commits A and B represent two “tip” commits (no commits have A or B as parents). Commit A has a single parent while commit B is a merge between two commits. There are a lot of questions we want to ask about this commit graph that help with developer workflows in Git, such as: * What commit is the best merge base between A and B? * Which commits are ancestors of A but not ancestors of B? We use this to determine which commits are introduced by a pull request. To make things easier, we say a commit X is
reachable from a commit Y if there is a sequence of commit-to-parent edges that we can follow to “walk” from Y to X. Consider the following: 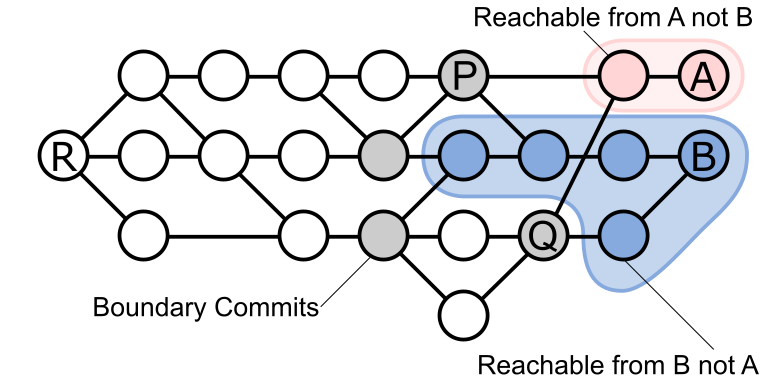
A and BA but not reachable from B. In blue we highlight the commits reachable from B but not A. The gray commits P and Q are the commits that are reachable from both A and B but not from any other commit that is also reachable from A and B. These commits P and Q are options for merge-bases between A and B. The other gray nodes are not acceptable merge bases, because they are reachable from P or Q. Git answers these commit graph questions by using various graph walking algorithms, such as breadth first search (BFS), depth first search (DFS), or “best first” search using commit date as a heuristic. While walking these commits, Git loads the following information about a commit:
- The parent list
- The commit date
The parent list is required so we know which commits to visit next in our walk. The commit date is required due to the heuristic that helps select which commit to visit next. The rest of the information in a commit is only required if we need to display that information to a user (such as in
git log) or when we want to filter on that information (such as in git log --author=X). Before Git 2.18, Git had to go looking for where the commit was stored, decompress the commit file, and parse the commit in plain-text. This can be expensive, especially when doing it thousands of times.
Basic Structure of a Commit-Graph File
In Git 2.18, we can now store the commit graph information in a compact way in the .git/objects/info/commit-graph file. The file is structured to make parsing as efficient as possible. It also has extension points so we can create more advanced features in the future using this file. The commit-graph file has four main sections, called “chunks”.
- Commit IDs: A sorted list of every commit ID. The position of a commit ID in this list is called the graph position of the commit.
-
Fanout: A fanout table of 256 entries. The fanout value
F[i]stores the number of commits whose first byte (or first two hex digits) of their ID is at mosti. Thus,F[0xff]stores the total number of commits. This allows us to seed the initial values of the binary search into the commit IDs. - Commit Data: A table containing the important data for each commit, including its root tree ID, the commit date, and the graph position of up to two parents. If a commit has fewer than two parents, we use a special constant to mark the column to be ignored.
- Octopus Edges: In the case of an octopus merge, we need more than two parent values. In these cases, we keep a separate list of graph positions and the second parent value of an octopus merge stores a position in this list of octopus edges. We use a null-termination trick to let the list of parents be arbitrarily large, such as when someone commits a Cthulhu merge with 66 parents.
Thus, the file looks something like this: 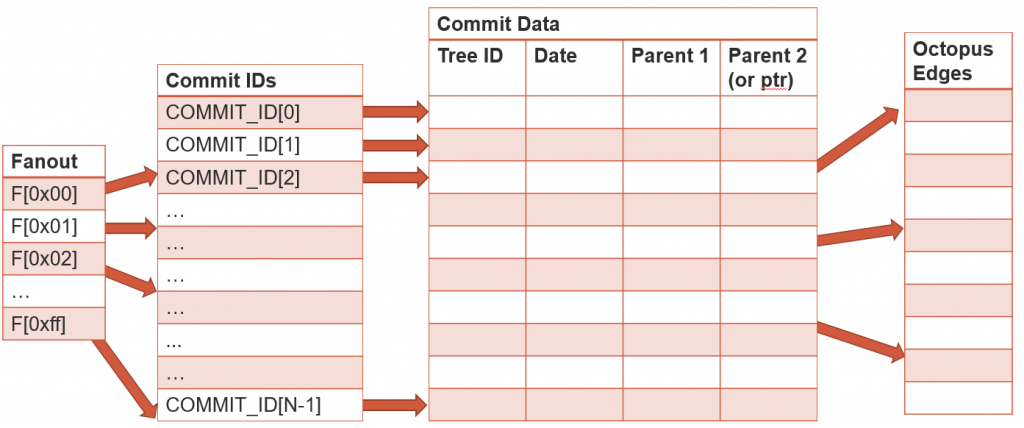
Small Optimizations
At Microsoft, we care deeply about Git’s performance. After we saw performance benefits in the commit-graph file, we took another look at Git’s performance. We inspected the stack traces for commands like git status using PerfView. Here are a few of those stack traces with some hot spots identified: 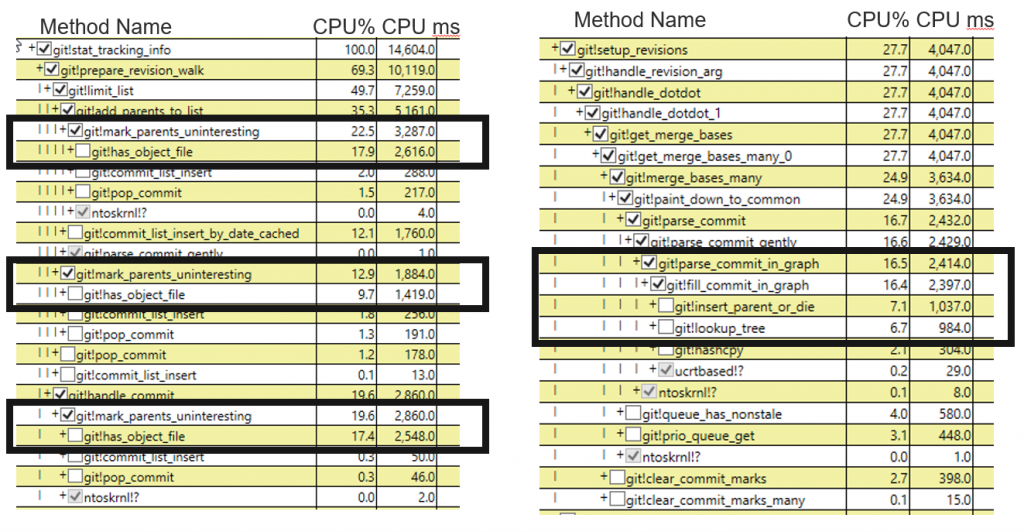
git status callmark_parents_uninteresting() is spending a lot of time calling has_object_file(). We knew that the commit-graph should allow Git to avoid checking the object database to see these commits, so this must be wasted effort. After digging in, we found that this call can be avoided. Since this call seemed to exist for a historical reason, we first made the safe change that conditionally skipped the call. Later, Jeff King removed the call entirely. This was an excellent example of collaboration in the community! Together, this change can save up to 7% of end-to-end time on a git status call in the Linux repository without the commit-graph feature. The relative benefit is even higher when the commit-graph feature is enabled (over 50% in the stack traces above). In the right side of the stack traces, we see that our commit parsing is taking 6.7% in the lookup_tree() method. We knew that git status was computing merge bases at the time, so why did it need to load trees? Recall above that the root tree object ID is an important element in a commit. Since Git frequently needs to walk from a commit to its root tree, the parse_commit() method is expected to load an object pointer for that tree. The tree object is just a placeholder, but Git also has an object cache to avoid duplicate copies of the same object. That’s what lookup_tree() is doing: it is checking the in-memory cache for a copy of that tree, even though we never need to look at the tree for our current code path. To improve commit-graph walks that do not need to also walk trees, we made Git load trees lazily. This gave us an additional 28% speedup in git log --graph calls in the Linux repository.
Parsing is not Enough
While the commit-graph file speeds up commit graph walks by improving parsing speed, it still has a problem: if git log --graph took 15 seconds to show a single commit before, it takes at least 1.5 seconds with Git 2.18. This is the case we are in with the Windows repository, as it has over 2 million reachable commits. The algorithm for git log --graph requires reporting the commits in topological order and the algorithm walks every reachable commit before displaying a single commit to the user. Visual Studio Team Services (VSTS) displays commit history in topological order by default, and can return history queries on the Windows repository in under 250 milliseconds. 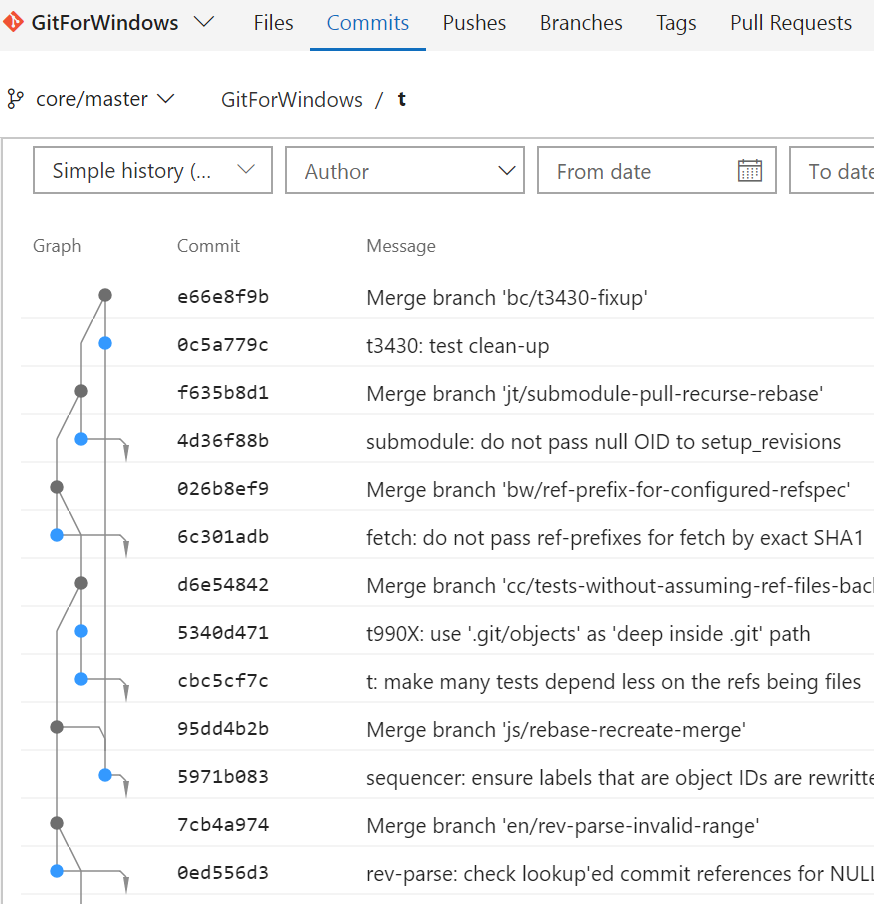
This is such an amazing article. Thanks for publishing this article.
Amazing Contant
Unfortunately, your markup isn’t working correctly now. Probably broke in a blog engine “upgrade”?