
Attaching and Detaching an Edge Node From a HDInsight Spark Cluster when running Dataiku Data Science Studio (DSS)
Background
Microsoft Global Partner Dataiku is the enterprise behind the Data Science Studio (DSS), a collaborative data science platform that enables companies to build and deliver their analytical solutions more efficiently.
Microsoft has been working closely with Dataiku for many years to bring their solutions and integrations to the Microsoft platform. In particular, Microsoft has assisted with bringing Dataiku’s Data Science Studio application to Azure HDInsight as an easy-to-install application, as well as other data source and visualisation connectors such as Power BI and Azure Data Lake Store.
Azure HDInsight is the industry-leading fully-managed cloud Apache Hadoop & Spark offering on Azure which allows customers to do reliable open source analytics with an SLA. The combined offering of DSS as an HDInsight (HDI) application enables Dataiku and Azure customers to easily use data science to build big data solutions and run them at enterprise grade and scale.
Earlier this year, Dataiku and Microsoft joined forces to add extra flexibility to DSS on HDInsight, and also to allow Dataiku customers to attach a persistent edge node on an HDInsight cluster – something which was previously not a feature supported by the most recent edition of Azure HDInsight.
Below are two diagrams (Figure 1 and 2) showing Dataiku’s application in action for a Predictive Maintenance scenario – both the project creation with team collaboration and also the machine learning workflow and triggers involved to complete the project:
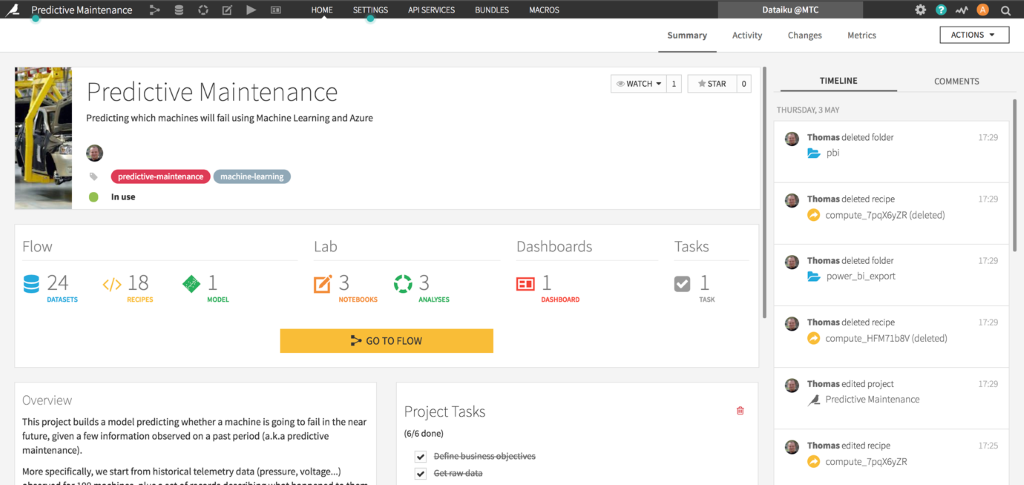
[Figure 1: A screenshot of the Dataiku Data Science Studio application for a predictive maintenance scenario]
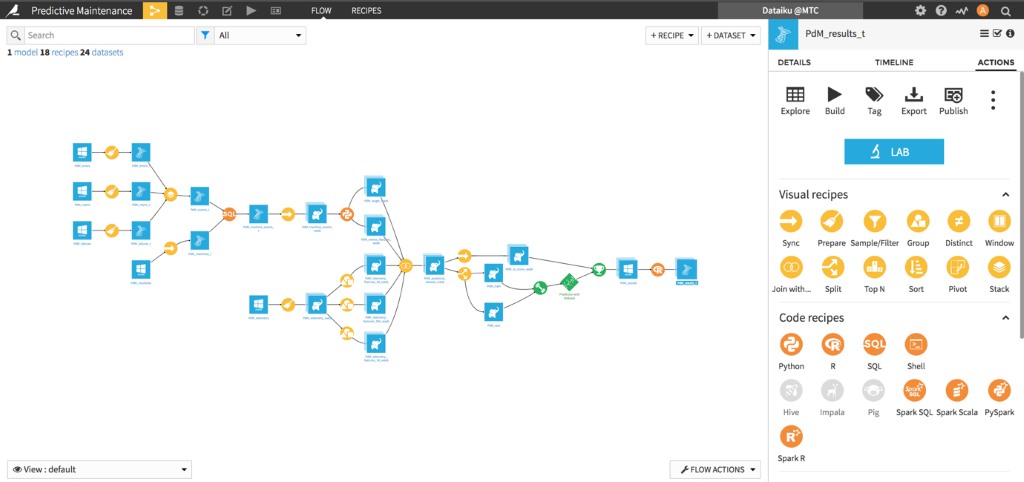
[Figure 2: A screenshot of the machine learning workflow and design surface in Dataiku’s Data Science Studio application]
Challenges and Solution
During this project, our joint team aimed to add extra flexibility to DSS on HDInsight and allow Dataiku customers to have a persistent edge node on an HDInsight cluster so their projects can leverage huge amounts of compute only when they need them, but they are not tied to having the cluster always running.
Attaching an edge node (virtual machine) to a currently running HDInsight cluster is not a feature supported by Azure HDInsight (July 2018). Standard deployment options include:
- Provisioning an application (in this case Dataiku Data Science Studio) as part of the cluster (a managed edge node) – see Figure 3 below, an architecture diagram for Option A
- Provisioning Dataiku DSS directly on the HDInsight head node – see Figure 3 below, an architecture diagram for Option B
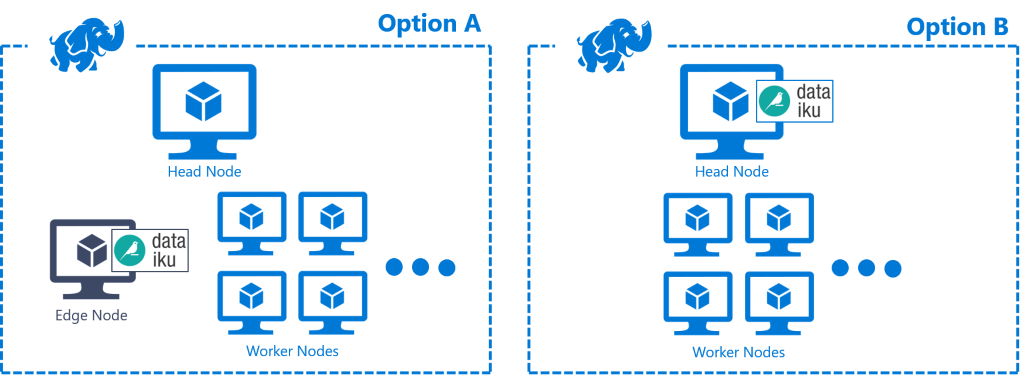
[Figure 3: Two architecture diagrams showing the current deployment options you have with Azure HDInsight and where a partner application can be hosted and communicate with the HDInsight cluster]
Note:
- Option A can be setup automatically via the Azure HDInsight Applications tab in the Azure Portal. For more information see the blog post here
- Option B is a manual setup once you have created an HDInsight Cluster in Azure.
You would need first to connect to the HDInsight Cluster using SSH and then perform a manual DSS installation on the head node.
In both cases there is a drawback, as the DSS application instance will always be deleted when the HDI cluster is deleted. With Azure HDInsight the edge node is always part of the lifecycle of the cluster, as it lives within the same Azure resource boundary as the head and all worker nodes. Therefore, the action to delete the large amounts of compute (to save money when it is not being used) will result in the edge node being deleted as well.
There are times when Dataiku customers may wish to have DSS run as a standalone machine during testing and then attach it to a large amount of compute (cluster) when they wish to submit large queries; and then also detach the edge node — but keep the results — once finished.
Another challenge to be tackled during this project was the ability to attach an edge node to different clusters being run within an organisation, easily – such as development cluster and production cluster etc.
Attach and detach from the cluster
Figure 4 below is an architecture diagram showing a desired scenario whereby the partner application is hosted on a separate virtual machine outside the blue HDInsight cluster network and therefore the VM can outlive the HDInsight cluster if it was to be deleted to save compute costs.
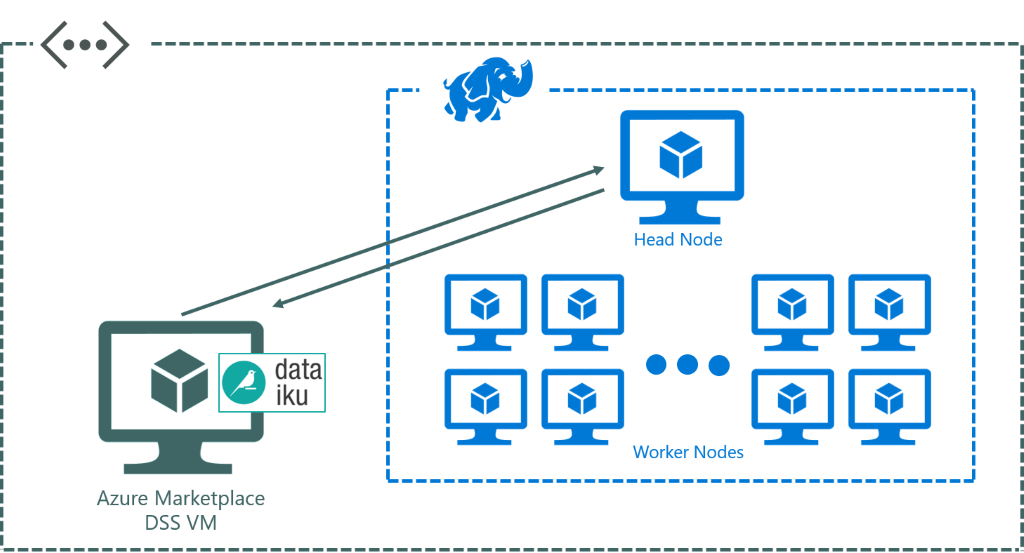
[Figure 4: An architecture diagram showing a possible desired setup for the DSS application to communicate with the HDInsight Cluster without being directly within the HDInsight setup]
Connect to another cluster
Figure 6 below is an example architecture diagram for having a single instance of the DSS application on a virtual machine able to connect to many different HDInsight clusters running within the same VNET. For example, one can have a developer and production cluster within a single organisation’s subscription and the user of DSS can choose when to connect/disconnect from each.
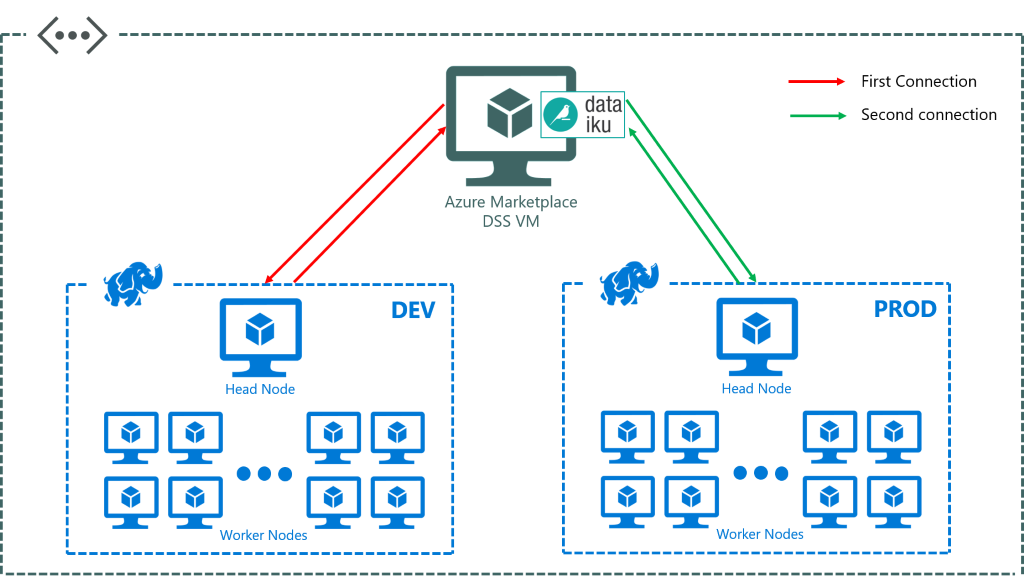
[Figure 6: An architecture diagram to show the desired outcome of the DSS application running on a virtual machine able to choose to connect and disconnect from different HDInsight clusters within the same virtual network depending on the job being run]
The Solution
Our team created a VM and added HDI edge node configuration (packages and libraries) that would allow Dataiku to submit spark jobs to an HDInsight Cluster. Because the VM lives outside of the cluster boundary, it can survive the deletion of the HDInsight cluster and retain the information and results it has.
Figure 7 illustrates the configuration changes we designed to allow the VM to talk to the head node of the HDInsight cluster and submit jobs as if it was part of the cluster:
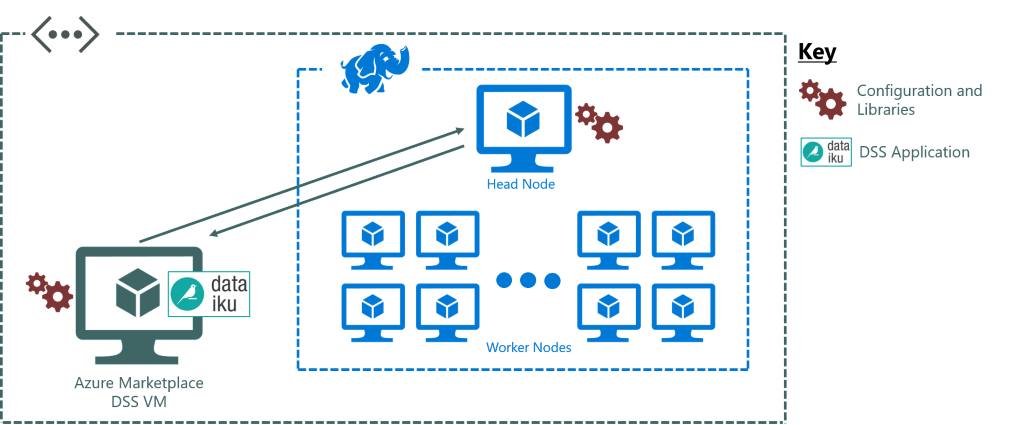
[Figure 7: An architecture diagram to show the DSS application on a VM outside of the HDInsight cluster that can communicate with the head node of the HDInsight cluster because the configuration libraries are matching in both head node and VM to communicate]
The Process
First, our team needed to attach a virtual machine with DSS installed to a running HDInsight cluster and check that queries could be submitted as if we were on a managed edge node within the cluster.
We initially worked through the setup manually, however we also created a helper script to allow others to quickly replicate the setup, which has proven to be very useful for Dataiku customers. The setup can be run manually via documentation here or from a shell script.
Preparing the DSS environment
To copy and submit commands from a different destination (to the head-node) the idea was to make the VM have exactly the same setup as the edge node within the HDInsight Cluster.
To do this we first copied the HDP (Hortonworks Data Platform) repo file from the cluster head-node to the Dataiku DSS VM. We found these files in /etc/apt/sources.list.d/HDP.list on the cluster head-node and copied them to etc/apt/sources.list.d/HDP.list within the DSS VM inside the same virtual network for communication purposes.
As many of the commands we were using needed administrator privileges we checked we had sufficient sudo permissions on the DSS VM by using sudo -v and entered the admin password. We also created root ssh keys which are used to authenticate and communicate between the VM and the edge node within the cluster.
We then installed the APT keys for Hortonworks and Microsoft, as well as installing Java and Hadoop client packages on the VM and removing the initial set of Hadoop configuration directories, to avoid any conflicts (commands shown below).
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 07513CAD 417A0893
rm -rf /etc/{hadoop,hive*,pig,spark*,tez*,zookeeper}/conf
The final elements of setup lead to creating a directory that was used by the HDInsight Spark configuration and defining the environment variables for spark and python on the DSS machine to match the head-node (/etc/environment, or for this setup DSS_HOMEDIR/.profile).
mkdir -p /var/log/sparkapp && chmod 777 /var/log/sparkapp AZURE_SPARK=1 SPARK_MAJOR_VERSION=2 PYSPARK_DRIVER_PYTHON=/usr/bin/python
Cluster association
Now that the DSS VM was correctly setup with permissions, libraries and keys (becoming a mirror of the HDInsight head-node) we needed to connect the two machines to be able to copy files to each other
We installed the DSS VM ssh key onto the HDInsight head-node so this can be used for copying of files and connections. But also, we needed to change the network /etc/hosts definition file to be the same. To do this, we copied the /etc/hosts definition for “headnodehost” from the head node to the DSS VM and then flushed the ssh key cache afterwards.
Finally, to complete the synchronisation of the DSS VM and the HDInsight head-node we synchronised the Hadoop base services packages, as follows:
declare -a hadoopBaseServices=( "hadoop" "hive" "pig" "spark" "tez" "zookeeper" )
We also used the rsync command to remove the current packages from the DSS VM and synchronise the packages from the HDInsight head-node
for service in ${hadoopBaseServices[@]}
do
reg="/etc/$service.*/conf"
echo "Removing configuration for service $service maching $reg"
sudo find /etc -regex $reg | xargs sudo rm -rf
echo "Synchronizing configuration for service $service"
sudo rsync -av -e "ssh -o StrictHostKeyChecking=no -i $PRIVATEKEYPATH" $headnode_user@$headnode_ip:/etc/${service}\* /etc/
Done
Before testing we realized that it was necessary to (re-)run Hadoop and Spark integration on DSS before restarting the DSS VM. You need to re-run Hadoop and/or Spark integration when you modify the local-to-the-VM Hadoop and Spark configuration, typically when you install/synchronize new Hadoop jars as we did earlier on in the project. For more information on this topic see the documentation here: https://doc.dataiku.com/dss/latest/hadoop/installation.html#setting-up-dss-hadoop-integration
Prove Connectivity
As the setup and synchronisation were completed, we tested the connection had worked so we could submit spark commands on the DSS VM and they would be submitted to the HDInsight cluster.
An example command we used to check that connectivity works is hdfs dfs -ls / or spark2-shell command.
Figure 8 and 9 below are screenshots showing our results once those commands were run for HDFS and Spark-submit respectively:
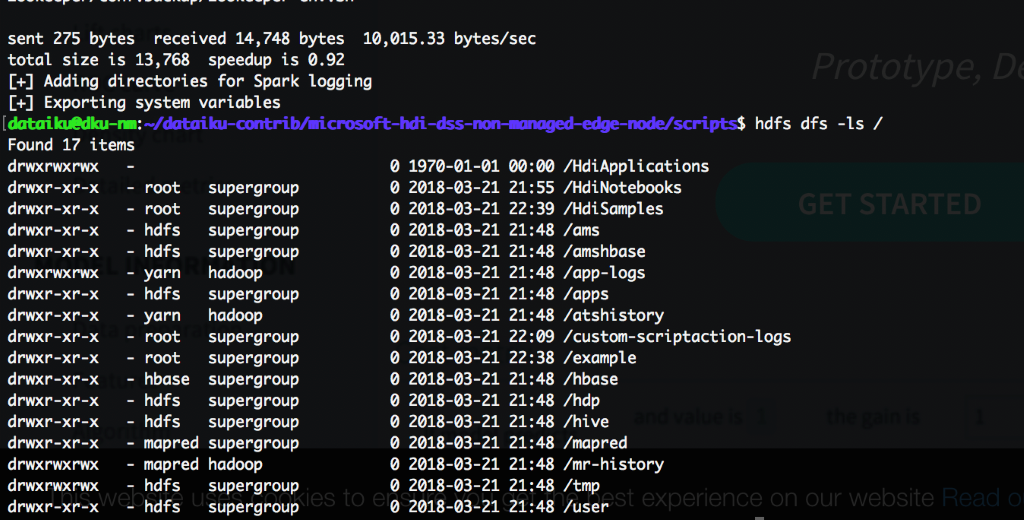
[Figure 8: A screenshot of the command line interface on the DSS VM showing the connection to the head-node of the cluster was successful by running the HDFS command]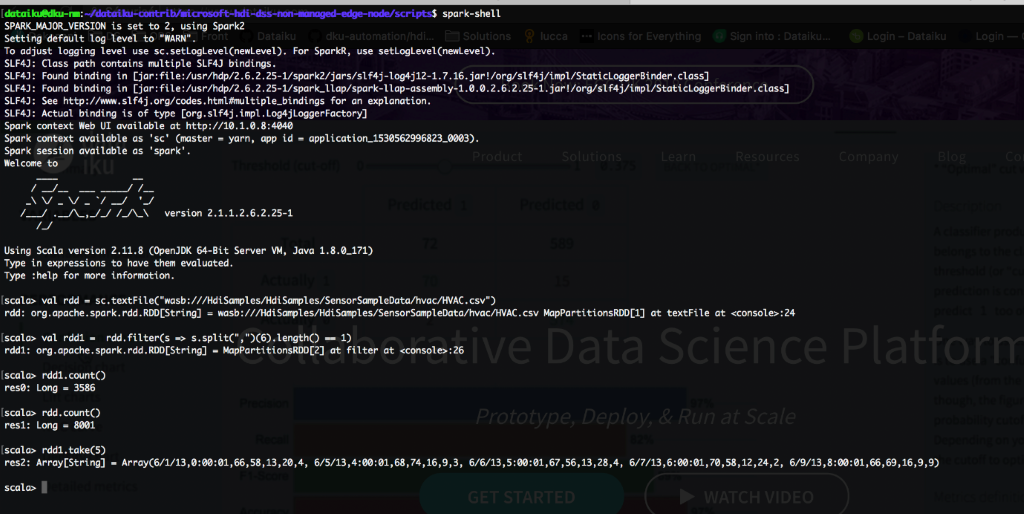
[Figure 9: A screenshot of the command line interface on the DSS VM showing the connection to the head-node of the cluster was successful by running the spark commands and creating arrays and evaluating them]
Shell Script for Automation
After we followed the manual process above – which has a lot of commands that need to be run in the command line interface and often leads to mistakes or missing commands – it felt natural to create a script for Dataiku’s customers to quickly and easily implement this scenario within the DSS setup. We have made a helper script available here. To run the helper script, submit the command below with the required parameters:
source hdi-edge-node-from-existing-vm.sh -headnode_ip <HEADNODE_IP> -headnode_user <HEADNODE_USER>
The script itself tests automatically that all required conditions are fulfilled.
Conclusion
In this blog post we demonstrated how to attach and detach edge nodes/virtual machines from a HDInsight cluster. We went through the process of:
- Preparing the DSS VM environment and installing the basic packages
- Copying HDI configuration and libraries from HDI head node to the DSS VM
- Testing that job submission was running
- Creating a helper script for automation
We also created and shared a helper script that allows users to take advantage of a stand-alone edge node running Dataiku DSS, which can communicate with a HDInsight cluster to submit Spark jobs but also persists outside of the lifecycle of the HDInsight cluster as a VM on its own. This will benefit Dataiku customers going forward as it allows them to run the Dataiku DSS application and have the flexibility to attach to and disconnect from large compute (clusters). This saves money on compute while being able to keep/persist the result of the big data queries within the DSS environment. This solution could also be leveraged by other companies building big data solutions for their customer in the big data space, allowing them the flexibility to repeat this scenario.
Dataiku and Microsoft have a close relationship from the past, and one which we built upon through this project. It is our hope that the work presented here will lead to further collaboration in the future on additional technical projects using the Azure Platform.
Other Useful Resources
This solution is designed specifically for Dataiku’s Data Science Studio application, however a similar process could be relevant to anyone using HDInsight for their Big Data scenarios. If you wish to follow step-by-step the process to replicate, please find repository links here to a step-by-step guide we created and a helper script that can be used and adapted.
** Please note: there are some limitations and restraints to this solution. Please review these here before proceeding. Disclamer: This contribution is not subject to official support from Dataiku nor Microsoft and does not guarantee compatibility with future versions of HDI **
To learn more about the solution described above, Azure HDInsight and Dataiku Data Science Studio please find the links below:
- Dataiku Technical Documentation for workaround
- Azure HDInsight
- Dataiku Data Science Studio (DSS)
- Dataiku DSS in the Azure Marketplace
- Dataiku DSS as a HDInsight Application
 Light
Light Dark
Dark