
Rise of the Tomb Raider is the first title to implement explicit MultiGPU (mGPU) on CrossFire/SLI systems using the DX12 API. It works on both Win32 and UWP. Using the low level DX12 API, Rise of the Tomb Raider was able to achieve extremely good CPU efficiency and in doing so, extract more GPU power in a mGPU system than was possible before.
This app, developed by Crystal Dynamics and Nixxes, even shows how explicit DX12 mGPU can win over DX11 implicit mGPU. In some configurations, you can even see up to 40% better mGPU scaling over DX11.
Read below for details on what mGPU scaling is, where these gains are coming from and what this all means for the future of high performance gaming.
Update: The UWP version is now live! Here’s the link.
![]()
![]()
Recap: What is Explicit MultiGPU and how does it make things better?
Explicit mGPU refers to the explicit control over graphics hardware (only possible in DX12) by the game itself as opposed to an implicit (DX11) implementation which by nature is mostly invisible to the app.
Explicit mGPU comes in two flavors: homogeneous, and heterogeneous.
Homogeneous mGPU refers to a hardware configuration in which you have multiple GPUs that are identical (and linked). Currently, this is what most people think of when ‘MultiGPU’ is mentioned. Right now, this is effectively direct DX12 control over Crossfire/SLI systems. This type of mGPU is also the main focus of this post.
Heterogeneous mGPU differs in that the GPUs in the system are different in some way; whether it be vendor, capabilities, etc. This is a more novel but exciting concept that game developers are still learning about. This opens up doors to many more opportunities to using all of the silicon in your system. For more information on heterogenous mGPU, you can read our blog posts here and here.
In both cases, MultiGPU in DX12 exposes the ability for a game developer to use 100% of the GPU silicon in the system as opposed to a more closed-box and bug prone implicit implementation.
Explicit control over work submission, memory management, and synchronization gives game developers the power to provide you the fastest, highest quality gaming experience possible; something only achievable with a well thought out game implementation, an efficient API, and a large amount of GPU power.
With Rise of the Tomb Raider, Nixxes leads the way on showing how to effectively transform CPU usage savings into maximum GPU performance using DX12 on mGPU systems.
Now onto the details!
Maximum performance, maximum efficiency

The developers of Rise of the Tomb Raider on PC have implemented DX12 explicit homogeneous mGPU. They also have a DX11 implicit mGPU implementation. That makes it a great platform to demonstrate how they used DX12 mGPU to maximize CPU efficiency and therefore mGPU performance.
Before we get to the actual data, it’s important to define what ‘scaling percentage’ (or ‘scaling factor’) is. If a system has two GPUs in it, our maximum theoretical ‘scaling percentage’ is 100%. In plain words, that means we should get a theoretical increase of 100% performance per extra GPU. Adding 3 extra GPUs for a total of 4 means the theoretical scaling percentage will be 3 * 100% = 300% increase in performance.
Now of course, things are never perfect, and there’s extra overhead required. In practice, anything over 50% is fairly good scaling. To calculate the scaling percentage for a 2 GPU system from FPS, we can use this equation:
ScalingPercentage = (MultiGpuFps / SingleGpuFps) – 1
Plugging in hypothetical numbers of 30fps for single GPU and 50fps for a 2 GPU setup, we get:
ScalingPercentage = (50 / 30) – 1 = ~0.66 = 66%
Given that our actual FPS increase was 20 over a 30fps single GPU framerate, we can confirm that 66% scaling factor is correct.
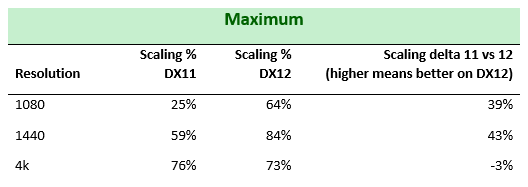
Here’s the actual data for 3 resolutions across one high end board from both AMD and NVIDIA. These charts show both the minimum and maximum scaling benefit an AMD or NVIDIA user with DX12 can expect over DX11, at each resolution.
Minimum scaling wins of DX12 mGPU over DX11 mGPU:

Maximum scaling wins of DX12 mGPU over DX11 mGPU:

The data shows that DX11 scaling does exist but at both 1080 and 1440, DX12 achieves better scaling than DX11. Not only does DX12 have an extremely good maximum scaling factor win over DX11, it also shows that the minimum scaling factor is also above the DX11 minimum scaling factor. Explicit DX12 mGPU in this game is just uncompromisingly better at those resolutions.
At 4k, you can see that we are essentially close to parity, within error tolerance. What’s not immediately clear is that DX12 retains potential wins over DX11 here. There are even more hidden wins not expressed by the data and it has to do with more unrealized CPU potential that game developers can take advantage of. The next section in this post will describe both how game developers can extract even more performance from these unrealized gains and why 4k does not show the same scaling benefits as lower resolutions in this title.
The take away message from the data is that the CPU efficiency of DX12 explicit mGPU allows for significantly better GPU scaling using multiple cards than DX11. The fact that Rise of the Tomb Raider achieves such impressive gains despite being the first title to implement this feature shows great promise for the use of explicit mGPU in DX12.
Using this technology, everyone wins: AMD customers, NVIDIA customers, and most importantly, gamers who play DX12 explicit mGPU enabled games trying to get the absolute best gaming experiences out there.
Where do the performance gains actually come from? Think about CPU bound and GPU bound behavior.
All systems are made up of finite resources; CPU, GPU, Memory, etc. mGPU systems are no exception. It’s just that those systems tend to have a lot of GPU power (despite it being split up over multiple GPUs). The API is there to make it as easy as possible for a developer to make the best use of these finite resources. When looking at performance, it is important to narrow down your bottleneck to one of (typically) three things, CPU, GPU, and Memory. We’ll leave memory bottlenecks for another discussion.
Let’s talk about CPU and GPU bottlenecks. Lists of GPU commands are constructed and submitted by the CPU. If I’m a CPU, and I’m trying to create and push commands to the GPU but the GPU is chewing through those too fast and sitting idle the rest of the time, we consider this state to be CPU bound. Increasing the speed of your GPU will not increase your framerate because the CPU simply cannot feed the GPU fast enough.
The same goes the other way around. If the GPU can’t consume commands fast enough, the CPU has to wait until the GPU is ready to accept more commands. This is a GPU bound scenario where the CPU sits idle instead.
Developers always need to be aware of what they are bound on and target that to improve performance overall. What’s also important to remember is that removing one bottleneck, whether it’s CPU or GPU, will allow you to render faster, but eventually you’ll start being bottlenecked on the other resource.
In practical terms, if a developer is CPU bound, they should attempt to reduce CPU usage until they become GPU bound. At that point, they should try to reduce GPU usage until they become CPU bound again and repeat; all without reducing the quality or quantity of what’s being rendered. Such is the iterative cycle of performance optimization.
Now how does this apply to mGPU?
In mGPU systems, given that you have significantly increased GPU potential, it is of the utmost importance that the game, API, and driver all be extremely CPU efficient or the game will become CPU bound causing all your GPUs to sit idle; clearly an undesirable state and a huge waste of silicon. Typically, game developers will want to maximize the use of the GPU and spend a lot of time trying to prevent the app from getting into a CPU bound state. At the rate that GPUs are becoming more powerful, CPU efficiency is becoming increasingly important.
We can see the effects of this in the 1080 and 1440 data. We are CPU bound on 11 much quicker than DX12 which is why DX12 gets all around better scaling factors.
As for 4k, it looks as though DX11 and DX12 have the same scaling factors. The 1080 and 1440 resolutions clearly indicate that there are CPU wins that can be transformed into GPU wins, so where did those go at 4k? Well, consider that higher resolutions consume more GPU power; this makes sense considering 4k has 4 times as many pixels that need to be rendered as compared to 1080. Given that more GPU power is required at 4k, it stands to reason that in this configuration, we have become GPU bound instead of CPU bound.
We are GPU bound and so any extra CPU wins from DX12 are ‘invisible’ in this data set. This is where those hidden gains are. All that means is that game developers have more CPU power that’s free for consumption by the DX12 mGPU implementation at 4k!
That is unrealized DX12 potential that game developers can still go and use to create better AI, etc without affecting framerate unlike in DX11. Even if a game developer were to not do any more optimization on their GPU bound mGPU enabled game, as GPU technology becomes even faster, that same game will tend to become CPU bound again at which point DX12 will again start winning even more over DX11.
DirectX 12 helps developers take all of the above into account to always get the most out of your hardware and we will continue helping them use the API to its maximum effect.
What about UWP?
It works just the same as in Win32. We’re glad to tell you there really isn’t much else to say other than that. Nixxes let us know that their DX12 explicit mGPU implementation is the same on Win32 as it is on UWP. There are no differences in the DX12 mGPU code between the two programming models.
Update: Nixxes has published the UWP patch. Here’s the link.
Innovate even more!
DX12 mGPU isn’t just a way to make your games go faster. That is something that gamers know and can hold up as the way to get the best gaming experiences out there using current day technology; but this is really only just the beginning. Consider VR for example; a developer could effectively double the visual fidelity of VR scenarios by adding a second GPU and having one card explicitly draw one eye’s content and the second card draw the second eye’s content with no added latency. By allowing the developer to execute any workload on any piece of GPU hardware, DX12 is enabling a whole new world of scenarios on top of improving the existing ones.
Continued support and innovation using DirectX 12 even after shipping
DX12 is still very new and despite it being the fastest API adoption since DX9, there are still a lot of unexplored possibilities; unrealized potential just waiting to be capitalized on even with existing hardware.
Studios like Crystal Dynamics and Nixxes are leading the way trying to find ways to extract more potential out of these systems in their games even after having shipped them. We are seeing other studios doing similar things and studios who invest in these new low level DX12 API technologies will have a leg up in performance even as the ecosystem continues to mature.
We of course encourage all studios to do the same as there’s a huge number of areas worth exploring, all other forms of mGPU included. There’s a long road of great possibilities ahead for everyone in the industry and we’re excited to continue helping them turn it all into reality.
{kind=link}
0 comments