

What happens when you fall off a cliff…
It’s 2am. Your lead developer’s phone buzzes…again. She groggily gets out of bed and fires up her laptop. It appears your web platform has become unresponsive. Requests to the backend database are all timing out. Customers across the globe are angry.
It appears that the database is over-consuming memory. A workload that, just yesterday, operated smoothly is now consuming too many resources, limiting the database bandwidth, and timing out. Your lead developer opens up a tool that allows her to see regressed queries. Two of them have experienced changes in the way they execute in the past 4 hours, and those two queries are now consuming massively more memory than they once were. This memory consumption is bogging down the system – not only are the queries much slower, but they are also consuming far more memory and CPU than they had been. This means that the other queries can’t get through. The system is at a complete standstill, even though the database is working overtime. Fortunately, she is able to request that the future executions of these two queries go back to the strategy of 6 hours ago, at least until she and the team can do more investigation tomorrow. She trudges back to bed, hoping to get a few more hours of shuteye before her morning commute.
The scenario above describes what I call “Falling off a cliff”. Your database is doing fine. Great even. Then something changes, and performance, response time, everything, changes in a blink of an eye. All the time, databases are changing – data is being inserted, loaded, archived, updated…etc. Most often, the number of rows in an active database is steadily increasing. Sometimes, the number of rows passes a threshold – and the way the queries are executed changes. In the general case, this is good. You want your database to adapt to changing data loads and query loads. Unfortunately for the developer in the story above, the change was not smooth, and did not yield better overall workload performance, in fact, things got very bad very quickly.
In this blog, I will attempt to explain, at a high level, why Query Processing (QP) matters, how it works, what can go wrong when QP makes a mistake, and what exciting features are present in the Azure SQL and SQL Server QP that will improve end-user experience, and ultimately, allow you to use resources smarter. Your developers will be able to get work done faster and with fewer middle of the night emergencies.
Why Good QP Matters
Typically, QP is silent and unseen. Not thinking about QP means things are going well. It’s only when you see a sudden degradation in performance, or when queries stop completing, that you must think about QP. While every database requires some planning and setup, once that is complete you want business to move forward without investing substantial time fixing issues or making tweaks. To this goal, having a good quality QP is essential.
A good QP:
- Expands the capability of the database
- Uses resources effectively
- Reduces manual intervention
- Adapts to changing conditions
Expands the capability of the database: When a query doesn’t undergo a good optimization process, it may never complete (or will take too long to complete to be reasonable), but, with good optimization, the same query can complete quickly. This means that a good optimizer allows queries that may be impossible, or require extensive re-writing, or even need multiple execution steps in an un-optimized environment.
Uses resources effectively: When an optimizer is able to grant the correct amount of resources to a query, parallelization can occur. If a query is given too many resources, it could block other queries from executing simultaneously. If given too few, it could execute too slowly.
Reduces manual intervention: Oftentimes, when a query runs too slowly (or doesn’t complete), someone need to go do some work, or tweaks, etc. to fix the problem. Not only is manual intervention tedious, it can be error prone and may not adapt well to changing conditions inside the database. Further, sometimes these tweaks can slow down other operations.
Adapts to changing conditions: As table sizes change, or as plan parameters change, the query plan will often automatically adjust to these new conditions. These changes reflect the most optimal plan for the query given the database as it is now. If QP only used the very first plan it created for a query, it would be blind to the changes in data or plan parameters, and thus may executions would be far from optimal.
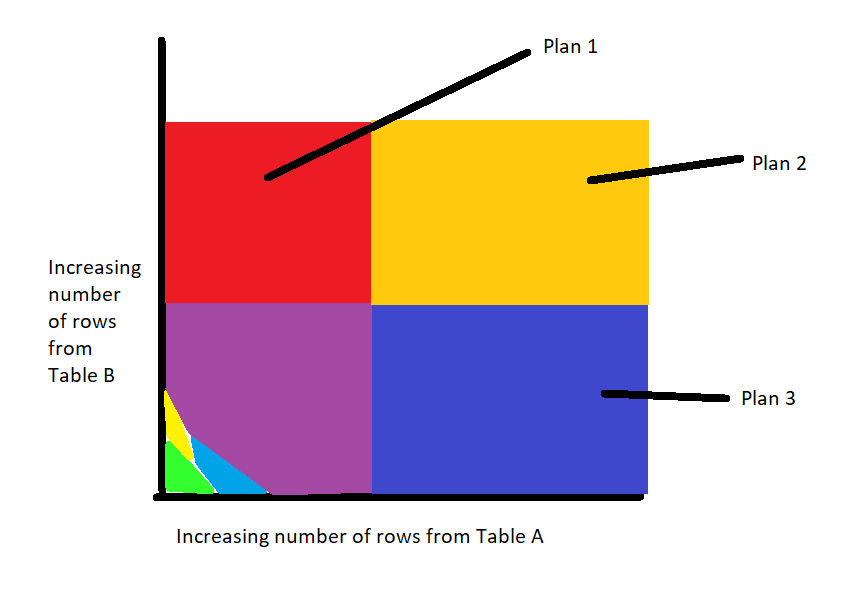
You can see in Figure 1 a diagram called a “plan space” diagram. As the number of rows selected by a query from various tables increases, the plan changes. The diagram in figure 1 is just a cartoon, with the intent of showing what the Plan Space for a given query might be, as the number of rows being processed increases. In this diagram, each colored area represents a different plan for the same query, as the number of rows being processed changes. The plan space for this imaginary query and tables contains 7 plans, each of which is ideal based on the number of rows being processed.
The general trend with plan spaces is that there are more plans when the number of rows is smaller, and fewer plans when the number of rows gets very large. The reason for this trend is that QP has a limited set of tools – some work better for large data sets, some for smaller. When the number of rows is small, tools can be combined and balanced to create different plans. However, when the data size becomes large enough, the QP chooses all of the best operators for large data. For example, nested loops join is a join technique that is well-suited to smaller data sets. Hash join is preferred for processing larger numbers of rows. It is easy to keep making the data size larger, but once the QP is choosing hash join (and other operational equivalents for large data), the options for further improvement are limited.
What a good QP does
But how does a good QP even find this “plan space” and execute queries? First, the QP needs to determine how it is going to execute a query, then it needs to execute efficiently.
Upon receipt of a query, the QP first determines how the query will be executed. The result of this step is a query plan. A few of the steps involved are:
Reorganizing the query: Some operators can be moved around to occur at different times during execution for faster results, but with no difference in the result set (semantically equivalent).
Choosing specific execution strategies: With knowledge about the various operators and by using statistics about the data, the optimizer can choose, for example, the way a join will be executed, considering memory usage and the estimated size of the data.
To do these things, may underlying pieces play a part, the details of which I will skip here. A few examples would be: selecting good indexes to operate on and estimating the data size for each step of execution. In Azure SQL and SQL Server, you can optimize a query without executing it. This way you can see the query plan without waiting for execution to complete. Once the QP creates a plan for a query, that plan can be executed multiple times. Since these plans adjust based on the estimated size of the data, it makes sense that there are a number of different plans that could be selected for the same query.
Query execution involves manipulating the rows from the source tables through the query and into the result set. Query execution accesses the indexes, performs the joins, filters the rows according to the query plan, and ultimately provides as output the qualifying rows from the query.
What can go wrong?
Sometimes, however, query processing makes reasonable, understandable choices that simply don’t work once the query starts to execute. This is typically due to lack of complete information, or due to the necessary assumptions that the must be made: finding a plan works well in the general case, even if it doesn’t work well in a specific case.
At the highest level, either query processing has chosen one or more operators incorrectly based on the actual size of the data (plan generation relies on estimates only), or it has requested the wrong amount of memory for the plan to execute with. Both problems come from the generalizations and assumptions that are necessary for planning a query without having executed it
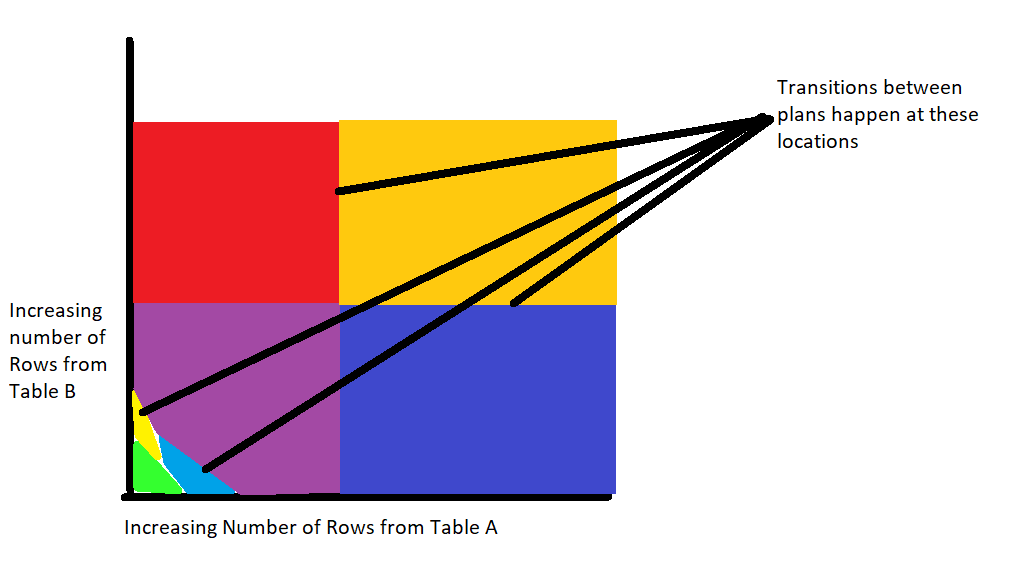
Another thing that can go wrong is when plans change gracelessly. As you can see if Figure 2, we should take note of the transition points between plans. In some cases, users experience a performance change at those points. I often refer to it as going off a cliff. You are chugging along with a decent plan, the data size changes, and boom! Now your query takes a lot longer, or a lot more memory to complete.
Intelligent QP to the Rescue
Azure SQL and SQL Server have released a number of improvements that improve upon this standard workflow in an attempt to lessen or correct common errors.
Briefly, Intelligent QP can:
- Remember past query execution’s memory consumption and allocate the proper amount in future executions using memory grant feedback (1, 2).
- Adjust on the fly when a join operator turns out to be the wrong one for the job using Adaptive Join.
- Postpone decision making during optimization while it gathers more information by using both Interleaved execution and Table variable deferred computation.
- Invest less time and fewer resources optimizing when the exact answer is not needed with Approximate QP.
- Use Scalar UDF inlining replace function calls with the body of the function, thus allowing for more optimization.
- Execute things in batches, even when data is not compressed, using Batch mode on row store.
Another way of looking at these elements of Intelligent QP is that they are designed to:
- Learn (1) – Modify behavior based on past performance.
- Adapt (2, 3) – Instead of generating a plan and executing it with no changes, these improvements allow for on-the-fly adjustments so that queries execute more smoothly.
- Enhance Efficiency (4, 5, 6) – New capabilities allowing the QP to execute in the most efficient way possible. These new techniques improve the efficiency of plan execution.
These features of intelligent QP have one goal in mind: Better plans, fewer surprises. By learning, adjusting, and adapting to the changing context of the database, intelligent QP means that:
- DBAs don’t have to spend so much time on manual adjustment and workarounds for poor query performance.
- Queries, on average, execute faster. Faster queries save time and machine hours.
- A small team can be successful with Azure SQL’s QP without hiring a full time DBA.
- Fewer customer incidents when plans go south unexpectedly.
In this way, Intelligent QP reduces the likelihood of sudden, abrupt plan regressions. With it, you can walk smoothly along the heights without worrying about falling off a cliff.
Photo by @joagbriel from Pexels
The only config setting right now in Azure SQL for this is the “use last good query plan”-flag. There is a new flag in the same view but it is not possible to set it yet.
Edit:
The things you talk about are enabled by compat.level 14/15 I see now…
/Håkan Nilsson, DBA, CAB Group Sweden