
Serverless Streaming At Scale with Azure SQL
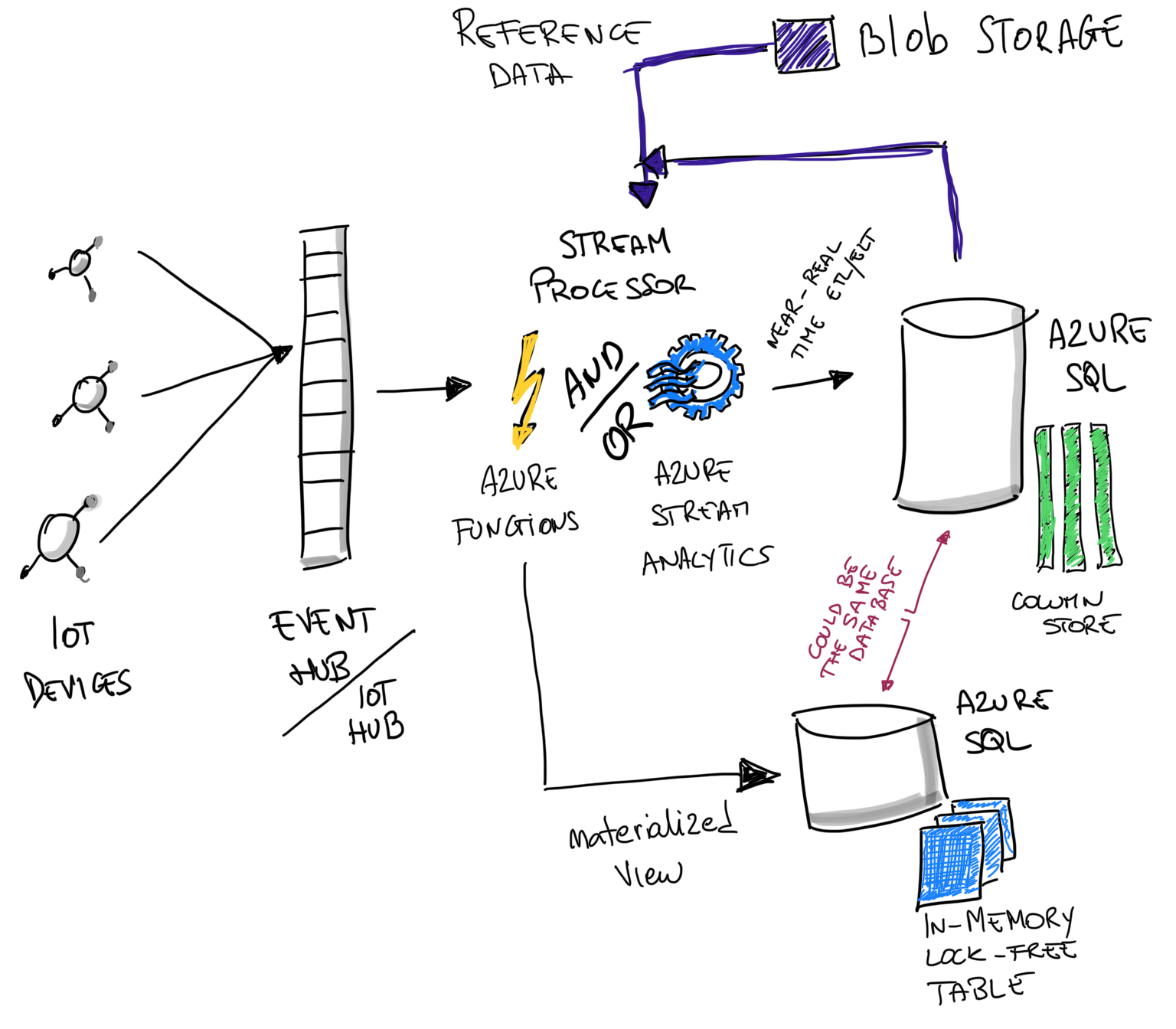
Just before Ignite, a very interesting case study done with RXR has been released, where they showcased their IoT solution to bring safety in buildings during COVID times. It uses Azure SQL to store warm data, allowing it to be served and consumed to all downstream users, from analytical applications to mobile clients, dashboards, API, and business users.
If you haven’t done yet, you definitely should watch the Ignite recording (the IoT part start at minute 22:59). Not only the architecture presented is super interesting, but also the guest presenting it — Tara Walker — is super entertaining and joyful to listen to. Which is not something common in technical sessions. Definitely a bonus!

If you are interested in the details, besides the Ignite recording, take a look also at the related Mechanics video, where things are discussed a bit more deeply.
Implement a Kappa or Lambda architecture on Azure using Event Hubs, Stream Analytics and Azure SQL, to ingest at least 1 Billion message per day on a 16 vCores database
The video reminded me that in my long “to-write” blog post list, I have one exactly on this subject. How to use Azure SQL to create an amazing IoT solution. Well, not only IoT. More correctly how to implement a Kappa or Lambda architecture on Azure using Event Hubs, Stream Analytics, and Azure SQL. It’s a very generic architecture that can be easily turned to IoT just by using IoT Hub instead of Event Hubs and it can be used as-is if you need, instead, to implement an ingestion and processing architecture for the Gaming industry, for example.
The goal is to create a solution that can ingest and process up to 10K messages/sec, which is close to 1 Billion messages per day, which is a value that will be more than enough for many use cases and scenarios. And if someone needs more, you can just scale up the solution.
Long Story Short
This article is quite long. So, if you’re in hurry, or you already know all the technical details on the aforementioned services, or you don’t really care too much about tech stuff right now, you can just go away with the following key points.
- Serverless streaming at scale with Azure SQL works pretty well, thanks to Azure SQL support to JSON, Bulk Load, and Partitioning. As with any “at scale” scenarios it has some challenges but they can be mostly solved just by applying the correct configuration.
- The sample code will allow you to set up a streaming solution that can ingest almost 1 billion messages per day in less than 15 minutes. That’s why you should invest in the cloud and in infrastructure-as-code right now. Kudos if you’re already doing that.
- Good coding and optimization skills are still key to create a nice working solution without just throwing money at the problem.
- The real challenge is to figure out how to create a balanced architecture. There are quite a few moving parts in a streaming end-to-end solution, and all need to be carefully configured otherwise you may end with bottlenecks on one side, and a lot of unused power on the other. In both cases, you’re losing money. Balance is the key.
If you’re now ready for some tech stuff, let’s get started.
Serverless: This is the way
So, let’s see it in detail. As usual, I don’t like to discuss without also having a practical way to share knowledge, so you can find everything ready to be deployed in your Azure subscription here:
As that would not be enough, I also enjoyed recording a short video to go through the working solution, giving you a glimpse of what you’ll get, without the need for you to spend any credit if you are not yet ready to do that:
Kappa and Lambda Architectures
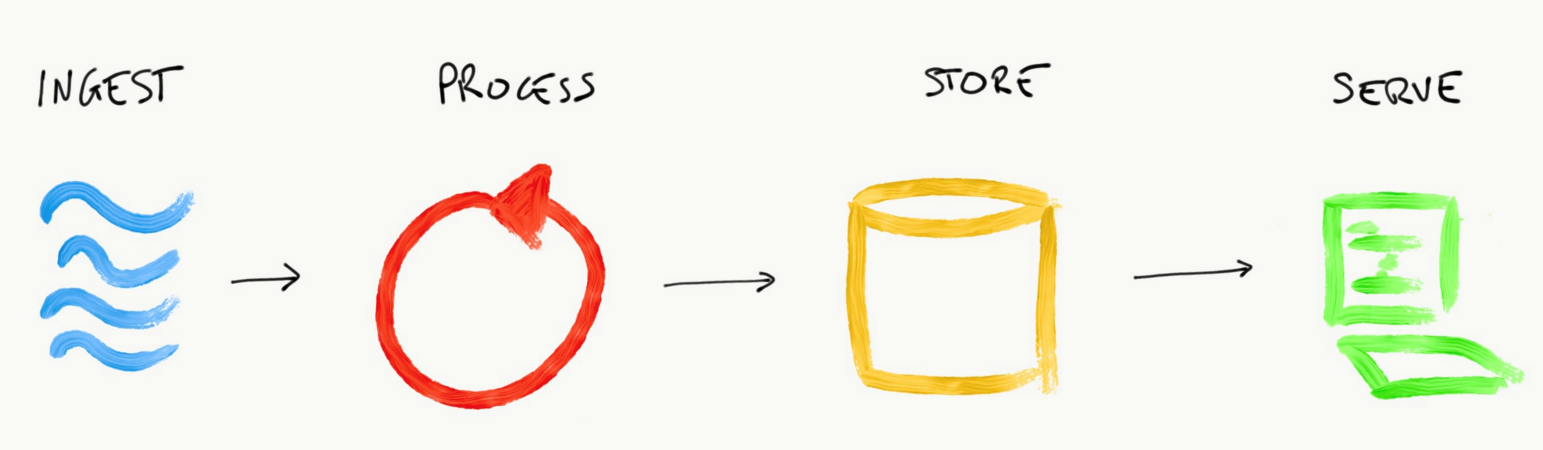
Creating a streaming solution usually means implementing one of two very well know architectures: Kappa or Lambda. They are very close to each other, and it’s safe to say that Kappa is a simplified version of Lambda. Both have a very similar data pipeline:
- Ingest the stream of data
- Process data as a stream
- Store data somewhere
- Serve processed data to consumers
Ingesting data with Event Hubs
Event Hubs is probably the easiest way to ingest data at scale in Azure. It is also used behind the scenes by IoT Hub, so everything you learn on Event Hubs will apply to IoT Hub too.
It is very easy to use, but at the beginning, some of the concepts can be quite new and not immediate to grasp, so make sure to check out this page to understand all the details: Azure Event Hubs — A big data streaming platform and event ingestion service
Long story short: you want to ingest a massive amount of data in the shortest time possible and keep doing that for as much as you need. To achieve the scalability you need, a distributed system is required, and so data must be partitioned across several nodes.
Partitioning is King
In Event Hubs, you have to decide how to partition ingested data when you create the service, and you cannot change it later. This is the tricky part. How do you know how many partitions you will need? That’s a very complex answer, as it is completely dependent on how fast who will read the ingested data will be able to go.
If you have only one partition and one of the parallel applications that will consume the data is slow, you are creating a bottleneck.
If you have too many partitions, you will need to have a lot of clients reading the data, but if data is not coming in fast enough, you’ll starve your consumers, meaning you are probably wasting your money on running processes that are doing nothing for a big percentage of their CPU time.
So let’s say that you have 10MB/sec of data coming in. If each of your consuming clients can process data at 4MB/sec, you probably want 3 of them to work in parallel (with the hypothesis that your data can be perfectly and evenly spread across all partitions), so you will probably want to create at least 3 partitions.
That’s a good starting point, but “3 partitions” is not the correct answer. Let’s understand why by making the example a bit more realistic and thus slightly more complex.
Event Hubs let you pick and choose the Partition Key, which is the property whose values will be used to decide in which partition an ingested message will land. All messages with the same partition key value will land in the same partition. Also, if you need to process messages in the order they are received, you must put them in the same partition. In fact, the order is guaranteed only at the partition level.
In our sample we’ll be partitioning by DeviceId, meaning data coming from the same device will land in the same partition. Here’s how the sample data is generated
stream = (stream
.withColumn("deviceId", ...)
.withColumn("deviceSequenceNumber", ...)
.withColumn("type", ...)
.withColumn("eventId", generate_uuid())
.withColumn("createdAt", F.current_timestamp())
.withColumn("value", F.rand() * 90 + 10)
.withColumn("partitionKey", F.col("deviceId"))
)
Throughput Units
In Event Hubs the “power” you have available (and that you pay for) is measured in Throughput Units (TU). Each TU guarantees that it will support 1MB/sec or 1000 messages(or events)/sec, whichever came first. If we want to be able to process 10.000 events/sec we need at least 10 TU. Since it’s very unlikely that our workload will be perfectly stable, without any peak here and there, I would go for 12 TU, to have some margin to handle some expected workload spike.
TU can be changed on the fly, increasing or reducing them as you need.
Decisions
It’s time to decide how many TU and Partitions we need in our sample. We want to be able to reach at least 10K messages/second. TUs are not an issue as they can be changed on the fly, but deciding how many partitions we need is more challenging. We’ll be using Stream Analytics, and we don’t exactly know how fast it will be able to consume incoming data.
Of course, one road is running a test to figure out the correct numbers, but we still need to come up with some reasonable numbers also to just start with such a test. Well, a good rule of thumb is the following:
Rule of thumb: create an amount for partitions equal to the number of throughput units you have or you might expect to have in future
For what concerns the ingestion part we’re good now. If you want to know more, please take a look at this article: Partitioning in Event Hubs and Kafka, which will go into detail about this topic. Super recommended!
Let’s now move to discuss how to process the data that will be thrown at us, doing it as fast as possible.
Processing Data with Stream Analytics
Azure Stream Analytics is an amazing serverless streaming processing engine. It is based on the open-source Trill framework which source code is available on GitHub and is capable to process a trillion messages per day. All without requiring you to manage and maintain the complexity of an extremely scalable distributed solution.
Stream Analytics support a powerful SQL-like declarative language: tell it what you want and it will figure out how to do it, fast.
It also supports a SQL-like language so all you have to do to define how to process your event is to write a SQL query (with the ability to extend it with C# or Javascript) and nothing more. Thanks to SQL simplicity and the ability to express what you want as opposed to what to do, development efficiency is very high. For example determining for how long an event lasted, for example, is as easy as doing this:
SELECT
[user],
feature,
DATEDIFF(second,
LAST(Time) OVER (
PARTITION BY [user], feature
LIMIT DURATION(hour, 1)
WHEN Event = 'start'
),
Time) as duration
FROM
input
TIMESTAMP BY
Time
WHERE
Event = 'end'
All the complexity of managing the stream of data used as the input, with all its temporal connotations, is done for you, and all you have to tell Stream Analytics is that it should calculate the difference between a start and end event on per user and feature basis. No need to write complex custom stateful aggregation functions or other complex stuff. Let’s keep everything simple and leverage serverless power and flexibility.
Embarrassingly parallel jobs
As for any distributed system, the concept of partitioning is key, as it is the backbone of any scale-out approach. In Stream Analytics, since we are getting data from Event Hub or IoT Hub, we can try to use exactly the same partition configuration already defined in those services. If was use the same partition configuration also in Azure SQL, we can achieve what is defined as embarrassingly parallel jobs where there is no interaction between partitions and everything can be processed fully in parallel. Which means: at the fastest speed possible.
Streaming Units
Streaming Units (SU) is the unit of scale that you use — and pay for—in Azure Stream Analytics. There is no easy way to understand how many SU you need, as consumption will totally depend on how complex your query is. The recommendation is to start with 6 and then monitor the Resource Utilization to see how much percentage of available SU you are using. If your query partition data using PARTITON BY, SU usage will increase as you are distributing the workload across nodes. This is good, as it means you’ll be able to process more data in the same amount of time. You also want to make sure SU utilization is below 80% as after that your events will be queued, which means you’ll see higher latency. If everything works well, we’ll be able to ingest our target of 10K events/sec (or 600K events/minute as pictured below)

Storing and Serving Data with Azure SQL
Azure SQL is really a great database for storing hot and warm data of an IoT solution. I know this is quite the opposite of what many think. A relational database is rigid, it requires schema-on-write, and on IoT or Log Processing scenarios, the best approach is a schema-on-read instead. Well, Azure SQL actually supports both and more.
With Azure SQL you can do both schema-on-read and schema-on-write, via native JSON support
In fact, besides what just said, there are several reasons for this, and I’m sure you are quite surprised to hear that, so, read on:
- JSON Support
- Memory-Optimized Lock-Free Tables
- Column Store
- Read-Scale Out
Describing each one of the listed features, even just at a very high level, would require an article on its own. And of course, such an article is available here, if you are interested (and you should!): 10 Reasons why Azure SQL is the Best Database for Developers.
To accommodate a realistic scenario where you have some fields that are always present, while some other can vary by time or device, the sample is using the following table to store ingested data
CREATE TABLE [dbo].[rawdata] ( [BatchId] [UNIQUEIDENTIFIER] NOT NULL, [EventId] [UNIQUEIDENTIFIER] NOT NULL, [Type] [VARCHAR](10) NOT NULL, [DeviceId] [VARCHAR](100) NOT NULL, [DeviceSequenceNumber] [BIGINT] NOT NULL, [CreatedAt] [DATETIME2](7) NOT NULL, [Value] [NUMERIC](18, 0) NOT NULL, [ComplexData] [NVARCHAR](MAX) NOT NULL, [EnqueuedAt] [DATETIME2](7) NOT NULL, [ProcessedAt] [DATETIME2](7) NOT NULL, [StoredAt] [DATETIME2](7) NOT NULL, [PartitionId] [INT] NOT NULL )
As we really want to create something really close to a real production workload, indexes have been created too:
- Primary Key Non-Clustered index on
EventId, to quickly find a specific event - Clustered index on
StoredAt, to help time-series-like queries, like, querying the last “n” rows reported by devices - Non-Clustered index on
DeviceId, DeviceSequenceNumberto quickly return reported rows sent by a specific device - Non-Clustered index on
BatchIdto allow the quick retrieval of all rows sent by a specific batch
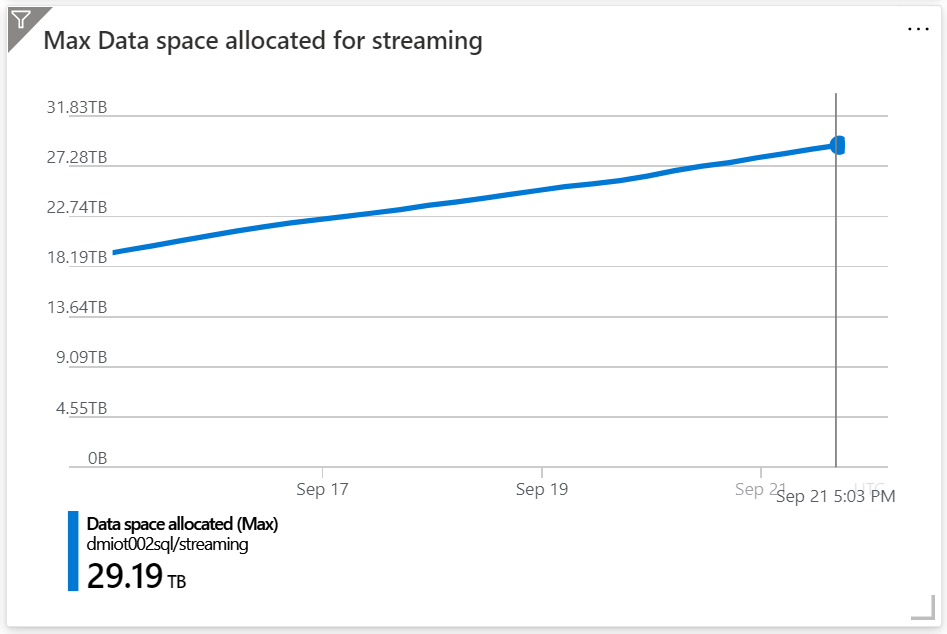
At the time of writing, I’ve been running this sample for weeks and my database is now close to 30TB:
The table is partitioned by PartitionId (which is in turn generated by Event Hubs based on DeviceId) and a query like the following
SELECT TOP(100) EventId, [Type], [Value], [ComplexData], DATEDIFF(MILLISECOND, [EnqueuedAt], [ProcessedAt]) AS QueueTime, DATEDIFF(MILLISECOND, [ProcessedAt], [StoredAt]) AS ProcessTime [StoredAt] FROM dbo.[rawdata2] WHERE [DeviceId] = 'contoso://device-id-471' AND [PartitionId] = 0 ORDER BY [DeviceSequenceNumber] DESC
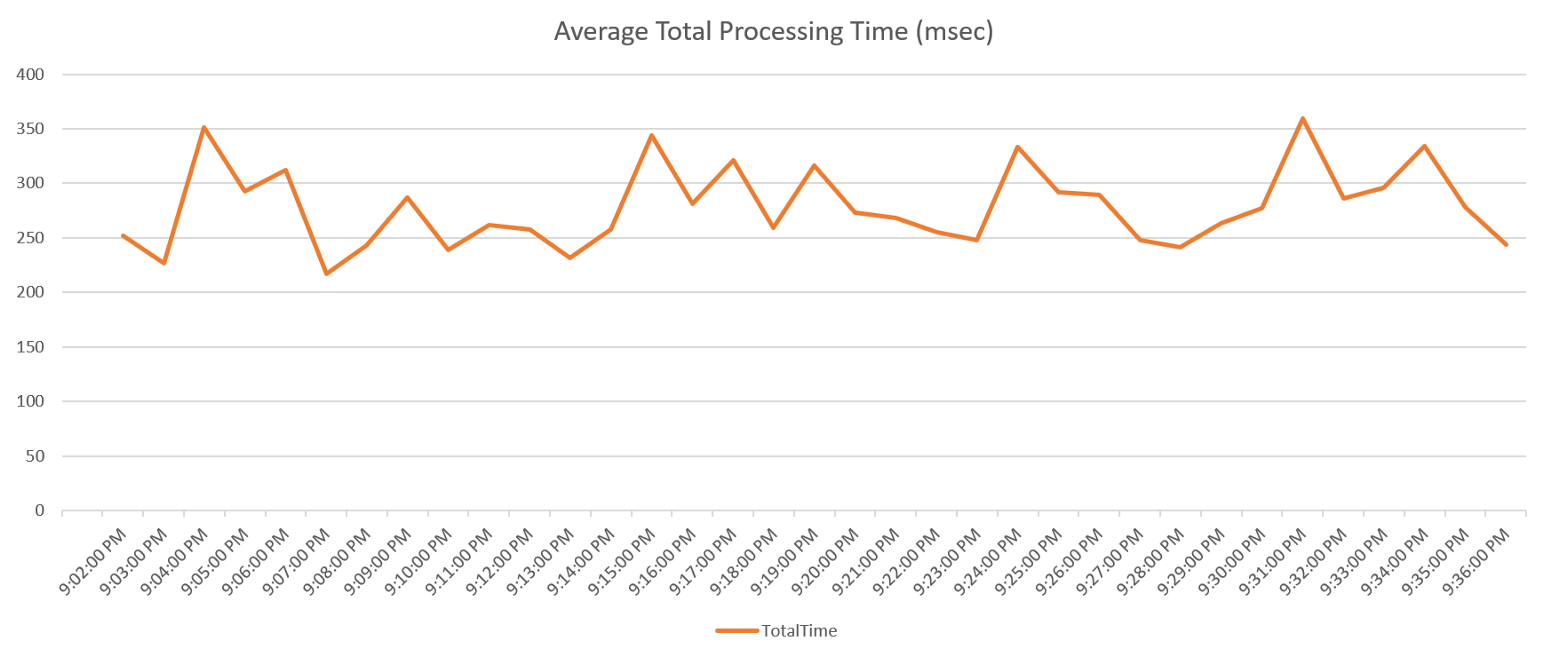
Takes less than 50 msec to be executed including also the time to send the result to the client. That’s pretty impressive. The result also shows something impressive too:
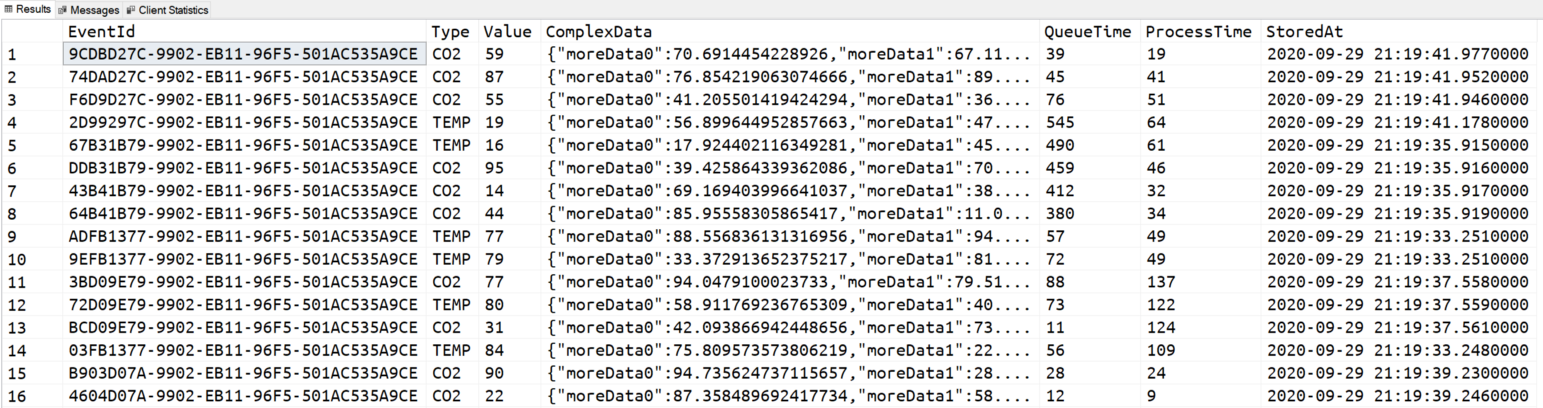
As you can see, there are two calculated columns QueueTime and ProcessTime that shows, in milliseconds, how much time an event has been waiting in Event Hubs to be picked up by Stream Analytics to be processed, and how much time the same event spent within Stream Analytics before land into Azure SQL. Each event (all the 10K per second) is processed in — overall—less than 300 msec on average. 280msec more precisely.
That is very impressive.
End-to-End ingestion latency is around 300msec
You can also go lower than that using some more specific streaming tool like Apache Flink, if you really need to completely avoid any batching technique to decrease the latency to the minimum possible. But unless you have some very unique and specific requirements, processing events in less than a second is probably more than enough for you.
Sizing Azure SQL database for ingestion at scale
For Azure SQL, ingesting data at scale is not a particularly complex or demanding job, on the contrary of what one can expect. If done well, using bulk load libraries, the process can be extremely efficient. In the sample I have used a small Azure SQL 16 vCore tier to sustain the ingestion of 10K event/secs, using on average 15% of CPU resources on a bit more of 20% of the IO resources.
This means that in theory, I could also use an even smaller 8 vCore tier. While that is absolutely true, you have to think of at least three other factors when sizing Azure SQL:
- What other workloads will be executed on the database? Analytical Queries to aggregated non-trivial amounts of data? Singleton rows lookups to get details on a specific item (for example to get the latest status of a device?)
- In case the workload will spike, will Azure SQL be able to handle, for example, twice or trice the usual workload? That’s important as spikes will happen, and you don’t want to have a single spike to bring down your nice solution.
- Maintenance activities may need to be executed (that really depends on the workload and the data shape), like index defragmentation or partitioning compression. Azure SQL needs to have enough spare power to handle such activities nicely.
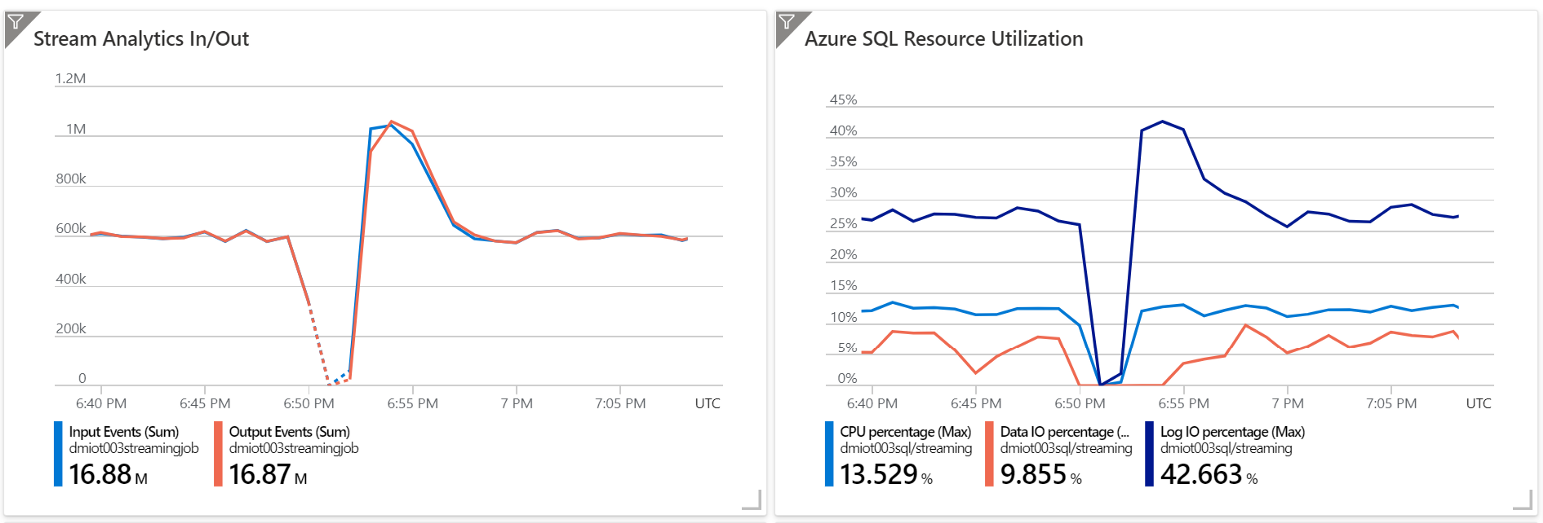
Just as an example, I have stopped Stream Analytics for a few minutes, allowing messages to pile up a bit. As soon as I restarted it, it tried to process messages as fast as possible, to empty the queue and return to the ideal situation where latency is less than a second. To allow Stream Analytics to process data at a higher rate, Azure SQL must be able to handle the additional workload too, otherwise, it will slow down all the other components in the pipeline.
As expected, Azure SQL handled the additional workload without breaking a sweat.
For all the needed time, Azure SQL was able to ingest almost twice the regular workload, processing more than 1 Million messages per minute. All of this with CPU usage staying well below 15%, and with a relative spike only to the Log IO — something expected as Azure SQL uses a Write-Ahead Log pattern to guarantee ACID properties—which, still, never went over 45%.
Really, really, amazing.
With such configuration — and remember we’re just using a 16vCore tier, but we can scale up to 80 and more — our system can handle something like 1 billion messages a day, with an average processing latency of less than a second.
The deployed solution can handle 1 billion messages a day, with an average processing latency of less then a second.
Partitioning is King, again.
Partitioning plays a key role also in Azure SQL: as said before, if need to operate on a lot of data concurrently, partitioning is really something you need to take into account.
Partitioning, in this case, is used to allow concurrent bulk insert into the target table, even if on such table several indexes exist and thus needs to be kept updated.
The table has been partitioned using the PartitionId column, to have the processing pipeline completely aligned. The PartitionId value is in fact generated by Event Hub, which partitions data by DeviceId, so that all data coming from the same device will land in the same partition.
Stream Analytics uses the same partitions provided by Event Hub and so it makes sense to align Azure SQL partitions to this logic too, to avoid to cross the streams, which we all know is a bad thing to do. Data will move from source to destination in parallel streams providing the performances and the scalability we are looking for.
CREATE PARTITION FUNCTION [pf_af](int) AS RANGE LEFT FOR VALUES (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16)
Table partitioning also allows Azure SQL to update the several indexes existing on the target table without ending in tangled locking, where transactions are waiting for each other with the result of a huge negative impact on performances. As long as table and indexes are using the same partitioning strategy everything will move forward without any lock or deadlock problem.
CREATE CLUSTERED INDEX [ixc] ON [dbo].[rawdata] ([StoredAt] DESC) WITH (DATA_COMPRESSION = PAGE) ON [ps_af]([PartitionId]) CREATE NONCLUSTERED INDEX ix1 ON [dbo].[rawdata] ([DeviceId] ASC, [DeviceSequenceNumber] DESC) WITH (DATA_COMPRESSION = PAGE) ON [ps_af]([PartitionId]) CREATE NONCLUSTERED INDEX ix2 ON [dbo].[rawdata] ([BatchId]) WITH (DATA_COMPRESSION = PAGE) ON [ps_af]([PartitionId])
Higher concurrency is not the only perk of a good partitioning strategy. Partitions allow extremely fast data movement between tables. We’ll take advantage of this ability for creating highly compressed column-store indexes soon.
Scale-out the database
What if you need to run complex analytical queries on the data being ingested? That’s a very common requirement for Near-Real-Time Analytics or HTAP (Hybrid Transaction/Analytical Processing) solutions.
As you have noticed, you still have enough resources free to run some complex queries, but what if you have to run many really complex queries, for example, to compare average values of month-over-month, on the same table where data is being ingested? Or what if you need to allow many mobile clients to access the ingested data, all running small but CPU intensive queries? The risk of resource contention — and thus low performances — becomes real.
That’s when a scale-out approach starts to get interesting.
With Azure SQL Hyperscale you can create up to 4 readable-copies of the database, all with their own private set of resources (CPU, memory, and local cache), that will give you access to exactly the same data sitting in the primary database, but without interfering with it at all. You can run the most complex query you can imagine on a secondary, and the primary will not even notice it. Ingestion will proceed at the usual rate, completely unaffected by the fact that a huge analytical query or many concurrent small queries are hitting the secondary nodes.
Columnstore, Switch-In, and Switch-Out
Columnstore tables (or index in Azure SQL terms) are just perfect for HTAP and Near-Real-Time Analytics scenario, as already described times ago here: Get started with Columnstore for real-time operational analytics.
This article is already long enough, so I’ll not get into details here, but I will focus on the fact that using columnstore index as a target of a Stream Analytics workload, may not be the best option if you are also looking for low latency. To keep latency small, a small batch size needs to be used, but this is against the best practices for columnstore, as it will create a very fragmented index.
To address this issue, we can use a feature offered by the partition table. Stream Analytics will land data into a regular partitioned rowstore table. On scheduled intervals, a partition will be switched out into a staging table, so that it be loaded into a columnstore table using Azure Data Factory, for example, so that all best practices can be applied to have the highest compression and the minimum fragmentation.
Still not fast enough?
What if everything just described is still not enough? What if you need a scale so extreme that you need to be able to ingest and process something like 400 Billion rows per day? Azure SQL allows you to do that, by using In-Memory, latch-free, tables, as described in this amazing article:
Scaling up an IoT workload using an M-series Azure SQL database
I guess that, now, even if you have the most demanding workload, you should be covered. If you need even more power…let me know. I’ll be extremely interested in understanding your scenario.
Conclusion
We’re at the end of this long article, where we learned how it is possible with a Kappa (or Lambda) architecture to ingest, process, and serve 10K msg/sec using only PaaS services. As we haven’t maxed out any of the resources of our services, we know we can scale to a much higher level. At least twice that goal value, without changing anything and much more than that by increasing resources. With Azure SQL we are just using 16 vCores and it can be scaled up to 128. Plenty of space to grow.
Azure SQL is a great database for IOT and HTAP workload
 Light
Light Dark
Dark
0 comments