

In our previous overview of DevOps for Azure SQL DB, we showed you how you can use the built-in tasks in Azure Pipelines to deliver changes continuously to an Azure SQL database. That pipeline was quite simple, and did not have a separate step to create the database. It also did not have any built-in mechanism for approvals.
A more realistic scenario will have increased requirements. As an example, let’s consider the following requirements for our pipeline:
- Have separate build (CI) and deliver (CD) stages in our database deployment pipeline.
- Use Azure CLI, running on a Linux-based agent, to create the logical Azure SQL server and Azure SQL DB.
- Use declarative “everything-as-code” principles to drive the actual deployment actions:
- Do nothing if the server and / or the database exists (“idempotent” deployments).
- Update the target to match the desired final state (for example, Service Objective) if needed.
- Introduce an explicit approval requirement before actual DB deployment can proceed.
The above are just some common requirements – the key point is that customers like yourself, would like to blend usage of preferred tools (including third party tools like Terraform, Ansible etc.), and preferred workflow, on top of the core step of deploying changes to the database.
Let’s get started!
This post shows you how you can easily accomplish these requirements. The tools and services we will use include Azure DevOps multi-stage pipelines, Azure CLI and the sqlpackage tools. Let’s briefly look at each of these tools individually before putting them all together.
Azure Pipelines
In case you are not familiar, Azure Pipelines are comprised of a series of Stages, each Stage in turn containing one or more Jobs, each job in turn comprising of a set of Steps, which in turn contain Tasks. This blog post does a great job summarizing the terminology and concepts. Specifically, Multi-Stage Pipelines allow a great degree of control and flexibility – see this post which has a great overview of those capabilities. Each job can execute on a distinct agent pool, opening up a lot of possibilities even in a hybrid or tightly locked down setup. The key point here is that by organizing our pipeline into distinct set of stages and jobs, and by associating approval requirements with specific “environments”, we can accomplish all of the above stated requirements (and potentially much more).
CRUD tool options
There are several tooling options which support create, update, and delete (CRUD) operations for Azure SQL DBs and servers. While T-SQL supports Azure SQL DB creation, other operations like creating a logical Azure SQL server, an elastic pool, etc. need to be done externally by eventually invoking the core Azure APIs. These tools wrap the relative complexity of working directly with the APIs and are easier to work with for most users. Most of these tools operate on the principle of declaratively specifying the intended state, and internally figure out what needs to be done to get there.
Azure CLI
The Azure Command Line Interface is a popular, multi-platform tool which provides (among many other commands) convenient way to create a logical Azure SQL server, to create an Azure SQL DB etc. In specific cases, Azure CLI is idempotent, which means that it will ensure that nothing is done if the target already exists. Also, if the target exists (albeit with different configuration) the target will be automatically updated to match the required configuration. This is because the create DB command internally reduces down to an underlying Databases – Create Or Update API call (for those interested, the corresponding source code for the AZ CLI is here). So, as an example, if the target DB exists, but has a different service (tier) objective of HS_Gen5_2, the DB will be updated to the desired service objective (let’s say, HS_Gen5_24) etc.
While many Azure CLI operations are “idempotent” in a way, Note that not all other Azure CLI operations are idempotent – you should test and validate if they behave as intended in your specific scenario. Ultimately, since the source code for the Azure CLI is available on GitHub, it should be feasible to determine the intended behavior outside of just empirical testing.
Azure PowerShell etc.
Azure PowerShell also provides cmdlets for Azure SQL CRUD operations. You can refer to the docs for New-AzSqlDatabase as an example.
Terraform, Ansible etc.
Some customers prefer to use third-party Infrastructure-as-Code (IaC) tools like Terraform or Ansible (there are other tools like these – this is not a comprehensive list) when working with their Azure SQL environments. The good news (as you will see below) is that both these tools can leverage the underlying AZ CLI environment, in the context of an Azure DevOps pipeline, to obtain a security context to execute their requests against Azure. Also, while some IaC tools like Ansible do not support running on Windows, the good news is that AZ CLI command line supports running on Linux and macOS. Though we don’t use any of these third party tools in this blog post, we’ll see how we accommodate this potential OS requirement when we put all of this together later in this post.
sqlpackage
Earlier in this post, we linked to the sqlpackage download page. In this blog post, we used this tool to support a declarative / state-based approach to database deployments. For more details on this approach, and alternatives therein, please refer to our previous overview of DevOps for Azure SQL DB. Sqlpackage is internally invoked by built-in activities within Azure DevOps to facilitate the deployment of changes to the target DB. For the core DB deployment step, this tool is idempotent – if the target database is already at the intended state, no changes are needed to the target DB. (Fine print: if the developer adds pre-deployment, or post-deployment scripts to the SQL Project, idempotency of those scripts needs to be handled by the developer in the T-SQL code).
It is useful to consider that while sqlpackage has some capabilities to create an Azure SQL DB as part of the deployment, it is rather limited. Our recommendation is to leverage Azure CLI, PowerShell or IaC tools to manage the CRUD of the server / pool / database, and then use sqlpackage to deliver the in-database changes. If you use other migration-based libraries like Flyway or DbUp, you will still need to rely on the Azure CLI, PowerShell or IaC tools for CRUD operations.
Putting it all together
The source code for the multi-stage Azure DevOps pipeline is available here. The pipeline has 3 distinct stages:
- CreateDB – this stage has a single job, which uses the Azure CLI task for CRUD of the database. This stage runs on an Azure DevOps-hosted Linux agent (to illustrate the flexible OS choice).
- BuildDACPAC – we build the DACPAC from the SQL project source code, and publish it as an artifact for subsequent deployment task. The DACPAC build job in this stage runs on a self-hosted Windows agent and uses the VSBuild task to compile the SQLProject into a DACPAC. Note, this illustrates the flexibility on OS and environments that agent pools offer us.
- DeployDB – this stage contains 2 jobs – one used solely for the purposes of “gating” deployment till an approval is (manually) granted as part of a fictional workflow; the second job actually downloads the DACPAC artifacts, and then deploys the DACPAC to the target logical Azure SQL server using the built-in Azure SQL DB deployment task.
It is worth noting that Microsoft periodically updates the versions of the software (including AZ CLI and SQLPackage) on the Azure DevOps / Microsoft-hosted agents. The list of exactly which versions are currently installed is documented here.
Pipeline Artifacts
It is important to note that each job is run on a different agent VM. Even if it was part of the same pool, the VM state is reset between job runs. Hence, the usage of artifacts to save state and enable later jobs in the same pipeline to operate on the same effective state, is an important technique we leverage.
Pipelines UI
Here’s how the pipeline looks when viewed in the Azure DevOps UI:
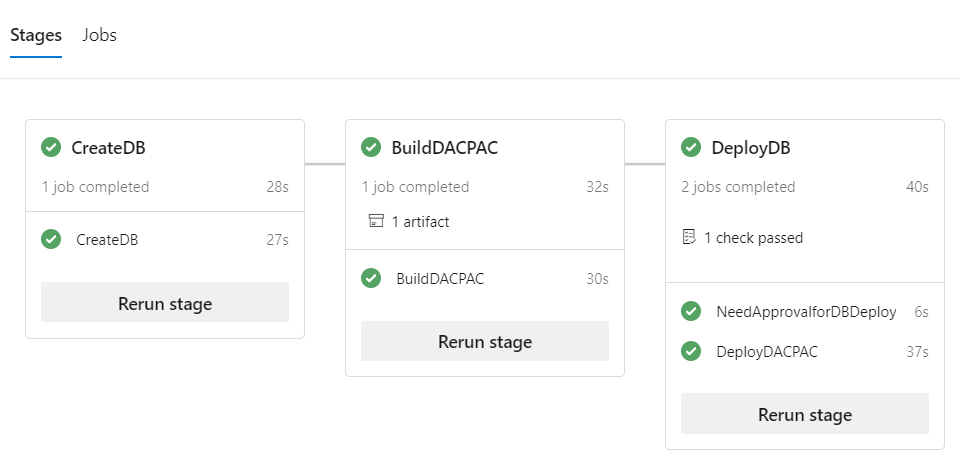
The main supporting objects for the above pipeline are described below.
Environment
Azure Pipelines allow the definition and targeting of specific “environments” as described here. Environments can be configured so that they require approvals to deploy into. In this example, we configured the approval requirement so that a user called “Azure SQL PR Reviewer” needs to approve:
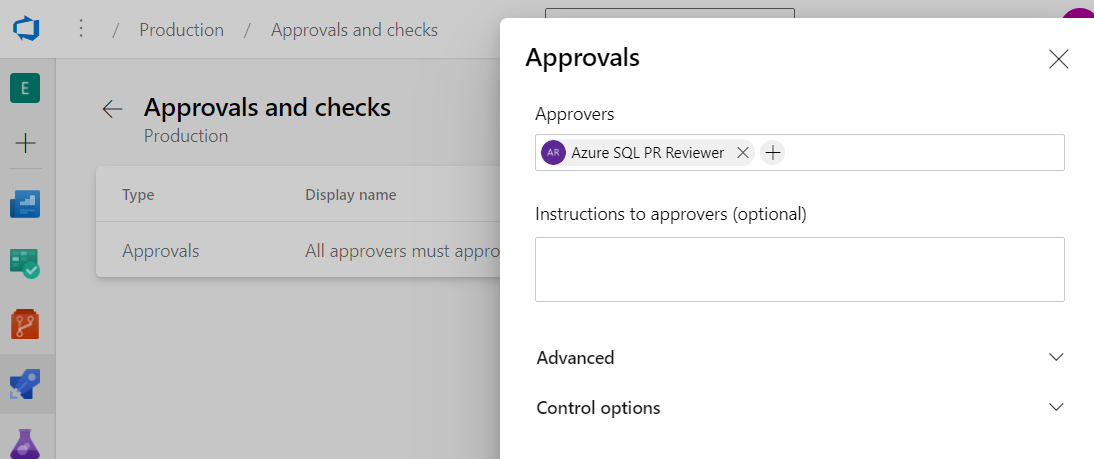
Here’s how the pipeline UI looks when it is pending on approval for the “Production” environment:
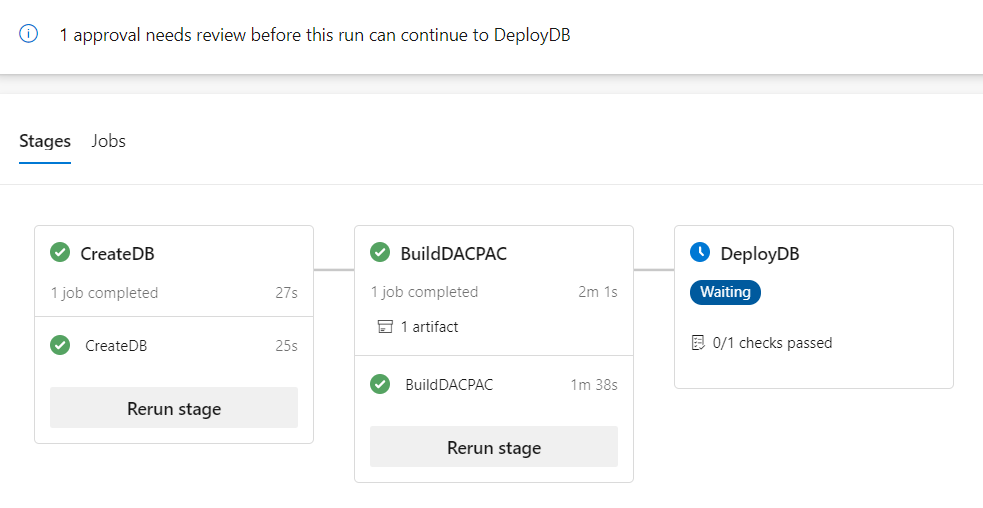
The required approver, in turn, gets a notification which looks like this:
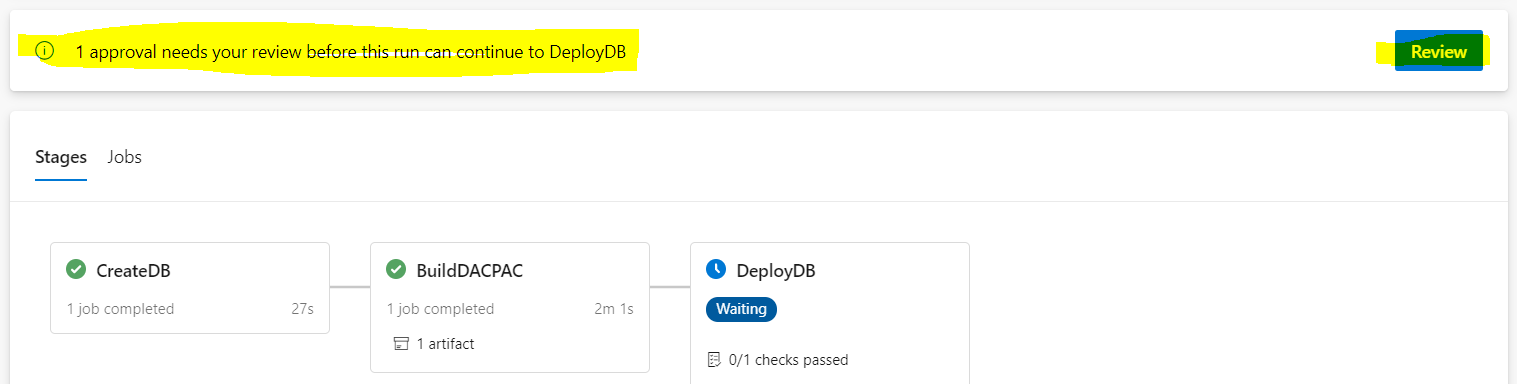
The DeployDB stage will proceed to the actual DACPAC deployment job, once the approval is granted.
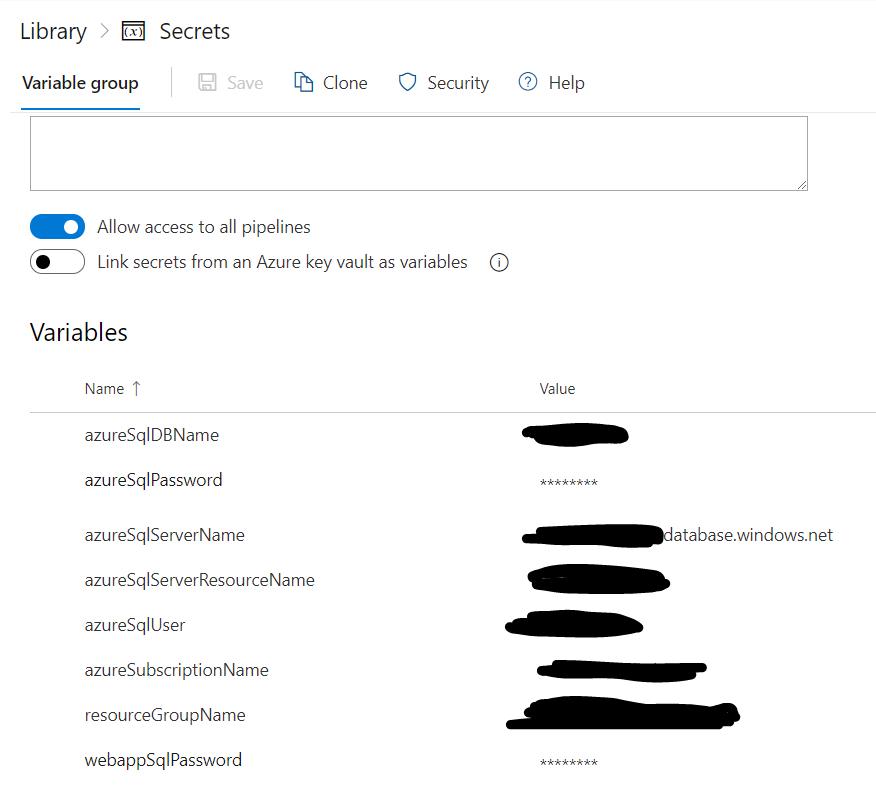
Secrets Management – Library
Azure Pipelines Library is where you can define and populate secrets. As seen below, we can store essential variables used by our sample pipeline in the Library. Variables can be marked as secret, so they are protected from accidental disclosure. You can also integrate with Azure Key Vault to access secrets.
Service Connections – Azure subscription
The AzureCLI task within the pipeline requires a “Service Connection” to an Azure subscription. The details on how to do this are here. The service principal used for this purpose should have the required permissions for CRUD operations at a given resource group level.
Conclusion
Multi-stage pipelines in Azure DevOps offer a rich, declarative, YAML-based mechanism to implement and customize pipelines. Integrating multiple tools like Azure CLI, sqlpackage etc. across different OS platforms (Linux and Windows as shown in this example) is very easy, and allows you to quickly implement your Azure SQL DB CI / CD pipelines with maximum flexibility and alignment with other networking and security requirements. The sample YAML pipeline definition here will hopefully help you get a quick start towards this!
Great post Arvind. If you would like to be able to build a SSDT project without having to depend on Windows, you can use this project: https://github.com/jmezach/MSBuild.Sdk.SqlProj
Suggestions for a follow up:
– Using .dacpac deployment with a user with limited rights, for example only access to a single schema.
– Obtaining the AAD AccessToken for the Azure Service Connection, and using that with sqlpackage (to avoid use of sql logins and storing passwords anywhere)
Thank you Erik! Yes, I have been tracking the project for a while, great work!
Regarding your ideas for follow-up posts, the AAD scenario definitely is something I want to take up soon, given it is coming up frequently these days.