

Literally, I just said that! I have three daughters, and it’s amazing how they ask me the same questions over and over. I don’t mind answering them, but I sure wish they would either remember my answer or, at least, write it down. There’s a measurable cognitive load with the context switching and staying consistent in my answers. And that’s a good—though a little messy—segue into data caching. Data API builder can now relieve your database’s burden with the new caching feature available to REST endpoints.
Version 0.11 is now available
Data API builder goes into General Availability soon, in the meantime, these are pre-version 1.0 releases, like version 0.11, with bug fixes, fit and finish improvements, and brand-new features like caching—the focus of this article.Your database is good at joining, filtering, sorting, and projecting data. Two, ten, even a hundred times a second isn’t a big deal if you have a sufficiently allocated database. But eventually, you reach a point where just asking the same question over and over doesn’t yield new results and pushes your database to its knees for no good reason. 
Data caching is an important strategy that lets you more freely determine how to invest in each part of your solution topology. Let’s weigh the advantages while comparing the cost of each component.
Do you pay for a larger database, or do you pay for a caching service? This is a reasonable question because the TCO (Total Cost of Ownership) of each service is not equal—even if they start that way. Databases, reliable and capable, eventually become a significant cost in any solution.
Caching in the API tier
Introducing a data API layer centralizes non-database capabilities in one place, offering significant benefits. For example, Data API builder manages data projection, security policies, graph resolution, application logs, and now in-memory caching. Since JSON payloads are generally small, caching them in container memory is straightforward. Your API often represents the most cost-effective part of your solution, and leveraging underutilized RAM can greatly benefit your budget.
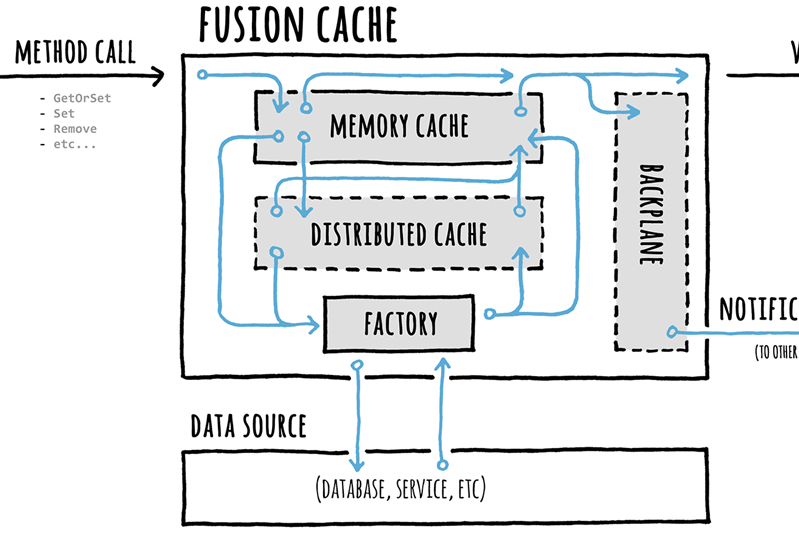
We use Fusion Cache
 What’s great about Data API builder is that we aren’t building something exotic. We’re building a regular data API just like you would build. Because of this, your code base doesn’t need as much source code. As we often say about Data API builder, “more engine, less code.”
What’s great about Data API builder is that we aren’t building something exotic. We’re building a regular data API just like you would build. Because of this, your code base doesn’t need as much source code. As we often say about Data API builder, “more engine, less code.”
But even better, because this is all standard, we use common technologies, frameworks, and techniques. To that end, we have selected Fusion Cache as our caching library. Why? Because it’s .NET, it’s brand new, it’s pluggable, and it allows us to plan for the future—introducing distributed, second-level caches like Redis or Microsoft Garnet.
Fusion Cache is award-winning and includes advanced resiliency features like cache stampede prevention, a fail-safe mechanism, fine-grained soft/hard timeouts with background factory completion, and customizable extensive logging. It uses a memory cache as the primary backing store and, optionally, a distributed, second-level cache as a secondary backing store for better resilience and higher performance, such as in a multi-node scenario or to mitigate the typical effects of a cold start.
Simple to use caching feature
![]() Data API builder remains committed to simplicity. Developers have the flexibility to configure caching on a global scale or for each entity as needed. The available settings are Enabled and Time-To-Live (TTL). You can set Enabled to either true or false (default). TTL specifies how long cached data remains valid before expiring.
Data API builder remains committed to simplicity. Developers have the flexibility to configure caching on a global scale or for each entity as needed. The available settings are Enabled and Time-To-Live (TTL). You can set Enabled to either true or false (default). TTL specifies how long cached data remains valid before expiring.
Activating caching and setting a TTL for an entity prompts the system to store the data returned from the API call in an in-memory cache. The system then utilizes this cached data for future requests for the same data, significantly boosting your application’s performance by minimizing the need for additional network calls or database queries. Check out our docs.
Global configuration
{
...
"runtime": {
"cache": {
"enabled": true,
"ttl-seconds": 5
}
}
}Allowing developers global control to enable or disable caching lets them deactivate caching (default) for debugging or activate it during crucial, peak events. Setting the TTL globally enables developers to omit this value from individual entity configurations if they prefer.
Entity configuration
"entities": {
"Actor": {
...
"cache": {
"enabled": true,
"ttl-seconds": 1
}
},Granular control over each entity allows developers to pinpoint the best opportunities for cost savings and performance gains, while maintaining the control they need to ensure appropriate representation of volatile data.
Cache caveats
Caching supports REST endpoints but not GraphQL endpoints. With REST, the system returns entities one at a time, and filters appear in the URL, simplifying the identification of repeated calls and the creation of caching keys. We are still developing a secure and reliable method to uniquely identify GraphQL queries, an initial step necessary to enable GraphQL caching. As a result, we have not enabled caching for GraphQL endpoints yet.
The system automatically disables caching when it enables session context in the configuration file. This feature, specific to SQL Server, allows developers to pass claims information to the database where objects can use them for custom logic—often for row-level security. This custom logic can generate internal predicates invisible to the Data API builder, making the caching key unreliable and possibly returning results inadvertently. Consequently, the system disables caching when it enables the session context.
{
...
"data-source": {
"database-type": "mssql",
"connection-string": ...,
"options": {
"set-session-context": false
}
},
}The system fully supports caching for tables and views, but support for stored procedures is forthcoming. Despite these caveats, caching is available to most Data API builder customers and in most currently deployed scenarios.
Caching benefits: relieves your database
Understanding that caching is more than just a way to budget resources is crucial. Yes, caching allows you to allocate spending toward lower-cost services in your solution. But it also offers an incredible way to scale. Developers often consider caching in terms of minutes, but let’s discuss caching for just a single second—that is, with a time-to-live value of one.
Time to live: one second
When several calls simultaneously hit your endpoint (presenting the same caching key), we refer to this burst of requests as a stampede. Practically speaking, Data API builder executes the first call against the database and makes the others wait. This approach means 100 simultaneous calls result in a single database query. To put it more dramatically, 1,000,000 simultaneous calls to your endpoint would result in just a single database query. Then, once the first call returns, the system returns the results for the rest.
After that, the system returns every call inside the time-to-live window instantly from memory, without involving the database. This improvement not only reduces response times from seconds to milliseconds but also frees your database to perform other operations or respond to other queries. You have scaled your endpoint to handle 10, even 100 times as many requests with a TTL value so low, most scenarios would not consider the results stale.
Consider these results:
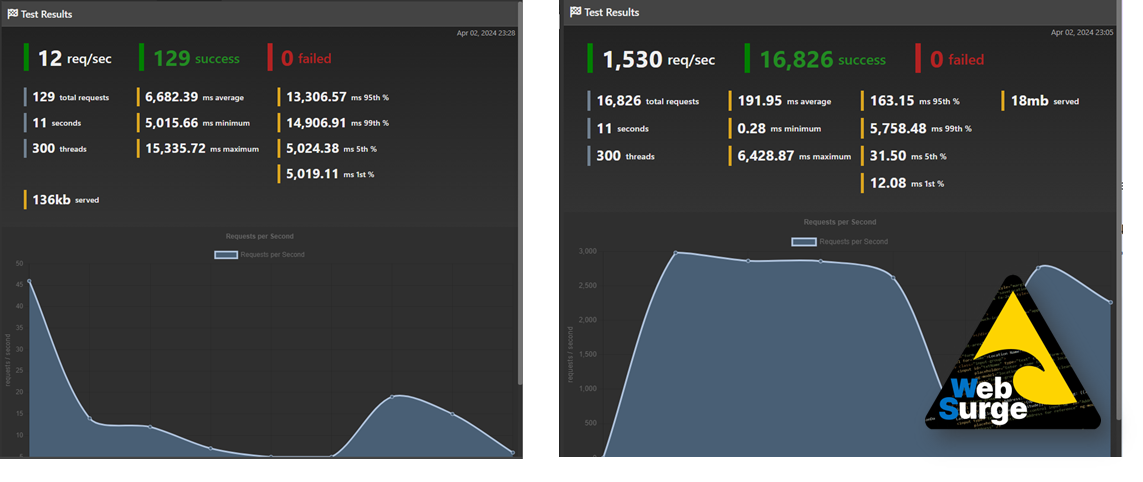
The left and right tests are identical in concurrency and duration. The test on the left sets a time-to-live of zero seconds, effectively turning caching off. The test on the right sets a time-to-live of just one second. The database query takes 5 seconds to execute. Look at the multiplier between the two scenarios even with such a tiny time-to-live. Caching works wonders and makes your database look like a champ. Data API builder can now relieve your database’s burden with the new caching feature available to REST endpoints.
We hope you love Data API builder. Our open-source repository on GitHub is a great place to view the code, report issues, and—importantly—sign up to be part of the Data API builder community. You can find the signup at the top of the repository’s readme file. We invite you to join our open-source team.
0 comments