

We’re excited to present the seventh edition of our blog series, dedicated to exploring design patterns in Azure Cosmos DB for NoSQL applications. Drawing from real-world customer experiences, our aim is to help you navigate the intricacies of JSON-based NoSQL databases. In this chapter, we delve deeper into prevalent NoSQL patterns, perfect for those new to this database type. We also focus on patterns specific to Azure Cosmos DB, demonstrating how to harness its distinct capabilities to tackle complex architectural issues.

These patterns, previously shared individually with customers, are now being made more widely accessible. We believe it’s the right moment to broadly publish these insights, enhancing their discoverability among users. Thus, we’ve created Azure Cosmos DB Design Patterns — a GitHub repository filled with an array of examples. These samples are meticulously curated to demonstrate the implementation of specific patterns, assisting you in addressing design challenges when utilizing Azure Cosmos DB in your projects.
To help share these, we have created a blog post series on each of them. Each post will focus on a specific design pattern with a corresponding sample application that is featured in this repository. We hope you enjoy it and find this series useful.
Here is a list of the previous posts in this series:
- Part 1: Attribute Array
- Part 2: Data Binning
- Part 3: Distributed counter
- Part 4: Global distributed lock
- Part 5: Document versioning
- Part 6: Event sourcing
Azure Cosmos DB design pattern: Materialized Views
The Materialized View pattern in NoSQL databases is a design approach that optimizes query performance by precomputing and storing the results of complex queries. This pattern is particularly effective when the data’s original format is not ideally structured for frequent query operations. By creating these precomputed views, the pattern aids in efficient data retrieval, especially for large datasets or where queries involve aggregations like sum, average, or count.
In practice, materialized views store only the necessary data required by specific queries, enabling applications to access information swiftly. These views are typically disposable and can be rebuilt from the source data, meaning they are not directly updated but refreshed or regenerated in response to changes in the source data. This approach can significantly reduce computational overhead during query execution, leading to faster responses and improved system performance.
Materialized views are beneficial in scenarios such as simplifying complex queries, improving query performance, and providing access to specific data subsets. They are also useful in bridging different data stores to leverage their individual capabilities. However, they might not be ideal in situations where source data changes rapidly or where high consistency between the view and the original data is required.
Overall, the Materialized View pattern is a strategic choice in NoSQL database design, enhancing data access efficiency and catering to specific querying needs while managing the trade-offs between data storage and retrieval.
The Scenario:
Materialized views are a useful way of improving query performance by precalculating and saving optimized data representations. This process involves creating derived tables that record and maintain the results of certain queries. By doing this, materialized views solve the problem of slower and less effective data retrieval.In practice, materialized views are used in different situations, each meeting different optimization needs:
- Views with Different Partition Keys: Materialized views can be tailored to accommodate diverse partition keys, allowing for more efficient organization and retrieval of data based on varying criteria. This capability is particularly beneficial in systems where data needs to be accessed and manipulated using multiple perspectives.
- Subsets of Data: When working with large datasets, it often makes sense to focus on specific subsets of information that are frequently queried. Materialized views can be employed to create summarized versions of these subsets, optimizing access to relevant data and minimizing the need for resource-intensive full-table scans.
- Aggregate Views: Analytical queries frequently involve aggregations, such as sum, average, or count, performed on certain data attributes. Materialized views can precompute these aggregations, enabling swift execution of analytical queries without the need to repeatedly process the raw data.
In essence, materialized views serve as a performance-enhancing layer that strikes a balance between data storage and retrieval efficiency. By precomputing and storing query results, these views significantly reduce the computational burden during query execution, leading to quicker responses and improved overall system responsiveness.
Sample Implementation:
Case Study: Implementation of materialized views for different partition keys
This section delves into the implementation of materialized views using the change feed in Azure Cosmos DB for NoSQL.
Consider Tailspin Toys, which utilizes Azure Cosmos DB for storing its sales data. The system writes incoming sales details to a container named “Sales,” partitioned by /CustomerId. To highlight currently popular products based on sales volume, querying a container partitioned by Product proves more efficient than querying by CustomerId. Here, the Azure Cosmos DB change feed plays a crucial role in creating a materialized view, significantly accelerating query performance over the course of a year.
The architecture involves a single Azure Cosmos DB account encompassing two distinct containers. The primary container, “Sales,” holds the core sales data. To align with Tailspin Toys’ objective of displaying popular products, a secondary container, “SalesByProduct,” organizes sales data by product. This setup not only meets the company’s specific requirements but also optimizes data retrieval for enhanced user experience.
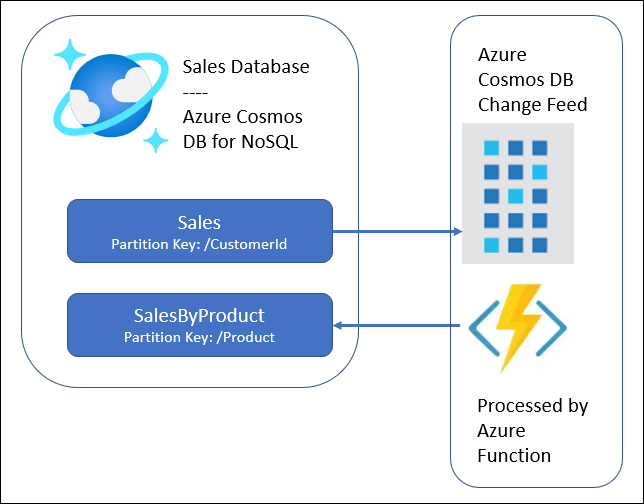
When implementing the materialized view pattern, there is a container for each materialized view.
Why would you want to create two containers? Why does the partition key matter? Consider the following query to get the sum of quantities sold for a particular product:
SELECT c.Product, SUM(c.Qty) as NumberSold FROM c WHERE c.Product = "Widget" GROUP BY c.ProductTo run this query for the Sales container – the container that holds the source data, Azure Cosmos DB will examine the WHERE clause and try to find the partitions that have the data that matches the WHERE clause. When the WHERE clause does not have the partition key, Azure Cosmos DB will query every partition. For this query, any customer could have widget sales, so Azure Cosmos DB will query all partitions of customers for widget sales.
![]()
However, when running the query to get the totals for a product in the SalesByProduct container, Azure Cosmos DB will only need to query one partition – the partition that holds the data for the product in the WHERE clause.
![]()
In the demo, you may not see the performance implications with smaller sets of data – smaller in terms of the amount of data overall as well as diversity in the CustomerId column. However, when your data grows beyond 50 GB in storage or throughput of 10000 RU/s, you will see the performance implications at scale.
Note: If you are running into aggregation analysis at scale, the materialized views would not be advised. For large-scale analysis, consider Azure Cosmos DB analytical store and Azure Synapse Link for Azure Cosmos DB.
Why it Matters.
Using materialized views is significant for several key reasons, especially in the context of database management and query optimization:
- Improved Query Performance: Materialized views store precomputed data based on the original database. This means that instead of running complex joins, aggregations, or calculations every time a query is executed, the query can directly access the precomputed results from the materialized view. This drastically reduces the time taken to return results, especially for frequently executed and complex queries.
- Efficient Data Management: In scenarios where data needs to be presented in a format different from its storage format, like in the Tailspin Toys example where sales data needed to be viewed by product rather than by customer, materialized views make this transition smooth and efficient.
- Load Reduction on Original Data Sources: Since materialized views handle a significant portion of read load, especially for complex queries, they reduce the burden on the original data sources. This can be particularly beneficial for systems where the operational data store needs to maintain high transactional performance.
- Data Consistency and Accuracy: Materialized views can be set up to refresh at specific intervals, ensuring that the data they contain is consistently up-to-date with the base tables. This ensures that users are accessing the most current data available, without the need to directly query the operational database.
- Scalability and Performance at Scale: For large-scale applications, such as in databases exceeding 50 GB or with high throughput, the performance improvement gained from using materialized views becomes even more pronounced. They can efficiently handle large datasets and high query loads, which might otherwise slow down a traditional database system.
- Simplified Query Logic: Materialized views can simplify the logic of the application layer. Developers and analysts can write simpler queries against a materialized view, as it can encapsulate the complexity of the data transformation required.
In summary, materialized views matter because they offer a powerful tool for enhancing data retrieval performance, reducing load on primary data stores, ensuring data consistency, and simplifying query complexity, all of which are crucial for efficient and effective data management.
Getting Started with Azure Cosmos DB Design Patterns
You can review the sample code by visiting the Materialized Views design pattern on GitHub. You can also try this out for yourself by visiting the Azure Cosmos DB Design Patterns GitHub repo and cloning or forking it. Then run locally or from Code Spaces in GitHub. If you are new to Azure Cosmos DB, we have you covered with a free Azure Cosmos DB account for 30 days, no credit card needed. If you want more time, you can extend the free period. You can even upgrade too.
Sign up for your free Azure Cosmos DB account at aka.ms/trycosmosdb.
Explore this and the other design patterns and see how Azure Cosmos DB can enhance your application development and data modeling efforts. Whether you’re an experienced developer or just getting started, the free trial allows you to discover the benefits firsthand.
To get started with Azure Cosmos DB Design Patterns, follow these steps:
- Visit the GitHub repository and explore the various design patterns and best practices provided.
- Clone or download the repository to access the sample code and documentation.
- Review the README files and documentation for each design pattern to understand when and how to apply them to your Azure Cosmos DB projects.
- Experiment with the sample code and adapt it to your specific use cases.
About Azure Cosmos DB
Azure Cosmos DB is a fully managed and serverless distributed database for modern app development, with SLA-backed speed and availability, automatic and instant scalability, and support for open-source PostgreSQL, MongoDB, and Apache Cassandra. Try Azure Cosmos DB for free here. To stay in the loop on Azure Cosmos DB updates, follow us on Twitter, YouTube, and LinkedIn.
0 comments