

Have you heard about the Seasons of Serverless challenge? Join the festive virtual potluck by creating solutions to challenges leveraging Azure serverless computing. Throughout the next seven weeks we’ll be sharing a solution to the week’s challenge that integrates Azure SQL Database serverless with Azure serverless compute.
Challenge 1: The Perfect Holiday Turkey 🦃
The first week features the North America tradition of cooking a turkey. The challenge calls for converting a brine recipe based on the input weight of a turkey and recommends leveraging an Azure Function to generate the recipe. Below is a high level view of the solution we created, utilizing an Azure Function and Azure SQL Database serverless. The completed example can be found on GitHub.

Creating an Azure Function in VS Code
Using the VS Code Azure Functions extension and the “Azure Functions: Create New Project” command, we’re creating a new Azure Function locally in VS Code in Python with the HTTP trigger template. This function will receive HTTP GET requests with a turkey size in pounds (lbs) through a query string parameter. The body of the function is defined in the main(req: func.HttpRequest) function in the file __init__.py. Dependencies for our function that need to be installed to run the function are detailed in the file requirements.txt, where we want to begin by adding a line for pyodbc. pyodbc is an open-source module for Python that enables connecting to ODBC databases, including Azure SQL and Microsoft SQL Server.
 Our Python function will utilize 3 internal functions, getSqlConnection, getIngredients, and generateHttpResponse. The first, getSqlConnection, implements the initial connection of the pyodbc driver to our database based on the connection string retrieved from the application settings. Since we are implementing our project on the serverless tier of Azure SQL database, we need our function to be able to gracefully handle instances when our database has autopaused. Login events are one of the events that trigger autoresume, so our function needs to try the pyodbc.connect() call again if a database connection error is encountered.
Our Python function will utilize 3 internal functions, getSqlConnection, getIngredients, and generateHttpResponse. The first, getSqlConnection, implements the initial connection of the pyodbc driver to our database based on the connection string retrieved from the application settings. Since we are implementing our project on the serverless tier of Azure SQL database, we need our function to be able to gracefully handle instances when our database has autopaused. Login events are one of the events that trigger autoresume, so our function needs to try the pyodbc.connect() call again if a database connection error is encountered.
def getSqlConnection(sqlConnectionString):
i = 0
while i < 6:
logging.info('contacting DB')
try:
sqlConnection = pyodbc.connect(sqlConnectionString)
except pyodbc.DatabaseError:
time.sleep(10) # wait 10s before retry
i+=1
else:
return sqlConnection
Once the database has successfully connected, we will ask the database to send us back the ingredients. One of the many developer-friendly features of Azure SQL is how quickly it can create JSON in query results, so we have quick work of implementing handling our database results:
def getIngredients(sqlConnection, turkeySize):
logging.info('getting ingredients')
results = []
sqlCursor = sqlConnection.cursor()
sqlCursor.execute('EXEC calculateRecipe '+str(turkeySize))
results = json.loads(sqlCursor.fetchone()[0])
sqlCursor.close()
return results
The full code for the Azure Function __init__.py is available here.
Creating and Building the Azure SQL Database
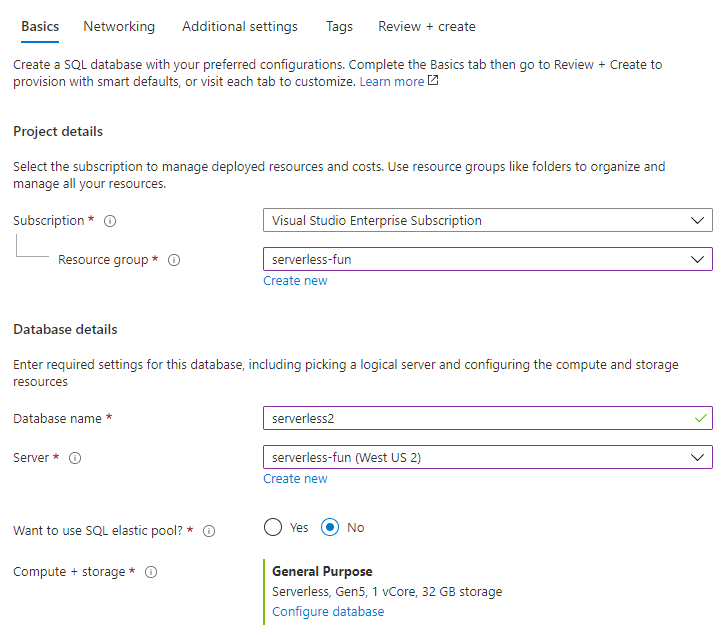 Azure SQL database serverless is a compute tier for SQL databases that automatically pauses and scales based on the current workload. Similar to Azure Functions, not only does Azure SQL database serverless have the capability to automatically scale with your workload, but you can build your solution locally once and deploy it to one or more instances.
Azure SQL database serverless is a compute tier for SQL databases that automatically pauses and scales based on the current workload. Similar to Azure Functions, not only does Azure SQL database serverless have the capability to automatically scale with your workload, but you can build your solution locally once and deploy it to one or more instances.
Starting from the Create SQL Database pane in the Azure Portal, we provide a new database name and can leverage an existing or new server. The option to configure Compute + storage should be adjusted to select the Serverless compute tier. When using another Azure resource with an Azure SQL database, such as Azure Functions, it is important to permit network access between them. This option is commonly referred to as “Allow Azure services and resources to access this server” and is set at the server level.
SQL Database Projects in Azure Data Studio
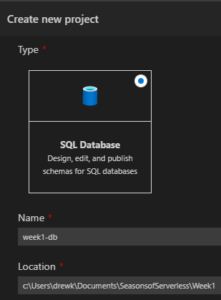
After provisioning a serverless tier Azure SQL database through the Azure Portal, we start by creating the database structures in Azure Data Studio with the SQL Database projects extension. To begin, we create a new database project in Azure Data Studio. The database schema we’ve designed is relatively simple, we need a table to store the ingredients for the given recipe and a stored procedure to return the recipe scaled based on an input turkey size. We create these objects in the database project by right-clicking the project or desired folder in the project and selecting “Add Table” and “Add Stored Procedure”.
CREATE TABLE [dbo].[Ingredients] ( IngredientName NVARCHAR(200) NOT NULL PRIMARY KEY, UnitofMeasure NVARCHAR(20) NOT NULL, RatioToTurkeyLBs DECIMAL(10,4) NOT NULL ); GO
As previously mentioned, we want our stored procedure to return JSON to the Azure Function. No problem! Using FOR JSON PATH in our stored procedure query bundles the rows into a JSON array.

CREATE PROCEDURE [dbo].[calculateRecipe] @turkeySize DECIMAL(10,5) AS BEGIN SELECT IngredientName, UnitofMeasure, cast(round((RatioToTurkeyLBs*@turkeySize),2) as decimal(6,2)) AS IngredientAmount FROM Ingredients FOR JSON PATH END
After adding both of these objects, we’re well on our way to creating our serverless database! We do have 1 more thing to add to our database project – the recipe. By adding a “Post-Deployment Script” to our project, we’re adding some T-SQL that will execute after the project has published to the database. We can add a script that inserts the values for the ingredients to the Ingredients table.
DELETE FROM INGREDIENTS;
GO
INSERT INTO INGREDIENTS (INGREDIENTNAME, UNITOFMEASURE, RATIOTOTURKEYLBS)
VALUES ('Salt', 'cups', 0.05), ('Water', 'gal', 0.66),
('Brown sugar', 'cups', 0.13), ('Shallots', 'each', 0.2),
('Garlic', 'cloves', 0.4), ('Whole peppercorns','tbsp', 0.13),
('Dried juniper berries', 'tbsp', 0.13), ('Fresh rosemary','tbsp', 0.13),
('Thyme', 'tbsp', 0.06), ('Brine time','hours', 2.4),
('Roast time','minutes', 15);
GO
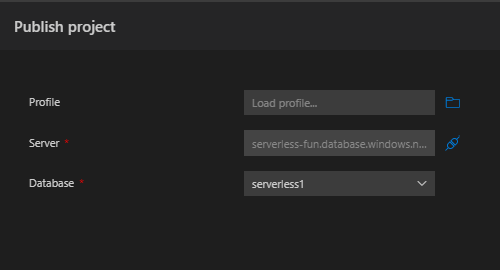 To deploy these objects to our Azure SQL database, we will build and publish the project to the serverless tier database we created in Azure. Right-clicking on the database project in Azure Data Studio After publishing the project from Azure Data Studio to the Azure SQL database, the database is all set! You might have noticed some new files in the folder under bin\Debug are created during project build. The .dacpac file is a data-tier application, a file that contains the database objects we created and can be published one or many times. In future challenges we will dig into how to leverage automation to deploy our database solutions as we will do for the Azure Function below.
To deploy these objects to our Azure SQL database, we will build and publish the project to the serverless tier database we created in Azure. Right-clicking on the database project in Azure Data Studio After publishing the project from Azure Data Studio to the Azure SQL database, the database is all set! You might have noticed some new files in the folder under bin\Debug are created during project build. The .dacpac file is a data-tier application, a file that contains the database objects we created and can be published one or many times. In future challenges we will dig into how to leverage automation to deploy our database solutions as we will do for the Azure Function below.
Deploying the Azure Function
The Azure Function that we created earlier in this post in the local VS Code environment can be deployed to Azure directly from our GitHub repository. This will enable continuous deployments to Azure from our future code changes. We will create an Azure Function App in the Portal to publish our code to on the Python runtime stack, and once it is created we need to download the publish profile from the overview page. Treat the publish profile like a password – it allows privileged access to manage the function and we’re going to use it to allow GitHub to publish our code as a function.
Before we leave the Function App in the Azure Portal, we should add the Azure SQL serverless connection string to the Application settings such that the function can access it through an environment variable. In a Python Azure Function this is written os.environ[“serverlessdb”] for the application setting named “serverlessdb”. The full connection string for the value is in the format:
DRIVER={ODBC Driver 17 for SQL Server};SERVER=yourservernamehere.database.windows.net;PORT=1433;DATABASE=yourdatabasenamehere;UID=sqladmin;PWD=yourpasswordhere
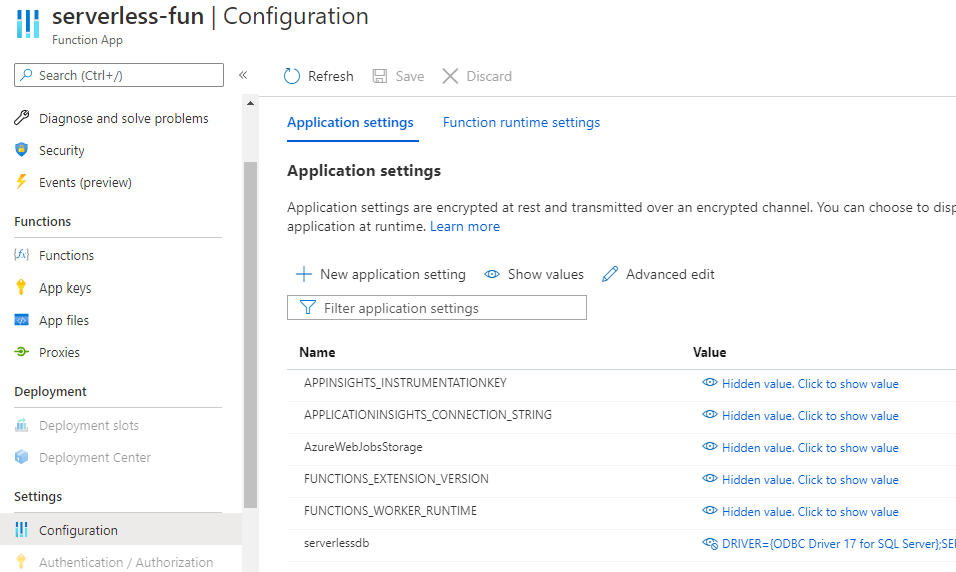
This method stores the password for a database user in clear text and it is visible to anyone with access to this pane in the Azure Portal. You are encouraged to consider additional security in full scale implementations, such as Azure Key Vault or utilizing limited permission SQL users (seen in the sample).
Want to test your Azure Function locally? Place the same application setting for the database connection string in the local.settings.json file under “Values”.
GitHub Action
We need to add the contents of the publish profile to our GitHub repository as a secret (under Settings>Secrets) for AZURE_FUNCTIONAPP_PUBLISH_PROFILE. This value can now be used in GitHub actions to access the Azure Function App. The Azure Functions action handles the deployment for us and even provides samples for several runtimes, including Python. To leverage their sample, add the code to the .github/workflows folder in your project and update the env variables at the top of the script. In our instance, it’s in a file named main.yml. The action leverages a cloud environment to:
- remotely checkout (grab) your code
- setup a Python environment and install dependencies (remember the requirements.txt file?)
- deploy the environment to your Azure Function
You can track the progress of the deployment after you push code under the Actions tab in the GitHub repo.
Wrapping Up
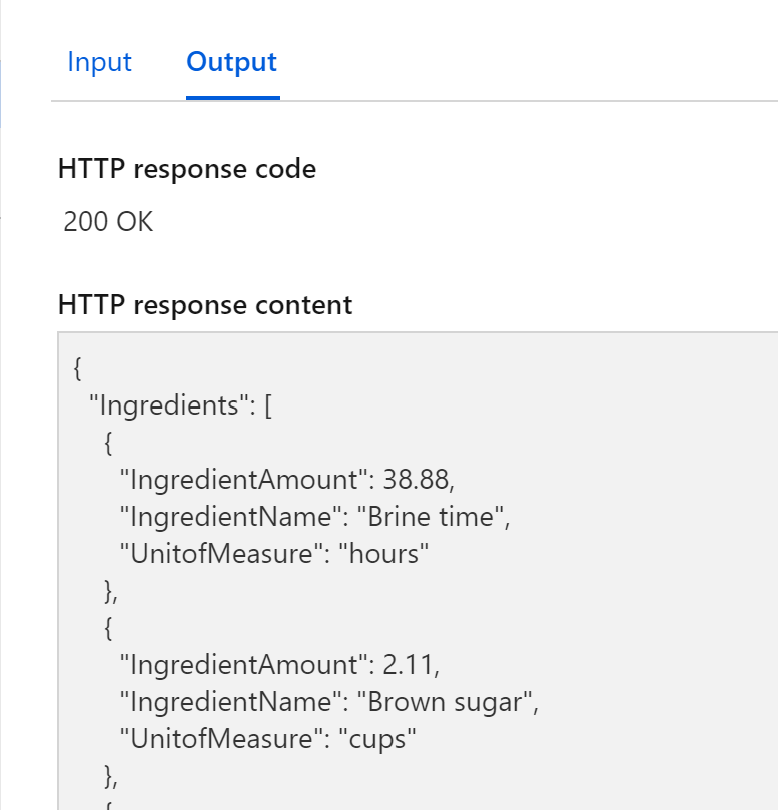 Once the Azure Function code has deployed to Azure, we are able to test the Function in the Azure Portal or via a REST client such as Postman. If there’s a change in the recipe, the database can be updated to return different ingredients or amounts. Since both our compute and database are serverless, our costs are minimized when there is no workload. For the database, we are only charged for storage when the database is paused. Next time you need a database for your serverless architecture, consider Azure SQL database serverless. See you next week for our solution to Challenge 2: Lovely Ladoos!
Once the Azure Function code has deployed to Azure, we are able to test the Function in the Azure Portal or via a REST client such as Postman. If there’s a change in the recipe, the database can be updated to return different ingredients or amounts. Since both our compute and database are serverless, our costs are minimized when there is no workload. For the database, we are only charged for storage when the database is paused. Next time you need a database for your serverless architecture, consider Azure SQL database serverless. See you next week for our solution to Challenge 2: Lovely Ladoos!
0 comments