
Mark Taylor, Premier Services Senior Consultant and David S. Lipien, Director in Microsoft’s Premier Services present a 3 part installment on the internet of things (IoT). For this third and final part, we also strongly collaborated with Carroll Moon a Microsoft Senior Service Management Architect for Cloud.
Part 1 of the IoT series was a primer on the subject matter, looking at it from a business value perspective and looking at of some the important questions that should be considered when evaluating or diving into the space.
Part 2 of the series, we looked at a particularly hot topic these days, security and IoT.
A December 2014 Harvard Business Review article “Who Provides Tech Support for the Internet of Things?[1]” summarized it best:
“Which companies will be the first to remove their blinders and start thinking – and acting – beyond their own brands and their traditional scopes of service to help consumers experience the control, simplicity, and convenience the IoT has to offer?”
The need for monitoring applications is pretty clear – and it becomes even clearer for large cloud implementations:
- Problems will happen, but you don’t want your customers to be informing you of an outage.
- Redundancies and retry logic become critical
- When problems are found, you need to make sure you have the information needed to solve them in a timely fashion.
This thinking needs to start from the earliest phases of solution design. Looking at this from the perspective of the architect, a good methodology is to ask questions like:
- What are the services I am creating?
- What are the real world capabilities that these services provide?
- How can I know that these capabilities are healthy?
- How can I be notified ASAP if they are not?
- Am I capturing the data needed to root cause and fix issues?
Iterating over these questions from the planning stage through development and deployment helps to ensure focus on the priorities, making sure that the capabilities representing the core value of the solution remain healthy.
Starting this process as early as possible is even more critical with IoT solutions as these can include hardware/device development. This development has to start earlier, and often cannot be changed without massive project disruption. This can be problematic if you find that critical data or metrics are needed from the device in order to identify root cause issues.
The above is a high level description of a process which produces a health model of your solution. This should inform you about monitoring priorities, what metrics to monitor, et cetera. In other words, how to instrument your application. For that instrumentation to be useful, it needs to be surfaced so that it can be acted on by people who may be in various roles across the organization. This implies several requirements:
- People need to be alerted to issues in a timely and reliable way.
- People need capable monitoring tools to surface information in a way that fits into their workflow (for example integration with existing service desk and incident management).
- People need analysis tools that are tuned to their operational telemetry data for reporting.
To meet these requirements, development and operations teams will need to work together. There are potentially important changes focused on process and roles that will need to occur that are common to any shift to the cloud. The role of operations changes from one that controls infrastructure and tasks such as building out machines, to a strategic role responsible for alerting and monitoring capabilities provided to multiple application teams, and integration with existing incident management processes.[2] One way to envision this is as a shift from a resource management capability to a service provider or hub and spoke model.
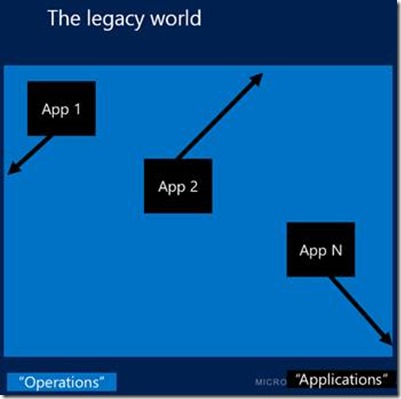
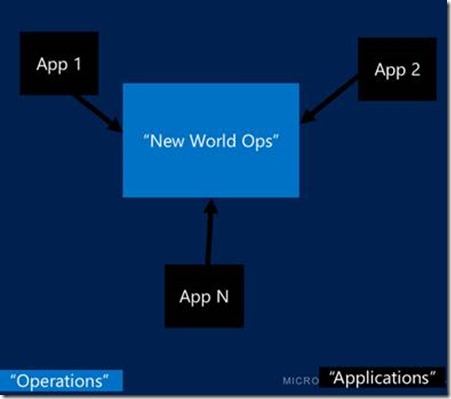
Because every application development team will not want to duplicate and manage all of this monitoring and alerting functionality, the services of the operations teams will be critical to their success.
Tom Bittman of Gartner indicated that 31% of clouds implementations were failing due to: “Failure to change the operational model: Agile clouds need agile processes — and people are your biggest supporters, or your biggest roadblocks.”[3]
Supportability is another major concern for IoT implementations, and one that is often overlooked until it is too late to fix without major expense/delays. An IoT solution consist of a large number of technologies, many with SLAs or support standards that span different companies.
The Harvard Business Review article takes about the challenge and opportunities for IoT business and the continuous service experience.
“The necessary cross-brand integration presents both a huge challenge and a significant opportunity for companies in the IoT business. Tech support is no longer about individual manufacturers, retailers, telcos, and internet service providers’ product sets; it’s about a continuous service experience of the full connected environment to deliver on consumer expectations, while adding customer value to drive loyalty”
It is important to be aware of and plan for supportability across the solution from the earliest planning phase. If vendor A provides the device hardware, vendor B provides support for the device OS, and vendor C supplies the agent and the cloud infrastructure, what is the path of incident resolution across all of these? Are there components (e.g., open source software) for which there is no outside support available? Mapping out the organizations that support various components, and thinking through the relationships between these organizations in the context of potential failures is critical.
Realizing these technical and organizational changes can be a long and challenging process, obviously this article has just scratched the surface. Some of the challenges in this area are specific to IoT, and some are critical to successfully operating any cloud based solution. Microsoft Premier Support has experts who can help your organization make the technical and people/process transitions described above, to help enable the success of your IoT solution. Contact your Microsoft Application Development Manager if you would like more information.
[1] https://hbr.org/2014/12/who-provides-tech-support-for-the-internet-of-things
[2] For more information, please see Carroll Moon’s excellent series of blog articles on the topic.
[3] http://blogs.gartner.com/thomas_bittman/2015/02/05/why-are-95-of-private-clouds-failing/
0 comments