


This is the official release of D3D12 Work Graphs, enabling new types of GPU autonomy, originally available as a preview in 2023.
To start, here’s what Epic sees:
With the proliferation of GPU-driven rendering techniques – such as Nanite in Unreal Engine 5 – the role of the CPU is trending towards primarily resource management and hazard tracking, with only a fraction of time spent generating GPU commands. Prior to D3D12 Work Graphs, it was difficult to perform fine-grained memory management on the GPU, which meant it was practically impossible to support algorithms with dynamic work expansion. Even simple long chains of sequential compute work could result in a significant synchronization and memory overhead.
GPU-driven rendering was accomplished by the CPU having to guess what temporary allocations were needed by the GPU, often over-allocating to the worst case, and using previous frame readback for refinement. Any workloads with dynamic expansion either meant issuing worst case dispatches from the CPU, having the GPU early out of unnecessary work, or non-portable techniques were used, like persistent threads.
With Work Graphs, complex pipelines that are highly variable in terms of overall “shape” can now run efficiently on the GPU, with the scheduler taking care of synchronization and data flow. This is especially important for producer-consumer pipelines, which are very common in rendering algorithms. The programming model also becomes significantly simpler for developers, as complex resource and barrier management code is moved from the application into the Work Graph runtime.
We have been advocating for something like this for a number of years, and it is very exciting to finally see the release of Work Graphs.
— Graham Wihlidal, Engineering Fellow, Graphics, Epic Games
GPU vendor Work Graph blogs:
Development links:
- Full Work Graphs spec, the blog below is a quicker intro.
- Start now on AMD and NVIDIA GPUs
- Samples
- Use PIX with Work Graphs
The content below is similar to the 2023 preview blog, mostly a refresh. See Notable changes since 2023 preview below.
Contents
- Introduction to work graphs
- Specification <—— the docs
- Node types
- Other features
- Condensed programming guide
- Drivers and other prerequisites <—— get running on AMD and NVIDIA
- Authoring shaders
- Creating a work graph on a device
- Dispatching a work graph in a commandlist
- Samples
- PIX
- Notable changes since 2023 preview
Introduction to work graphs
Work graphs are a system for GPU autonomy in D3D12. Given the increasing prevalence of general compute workloads on GPUs, the motivation is to address some limitations in their programming model, unlock latent GPU capabilities, and enable future evolution.
Basis
In many GPU workoads, an initial calculation on the GPU determines what subsequent work the GPU needs to do. This can be accomplished with a round trip back to the CPU to issue the new work. But it is typically better for the GPU to be able to feed itself directly. ExecuteIndirect in D3D12 is a form of this, where the app uses the GPU to record a very constrained command buffer that needs to be serially processed on the GPU to issue new work.
Consider a new option. Suppose shader threads running on the GPU (producers) can request other work to run (consumers). Consumers can be producers as well. The system can schedule the requested work as soon as the GPU has capacity to run it. The app can also let the system manage memory for the data flowing between tasks.
This is work graphs. A graph of nodes where shader code at each node can request invocations of other nodes, without waiting for them to launch. Work graphs capture the user’s algorithmic intent and overall structure, without burdening the developer to know too much about the specific hardware it will run on. The asynchronous nature maximizes the freedom for the system to decide how best to execute the work.
Here is a graph contrived to illustrate several capabilities (click to zoom):
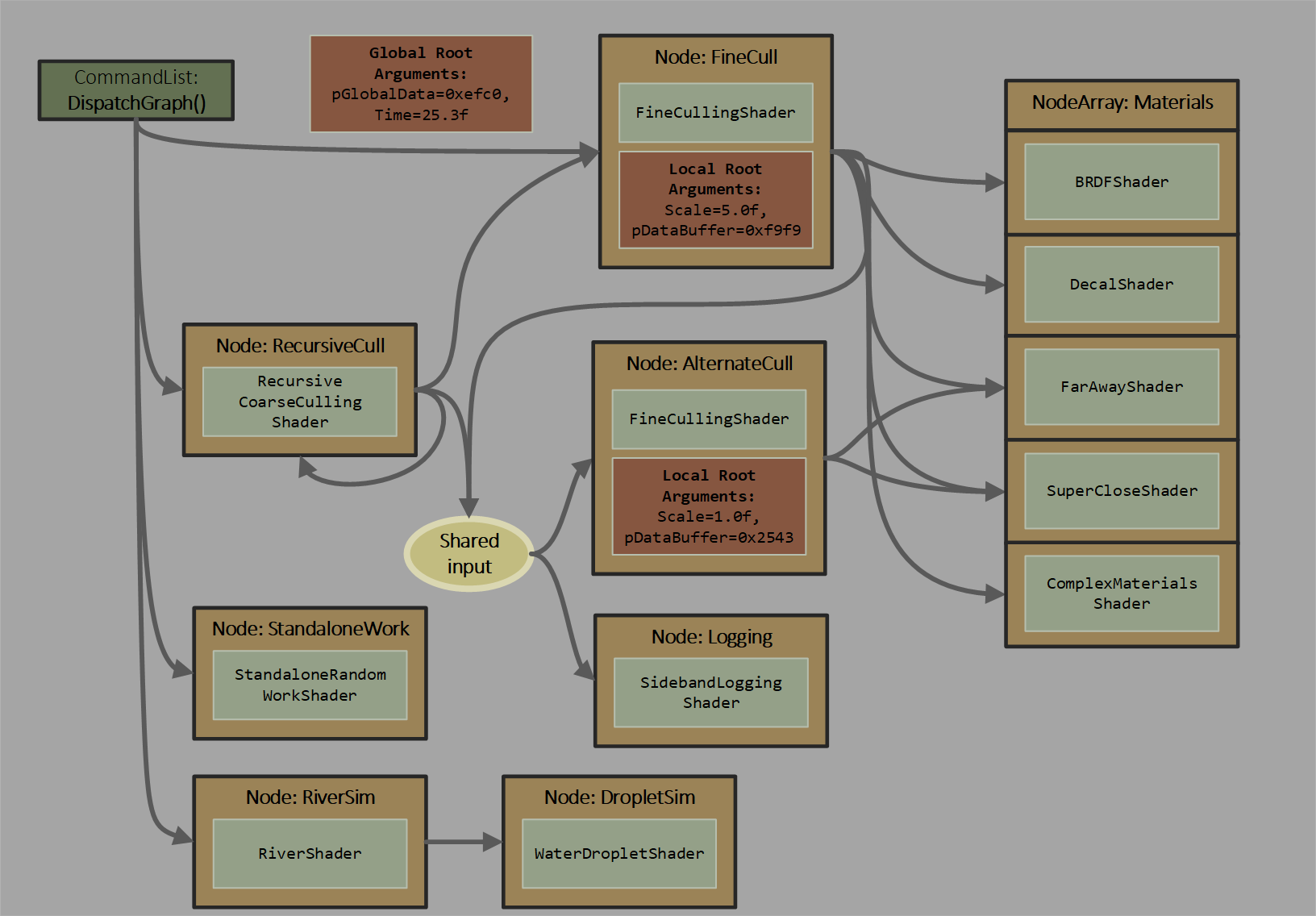
Characteristics
- When initiating work with
DispatchGraph(), the app can pass arguments to graph entrypoints from either app CPU memory copied into a command list’s recording, or app GPU memory read at command list execution. These options are convenient even with a single node graph. Traditional compute shaders can only get input data from D3D12 root bindings or by manually reading memory as a function of various ID system values.
- There are a few options for how a node translates incoming work requests into a set of shader invocations, ranging from a single thread per work item to variable sized grids of thread groups per work item.
- The graph is acyclic, with one exception: a node can output to itself. There is a depth limit of 32 including recursion.
- For implementation efficiency there are limits on the amount of data that node invocations can pass directly to other nodes; for bulk data transfer apps need to use UAV accesses.
- Scheduling of work requests can be done by the system with whatever underlying hardware tools are at its disposal.
- Less capable architectures might revert to a single processor on the GPU scheduling work requests. More advanced architectures might use distributed scheduling techniques and account for the specific topology of processing resources on the GPU to efficiently manage many work requests being generated in parallel.
- This is in contrast to the ExecuteIndirect model which forces a serial processing step for the GPU – walking through a GPU generated command list to determine a sequence of commands to issue.
- Data from a producer might be more likely to flow to a consumer directly, staying within caches
- This could reduce reliance on off-chip memory bandwidth for performance scaling
- Because data can flow between small tasks in a fine-grained way, the programming model doesn’t force the application to drain the GPU of work between data processing steps.
- Since the system handles buffering of data passed between producers and consumers (if the app wants), the programming model can be simpler than ExecuteIndirect.
Analysis
Despite the potential advantages, the free scheduling model may not always the best target for an app’s workload. Characteristics of the task, such as how it interacts with memory/caches, or the sophistication of hardware over time, may dictate whether some existing approach is better. Like continuing to use `ExecuteIndirect`. Or building producer consumer systems out of relatively long running compute shader threads that cross communicate – clever and fragile. Or using the paradigms in the DirectX Raytracing model, involving shaders splitting up and continuing later. Work graphs are a new tool in the toolbox.
Given that the model is about producers requesting for consumers to run, currently there isn’t an explicit notion of waiting before launching a node. For instance, waiting for all work at multiple producer nodes to finish before a consumer launches. This can technically be accomplished by breaking up a graph, or with clever shader logic. Synchronization wasn’t a focus for the initial design, hence these workarounds, discussed more in the spec: Joins – synchronizing within the graph. Native synchronization support may be defined in the future and would be better than the workarounds in lots of ways. Many other compute frameworks explicitly use a graph to define bulk dependencies, in contrast to the feed-forward model here.
Scenarios summary
- Reducing number of passes out to memory and GPU idling in multi-pass compute algorithms
- Avoiding the pattern in ExecuteIndirect of serial processing through worst case sized buffers
- Classification and binning via node arrays
- Future potential:
- Feeding graphics from compute
- Bulk work synchronization
Specification
The spec begins with the same introduction as above.
For a much shorter read than the rest of the full spec, the following sections skim through basic concepts with a small programming guide.
Node types
Here is a summary of the currently defined node types, defined fully in the spec. They are variations on compute shaders, distinguished by how node inputs translate to a grouping of threads to launch.
Broadcasting launch
This is like a traditional compute shader, with fixed size thread groups invoked over a dispatch grid. The dispatch grid size can be fixed for a node or dynamic (part of the input record). “Broadcasting” denotes that the input record is visible to all launched threads.
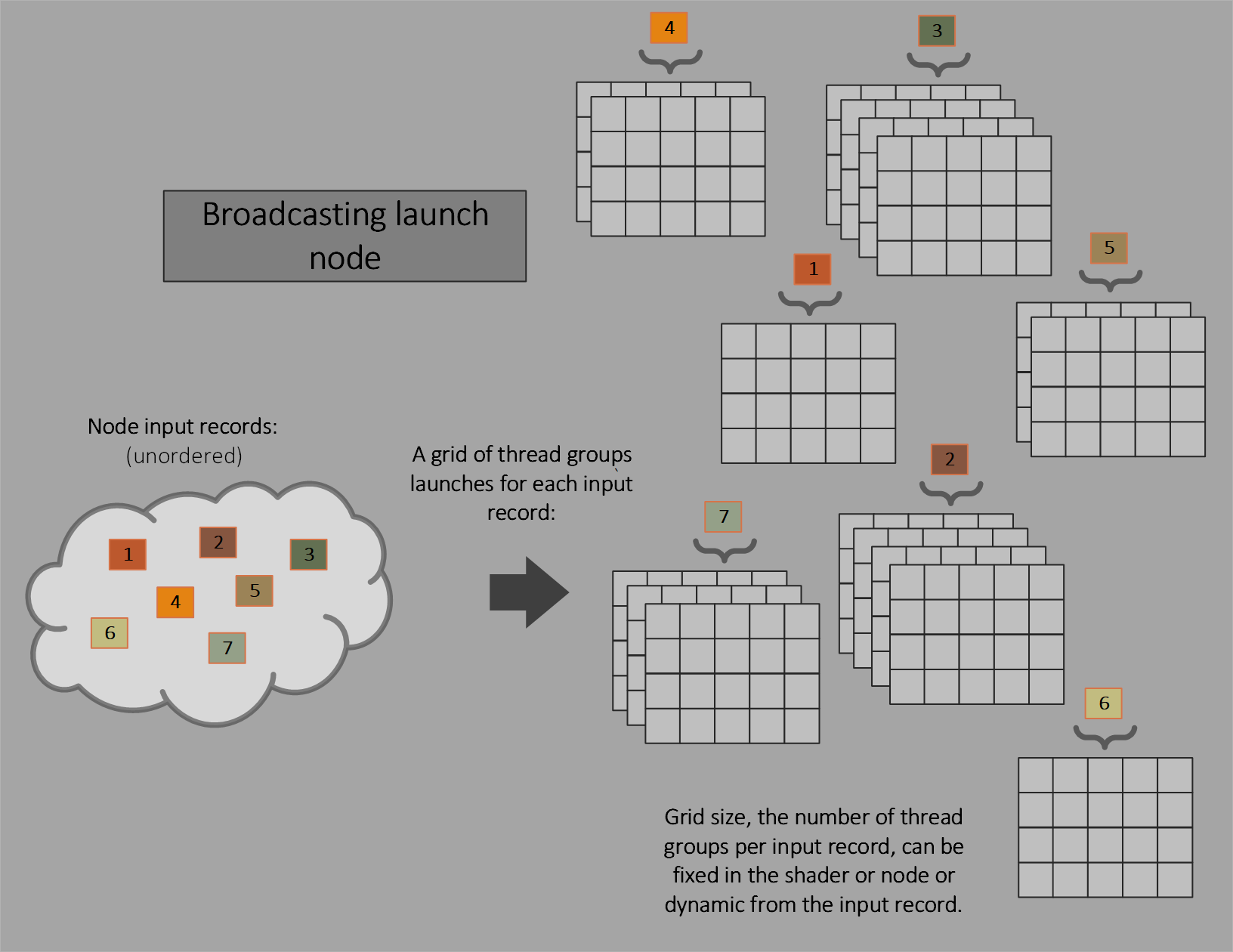
Coalescing launch
Multiple input records per individual thread group launch, with no dispatch grid. The shader declares a fixed thread group size and the maximum number of input records a thread group can handle. The hardware will attempt to fill that quota with each thread group launch, with freedom to launch with as few as one record if it wants or has no choice.
This node type is useful only if the shader can do some sharing of work across the set of input records, such as using thread group shared memory, knowing the declared maximum number of records per thread group is not guaranteed to be filled. If records will just be processed individually per thread, thread launch nodes are more appropriate.
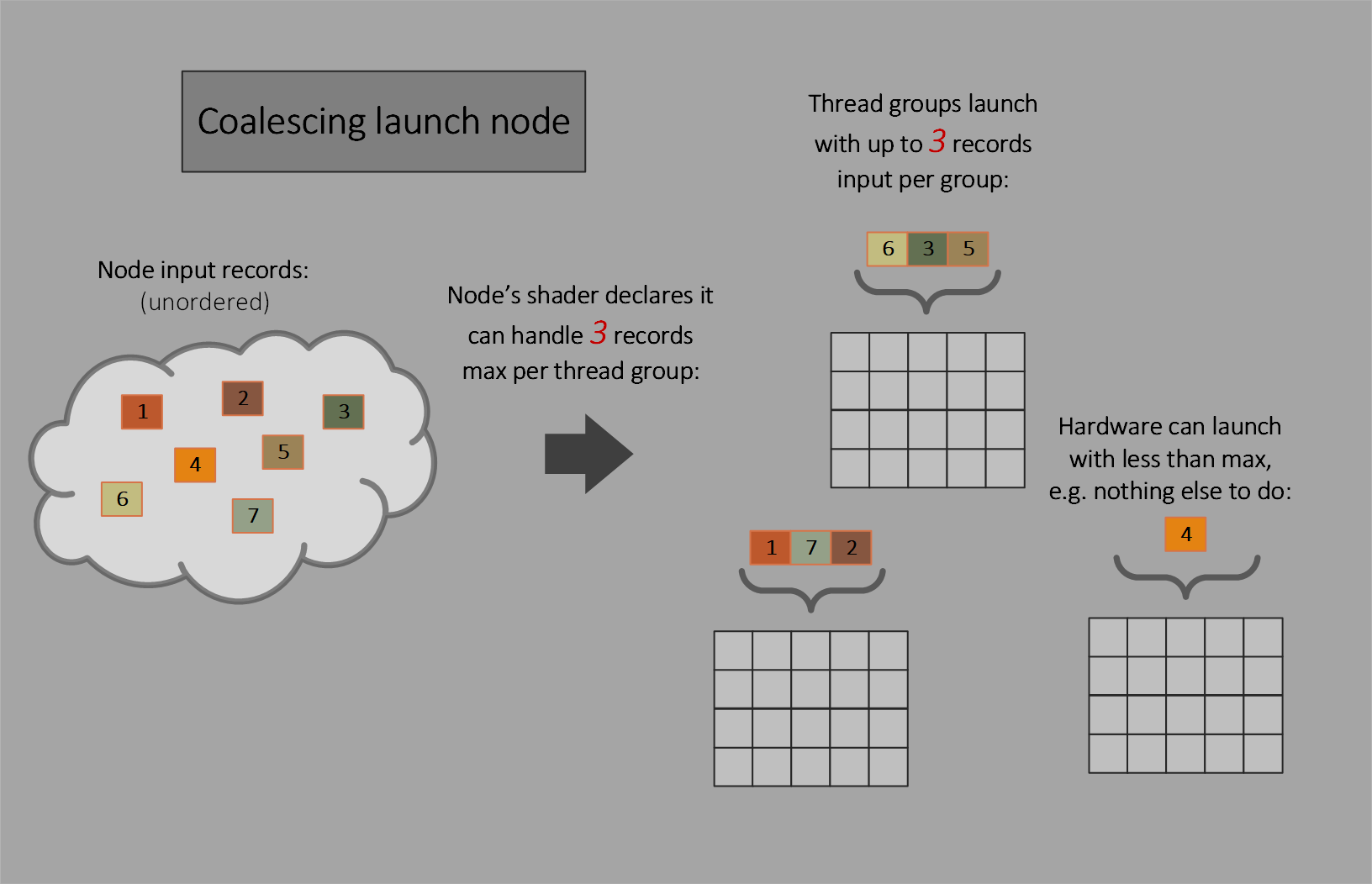
Thread launch
Thread launch nodes invoke one thread for each input.
Thread launch nodes are conceptually a subset of coalescing launch nodes. They use a thread group size of (1,1,1), so the thread group size need not be declared, and limit the number of input records per thread group launch to 1. Thread launch nodes can pack work fundamentally differently than coalescing or broadcasting launch nodes: thread launch nodes allow multiple threads from different launches to be packed into a wave (e.g. visible to wave operations).
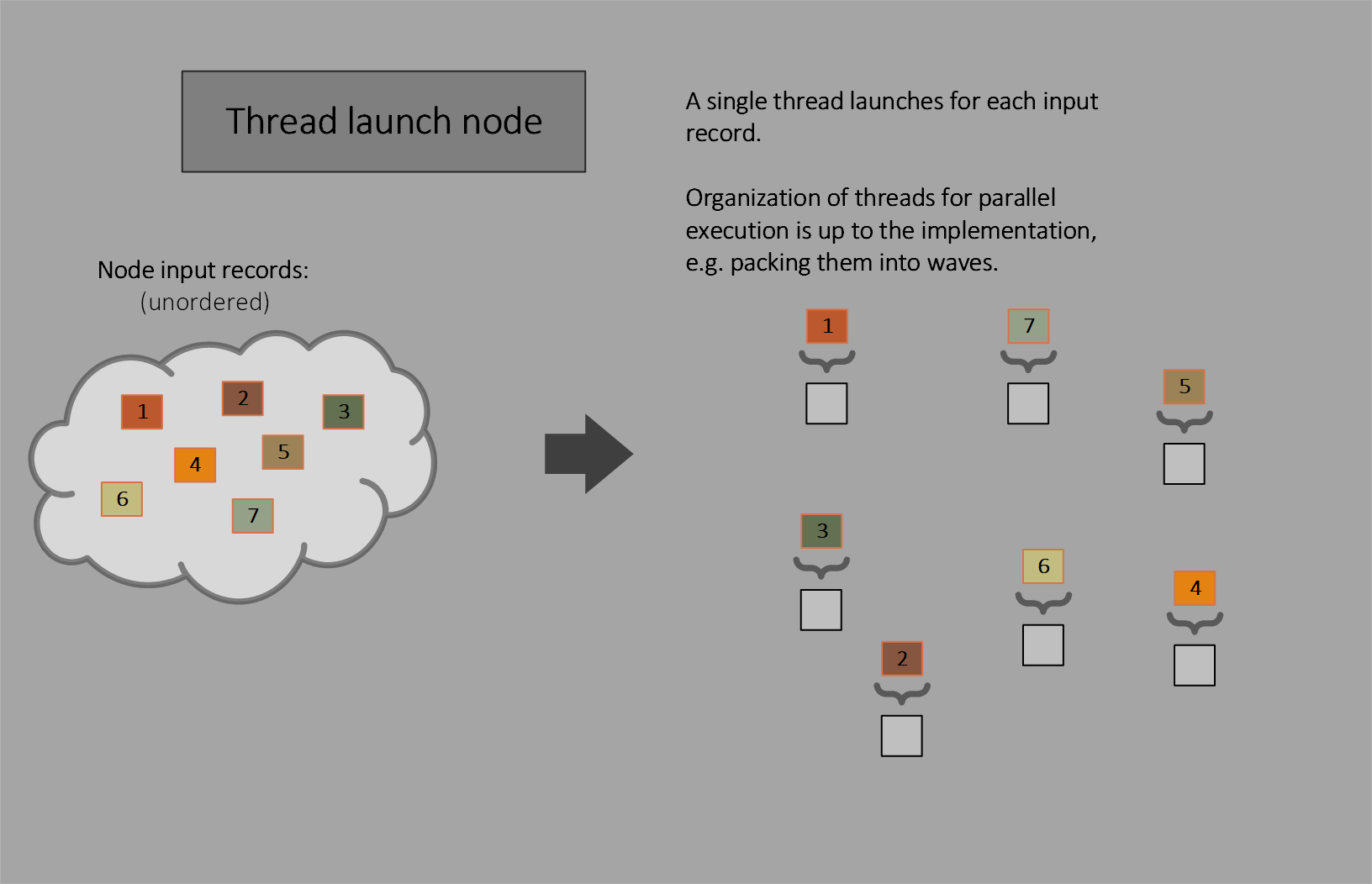
Other features
Here are a couple of other features that come along with the presence of work graphs:
Adding nodes to existing work graphs
AddToStateObject() existed in D3D for raytracing and now supports work graphs. This allows quite flexible types of additions to work graphs: nodes, graphs of nodes, new entrypoints to new graphs etc. This enables scenarios like adding new material nodes to a sparse material node array.
New way to define graphics and compute pipelines
Generic programs: In parallel to work graphs support, devices that support shader model 6.8 support generic programs in state objects. A generic program is the equivalent of existing pipeline state objects (PSOs) but defined in state objects, like how raytracing pipelines and work graphs are defined. So all types of shaders and pipelines can be defined in a consistent way if desired now.
A single state object can define a bunch of subobjects that act as building blocks – shaders, blend state, rasterizer state etc.. Then any number of permutations of these can be used to define a set of program definitions – each program definition is just a name and a list of subobjects to use. Apps can then retrieve an identifier for each program to bind on the command list using SetProgram() then and execute as usual via Draw*()/Dispatch*() etc, including DispatchGraph() for work graphs. Raytracing pipelines still need to be bound via existing SetPipelineState1().
AddToStateObject() is supported as well, so new pipeline permutations can be added using existing building blocks in the state object and/or using newly added ones.
There are still some minor differences between how raytracing and work graph node shaders are authored versus shaders for generic programs – VS/PS etc still use vs_6_*/ps_6_* target and are not authored in lib_6_* like raytracing and work graph node shaders. But those vs_6_8 etc. compiled shaders can be passed into a state object definition as if they are a dxil library, and will simply appear like a library with a single shader entry in it.
There isn’t expected to be any performance difference here versus previous methods of defining PSOs that required separate full API object for every permutation. Perhaps some minor CPU side difference from having fewer API objects. For most, it may be fine to ignore this feature for now. The main benefits of this addition are:
- Enable the option for an application to manage all shaders and other pipeline state subobjects for all shader types – raytracing, work graphs, vertex shader pipelines, mesh shader pipelines in a mostly consistent way.
- Having generic programs/pipeline (e.g. VS/PS, MS/PS) defined in state objects paves the way for future ability for work graphs to include them as leaf nodes. In other words work graphs could drive the graphics pipeline directly. The work graphs spec proposes how this might work – see graphics nodes.
Condensed programming guide
The spec has full programming details. Here is a minimal walkthrough based on the D3D12HelloWorkGraphs sample.
Drivers and other prerequisites
What you need:
- A PC with any OS that supports the AgilitySDK
- App set up to use AgilitySDK 1.613 and the latest DirectX Shader compiler
- The sample projects automatically download the nugets for these.
- A GPU with corresponding driver installed that is advertised to support work graphs. See below.
- Optional: Install WARP for work graphs as a software driver alternative that could be handy for testing. WARP supports virtually all D3D features including shader model 6.8 including features like raytracing.
AMD, NVIDIA, Intel and Qualcomm all helped with the work graphs design. Here are the supported GPUs as of March 11, 2024:
- AMD: AMD Software: Adrenalin Edition™ Knowledge Base 23.40.14.01 driver for Windows has support for the Work Graphs 1.0 API on AMD Radeon™ RX 7000 Series graphics cards and can be downloaded here. Support for Work Graphs 1.0 in our public Adrenalin drivers will hit the shelves in Q2 2024. Visit the GPUOpen blog post here to get all the details and samples for this inaugural production release of Work Graphs.
AMD is excited to work with Microsoft on the production launch of the Work Graphs API, allowing developers to tackle graphics and AI workloads in a new and efficient way on the GPU. It was a pleasure to partner with Microsoft over the last few years to bring this innovation to graphics developers & researchers all around the world. We hope you’ll have as much fun using them as we had building them. If you would like to see them running yourself, please make sure to come and see our demo at GDC 2024!
Andrej Zdravkovic, AMD SVP and Chief Software Officer
- NVIDIA: Work graphs are supported on NVIDIA GeForce RTX GPUs starting with GeForce RTX 30 Series along with driver version 551.76 and newer which can be downloaded here. NVIDIA also has a work graphs blog with a practical example and their best practices here.
Authoring shaders
Work graph node shaders are authored using the lib_6_8 shader target.
In the interest of brevity, one shader is shown here from sample code. The full set of of the shaders for this graph can be found the samples described later. For definitions of what is happening see the spec which defines it all, including specific examples.
struct entryRecord
{
uint gridSize : SV_DispatchGrid;
uint recordIndex;
};
struct secondNodeInput
{
uint entryRecordIndex;
uint incrementValue;
};
// ------------------------------------------------------------------------
// firstNode is the entry node, a broadcasting launch node.
//
// For each entry record, a dispatch grid is spawned with grid size from
// inputData.gridSize.
//
// Grid size can also be fixed for the node instead of being part of the
// input record, using [NodeDispatchGrid(x,y,z)]
//
// Each thread group sends 2 records to secondNode asking it to do some
// work.
// ------------------------------------------------------------------------
[Shader("node")]
[NodeLaunch("broadcasting")]
[NodeMaxDispatchGrid( 16, 1, 1)] // Contrived value, input records from the
// app only top out at grid size of 4.
// This declaration should be as accurate
// as possible, but not too small
// (undefined behavior).
[NumThreads(2,1,1)]
void firstNode(
DispatchNodeInputRecord<entryRecord> inputData,
[MaxRecords(2)] NodeOutput<secondNodeInput> secondNode,
uint threadIndex : SV_GroupIndex,
uint dispatchThreadID : SV_DispatchThreadID)
{
// Methods for allocating output records must be called at thread group
// scope (uniform call across the group) Allocations can be per thread
// as well: GetThreadNodeOutputRecords(...), but the call still has to
// be group uniform albeit with thread-varying arguments. Thread
// execution doesn't have to be synchronized (Barrier call not needed).
GroupNodeOutputRecords<secondNodeInput> outRecs =
secondNode.GetGroupNodeOutputRecords(2);
// In a future language version, "->" will be available instead of
// ".Get()" to access record members
outRecs[threadIndex].entryRecordIndex = inputData.Get().recordIndex;
outRecs[threadIndex].incrementValue =
dispatchThreadID * 2 + threadIndex + 1;
outRecs.OutputComplete(); // Call must be group uniform. Thread
// execution doesn't have to be synchronized
// (Barrier call not needed).
}
Enabling work graphs in an app
Once a D3D device has been created, check that work graphs are supported.
From the samples:
D3D12_FEATURE_DATA_D3D12_OPTIONS21 Options;
VERIFY_SUCCEEDED(Ctx.spDevice->CheckFeatureSupport(
D3D12_FEATURE_D3D12_OPTIONS21, &Options, sizeof(Options)));
if (Options.WorkGraphsTier == D3D12_WORK_GRAPHS_TIER_NOT_SUPPORTED) {
PRINT("Device does not report support for work graphs.");
return -1;
}Creating a work graph on a device
Given some node shaders authored in a DXIL library, a work graph can be made in a state object at runtime. There is a lot of flexibility in how a work graph is constructed. For example, more than one can be defined in a single state object. The set of nodes in a graph can be hand-picked and optionally have various properties overridden at state object creation, such as renaming nodes. These are all described in the spec.
But the simplest case is illustrated from a sample below, telling the runtime to create a work graph out of all the shaders available. The runtime will piece together the graph by looking for nodes whose names match the names of the outputs of any given node.
There are some helpers for state object construction from d3dx12_state_object.h used by this example. d3dx12.h can be included instead to get all helper headers at once.
CD3DX12_STATE_OBJECT_DESC SO(D3D12_STATE_OBJECT_TYPE_EXECUTABLE);
auto GlobalRootSig =
SO.CreateSubobject<CD3DX12_GLOBAL_ROOT_SIGNATURE_SUBOBJECT>();
GlobalRootSig->SetRootSignature(spRS); // spRS created earlier
auto pLib = SO.CreateSubobject<CD3DX12_DXIL_LIBRARY_SUBOBJECT>();
CD3DX12_SHADER_BYTECODE libCode(library);
pLib->SetDXILLibrary(&libCode);
auto pWG = SO.CreateSubobject<CD3DX12_WORK_GRAPH_SUBOBJECT>();
pWG->IncludeAllAvailableNodes(); // Auto populate the graph
LPCWSTR workGraphName = L"HelloWorkGraphs";
pWG->SetProgramName(workGraphName);
VERIFY_SUCCEEDED(
Ctx.spDevice->CreateStateObject(SO, IID_PPV_ARGS(&spSO)));
Once a state object with a work graph has been created, some properties can be extracted from it. The sample code below extracts a program identifier for the work graph. This is used later on a command list to identify what program to execute.
The code also determines how much backing memory the device needs to execute the graph. This is basically scratch memory the device can use to spill intermediate data when executing a graph, such as data that doesn’t fit in a cache, or any other live data. The sample chooses to make a backing memory allocation of the maximum size recommended by the device for the graph. This will be used later on a command list when the work graph is set for use.
class WorkGraphContext
{
public:
void Init(D3DContext& D3D, CComPtr<ID3D12StateObject> spSO,
LPCWSTR pWorkGraphName)
{
// D3DContext above is just a D3D object container in the sample,
// not shown for brevity
CComPtr<ID3D12StateObjectProperties1> spSOProps;
spSOProps = spSO;
hWorkGraph = spSOProps->GetProgramIdentifier(pWorkGraphName);
CComPtr<ID3D12WorkGraphProperties> spWGProps;
spWGProps = spSO;
UINT WorkGraphIndex =
spWGProps->GetWorkGraphIndex(pWorkGraphName);
spWGProps->GetWorkGraphMemoryRequirements(WorkGraphIndex,
&MemReqs);
BackingMemory.SizeInBytes = MemReqs.MaxSizeInBytes;
// MakeBuffer is a helper function not shown
MakeBuffer(D3D, &spBackingMemory, BackingMemory.SizeInBytes,
D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS);
BackingMemory.StartAddress =
spBackingMemory->GetGPUVirtualAddress();
}
CComPtr<ID3D12Resource> spBackingMemory;
D3D12_GPU_VIRTUAL_ADDRESS_RANGE BackingMemory = {};
D3D12_PROGRAM_IDENTIFIER hWorkGraph = {};
D3D12_WORK_GRAPH_MEMORY_REQUIREMENTS MemReqs = {};
};
Dispatching a work graph in a commandlist
First some global resource bindings are set. This code, from D3D12HelloWorkGraphs doesn’t use the option of having per-node static bindings in GPU memory. The more advanced D3D12WorkGraphsSandbox does show it.
D3D.spCL->SetComputeRootSignature(spRS);
D3D.spCL->SetComputeRootUnorderedAccessView(
0, spGPUBuffer->GetGPUVirtualAddress());
Then the work graph is set on the device, including backing memory. Since it is the first time the backing memory is used with the graph, a flag is set to initialize the work graph.
// Setup program
D3D12_SET_PROGRAM_DESC setProg = {};
setProg.Type = D3D12_PROGRAM_TYPE_WORK_GRAPH;
setProg.WorkGraph.ProgramIdentifier = WG.hWorkGraph;
setProg.WorkGraph.Flags = D3D12_SET_WORK_GRAPH_FLAG_INITIALIZE;
setProg.WorkGraph.BackingMemory = WG.BackingMemory;
D3D.spCL->SetProgram(&setProg);
Finally graph inputs in CPU memory are passed into a DispatchGraph() call. The command list copies the inputs there, so the driver doesn’t hold a reference to the memory. Inputs can be provided in GPU memory as well, which get read at the time of execution on the GPU.
// Generate graph inputs
struct entryRecord // equivalent to the definition in HLSL code
{
UINT gridSize; // : SV_DispatchGrid;
UINT recordIndex;
};
vector<entryRecord> inputData;
UINT numRecords = 4;
inputData.resize(numRecords);
for (UINT recordIndex = 0; recordIndex < numRecords; recordIndex++)
{
inputData[recordIndex].gridSize = recordIndex + 1;
inputData[recordIndex].recordIndex = recordIndex;
}
// Spawn work
D3D12_DISPATCH_GRAPH_DESC DSDesc = {};
DSDesc.Mode = D3D12_DISPATCH_MODE_NODE_CPU_INPUT;
DSDesc.NodeCPUInput.EntrypointIndex = 0; // just one entrypoint in graph
DSDesc.NodeCPUInput.NumRecords = numRecords;
DSDesc.NodeCPUInput.RecordStrideInBytes = sizeof(entryRecord);
DSDesc.NodeCPUInput.pRecords = inputData.data();
D3D.spCL->DispatchGraph(&DSDesc);
Samples
Work graphs and generic programs samples can be found at DirectX-Graphics-Samples on GitHub, under the Samples/Desktop/D3D12HelloWorld folder.
These are the relevant samples:
More elaborate samples information is available at these links from AMD and NVIDIA.
D3D12HelloWorkGraphs
DirectX-Graphics-Samples path: Samples/Desktop/D3D12HelloWorld/src/HelloWorkGraphs
This is a minimal work graphs sample in one cpp and one hlsl file. It uses a graph to accumulate some arbitrary numbers to a UAV. The app then prints the UAV contents to the console.
This intentionally is not trying to do anything useful. It is meant to be a starting point for you to try your own (likely complex) compute algorithms.
See the comments in D3D12HelloWorkGraphs.hlsl. A lot of experimenting can be done simply by editing this file and running without having to recompile the app.
Of course, feel free to tweak the source and rebuild the project.
D3D12WorkGraphsSandbox
DirectX-Graphics-Samples path: Samples/Desktop/D3D12HelloWorld/WorkGraphsSandbox
This is a slightly more elaborate sample that can autogenerate input data to feed whatever graph you author. It also uses more features, like node local root arguments and shows how to feed graph inputs from the GPU or CPU. Finally, it prints out execution timing to the console.
Like the hello world sample, this also isn’t trying to do anything useful. It is meant to be a starting point for you to try your own (likely complex) compute algorithms.
See the comments in D3D12WorkGraphsSandbox.hlsl to understand how to play around with the sandbox. A lot of experimenting can be done simply by editing the hlsl input file or making multiple versions of the file to keep different experiments around.
D3D12HelloGenericPrograms
DirectX-Graphics-Samples path: Samples/Desktop/D3D12HelloWorld/src/HelloGenericPrograms
This sample is a tweak of the basic D3D12HelloTriangle sample that uses generic programs in state objects to define the pipeline state instead of a pipeline state object.
The sample also minimally demonstrates using [AddToStateObject()](#addtostateobject) to add a new program that uses the same vertex shader as the first but a different pixel shader, and draws a second triangle with it.
PIX
The PIX tool supports all shader model 6.8 features. See here.
Notable changes since 2023 work graphs preview
The earlier work graphs preview lined up with v0.43 of the work graphs spec. The current spec is here, where the full list of changes can be seen in the change log after v0.43.
Summary of changes between the preview and this official release:
- Producer – consumer dataflow through UAVs. This section in the spec describes rules for when an app wants to pass data between nodes through UAVs (i.e. GPU memory) instead of via node records for whatever reason, including if the amount of data exceeds node record size limits.
In the design process here, an attempt was made at introducing ways to do bulk synchronization of data between multiple producer threads/groups cooperating to produce output to a consumer node’s threads, without using the heavy hammer of declaring UAVs [globallycoherent], but the amount of change required proved too much to take on for now.
If it could have been addressed for this release there may have been less need to break up big graphs into smaller graphs for some scenarios. That said, whether breaking up graphs around bulk synchronization turns out to be a significant issue can certainly inform future API evolution.
- Barrier(): Did some refinement and refactoring of the new general purpose `Barrier()` intrinsics in shader model 6.8 relative to the preview release. These are a slightly more expressive superset of the various permutations of barrier intrinsics that have existed in shaders for many years, and which are still available. The equivalencies between old and new barrier intrinsics are defined.
- D3D12_COMMON_COMPUTE_NODE_OVERRIDES: Added a simplification for the scenario of overriding a node’s behavior at the API during graph construction vs how it was defined in HLSL. There is a new common override type for properties common to all node launch modes. So the API user doesn’t have to know the launch mode of a node shader when assembling a graph out of node shaders just to be able to perform a common override such as renaming the node or what nodes it outputs to.
- AddToStateObject() and Generic programs support are now present, discussed above.
- Code tweaks to migrate from preview test code to official release:
- Stop calling D3D12EnableExperimentalFeatures(), and OS no longer needs to be in developer mode.
- ID3D12DeviceExperimental -> ID3D12Device14
- ID3D12GraphicsCommandListExperimental -> ID3D12Device14
- Checking support for D3D12_WORK_GRAPHS_TIER_1_0: D3D12_FEATURE_D3D12_OPTIONS_EXPERIMENTAL -> D3D12_FEATURE_D3D12_OPTIONS21
Thanks Microsoft DirectX Development Team,
I hope this message finds you well. I am reaching out to gather information on a specific aspect of real-time rendering techniques employed within DirectX, particularly regarding Occlusion Culling.
Given the increasing integration of artificial intelligence in optimizing various computing and rendering processes, I am keen to understand whether the DirectX team currently utilizes AI or machine learning models to enhance Occlusion Culling efficiency. My interest lies in exploring how AI could potentially predict occlusion scenarios more effectively, thereby optimizing rendering workflows and improving performance in complex 3D environments.
Could you please share any insights or developments in...
DirectX
We look forward to a patch coming out so that many of us can enjoy that improvement and evolve together. I hope the solution that so many of us have decided on comes out soon👍