

Work Graphs is now out of preview. See the launch blog here
Contents
- Introduction to work graphs
- Specification <– the docs
- Node types
- Condensed programming guide
- Samples
- PIX
Introduction to work graphs
Work graphs are a system for GPU autonomy in D3D12. Given the increasing prevalence of general compute workloads on GPUs, the motivation is to address some limitations in their programming model, unlock latent GPU capabilities, and enable future evolution.
To start, here are some words on the potential:
Epic Games has been searching and advocating for a better solution to the GPU generated work problem for a while now. UE5 rendering features such as Nanite and Lumen are hitting the limits of the current compute shader paradigm of chains of separate dispatches issued by the CPU.
Work graphs directly address that problem in a way that not only allows us to do things we previously could not but also enables us to do them in ways that should be far easier to write. We have already started exploring how we can optimize our current features with work graphs and are excited about what possibilities they could unlock in the future.
— Brian Karis, Epic Games
This is very much a preview, with reasonably functional drivers available now.
The current state reflects a lengthy collaboration between Microsoft and hardware vendors as well as developer input. Looking forward longer term, there should also be a lot of improvement both in software and hardware.
Basis
In many GPU workoads, an initial calculation on the GPU determines what subsequent work the GPU needs to do. This can be accomplished with a round trip back to the CPU to issue the new work. But it is typically better for the GPU to be able to feed itself directly. ExecuteIndirect in D3D12 is a form of this, where the app uses the GPU to record a very constrained command buffer that needs to be serially processed on the GPU to issue new work.
Consider a new option. Suppose shader threads running on the GPU (producers) can request other work to run (consumers). Consumers can be producers as well. The system can schedule the requested work as soon as the GPU has capacity to run it. The app can also let the system manage memory for the data flowing between tasks.
This is work graphs. A graph of nodes where shader code at each node can request invocations of other nodes, without waiting for them to launch. Work graphs capture the user’s algorithmic intent and overall structure, without burdening the developer to know too much about the specific hardware it will run on. The asynchronous nature maximizes the freedom for the system to decide how best to execute the work.
Here is a graph contrived to illustrate several capabilities (click to zoom):
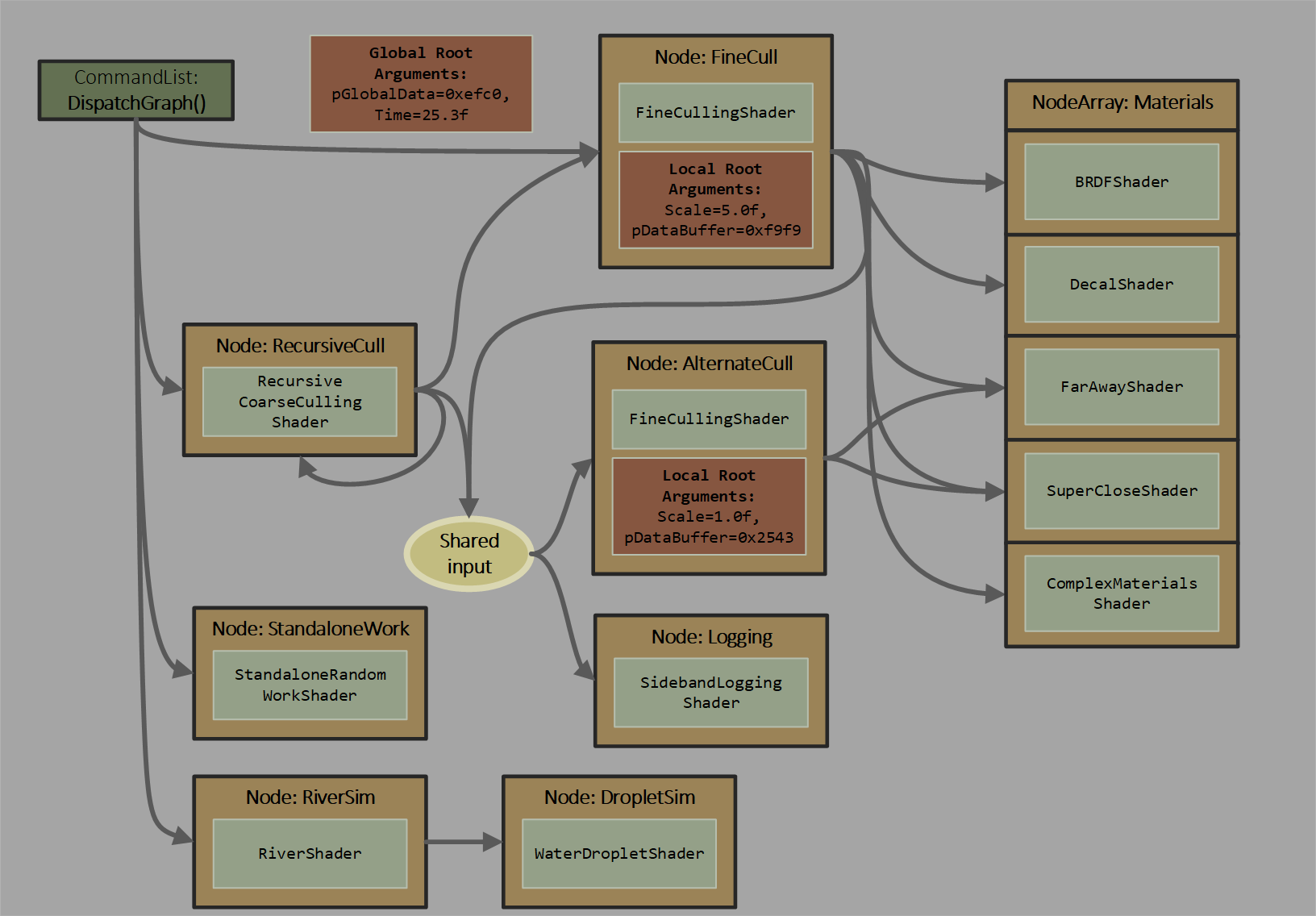
Characteristics
- When initiating work with
DispatchGraph(), the app can pass arguments to graph entrypoints from either app CPU memory copied into a command list’s recording, or app GPU memory read at command list execution. These options are convenient even with a single node graph. Traditional compute shaders can only get input data from D3D12 root bindings or by manually reading memory as a function of various ID system values.
- There are a few options for how a node translates incoming work requests into a set of shader invocations, ranging from a single thread per work item to variable sized grids of thread groups per work item.
- The graph is acyclic, with one exception: a node can output to itself. There is a depth limit of 32 including recursion.
- For implementation efficiency there are limits on the amount of data that node invocations can pass directly to other nodes; for bulk data transfer apps need to use UAV accesses.
- Scheduling of work requests can be done by the system with whatever underlying hardware tools are at its disposal.
- Less capable architectures might revert to a single processor on the GPU scheduling work requests. More advanced architectures might use distributed scheduling techniques and account for the specific topology of processing resources on the GPU to efficiently manage many work requests being generated in parallel.
- This is in contrast to the ExecuteIndirect model which forces a serial processing step for the GPU – walking through a GPU generated command list to determine a sequence of commands to issue.
- Data from a producer might be more likely to flow to a consumer directly, staying within caches
- This could reduce reliance on off-chip memory bandwidth for performance scaling
- Because data can flow between small tasks in a fine-grained way, the programming model doesn’t force the application to drain the GPU of work between data processing steps.
- Since the system handles buffering of data passed between producers and consumers (if the app wants), the programming model can be simpler than ExecuteIndirect.
Analysis
Despite the potential advantages, the free scheduling model may not always the best target for an app’s workload. Characteristics of the task, such as how it interacts with memory/caches, or the sophistication of hardware over time, may dictate whether some existing approach is better. Like continuing to use `ExecuteIndirect`. Or building producer consumer systems out of relatively long running compute shader threads that cross communicate – clever and fragile. Or using the paradigms in the DirectX Raytracing model, involving shaders splitting up and continuing later. Work graphs are a new tool in the toolbox.
Given that the model is about producers requesting for consumers to run, currently there isn’t an explicit notion of waiting before launching a node. For instance, waiting for all work at multiple producer nodes to finish before a consumer launches. This can technically be accomplished by breaking up a graph, or with clever shader logic. Synchronization wasn’t a focus for the initial design, hence these workarounds, discussed more in the spec: Joins – synchronizing within the graph. Native synchronization support may be defined in the future and would be better than the workarounds in lots of ways. Many other compute frameworks explicitly use a graph to define bulk dependencies, in contrast to the feed-forward model here.
While the hope is that work graphs can be useful out of the gate, the expectation is hardware/drivers and diagnostic tools will improve over time. This API is being exposed – before optimal systems for running it exist – to allow for:
- Accelerating the arrival of optimal hardware/drivers, including learnings from how developers start to use work graphs.
- Encouraging similar concepts to be explored across different platforms or APIs, if not already, making this more viable for developers.
- Exploring ways to extend the model further, such as:
- driving rasterization at leaf nodes – proposed in this spec but not refined enough to be implemented yet
- synchronization constructs, mentioned earlier
- supporting other fixed function tasks that command lists can do, like UAV<>SRV resource transitions
- Learning lessons that lead to an even better programming model in the future.
- For example: Exposing low level scheduling building blocks instead of a monolithic API was considered but didn’t currently seem viable across the breadth of hardware. Perhaps a path to this will emerge, either from hindsight with work graphs on PC, or inspired by what fixed platforms accomplish.
All of these outcomes are welcome and might appear over a wide timespan.
Scenarios summary
- Reducing number of passes out to memory and GPU idling in multi-pass compute algorithms
- Avoiding the pattern in ExecuteIndirect of serial processing through worst case sized buffers
- Classification and binning via node arrays
- Eventually:
- Feeding graphics from compute
- Bulk work synchronization
Specification
The spec begins with the same introduction as above.
For a much shorter read than the rest of the full spec, the following sections skim through basic concepts with a small programming guide.
Node types
Here is a summary of the currently defined node types, defined fully in the spec. They are variations on compute shaders, distinguished by how node inputs translate to a grouping of threads to launch.
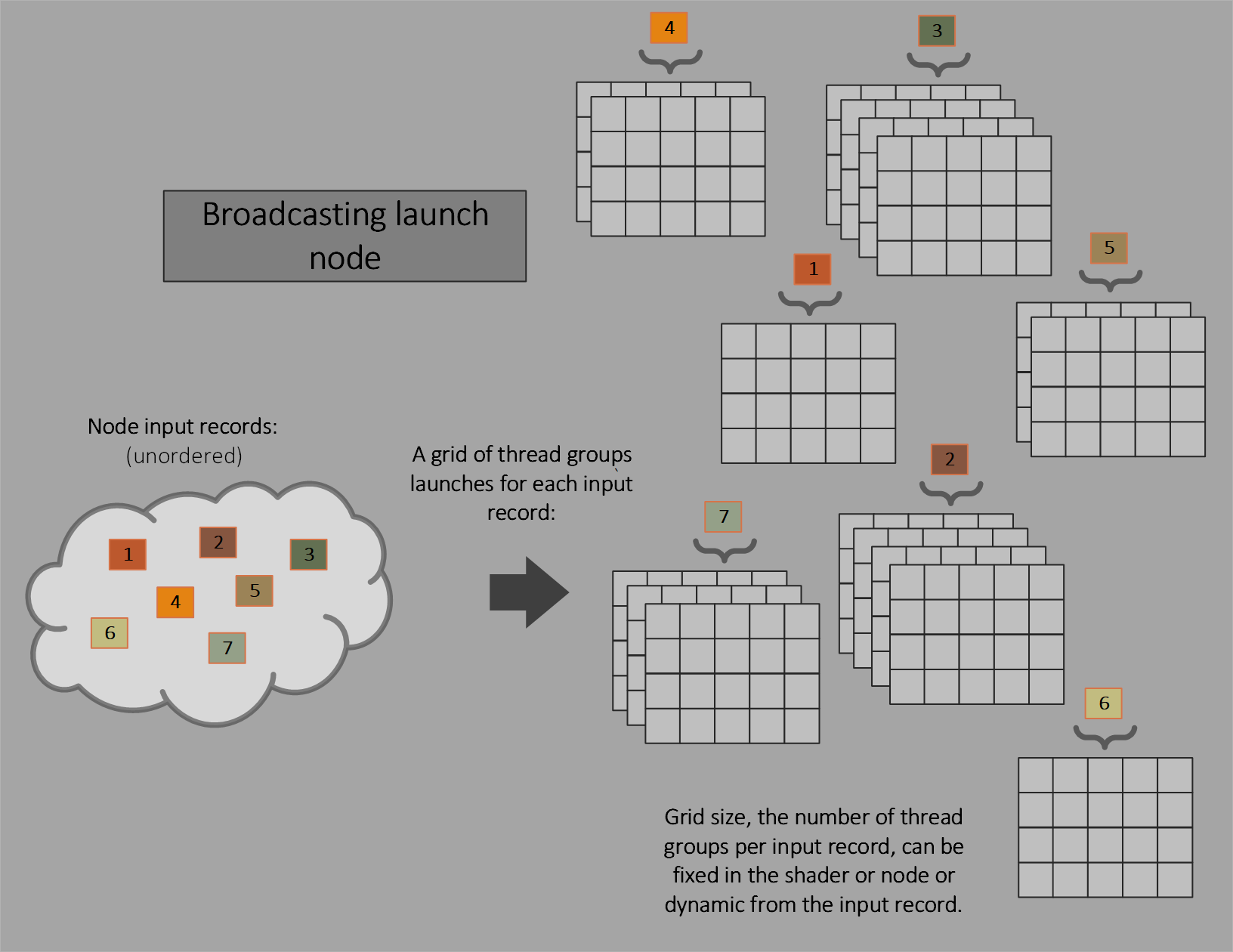
Broadcasting launch
This is like a traditional compute shader, with fixed size thread groups invoked over a dispatch grid. The dispatch grid size can be fixed for a node or dynamic (part of the input record). “Broadcasting” denotes that the input record is visible to all launched threads.
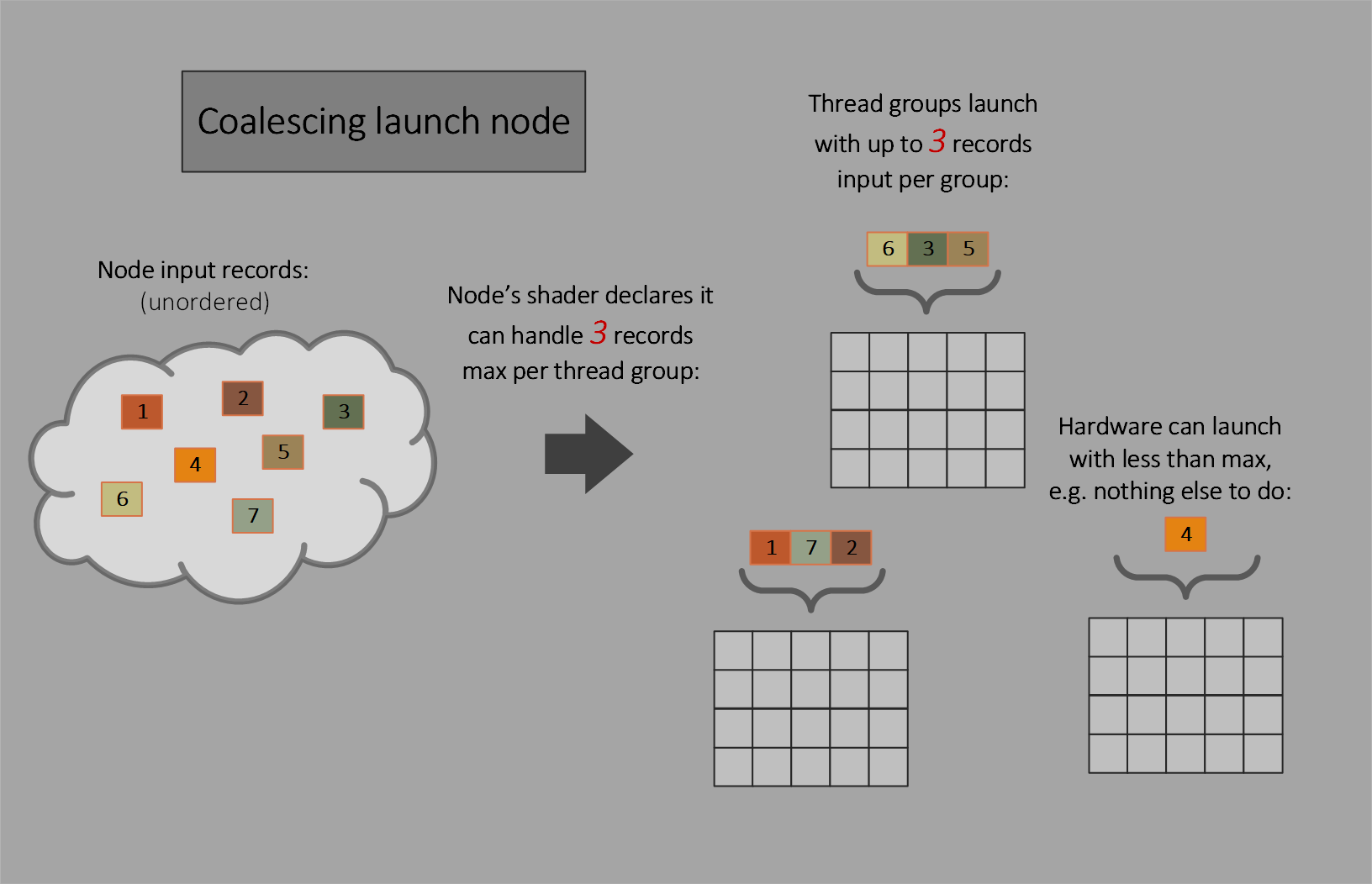
Coalescing launch
Multiple input records per individual thread group launch, with no dispatch grid. The shader declares a fixed thread group size and the maximum number of input records a thread group can handle. The hardware will attempt to fill that quota with each thread group launch, with freedom to launch with as few as one record if it wants or has no choice.
This node type is useful only if the shader can do some sharing of work across the set of input records, such as using thread group shared memory, knowing the declared maximum number of records per thread group is not guaranteed to be filled. If records will just be processed individually per thread, thread launch nodes are more appropriate.
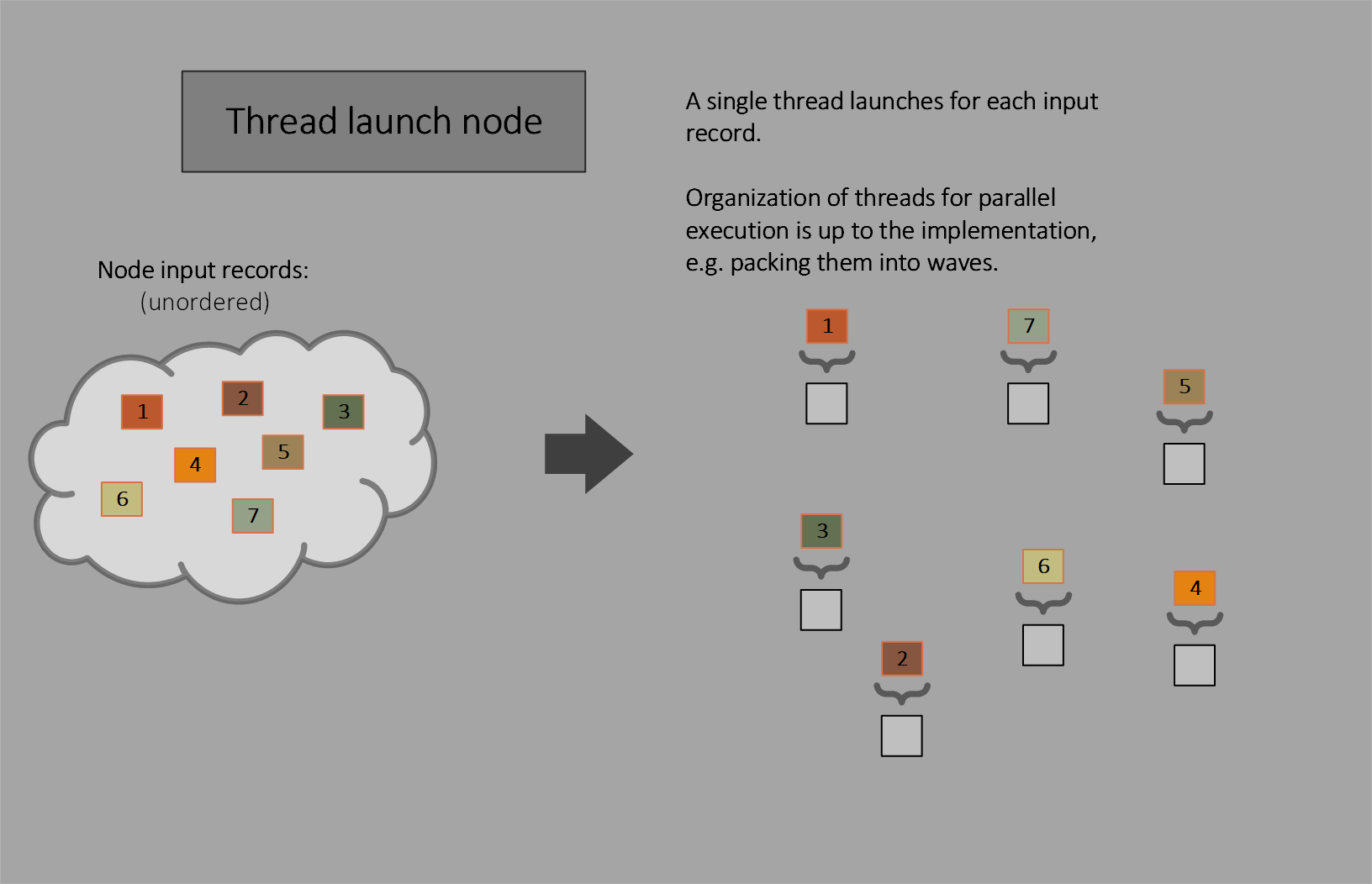
Thread launch
Thread launch nodes invoke one thread for each input.
Thread launch nodes are conceptually a subset of coalescing launch nodes. They use a thread group size of (1,1,1), so the thread group size need not be declared, and limit the number of input records per thread group launch to 1. Thread launch nodes can pack work fundamentally differently than coalescing or broadcasting launch nodes: thread launch nodes allow multiple threads from different launches to be packed into a wave (e.g. visible to wave operations).
Condensed programming guide
The spec has full programming details. Here is a minimal walkthrough based on the D3D12HelloWorkGraphs sample.
Drivers and other prerequisites
What you need:
- A PC with any OS that supports the AgilitySDK
- Developer mode enabled for Windows
- App set up to use the AgilitySDK 1.711.3 preview and the DirectX Shader compiler preview
- A GPU with corresponding driver installed that is advertised to support work graphs. See below.
- Optional: Install preview WARP for Work Graphs as a software driver alternative that could be handy for testing. This release supports almost all D3D features leading up to shader model 6.8 including features like raytracing.
AMD, NVIDIA, Intel and Qualcomm have all helped with the work graphs design. Here is the status on driver availability:
- AMD: Any AMD Software: Adrenalin Edition™ driver 23.9.2 or newer for Windows has support for the Work Graphs API on AMD Radeon™ RX 7000 Series graphics cards and can be downloaded here. See how AMD worked with Microsoft and the developer community to bring Work Graphs to life here and when you’re ready to try this for yourself you can read the corresponding AMD GPUOpen Programmer’s Guide to Work Graphs here.
At AMD we are incredibly excited to see the Work Graph API finally in the hands of developers. After multiple years of effort and collaboration, it’s great to see this release realized and we can’t wait to hear about what you’ll will accomplish with these new capabilities. We strongly encourage you to give it a try today and look forward to hearing your feedback!
Mike Mantor, Chief GPU architect and Corporate Fellow
- NVIDIA: To obtain the NVIDIA drivers supporting work graphs, please reach out to your developer engagement representative.
- Intel: Intel’s close collaboration and partnership with Microsoft on the work graphs feature set will enable developers to better harness the power of Intel Graphics processors, delivering increased performance and innovative graphics techniques. We look forward to supporting the upcoming work graphs in a future driver release. For further inquiries please reach out to Intel developer relations at gamedevtech@intel.com.
Authoring shaders
Work graph node shaders are authored using the lib_6_8 shader target.
In the interest of brevity, one shader is shown here from sample code. The full set of of the shaders for this graph can be found the samples described later. For definitions of what is happening see the spec which defines it all, including specific examples.
struct entryRecord
{
uint gridSize : SV_DispatchGrid;
uint recordIndex;
};
struct secondNodeInput
{
uint entryRecordIndex;
uint incrementValue;
};
// ------------------------------------------------------------------------
// firstNode is the entry node, a broadcasting launch node.
//
// For each entry record, a dispatch grid is spawned with grid size from
// inputData.gridSize.
//
// Grid size can also be fixed for the node instead of being part of the
// input record, using [NodeDispatchGrid(x,y,z)]
//
// Each thread group sends 2 records to secondNode asking it to do some
// work.
// ------------------------------------------------------------------------
[Shader("node")]
[NodeLaunch("broadcasting")]
[NodeMaxDispatchGrid( 16, 1, 1)] // Contrived value, input records from the
// app only top out at grid size of 4.
// This declaration should be as accurate
// as possible, but not too small
// (undefined behavior).
[NumThreads(2,1,1)]
void firstNode(
DispatchNodeInputRecord<entryRecord> inputData,
[MaxRecords(2)] NodeOutput<secondNodeInput> secondNode,
uint threadIndex : SV_GroupIndex,
uint dispatchThreadID : SV_DispatchThreadID)
{
// Methods for allocating output records must be called at thread group
// scope (uniform call across the group) Allocations can be per thread
// as well: GetThreadNodeOutputRecords(...), but the call still has to
// be group uniform albeit with thread-varying arguments. Thread
// execution doesn't have to be synchronized (Barrier call not needed).
GroupNodeOutputRecords<secondNodeInput> outRecs =
secondNode.GetGroupNodeOutputRecords(2);
// In a future language version, "->" will be available instead of
// ".Get()" to access record members
outRecs[threadIndex].entryRecordIndex = inputData.Get().recordIndex;
outRecs[threadIndex].incrementValue =
dispatchThreadID * 2 + threadIndex + 1;
outRecs.OutputComplete(); // Call must be group uniform. Thread
// execution doesn't have to be synchronized
// (Barrier call not needed).
}
Enabling work graphs preview in an app
Before creating a D3D device, enable two experimental features:
D3D12ExperimentalShaderModelsD3D12StateObjectsExperiment
From the samples:
UUID Features[2] =
{D3D12ExperimentalShaderModels, D3D12StateObjectsExperiment};
HRESULT hr = D3D12EnableExperimentalFeatures(_countof(Features), Features,
nullptr, nullptr);Once a D3D device has been created, double check that work graphs are supported.
From the samples:
D3D12_FEATURE_DATA_D3D12_OPTIONS_EXPERIMENTAL Options;
VERIFY_SUCCEEDED(Ctx.spDevice->CheckFeatureSupport(
D3D12_FEATURE_D3D12_OPTIONS_EXPERIMENTAL, &Options, sizeof(Options)));
if (Options.WorkGraphsTier == D3D12_WORK_GRAPHS_TIER_NOT_SUPPORTED) {
PRINT("Device does not report support for work graphs.");
return -1;
}Creating a work graph on a device
Given some node shaders authored in a DXIL library, a work graph can be made in a state object at runtime. There is a lot of flexibility in how a work graph is constructed. For example, more than one can be defined in a single state object. The set of nodes in a graph can be hand-picked and optionally have various properties overridden at state object creation, such as renaming nodes. These are all described in the spec.
But the simplest case is illustrated from a sample below, telling the runtime to create a work graph out of all the shaders available. The runtime will piece together the graph by looking for nodes whose names match the names of the outputs of any given node.
There are some helpers for state object construction from d3dx12_state_object.h used by this example. d3dx12.h can be included instead to get all helper headers at once.
CD3DX12_STATE_OBJECT_DESC SO(D3D12_STATE_OBJECT_TYPE_EXECUTABLE);
auto GlobalRootSig =
SO.CreateSubobject<CD3DX12_GLOBAL_ROOT_SIGNATURE_SUBOBJECT>();
GlobalRootSig->SetRootSignature(spRS); // spRS created earlier
auto pLib = SO.CreateSubobject<CD3DX12_DXIL_LIBRARY_SUBOBJECT>();
CD3DX12_SHADER_BYTECODE libCode(library);
pLib->SetDXILLibrary(&libCode);
auto pWG = SO.CreateSubobject<CD3DX12_WORK_GRAPH_SUBOBJECT>();
pWG->IncludeAllAvailableNodes(); // Auto populate the graph
LPCWSTR workGraphName = L"HelloWorkGraphs";
pWG->SetProgramName(workGraphName);
VERIFY_SUCCEEDED(
Ctx.spDevice->CreateStateObject(SO, IID_PPV_ARGS(&spSO)));
Once a state object with a work graph has been created, some properties can be extracted from it. The sample code below extracts a program identifier for the work graph. This is used later on a command list to identify what program to execute.
The code also determines how much backing memory the device needs to execute the graph. This is basically scratch memory the device can use to spill intermediate data when executing a graph, such as data that doesn’t fit in a cache, or any other live data. The sample chooses to make a backing memory allocation of the maximum size recommended by the device for the graph. This will be used later on a command list when the work graph is set for use.
class WorkGraphContext
{
public:
void Init(D3DContext& D3D, CComPtr<ID3D12StateObject> spSO,
LPCWSTR pWorkGraphName)
{
// D3DContext above is just a D3D object container in the sample,
// not shown for brevity
CComPtr<ID3D12StateObjectProperties1> spSOProps;
spSOProps = spSO;
hWorkGraph = spSOProps->GetProgramIdentifier(pWorkGraphName);
CComPtr<ID3D12WorkGraphProperties> spWGProps;
spWGProps = spSO;
UINT WorkGraphIndex =
spWGProps->GetWorkGraphIndex(pWorkGraphName);
spWGProps->GetWorkGraphMemoryRequirements(WorkGraphIndex,
&MemReqs);
BackingMemory.SizeInBytes = MemReqs.MaxSizeInBytes;
// MakeBuffer is a helper function not shown
MakeBuffer(D3D, &spBackingMemory, BackingMemory.SizeInBytes,
D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS);
BackingMemory.StartAddress =
spBackingMemory->GetGPUVirtualAddress();
}
CComPtr<ID3D12Resource> spBackingMemory;
D3D12_GPU_VIRTUAL_ADDRESS_RANGE BackingMemory = {};
D3D12_PROGRAM_IDENTIFIER hWorkGraph = {};
D3D12_WORK_GRAPH_MEMORY_REQUIREMENTS MemReqs = {};
};
Dispatching a work graph in a commandlist
First some global resource bindings are set. This code, from D3D12HelloWorkGraphs doesn’t use the option of having per-node static bindings in GPU memory. The more advanced D3D12WorkGraphsSandbox does show it.
D3D.spCL->SetComputeRootSignature(spRS);
D3D.spCL->SetComputeRootUnorderedAccessView(
0, spGPUBuffer->GetGPUVirtualAddress());
Then the work graph is set on the device, including backing memory. Since it is the first time the backing memory is used with the graph, a flag is set to initialize the work graph.
// Setup program
D3D12_SET_PROGRAM_DESC setProg = {};
setProg.Type = D3D12_PROGRAM_TYPE_WORK_GRAPH;
setProg.WorkGraph.ProgramIdentifier = WG.hWorkGraph;
setProg.WorkGraph.Flags = D3D12_SET_WORK_GRAPH_FLAG_INITIALIZE;
setProg.WorkGraph.BackingMemory = WG.BackingMemory;
D3D.spCL->SetProgram(&setProg);
Finally graph inputs in CPU memory are passed into a DispatchGraph() call. The command list copies the inputs there, so the driver doesn’t hold a reference to the memory. Inputs can be provided in GPU memory as well, which get read at the time of execution on the GPU.
// Generate graph inputs
struct entryRecord // equivalent to the definition in HLSL code
{
UINT gridSize; // : SV_DispatchGrid;
UINT recordIndex;
};
vector<entryRecord> inputData;
UINT numRecords = 4;
inputData.resize(numRecords);
for (UINT recordIndex = 0; recordIndex < numRecords; recordIndex++)
{
inputData[recordIndex].gridSize = recordIndex + 1;
inputData[recordIndex].recordIndex = recordIndex;
}
// Spawn work
D3D12_DISPATCH_GRAPH_DESC DSDesc = {};
DSDesc.Mode = D3D12_DISPATCH_MODE_NODE_CPU_INPUT;
DSDesc.NodeCPUInput.EntrypointIndex = 0; // just one entrypoint in graph
DSDesc.NodeCPUInput.NumRecords = numRecords;
DSDesc.NodeCPUInput.RecordStrideInBytes = sizeof(entryRecord);
DSDesc.NodeCPUInput.pRecords = inputData.data();
D3D.spCL->DispatchGraph(&DSDesc);
Samples
Work graphs samples can be found on at DirectX-Graphics-Samples on GitHub, under the Samples/Desktop/preview folder.
There are a couple of samples to start with, D3D12HelloWorkGraphs and D3D12WorkGraphsSandbox.
D3D12HelloWorkGraphs
DirectX-Graphics-Samples path: Samples/Desktop/preview/D3D12HelloWorkGraphs
This is a minimal work graphs sample in one cpp and one hlsl file. It uses a graph to accumulate some arbitrary numbers to a UAV. The app then prints the UAV contents to the console.
This intentionally is not trying to do anything useful. It is meant to be a starting point for you to try your own (likely complex) compute algorithms.
See the comments in D3D12HelloWorkGraphs.hlsl. A lot of experimenting can be done simply by editing this file and running without having to recompile the app.
Of course, feel free to tweak the source and rebuild the project.
D3D12WorkGraphsSandbox
DirectX-Graphics-Samples path: Samples/Desktop/preview/D3D12WorkGraphsSandbox
This is a slightly more elaborate sample that can autogenerate input data to feed whatever graph you author. It also uses more features, like node local root arguments and shows how to feed graph inputs from the GPU or CPU. Finally, it prints out execution timing to the console.
Like the hello world sample, this also isn’t trying to do anything useful. It is meant to be a starting point for you to try your own (likely complex) compute algorithms.
See the comments in D3D12WorkGraphsSandbox.hlsl to understand how to play around with the sandbox. A lot of experimenting can be done simply by editing the hlsl input file or making multiple versions of the file to keep different experiments around.
PIX
A preview version of PIX with early work graphs support is available with the following support:
- Apps using work graphs can be captured and replayed.
- A work graph description in a state object can be inspected, as well as the parameters used to launch a graph.
- Graph outputs can be observed by inspecting the UAV buffers its shaders wrote to.
- Finally, overall graph execution time can also be measured.
This is just a start – there is a lot more future work to be done to help make debugging and profiling work graphs easier.
More details including download link are here.
Great article! I really enjoyed reading about the advancements in 3D graphics. The concept of bindless textures on the GPU is fascinating and has significantly improved rendering efficiency. It got me wondering if a similar approach could be applied to vertex and index buffers.
Instead of wasting valuable CPU cycles, wouldn't it be fantastic if we could switch vertex and index buffers directly on the GPU, just like we do with bindless textures? Something like this:
<code>
This could potentially reduce the overhead and streamline the rendering pipeline even further. I'm curious to know if such a technique is being explored...
Hi Viktor,
In the context of work graphs, there are some proposed additions that you might find interesting:
Graphics Nodes
To make driving graphics work as leaf nodes in a graph, the proposal explores one possible way to expose bindless vertex and index buffers. If we end up exposing that, it might make sense to surface it on vanilla command list draws as well.
It's too early to know how viable these proposed additions are for industry to support, or whether they are worth the cost/benefit to expose at this point versus other things. Perhaps focusing on mesh shaders...
Thanks info
I can’t build the samples. Seems like the packages.config file is missing from the workgraph samples.
Fixed, thanks!
Game changing stuff