

Data modeling in the NoSQL world is driven by data access patterns. There are scenarios where it makes sense to duplicate data into multiple separate tables depending on the read/write pattern. This is even more important when you want to access the same information using different unique identifiers (not restricted to only the primary key).
Writing to multiple tables in the same transaction or flow brings in a lot of overhead. The application needs to do heavy lifting to keep the data consistent across all the tables. Trying to do this using a secondary index and not specifying a primary key is not optimal for data with high cardinality.
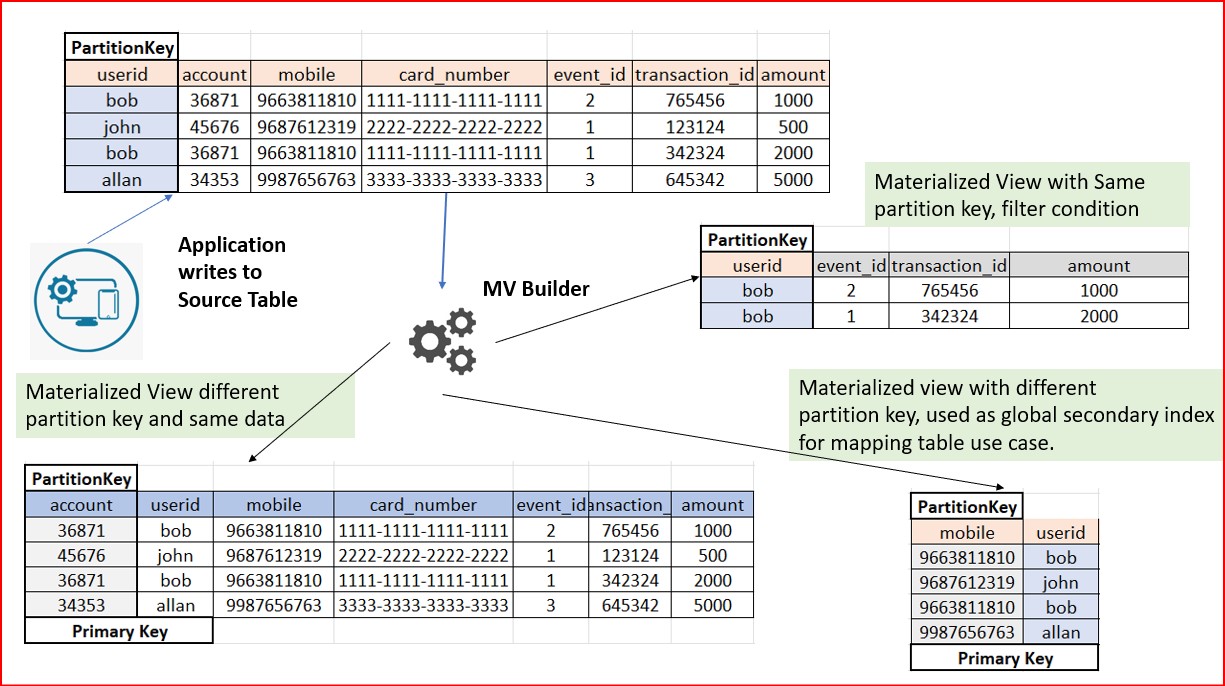
This is where materialized views can help. A table created on top of the base table to give a different view is called materialized view. This view allows the same information in the base table to be queried using a different key or keys.
So how does the materialized view feature help?
- With materialized views (server side denormalization), you can avoid multiple independent tables and client side denormalization.
- You can avoid dual writes as the materialized view feature takes on the responsibility of updating views to keep them consistent with the base table. This is automatically done in the background.
- Since writes need to be committed only to the base table you can reduce write latency. Materialized views take care of updating the view asynchronously.
- If need be, you can create more than one materialized view on the base table.
Scenarios which benefit from materialized views
- A table with two or more unique identifiers, such as account number and email address where users can provide any one of the unique identifiers for fast data look up.
- You want to create a read only table for an application which contains a subset of the details present in the base table and searchable on a key which may be different than the primary key
- Say, from a transaction table which is used to record transactions of all users for each year, you want to get information all the transactions for a given day.
In the above scenarios, creating a Secondary index on a high cardinality column such as account number or email id is not efficient as it results in a cross-partition query. This is where materialized view helps.
Important points on Azure Cosmos DB Cassandra API materialized view
Although Apache Cassandra introduced materialized view way back in 2017, users have observed performance issues during usage. Azure Cosmos DB Cassandra API materialized view are more robust, powerful, and stable by design.
Materialized view builder is a component that maintains materialized views on Azure Cosmos DB. You get flexibility to configure the materialized view builder depending on how quickly you want the view to be consistent. All materialized views within the database account share the builder. This will maximize resource utilization and lower costs. Multiple tasks are spawned in parallel to read change feeds from base table partitions and write data to the view. If required, data transformation can be done in the materialized view definition.
The materialized view implementation on Azure Cosmos DB is based on a pull model, which doesn’t affect write performance. This means the source table writes are not blocked in any way to maintain the materialized view.
Large number of partition tombstones and SSTables compaction in Apache Cassandra affects materialized view performance. Azure Cosmos DB does not maintain tombstones in the same way as Apache Cassandra and SSTables don’t need compaction, so these issues don’t affect Azure Cosmos DB.
You can also specify the throughput for materialized views independently. This provides performance isolation between capacity for materialized views and rest of the tables. This is a clear advantage over Apache Cassandra.
Materialized views can be used in a similar way to Global Secondary Indexes. This saves cross partition scans which in turn reduces expensive queries.
Through extensive monitoring capabilities, you can easily find out how far behind the view is when compared to the updates on the base table. This is determined by “Max Materialized View Catchup Gap” in Minutes. Value(t) indicates rows written to base table in last ‘t’ minutes is yet to be propagated to materialized view. If needed, you can scale up or scale down the materialized view builder to optimize.
Transformation options while creating the view
Currently, you can specify a partition key that is different than the base table partition key. In fact, you can create up to five views on a base table with different primary keys. You can also project only a subset of columns that you need in the view.
Caveats with this preview
- You can only create Materialized Views on new tables created after registering for the preview. A new preview feature, Container Copy, can be used to simplify creating new tables from existing ones.
- You can only use “IS NOT NULL” filters for the materialized view definition’s WHERE clause. You cannot use equalities, inequalities or contains filters during this early preview.
- You cannot use “ALTER TABLE ADD” operations against the base table if using “SELECT *” in the MV definition.
- Restoring from backups does not restore materialized views. You need to re-create the materialized views after the restore process is complete.
- You must delete all materialized views first, before deleting a base table.
Get started
Please refer to this link for public documentation on materialized views.
Next Steps
To get started, see:
- Technical documentation: how to adapt to the Azure Cosmos DB Cassandra API from Apache Cassandra
- Blog: autoscaling in the Azure Cosmo DB Cassandra API
- Blog: Simplified Write and Read paths in the Azure Cosmos DB Cassandra API
- Technical documentation: Apache Cassandra and Azure Cosmos DB consistency levels
Discover additional features and capabilities about Azure Cosmos DB and get started for free.
For up-to-date news on all things, Azure Cosmos DB be sure to follow us on Twitter, and YouTube.
Please give us cross-container transactions for SQL API. I’m actually debating if I should move everything to another db (Mongo or Dynamo) just for this purpose.
While MongoDB and DynamoDB support distributed transactions, careful reading of their docs illustrates that using distributed transactions can impact performance. DynamoDB suggests breaking them up to be as small as possible as a best practice. MongoDB goes even further to suggest in a call out in their documentation that using distributed transactions, "incurs greater performance costs" and is not a replacement for "effective schema design".
Our customers rely upon our service to provide consistent and predictable high performance for their applications. We understand that customers, particularly those who are either new to distributed, NoSQL databases, or are just more comfortable with...
Mark, I'm aware of the tradeoffs you mentioned. My application is designed in a way that I don't need distributed transactions 99% of the time. However, there are a few cases that require updating multiple containers or partitions in an atomic way for correctness. MongoDB and DynamoDB give customers the option to execute such transactions. CosmosDB does not. It can be more flexible and let people weigh pros and cons and make a choice.
The third article you linked has a "username" field. Something as simple as registering usernames is problematic in CosmosDB. A username is supposed to be globally unique....
Are materialized views available in the SQL API for CosmosDB as well?
right now just for Cassandra, but keep your eyes open in the future for any changes