
Azure Cosmos DB is a fully managed service which can be used as a backing data store for applications using Apache Cassandra, using the API for Cassandra. Built on top of Azure Cosmos DB, the Cassandra API provides scale, performance and availability guarantees while eliminating the operational overhead needed to manage Cassandra data.
In this blog post, we dive into what goes on behind the scenes when read and write requests are sent to a Cassandra API endpoint. By delving into the details, we list the various components that are fully managed and optimized by the service and no longer require fine grained user intervention to get the most out of Cassandra.
The Write Path
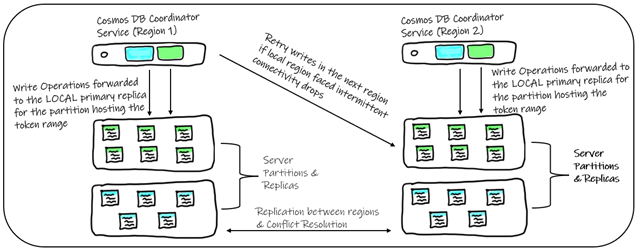
Figure 1: The path followed by a write request in Azure Cosmos DB Cassandra API
When a write operation is initiated by a client to a Cassandra API endpoint on Azure Cosmos DB, the request lands on a distributed and multi-tenant coordinator service. Like a coordinator node in Apache Cassandra, the role of the coordinator service is to determine the physical address of the primary replica hosting the token range for the request. Unlike Apache Cassandra, the coordinator does not need to communicate with all the replicas for the partition. The primary replica for a partition is responsible for persisting the write locally as well as replicating to its secondary replicas to ensure quorum.
In a multi-region Azure Cosmos DB account, the server partition hosting the token range handles replicating to its counterparts in all subsequent regions. By default, the partition responds to the coordinator service immediately after persisting locally, while asynchronous geo-replication is triggered. When Strong consistency is explicitly specified, the server partition triggers a synchronous replication to all other regions. Once confirmed, a response is sent to the coordinator service, which in turn responds to the client.
In a multi-region account with a multi-write setup, if the local server partition does not respond in time, the coordinator service is resilient and retries the request in one of the other regions for the account. Retries are triggered on a per request basis to ensure availability.
Furthermore, the Azure Cosmos DB Cassandra API makes management of writes simpler in several ways:
- Unlike Apache Cassandra, the onus of tuning optimal sizes for commit logs no longer falls on the user as there are no commit logs.
- Unlike Apache Cassandra, memtable memory limits and heap sizes do not need to be managed by the user as there are no memtables.
- The lack of Memtables eliminates the concern of nodes failing before memtables are flushed to disk. Furthermore, the Apache recommended best practice of manually flushing memtables prior to restarting nodes no longer applies as nodes do not need to be managed and restarted manually and are fully abstracted.
- Availability of partitions and replicas is guaranteed by Azure Cosmos DB and there is no need to track anti-entropy operations such as hinted handoffs and read repairs.
- Updates are in-place operations and since there are no SSTables, resources are not consumed by adding tombstones, compacting SSTables or updating bloom filters.
- Lastly, capacity does not need to be monitored by users to ensure data disks do not consume more than half their capacity. Disk and node I/O do not need to be monitored and most importantly, clusters do not need to be scaled out and in to adapt to changing rates of ingestion.
The Read Path

Figure 2: The path followed by a read request in Azure Cosmos DB Cassandra API
When a read request is sent to a Cassandra API endpoint on Azure Cosmos DB, the request once again lands on the coordinator service. The coordinator service uses its cache to retrieve the physical addresses of the underlying server partitions and replicas to correctly route the request.
Like Apache Cassandra, the specified consistency level determines the number of replicas for the partition to which the request is sent. Unlike in the write path where the coordinator service only communicates with the primary replica, for read requests the coordinator service communicates with all the required replicas based on the specified consistency level. Responses are resolved from the required replicas before responding to the application.
Like the write path, if the replicas in the local region are intermittently unavailable, the coordinator service ensures high availability by retrying the request under the covers in one of the remote regions.
Cosmos DB offers additional resiliency and operational efficiency for reads in the following ways:
- The coordinator service is aware of all the regions for the Azure Cosmos DB account. In the event of a local partition becoming unavailable intermittently, retries are executed by the coordinator service against a remote region on a per request basis.
- There are no read repairs. Consistency is maintained on the write path and thus read repairs are not needed to keep data nodes consistent.
- Reads in the Azure Cosmos DB Cassandra API are more efficient as tombstones do not need to be skipped over and SSTables do not need to be compacted.
- Unlike Apache Cassandra, there is no impact of compaction (or lack thereof) on read performance and by extension, no need for specifying a compaction strategy either.
- Bloom Filters do not need to be setup to optimize reading SSTables as SSTables do not exist.
Next Steps
To get started, see:
- Technical documentation: how to adapt to the Azure Cosmos DB Cassandra API from Apache Cassandra
- Blog: autoscaling in the Azure Cosmos DB Cassandra API
- Technical documentation: Apache Cassandra and Azure Cosmos DB consistency levels
Discover additional features and capabilities about Azure Cosmos DB and get started for free.
For up-to-date news on all things, Azure Cosmos DB be sure to follow us on Twitter, YouTube, and our blog.
0 comments