
Overview
We know that Apache Cassandra, a wide-column NoSQL database, is a great option to solve the 3 V’s (Volume, Variety and Velocity) of data requirements. It is a given that data will grow as the business expands. Invariably you will need to expand the cluster to accommodate additional data and handle greater throughput. This load may be difficult to predict.
Apache Cassandra customers experience pain all through the scaling journey. With Azure Cosmos DB Cassandra API, customers experience no such pain because of seamless autoscaling.
The provisioned throughput autoscale feature on Azure Cosmos DB Cassandra API is highly beneficial when the workload is variable or unpredictable. It’s also great when the application is used infrequently or wants to use off-peak or idle time in a better way. Autoscaling also comes handy to check development and test workloads.
Let’s look at some of the challenges with Apache Cassandra, and how Azure Cosmos DB can help:
Capacity Planning
In Apache Cassandra scaling-out and scaling-in processes are extensive, complex, effort intensive and involve constant monitoring. Detailed capacity planning needs to be done to procure and provision the infrastructure to sustain the peak loads. We know that procurement and setting up servers is easier said than done. Also, the infrastructure to sustain the maximum load needs to be always up and running, whether there is full load or no load. On self-hosted clusters this is one of the most critical aspects to be taken care of.
In Azure Cosmos DB Cassandra API, you simply set a max throughput, and the database layer will scale up and scale down automatically and seamlessly with zero to minimal impact to application.
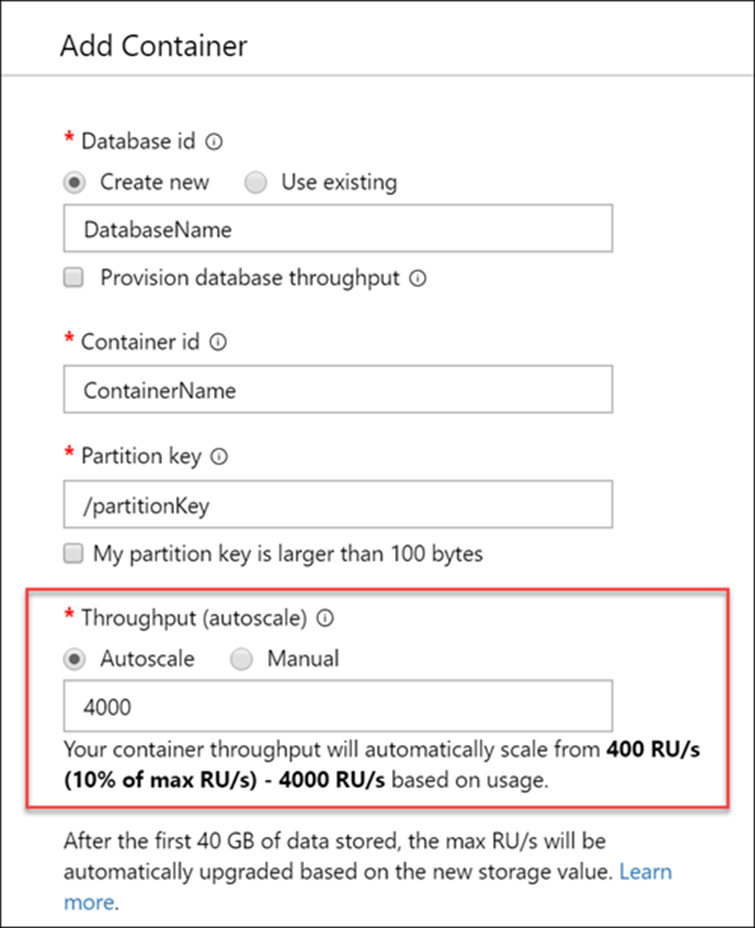
Speed of Scale
Let’s consider a scenario where you need to scale out the cluster by adding more nodes to cater to a major spike in data caused by yearly sale. This may last for a month after which you will go back to business as usual. To add additional nodes, you need to perform several critical steps. Installing the operating system, installing Apache Cassandra, configuring the same (Cassandra.yaml for setting the seed nodes, partitioner, snitch, and network ports), running nodetool commands etc.
These changes are a function of the data workload % increase. For example: Throughput increase from <x> to <y> on the database because of the event we cited above, and then decrease the throughput back to <x> after a month. The process to add new nodes involves:
- Planning to identify the number of nodes
- Planning the family type of nodes to add
- Procuring the nodes based on the above two and hardening them
You have to plan and identify days to add nodes into the cluster. Planning and execution might take several weeks. You need to allow streaming and compaction without restrictions for streaming to happen quickly. This is especially important with large nodes and more data.
On Azure Cosmos DB Cassandra API, once you decide the max throughput (RU/s), you can automatically scale between 10%-100% of the max throughput instantaneously. For example, if you need a max of 50k Ru/s at peak, Azure Cosmos DB Cassandra API autoscales between 5000 and 50000 RU’s as needed. This level of simplicity on open-source Apache Cassandra is hard to achieve. Think of an activity where you reduce from 20 nodes to 2 nodes and then scale back up to 20 nodes in an instant.
Operations Overhead
You can script and automate some of the tasks to bring up a node and add it to the cluster. However the process is complex, time consuming, and required extensive effort. The automation tools are expensive and the written code needs to be maintained and cared for.
Performance goals towards throughput and latency need to be clearly identified and performance tuning needs to be done accordingly. Management of token ranges per node also needs to be done. All these tasks become even more important as the data size in the cluster grows.
It is not a trivial effort to patch the underlying operating system, install hotfixes, install security updates, upgrade Apache Cassandra Version which needs to be done on all the nodes in the cluster, one data center at a time. We have also seen instances where disk outages take weeks to rectify and changing disks across all the nodes takes years to complete.
On Apache Cassandra you need to monitor replication, repair process, tombstone, etc. to make sure the cluster is running optimally. Azure Cosmos DB Cassandra API takes care of these operation pain points easily and seamlessly. You just set an upper bound for throughput and the service handles everything else.
Cost Reduction
In most cases, there is a direct benefit of cost reduction with Azure Cosmos DB Cassandra API. You just need to set preset limits for scale. When you have an increased workload, keyspaces and tables automatically scale the provisioned throughput up to the max limit as needed. There is no disruption to client connections, applications, or impact to Azure Cosmos DB SLAs. And, when the workload is reduced, autoscaling helps optimize your RU/s usage and cost usage by scaling down when not in use. You only pay for the resources that your workload needs on a per-hour basis with detailed metrics explaining the usage. Billing is transparent and predictable for a given workload.
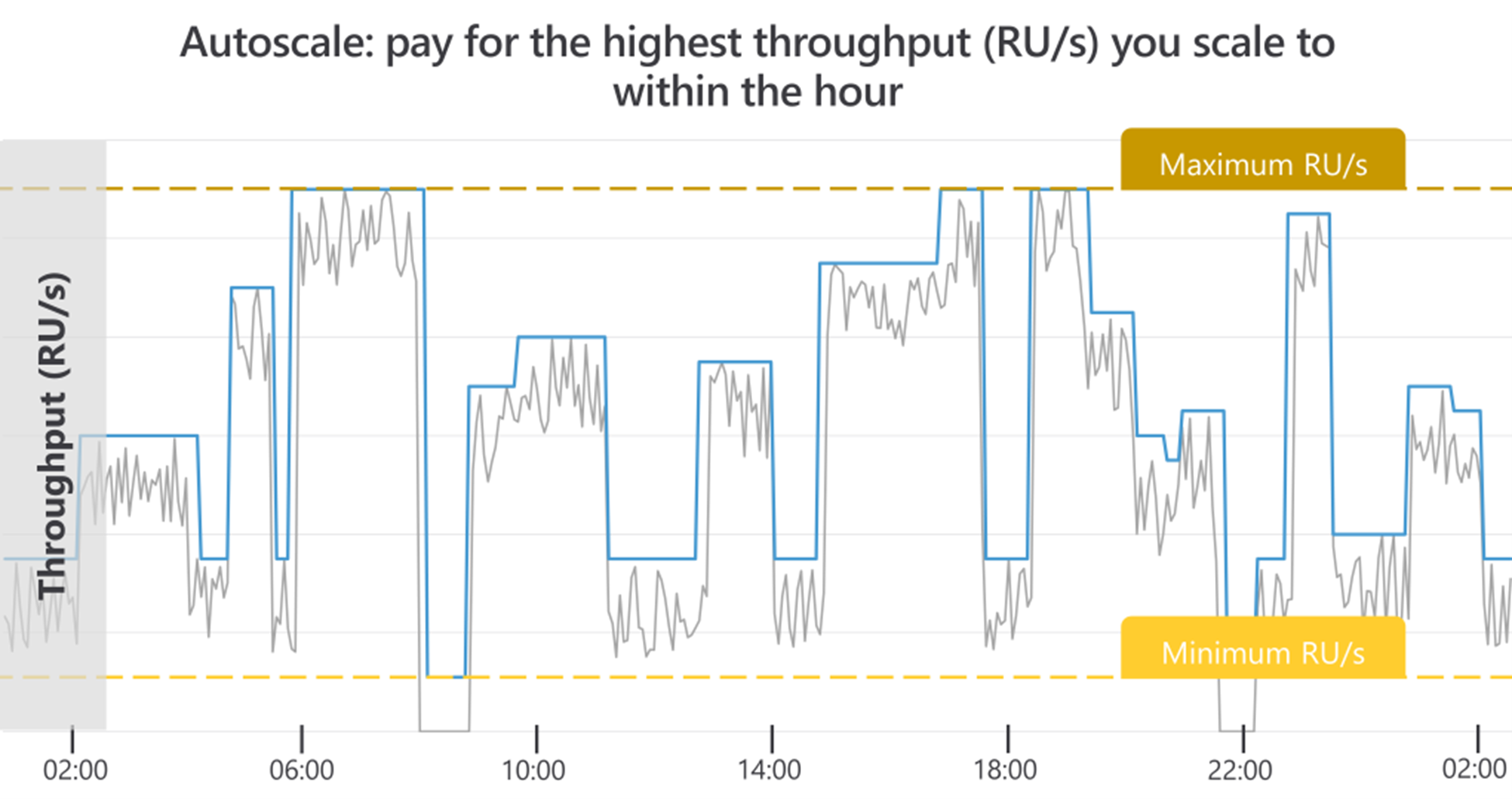
If you set the provisioned throughput autoscale max RU/s Tmax and use the full amount Tmax for 66% of the hours or less, it’s estimated that you’ll save with autoscaling. You can provision throughput manually for predictable and continuous high usage load.
With Azure Cosmos DB Cassandra API, you have better control to handle resource churn.
Conclusion
The provisioned throughput autoscale feature in Azure Cosmos DB allows you to scale the throughput (RU/s) of your database or container automatically and instantly. It is ideal in situations where you have unpredictable workloads but still need predictable SLA’s. This simple and scalable solution reduces management complexity and helps optimize costs. You don’t compromise on benefits of Azure Cosmos DB with respect to high availability.
Next steps and More to explore!
Request Units as a throughput and performance currency in Azure Cosmos DB | Microsoft Docs
Create Azure Cosmos containers and databases in autoscale mode. | Microsoft Docs
Frequently asked questions on autoscale provisioned throughput in Azure Cosmos DB | Microsoft Docs
An excellent write-up that summarizes the advantages available in this easy-to-adopt capability.
This is a nice write-up. The “Autoscale feature” will greatly benefit Cassandra users along with the added advantages that is popular with Azure Cosmos DB.