

This post was authored by Microsoft MVP and Azure Cosmos DB community champion Blaize Stewart. You can reach Blaize (@theonemule) on Twitter.
Software developers of all kinds love patterns. They give us reusable ideas that can be applied in many different contexts. We also have antipatterns: bad practices and habits that crop up enough to become patterns but should be avoided.
Developing with Azure Cosmos DB is no exception. Over the last few years, I have encountered many different problems in working with folks on Azure Cosmos DB. I am not exactly sure why these have been so common, but I suspect it may have something to do with Azure Cosmos DB being easy to create and use. When things tend to be easy, people tend to gloss over important details. It reached the point where I would almost just check these things when looking at a database, even if they were not experiencing problems.
In some cases, even “good” databases had issues with them. They may not have been problematic at the time, but they might have been at some point. Regardless of how one arrives at these problems, most of them are easy to avoid up front, but hard to fix once a database has matured. So here are a few common things to look for and how to avoid them.
This blog post will cover the following subjects:
- Antipattern 1: Choosing a partition scheme that does not work for your data
- Antipattern 2: Not understanding the consistency models
- Antipattern 3: Bad query patterns
- Antipattern 4: Using Cosmos DB for OLAP
- Antipattern 5: Not using the SDKs correctly
Antipattern 1: Choosing a partition scheme that does not work for your data
Partitioning on Azure Cosmos DB can make or break database performance. Data on Cosmos DB is partitioned to enable the databases on the platform to scale well horizontally, contain huge amounts of data, and perform well with high concurrency. When data is partitioned, work can be spread across multiple storage and compute nodes to accelerate queries. The results are brought back together from the partitions and returned to a calling application. The problem, however, is that Azure Cosmos DB does not and cannot know beforehand how it ought to distribute the data when data is written, so it falls to the users to tell Azure Cosmos DB how the data will be stored. Data is best partitioned by how it is most likely to be used and in a way that will enable data to be evenly distributed across the nodes for a database when designing for write-heavy workloads, or co-located on a single partition when designing for read-heavy scenarios. If one does not take the time to consider the implications of a partition key, a database can end up with grossly unbalanced partitions and perform poorly under load.
If you’re unsure what to use, this is okay but not optimal. You can use a generated ”id” and assign that “id” as the partition key. This will distribute the evenly across partitions. If you create the database in the portal, the default key is “id”, and the SDK will automatically generate a GUID for this key if a value is not assigned by your code. Alternatively, users can create a property called “partitionKey” for the partition key. This allows users to create a new document from an existing one with a different partition key in the same container.
For read-heavy scenarios, one should partition a database by something that supports how the data is most often read . Suppose an application tracked customer data by region, and most of the application requests against the database filtered the data by region or within a region. In this scenario, a partitioning scheme that used a region ID as a partition key would be conducive to the application. Each request made against the data would include the partition key, and Azure Cosmos DB would be able to accelerate queries using the key because it does not have to partition spanning queries or aggregate data from multiple partitions before returning results.
Another common scheme for smaller datasets is to use a single partition for all the data. This works well because every query is routed to the same partition like how a well partitioned database works. For reference data, you may want to consider adding a “type” property to the document. You can use a single partition on a single container for multiple kinds of data in that case, which saves on RU’s.
Conversely, for write-heavy workloads, choose a key that distributes the data across partitions. The more values that one can associate with this partition key, the more it can be spread.
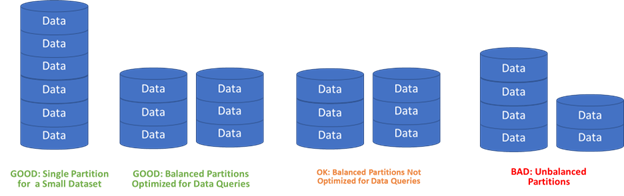
Whatever you use for a partition key, ensure it works for your data. Do not skip this – take the time to consider the impact it will have your database!.
Antipattern 2: Not understanding the consistency models
Azure Cosmos DB offers five consistency models. Each has different implications on how well a database scales, data availability, and data consistency. These govern how data replication works in a disturbed system. Not taking time to understand this can profoundly impact database performance and scalability.
Consistency is all about when writes show up for reading. Most developers that have worked with databases in the past are used to strong consistency because it is the default on many RDMS databases like SQL Server, MySQL, or Oracle. Strong consistency means that data is readable as soon as a write completes. If I update a database, there’s no chance that any read against that record by a subsequent query will read a previous version of the data. Strong consistency works great when a database is running a smaller database, and all the database nodes are on a LAN with high-speed connections that link them all together. It does not, however, work well when a database has to scale across geographic space. Writes take time, and the more distance data must travel, the more latency it introduces to writes in a database. Some databases loosen their promises on consistency to allow a write transaction to complete before a write propagates to all the nodes in a database. This creates a small window of time that a read on a node that has not received the write might get an previous of the data. The tradeoff, however, allows databases to scale with high concurrency and provide high availability across geography. Stronger consistency has tradeoffs though. Stronger consistency usually means less throughput on the database because write transactions can take longer.
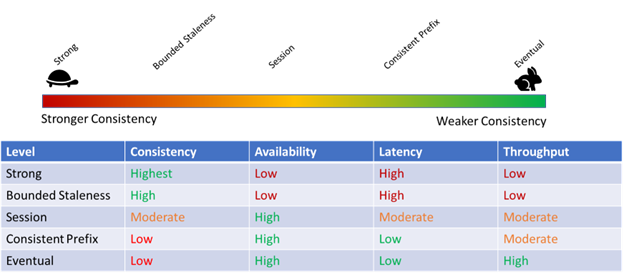
Fortunately for most, the default consistency model on Azure Cosmos DB, session consistency, keeps this from becoming a big problem. The problems arise, however, when a Cosmos DB user does not take the time to consider the implication that consistency has on the database. If performance, throughput, and availability are a database’s goals, strong consistency will work against these goals. If data consistency is the case, then a weaker consistency model, like eventual consistency, will work against the goals.
The bottom line is understanding the implications for consistency models and how they will impact an application. As a rule, prefer weaker consistency (I prefer eventual consistency) until one has a reason to turn on strong consistency. It all comes down to how the data is used, though.
Antipattern 3: Bad query patterns
Query performance in an Azure Cosmos DB database depends heavily on partitioning. But next to that, it depends heavily on indexing as well. By default, everything is indexed, so it’s not something that one has to turn on like one might do in SQL Server or another database. Even so with indexing enabled, some bad query patterns can really kill performance because they either fan out across partitions, don’t leverage the indexes, or both.
- Best: Index queries in a single partition. If a query can run in a single partition against indexed data, odds are the query will not only run fast, but will also be cheap in terms of RU’s consumed. This is why it’s essential to partition data appropriately. When you do query data, even if the indexed data is all in a single partition, include the partition key as part of the query, so Azure Cosmos DB does not assume that you want to do a partition-spanning query.
- Okay: Indexed queries across partitions. I have harped on partitioning here for a while because it is important for reading data, but it’s almost impossible to come up with a partition key that will work for every query. Sometimes, you need to query across partitions, but these queries should be the exception, not the rule. If you often need to query data across partitions, sometimes it’s more performant and cost efficient to copy the data to a second container with a different partition key and keep it in sync using change feed and use that to serve the query. Storage is cheaper than RU’s. In any case, prefer single partition indexed queries, and if you have to do cross-partition queries, ensure the data is indexed.
- Bad: Unindexed queries in a single partition. These queries will probably work, but you can avoid these. An unindexed query is a query that runs across data that must first be converted or transformed in some way before the query engine applies a filter. Consider the following query: “SELECT * FROM c WHERE c.Id = ‘ABC’ AND pk = ‘XYZ’”. This query is fine. There’s no conversion. Change it slightly: “SELECT * FROM c WHERE UPPER(c.Id) = ‘ABC’ AND pk = ‘XYZ’” This query will work, but now the search on field “Id” is no longer using an index because the query engine has to convert the value using “UPPER” to compare it to the literal, “ABC.” This is slow and will cost a fortune with RU’s. Again, storage is cheaper than RU’s. Store the data in a converted alongside the original form or something like that; that way, the indexer will index the fields. There are other strategies to mitigate this, but the bottom line is to ensure that your querying data is using indexed fields rather than unindexed fields.
- Terrible: Unindexed queries across partitions. Just do not. For all the reasons mentioned above, avoid it at all costs.
Antipattern 4: Using Azure Cosmos DB for OLAP
Azure Cosmos DB is a fantastic tool. It supports all sorts of database paradigms, but at its heart, especially for the Core (SQL) API, API for MongoDB, and Gremlin API, Azure Cosmos DB is a transaction-oriented database, sometimes called an Online Transaction Processor (OLTP). The engine performs best for record-level operations, and the database stores data in a way that is more conducive to record-level operations.
Sometimes, however, data needs to be presented in a way that is more conducive to summaries (like averages, time series data, sums, aggregates, etc.) for reporting and other analytical purposes. Databases that support these workloads are called Online Analytics Processors (OLAP). Cosmos DB has the column-store database paradigm with Cassandra that supports big data workloads, but it is not an OLAP tool. OLAP and column store databases store data optimized for reads across columns of data rather than each record. This way of storing data makes doing cross-record operations more efficient and faster. Still, you would not want to use Cassandra or any other paradigm in Cosmos DB for OLAP purposes.
While Azure Cosmos DB can do data summaries and aggregates, it’s not optimized for that. The Azure Cosmos DB team, however, has made it easy to feed data from the document databases into Azure Synapse through the Azure Synapse Link. This takes data from Azure Cosmos DB and creates a column-store copy that Synapse can use for analysis. This turnkey solution ensures the user does not have to create ETL jobs to do this work.
Synapse link is one solution, but another may be just to store data in another container in an aggregated form. The secondary copy is created by an ETL job using a tool like Data Factory from the primary, unaggregated copy of the data. The secondary copy is sometimes called a “speed layer” because the database does not have to perform heavy calculations.
Whatever you do, try to avoid using Azure Cosmos DB for summarizing and aggregating data. This might be okay for small, highly filtered queries but summarizing documents across an entire container is costly and inefficient. OLAP or ETL solutions, not Azure Cosmos DB, should do this.
Antipattern 5: Not using the SDKs correctly
The Azure Cosmos DB SDKs are your friend because they take the edge off working with Azure Cosmos DB. Behind the scenes, the SDK performs many background tasks that take care of much of the handshaking, session tracking, and metadata refreshing that would otherwise be done manually without the SDKs.
However, the help the SDKs provide comes with a set of assumptions—they must be set up correctly to reap the benefits they provide. One of the developers’ biggest mistakes with Azure Cosmos DB is not reusing a database connection. Instead, each time they need to make a new request to the database, the user will instantiate a new connection client, run a query, then forget about the client, hoping that the garbage collector will pick it up. The problem, however, is that the Azure Cosmos DB SDKs want you to keep the connection and reuse it. If a user is creating a new instance each time, behind the scenes, the SDK is starting the maintenance tasks again and again in a way that could result in thread exhaustion, port exhaustion, memory leaks, or any number of bad behaviors that are hard to detect.
Preventing this is simple: create a single instance of the client. A singleton pattern for the client is a great way to handle this. Many dependency injection frameworks support singletons as well. Creating the client and then passing around the single instance ensures that the application only has a single copy and will avoid anomalous behaviors.
Conclusion
So, these are just five Azure Cosmos DB antipatterns. What antipatterns have you seen? In any case, avoiding these things and taking steps to mitigate them will help ensure your Azure Cosmos DB databases and your consuming application are working well. If you would like to see even more about Azure Cosmos DB anti-patterns, watch the Azure Cosmos DB Live TV video on YouTube for a full conversation with Mark Brown and Blaize Stewart. Azure Cosmos DB Live TV streams Thursdays at 1 PM PT / 4 PM ET, and every episode is available on-demand.
About Azure Cosmos DB
Azure Cosmos DB is a fast and scalable cloud database for modern app development. See how to get started, dev/test, and run small production workloads free.
Get product updates, ask questions, and learn more about Azure Cosmos DB by following us on LinkedIn , YouTube, and Twitter.
About Blaize
Blaize is a Microsoft Azure MVP, Azure Architect, and Microsoft MCT. He specializes in apps on Azure, working with migrations and greenfield apps on IaaS, PaaS, and databases of all kinds. Blaize has been interested in software development since childhood. Blaize has loved teaching about technology too. Blaize loves to spend time with his wife and girls. He also enjoys various activities, including reading, writing, photography, cycling, guitar, language learning, and travel.
Isn´t the first antipattern not understanding Request Units ? That´s lesson one for every new developer to Cosmos.