
Hello prompt engineers,
Over the last few weeks, we’ve looked at different aspects of the new OpenAI Assistant API, both prototyping in the playground and using Kotlin in the JetchatAI sample. In this post we’re going to add the Code Interpreter feature which allows the Assistants API to write and run Python code in a sandboxed execution environment. By using the code interpreter, chat interactions can solve complex math problems, code problems, read and parse data files, and output formatted data files and charts.
To keep with the theme of the last few examples, we are going to test the code interpreter with a simple math problem related to the fictitious Contoso health plans used in earlier posts.
Enabling the code interpreter
The code interpreter is just a setting to be enabled, either in code or via the playground (depending on where you have set up your assistant). Figure 1 shows the Kotlin for creating an assistant using the code interpreter – including setting a very basic system prompt/meta prompt/instructions:
val assistant = openAI.assistant(
request = AssistantRequest(
name = "doc chat",
instructions = "answer questions about health plans",
tools = listOf(AssistantTool.CodeInterpreter), // enables the code interpreter
model = ModelId("gpt-4-1106-preview")
)
)
Figure 1: enabling the code interpreter in Kotlin when creating an assistant
As discussed in the first Kotlin assistant post, JetchatAI loads an assistant definition that was configured in the OpenAI playground, so it’s even easier to enable the Code interpreter by flipping this switch:
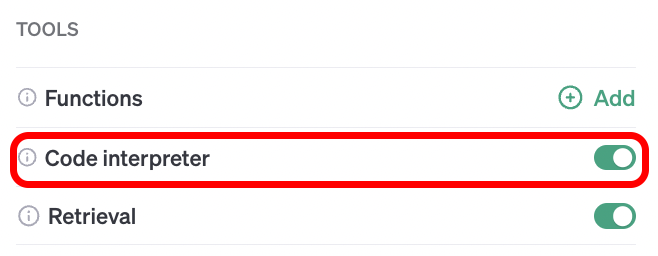
Figure 2: enabling the code interpreter in the OpenAI playground
Extending JetchatAI #assistant-chat
With the code interpreter enabled, we can test it both interactively in the playground and in the JetchatAI app. The test question is “if the health plan costs $1000 a month, what is deducted weekly from my paycheck?”.
The playground output includes the code that was generated and executed in the interpreter – in Figure 3 you can see it creates variables from the values mentioned in the query and then a calculation that returns a value to the model, which is incorporated into the response to the user.

Figure 3: Testing the code interpreter in the playground with a simple math question (using GPT-4)
Notice that the code interpreter just returns a numeric answer, and the model decides to ‘round up’ to “$230.77” and format as a dollar amount.
When implementing the Assistant API in an app, the code interpreter step (or steps) would not be rendered (in the same way that you don’t render function call responses), although they are available in the run’s step_details data structure so you could still retrieve and display them to the user, or use for logging/telemetry or some other purpose in your app.
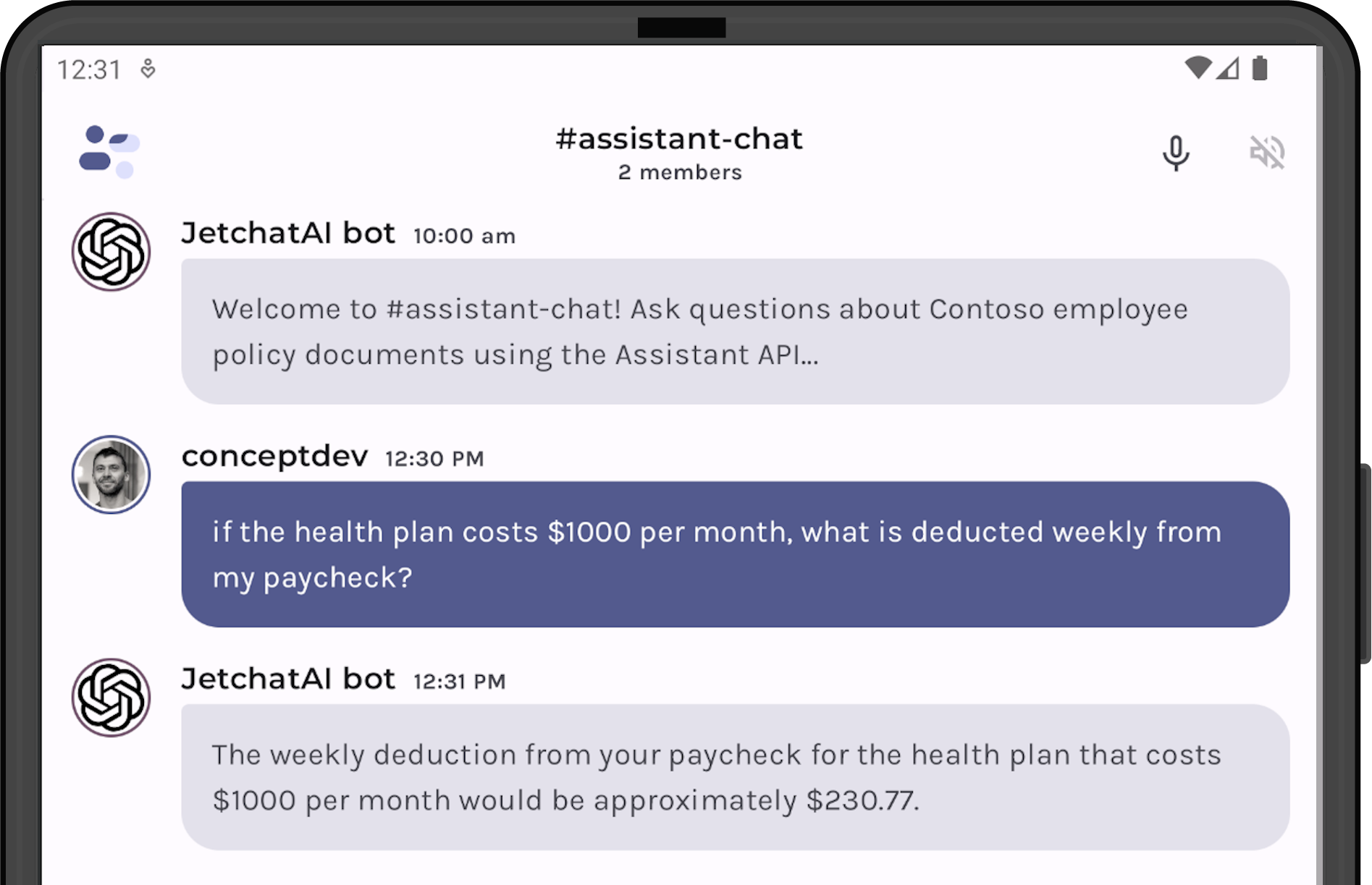
Figure 4: Testing the same query on Android (also using GPT-4)
No code changes were made to the JetchatAI Android sample for this testing, it just needs the Assistant’s configuration updated as shown.
Why add the code interpreter?
One of the reasons that the code interpreter option exists is because LLMs “on their own” can be terribly bad at math. Here are some examples using the same prompt on different models without a code interpreter to help:
- GPT 3.5 Turbo playground – answers $250
- GPT 4 playground – answers $231.17
- ChatGPT – answers $231.18
The full response for each of these is shown below – I included the ChatGPT response separately because although it’s likely using similar models to what I have access to in their playground, it has its own system prompt/meta prompt which can affect how it approaches these types of problems. All three of these examples appear to be following some sort of chain of thought prompting, although they take different approaches. While some of these answers are close to the code interpreter result, that’s probably not ideal when money’s involved! How chat applications respond to queries with real-world implications (like financial advice, for example) is something that should be evaluated through the lens of responsible AI – remember this is just a fictitious example to test the LLM’s math skills.
GPT 3.5 Turbo playground (without code interpreter)
GPT 3.5 Turbo attempts to ‘walk through’ the calculation, but doesn’t seem to understand all months will not necessarily contain exactly two pay days. At least the response includes a disclaimer to consult HR or payroll to verify!

Figure 5: output from gpt-3.5-turbo for the same query
It’s worth noting that when the code interpreter is enabled with gpt-3.5-turbo in the playground, it returns $230.77 (just like gpt-4 with the interpreter does in Figures 3 and 4).
GPT 4 playground (without code interpreter)
Using the GPT 4 model results in a different set of steps to solve, but unlike the code interpreter which multiplies out the total cost first, this solution calculates the average number of weeks in a month. The first mistake is that value is 4.3(repeating), and by rounding to 4.33 it will get a slightly different answer. The second mistake is that $1000/4.33= 230.9468822170901; however it returns a result of $231.17 which is about 22 cents different to what the rounded answer should be. It also includes a disclaimer and advice to confirm with HR or payroll.
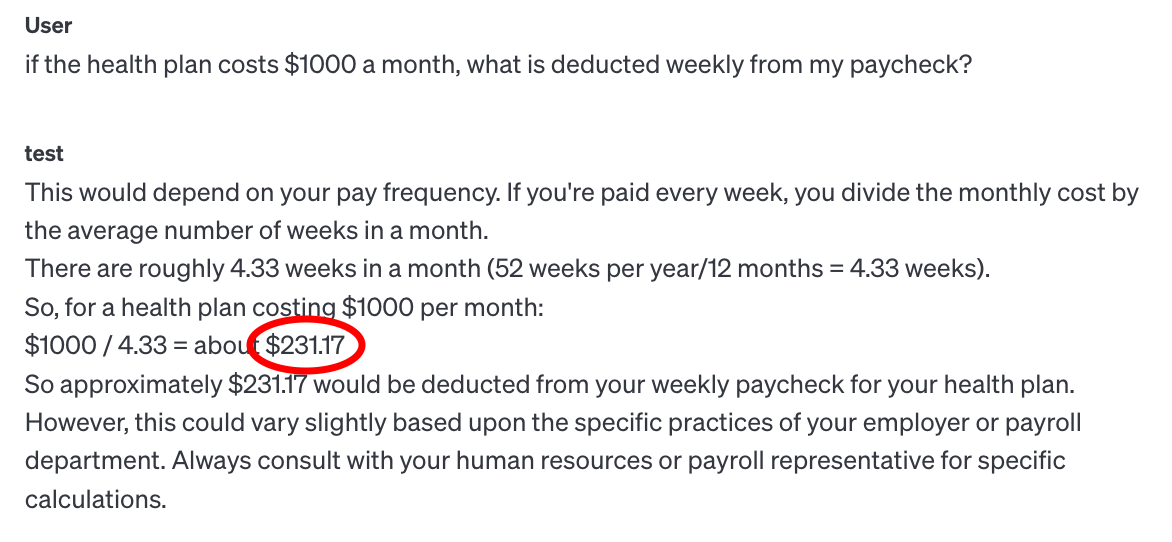
Figure 6: output from gpt-4 for the same query
ChatGPT (public chat)
The public ChatGPT follows similar logic to the GPT-4 playground, although it has better math rendering skills. It makes the same two mistakes, first rounding an intermediate value in the calculation, and then still failing to divide 1000/4.33 accurately.
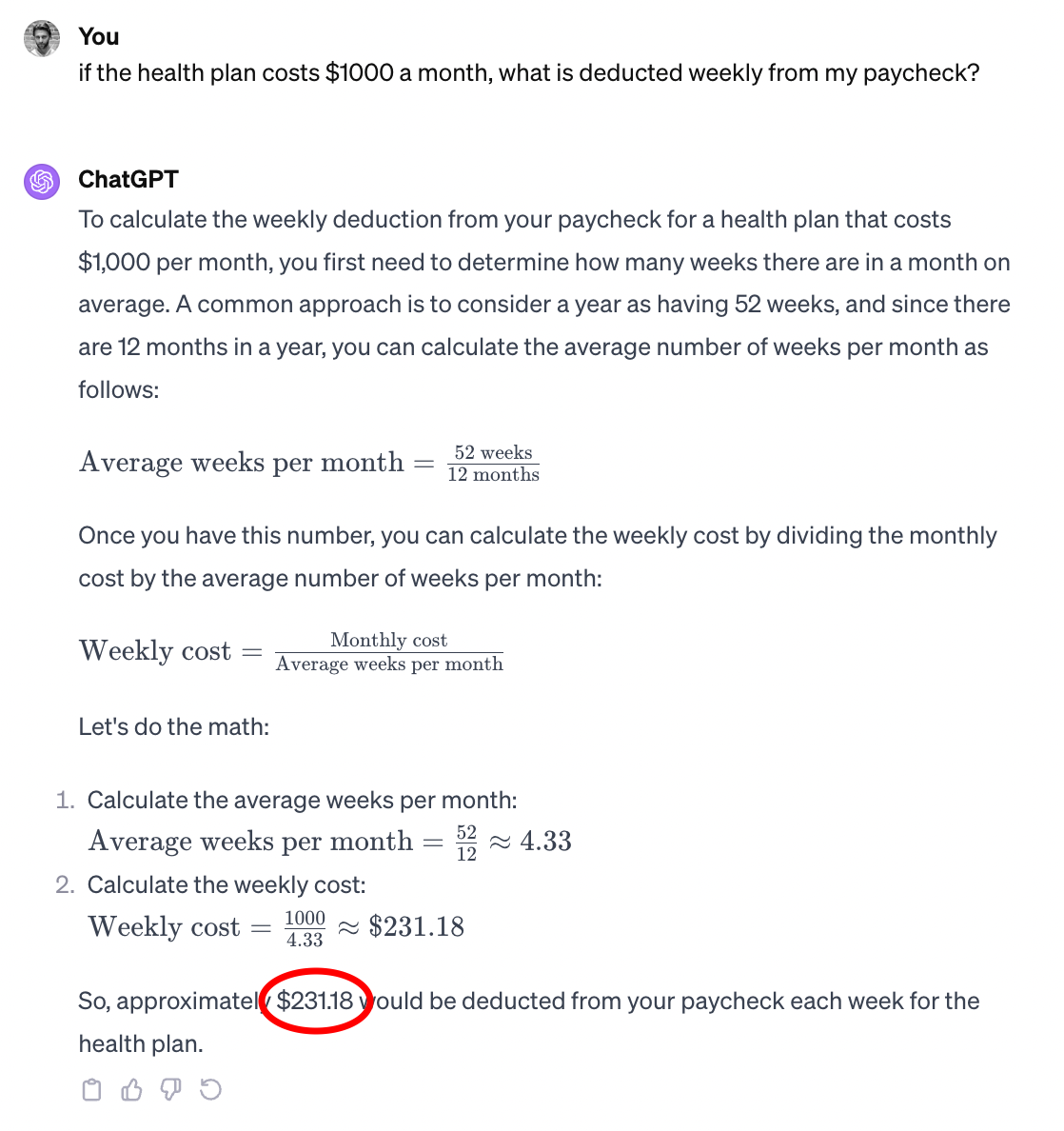
Figure 7: output from ChatGPT for the same query
Summary
OpenAI models without the code interpreter feature seem to have some trouble with mathematical questions, returning different answers for the same question depending on the model and possibly the system prompt and context. In the simple testing above, the code interpreter feature does a better job of calculating a reasonable answer, and can do so more consistently on both gpt-4 and gpt-3.5-turbo models.
Resources and feedback
Refer to the OpenAI blog for more details on the Dev Day announcements, and the openai-kotlin repo for updates on support for the new features like the Assistant API.
We’d love your feedback on this post, including any tips or tricks you’ve learned from playing around with ChatGPT prompts.
If you have any thoughts or questions, use the feedback forum or message us on Twitter @surfaceduodev.
0 comments