
Hello prompt engineers,
A few weeks ago we talked about token limits on LLM chat APIs and how this prevents an infinite amount of history being remembered as context. A sliding window can limit the overall context size, and making the sliding window more efficient can help maximize the amount of context sent with each new chat query.
However, to include MORE relevant context from a chat history, different approaches are required, such as history summarization or using embeddings of past context.
In this post, we’ll consider how summarizing the conversation history that’s beyond the sliding window can help preserve context available to answer future queries while still keeping within the model’s token limit.
The test case
In the droidcon sample, one possible query that requires a lot of historical context could be “list all the sessions discussed in this chat”. Ideally, this would be able to list ALL the sessions in the conversation, not just the ones still mentioned in the sliding window. To test this, we’ll need to first chat back-and-forth with the model, asking questions and getting responses until the sliding window is full.
An interesting side-effect of all the features we already added is that queries like this trigger the
AskDatabaseFunctionfrom Dynamic Sqlite queries with OpenAI chat functions. The model generates aSELECT * FROM sessionsquery and attempts to answer with ALL the sessions in the database. For simplicity, I have commented-out that function in DroidconEmbeddingsWrapper.kt for the purposes of testing the history summarization feature discussed in this post. Tweaking the prompt for that function will be an exercise for another time…
To make testing easier, I wrote a test conversation to logcat and then hardcoded it to simulate a longer conversation (the initial generation of the test data proved that the ‘history accumulation’ code worked). The test conversation can be seen in this commit.
Summarizing the message history
Older messages that exist outside of the sliding window need to be ‘compressed’ somehow so that they can still be included in API calls but under the token limit. To perform this ‘compression’, we will do an additional LLM completion to generate a summary of as many messages as we can that fit inside a separate completion request (which will be limited by its own maximum token size).
The message history will be plain text formatted, so the responses will be prefixed with “USER:” or “ASSISTANT:”. Here’s an example of the format:
USER: are there any sessions about AI? ASSISTANT: Yes, there is a session about AI titled “AI for Android on- and off- device” presented by Craig Dunn, a software engineer at Microsoft. The session will take place on June 9th at 16:30 in Robertson 1. USER:...
Figure 1: Example text representation of chat history
Conversation history like this, that extends beyond the sliding window, is what we need to succinctly summarize to keep ‘context’ while still using our token limit efficiently.
NOTE: the prompt used to generate the summary will have a big impact on the success of the feature. With this in mind, I tested a number of different prompts directly in the OpenAI Playground before working on the Android sample in Kotlin.
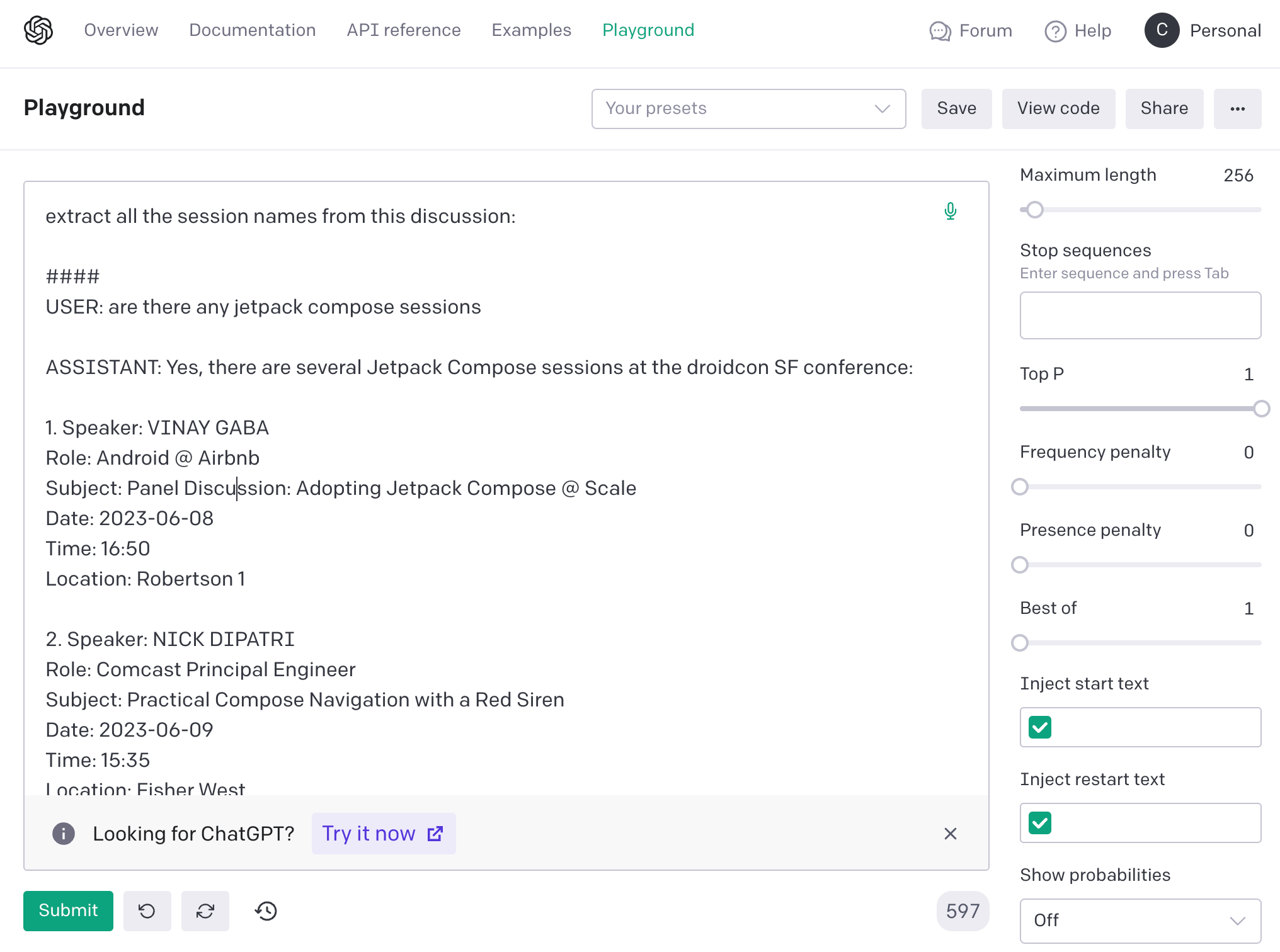
Figure 2: OpenAI playground showing the summary prompt testing
The following table shows some of the different prompts that were tested on the hardcoded sample conversation:
|
Prompt |
Summarized text |
|
Summarize the following conversation and extract key points: <CONVERSATION> |
The droidcon SF conference will feature several Jetpack Compose and Gradle sessions. Jetpack Compose sessions will be held on June 8th and 9th, with speakers VINAY GABA, NICK DIPATRI, ALEJANDRO SANCHEZ and TASHA RAMESH, while Gradle sessions will be held on June 8th and 9th, with speakers NELSON OSACKY, IURY SOUZA and AURIMAS LIUTIKAS. |
|
Summarize the following conversation and extract key points, especially from USER: <CONVERSATION> |
The user asked if there were any Jetpack Compose and Gradle sessions at the droidcon SF conference. The assistant provided five sessions for Jetpack Compose and three sessions for Gradle. The user was provided with information regarding the speakers, topics, dates, times, and locations of the sessions. |
|
Extract all the session names from this discussion: <CONVERSATION> |
Jetpack Compose sessions: |
Figure 3: testing different prompts for the best summarization of message history
In this test scenario the message history consisted of 502 tokens, and the summaries range from 60-100 tokens. This suggests we can get at least five times as much ‘information’ into our chat context by summarizing it!
Choose a prompt that gives you the summary that seems most useful for the types of questions you expect the user to ask. For the droidcon conference chat, the last prompt seems to produce the most useful output – the chat will retain a record of all the sessions that were previously discussed. A more open-ended chat application might prefer one of the other prompt styles.
To actually generate the summary, the code will call the OpenAI completions API, totally independently of the ongoing chat API calls. This is done using the completion endpoint to summarize text that was covered in a blog post in April. The new SummarizeHistory.summarize function is shown in Figure 4:
suspend fun summarize(history: String): String {
val summarizePrompt = """Extract all the session names from this discussion:
#####
$history
#####""".trimMargin()
// send the function request/response back to the model
val completionRequest = completionRequest {
model = ModelId(Constants.OPENAI_COMPLETION_MODEL)
prompt = summarizePrompt
maxTokens = 500
}
val textCompletion: TextCompletion = openAI.completion(completionRequest)
return textCompletion.choices.first().text
}
Figure 4: Code to summarize the message history using OpenAI
This summarize is called from the SlidingWindow.chatHistoryToWindow function, where the loop through the message history has been updated. Instead of break when the sliding window is full, the loop now concatenates older messages into a string format which is sent to the summarize function.
Once the older messages have been concatenated into the messagesForSummarization variable, they are summarized using the method shown above and then wrapped in further instructions so that the model knows the ‘meaning’ of the summarized data:
val history = SummarizeHistory.summarize(messagesForSummarization)
val historyContext = """These sessions have been discussed previously:
$history
Only use this information if requested.""".trimIndent()
Figure 5: the summarized history is wrapped in a prompt message to help the model understand the context
Without the additional prompt instructions, the model is prone to using the data in the
$historyto answer every question the user asks… i.e. a form of “hallucination”! As with all prompt instructions, small changes in wording (or changing the model you use) can have a big effect on the output.
Where to reference the summary
Now that we have a historical context summary, we need to pass it back to the model in subsequent API calls. There are at least three options for where in the chat API we could insert the summary, each of which could behave differently depending on your prompts and model choice:
- System prompt
- Insert as the oldest user message
- As grounding for the current user query
It’s not clear that any of these options are superior to the others; it’s more likely to be dependent on the model you are using, your built-in prompts, and the user queries! The options are discussed below:
System prompt
The system prompt seems like an ideal place to include additional context. However, some models (e.g., GPT 3.5) do not give as much weight to this context as others. Testing will be required to see if context added here is ‘observed’ in completions or whether it is ignored (for your application’s specific use case).
“First/oldest” user query
Sending the history summary as the first/oldest message reflects the fact that the data was earlier in the conversation (prior to being summarized). In theory, this suggests the model should give the same “level of consideration” as the original (longer) message history when generating new completions.
Current user query
If either of the first two methods fail to cause the summary to be referenced effectively, adding to the current user query as additional grounding should cause it to be considered when the model formulates its answer. The downside may be that it’s considered more important than other context within the sliding window, resulting in confusing responses.
Further research
In addition to conducting testing with your scenarios, there is also more general research available on how models use the context, such as the paper Lost in the Middle: How Language Models Use Long Contexts, which discusses a bias in responses towards information at the beginning or end of the context.
Add the summary to the chat
For this demonstration, I’ve chosen the first option – to add the history summary to the system prompt. The updated code is shown in figure 6:
if (history.isNullOrEmpty()) { // no history summary available
messagesInWindow.add(systemMessage)
} else { // combine system message with history summary
messagesInWindow.add(
ChatMessage(
role = ChatRole.System,
content = (systemMessage.content + "\n\n" + historyContext)
)
)
}
Figure 6: if a history summary exists, add it to the system prompt
It works!
The screenshot below shows a conversation where the most recent chat response (about an AI session), as well as Gradle and Compose sessions from the summarized history, are all included in response to the test query “list all the sessions discussed in this chat”:
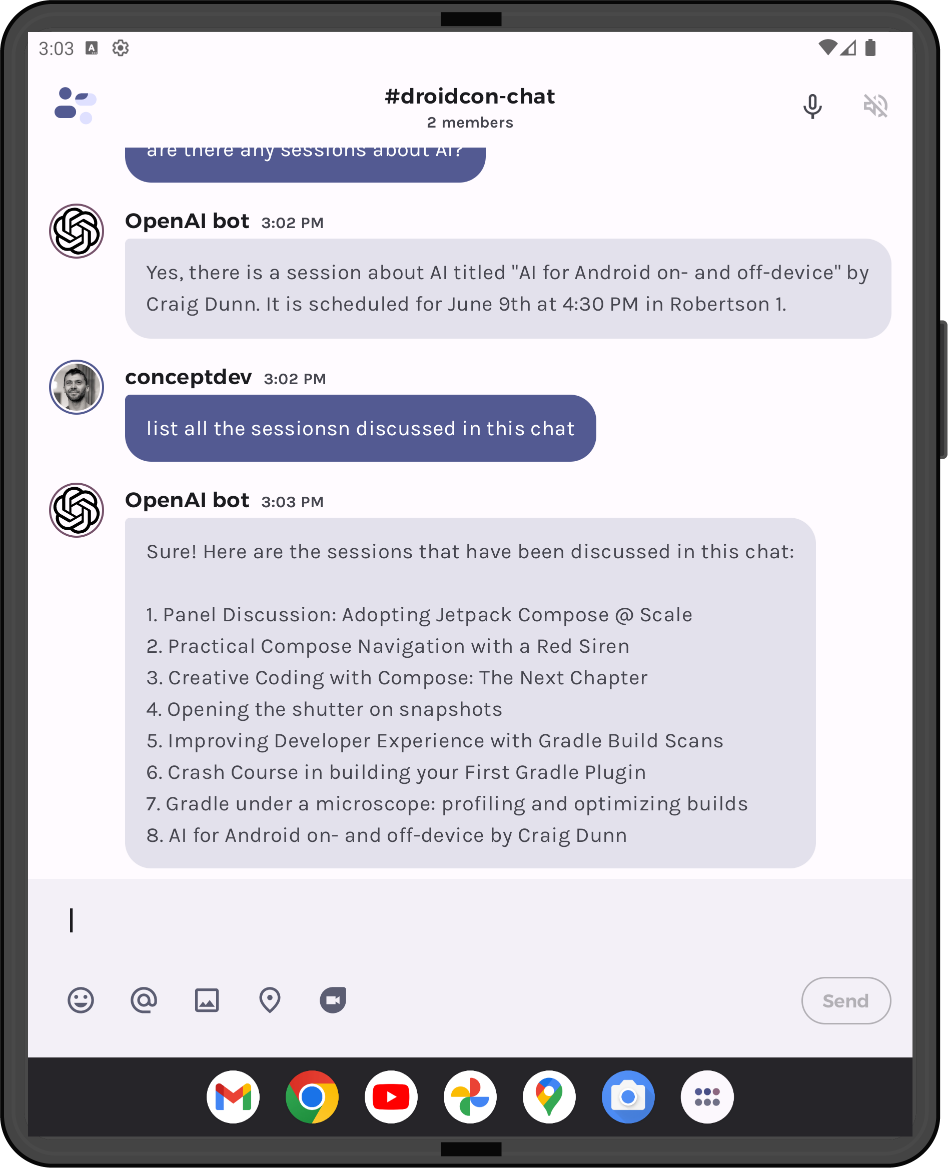
Figure 7: a question about all sessions in the chat includes both the most recent response AND sessions from the summarized history
If you look closely at the response, you’ll notice that only the 8th session includes the presenter name. This is a good indication that the summarized history in combination with recent messages is being used to generate this response – in the history summary example above, you can see that only the session names are included and not the speakers.
Test different types of query to verify that the historical context is being used, for example “what was the first session mentioned?” correctly responds with the “Panel Discussion: Adopting Jetpack Compose @ Scale” from the summarized history.
One last thing…
Scaling the summarization process as the history grows really long will require repeated API calls which could end up potentially summarizing summaries. Although the concept of summarizing history to keep some context can probably work for a given amount of history, ultimately the token limit will mean that eventually historical information will be lost/forgotten.
While summarization might be a good solution to extend the amount of content remembered for some chat conversations, it can’t be relied upon to support a true “infinite chat”. For another possible solution, the next post will discuss embeddings as a way to recall past chat interactions.
Resources and feedback
The OpenAI developer community forum has lots of discussion about API usage and other developer questions. In particular, it discusses how the OpenAI completions API is now considered legacy, and for performance and cost reasons the chat model is preferred (either gpt-3.5-turbo or gpt-4).
The code added specifically for this blog post can be viewed in pull request #13 on the sample’s GitHub repo.
We’d love your feedback on this post, including any tips or tricks you’ve learned from playing around with OpenAI.
If you have any thoughts or questions, use the feedback forum or message us on Twitter @surfaceduodev.
There will be no livestream this week, but you can check out the archives on YouTube.
0 comments