
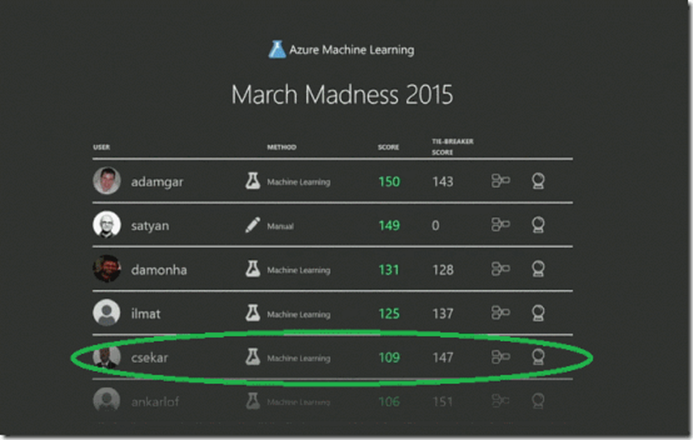
Chandra Sekar, Senior Application Development Manager, shares how his simple exploration into Azure Machine Learning quickly produced an accurate predication of March Madness.
If you watched the Day 2 BUILD keynote you might have noticed Joseph Sirosh, CVP-Machine Learning, talking about an internal hackathon where competitors used Azure ML to predict the 2015 March Madness bracket. So how hard was it to develop an algorithm and generate a bracket which got me onto the leaderboard? I am not a data scientist but I have passion for machine learning and Azure ML have peaked my interest. I entered the contest just for a learning experience.
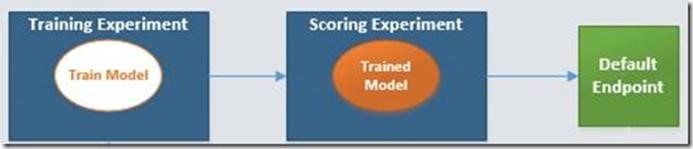
Azure ML allows users to publish trained Machine Learning models as web services to quickly operationalize their experiments. The first step in the process is creating a Training experiment to train a model. The trained model is then published as a web service using a Scoring experiment. The end-result of this process is a “default endpoint”.
To begin, Sign into ML studio and watch the get started videos and you will be on the way to creating your own first machine learning experiment.
To get the NCAA Bracket prediction I used a standard classification algorithm “Two-Class Boosted Decision tree” and fed the historical NCAA tournament data.
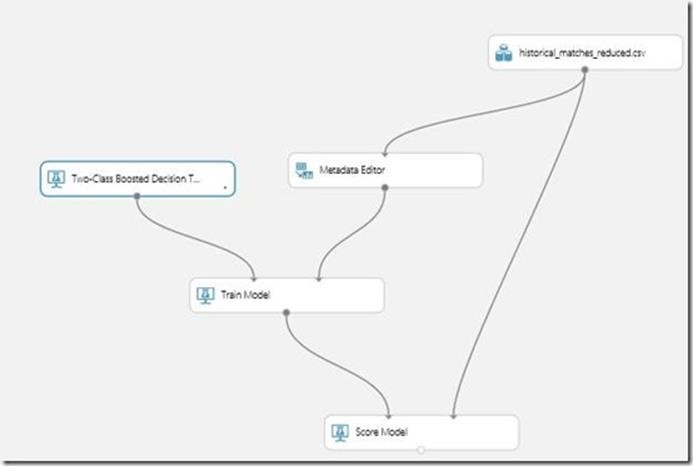
When I scored this simple model and evaluated the results, I wasn’t satisfied since it pretty much picked as per the rankings and predicted all higher seeds to win every game. So I wanted to train it with a higher accuracy model and looked into R programming and standard R packages in the field. I used the infamous rpart to solve this classification problem and created another training experiment.
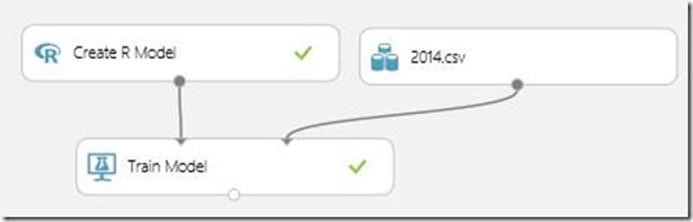
Creating an R model was quite easy in ML studio, all I have to do was include the following training script so that rpart package is included and trains for Team1Wins or not over the mentioned features in my dataset.
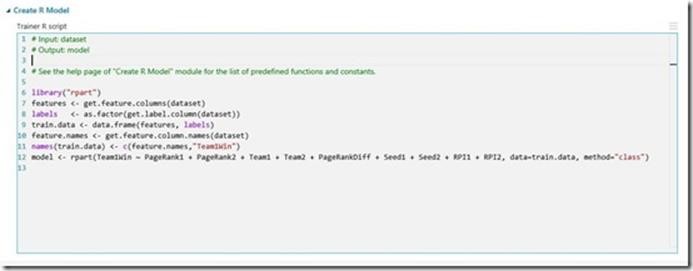
Once I ran the training experiment, I clicked on “Create Scoring Experiment” and scored the model. I also included few R scripts to calculate weighted probabilities for each year’s historical data.
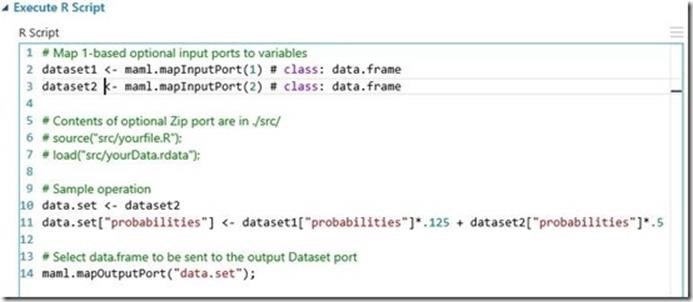
Once I evaluated the scored model, I looked at the probabilities of the result and to fine tune it I split the data with less accuracy and scored it with the trained model I created before with a standard “Two-class Boosted Decision tree” algorithm. As you can see splitting and manipulating datasets for appropriate trained models is quite easy and doesn’t need complex data transformation.
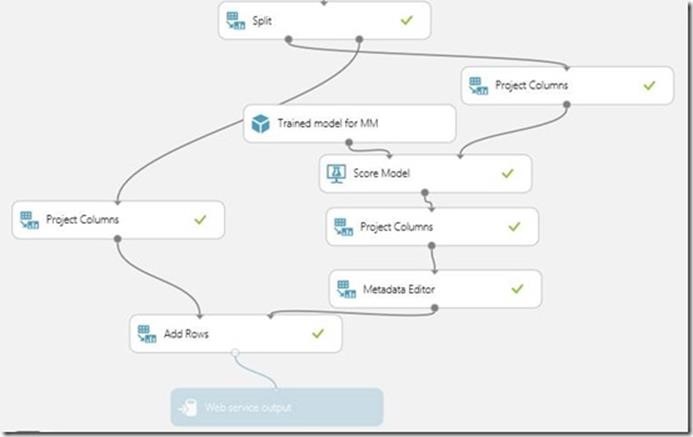
Here is the generated bracket out of my predicted results. This was generated by a simple program that the hackathon organizers used to call the web service provided by each participant.

Isn’t it amazing that with a few clicks I was able to create a web service that predicted an NCAA bracket’s final four teams accurately? Azure ML rocks!
If you are interested in learning more about Azure ML, here is our free Microsoft Press ebook by Jeff Barnes.
0 comments