

To help you understand and use the RWA pattern, we’ve created a comprehensive collection of materials that describe it in full. You can review the documentation and access the production-quality and ready-to-deploy web application – Reference Implementation.
The Reliable Web App Pattern
We’re excited to announce the release of a new video series on the Reliable Web App Pattern (RWA) using Java! The RWA pattern is intended to help developers successfully re-platform their Java apps to the cloud and set a foundation for future Java modernization in Azure.
The Reliable Web App pattern builds on the Azure Well-Architected Framework to provide guidance on business and technical goals, focusing on low-cost, high-value wins. It supplies guidance on security, reliability design patterns, operational excellence, cost-optimized environments, and more.
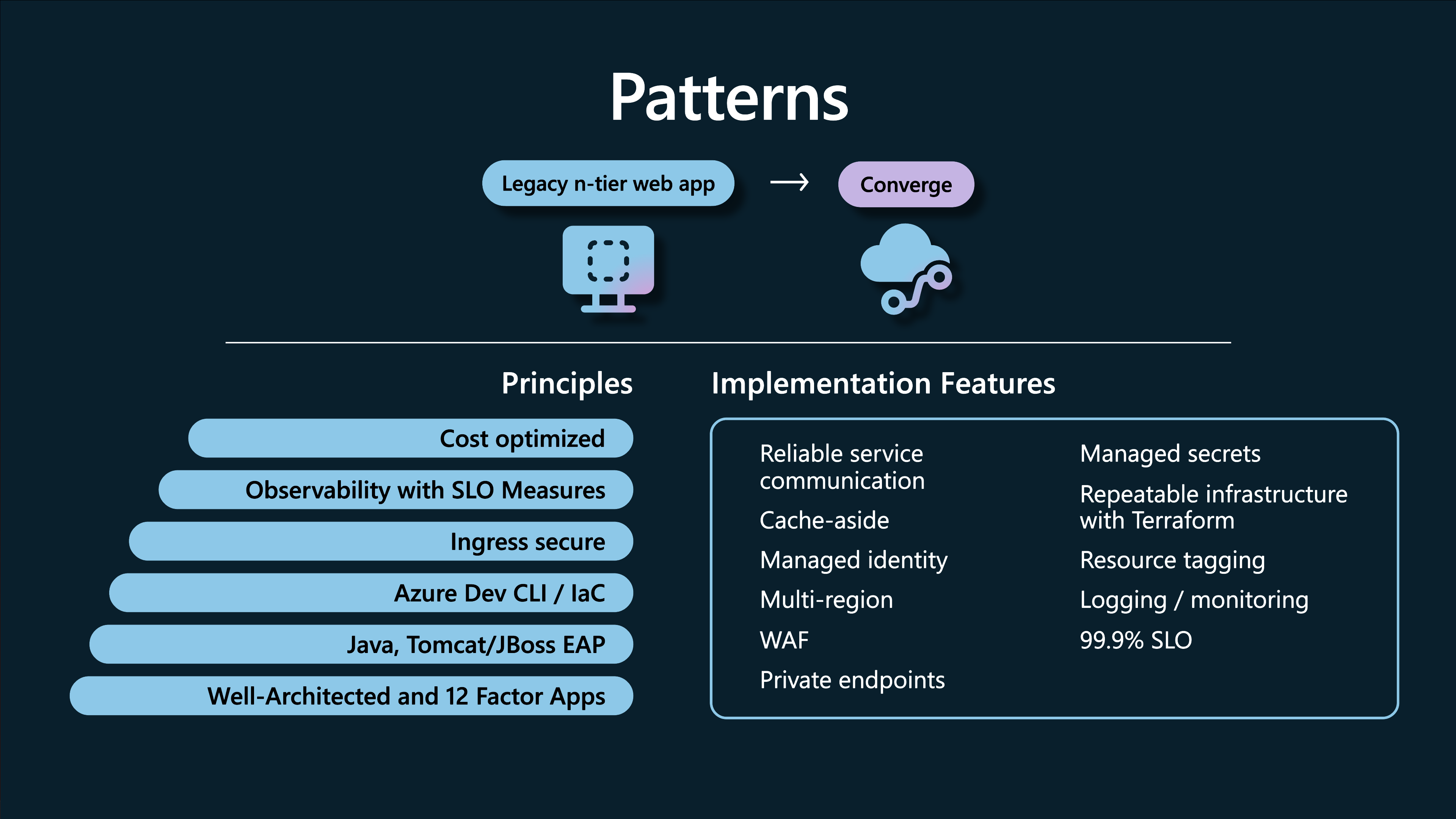
In other words, the RWA pattern gives you prescriptive guidance to get your application ready to successfully run on Azure with as little code changes to your existing application as possible.
In this article we look at three of the most interesting and powerful patterns that are a core part of the Reliable Web App pattern – Retry, Circuit-breaker and Cache-Aside.
Retry Pattern
The Retry Pattern is one of the most critical principles of the Reliable Web App pattern. Imagine your application making a request to a service. Sometimes, the service might be temporarily unavailable, or, as we techies say, there might be a ‘transient fault’. Our superhero, the Retry pattern, comes to the rescue by resending failed requests to the service until it’s back up.
The Retry Pattern isn’t about mindlessly resending requests, though. It’s about intelligent retries. This means that the pattern doesn’t just resend the requests blindly. Instead, it waits for a certain amount of time between each retry, giving the failing service a chance to recover. This delay, or ‘backoff’, can be fixed or it can increase exponentially with each retry, depending on your configuration.
Reference
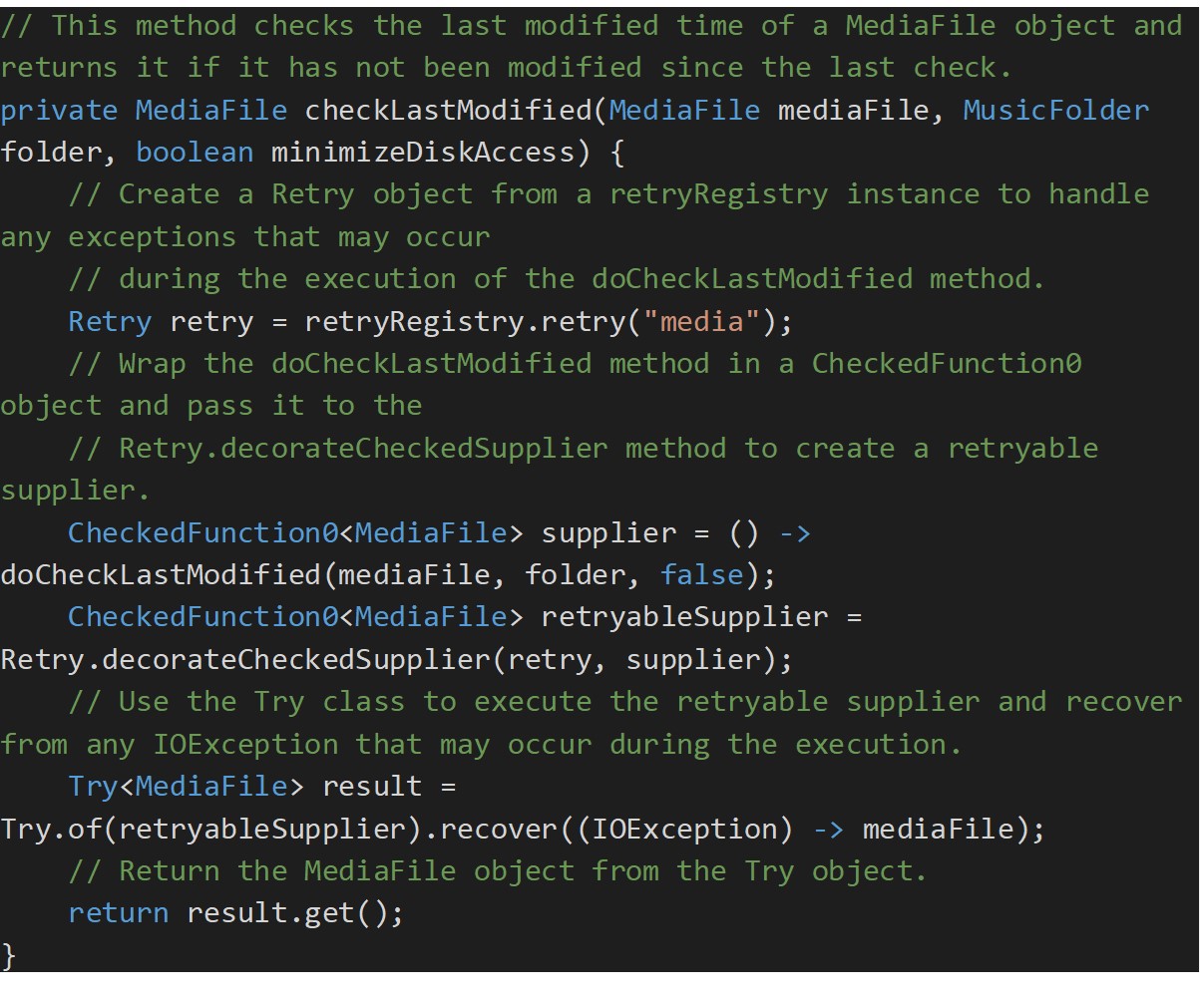
The reference implementation uses the retry pattern heavily especially when it comes to dependencies on external resources!
The code snippet below uses Resilience4j to retry a call to Azure Files until it successfully retrieves the last modified time.
Circuit Breaker Pattern
While the Retry Pattern is indispensable, it’s not enough on its own. In some cases, a service might be down for an extended period, or it might even be permanently unavailable. Continually trying to invoke such a service would be a waste of resources. That’s where the Circuit Breaker Pattern comes in.
The Circuit Breaker Pattern works like an electrical circuit breaker. When everything is running smoothly, the circuit is ‘closed’, and requests can flow through. But when a certain failure threshold is reached, the circuit ‘opens’, and the flow of requests is stopped. This prevents your application from repeatedly trying to invoke a service that’s down, sparing it from wasting resources on futile attempts.
Once the circuit is open, it doesn’t close at once. Instead, it enters a ‘half-open’ state after a certain amount of time. In this state, a limited number of requests are allowed through. If these requests succeed, the circuit closes again. If they fail, the circuit stays open. This strategy allows the Circuit Breaker Pattern to adapt to the state of the service it’s invoking, supplying a dynamic and efficient fault-handling mechanism.
Reference Implementation
The reference implementation comes with an application configuration setting that lets you simulate and test a transient failure when making a web request to GitHub. This way you can see when the circuit breaker opens or closes due to failure threshold!
Cache-Aside Pattern
In addition to reliability, performance is another crucial factor that decides the success of your cloud re-platform journey. The Cache-Aside Pattern is a key player in ensuring the high performance of your Java application in the cloud.
The Cache-Aside Pattern is a smart caching strategy. Instead of blindly caching everything, it caches data on demand. When a request for data arrives, the application first checks the cache. If the data is in the cache, it’s returned at once. If it’s not, the application queries the database, stores the result in the cache, and then returns it.
This pattern ensures that your cache always has the most often requested data, maximizing its effectiveness. Moreover, by reducing the load on your database, it also contributes to the overall performance and scalability of your application.
Reference Implementation
In the reference implementation, the cache-aside pattern enables us to limit read queries to the Azure PostgreSQL Flexible Server. Later calls don’t have to connect to the DB and instead use the data from Azure Cache for Redis. It also provides a layer of redundancy that can keep parts of our application running if there are issues with your Azure PostgreSQL Database.
In the context of transitioning from on-premises to Azure Cloud, it’s crucial to be selective about what data gets cached. In our reference architecture, we don’t cache all data indiscriminately. Instead, we focus on caching user details and specific settings, a decision rooted in both performance and necessity. The reason for this selective caching is twofold. First, user details and settings are accessed frequently but change infrequently, making them ideal candidates for caching. This ensures that the application remains responsive, reducing latency by eliminating the need for constant database queries. Second, not all data has the same access patterns or the same impact on application performance. Caching everything would not only consume more resources but might also introduce complexity in ensuring data consistency. Therefore, understanding what to cache—and why—is essential for optimizing both the performance and reliability of your re-platformed application in Azure. For a more detailed dive into caching, see the recently published blog post on this: How To Use Cache for Re-platform to Azure – Microsoft Community Hub.
Security and Infrastructure Reliability Considerations
Security is baked right into our 3 patterns, not just tacked on as an afterthought. For example, our Retry Pattern leverages short-lived OAuth tokens for enhanced security. Similarly, the Circuit Breaker Pattern serves a dual purpose: it not only manages service failures but also acts as a rate limiter to fend off potential attacks. We’ve even implemented role-based access controls, designating ‘User’ and ‘Creator’ roles to govern app interactions. And rest assured, all sensitive data is securely stored in Azure Key Vault.
When it comes to reliability, our reference implementation is designed to meet a stringent 99.9% Service Level Objective (SLO), it employs a two-region, active-passive setup. This isn’t just a random choice; it’s a strategic extension of the Circuit Breaker Pattern, aimed at handling regional outages. All traffic is funneled to the active region, eliminating the need for complex data management like event-based synchronization. If that region fails, a manual failover redirects traffic to the passive region. This setup not only aligns with the goal of minimal code changes but also synergizes well with our existing Retry and Cache-Aside Patterns.
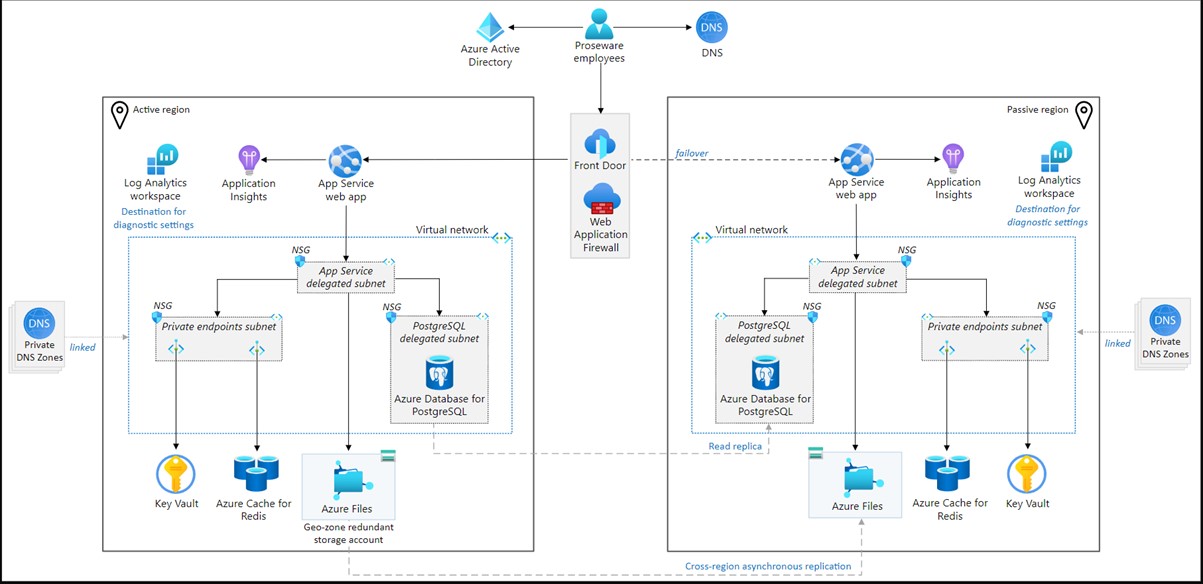
Download a Visio file of this architecture
The Importance of Reliability Developer Patterns in Re-platforming
Before we wrap up, it’s crucial to emphasize that the reliability developer patterns we’ve discussed are not just optional add-ons; they’re a necessary first step in the re-platform story. Many developers who work in typical on-premises scenarios may not have felt the urgency to implement these patterns. However, the cloud environment presents a different set of challenges, notably transient failures.
In an on-premises setup, your application might be running in a more controlled environment where you have better predictability over hardware and network stability. Moving to the cloud, on the other hand, means thinking about these transient failures proactively. You’ll likely be interacting with multiple services over a network, making your application more susceptible to sporadic issues that you have no control over. That’s why implementing reliability patterns such as Retry, Circuit-breaker, and Cache-Aside is a necessary first step for establishing future modernization on the cloud.
By considering these patterns early on, you’re building a robust foundation that not only ensures the smooth functioning of your application today but also paves the way for easy adaptability to future Azure services and features. It sets you on the right course to reap the full benefits of modernization with minimal disruptions to your existing workflow.
In summary, as you embark on your journey to re-platform your Java application on Azure, remember that adopting the Reliable Web App pattern and its core reliability developer patterns is more than just good practice; it’s essential for success.
Final Words
In this article, we’ve explored the core design patterns of the Reliable Web App pattern for Java, from handling transient and non-transient faults with the Retry and Circuit Breaker Patterns to improving performance with the Cache-Aside Pattern. Armed with these tools and our comprehensive collection of materials, you’re well-prepared to navigate the challenges of cloud re-platforming, ensuring your Java application not only survives the transition but also thrives in its new environment.
Relevant Links:
Reliable Web Pattern: https://learn.microsoft.com/azure/architecture/web-apps/guides/reliable-web-app/java/plan-implementation
Reference implementation: https://github.com/Azure/reliable-web-app-pattern-java
Reliable Web Apps Video Series:
- https://aka.ms/eap/rwa/java/videos
- https://aka.ms/eap/rwa/java/videos/overview
- https://aka.ms/eap/rwa/java/videos/reliability
- https://aka.ms/eap/rwa/java/videos/security
- https://aka.ms/eap/rwa/java/videos/costoptimization
- https://aka.ms/eap/rwa/java/videos/opexcellence
- https://aka.ms/eap/rwa/java/videos/performance
0 comments