
Versions 16.3 and 16.4 of Visual Studio 2019 brought many new improvements in code generation quality, build throughput, and security. If you still haven’t downloaded your copy, here is a brief overview of what you’ve been missing out on.
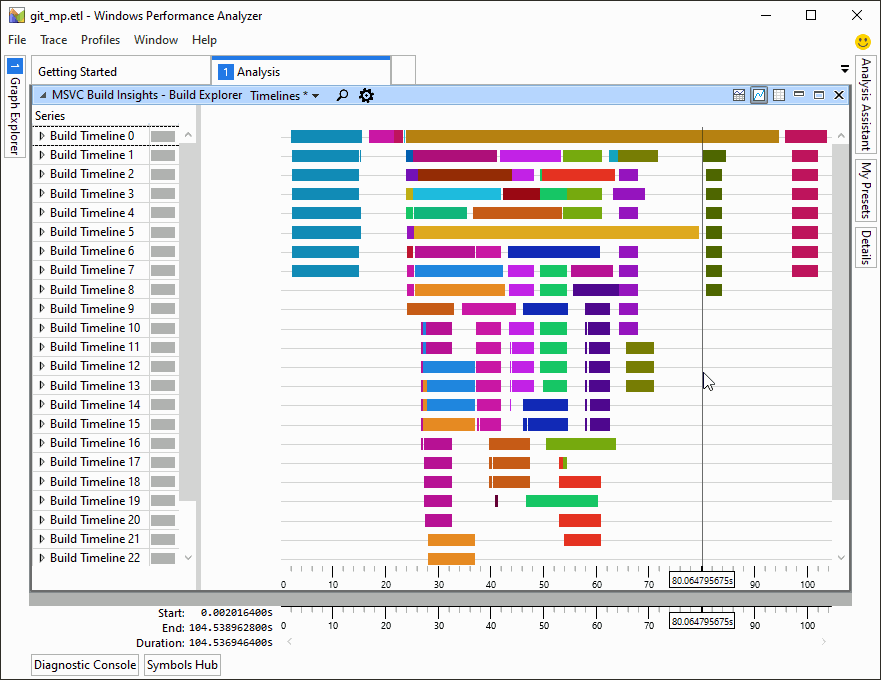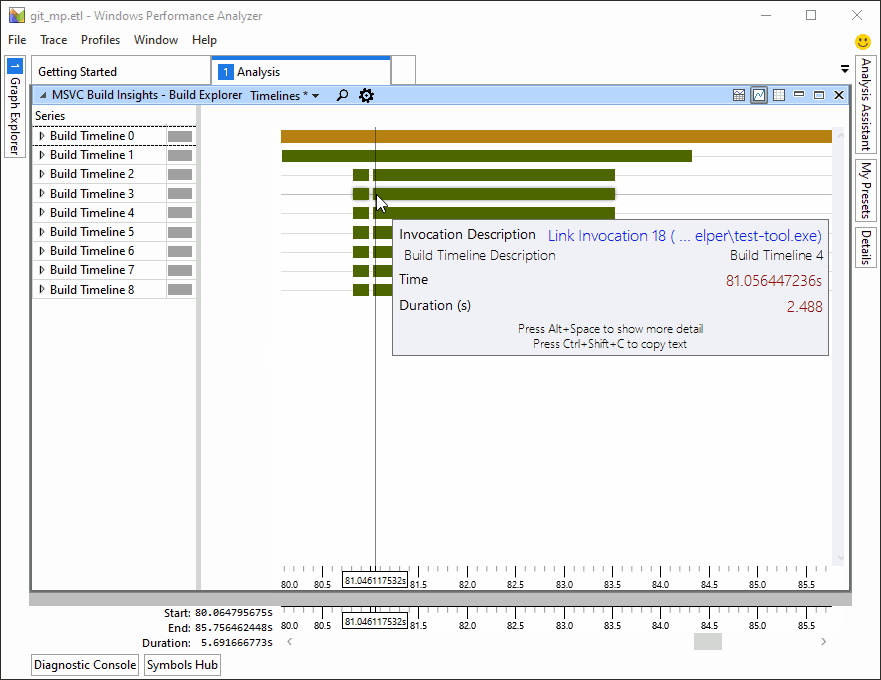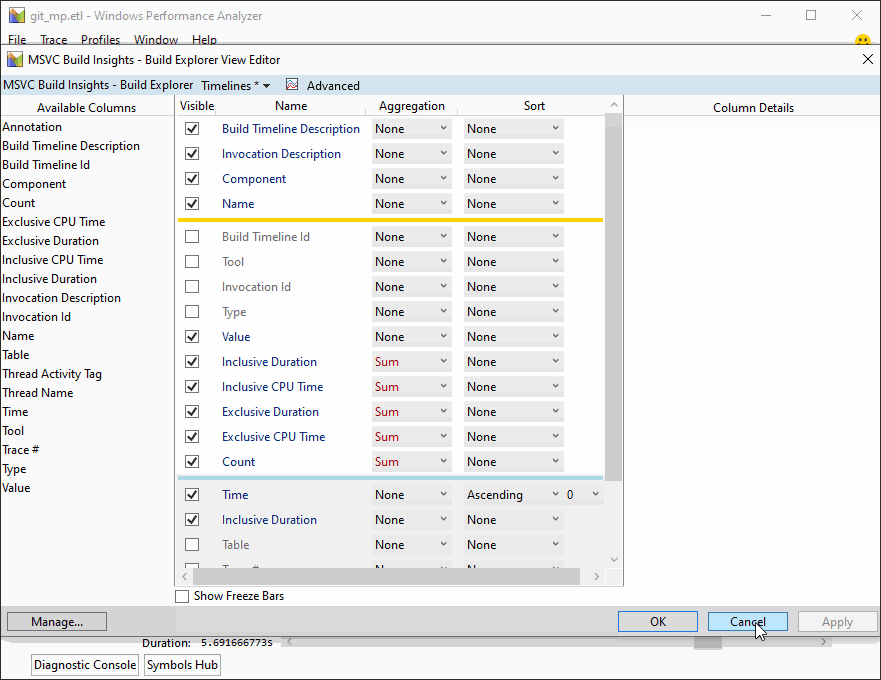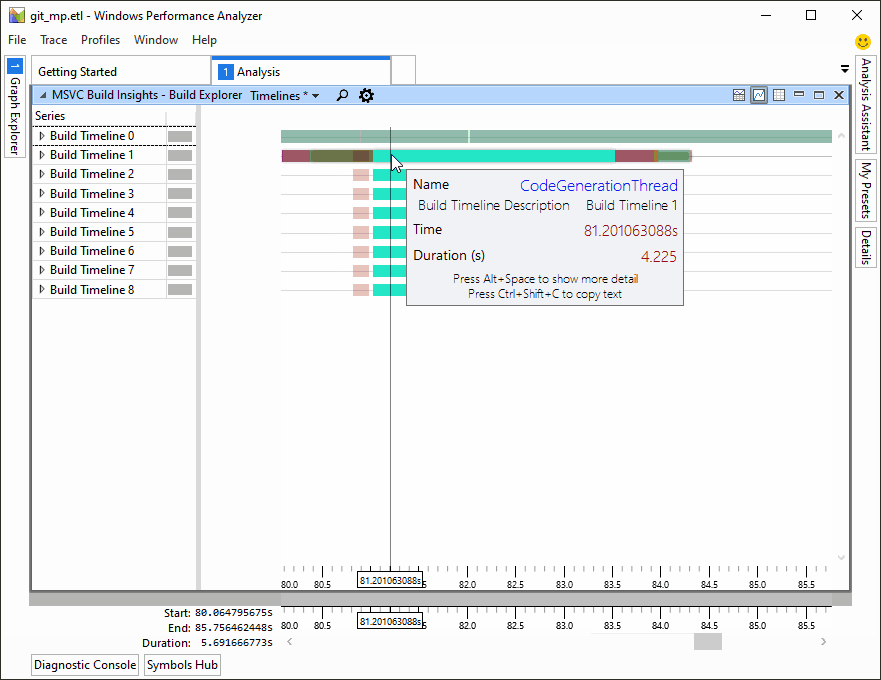
Demonstration of C++ Build Insights, a new set of build analysis tools in Visual Studio 2019 version 16.4.
Visual Studio 2019 version 16.3
- AVX-512 auto vectorizer support under the /arch:AVX512 switch, enabling logical, arithmetic, memory, and reduction vector operations targeting the AVX-512 instruction set.
- Enhancements to the general inliner by estimating the values of both variables and memory. Enabled under /Ob3.
- Improvements to inlining of small functions for faster build times and smarter inlining.
- Partial ability to inline through indirect function calls
- Dataflow-driven alias package added to the SSA Optimizer, enabling more powerful SSA-based optimizations
- Improvements to the common sub-expression (CSE) optimization focused on eliminating more memory loads.
- Compile-time computation of spaceship operator comparisons on string literals.
- Automatic conversion of fma, fmal, fmaf, and std::fma to the intrinsic FMA implementation, when supported.
- Optimized code generation when returning register-sized structs by using bit manipulations on registers instead of memory operations.
- __iso_volatile_loadxx and __iso_volatile_storexx functions, which allow direct atomic read and write of aligned integer values.
- Intrinsic versions of most AVX-512 functions that were previously implemented as macros.
- Improvements to instruction selection for mm_shuffle and _mm_setps intrinsics under /arch:AVX2.
- Enabling of FrameHandler4 (FH4) by default for the AMD64 platform.
Visual Studio 2019 version 16.4
- Support for AddressSanitizer (ASAN), allowing the detection of memory safety issues at runtime.
- C++ Build Insights, a new collection of tools for understanding and improving build times.
- Significant improvements to code generation time by using up to 24 threads instead of 4, depending on available CPU cores.
- Further improvements to code generation time through better algorithms and data structures used by the compiler.
- Introduction of a new /d2ReducedOptimizeHugeFunctions compiler option to improve the code generation time by omitting expensive optimizations for functions with more than 20,000 instructions. This threshold can be customized by using the /d2ReducedOptimizeThreshold:# switch.
- Improvements to the AVX-512 auto vectorizer, supporting more instruction forms: variable width compares, int32 multiplication, int-to-fp floating point conversion. Available under /arch:AVX512.
- Improved analysis of control flow to better determine when values are provably positive or negative.
- Enabling of the enhanced inliner introduced in 16.3 by default, without the use of /Ob3.
- Intrinsic support for the ENQCMD and ENQCMDS instructions, which write commands to enqueue registers.
- Intrinsic support for the RDPKRU and WRPKRU instructions, which read and write the PKRU register available in some Intel processors.
- Intrinsic support for the VP2INTERSECTD and VP2INTERSECTQ instructions, which generate a pair of masks indicating which elements of one vector match elements of another vector.
Do you want to benefit from all of these improvements? If so, download the latest Visual Studio 2019 and tell us what you think! We can be reached via the comments below, via email at visualcpp@microsoft.com, or via Twitter (@VisualC).
Is the "Significant improvements to code generation time by using up to 24 threads instead of 4, depending on available CPU cores." intended to be available when running under /LTCG in the linker?
I'm not seeing any improvement in this area.
Unfortunately Build Insight doesn't break out much of what the linker is doing - it just says "Link Invocation" under timelines. Under activity it shows LinkerLTCG but doesn't break anything down per file. This is a bit unfortunately because that's where the >80% of the overall build time goes. I do however see in there that Link.exe only runs on 4...
Hello Deon,
When using Visual Studio 2019 version 16.4, you should also see activities named CodeGenerationThread in the Build Explorer. Do you see them? I would suggest reporting a problem on Developer Community. After describing and creating your issue, you will be able to add a comment to attach your Build Insights trace file. This will give us much more information and help figure out what is going on. Feel free to compress the trace if it is very large; etl files tend to compress well. If the trace contains private information that you would like the public not to see,...
I sent in the .etl file to you guys. I do see the CodeGenerationThread - it is running the whole time during the link phase. The CompilerParsingPass just has C1DLL entries, and the Linker pass has C2DLL entries as expected for a /GL /LTCG build.
Another interesting view - if I look at the Build Explorer analysis , I see 24 build timelines. When I look at Functions analysis, I only see 4 timelines. So it definitely looks deliberate that there are only 4 threads.
Please tell me I'm just missing a setting somewhere! (Maximum Concurrent C++ Compilations setting is currently set...
Sadly this may be too little too late for at least the folks over at Blender 3D. They're seriously considering a switch to clang due to performance differences even after using the latest compiler set with /Ob3. I know blender is part of spec 2017 but the part that's primarily measured there is not the main cause of concern. So if you're only looking at that benchmark you'd be missing it. Not having 64bit asan is also grinding their gears pretty bad too...
The code in question is dealing with building the bvh tree during scene preparation (before...
I'll ping the ASAN @ Microsoft folks and ask them to respond about ASAN for 64.
Hi Roger, we are somewhat familiar with Blender 3D, but we haven't done a deep dive into the performance of it. We've made significant improvements in the last year in code performance as well as build time (full builds, as well as the common developer iteration builds), and we're set up to continue to make improvements that will affect many codebases. We'll be happy to take a look at Blender's sources & performance and see what we can do to help. The performance issues we've...
Hi,
I'm a windows platform maintainer for blender, there's currently no plans to switch to clang, I'm in contact with Gratian Lup who is already prodding at some of the perf differences between msvc and clang.
Roger seems to be an excited user jumping the gun a little bit :)
Don't get me wrong ASAN64 would be awesome, but given the diverse group of developers on blender it's easy just to ask one of the linux devs to try a bug with ASAN on GCC so the lack of it is not that big of a deal. Also not nearly as informative...
I’d really like it if these blog posts provided a way to pause the animation. Playing animations embedded in the text you’re trying to read is the sort of thing adverts like to do, and getting rid of them is one of the main reasons adblockers became popular.
When can we expect x64 support for ASAN? I know you probably can’t commit to a hard deadline, but at least some information would be useful (future update of VS 2019? No sooner than the next major version?)
This floors me. I haven’t done 32-bit development for years.