

Introduction
Great code completions make you more productive while composing your code. Visual Studio 2022 now automatically completes C# code up to a whole line at a time, using a rich knowledge of your coding context. We have also released the IntelliCode Completions extension in Visual Studio Code (VSCode) to speed up coding in Python/TypeScript/JavaScript. Both Visual Studio and VSCode achieve this using a transformer model trained on large volume of code data; The research has been published in ESEC/FSE 2020. In this post we’ll dive deeper into the technical advances we’ve made to deliver the IntelliCode whole line completions experience.
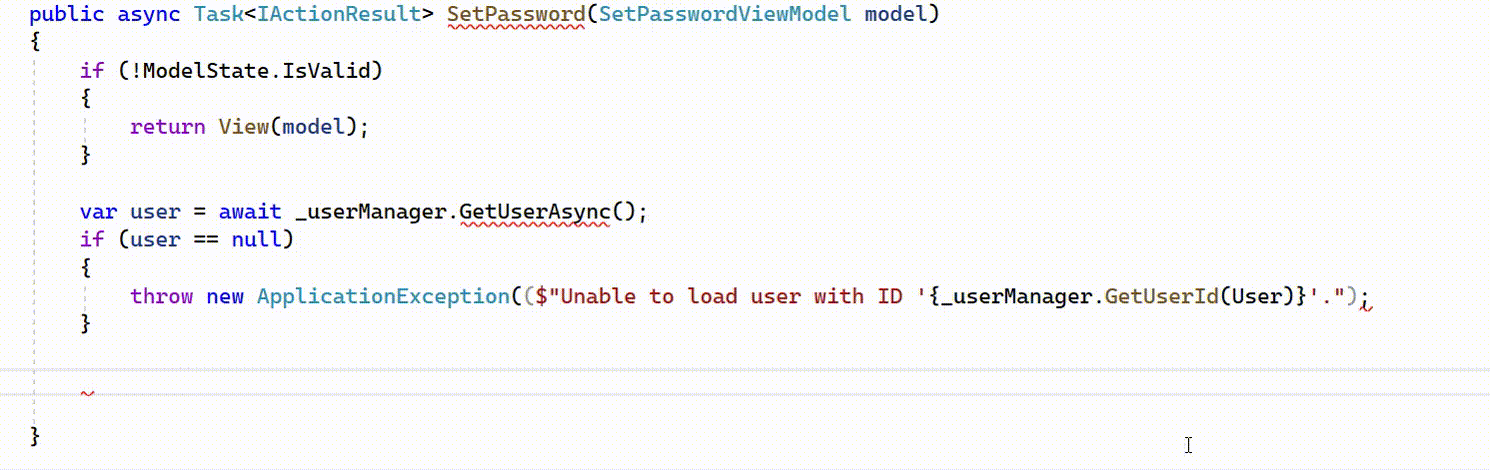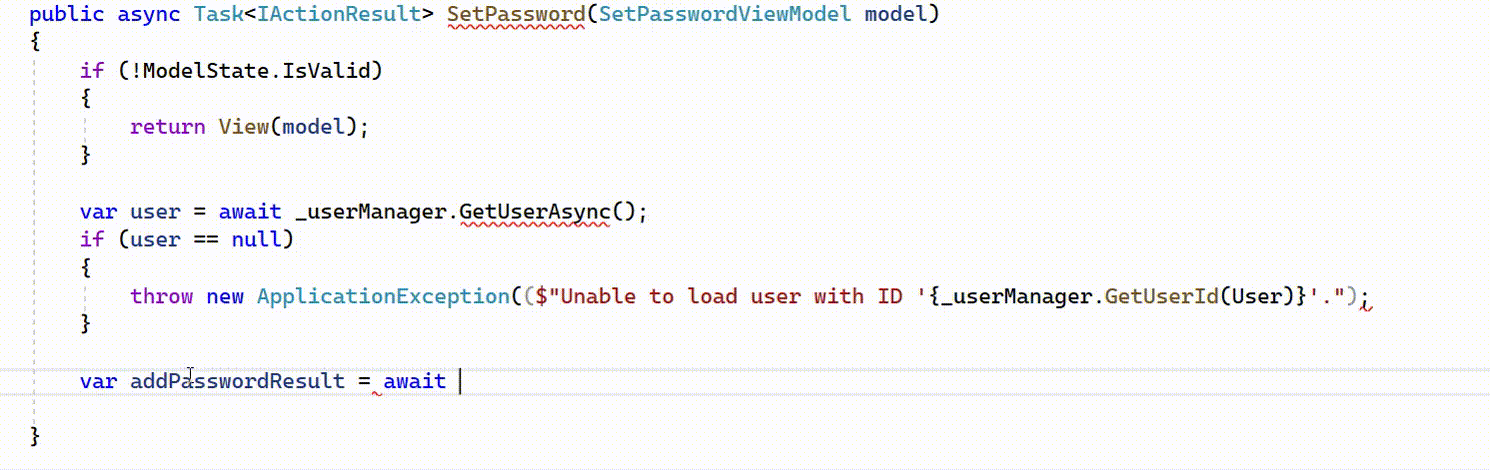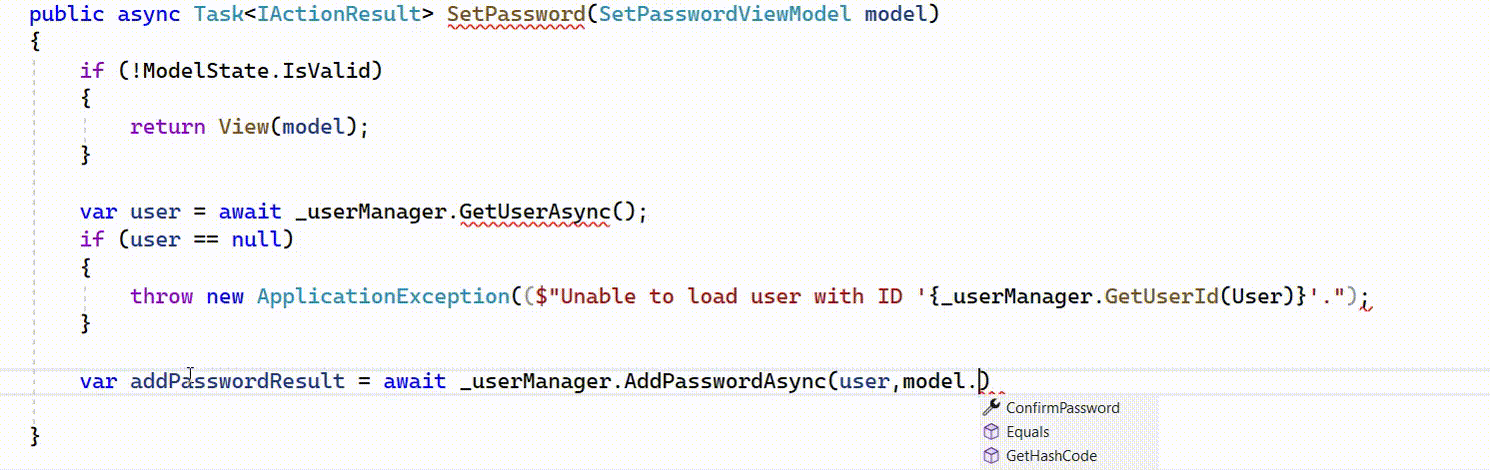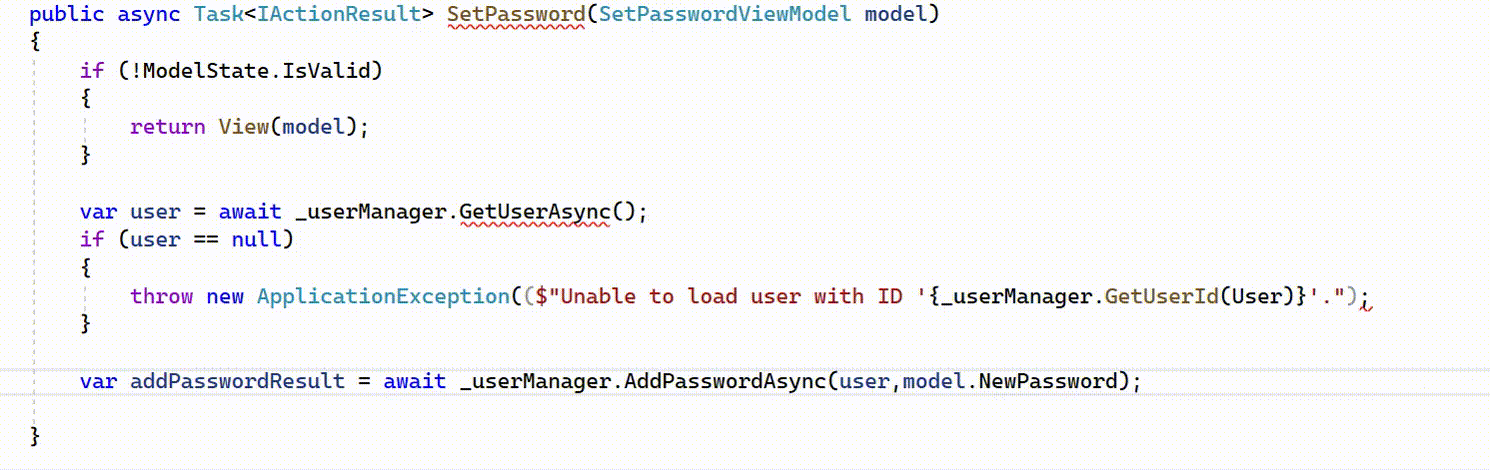
Example of IntelliCode whole line completions for C# in Visual Studio
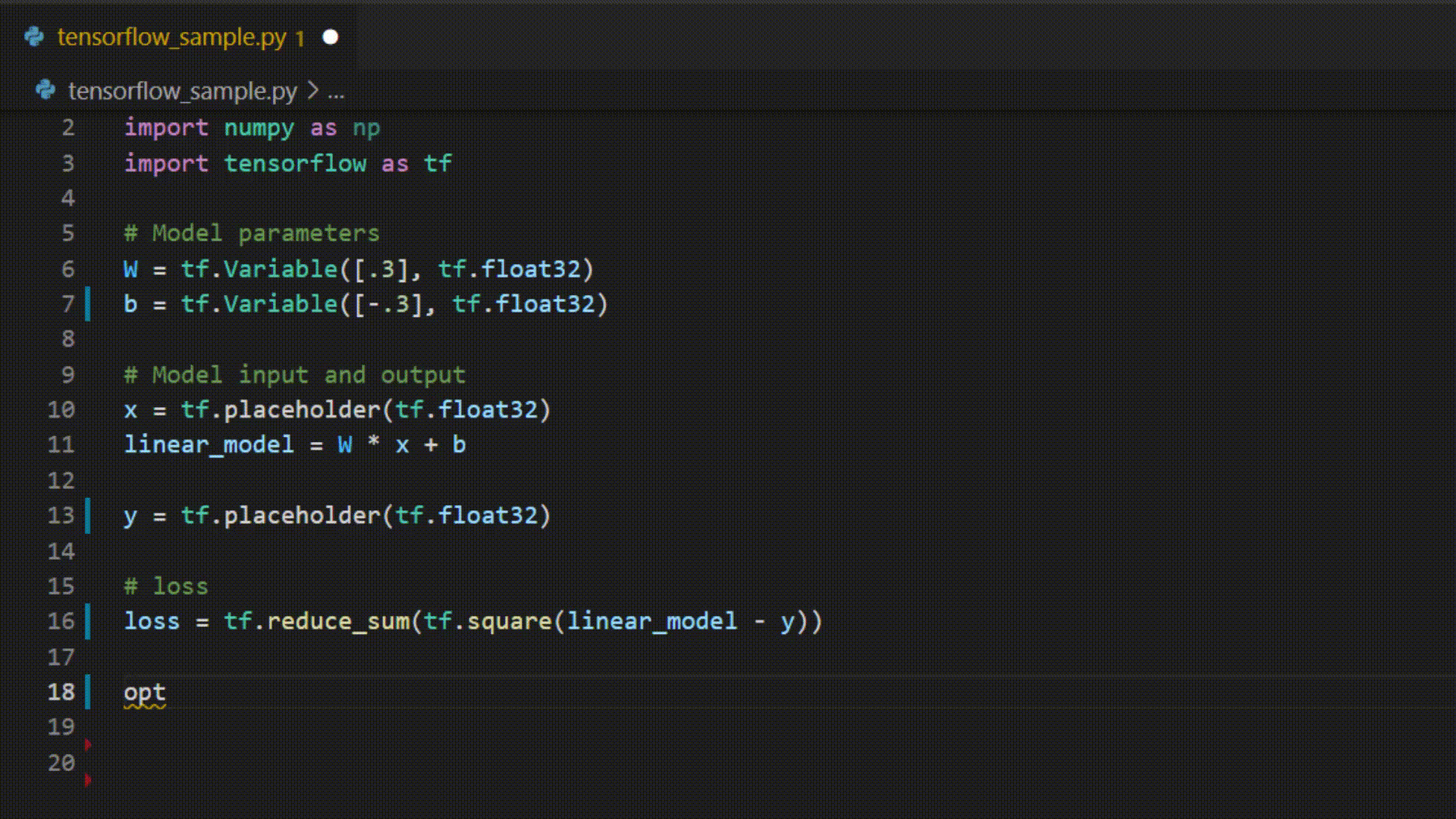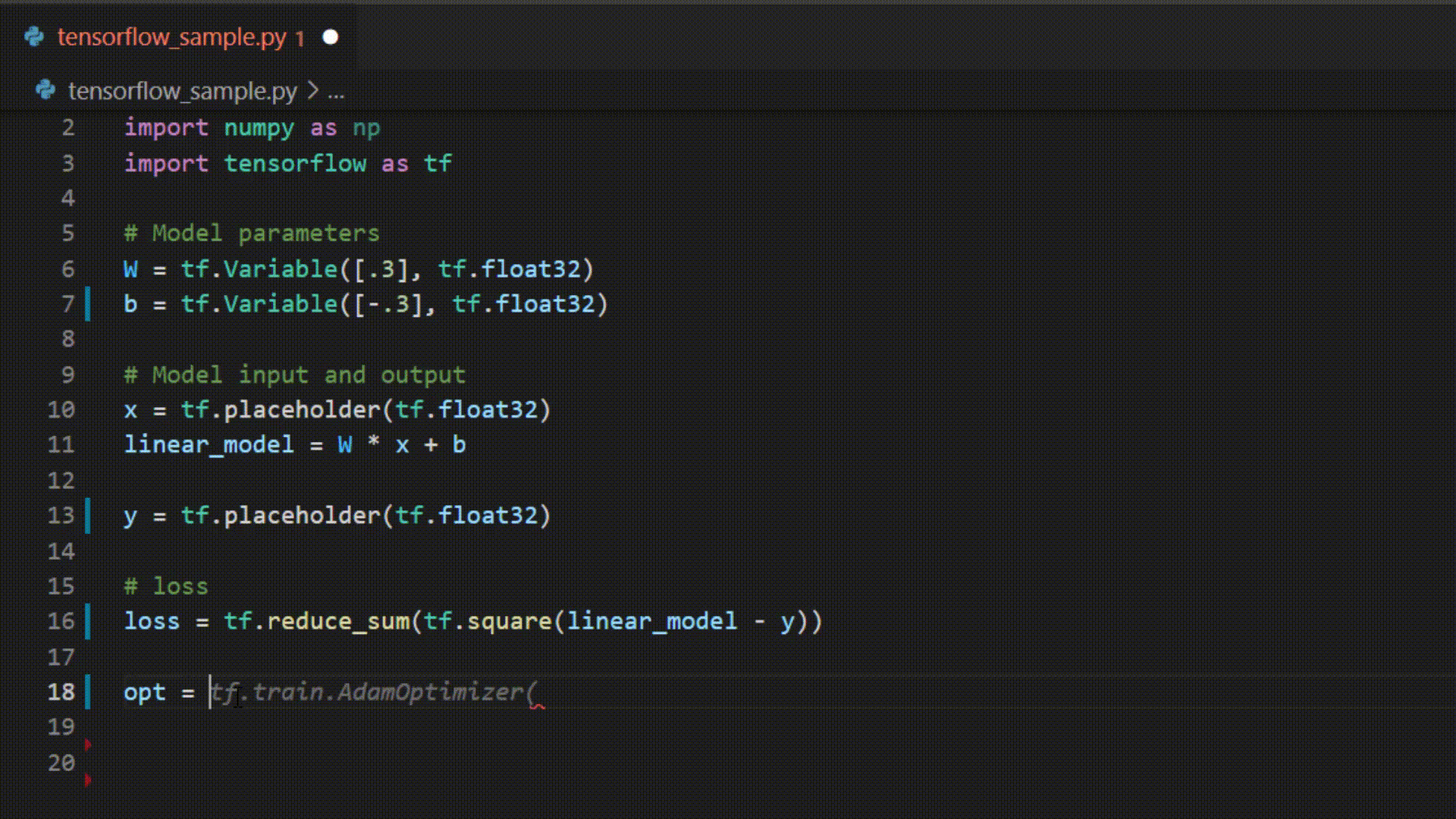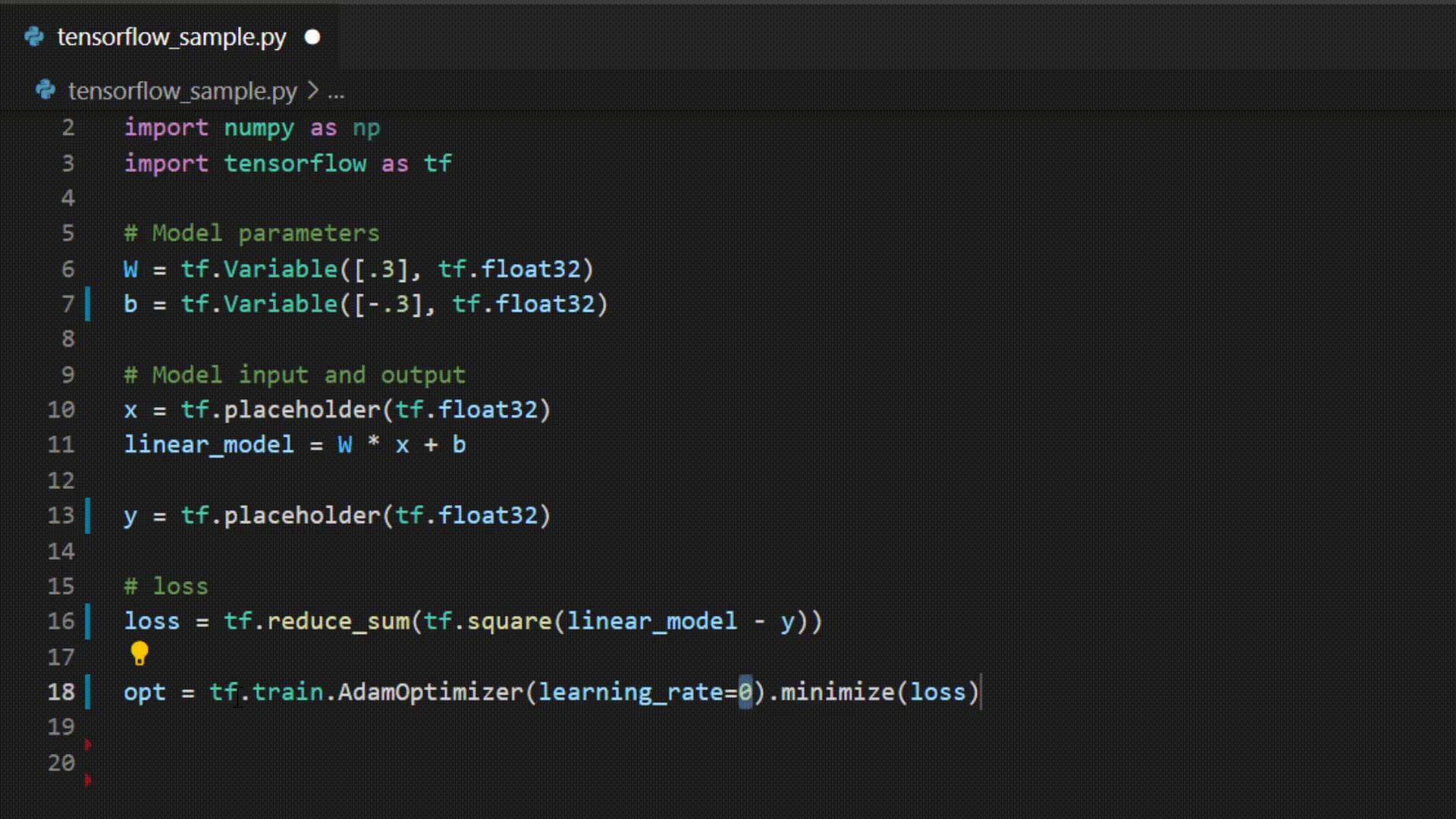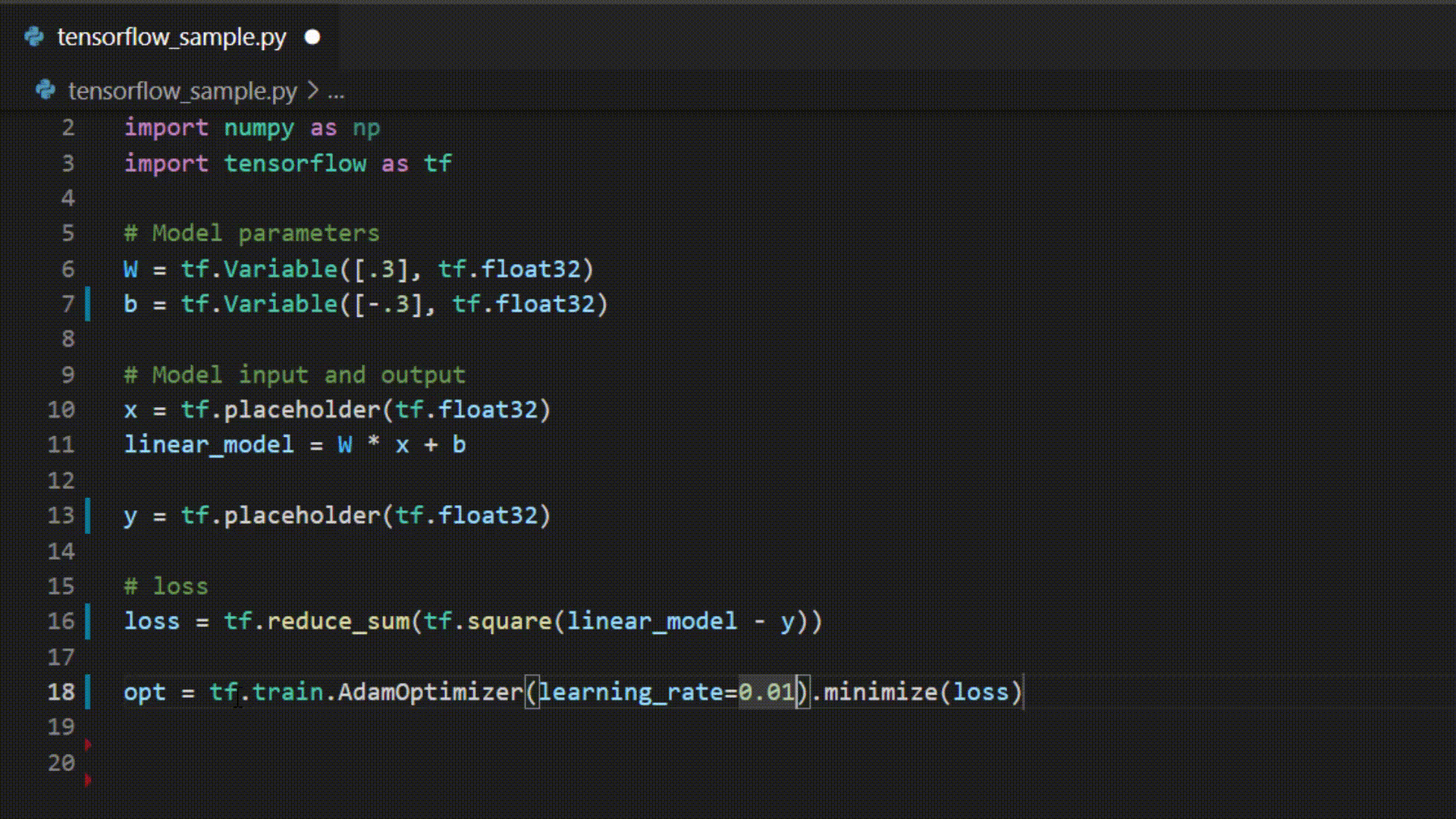 Example of IntelliCode whole line completions for python in Visual Studio Code
Example of IntelliCode whole line completions for python in Visual Studio Code
Multilingual Transformer Model for Code (GPT-C)
The IntelliCode whole line completion task is modeled to predict a sequence of tokens 𝑀 = {𝑚i}, i = 1…𝑁, conditioned on preceding code tokens {𝑐𝑡}, 𝑡 = 1…𝑇. We need to estimate the following conditional probability distribution:
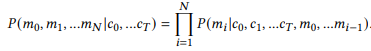
With the autoregressive generation, the objective is to maximize the sum of the log-likelihood:
𝐿(𝑀) = ∑i log 𝑃 (𝑚𝑖 |𝑐0, 𝑐1, …𝑐𝑇, 𝑚𝑖−𝑘, 𝑚𝑖−𝑘+1, …𝑚𝑖−1; Θ)
where 𝑘 is the length of predicted code sequence, and the conditional probability 𝑃 is modeled using a neural network with parameters Θ. Θ are learned through stochastic gradient descent optimization.
Recurrent Neural Networks (RNN) and its variance, Long Short-Term Memory (LSTM), formed the base of many Natural Language Processing (NLP) tasks. The main limitation of RNN is capturing long sequence dependencies. Transformers are a family of neural networks introduced to capture long sequence dependency through the attention mechanism. They have found numerous applications in the fields of NLP, including machine translation, question answering, and document summarization. Inspired by the GPT-2 transformer model developed by OpenAI, we trained a multi-layer transformer model for code generation (GPT-C) on more than half-million public open-source repositories for multiple programming languages.
During data pre-processing, we parse the source code into a sequence of tokens through a syntactic parser. Instead of learning representations for each token, we learn representations for sub-tokens generated through Byte Pair Encoding (BPE) tokenization. BPE tokenization is known for its benefits on solving the out-of-vocabulary problem and helping to reduce the size of the vocabulary to a substantial extent.
During model training, we scale the computation using a synchronous data-parallel distributed training algorithm with local gradient accumulation. The training module is implemented by integrating PyTorch and Horovod with the AdaSum algorithm for gradient summation. The model is trained on the ND-series virtual machines provisioned by Azure machine learning platform.
Besides evaluating our model with NLP metrics presented in the research paper, we also did extensive offline evaluation based on the location, length, and log-likelihood of the completion suggestions. The extensive offline evaluation and online metrics collected through internal previews guided us to set the right completion-triggering locations and confidence threshold.
The IntelliCode whole line completions run efficiently right on your local machine while you’re coding. To make this happen we needed to overcome the technical challenges deploying the model in Visual Studio and VSCode with limited memory on CPU. Below are the key steps we took to reduce the model size and boost the inference speed:
- By distilling the model from 26-layers to 8-layers, we reduced the model size from ~370 MB to ~200MB and boosted the inferencing speed by ~4x.
- By applying model quantization from FP32 to INT8 through the ONNX (Open Neural Network Exchange) Runtime, we further reduced the model size from ~200MB to ~80MB.
- By moving beam search implementation from managed code to the ONNX computing graph, we further boosted the inferencing speed by ~4x. The beam search optimization work has been contributed back to the ONNX Runtime on GitHub.
- By leveraging Microsoft’s open-sourced BlingFire tokenizer, the time spent on BPE tokenization has been reduced by ~3X.
Through the optimizations above, we successfully shipped the GPT-C transformer model running locally in both Visual Studio and VSCode, thanks to our collaborators across Microsoft: Microsoft Research Asia, Azure AI Platform and Turing team.
What’s Next: More context for better predictions
Currently we are only using limited code context to generate the recommendations. In the next version of the model, we will be incorporating extended code context inside the document to improve model accuracy. We have published our research in ENMLP 2021, and in the process of productizing the new model with extended code context.
Help Us to Improve
If you are a C# coder in VS, please install Visual Studio 2022 to try out the new IntelliCode. For VSCode users, please install IntelliCode Completions extension to code in Python/TypeScript/JavaScript, and watch for more languages (e.g., Java) to be enabled. IntelliCode has benefited from all the constructive feedback received from you – Thank you!
Please report any issues you see via Developer Community and file feature requests. Happy coding!
You pulled something incredible with this new Intellisense upgrade.
Congrats, the coding experience is exquisite. 🙂
Great work you guys! I am going to upgrade my Visual Studio right now, 🧡 Microsoft!
Just a quick kudos to the team. VS2022 Intellicode is amazingly awesome. I still get excited when I see the prompt for almost exactly what I was going to type, and sometimes, the suggestion is an even better version of what I was thinking. (plus, after all these years, my typing sucks…so thanks )
How does that play with GitHub CoPilot, which completes entire methods?
Hey Tsahi,
Aaron from IntelliCode team here. Two pieces to this:
1) The underlying tech is different. Copilot uses a larger CODEX Model that inferences on the cloud. IntelliCode uses the GPT-C model and inferences locally.
2) Although they work exclusive of each other right now in VSCode, there’s a better together story that we’re working on.