

Summary: Learn how to use Windows PowerShell 5.0 to scrape a web page so that you can easily return parsable objects.
Good morning. Ed Wilson here, and today I have a guest blog post by Doug Finke…
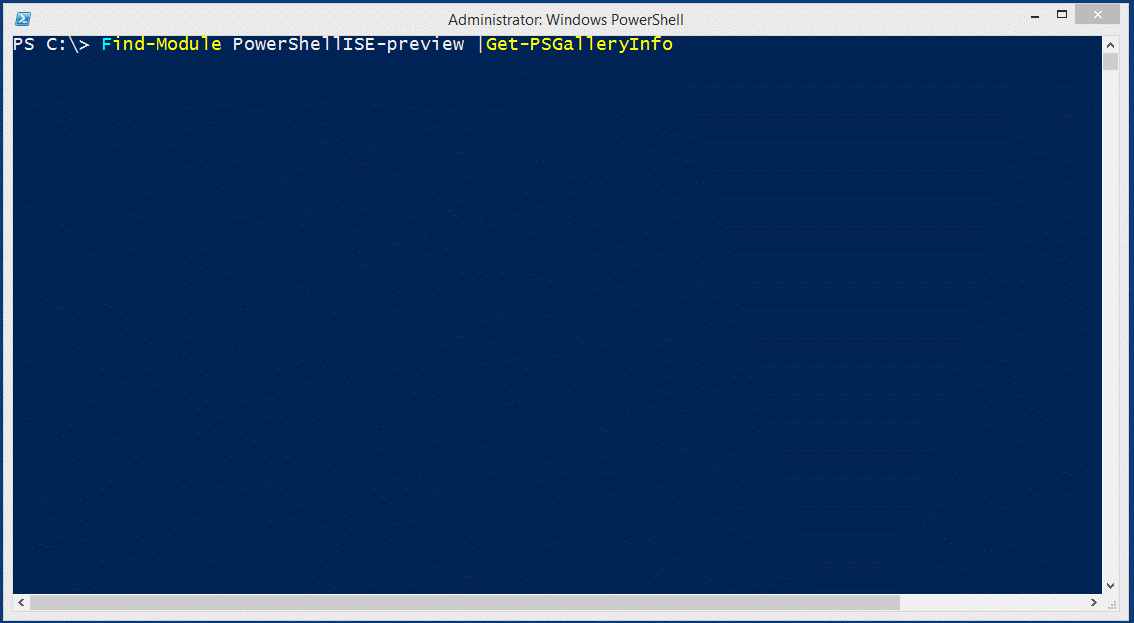
When surfing the PowerShell Gallery, you'll find that each module has a web page with a version history, for example:

Wouldn't it be great if you could get this information at the command line? Click here for a 20 second video that shows the code to do it.
How to do web scrapping
This approach will only work in Windows PowerShell 5.0, because it uses the new ConvertFrom-String function to convert the parsed HTML text into objects.
It's a simple approach. First, use Invoke-WebRequest to get the HTML back from the web page. Then, AllElements returns a list of objects that you pipe to Where and do a match on versionTableRow. You grab the InnerText property and pipe all of this to ConvertFrom-String using the contents of $t as the template to convert the text to objects with the property names Name, Version, Downloads, and PublishDate.
function Get-PSGalleryInfo {
param(
[Parameter(Mandatory=$true,ValueFromPipelineByPropertyName=$true)]
$Name
)
Begin {
$t = @"
{Name*:PowerShellISE-preview} {[version]Version:5.1.0.1} (this version) {[double]Downloads:885} {[DateTime]PublishDate:Wednesday, January 27 2016}
{Name*:ImportExcel} 1.97 {Downloads:106} Monday, January 18 2016
"@
}
Process {
$url ="https://www.powershellgallery.com/packages/$Name/"
$r=Invoke-WebRequest $url
($r.AllElements | Where {$_.class -match 'versionTableRow'}).innerText |
ConvertFrom-String -TemplateContent $t
}
}
How to figure out the content of class
Launch your browser and navigate to the ImportExcel 1.98 module. You should be able to right-click the page and find an option called View page source. When you click it, you'll get another tab in your browser, which shows you the underlying HTML. Scroll down (or use Search) for text that looks familiar in the rendered page.
Here you can see an HTML class attribute that contains versionTableRow. For other pages you want to scrape, you need to examine the HTML to figure out what uniquely identifies what you want to extract. Sometimes it's as easy as this:

Next, you can see the text returned with this PowerShell snippet:
$r.AllElements | Where {$_.class -match 'versionTableRow'}).innerText
Use that to create the TemplateContent for ConvertFrom-String, which transforms the text to objects.
For a great write up on how to work with ConvertFrom-String, check out this post on the Windows PowerShell blog: ConvertFrom-String: Example-based text parsing.
~Doug
Thank you, Doug, for that way cool post. Join me tomorrow for more cool Windows PowerShell stuff.
I invite you to follow me on Twitter and Facebook. If you have any questions, send email to me at scripter@microsoft.com, or post your questions on the Official Scripting Guys Forum. Also check out my Microsoft Operations Management Suite Blog. See you tomorrow. Until then, peace.
Ed Wilson, Microsoft Scripting Guy
Hi Dr Scripto, I know this is an old thread, but I was wondering how you accomplish the above when you have to use the -UseBasicParsing option. I have found some pages throw a ‘vector smash protection’ error and the only way to scrape them is to add the -UseBasicParsin option to download the page. Using this, the .parsedHTML value does not exist and you would have to parse the .content value instead. Do you have any thoughts on how this could be used to either grab a table or value from a specific class?