
Sr. Application Development Manager / Customer Engineer and PhD, David Da-Teh Huang, provides an introduction to supervised machine learning
Author Introduction:
Dr. Huang obtained his PhD from Caltech in 1990 and has been with Microsoft for over 20 years. He is a Certified Azure DevOps Expert, Certified Azure Developer, and owns MCSE, MCSA badges.
SUPERVISED LEARINING WITH KNOWN OUTPUT
#Features #Labels #Categorical #Training Set #Test Set #Validation
What is supervised learning? Gauss invented linear regression in 1809 to describe planetary orbits. At that time, they had to calculate very complicated mathematics by hand. Since the invention of personal computers, statistical learning tools have been put into the hands of businesses, researchers, and lay people everywhere. Today we will discuss “supervised learning”. Supervised learning is where we try to create a model and describe the relationship between a set of inputs X (where bold-font capital letter represents a matrix) and outputs y (where bold-font lower-case letter presents a column matrix). The goal is to accurately make predictions on new data that we have not seen before.
In machine learning, the inputs are called “features” and most often expressed in m x n matrix, where n is the number of data points, and m is the number of inputs describing each data point. For example, if we had a data set describing 100 hospital patients, and had information on their age, gender, height, and weight, then “m” would be 4, and “n” would be 100. The outputs are called “labels” or “responses”, and either be numerical or categorical (i.e., of different categories).
The two types of problems we encounter in supervised learning are “regression” and “classification”. “Regression” is when we try to predict the numerical response. “Classification” is when we try to predict a categorical response. There are three steps in the workflow of supervised learning: (1) Training a model, (2) validating the model, and (3) generating predictions.
For supervised learning, we are given training data where we already know the output, and we want to make predictions on a separate test data where the output is unknown.
We will begin by partitioning the training data into a “training set” and a “validation set”. We can build the model on the training set, assess its performance using the validation set, and generate predictions on the test set. Typically, data scientists will choose 80-90% of the total data to be the training set, and the other 10-20% to be the validation set.
TYPES OF MODELS
#Linear model #Nonlinear model #Nearest neighbors #Decision Tree #Neural Network
There are many types of models that statisticians and computer scientists have invented to describe the relationship between features and labels.
- Linear model: Describes a straight-line relationship between the features and a numerical output. Each input is multiplied by a weight and then summed up to get the result. (ax1 + bx2 + … = y)
- Nonlinear model: Describes a nonlinear relationship between the features and numerical output.
- Nearest neighbors: Uses the nearby data points to generate local predictions for data point.
- Decision trees: Uses a decision tree to generate predictions.
- Neural network: Uses a set of artificial “neurons” to create a complicated model.
ASSESSING THE MODEL
#Regression #Classification #Metrics #Mean-Squared Error (MSE) #Mean Absolute Error (MAE) #R-square #Accuracy #Log-Loss #Bias #Variance
For any given model, we will assess its performance using various metrics.
Regression:
- Mean squared error: the mean of the square of the error term (the real output minus the prediction)
- Mean absolute error: The mean of the absolute value of the error term.
- R-squared: The proportion of variation in the response that can be described by the model. Ranges between 0 and 1.
Classification:
- Accuracy: The proportion of predicted data points that was correct; the value of accuracy ranges between 0 and 1.
- Log-loss: A metric that punishes inaccurate predictions according to a logarithmic scale.
The metrics are generated over both the training set (training error) and the validation set (test error). The training error will always be lower than the test error because the model was specifically created to describe the training set. The training error is also known as the “bias.” The lower the bias, the more optimized the model is at describing the training data.
However, if the model is too optimized for the training data, it runs the risk of being “overfit” and will not be able to accurately predict for new data points. Overfit happens when the model simply memorizes the data points in the training set but doesn’t truly learn the relationship pattern between input matrix X and output matrix y. We know that the model has become overfit when the test error or “variance” begins to increase. In data science, this is known as the “bias variance tradeoff.” We need to choose a balance that is able to both accurately describe the training data and make useful predictions. Therefore, we have to keep the model from introducing unneeded complexity during training. Figure 1 shows the concept of finding optimal complexity in bias-variance tradeoff.
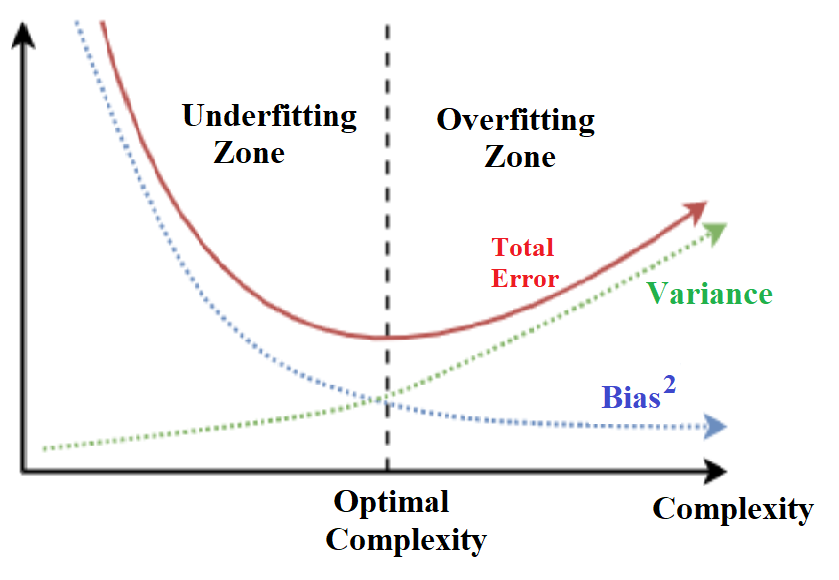
Figure 1. Bias-Variance Tradeoff technique in searching for the optimal complexity
FEATURE SELECTION
#Regularization #Penalty #Bagging #Boosting #Dimensional Reduction #F-Test
One way of reducing the complexity of models is through feature selection. Feature selection means only choosing the data that is useful in making predictions and not just adding irrelevant information. For example, when training linear models, we can begin with a very simple model and add new features in one by one in steps. We can determine if the new feature improves the prediction results using an F-test on the error terms. An F-test is a statistical test that compares whether two distributions are different. If the new error distribution is found to have a different variance from the previous error distribution, then we can determine that the new feature has added informational value.
Regularization:
Regularization is another technique for controlling the complexity of statistical models. It works by introducing a penalty associated with weight terms. For instances, if the model is (ax1 + bx2 + … = y), then an “L1” penalty would equal (p = a + b +…) and an “L2” penalty would equal (p = a^2 + b^2+…). Using different penalties will yield different results when training the model. If we use an L1 penalty, the model will perform feature selection and will not allocate weight to the uninformative features. Whereas in an L2 penalty, the model will continue to allocate weight to all features but does so in a constrained way. Figure 2 shows mathematically how the penalty terms are expressed in L1 and L2 regularizations respectively.

Figure 2. L1 and L2 Regularization math expression with the penalty terms circled
Bagging:
Bagging (bootstrap aggregating) is a technique where the model is made more robust to overfitting. This technique involves splitting the training data into many randomly selected sample (bootstrapping). Then, a model is fit to each one of the random samples. Finally, the models are averaged together (aggregating). By taking the average over many different models trained for randomly selected samples, we prevent overfitting to the training dataset.
There are many other ways of balancing the bias variance tradeoff, including boosting and dimensional reduction, but these are beyond the scope of our discussion.
CONCLUSION
Today, the most common tools used by data scientists to create machine learning models are Python and R language. Python is generally favored because it is more easily integrated into production workflows. Microsoft has a variety of products with user interfaces that implementing these language capabilities, including Azure, Office, and Visual Studio. For example, with Microsoft Azure Machine Learning, developers can build powerful, cloud-based machine learning applications.
Microsoft Azure provides automated hyperparameter tuning capability that saves developers time and effort by achieving the best model performance. It automates the machine learning model development workflow and seamlessly integrates into DevOps cycles, allowing large-scale and consistent deployment of models.
In conclusion, machine learning is a very powerful tool for businesses and researchers to create predictions for data problems. However, there are many steps to creating models and not every model is suited for each problem. We have to use a combination of human judgment and computational techniques to create the right model.
0 comments