
One of the most significant changes we’ve made in PIX-2008.26 has been to make the GPU capture process focus on capturing GPU work rather than API calls. This blog post will explain how PIX used to work, describe some of the drawbacks with this approach, how it works now, and the benefits we get from it. Hopefully, you’ll find this discussion of PIX’s implementation interesting and be able to use this information to better interpret the data provided by PIX.
Capture Layer
PIX on Windows supports GPU Captures by inserting a capture layer in-between the application and D3D. For example, PIX intercepts calls to D3D12CreateDevice, and provides its own implementation of ID3D12Device that wraps the real D3D version. This allows PIX to execute some code before and after the real object gets to do its work. We call the one returned by PIX the “Outer” and the one returned by D3D the “Inner”:
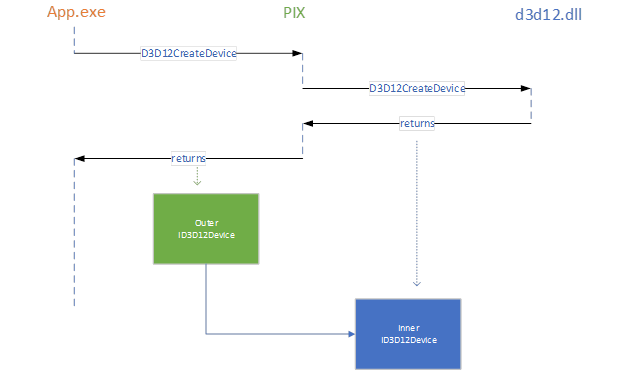
All other D3D12 objects are created via PIX’s new ID3D12Device implementation, so PIX continues this wrapping inners with outers, eventually forming a “layer” of Outers in-between the application and D3D.
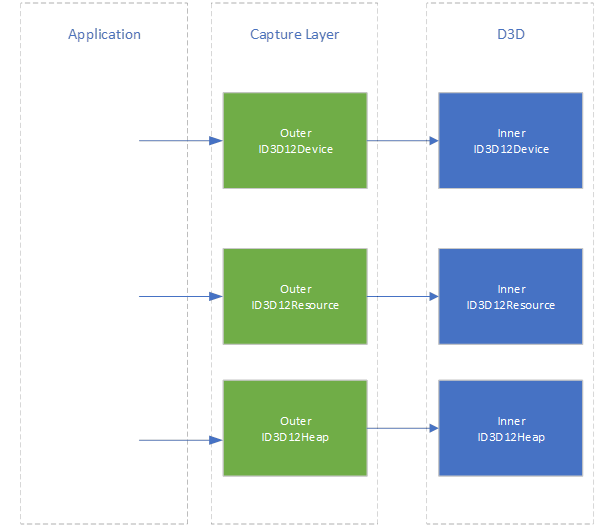
This layer allows PIX to perform additional state tracking. This is required since much of D3D12’s API is “write only”. Without state tracking, PIX would be unable to retrieve the list of commands that have been recorded into a command list, what the current resource barrier state is for a subresource, the shaders that were used to create a PSO, and so on. This information is used to store the contents of resources so they can be recreated at playback time.
Capturing API Calls
The strategy that we originally chose for capturing D3D12 applications was the same one that we had used for capturing D3D11 and D3D9 in previous products: capture all API calls and then play them all back. This was conceptually simple, but there were downsides to this approach:
- All API calls needed to be recorded and played back, including AddRef and Release. This was important to ensure that an object’s life span at playback time matched the life span at capture time. This worked well for D3D versions before D3D12 where the only significant life span is that of the objects themselves. With D3D12, it is up to the application to correctly ensure that many resources are not destroyed while the GPU is using them. The relationship between CommandLists and CommandAllocators can be especially problematic when you consider that the same command list can be used with multiple allocators. The reference counting implementation was extremely complicated! In addition to this, a significant portion of playback time was spent processing all of these API calls that ultimately had no impact on the GPU workload.
- As API calls may be made asynchronously on multiple threads, but playback is single threaded, we needed to figure out a single ordering for playback. This boiled down to having to serialize all API calls. This wasn’t a huge problem prior to D3D12 since applications tended not to be heavily multi-threaded. D3D12, however, was designed around supporting multiple threads recording command lists simultaneously, and so this overhead became an issue.
- When a capture was started, PIX needed to recreate the state of all D3D objects so that any subsequent API calls were replayed onto the correct state. This meant that all command list / command allocator pairs needed to have their state restored – even if the first API played back was Reset(). This doubled the number of commands that got recorded.
- It was hard to reason about the order that things were executed. The API calls may not necessarily happen in the same order that the GPU executes them (command lists may not be executed in the same order that they’re recorded, for example).
- Future features such as asynchronous playback on multiple queues really want to be more queue-focused rather than thread-focused.
Given all of this, we decided to move away from API Capture and instead capture GPU Work.
Capturing GPU Work
In Direct3D12, all GPU work is initiated by calling methods on a command queue. Work is executed on the command queue in a well-defined sequential order. Multiple command queues are synchronized by signaling and waiting on fences. Since all of this is visible to PIX, it can correctly recreate the GPU timeline at playback time and can defer the heavy lifting required to capture something until it sees it accessed by a method on the command queue.
Command Lists
Let’s look at what this means for ExecuteCommandLists in some more detail, since this is the main method that results in actual GPU work. When viewed through an API-call lens, command lists have some very strange behaviors. The commands are recorded through calls to DrawIndexedInstanced, Dispatch and so on and the command list is passed to ExecuteCommandLists to execute it. As soon as this has happened, you are free to Reset the command list and record new commands in it….but…you mustn’t reset the command allocator until the commands in that command list have finished executing on the GPU!
The reality here is that the commands are stored in the command allocator. The command list is the interface used to record new commands in the allocator; the main state in the command list itself is the information about the region in the command allocator containing the commands.
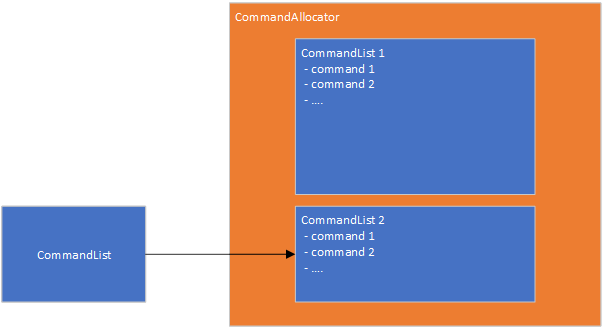
This allows us to simplify much of the reference counting code, as well as fix various life span issues involving bundles and ExecuteIndirect.
In the API capture world, PIX performed a full serialization of the API calls on a command list. When we approached this from a capturing GPU work direction, it was clear we could save lot of effort and instead just use simple in-memory data structures to represent the recorded commands. This is the source of one of the major performance improvements from the new capture layer.
Resource Recreation
When a capture is started, PIX needs to save the current contents of all resources – including any buffers, textures, render targets, PSOs etc. Previously, PIX serialized the API calls required to create and populate each resource. In the more GPU-work focused approach, PIX now serializes the data and metadata required to recreate the resources and is free to pick the best strategy to recreate them. This has allowed for some immediate optimizations in the caching behavior (where PIX is able to skip recreating a resource if it is still valid from the previous playback), and opens the door to some future ones – such as parallelizing PSO creation.
CPU Resource Updates
Another challenge that GPU captures face is how to track and update changes to resources that were made outside of the D3D API. Applications can use Map() to grant the CPU direct access to a resource in an upload heap and then modify it while rendering a frame. PIX needs to detect when the contents of a mapped resource changes and save out information about how to update the resource. When all you’re capturing is API calls this becomes confusing, since there’s no API call involved!
Our new approach is to record CPU modifications on a new CPU Timeline. This allows us to show CPU modifications in resource history, which is nice.
Capturing Video Playback
The D3D12 video APIs can only be used from specific types of queues. This is a problem for PIX since it currently uses a single DIRECT command queue to replay all its GPU work. Although we want to address this in the future, this is longer term goal (of which the new capture layer was an initial step). We would also like to enable capture of applications that use video APIs in the short term.
Rather than try to capture and replay the video API calls, we instead capture the changes the video APIs made to resources at capture time. See Austin’s blog post for more details on this.
Looking Forward
We’ve been thinking about moving towards this style of capturing GPU work for a couple of years now. Last year we started designing and implementing this for real. It’s exciting to see where this has taken us and the immediate performance gains it has provided. We see this approach as laying the ground work for all sorts of improvements to PIX, such as:
- Improved analysis performance
- Playback on correct queue types
- Analysis of async compute
- Interactive debugging of running applications
- Improved TDR debugging
As always, please feel free to contact us if you have any questions about using PIX on Windows.
I tried installing Pix on the surface pro x, and I get an error when it tries to install vc redistributables 2015. For some reason it doesn’t recognized that my surface is on Windows Pro, I made sure am at the latest. I hope someone can help me.