

Introduction
In this blog post, we share how our team improved the performance of data retrieval in Azure Cosmos DB while working on a customer engagement focused on seismic processing and imaging. The solution we were working with was already quite mature, but as the database size reached millions of documents, the customer was experiencing serious scalability issues with some of the basic read operations in Cosmos DB.
In our investigation, we found out that the Cosmos DB queries used in the solution to retrieve data were inefficient, taking minutes to return results when working with large databases. Our goal was to reduce the time required to query millions of documents down from minutes to seconds.
In this article, we describe how we adapted the Cosmos DB queries and why this improved performance. We also explore other patterns and tools that are useful when attempting to optimize data retrieval in large databases. The learnings we share in this article can be useful for other teams who struggle with slow queries in Cosmos DB and aim to improve the performance of data retrieval.
Context
In this example, Cosmos DB is used in the context of seismic processing and imaging data. In a typical seismic workflow, petabytes of data are stored as millions of datasets. Each dataset is comprised of files uploaded to blob storage and their associated metadata stored in Cosmos DB. The metadata contains, among other information, a project name with a ‘path’ attribute indicating the logical location of the specific file in a folder tree (as in a traditional file system).
The snippet below shows an example of a metadata document stored in Cosmos DB:
{
"id": "...",
"data": {
"name": "file.txt",
"project": "project_name",
"path": "/test/data/",
"created_by": "...",
"created_date": "..."
}
}Users working with seismic data frequently perform operations on millions of datasets at once, such as retrieving all datasets located in a specific project and path. Another common operation is retrieving all subfolders of a specified path; for example, given the snipped above, users may want to query all subfolders of the ‘test’ folder. Folders have no corresponding metadata documents of their own; a folder is considered to exist if there is at least 1 dataset with this folder in its path.
Initially, Cosmos DB was selected to store metadata, among other reasons, for its flexibility. In this case, different users of the system may choose to use different schemas for metadata. Another reason was the high scalability and SLAs offered by Cosmos DB.
The problem
Users query the database to retrieve datasets or subfolders in a specific project, located in a given path. The case which is particularly problematic (from a performance point of view) is the retrieval of a distinct list of folders (e.g. subfolders of folder ‘/test/data’) from a large set of documents (millions of datasets). The retrieving of datasets was significantly faster than fetching subfolders, hence we primarily focused on optimizing the subfolder retrieval.
Below is the original query that was initially used to retrieve subfolders. An explanation of what the query attempts to do is provided below.
SELECT
SUBSTRING(
c.data.path,
LENGTH("/test/data/") - 1,
INDEX_OF(
c.data.path,
"/",
LENGTH("/test/data/")
) - LENGTH("/test/data/") + 2
) AS path
FROM c
WHERE
RegexMatch(
c.id, "^(project_name-)([a-z0-9]+)$"
)
AND STARTSWITH(c.data.path, "/test/data/", true)
AND c.data.path != "/test/data/"
GROUP BY
SUBSTRING(
c.data.path,
LENGTH("/test/data/") - 1,
INDEX_OF(
c.data.path,
"/",
LENGTH("/test/data/")
) - LENGTH("/test/data/") + 2
)The query accomplishes the following:
- Filters dataset IDs against a prefix regex, to retrieve datasets belonging to a specific project.
- Filters the datasets by the path prefix.
- Groups by a calculated path substring that follows the given prefix, essentially performing a SELECT DISTINCT operation.
- Returns a list of subfolders located in the given path (in this case subfolders of the ‘/test/data’ folder).
While the original query performed well enough for small databases, it was very slow when working with millions of datasets, returning results after several minutes. The reason is that the subfolders query caused Cosmos DB to scan all documents in the database which is highly inefficient. There was also no custom indexing policy set up in Cosmos DB at the time.
Our goal was to improve the efficiency of retrieving datasets and subfolders and reduce the time required to fetch the results from minutes to seconds. The system we were working with was actively used in a production environment, hence our intention was to first explore options to improve performance without the need for data migration or changing the underlying storage.
Optimizing the query
The core of the improvements we applied was focused on optimizing the mentioned Cosmos DB query for retrieving subfolders. As a result of our investigation, our team decided to use the following query to achieve faster and more efficient retrieval of the results.
Query 1:
SELECT
distinct value c.data.path
FROM c
WHERE
c.data.project = "project_name"
AND startswith(c.data.path, '/test/data/', false)Unlike the original subfolders query, this query returns all distinct paths for the specified folder, each containing all parent folders up to the root. For example, let’s imagine that ‘/test/data/’ contains two subfolders, subfolder1 and subfolder2. The query will then return:
- /test/data/subfolder1
- /test/data/subfolder2
To only return the folder names at the deepest level (without the full path), as in the original query, we considered two options – using the distinct paths query as above and processing the paths programmatically in the client application or using a more complex query returning only the subfolders (Query 2).
Query 2:
SELECT
distinct value SUBSTRING(
c.data.path,
LENGTH("/test/data/") - 1,
INDEX_OF(
c.data.path,
"/",
LENGTH("/test/data/")
) - LENGTH("/test/data/") + 2
)
FROM c
WHERE
c.data.project = "project_name"Query 1 turned out to be faster in our tests, which is why we used the ‘distinct paths’ query and added post-processing of the results in the code. The reason why Query 1 is faster is that it is able to utilize the index on ‘c.data.path’ property, unlike Query 2 where we select a substring of the path.
Overall, the modified subfolders query brings the following optimizations:
- The new query filters the results explicitly by the project name instead of using a regular expression to match a prefix of the dataset ID.
- The original query scans the documents, calculates a complex substring expression for the entries, and deduplicates the results using the
GROUP BYstatement. Cosmos DB has another keyword,DISTINCT VALUE, which allows us to remove duplicates from the results. In our tests we found thatDISTINCT VALUEperforms better than an equivalentGROUP BYexpression. - The original query uses the case-insensitive version of
STARTSWITH; in our tests we saw that this version was significantly slower than the case-sensitive one, hence we modified the parameters of theSTARTSWITHfunction to make it case-sensitive. - In our case, there are significantly more datasets than distinct paths. As mentioned, we noticed that retrieving the paths first and then transforming them into subfolders was faster than the original query, hence we decided to use the distinct paths query.
Results
In this section we show the results we achieved for retrieving subfolders, after applying the mentioned patterns. The results depend heavily on the structure of the data. This includes how deep the logical folder tree is, how many folders are at a given level, etc. In the results below, the folder structure used can be explained with the help of the following diagram:
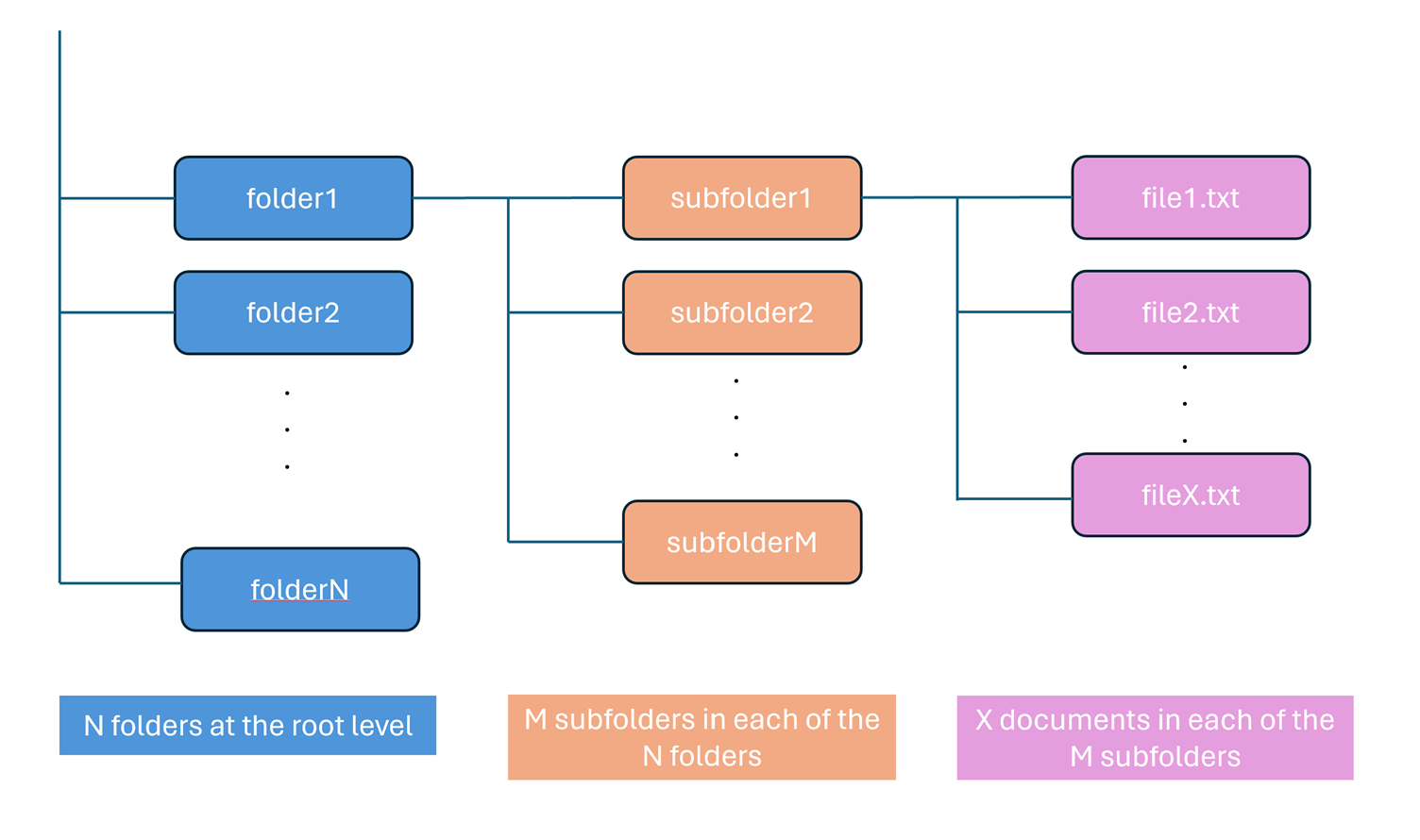
For example, folder structure 1,000 x 100 means that there are 1,000 folders at the root level and 100 nested subfolders in each of the 1,000 folders. The total number of datasets is evenly distributed across the subfolders.
Retrieving distinct paths / subfolders
| # of datasets | Folder structure (X folders at the root level x Y nested subfolders) | # of datasets per subfolder | New query runtime (mm:ss) | Original query runtime (mm:ss) |
|---|---|---|---|---|
| 1,000,000 | 1,000 x 100 | 10 | 00:05 | 01:17 |
| 10,000,000 | 10 x 1 | 1,000,000 | 00:04 | 10:53 |
| 10,000,000 | 1,000 x 100 | 100 | 00:12 | 12:02 |
| 100,000,000 | 1,000 x 100 | 1,000 | 05:38 | 37:56 |
In general, the applied optimizations showed very good results in terms of efficiency of subfolder retrieval, compared to the initial query. In most cases, the results are returned in under 30 seconds, while the original query often took several minutes. Thanks to the modifications, the query can be served more efficiently from the index, instead of having Cosmos DB scan all documents as before.
Looking at the numbers, the modified query gets significantly slower when the number of datasets reaches 10s of millions. In the next sections we look at other patterns that should be considered when optimizing data retrieval in large databases.
RU consumption in Cosmos DB queries
When queries are served from the index, the consumed RUs (Request Units) are typically much lower than for queries which result in a full scan. If there is a suspicion that the index is not utilized as expected, it is generally a good idea to look into the RU consumption. The table below shows the difference in consumed RUs in Cosmos DB that we observed with the initial and modified query.
Retrieving subfolders / distinct paths
| # of datasets | Folder structure | Consumed RUs – before | Consumed RUs – after |
|---|---|---|---|
| 1,000,000 | 1,000 x 100 | 59,566 | 820 |
| 10,000,000 | 1,000 x 100 | 580,368 | 8,164 |
| 100,000,000 | 1,000 x 100 | 2,744,887 | 127,096 |
Further improvements
This section covers some of the possible improvements that could further help optimize data retrieval from Cosmos DB. Please note that this article is not exhaustive and there might be other optimization patterns possible that we did not consider.
Choosing the partition key
In our case, each item stored in Cosmos DB has a unique ID, calculated as a combination of the dataset’s project name and a SH512 hash generated from the path and name. Given the unique IDs, each document is stored in its own logical partition and all items are evenly distributed across physical partitions.
This partition key was originally chosen for performant inserts. Each physical partition in Cosmos DB has a limit of 10,000 RU/s. Insert operations count towards this quota, so when too many inserts target the same physical partition, they will start failing. In case of the seismic metadata store we were working with, the insertion rate was high enough to consistently encounter this problem when the ‘project’ was used as the partition key.
Given the query patterns in our case, we considered introducing a hierarchical partition key to see if this could help us reduce the time needed to retrieve subfolders. However, for the reasons mentioned above, a hierarchical partition key starting with ‘project’ would not be helpful as it would lead to the same problem related to the physical partition limit in Cosmos DB.
Changing the partition key is an operation that requires a database migration. This was another consideration which led us to a decision not to introduce changes in the partition key.
Materialized views
After we realized that changing the partition key is not a good solution in our case, as it requires a migration and would lead to insert failures, a materialized view seemed like the perfect solution – it makes a copy of the database container with a new partition key, so that we can efficiently read from this new conveniently partitioned container without affecting write performance.
However, materialized views have certain limitations. They are currently still in preview, require recreating old containers, and there is always a sync lag between the base container and the view container. We discarded this option, but it can be a viable solution when it matures.
Optimizing the indexing policy
Cosmos DB by default indexes every property of a document. In our case, we only query the data by specific attributes (project and path), hence we considered modifying the indexing policy to better reflect these query patterns by adding a composite index including the project and path. Later, our tests showed that adding the composite index didn’t improve the performance of our queries, however, it is an important aspect that should be considered when attempting to optimize data retrieval from Cosmos DB.
Storing and indexing path segments
The query we use to retrieve subfolders is inherently inefficient because it groups documents by a substring of the ‘path’; such operations on the substrings of properties cannot use the index in Cosmos DB. To mitigate this, we could leverage the fact that these substrings are parts of the logical document path and pre-calculate them. The documents stored in Cosmos DB could then be enriched with these path parts and used explicitly in the indexing policy. The best approach we found to implement this optimization was to store path prefixes. The example below illustrates this concept:
{
"data": {
"project": "project_name",
"path": "/test/data/subfolder/",
"pathPrefixes": {
"prefix0": "/test",
"prefix1": "/test/data",
"prefix2": "/test/data/subfolder"
}
}
}
It is also possible to store just the individual path parts, instead of full prefixes. While the prefixes consume more disk space than storing only the path parts, we found that it is easier to manage the indexing policy for the path prefixes. In this approach, the index would look as follows:
{
"compositeIndexes": [
[
{"path": "/data/project", "order": "ascending"},
{"path": "/data/pathPrefixes/prefix0", "order": "ascending"},
{"path": "/data/pathPrefixes/prefix1", "order": "ascending"}
],
[
{"path": "/data/project", "order": "ascending"},
{"path": "/data/pathPrefixes/prefix1", "order": "ascending"},
{"path": "/data/pathPrefixes/prefix2", "order": "ascending"}
]
]
}The query retrieving subfolders would then efficiently fetch the results from the index:
SELECT DISTINCT VALUE c.data.pathPrefixes.prefix2
FROM c
WHERE
c.data.project = "project_name"
AND c.data.pathPrefixes.prefix1 = "/test/data"
Cosmos DB is introducing computed properties (the feature was still in preview at the time of writing this article) which could be a good solution for a case like this, if we prefer not to change our data model by adding the ‘artificial’ path parts to the stored metadata. Computed properties allow users to specify values derived from the existing attributes and include them in the indexing policy, without the need to persist them in the data stored in Cosmos DB.
We experimented with computed properties and, in our tests, they performed equally well as using the persisted properties to store the path segments, while the overall database size was smaller.
We did not end up using computed properties in our solution due to the preview status, however, it is a viable option that can help improve the performance of subfolder retrieval and could be considered in the future.
Considering another storage solution
In the case described, Cosmos DB is used to store information about logical paths of the datasets. If possible, it should be investigated whether using a different type of storage, such as a relational or a graph database, might bring performance improvements. In our case, there were other factors and dependencies which made us search for the optimizations based on using Cosmos DB as the storage back-end rather than switching to a different database.
Conclusion
We have shown how the original query used to retrieve subfolders from Cosmos DB was inefficient and resulted in scanning all items in the database. We demonstrated that optimizing the query to be served from the index instead allowed us to reduce the time needed to retrieve data from several minutes to seconds, when working with millions of records in a database.
This example shows that when working with large databases it is important to ensure that queries can be served from the index, especially where the partition key cannot be used to narrow down the datasets to be queried, in order to achieve fast data retrieval.
These learnings can be helpful for other teams who are struggling with low performance of data retrieval in Cosmos DB. When working with slow queries in large databases, we recommend investigating whether the applied indexing policy is being used efficiently. If this is not the case, optimizing the queries using the patterns described in this article can help significantly improve the performance of read operations.
Acknowledgements
Contributions to the optimization patterns described in this article from the Microsoft ISE team: Laura Damian, Alexandre Gattiker, Konstantin Gukov, Izabela Kulakowska, Christopher Lomonico, Max Zeier.