

Introduction
Companies commonly face challenges in centralizing their data to establish a single source of truth throughout the organization. This centralization is required for generating reports, alerts, and analytics that drive business decisions. While a unified data management platform is a frequent goal, each organization encounters distinct challenges in its development, such as:
- Data Source Management: Bringing together scattered data is like solving a puzzle.
- Concurrency Handling: Managing data tasks simultaneously requires strategic coordination.
- Simplifying Updates: Updates should be seamless, but complexities often arise.
This blog reveals our practical approach, the challenges we encountered, and the innovative solutions that paved the way for data centralization.
Section 1: Why We Did It?
The Need for Centralization
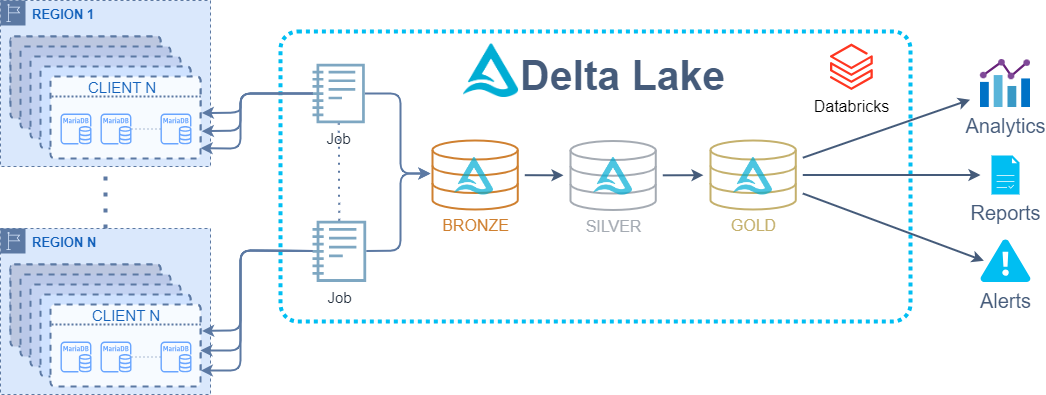
As part of our collaborative engagement with a customer, the primary business imperative they presented was the requirement for reports, alerts, and the extraction of valuable business insights from their available data. In this context, we found ourselves facing a situation where each client maintained their own MariaDB databases instances across different regions, all with identical table structures but significant data variations.
To meet this business need, we recognized the requirement to establish a single source of truth for our data. Centralization emerged as the essential solution to unlock the full potential of their data. This centralization would also lay the groundwork for building a Medallion Architecture over Databricks and provide their data scientists with a unified platform, simplifying their analytical tasks and improving overall productivity.
Some of the benefits of centralization for the customer include:
- Unified Global Data: Ensuring a single, unified view of data across all regions and clients.
- Efficient Reporting and Alerts: Streamlining the creation of reports and alerts for improved efficiency.
- Enhanced Business Insights: Enriching reports and alerts with valuable business insights.
- Simplified Data Extraction: Empowering teams on both sides to easily extract data.
This centralization initiative was a strategic response to a real-world business challenge, and the subsequent sections will focus on the “how” of turning this collaborative need into a reality.
Section 2: How We Did It
The Decision to Go for a Proof of Concept
In our case, building a complete development environment and acquiring a reliable, testable dataset were time-consuming tasks.
Faced with numerous designs to implement and only a couple of weeks to address development, we opted for a Proof of Concept approach. This allowed us to prioritize immediate business value while recognizing the potential for future enhancements.
Why Azure Databricks Was the Ideal Solution
Azure Databricks proved to be the perfect solution for our data centralization needs, for several key reasons:
- Monitoring: Azure Databricks provided robust monitoring capabilities, allowing us to keep a close eye on the entire data synchronization process of running jobs, spark performance, lineage and more.
- Concurrency: With Azure Databricks, we had built-in concurrency management. This was important as we needed to ingest large amount of data, optimizing data transfer using concurrency was a must.
- Familiarity and Infrastructure: One of the main reasons for choosing Azure Databricks was our customer’s familiarity with the platform. They had already deployed it in their environments for other use cases, and our team was well-versed in working with Azure Databricks.
- Business Analytics: Beyond just data centralization, Azure Databricks can be served as a platform for leveraging data for business analytics. The ability to easily analyze and extract insights from the consolidated data was a significant benefit for our project.
- Smooth Transition: Azure Databricks turned out to be a flexible in-between solution. If needed, switching from Azure Databricks to Azure Data Factory (ADF) or creating our own system was relatively straightforward.
- Security and Governance: A future enhancement for security in Databricks might include incorporating Unity Catalog providing unified governance and access control for data.
Our Data Centralization Strategy and Implementation
To centralize data from MariaDB databases into Delta Lake in Azure Databricks, we needed an efficient solution capable of ingesting data incrementally. Fortunately, most of the tables we were working with had an update_timestamp column that indicated when a row was last updated. This timestamp allowed us to filter for new data, essentially creating an incremental update system.
For our solution, we decided to leverage Databricks Jobs as part of the centralization process. Here’s how we laid the groundwork:
- Delta Table Creation: We started by creating a Delta table that stored the information that would help to keep track of when was the last time we synced the data, the table had these columns: client id, table name, the last sync timestamp, and the specific schema the table came from. This table acted as the ‘control center’ for managing the data synchronization process.
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {table_path} (
schema STRING,
client_id INT,
table_name STRING,
last_sync_timestamp TIMESTAMP
)
USING delta
PARTITIONED BY (schema, client_id)
""")- Orchestrating Jobs: We designed a PySpark notebooks job orchestration system. For each client, we created an ingestion job for every table. This allowed us to monitor the data ingestion process closely, while Azure Databricks built-in capabilities provided us with retry mechanisms and concurrency.
- Database Source: As our clients database sources were primarily MariaDB, we developed a basic JSON configuration file that specify table names, schemas, and connection details to the database. We scheduled daily, weekly, or monthly jobs based on our business requirements, and each type of job had a different JSON configuration file.
Ingestion and Merging
Centralizing data from MariaDB databases into Delta Lake was like piecing together a puzzle, where each part had a role to play.
1. Setting the Stage:
- Each notebook job was like a stage manager, arranging the necessary settings, loading the appropriate job JSON configuration file, and setting up the spark environment.
- It connected to MariaDB databases using the details in the configuration file.
- it loaded the clients from a separate service and filtered them based on the region which was set as an environment variable.
2. The Magic of Spark:
- The notebooks used the power of PySpark to orchestrate the data operations seamlessly. Spark’s parallel processing capabilities allowed for efficient data fetching and writing.
- we also made sure that the appropriate central tables are created in Delta Lake to store the data, while Delta Lake’s architecture provided ACID transaction support, ensuring data integrity throughout the process.
3. Data Filtering and View for Data Scientists:
- Data filtering was performed based on criteria such as the client, last synchronization date, table, and columns to be centralized.
- We’ve added intermediate stages in the notebooks to allow data scientists to view details about the changed data and clients and make manual modifications if needed.
- For some tables, additional filtration was needed, based on the configuration we applied the additional queries. For example:
changes = self.spark.sql( f"SELECT * FROM {database}.{table_name} WHERE {desired_field} = {given_value} {additional_query}") return changes
4. The Big Merge:
- A critical phase of the process involved merging data from different client databases into a single source of truth table.
This was achieved using SQL-based MERGE, For example:
table_path = f"{database}.{table_name}" # table to merge into df.createOrReplaceTempView("new_data") # new data to merge # merge statement based on the id column with additional dynamic merge keys, based if `client_id` and `region` exists in the table self.spark.sql( f""" MERGE INTO {table_path} AS target USING new_data AS source ON target.{id_column} = source.{id_column} {f"AND target.client_id = {client_id}" if "client_id" in table_columns else ""} {"AND target.region = source.region" if "region" in table_columns else ""} WHEN MATCHED THEN UPDATE SET * WHEN NOT MATCHED THEN INSERT * """ )
Using PySpark, we were able to modify the merge statement to fill the specific columns.
5. Keeping Records:
- A sync log table was updated to track the last time data was centralized for each client and table.:
# a simple merge statement to update the sync log table based on a single row of client table details, updating to the current timestamp, thats a simple hack to upsert a single row self.spark.sql( f""" MERGE INTO {sync_log_path} AS target USING (SELECT '{schema}' AS schema, '{client_id}' AS client_id, '{table_name}' AS table_name, current_timestamp() AS last_sync_date) AS source ON target.schema = source.schema AND target.table_name = source.table_name AND target.client_id = {client_id} WHEN MATCHED THEN UPDATE SET target.last_sync_date = source.last_sync_date WHEN NOT MATCHED THEN INSERT (schema, table_name, last_sync_date, client_id) VALUES (source.schema, source.table_name, source.last_sync_date, source.client_id) """ ) - The entire process was richly documented with structured logs to enable future analysis and troubleshooting.
Of course some challenges and complexities emerged during the process, for example inconsistencies between regions/client columns names, or a needed logic to extract the actual ID columns for each table, which weren’t the typical id.
Upon successful extraction and merging, the centralized data was readily available for use as a Bronze layer. which ultimately served as a single platform with all the data needed for generating reports, alerts, and fulfilling various business requirements. The data was well-prepared for further processing into curated business-level tables, aligning with the principles of a Medallion Architecture.
Managing Data Influx and Concurrency
Some of the challenges that surfaced while running our implementation was slow ingestion, and when running multiple regions ingestion job, as data streamed in from multiple sources, we received errors for multiple sources trying to update a specific partition that was already updated simultaneously. it became clear that effectively handling concurrency was crucial.
Tackling the Concurrency Challenge and Partitioning for Enhanced Performance:
Centralizing data brought unique challenges, like handling large data volumes rapidly. To tackle this, we adopted a strategic approach that managed data influx while partitioning Delta tables.
The first step was to separate data ingestion from table creation, trying to avoid multiple jobs creating the same single source of truth table.
Secondly, to ensure smooth data processing and avoid conflicting issues, we organized our tasks by region and client, aligning them with the necessary partitions in our Delta tables.
Working on different partitions concurrently, worked seamlessly and significantly reduced data ingestion times. Previously, ingesting demo data took 2 minutes per table, but our optimized approach brought it down to less than 20 seconds per table, showcasing the effectiveness of our strategy in handling data influx and concurrency.
Here’s an example of how we created and executed synchronization jobs for each client’s tables:
sync_job = "jobs/sync_clients_tables.py" # the job that syncs the tables
sync_job_path = os.path.join(databricks_service.get_repo_path(), sync_job) # the path to the job
for client in clients:
job_params = prepare_job_param_for_client(client) # prepare the job params for the client including the tables to sync
# <logs>
# prepare the job specific task, for running the python file with the job params
task = jobs.Task(
description=f"Tables sync for client - {client.ID}",
existing_cluster_id=cluster_id,
spark_python_task=jobs.SparkPythonTask(
python_file=sync_job_path, parameters=[json.dumps(job_params)]
),
task_key=f"tables-sync-for-{client.ID}",
timeout_seconds=0,
)
try:
# use the databricks jobs sdk to create the job and run it
created_job = w.jobs.create(
name=f"tables-synchronization-for-client-{client.ID}",
tasks=[task],
max_concurrent_runs=1
)
w.jobs.run_now(job_id=created_job.job_id)
# <logs>
except Exception as e:
# <logs>With management of data influx and concurrency in place, our centralization orchestration continued to thrive.
Section 3: Consideration of Azure Data Factory and Change Data Capture (CDC)
In the world of data integration, there are many solutions, each with its unique strengths and advantages. One of them is Azure Data Factory (ADF), a versatile tool for orchestrating data workflows. Before we explain why we didn’t use it, let’s provide a brief overview of what ADF offers and why it’s a popular choice.
Overview of Azure Data Factory
Azure Data Factory (ADF) is a comprehensive data integration service that excels in handling diverse data workflows. Its capabilities make it a robust choice for orchestrating complex data processes. ADF provides features for data movement, transformation, and orchestration, allowing organizations to design and manage data pipelines efficiently, and it offers a wide range of connectors for various data sources, with the ability to highly customize the data integration process, with a low-code approach.
Why We Opted for a Different Path
While ADF offers numerous capabilities, our data centralization project took a different approach based on our unique circumstances and requirements:
- Limited Data Source Compatibility: Azure Data Factory would have required extra configuration and custom connections to handle dynamic data sources. This extra step of creating a dynamic JSON configuration for the pipeline was time-consuming and not feasible within our tight project timeline.
- Real-time Adjustments: In our project, it was essential to have the flexibility to make instant changes during specific runs, especially for data scientists who might need to fine-tune things on the fly. For this particular need, we found a better fit in a more code-centric tool like Azure Databricks.
- Challenges with Incremental Updates in Azure Data Factory: The process of efficiently handling incremental updates in scenarios where data sources were dynamic and can have schema drift over time, exposed some challenges in Azure Data Factory which we found difficult to overcome.
- Time Setting up, upskilling, and planning an Azure Data Factory solution would have been too time-consuming, So, we opted for tools that we already knew well, and were already in the environment.
Unpacking Change Data Capture (CDC)
Change Data Capture (CDC) is the process of identifying and capturing changes made to data in a database and then delivering those changes in real-time to a downstream process or system. This feature is especially valuable for handling incremental updates, where only the modified data is extracted and processed.
There are multiple ways to get CDC, one way involves using Azure Data Factory. However, it’s essential to note that as of today, CDC within Azure Data Factory is in its preview stage and unfortunately, during our project evaluation, native CDC support for MariaDB in Azure Data Factory was not available. Otherwise, it might have been an ideal fit for us.
As an alternative, we considered using CDC with a combination of Kafka and the Debezium connectors, alongside ZooKeeper. However, it’s crucial to recognize the complexities in setting up this infrastructure, especially in our case where we were dealing with dynamic databases across multiple regions and clients. Additionally, configuring the right network policies within the Kubernetes (k8s) environment added another layer of intricacy. We tried to investigate that more closely, but we discovered that even if we do go the CDC way, our MariaDB databases did not expose the binlog, which is a requirement for CDC to work. Even if we enabled CDC right now, it wouldn’t resolve the data gap challenge for the initial data ingestion. So, while CDC remains a good choice for handling future incremental updates, it may not be the ideal solution for the initial bulk data transfer.
Section 4: Wrapping Up Our Journey
As we conclude our data centralization journey with Delta Lake in Azure Databricks, let’s reflect on the key takeaways:
- Why Centralize?: Centralizing data is like gathering scattered puzzle pieces. It might require some effort, but the end result produces business value that’s well worth the investment.
- The Right Tools Matter: The right tools can make all the difference, don’t hesitate to compare and evaluate different options.
- Creating Reusable Components: To handle lots of data, you need to think big. We split our data into pieces and processed them concurrently.
- Think About The Future: We designed our solution to be flexible and scalable, with the potential for future enhancements.
- User-Centric Approach: We put ourselves in the shoes of the data scientists who would be using the data, and designed our solution accordingly.
Final Thoughts
Our engagement aimed to support the customer in preparing for data centralization. The successful Proof of Concept marked a crucial step toward full-scale production.
This journey enhanced our skills and had a significant impact on the customer team needs, empowering us to drive value for the business. It sets the stage for future successes in data centralization and analytics.
Thank you for joining us on this journey, and we hope you found this blog useful.