
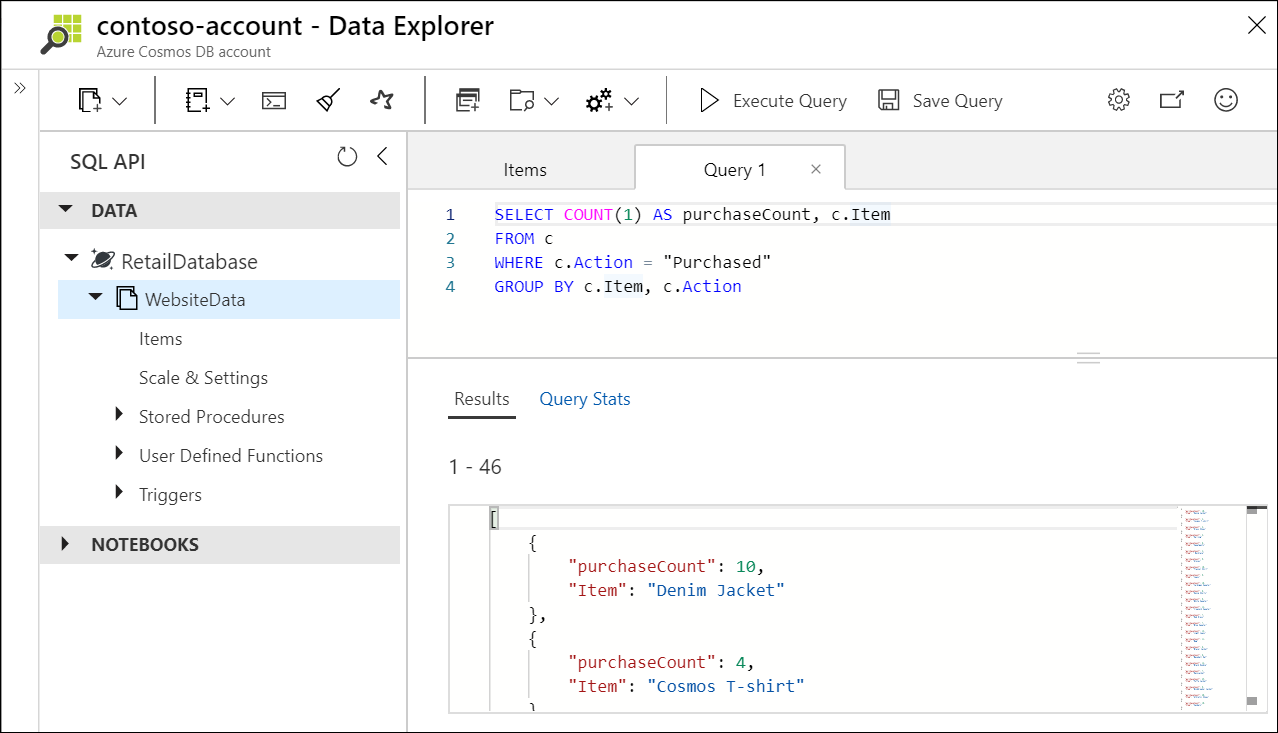
Azure Cosmos DB is Microsoft’s globally distributed, multi-model database service. It offers turn-key global distribution, guarantees single-digit millisecond latency at the 99th percentile, 99.999 percent high availability, and elastic scaling of throughput and storage.
For Ignite 2019, we’re excited to announce tons of new features, capabilities and improvements for our users based on your feedback, including support for GROUP BY queries, automatic scaling of throughput, an analytical storage engine for fast analytical queries, and more.
GROUP BY support
Azure Cosmos DB now supports GROUP BY queries! This is one of our top asks from customers and we are excited to release this capability. With GROUP BY, you can run queries that group your results according to the values of one or more specified properties. This feature is currently supported in Data Explorer, JavaScript SDK 3.4, and .NET SDK 3.3. Support for other SDKs will be available later this year.
Autopilot Preview
Estimating the right amount of throughput (RU/s) for your Cosmos databases and containers is key to optimizing cost and performance. We’ve heard from many of our customers that this can be a hard problem.
We’re excited to announce that we are making this a lot easier with our preview of Autopilot. With Autopilot, Azure Cosmos DB will automatically manage and scale the RU/s of your containers based on the usage. This eliminates the need for custom scripting to change RU/s and makes it easier to handle bursty, unpredictable workloads.
You can try out Autopilot in your Cosmos accounts by going to the Azure Portal and enabling the feature in the “Preview Features” blade.
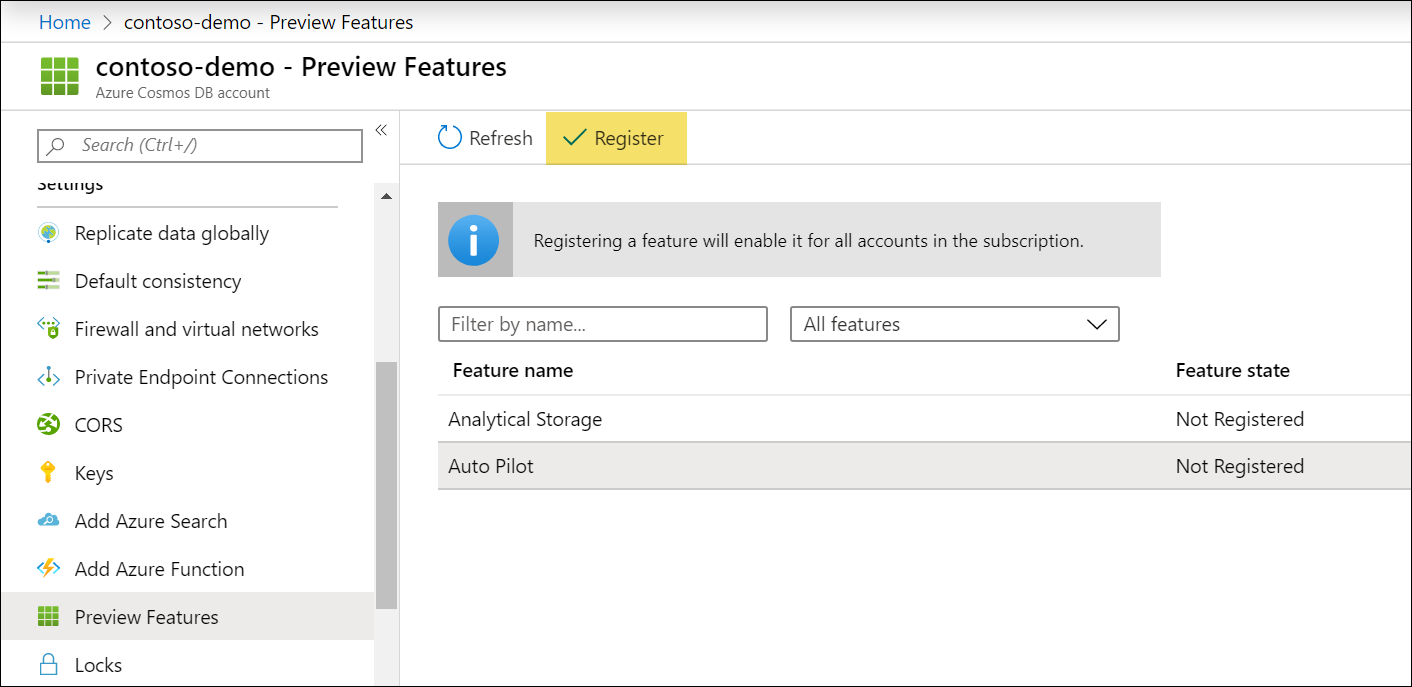
Then, in the container create pane, select Autopilot mode and choose the max RU/s you want Azure Cosmos DB to scale to.
Analytical storage & Synapse integration private preview
Many of our customers store operational or hot data in Azure Cosmos DB and would like to do analytics on larger volumes of current and historical data. Customers typically use our Change Feed or other ETL mechanisms to move the hot data into storage suitable for analytics and run their analytical queries there.
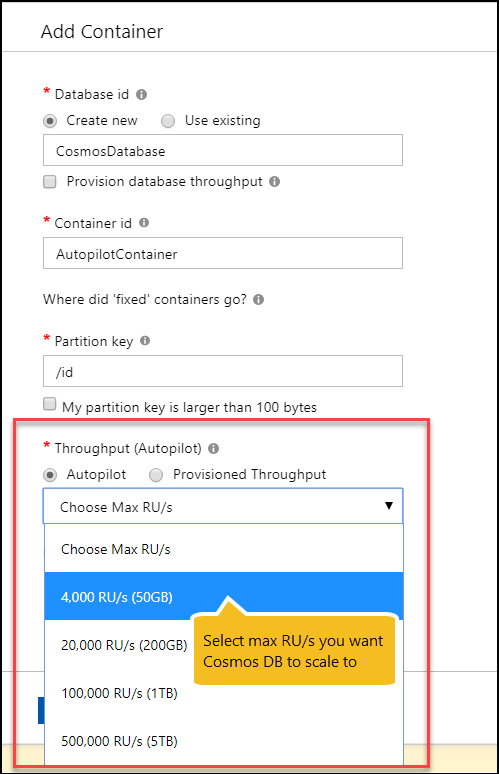
With our new analytical storage engine and Synapse integration preview, this capability is natively built into Azure Cosmos DB. Cosmos containers can now be enabled to be backed by two storage engines: a transactional storage engine – Azure Cosmos DB as you know it today – and a new analytical storage engine. For analytical workloads, you can configure your container to automatically have your data encoded in a versioned columnar storage format for fast analytical queries, scans and updates. This data is stored in a cost-efficient off-cluster storage, with no ETL from your end required. We’ve also integrated our Azure Cosmos DB Spark connector directly into Azure Synapse Analytics’ Spark capabilities, making it easy to query and operate over your data.
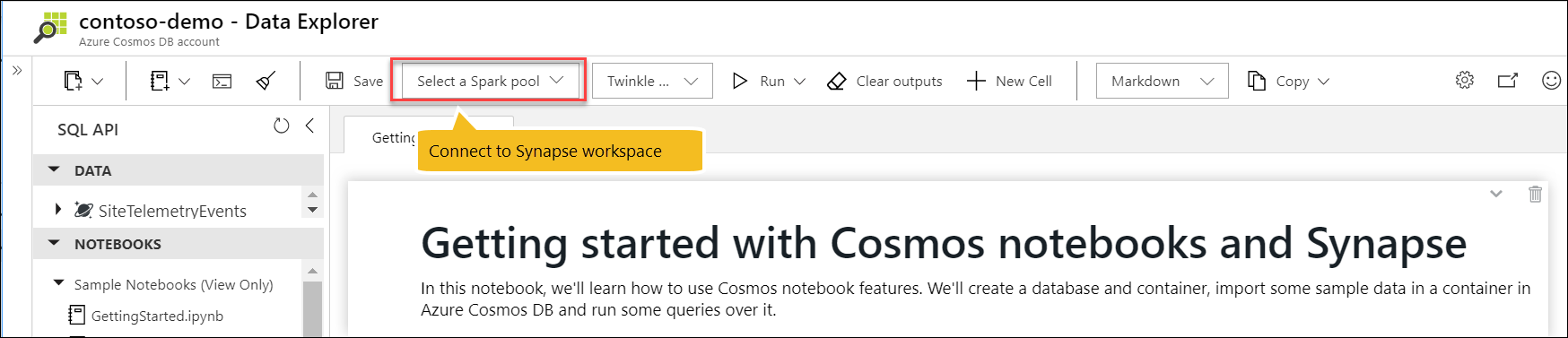
To sign-up for the private preview, go to your Cosmos account in the Azure Portal and register for the feature in the “Preview Features” blade. You can connect to a Synapse workspace and Spark pool resource directly from a Azure Cosmos DB notebook in Data Explorer.

Built-in Jupyter notebooks updates
In September, we made built-in Jupyter notebooks, or Cosmic notebooks available. Since then, we’ve added new features, including an %upload magic command that makes it easier and faster to import data, new built-in chart UX with Nteract integration, and support for Azure Synapse Analytics workspaces.
Developers, data scientists, engineers and analysts can use these notebooks – which are directly integrated in the Azure portal – to interactively run queries, explore, analyze, and visualize their Cosmos data, and build/train machine learning models. We’ve also bundled in our latest Azure Cosmos DB Python SDK and SQL query magic commands to make it easier to run operations against your data, no setup required. Get started with notebooks and checkout our samples gallery.
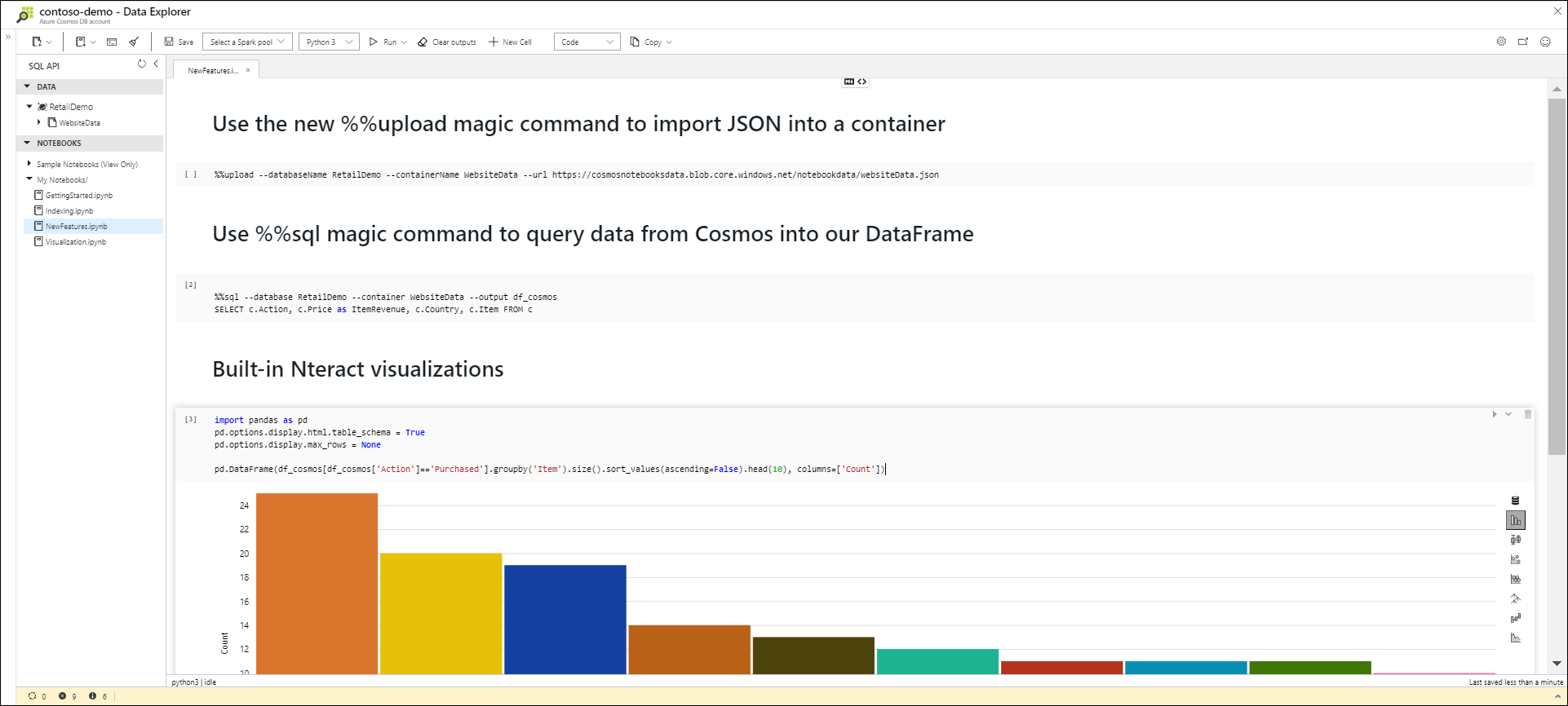
Cosmos Explorer
Cosmos Explorer, the full-screen standalone web-based version of the Azure Cosmos DB Data Explorer, now supports API for MongoDB and Cassandra API accounts, in addition to SQL (Core), Table, and Gremlin API. You can use Cosmos Explorer to access your database accounts for all APIs to do common operations, like creating new resources, running queries, and more. You can also share temporary access to authorized peers, without the need for them to have subscription or Azure portal access.

Bulk execution mode in .NET SDK
With the new bulk execution mode directly in the Cosmos .NET SDK, you no longer need to use a separate Cosmos bulk executor library to use bulk functionality. For bulk import and delete scenarios, you can now use bulk operation mode to optimize your usage of provisioned RU/s, all with the same SDK for your bulk operations and client application.
Bulk execution mode is available in Cosmos .NET SDK version 3.4 and later. It supports point operations (Create, Read, Upsert, Replace, Delete). Using it requires minimal code change: just set the AllowBulkExecution property when initializing your CosmosClient and run your point operations as normal. Behind the scenes, the SDK will group concurrent operations into a single service call to optimize the throughput utilization. Get started with our tutorial.
Transactional batch in .NET SDK
You can now do a transactional batch of operations on your data with the same partition key value, using the Cosmos .NET SDK version 3.4 and later. Previously you had to author and call server-side stored procedures written in JavaScript to achieve the same functionality. Operations in a batch will either all succeed atomically, or all be rolled back together.
SDK Updates
We are releasing new major preview versions of our .NET, Java and Python SDKs and a minor version update of our JavaScript SDK to provide a better developer experience and align with the Azure SDK guidelines.
| SDK | Major Version | Quickstart |
| .NET | V4 (Preview) | https://aka.ms/cosmos-dotnet-v4 |
| Java | V4 (Preview) | https://aka.ms/cosmos-java-v4 |
| Python | V4 (Preview) | https://aka.ms/cosmos-python-v4 |
| JavaScript | V3 | https://aka.ms/cosmos-javascript-v3 |
Private endpoint support (preview)
Azure Cosmos DB now supports private endpoint. With private endpoint, you can privately and securely connect to a service powered by Azure Private Link, effectively bringing the service into your VNET. Get started with private endpoint. The preview is currently available in West US, West Central US and North Central US, with more regions planned.
Management experience updates
We have two major updates to improve the management experience for Azure Cosmos DB. The first is a new Azure CLI that provides full support across all Azure Cosmos DB API’s including SQL (Core) API, Cassandra, API for MongoDB, Gremlin API and Table API. And last, the new Azure Resource Provider version includes support for idempotent ARM templates which now allow customers to change throughput for Azure Cosmos DB resources using the same ARM template used to deploy the resource.
Reserved Capacity updates
Reserved Capacity allows you to save money by purchasing 1 or 3 year reservations of provisioned RU/s at a discount. We’ve lowered the entry point 4x down to 5000 RU/s and you can now pay monthly. You can view recommendations for reserved capacity in the “Notifications” section of your Cosmos account in the Azure Portal.
Can't find where to post... But there has been a problem with Cosmos since it used to be called DocumentDB. I used it back then for a little. Found and problem and had a workaround. Left, just returned to CosmosDB with v4 of the SDK, and the problem is still there. The problem is manifested with CosmosContainer.CreateItemStreamAsync.
I'm not going to write a complete repro, up/down vote. I have a workaround. You should fix it. But if you don't... at least others won't have the problem again.
Below is a sloppily written repro case, don't...
Hi Jason, thanks for your feedback! Your issue seems to be really related to the SDK, and I think the SDK GitHub repo is probably the best place to present it.
Could you create an issue with all the required information in that repo (https://github.com/Azure/azure-cosmos-dotnet-v3/issues)?
Thanks!
Are Bulk execution mode and Transactional batch supported in Java SDK? Thanks
Hi, I'm looking at the transactional vs analytical storage engines excerpt. Is there any in depth documentation out there?
I would like to know how to switch/select between engines.
Is this a parameter that is selected upon the creation of a container only?
Also, I can see that there is no limit for the size of data for a given partition when the data engine is the Analytical. How does this affect read latencies?Read more
Say, I have (A) 100GB on a partition using the analytical engine, similarly, (B) I have 8GB of data on a parition using the transactional engine.
I think there is a bug with AutoPilot and the 4000-20000 option. It starts with 2 partitions and 1K RU each instead of 2K.
Just to continue my research i bumped up the 20K autopilot collection to 100K and noticed that during the transition
the system increased the partitions to 4 and each one ended up with 500 RUs which validates the previous observation.
Also bumping up a 20K collection to 100K results in uneven splits i.e hot partitions. The algorithm splits the first 2 into 4,
then the 4 into 8 and finally 2 out of the 8 are split...
Hi Anargyros. Please email us at askcosmosdb@microsoft.com and send us your Cosmos account names. We’d like to take a closer look.
Thanks.
Is there a way to deploy a new Cosmos DB with the Autopilot feature using an ARM template? If so, is there (already) any documentation on the configuration within ARM?
BTW: nice feature!
Not just yet. We’re working on updating our resource provider schema and then we will create a new ARM template and post it here as an example.
https://docs.microsoft.com/en-us/azure/cosmos-db/resource-manager-samples
Thanks!
How does “Reserved Capacity” apply to Autopilot RUs?
Are there more information on how the Auto Pilot works? Does it work quicker than upscaling manually (we noticed this sometimes takes several minutes) and when does it upscale? Is it configureable in any way (e.g. “after how many 429s upscaling should take place” or “how much percentage buffer should be allocated”?)
Thanks for this big update! Can we expect this every month now? 😉
Hi Roman. Right now Reserved Capacity does not apply to AutoPilot accounts. We are working on adding this for when it goes GA.
AutoPilot will instantly scale up and down but scaling up or down manually happens instantly as well. The key is to scale up your container to the desired throughput first and then scale it back down. Then ever time you scale it up it afterwards it happens instantly.
Thanks.
Hi Mark,
thanks for your quick reply. This clarifies my questions 🙂
Roman
Mark, after running a few tests we see that it scales up as expected. However, after finishing the tests we don’t see it scales down again (we’ve waited a few hours). Instead it stays at the maximum configured (shared) throughput. Since you mentioned “AutoPilot will instantly scale up and down” I was wondering if we either having a different understanding of the word “instantly” 😉 or that there is more to it which isn’t yet explained anywhere.
It should not take that long to scale down. We would like to get some more telemetry on this. Can you email askcosmosdb@microsoft.com with you subscription id and Cosmos account and container so we can take a closer look?
Thanks Bram.
FYI for anyone looking at the sample code for transactional batch support - it appears maybe there were some last minute API changes that broke the sample code provided. In order to get the example to compile I had to change a few things. I forked the gist and applied the changes I had to make: https://gist.github.com/andrewdmoreno/e93552ee0894dcbc1b403fe0b544c4bf
On that note, are we able to run this on local emulator? I imagine not at this time, but just wanted to confirm. When I attempted to run it it got stuck on the CreateTransactionalBatch method call.
This should run on local emulator. Can you send us a stack trace for that error and Activity Id to askcosmosdb@microsoft.com? We can help troubleshoot it for you.
Thanks.
Not sure what I was doing wrong yesterday Mark, but I can confirm that it is working in local emulator also. Thanks!
You bet!
I have turned the Autopilot preview feature and can now see the autopilot options when creating a new database.
However, when I go to an existing database there is no option for autopilot?
Is there a way to configure autopilot for an existing database? I want to switch over one of our dev environment databases to test this feature
Unfortunately today you need to create a new account. We will look into providing a migration path for customers but today this requires a new account.
Thanks
No worries, thank for the reply