

We’re excited to present the sixth edition of our blog series, dedicated to exploring design patterns in Azure Cosmos DB for NoSQL applications. Drawing from real-world customer experiences, our aim is to help you navigate the intricacies of JSON-based NoSQL databases. In this chapter, we delve deeper into prevalent NoSQL patterns, perfect for those new to this database type. We also focus on patterns specific to Azure Cosmos DB, demonstrating how to harness its distinct capabilities to tackle complex architectural issues.

These patterns, previously shared individually with customers, are now being made more widely accessible. We believe it’s the right moment to broadly publish these insights, enhancing their discoverability among users. Thus, we’ve created Azure Cosmos DB Design Patterns — a GitHub repository filled with an array of examples. These samples are meticulously curated to demonstrate the implementation of specific patterns, assisting you in addressing design challenges when utilizing Azure Cosmos DB in your projects.
To help share these, we have created a blog post series on each of them. Each post will focus on a specific design pattern with a corresponding sample application that is featured in this repository. We hope you enjoy it and find this series useful.
Here is a list of the previous posts in this series:
- Part 1: Attribute Array
- Part 2: Data Binning
- Part 3: Distributed counter
- Part 4: Global distributed lock
- Part 5: Document versioning
Azure Cosmos DB design pattern: Event Sourcing

Event sourcing is a powerful architectural pattern that has its roots in Domain-Driven Design. It represents a fundamental shift in how entities maintain their internal state. Unlike traditional methods that rely on direct serialization or object-relational mapping, event sourcing achieves this by recording a series of events in an event store.
At its core, event sourcing involves a container-like structure that records events in an append-only manner. This means that events are added to the log, but not updated or deleted. The result is a comprehensive historical record of all events, providing a valuable resource for various system functions.
This approach offers several significant advantages in application design. A key benefit is its natural pairing with the Command Query Responsibility Segregation (CQRS) architecture pattern. In such combinations, especially with Azure Cosmos DB, the Change Feed feature plays a crucial role. It facilitates the read layer of the architecture, supporting patterns like Materialized Views, which are also often used with CQRS. Additionally, event sourcing can establish a communication layer for loosely coupled services, enhancing system flexibility and scalability.
While event sourcing can be implemented with different database types, it finds resonance with developers using Azure Cosmos DB for several reasons:
- Flexible Schema: NoSQL databases like Azure Cosmos DB are known for their schema flexibility. This adaptability is ideal for event sourcing, where unstructured event data, often in JSON format, needs to be supported seamlessly.
- Scalability: NoSQL databases are designed to manage high scalability demands. Event sourcing can generate a vast range of data volumes, from thousands to millions of messages per second. Azure Cosmos DB’s scale-out architecture, with its highly elastic throughput and storage capabilities, is well-suited to meet these demands.
- Change Feed as a Messaging Mechanism: The Change Feed feature in Azure Cosmos DB acts as a centralized and scalable message publishing system. This is particularly useful in event sourcing patterns, where tracking changes and updates in real-time is crucial.
The Scenario:
A common scenario for using the NoSQL event sourcing data pattern is in building event-driven microservices architectures. Event sourcing can be particularly valuable in such scenarios due to its ability to capture and store all changes to an application’s state as a sequence of events.
Scenario: Event-Driven Microservices Architecture
- Microservices Communication: In a microservices architecture, different services communicate through events. When an event occurs in one microservice, it can be published to an event bus or event stream. Other microservices can then subscribe to relevant events and react accordingly, updating their own state based on the events received.
- Decoupled Components: Event sourcing allows microservices to be loosely coupled. Each microservice focuses on managing its own events and state changes without needing to know the internal workings of other services. This leads to better separation of concerns and enables each microservice to evolve independently.
- Scalability: As microservices communicate through events, they can scale independently to manage varying workloads. NoSQL databases, which are often used in event sourcing, are designed to scale horizontally, making them well-suited for supporting the high throughput of events generated and consumed by microservices.
- Resilience and Event Replay: In the event of failures or system crashes, event sourcing enables easy recovery by replaying events from the event log. By replaying the events, the application can reconstruct its state and continue processing from the point of failure, ensuring data consistency and reliability.
- Audit and Compliance: Event sourcing provides a complete history of events and state changes, offering a robust audit trail. This is valuable for compliance purposes and helps track and understand how the system reached its current state.
- Event Versioning and Evolution: As services evolve, events can be versioned, and new event types can be introduced. This allows smooth integration with both new and old versions of services. NoSQL databases’ flexibility in handling different data structures makes it easier to manage event versioning.
- Event Replay for Testing and Analytics: Event sourcing allows easy replication of events for testing and analytics purposes. Developers can use a test environment to replay events and verify the behavior of services, while data analysts can analyze the historical event log for insights and business intelligence.
Overall, the NoSQL event sourcing data pattern is well-suited for event-driven microservices architectures, enabling scalability, resilience, and loose coupling among microservices. It’s important to design the events carefully and choose the appropriate NoSQL database that fits the application’s requirements and expected event throughput. Additionally, this pattern requires careful consideration of event schema evolution to ensure backward and forward compatibility as services evolve over time.
Sample Implementation:
Case Study: eCommerce Shopping Cart Application
Design and Implementation
Consider the scenario of an eCommerce company needing to track all changes to a shopping cart. Event sourcing is an ideal choice for this scenario, as it ensures the retention of all history and allows the calculation of the state at any point in time.
In our case study, whenever a change is made to the cart, an event is appended to the `shopping_cart_event` event store collection. This approach avoids the need for updating multiple containers for each change. The partition key ‘/cartId’ is used to support the most common queries by the shopping cart service. Other services can consume data from the change feed and leverage solutions like materialized views for different query patterns.
Code Examples
Consider the state of products in the cart maintained as ‘productsInCart’. This could also be dynamically derived by each query or consumer. Here are sample events in the event store:
{
"cartId": guid,
"sessionId": guid,
"userId": guid,
"eventType": "cart_created",
"eventTimestamp": "2022-11-28 01:22:04"
},
{
"cartId": guid,
"sessionId": guid,
"userId": guid,
"eventType": "product_added",
"product": "Product 1",
"quantityChange": 1,
"productsInCart": [{"productName": "Product 1", "quantity": 1}],
"eventTimestamp": "2022-11-28 01:22:34"
},
{
"cartId": guid,
"sessionId": guid,
"userId": guid,
"eventType": "product_added",
"product": "Product 2",
"quantityChange": 3,
"productsInCart": [{"productName": "Product 1", "quantity": 1},
{"productName": "Product 2", "quantity": 3}],
"eventTimestamp": "2022-11-28 01:22:58"
},
{
"cartId": guid,
"sessionId": guid,
"userId": guid,
"eventType": "product_deleted",
"product": "Product 2",
"quantityChange": -1,
"productsInCart": [{"productName": "Product 1", "quantity": 1},
{"productName": "Product 2", "quantity": 2}],
"eventTimestamp": "2022-11-28 01:23:12"
},
{
"cartId": guid,
"sessionId": guid,
"userId": guid,
"eventType": "cart_purchased",
"productsInCart": [{"productName": "Product 1", "quantity": 1},
{"productName": "Product 2", "quantity": 2}],
"eventTimestamp": "2022-11-28 01:24:45"
}Cost Considerations
When designing and implementing this pattern, it’s essential to consider the cost implications, especially regarding the frequency and volume of events generated.
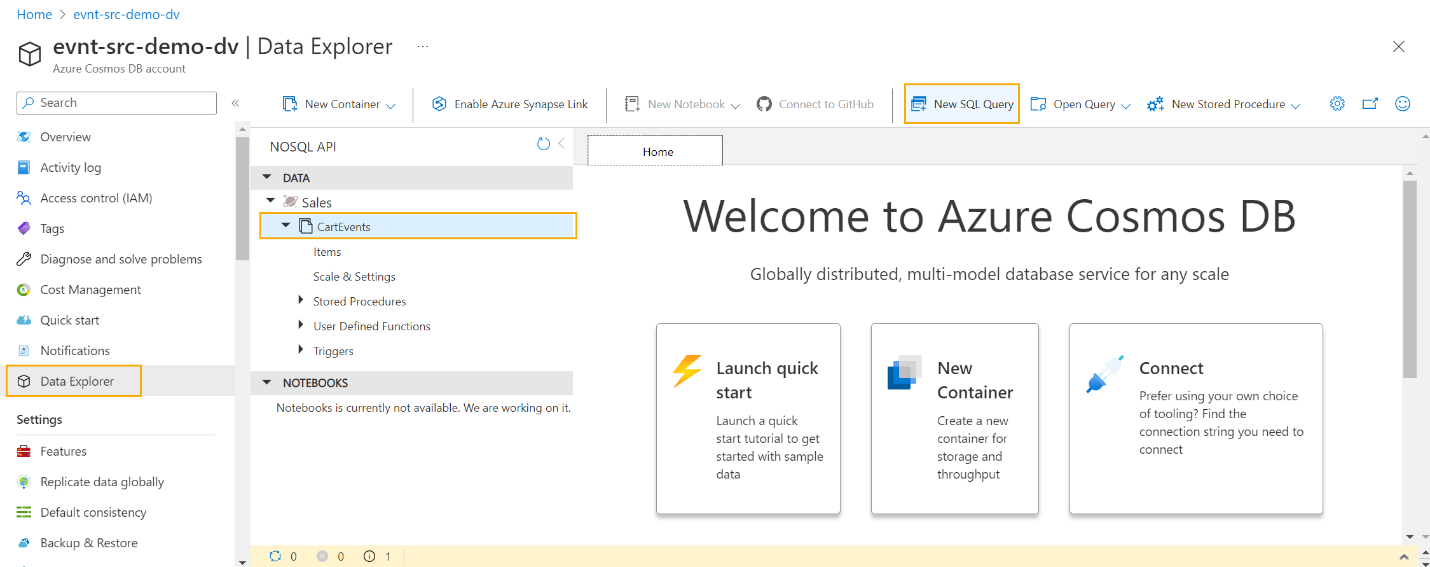
Querying the Event Source Data
After populating the event store with data, you can query it directly using Data Explorer in the Azure Portal. Here’s how:
- In the Azure Portal, navigate your Azure Cosmos DB resource.
- Select Data Explorer from the left menu.
- Choose your container and create a new SQL Query.
The most common query for this appends-only store is to retrieve events for a specific `CartId`, ordered by `EventTimestamp`. For example, to retrieve the latest event for a cart to know its last status and contents, use a query like:
SELECT *
FROM CartEvents c
WHERE c.CartId = "38f4687d-35f2-4933-aadd-8776f4134589"
ORDER BY c.EventTimestamp DESCAdvanced Queries
For more complex scenarios, you can run sophisticated queries on the event container, ideally using the partition key for cost optimization. For instance, if your application does not track `productsInCart`, you can derive this information with a query like:
SELECT c.CartId, c.UserId, c.Product,
SUM(c.QuantityChange) as Quantity
FROM CartEvents c
WHERE c.CartId = "38f4687d-35f2-4933-aadd-8776f4134589"
and IS_NULL(c.Product) = false
GROUP BY c.CartId, c.UserId, c.ProductIn our sample implementation, we explored the event sourcing pattern through the lens of a shopping cart application for an eCommerce company using Azure Cosmos DB. The design emphasized tracking all cart changes as events within a single event store collection named `shopping_cart_event`, with `/cartId` as the partition key to optimize query performance. This setup ensures comprehensive historical data tracking and helps efficient data retrieval and processing by various consuming services. We gave concrete examples of event entries and detailed how to query this data effectively using Azure Portal’s Data Explorer, highlighting the practicality and efficiency of event sourcing in handling dynamic, event-driven data requirements in a NoSQL database environment.
Why it Matters.
Event Sourcing with NoSQL is particularly important for developers due to:
- Immutable History: Ensures a complete, unchangeable record of state changes, enhancing auditability and reliability.
- Resilience and Recovery: Helps system recovery and debugging by allowing the replay of events, improving overall system resilience.
- Scalability and Performance: Supports handling large data volumes efficiently, crucial for distributed systems.
- Flexible Querying: Enables detailed historical data analysis, beneficial for analytics and compliance requirements.
- Microservices Compatibility: Promotes decoupled service interactions, aligning well with microservices architectures.
- Schema Flexibility: NoSQL databases offer the ease of evolving event schemas without complex migrations.
- Real-time Processing: Compatible with real-time data processing and streaming, enabling dynamic, responsive application development.
In conclusion, the Event Sourcing NoSQL design pattern offers developers a robust framework for building scalable, resilient, and flexible applications, particularly in complex, distributed environments. Its advantages in terms of system reliability, data integrity, and architectural flexibility make it a valuable pattern in the toolkit of modern software development.
Getting Started with Azure Cosmos DB Design Patterns
You can review the sample code by visiting the Global Distributed Event Sourcing on GitHub. You can also try this out for yourself by visiting the Azure Cosmos DB Design Patterns GitHub repo and cloning or forking it. Then run locally or from Code Spaces in GitHub. If you are new to Azure Cosmos DB, we have you covered with a free Azure Cosmos DB account for 30 days, no credit card needed. If you want more time, you can extend the free period. You can even upgrade too.
Sign up for your free Azure Cosmos DB account at aka.ms/trycosmosdb.
Explore this and the other design patterns and see how Azure Cosmos DB can enhance your application development and data modeling efforts. Whether you’re an experienced developer or just getting started, the free trial allows you to discover the benefits firsthand.
To get started with Azure Cosmos DB Design Patterns, follow these steps:
- Visit the GitHub repository and explore the various design patterns and best practices provided.
- Clone or download the repository to access the sample code and documentation.
- Review the README files and documentation for each design pattern to understand when and how to apply them to your Azure Cosmos DB projects.
- Experiment with the sample code and adapt it to your specific use cases.
About Azure Cosmos DB
Azure Cosmos DB is a fully managed and serverless distributed database for modern app development, with SLA-backed speed and availability, automatic and instant scalability, and support for open-source PostgreSQL, MongoDB, and Apache Cassandra. Try Azure Cosmos DB for free here. To stay in the loop on Azure Cosmos DB updates, follow us on Twitter, YouTube, and LinkedIn.
0 comments