
We had an incident on VS Online yesterday, starting at 1 AM UTC (5:00 PM PST). The incident was caused by an underlying Azure storage incident affecting many stamps in several regions. I don’t know the root cause of that yet but I’m sure I’ll find out.
I want to start by apologizing for the incident. No incident is good or acceptable. I know it disrupted important work happening for our customers and we take that very seriously.
At the same time, they happen. Nothing you can do can ever 100% prevent them. As a result, how you respond to them is as important as the work you do to prevent them. I wanted to share with you all a mail I sent to my team this morning that, I think, captures both how well the team did and how I think about what’s important.
——- Begin mail thread ——–
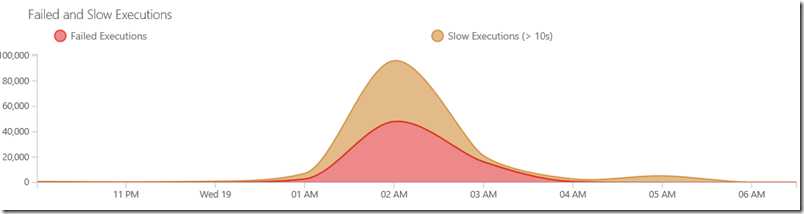
I want to congratulate the team for the hard work and great response to this incident. The availability graph below roughly corresponds to what Buck describes. It would be interesting to see the Azure storage availability graph overlaid so we could measure how much effect our own mitigations had over and above Azure’s.
Things you should be particularly proud of:
- Detection – The issue was detected promptly (before customers reported it)
- Response time – The team was on the issue within minutes.
- Communication – Buck notified me about the incident at 5:21pm PST – that’s within about 20 minutes of incident detection and within 10 minutes of the bridge beginning. More importantly, when I went to our support page a few minutes later, I saw that we had public communication about incident awareness already up for 15 minutes.
- Mitigation – I love the proactive steps taken below to figure out how to adjust the service to best mitigate the effects of the underlying outage.
- Proactiveness – I love that we are going to look at how to make the service able to make those kinds of configuration changes to mitigate effect automatically in the future.
- Telemetry – It’s awesome that I can easily produce the graph in the mail below that very clearly shows the magnitude and duration of the incident (note there’s more data on availability, etc that I didn’t include in the picture below).
- Tracking – There was great tracking of the exact incident and response. The fact that I can write this mail within 12 hours documenting what happened down to the minute is kind of amazing. It’s hard to understate how difficult it is to avoid the “fog of war” that obscures what’s actually going on in cases like this. Without a clear record of what happened and when, it’s hard to be precise about where you can improve.
There’s a lot here to be proud of. Great work all of you…
Brian
From: Buck Hodges Sent: Tuesday, November 18, 2014 8:15 PM To: Brian Harry Subject: FW: Mitigations and Rollback steps
These were the two things we did. The first made the service usable for most everyone (SPS was down due the calls to storage taking forever for things like roaming settings). The second made it usable by the rest (if your user prefs weren’t cached, you got a 500 when the web page loaded – I had a couple of accounts affected that way, which we used to verify that change addressed the problem). We’ll be changing the code to be resilient there. Due to past problems, we at least had the switches to be able to turn them off.
Some users may still have some issues intermittently with accessing files, work item attachments, git pushes.
This pair of changes put us in pretty good shape relatively quickly. A lot of other services didn’t fare as well.
Reaction time was not bad with room for improvement. First alert at 4:58 PM PST. First customer report via Twitter 5:03 PM PST (from Australia). Bridge spun up by 5:10 and had a bunch of people on it within a few minutes. Took us a little while to get to the storage issue. Applied the first change at 5:40 and figured out issue to address with second change an hour later. We actually have a report that makes the storage issue pretty clear. We need to get storage represented our devops overview report to narrow it down faster.
We’ll leave these mitigations in place until we get clear indications that things are good, both from azure and from pinging our storage accounts (probably over night).
Buck
——– End mail thread ——–
Again, it is not my intent to overlook the seriousness of any outage. But one of the things that I’ve learned is that building the culture in the team and leaders who are quick, decisive, drive for root cause and are always asking how we can do better in the future is one of the most important things any team running a mission critical service can do. I’m not proud of what happened last night. But I’m very proud of how the team handled it.
Hopefully there’s something you can extract from this that will help you run better services too.
Brian
0 comments
Be the first to start the discussion.